
Проверка pdf файлов на ошибки
Обновлено: 03.07.2024
Вы когда-нибудь задавались вопросом, возможно ли проверить орфографию в файле PDF-формата?" А может быть вы спрашивали кого нибудь о том, как проверить орфографию в PDF-файле? Если ваш PDF-файл был создан в Word, PowerPoint или любой другой программе с возможностью проверки орфографии, то скорее всего, такой документ будет автоматически проверен программой, а значит, количество орфографических ошибок будет минимальным. Тем не менее, автоматические системы проверки орфографии могут пропустить некоторое количество ошибок, поэтому всегда важно проверять орфографию PDF-файлов, чтобы убедиться в правильности текста. К счастью, в PDFelement есть подходящее решение.
PDFelement – это эффективный PDF-редактор с массой полезных функций для пользователей. Его можно использовать для добавления и редактирования аннотаций, включая сноски и заметки, выделение текста и разметку документа. В отличие от многих других PDF-редакторов, в данной программе вы можете использовать функцию оптического распознавания символов (OCR) для редактирования отсканированных документов. С помощью этого инструмента вы можете загружать и заполнять формы, объединять и разделять PDF-документы, вставлять и заменять страницы PDF и даже извлекать их содержимое.
Лучший способ проверки правописания в PDF
Шаг 1. Загрузка PDF-файлов для проверки орфографии
Запустите PDFelement и импортируйте PDF в программу. Чтобы найти файл и открыть его, перетащите PDF-файл в окно программы или нажмите «Открыть файл» в главном меню.
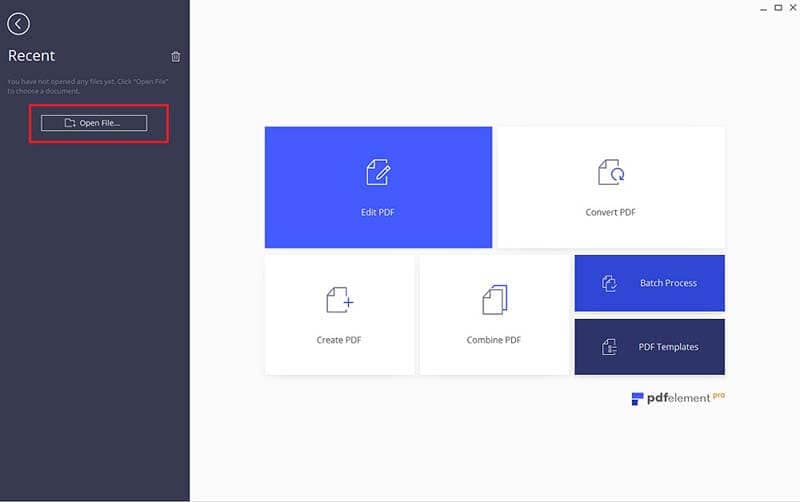
Шаг 2. Установка настроек проверки орфографии
Включение функции проверки орфографии: После открытия файла перейдите во вкладку «Файл» и выберите «Настройки» > «Общие». Чтобы включить проверку правописания, выберите соответствующую опцию в PDFelement.
Настройте пользовательский словарь: Нажмите «Пользовательский словарь», чтобы добавить специальную лексику в собственный словарь.

Шаг 3. Проверка орфографии в PDF-файле

Шаг 4. Редактирование PDF-файлов
Вы можете использовать проверку орфографии в PDFelement для проверки грамматических ошибок и внесения других быстрых правок в ваш файл. Вы можете вставлять, удалять, редактировать или заменять текст документа, одновременно проверяя орфографические ошибки. Не забудьте сохранить документ после окончания работы, чтобы убедиться, что внесенные изменения сохранены и не будут потеряны.
Помимо редактирования текста, вы можете использовать другие функции PDFelement для выполнения других операций с вашим документом, включая вставку, удаление или изменение положения изображений в документе. Узнайте больше о том, как редактировать PDF-файлы здесь. Если вы планируете работать с отсканированными файлами, подумайте о покупке полной версии программы для разблокировки функции оптического распознавания символов (OCR).

Иногда файлы PDF могут быть повреждены при отправке файлов PDF, передаче их между системами или компьютерами или получении их с жесткого диска несколько лет назад. Ваш PDF-файл также может быть поврежден во время создания.
Теперь некоторые проблемы, которые мешают вам открывать PDF-файлы, могут быть исправлены! Попробуйте эти сайты, которые я представил ниже, не только для простых, но и бесплатных.
1. Общие причины повреждения файла PDF
PDF (Portable Document Format), вероятно, является самым популярным форматом документов, потому что он поддерживается всеми операционными системами и является более безопасным. PDF-документы трудно изменить, и они также могут быть защищены паролем и водяными знаками.
- Файл PDF не читаемый с вашим программным обеспечением
- Корневой объект недействительный or отсутствующий
- Файл поврежденный or развращать
- Это был ошибка открытия этот документ
- Это был обработка ошибок эту страницу
- Содержит информацию не понял зрителем
- Ошибка формата - Не PDF-файл или поврежден
Чаще всего такие ошибки можно отнести к неисправность программного обеспечения (В том числе браузеры, почтовые программы, операционная система, антивирусное программное обеспечение or брандмауэр).
PDF2GO: Конвертируйте PDF файлы онлайн без установки программного обеспечения.
С помощью этого сайта PDF ремонта значительно проще. Все, что вам нужно сделать, это загрузить свой PDF-файл (облачное хранилище также поддерживается), и позвольте нам сделать волшебство. После этого просто загрузите отремонтированный PDF-документ.
В PDF2Go мы специализируемся на конвертации и редактировании файлов PDF. Таким образом, если вы попытаетесь восстановить документ другого типа, мы сначала преобразуем его в PDF, а затем запустим исправление. Однако полученный вами файл всегда будет PDF-документом.
Ремонт PDF - это бесплатный PDF доктор. У вас есть важный PDF, но когда вы откроете его в Adobe PDF Reader, он скажет, что файл поврежден? Есть много причин, по которым файл PDF может быть поврежден.
Этот веб-сайт восстановления PDF ищет все возможные причины и исправляет их все. Поврежденный PDF-файл будет исправлен, так что вы можете просмотреть его в любом PDF-ридере. Лишь в очень редких случаях файл PDF поврежден и не подлежит восстановлению.
Поврежденные PDF-файлы бесполезны, если их невозможно восстановить. Наш PDF fixer восстановит поврежденные PDF документы и сделает их снова полезными. Для того, чтобы использовать наше приложение все, что вам нужно, браузер. Нет необходимости устанавливать какое-либо программное обеспечение.
Шаг 1 Выберите поврежденный файл PDF.
Шаг 2 Настройки PDF.
iLovePDF: восстановить файл PDF
Вы можете получить другой формат файла при загрузке, если мы обнаружим этот формат в вашем файле.
Сейда: восстановить данные из поврежденного или поврежденного документа PDF
Файлы остаются приватными. Автоматически удаляется через 5 часов.
Бесплатный сервис для документов до страниц 200 или задач 50 Mb и 3 в час.
Шаг 1 Выберите ваши файлы и загрузить файлы PDF.
Нажмите на Загрузить PDF-файл файлы и выберите файлы с вашего локального компьютера. Папки также могут быть выбраны.
Шаг 2 Ремонт PDF
3. Как восстановить поврежденный PDF из Windows
Это самое простое решение. В этом решении вам понадобится профессиональное программное обеспечение для восстановления PDF.
FoneLab Data Retriever это мощный и технологически продвинутый инструмент восстановления PDF, который имеет возможность восстановить практически все потерянные файлы PDF путем глубокого сканирования дисков и корзины вашего компьютера.
FoneLab Data Retriever - восстанавливайте потерянные / удаленные данные с компьютера, жесткого диска, флэш-накопителя, карты памяти, цифровой камеры и многого другого.
- С легкостью восстанавливайте фотографии, видео, контакты, WhatsApp и другие данные.
- Предварительный просмотр данных перед восстановлением.
Шаг 1 Запустите это программное обеспечение.
Бесплатно скачайте и установите это программное обеспечение на свой компьютер. Тогда программное обеспечение будет запущено автоматически и немедленно.
Шаг 2 Выберите тип данных и диск.
В главном интерфейсе выберите Документ и место, где вы потеряли файл PDF.
Шаг 3 Сканирование данных.
Нажмите Scan кнопку, чтобы получить Быстрая проверка на выбранном жестком диске. Все файлы будут отображаться на левой боковой панели. Если быстрое сканирование не может принести желаемый результат, вы можете нажать Глубокий анализ повторить попытку.
Шаг 4 Выберите файл PDF
В результате сканирования вы можете нажать PDF, чтобы найти нужные элементы. Вам разрешено просматривать соответствующую информацию каждого файла, включая имя файла, размер, дату создания и изменения. Кроме того, вы можете использовать функцию фильтра, чтобы быстро найти файлы, которые вы хотите восстановить.
Шаг 5 Восстановить PDF файл
Нажмите на предметы и нажмите Recover Кнопка, чтобы восстановить выбранные файлы на ваш компьютер.
Заключение
FoneLab Data Retriever является надежным, который предназначен для восстановления почти всех потерянных файлов PDF путем глубокого сканирования жестких дисков. И это также может помочь вам восстановить файл PDF с жесткого диска.
В дополнение к файлам PDF, он может восстановить документы Word, Файлы Excel, изображения, электронные письма и другие данные.
Это также может помочь вам восстановить PDF файлы в Windows, флешка, карта памяти, съемный диск и т. д. и восстановление фотографий с цифровой камеры.
FoneLab Data Retriever - восстанавливайте потерянные / удаленные данные с компьютера, жесткого диска, флэш-накопителя, карты памяти, цифровой камеры и многого другого.
Также можно проверить конечный файл PDF, с помощью программы Adobe Acrobat Professional версии 6.0 и выше. Вам необходимо скачать профили Preiflight с названиями list_ofset_Fobos.kfp; newspaper_Fobos.kfp.
1. Откройте Adobe Acrobat Professional
2. Пройдите в раздел «Просмотр» > «Инструменты» > «Допечатная подготовка» > «Предпечатная проверка».
3. Откроется окно Preflight.
4. Перейдите «Option» > «Import Preflight Profile», как показано на рисунке.

5. Откроется окно просмотра Windows, где необходимо выбрать необходимый профиль, который вы скачали ранее.
6. Нажать «Execute (Analiz)», произойдёт анализ документа.

7. Профиль покажет отчет


8. Если есть ошибки, то возвращайтесь в исходный файл и исправляйте ошибки, после чего снова проводится проверка. Если все хорошо, то файл можно отправлять в типографию.
Перевод типовых ошибок
| PDF version number > 1.4 | Документ в формате PDF не соответствует версии |
| Resolution of color and gray scale images is lower than 250 pixels per inch (ppi) | Разрешение цветных и полутоновых растровых изображений меньше 250 ppi |
| Resolution of color and gray scale images ishigher than 450 pixels per inch (ppi) | Разрешение цветных и полутоновых растровых изображений больше 450 ppi |
| Resolution of bitmap images is lower than 550 pixels per inch (ppi) | Разрешение однобитных растровых изображений меньше 550 ppi |
| Resolution of bitmap images is higher than 3600 pixels per inch (ppi) | Разрешение однобитных растровых изображений больше 2400 ppi |
| Objects on the page use RGB | Объект RGB |
| Objects on the page use Device independent color | Объект содержит аппаратно зависимый цвет (встроен ICC профиль) |
| Font is not embedded | Не внедрен шрифт |
| Line thickness is less than 0.14 points | Линии тоньше 0,1 pt |
| Objects on the page use spot colors whose name | Объект окрашен в spot цвет |
| «White» object is not set to knock out | Под белым объектом нет выворотки (назначен оверпринт белому цвету) |
| «White» object is not set to knock out (stroked) | Под белой обводкой объекта отсутствует выворотка (назначен оверпринт белому цвету) |
| Ink coverage above ХХХ%_ (fill) | Превышен суммарный лимит краски (заливки) |
| Ink coverage above ХХХ%_ (stroke) | Превышен суммарный лимит краски (обводка) |
Preflight хоть и отлавливает часть ошибок, но не всегда дает полную информацию. Далее
рекомендуется провести визуальный контроль. Для проверки зон с превышением по краске (TIL)
вам понадобится Adobe Acrobat Professional версии 6 или выше.
1. «Редактирование» > «Установки» > «Основные» > «Диспетчер цветов».

2. В пункте «CMYK» укажите профиль типа печати: ч/б газетный, цветной газетный, листовой офсетный. Нажмите «ОК».
3. Пройдите по пути: «Просмотр» > «Инструменты» > «Допечатная подготовка» > «Просмотр цветоделения».
4. В появившемся окне «Просмотр цветоделения» (Output Preview) внизу строка «Суммарное покрытие» (Total Area Coverage) где необходимо поставить галочку и выставить процент, необходимый для вашего издания (зелёным цветом обозначены места, где суммарное количество красок превышено).


5. Также с помощью окна «Просмотр цветоделения» можно обнаружить обьекты RGB или «Плашечный цвет» (Spot Color) объекты. Для этого необходимо последовательно выбрать в меню «Показать» модель цвета RGB и плашечный цвет (Spot Color). Те объекты, что остались видимыми, и есть цвета RGB или плашечные (Spot Color).

Несколько месяцев назад я столкнулся с интересной задачей по анализу подозрительного pdf файла. К слову сказать, обычно я занимаюсь анализом защищенности веб приложений и не только веб, и не являюсь большим экспертом в направлении malware analysis, но случай представился довольно любопытный.
Практически все инструменты представленные в данной статье содержаться в дистрибутиве Remnux, созданном специально в целях reverse engineering malware. Вы можете сами загрузить себе образ виртуальной машины для VirtualBox или Vmware.
Первым делом я проанализировал полученный экземпляр с помощью скрипта pdfid:

Декодировал javascript код с помощью все того же pdf-parser:

Привел к удобному виду, для этого можно воспользоваться js-beautify:

Неплохо. Также проанализировал файл с помощью отличной утилиты jsunpack:

На первый взгляд им была обнаружена уязвимость CVE-2009-1492, связанная с выполнением произвольного кода или отказа в обслуживании через Adobe Reader и Adobe Acrobat версий 9.1, 8.1.4, 7.1.1 и ранних версий, с помощью pdf файла, содержащего annotaion и использующего метод getAnnots. Но если проверить мои результаты, полученные выше, с соответствующим exploit-ом, то обнаруживается, что эта уязвимость не имеет отношения к текущему случаю. В нашем варианте annotaion используется для хранения большой части скрипта в том числе в целях обфускации.
Данные из annotaion вызываются методом getAnnots и находятся в объекте 9 нашего файла(как показал pdfparser). Сохраним полученный javascript код, добавив к нему поток из объекта 9. Обычно, первым шагом для безопасного выполнения кода является замена функции eval безобидным alert или console.log и открытии файла с помощью браузера. Также в этих целях можно использовать Spidermonkey. Основные необходимые нам функции и переменные уже определены в файле pre.js, который вы также можете обнаружить в дистрибутиве Remnux.

Неплохо. После запуска Spidermonkey мы получили новый скрипт, который использует функции eval и поток данных из объекта 7:

Нет необходимости декодировать весь код, достаточно выполнить полученный скрипт с данными с помощью все того же spidermonkey или воспользоваться jsunpack.

Финальный скрипт выглядел так:

После рефакторинга получил:

Как видно во втором случае используются наши unescape("%u0c0c%u0c0c") и this.collabStore = Collab.collectEmailInfo(>);
В переменных v3, v4 просматривается shellcode из-за наличия серии NOP инструкций в начале значений переменных.
Чтобы подтвердить мои предположения я использовал эмулятор libemu из бесплатного продукта PDFStreamDumper со значением, взятым из переменной v4. Также libemu вы можете найти и в Remnux:

Бинго. Обнаружился url xxxxxx.info/cgi-bin/io/n002101801r0019Rf54cb7b8Xc0b46fb2Y8b008c85Z02f01010 который и использовался для загрузки с последующем исполнением нашего вредоноса:

3. Также параметры сравнения, обнаруженные в скрипте:

выглядят также как описано в CVE-2009-2990: Ошибка индекса в массиве Adobe Reader и Acrobat 9.x до версии 9.2, 8.x и 8.1.7, а также с версии 7.x до 7.1.4 позволяет выполнить произвольный код.
В кодируемом FlateDecode потоке объекта 11 мы также обнаруживаем код в U3D:

Теперь мы имеем URL, Shellcode, несколько CVE и этого вполне достаточно для данной статьи.
Автор статьи: Андрей Ефимюк, эксперт в области ИБ, OSCP, eCPPT, хороший друг PentestIT.
Оригинал статьи
Читайте также: