
При записи в файл слетает кодировка c
Обновлено: 16.05.2024
Как правило, при совместной работе с текстовыми файлами нет необходимости вникать в технические аспекты хранения текста. Однако если необходимо поделиться файлом с человеком, который работает с текстами на других языках, скачать текстовый файл из Интернета или открыть его на компьютере с другой операционной системой, может потребоваться задать кодировку при его открытии или сохранении.
Когда вы открываете текстовый файл в Microsoft Word или другой программе (например, на компьютере, язык операционной системы на котором отличается от того, на котором написан текст в файле), кодировка помогает программе определить, в каком виде нужно вывести текст на экран, чтобы его можно было прочитать.
В этой статье
Общие сведения о кодировке текста
То, что отображается на экране как текст, фактически хранится в текстовом файле в виде числового значения. Компьютер преобразует числические значения в видимые символы. Для этого используется кодикон.
Кодировка — это схема нумерации, согласно которой каждому текстовому символу в наборе соответствует определенное числовое значение. Кодировка может содержать буквы, цифры и другие символы. В различных языках часто используются разные наборы символов, поэтому многие из существующих кодировок предназначены для отображения наборов символов соответствующих языков.
Различные кодировки для разных алфавитов
Сведения о кодировке, сохраняемые с текстовым файлом, используются компьютером для вывода текста на экран. Например, в кодировке "Кириллица (Windows)" знаку "Й" соответствует числовое значение 201. Когда вы открываете файл, содержащий этот знак, на компьютере, на котором используется кодировка "Кириллица (Windows)", компьютер считывает число 201 и выводит на экран знак "Й".
Однако если тот же файл открыть на компьютере, на котором по умолчанию используется другая кодировка, на экран будет выведен знак, соответствующий числу 201 в этой кодировке. Например, если на компьютере используется кодировка "Западноевропейская (Windows)", знак "Й" из исходного текстового файла на основе кириллицы будет отображен как "É", поскольку именно этому знаку соответствует число 201 в данной кодировке.
Юникод: единая кодировка для разных алфавитов
Чтобы избежать проблем с кодированием и декодированием текстовых файлов, можно сохранять их в Юникоде. В состав этой кодировки входит большинство знаков из всех языков, которые обычно используются на современных компьютерах.
Так как Word работает на базе Юникода, все файлы в нем автоматически сохраняются в этой кодировке. Файлы в Юникоде можно открывать на любом компьютере с операционной системой на английском языке независимо от языка текста. Кроме того, на таком компьютере можно сохранять в Юникоде файлы, содержащие знаки, которых нет в западноевропейских алфавитах (например, греческие, кириллические, арабские или японские).
Выбор кодировки при открытии файла
Если в открытом файле текст искажен или выводится в виде вопросительных знаков либо квадратиков, возможно, Word неправильно определил кодировку. Вы можете указать кодировку, которую следует использовать для отображения (декодирования) текста.
Откройте вкладку Файл.
Перейдите к разделу Общие и установите флажокПодтверждать преобразование формата файла при открытии.
Примечание: Если установлен этот флажок, Word отображает диалоговое окно Преобразование файла при каждом открытии файла в формате, отличном от формата Word (то есть файла, который не имеет расширения DOC, DOT, DOCX, DOCM, DOTX или DOTM). Если вы часто работаете с такими файлами, но вам обычно не требуется выбирать кодировку, не забудьте отключить этот параметр, чтобы это диалоговое окно не выводилось.
Закройте, а затем снова откройте файл.
В диалоговом окне Преобразование файла выберите пункт Кодированный текст.
В диалоговом окне Преобразование файла установите переключатель Другая и выберите нужную кодировку из списка.
В области Образец можно просмотреть текст и проверить, правильно ли он отображается в выбранной кодировке.
Если почти весь текст выглядит одинаково (например, в виде квадратов или точек), возможно, на компьютере не установлен нужный шрифт. В таком случае можно установить дополнительные шрифты.
Чтобы установить дополнительные шрифты, сделайте следующее:
Выполните одно из указанных ниже действий.
В Windows 7
На панели управления выберите раздел Удаление программы.
В списке программ щелкните Microsoft Office или Microsoft Word, если он был установлен отдельно от пакета Microsoft Office, и нажмите кнопку Изменить.
В Windows Vista
На панели управления выберите раздел Удаление программы.
В списке программ щелкните Microsoft Office или Microsoft Word, если он был установлен отдельно от пакета Microsoft Office, и нажмите кнопку Изменить.
В Windows XP
На панели управления щелкните элемент Установка и удаление программ.
В списке Установленные программы щелкните Microsoft Office или Microsoft Word, если он был установлен отдельно от пакета Microsoft Office, и нажмите кнопку Изменить.
В группе Изменение установки Microsoft Office нажмите кнопку Добавить или удалить компоненты и затем нажмите кнопку Продолжить.
В разделе Параметры установки разверните элемент Общие средства Office, а затем — Многоязыковая поддержка.
Выберите нужный шрифт, щелкните стрелку рядом с ним и выберите пункт Запускать с моего компьютера.
Совет: При открытии текстового файла в той или иной кодировке в Word используются шрифты, определенные в диалоговом окне Параметры веб-документа. (Чтобы вызвать диалоговое окно Параметры веб-документа, нажмите кнопку Microsoft Office, затем щелкните Параметры Word и выберите категорию Дополнительно. В разделе Общие нажмите кнопку Параметры веб-документа.) С помощью параметров на вкладке Шрифты диалогового окна Параметры веб-документа можно настроить шрифт для каждой кодировки.
Выбор кодировки при сохранении файла
Если не выбрать кодировку при сохранении файла, будет использоваться Юникод. Как правило, рекомендуется применять Юникод, так как он поддерживает большинство символов большинства языков.
Если документ планируется открывать в программе, которая не поддерживает Юникод, вы можете выбрать нужную кодировку. Например, в операционной системе на английском языке можно создать документ на китайском (традиционное письмо) с использованием Юникода. Однако если такой документ будет открываться в программе, которая поддерживает китайский язык, но не поддерживает Юникод, файл можно сохранить в кодировке "Китайская традиционная (Big5)". В результате текст будет отображаться правильно при открытии документа в программе, поддерживающей китайский язык (традиционное письмо).
Примечание: Так как Юникод — это наиболее полный стандарт, при сохранении текста в других кодировках некоторые знаки могут не отображаться. Предположим, например, что документ в Юникоде содержит текст на иврите и языке с кириллицей. Если сохранить файл в кодировке "Кириллица (Windows)", текст на иврите не отобразится, а если сохранить его в кодировке "Иврит (Windows)", то не будет отображаться кириллический текст.
Если выбрать стандарт кодировки, который не поддерживает некоторые символы в файле, Word пометит их красным. Вы можете просмотреть текст в выбранной кодировке перед сохранением файла.
При сохранении файла в виде кодированного текста из него удаляется текст, для которого выбран шрифт Symbol, а также коды полей.
Выбор кодировки
Откройте вкладку Файл.
Выберите пункт Сохранить как.
Чтобы сохранить файл в другой папке, найдите и откройте ее.
В поле Имя файла введите имя нового файла.
В поле Тип файла выберите Обычный текст.
Если появится диалоговое окно Microsoft Office Word — проверка совместимости, нажмите кнопку Продолжить.
В диалоговом окне Преобразование файла выберите подходящую кодировку.
Чтобы использовать стандартную кодировку, выберите параметр Windows (по умолчанию).
Чтобы использовать кодировку MS-DOS, выберите параметр MS-DOS.
Чтобы задать другую кодировку, установите переключатель Другая и выберите нужный пункт в списке. В области Образец можно просмотреть текст и проверить, правильно ли он отображается в выбранной кодировке.
Примечание: Чтобы увеличить область отображения документа, можно изменить размер диалогового окна Преобразование файла.
Если разрешена подстановка знаков, знаки, которые невозможно отобразить, будут заменены ближайшими эквивалентными символами в выбранной кодировке. Например, многоточие заменяется тремя точками, а угловые кавычки — прямыми.
Если в выбранной кодировке нет эквивалентных знаков для символов, выделенных красным цветом, они будут сохранены как внеконтекстные (например, в виде вопросительных знаков).
Если документ будет открываться в программе, в которой текст не переносится с одной строки на другую, вы можете включить в нем жесткие разрывы строк. Для этого установите флажок Вставлять разрывы строк и укажите нужное обозначение разрыва (возврат каретки (CR), перевод строки (LF) или оба значения) в поле Завершать строки.
Поиск кодировок, доступных в Word
Word распознает несколько кодировок и поддерживает кодировки, которые входят в состав системного программного обеспечения.
Ниже приведен список письменностей и связанных с ними кодировок (кодовых страниц).
В учебнике Лафоре на стр.551-553 рассказано про форматированный вывод данных в файл, получение данных из файла.
Даются две небольшие программы. Первая выводит в файл символ, целое и вещественное числа, две строки и сообщает об окончании вывода (в консоль). Вторая — читает из созданного первой программой файла данные и выводит их на экран (в консоль).
Привычно (подробности — тут) переделываю эти программы вместо работы с обычными символами (char) для работы с широкими символами (wchar_t), чтобы можно было работать в программе с Юникодом (в том числе с русскими буквами). То есть тип char меняем на wchar_t, string на wstring, ofstream на wofstream, ifstream на wifstream, cout на wcout, символьные и строковые литералы предваряем префиксом L.
Кстати, чтобы смена cout на wcout сработала, в Windows требуется переключить стандартный поток вывода в формат Юникода (в Линуксе это делается по-другому) с помощью функции _setmode, которая требует подключения заголовочных файлов <io.h> и <fcntl.h>.
Как оказалось, для вывода в файл (чтения из файла) широких символов недостаточно использования классов, работающих с широкими символами — wofstream и wifstream (я ожидал, что запись в файл будет произведена в кодировке UTF-16, исходя из того, что символы в Windows хранятся в кодировке UCS-2 (подмножество UTF-16), но этого не случилось).
Для правильного вывода русских букв в файл в данном случае требуется для текущей локали (объект соответствующего класса locale, содержащий набор параметров, определяющих региональные настройки) правильно настроить ее фасет класса codecvt (набор параметров локали поделен на отдельные разделы, называемые фасетами), регулирующий преобразование символов из одной кодировки в другую.
Раз уж итоговую кодировку текстового файла, в который будем записывать данные, всё равно нужно будет указывать, то выбираю кодировку UTF-8, как самую популярную на сегодня для текстовых файлов. Для этой кодировки имеется специальный фасет класса codecvt_utf8.
Для использования указанных классов в программу должны быть включены соответствующие заголовочные файлы <locale> и <codecvt>.
Итак, в начале функции main обеих программ создадим константу, содержащую локаль с нужным фасетом для преобразования символов при сохранении в файл в кодировке UTF-8:
А после создания объекта-потока нужного класса свяжем наш поток с определенной ранее локалью, воспользовавшись методом ios::imbue:
для второй программы:
После этого обе программы должны работать правильно, а информация будет храниться в текстовом файле в кодировке UTF-8.


@kain Сохранил в txt, переименовал в csv, открыл в Excel, результат:
файл 1.txt
Переименованный файл 1.csv
Так что перекодировать всё равно приходится
@fox
А как указать путь чтоб брало файл с диска С:papka и ставило туда-же после перекодирования?
В Вашем примере работает только когда исходный файл лежит в папке AppData\Roaming\BrowserAutomationStudio\apps\21.0.1\
если там его нету то какие пути не указывай - не работает
пробывал так iconv -t WINDOWS-1251 -f UTF-8 C:\test\1.csv > "C:\test\1.csv"
может что не то делаю?
Записывает C:\test\1.csv нормально после перекодировки пустой файл
@avtopars Вы посмотрите внимательнее, я сам этот файл создаю в директории
и потом его конвертирую в нужную папку.
пробывал так iconv -t WINDOWS-1251 -f UTF-8 C:\test\1.csv > "C:\test\1.csv"
Нужно сохранять в другой файл. Можете поменять папку и сохранять с этим же именем
Мда. 2 дня гемора и наконец решение,мож кому-то тоже пригодится.
Суть такая
Проект от @fox работает,делаю вроде все так-же но ничего не работает.
Вместо нужного результата после смены кодировки получаю свой файл но он пустой 0 байт.
Создал новый проект чистый делаю все с нуля все работает, возвращаюсь в старый проект и тут вроде все также но не пашет и все тут.
Решение оказалось банальным в старом проекте в названии файла было пару слов и из-за пробелов нечего не работало. Если файл 1 слово все прекрасно конвертируется.
Логичный вопрос как решить проблему пробелов? Вернее как писать название файлов с пробелами так чтоб утилита это понимала?
@avtopars Действие "выполнить процесс" по сути создаёт bat файл и выполняет его, грубо говоря. А в командной строке если в пути встречается кирилица или пробелы, его обрамляют в кавычки. По сути можно любой путь обрамлять в кавычки, на всякий случай и всё.
@fox
Вы говорили что пользуетесь утилиткой давно,а проблем не возникало с конвертацией?
У меня почему-то она обрезает файл
Например csv оригинал имеет 130 строк выходной подрезает и получается 100 или 25-75 как получится.
от чего зависит не знаю но факт такой есть и это точно она делает,а не бас и ничто другое.
Кстати не всегда иногда и полный файл выдает
Вы говорили что пользуетесь утилиткой давно
Где я такое говорил?
Например csv оригинал имеет 130 строк выходной подрезает и получается 100 или 25-75 как получится.
В общем проблема более менее понятна.
Встречаются разные символы на источнике которые утилита не читает или не понимает, если их заменять на что-то тогда конвертится нормально без обрезок.
Символы которые встречаются в разных случаях разные,тут помоему общего решения нет. В каждом отдельном случае нужно смотреть на чем затык и добавлять его в обработку
Как пример слова не нашего алфавита Pułaskiego Namysłów
ну и вот на символах ł ó и будет обрезка
Ну и символы типа 89×65×92 см где встретится × там и порежет
@fox может есть мысли по поводу решения проблемы?
Обратился к разработчику за помощью в решении проблемы с конвертацией.
Выложу это тут для будущих поколений ))
Через node js проблема решается полностью, для работы нужно поставить модуль encoding
Следующий код решает проблемы
Код если пути у нас в переменных
Отдельная благодарность @fox за участие и консультации

@avtopars Пасиб, не только будущих но и счас. В лайв хаки можно смело. Правда с "узлами" не все дружат.. Пойдут вопросы как))

@fox возможно это только в лайброфис.
Сейчас новый прикол) Конвертирую после каждой записи и сейчас перестал дописывать сконвертированный файл после того, как он начинает весить где-то 13кб) Хрен знает почему)
@fox Перезаписываю кодировку файла csv по вашему проекту. Почему то перезаписывается только первая строчка, а остальные удаляются.
Сработал вариант @avtopars при сохранении.
Но потом когда BAS открывает заново этот файл он уже нечитаем.
Как его при открытии сконвертировать обратно в UTF-8
Пробовал заменить этот же вариант так:
Как правило, при совместной работе с текстовыми файлами нет необходимости вникать в технические аспекты хранения текста. Однако если необходимо поделиться файлом с человеком, который работает с текстами на других языках, скачать текстовый файл из Интернета или открыть его на компьютере с другой операционной системой, может потребоваться задать кодировку при его открытии или сохранении.
Когда вы открываете текстовый файл в Microsoft Word или другой программе (например, на компьютере, язык операционной системы на котором отличается от того, на котором написан текст в файле), кодировка помогает программе определить, в каком виде нужно вывести текст на экран, чтобы его можно было прочитать.
В этой статье
Общие сведения о кодировке текста
То, что отображается на экране как текст, фактически хранится в текстовом файле в виде числового значения. Компьютер преобразует числические значения в видимые символы. Для этого используется кодикон.
Кодировка — это схема нумерации, согласно которой каждому текстовому символу в наборе соответствует определенное числовое значение. Кодировка может содержать буквы, цифры и другие символы. В различных языках часто используются разные наборы символов, поэтому многие из существующих кодировок предназначены для отображения наборов символов соответствующих языков.
Различные кодировки для разных алфавитов
Сведения о кодировке, сохраняемые с текстовым файлом, используются компьютером для вывода текста на экран. Например, в кодировке "Кириллица (Windows)" знаку "Й" соответствует числовое значение 201. Когда вы открываете файл, содержащий этот знак, на компьютере, на котором используется кодировка "Кириллица (Windows)", компьютер считывает число 201 и выводит на экран знак "Й".
Однако если тот же файл открыть на компьютере, на котором по умолчанию используется другая кодировка, на экран будет выведен знак, соответствующий числу 201 в этой кодировке. Например, если на компьютере используется кодировка "Западноевропейская (Windows)", знак "Й" из исходного текстового файла на основе кириллицы будет отображен как "É", поскольку именно этому знаку соответствует число 201 в данной кодировке.
Юникод: единая кодировка для разных алфавитов
Чтобы избежать проблем с кодированием и декодированием текстовых файлов, можно сохранять их в Юникоде. В состав этой кодировки входит большинство знаков из всех языков, которые обычно используются на современных компьютерах.
Так как Word работает на базе Юникода, все файлы в нем автоматически сохраняются в этой кодировке. Файлы в Юникоде можно открывать на любом компьютере с операционной системой на английском языке независимо от языка текста. Кроме того, на таком компьютере можно сохранять в Юникоде файлы, содержащие знаки, которых нет в западноевропейских алфавитах (например, греческие, кириллические, арабские или японские).
Выбор кодировки при открытии файла
Если в открытом файле текст искажен или выводится в виде вопросительных знаков либо квадратиков, возможно, Word неправильно определил кодировку. Вы можете указать кодировку, которую следует использовать для отображения (декодирования) текста.
Откройте вкладку Файл.
Перейдите к разделу Общие и установите флажокПодтверждать преобразование формата файла при открытии.
Примечание: Если установлен этот флажок, Word отображает диалоговое окно Преобразование файла при каждом открытии файла в формате, отличном от формата Word (то есть файла, который не имеет расширения DOC, DOT, DOCX, DOCM, DOTX или DOTM). Если вы часто работаете с такими файлами, но вам обычно не требуется выбирать кодировку, не забудьте отключить этот параметр, чтобы это диалоговое окно не выводилось.
Закройте, а затем снова откройте файл.
В диалоговом окне Преобразование файла выберите пункт Кодированный текст.
В диалоговом окне Преобразование файла установите переключатель Другая и выберите нужную кодировку из списка.
В области Образец можно просмотреть текст и проверить, правильно ли он отображается в выбранной кодировке.
Если почти весь текст выглядит одинаково (например, в виде квадратов или точек), возможно, на компьютере не установлен нужный шрифт. В таком случае можно установить дополнительные шрифты.
Чтобы установить дополнительные шрифты, сделайте следующее:
Выполните одно из указанных ниже действий.
В Windows 7
На панели управления выберите раздел Удаление программы.
В списке программ щелкните Microsoft Office или Microsoft Word, если он был установлен отдельно от пакета Microsoft Office, и нажмите кнопку Изменить.
В Windows Vista
На панели управления выберите раздел Удаление программы.
В списке программ щелкните Microsoft Office или Microsoft Word, если он был установлен отдельно от пакета Microsoft Office, и нажмите кнопку Изменить.
В Windows XP
На панели управления щелкните элемент Установка и удаление программ.
В списке Установленные программы щелкните Microsoft Office или Microsoft Word, если он был установлен отдельно от пакета Microsoft Office, и нажмите кнопку Изменить.
В группе Изменение установки Microsoft Office нажмите кнопку Добавить или удалить компоненты и затем нажмите кнопку Продолжить.
В разделе Параметры установки разверните элемент Общие средства Office, а затем — Многоязыковая поддержка.
Выберите нужный шрифт, щелкните стрелку рядом с ним и выберите пункт Запускать с моего компьютера.
Совет: При открытии текстового файла в той или иной кодировке в Word используются шрифты, определенные в диалоговом окне Параметры веб-документа. (Чтобы вызвать диалоговое окно Параметры веб-документа, нажмите кнопку Microsoft Office, затем щелкните Параметры Word и выберите категорию Дополнительно. В разделе Общие нажмите кнопку Параметры веб-документа.) С помощью параметров на вкладке Шрифты диалогового окна Параметры веб-документа можно настроить шрифт для каждой кодировки.
Выбор кодировки при сохранении файла
Если не выбрать кодировку при сохранении файла, будет использоваться Юникод. Как правило, рекомендуется применять Юникод, так как он поддерживает большинство символов большинства языков.
Если документ планируется открывать в программе, которая не поддерживает Юникод, вы можете выбрать нужную кодировку. Например, в операционной системе на английском языке можно создать документ на китайском (традиционное письмо) с использованием Юникода. Однако если такой документ будет открываться в программе, которая поддерживает китайский язык, но не поддерживает Юникод, файл можно сохранить в кодировке "Китайская традиционная (Big5)". В результате текст будет отображаться правильно при открытии документа в программе, поддерживающей китайский язык (традиционное письмо).
Примечание: Так как Юникод — это наиболее полный стандарт, при сохранении текста в других кодировках некоторые знаки могут не отображаться. Предположим, например, что документ в Юникоде содержит текст на иврите и языке с кириллицей. Если сохранить файл в кодировке "Кириллица (Windows)", текст на иврите не отобразится, а если сохранить его в кодировке "Иврит (Windows)", то не будет отображаться кириллический текст.
Если выбрать стандарт кодировки, который не поддерживает некоторые символы в файле, Word пометит их красным. Вы можете просмотреть текст в выбранной кодировке перед сохранением файла.
При сохранении файла в виде кодированного текста из него удаляется текст, для которого выбран шрифт Symbol, а также коды полей.
Выбор кодировки
Откройте вкладку Файл.
Выберите пункт Сохранить как.
Чтобы сохранить файл в другой папке, найдите и откройте ее.
В поле Имя файла введите имя нового файла.
В поле Тип файла выберите Обычный текст.
Если появится диалоговое окно Microsoft Office Word — проверка совместимости, нажмите кнопку Продолжить.
В диалоговом окне Преобразование файла выберите подходящую кодировку.
Чтобы использовать стандартную кодировку, выберите параметр Windows (по умолчанию).
Чтобы использовать кодировку MS-DOS, выберите параметр MS-DOS.
Чтобы задать другую кодировку, установите переключатель Другая и выберите нужный пункт в списке. В области Образец можно просмотреть текст и проверить, правильно ли он отображается в выбранной кодировке.
Примечание: Чтобы увеличить область отображения документа, можно изменить размер диалогового окна Преобразование файла.
Если разрешена подстановка знаков, знаки, которые невозможно отобразить, будут заменены ближайшими эквивалентными символами в выбранной кодировке. Например, многоточие заменяется тремя точками, а угловые кавычки — прямыми.
Если в выбранной кодировке нет эквивалентных знаков для символов, выделенных красным цветом, они будут сохранены как внеконтекстные (например, в виде вопросительных знаков).
Если документ будет открываться в программе, в которой текст не переносится с одной строки на другую, вы можете включить в нем жесткие разрывы строк. Для этого установите флажок Вставлять разрывы строк и укажите нужное обозначение разрыва (возврат каретки (CR), перевод строки (LF) или оба значения) в поле Завершать строки.
Поиск кодировок, доступных в Word
Word распознает несколько кодировок и поддерживает кодировки, которые входят в состав системного программного обеспечения.
Ниже приведен список письменностей и связанных с ними кодировок (кодовых страниц).
При неправильной кодировке весь сайт или его часть отображаются в виде «кряпозяблов», т.е. непонятных символов, делающих текст нечитаемым. Такая ситуация может возникнуть при неверной настройке кодировки веб-сервера или при отсутствии настроек. Рассмотрим возможные варианты и способы устранения проблем
Неправильная кодировка HTML страниц
Создадим тестовый файлик:
Скопируем в него следующий HTML код, в котором отсутствует указание кодировки и посмотрим, какие проблемы могут с ним возникнуть и как их решить:
Как можно видеть, кодировка браузером определена неправильно:
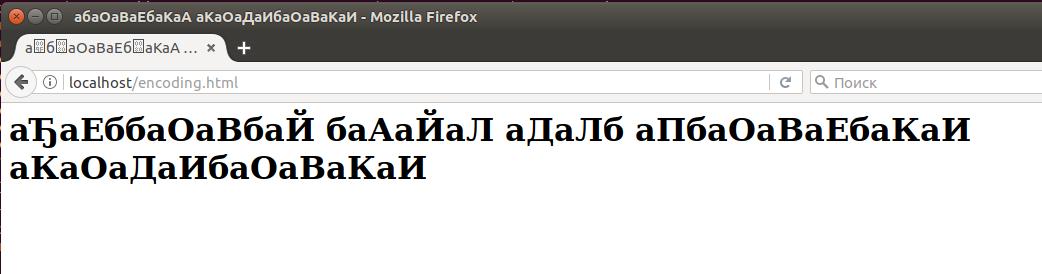
Добавим эту строку к нашему тестовому файлику, чтобы получилось так:
Как мы можем убедиться на следующем скриншоте, проблема решена:
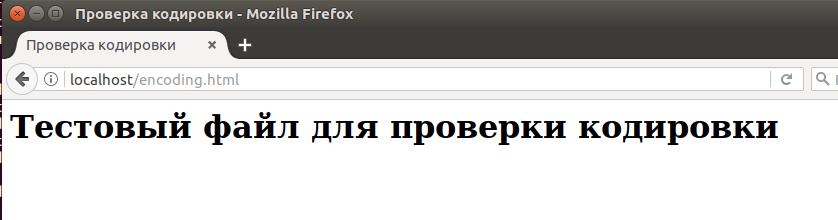
Если кодировка вашего файла отличается от UTF-8, то вместо неё поставьте windows-1251 или ту, которая соответствует кодировке веб-страницы. Чтобы научиться определять кодировку файлов, посмотрите эту инструкцию.
Это был самый простой способ исправления проблемы с кодировкой – без изменения настроек сервера.
Вернём наш тестовый файл в исходное состояние и продолжим изучение способов указания кодировки.
Если файлы .htaccess включены настройками Apache, то эти файлы можно использовать чтобы указывать кодировку отправляемых веб-сервером страниц. Чтобы включить поддержку файлов .htaccess в конфигурационном файле Apache ( /etc/apache2/apache2.conf ) найдите группу строк
И в ней замените
После этого сервер нужно перезапустить.
Файл .htaccess должен быть размещён в той же директории, что и сайт. Мой сайт размещён в корневой директории веб-сервера. Если у вас также, то теперь в папке /var/www/html/ создайте файл .htaccess и добавьте в него директиву AddDefaultCharset после которой укажите желаемую кодировку. Примеры
Можно указать кодировку, которая будет применена только к файлам определённого формата:
Набор файлов может быть любым, например:
Следующий вариант является альтернативным и также позволяет устанавливать кодировку для файлов определённого типа, для него нужно, чтобы был включён mod_headers:
Ещё один вариант, который также можно использовать в файле .htaccess для установки кодировки UTF-8:
Если сайт на PHP, то дополнительно может понадобиться продублировать кодировку с php_value default_charset:
Как установить UTF-8 кодировку в PHP
В PHP скрипте для установки кодировки используется header, например:
Обычно вместе с кодировкой также указывают тип содержимого (в примере вариант для HTML страницы):
Ещё один вариант для RSS ленты:
Описанный способ работает только когда PHP скрипт полностью генерирует содержимое страницы. Статические страницы (такие как html) вы должны сохранять в кодировке utf-8. Большинство веб серверов обратят внимание на кодировку файла и добавят соответствующий заголовок. На самом деле, сохранение PHP файла в кодировке utf-8 приведёт к такому же результату.
Неправильная кодировка результатов из базы данных MySQL
Если ваш сайт состоит из статической части (шаблон) и динамической, которая формируется из данных, получаемых из базы данных, то может возникнуть ситуация, когда часть сайта имеет правильную кодировку, а другая часть сайта имеет неправильную. В этом случае бесполезно менять настройки веб-сервера – поскольку всё равно часть страницы будет иметь неправильную кодировку.
Нужно начать с определения кодировки ваших таблиц. Можно посмотреть в phpMyAdmin:

Обратите внимание на столбец «Сравнение», запись «utf8_unicode_ci» означает, что используется кодировка UTF-8.
Можно подключиться к СУБД MySQL и проверить кодировку таблиц без phpMyAdmin. Для этого:
Если вы забыли имя базы данных, то выполните команду:
Предположим, я хочу посмотреть кодировку для таблиц в базе данных information_schema
Если вы забыли имя таблиц, выполните:
Далее выполните команду, в которой имя_таблицы замените на настоящее имя таблицы:
Вы увидите примерно следующее:

Смотрите столбец Collation. В моём случае там utf8_general_ci, это, как и utf8_unicode_ci, кодировка UTF-8. Кстати, если вы не знаете в чём разница между кодировками utf8_general_ci, utf8_unicode_ci, utf8mb4_general_ci, utf8mb4_unicode_ci, а также какую кодировку выбрать для базы данных MySQL, то посмотрите эту статью.
Теперь, когда мы узнали кодировку (в моём случае это UTF-8), то при каждом подключении к СУБД MySQL нужно выполнять последовательно запросы:
В PHP это можно сделать примерно так:
Обратите внимание, что UTF8 вам нужно заменить на ту кодировку, которая используется для ваших таблиц.
Изменение кодировки файлов
Если вы решили пойти другим путём и вместо установки новой кодировки изменить кодировку ваших файлов, то посмотрите статью «Как конвертировать файлы в кодировку UTF-8 в Linux». В ней рассказано, как узнать текущую кодировку файлов и как конвертировать файлы в любую кодировку (не только UTF-8).
Как узнать, какую кодировку отправляет сервер
Если вы хотите узнать, какие настройки кодировки имеет веб-сервер (какую кодировку передаёт в заголовках), то воспользуйтесь следующей командой:

Какую кодировку выбрать для веб-сайта
Рекомендуется выбрать кодировку UTF-8. Это более универсальная кодировка, практически, она стала стандартом. У вас не будет проблем с отображением необычных символов и букв из других алфавитов.
Читайте также: