
Sas retain как получить предыдущую текстовую строку
Обновлено: 03.07.2024
Что такое промежуточный итог SQL?
| Дата продажи | Количество проданных продуктов | Накопительный итог |
| 2021-04-10 | 10 | 10 |
| 2021-04-11 | 15 | 25 |
| 2021-04-12 | 5 | 30 |
В первом столбце отображается дата. Во втором столбце показано количество проданных продуктов в этот день. В третьем столбце [Накопительный итог] суммируется общее количество проданных продуктов в этот день.
Далее мы поговорим о SQL-запросе, который позволяет получить такой итог, и узнаем больше об оконных функциях.
Как вычислить совокупный итог в MSSQL
Если вы хотите вычислить промежуточный итог в MSSQL, вам необходимо знать оконные функции, предоставляемые вашей базой данных. Оконные функции работают с набором строк и возвращают агрегированное значение для каждой строки в наборе результатов.
Синтаксис оконной функции SQL, вычисляющей совокупный итог по строкам, следующий:
| window_function ( column ) OVER ( [ PARTITION BY partition_list ] [ ORDER BY order_list] ) |
Предложение OVER обязательно использовать в оконной функции, но аргументы в этом предложении необязательны.
Пример
В этом примере мы будем вычислять общую текущую сумму проданных продуктов каждый день.
| Дата продажи | Количество проданных продуктов |
| 2021-04-10 | 10 |
| 2021-04-11 | 15 |
| 2021-04-12 | 5 |
Данный запрос выбирает дату продажи для всех пользователей. Нам также нужна сумма всех продуктов за каждый день, начиная с первого заданного дня (2021-04-10):
| Дата продажи | Количество проданных продуктов | Накопительный итог |
| 2021-04-10 | 10 | 10 |
| 2021-04-11 | 15 | 25 |
| 2021-04-12 | 5 | 30 |
Чтобы вычислить промежуточный итог, мы используем SUM()агрегатную функцию и указываем столбец kolvo_product в качестве аргумента; мы хотим получить совокупную сумму проданных продуктов из этого столбца.
Следующим шагом будет использование предложения OVER. В нашем примере это условие имеет один аргумент: ORDER BY c_date. Строки результирующего набора сортируются в соответствии с этим столбцом ( c_date).
Для каждого значения в столбце c_date вычисляется общая сумма значений предыдущего столбца (т. е. сумма проданных продуктов до даты в текущей строке) и к ней добавляется текущее значение (т. е. продукты, проданные в день текущей строки). Общая сумма отображается в новом столбце, который мы назвали total_product.
Благодаря оконным функциям SQL легко найти кумулятивное общее количество проданных продуктов за заданный период времени. Например, в период с 10 апреля по 12 апреля 2021 года общее количество проданных продуктов равно 30.
Рассмотрим несложное, но очень важное понятие сортировки датасетов. Перед вами датасет Demo. Обратите внимание на столбец Subject Identifier for the Study (переменная SUBJID).
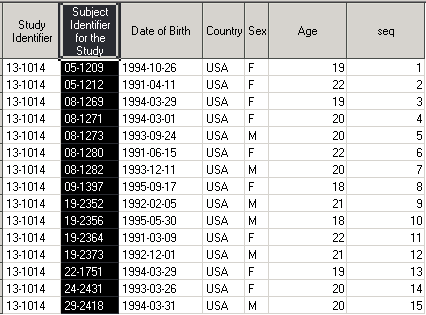
Наблюдения в датасете располагаются в порядке возрастания значений переменной SUBJID. Мы говорим, датасет Demo отсортирован по переменной SUBJID.
Отсортируем датасет по переменной AGE:
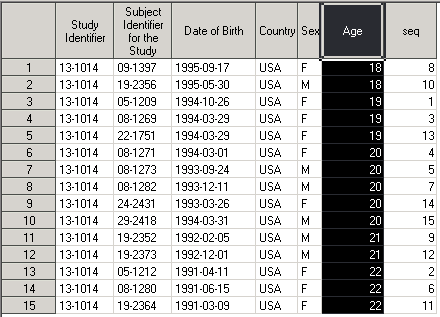
Обратите внимание на результат работы этой процедуры: создался новый датасет dm_by_AGE, который отсортирован по переменной AGE. Переменная seq показывает, как изменился порядок строк в датасете dm_by_AGE по сравнению с Demo.
Датасеты можно сортировать, как по числовым, так и по строковым переменным. Если это числовая переменная – соблюдается порядок возрастания/убывания, если это строковая переменная – соблюдается алфавитный порядок/обратный алфавитный порядок.
Чтобы отсортировать датасет в обратном порядке, нужно использовать опцию descending.
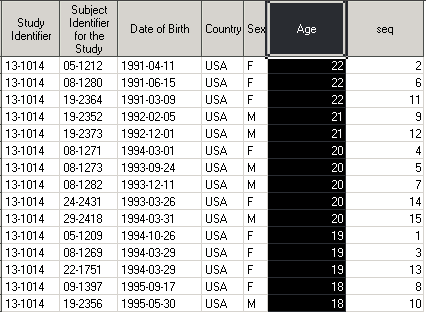
Как видите, можно не указывать опцию out, датасет dm_by_AGE теперь отсортирован по убыванию переменной AGE.
Обратите внимание, что некоторые значения переменной AGE повторяются в нескольких наблюдениях подряд. Каждая группа наблюдений с одним и тем же значением by-переменной называется by-группой. Одно значение переменной AGE – одна by-группа
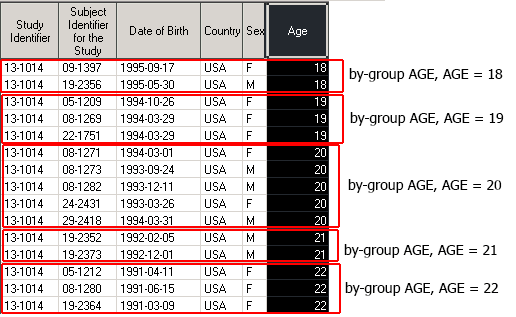
На практике нам зачастую необходимо контролировать порядок наблюдений внутри каждой by-группы. Это можно сделать, задав дополнительную by-переменную.
Пусть мы хотим, чтоб каждая by-группа AGE была отсортирована по дате рождения (BRTHDTC).
- 1 st by-group: AGE = 18, BRTHDTC = 1995-05-30
- 2 nd by-group: AGE = 18, BRTHDTC = 1995-09-17
- 3 rd by-group: AGE = 19, BRTHDTC = 1994-03-29
- 4 th by-group: AGE = 19, BRTHDTC = 1994-10-26
- etc…
Важно понимать, когда мы используем не одну by-переменную, а несколько, то by-группа – это комбинация значений всех by-переменных.
Одна уникальная комбинация – одна by-группа.
Количество by-переменных может быть более чем две, это число ограничено только количеством переменных в вашем датасете.
Также важным понятием является ключ датасета. Ключ – это такой набор by-переменных, любая by-группа которого представляет одну уникальную строку в датасете. В датасете demo ключом являться переменная SUBJID, поскольку любая by-группа SUBJID, а значит одно уникальное значение SUBJID – это одна уникальная строка в датасете. Мы говорим, в датасете demo одна строка на пациента.
Итак, сортировка датасета, by-переменные, by-группы, ключ – это понятия, с которыми мы неразлучны. Когда мы создаём стандартный датасет – он обязательно будет отсортирован в определенном порядке. Когда мы создаем таблицы и листинги – данные будут представлены в удобном порядке для просмотра (чаще всего хронологический или алфавитный, в зависимости от данных). Когда мы проводим какой-либо анализ – нам всегда может потребоваться провести его по подгруппам. Почти все наиболее часто используемые нами процедуры имеют оператор by, значит, все такие процедуры могут быть рассмотрены в контексте by-групп, и, перед использованием такой процедуры, ваш датасет должен быть предварительно отсортирован соответствующим образом.
Поверьте, многое в вашей работе будет зависеть от того, насколько правильно вы отсортируете ваш датасет.
На SAS support есть раздел «BY-Group Processing in the DATA Step», ознакомиться можно по ссылке:
Наиболее подробный синтаксис процедуры SORT смотрите по ссылке
Работа с by-группами на этапе дата степа
Итак, мы изучили понятие by-групп. Рассмотрим некоторые полезные операторы, связанные с обработкой by-групп.
Переменные FIRST. и LAST.
Имеется датасет Demo, отсортированный по переменной AGE и BRTHDTC:

Постановка задачи: в каждой возрастной подгруппе определить самого молодого пациента. Для этого создать переменную, которая бы принимала значение ‘истина’, если пациент имеет самую позднюю дату рождения среди пациентов того же возраста, и ‘ложь’ – в противном случае. Например, в by-группе AGE = 18, таким пациентом будет 09-1397 с датой рождения 1995-09-17.
Решение: Сортировка по переменной AGE и BRTHDTC располагает строки в датасете так, что пациент с самой поздней датой рождения (т.е. самый молодой пациент) будет последним в данной возрастной подгруппе. Последнюю строку в by-группе мы всегда можем определить с помощью переменной last.<by-переменная>.
В результате получим датасет Demo1 c переменной youngest, которая равна 1 на последней строке в каждой by-группе AGE.

Аналогично можно определить самых старших пациентов в каждой возрастной подгруппе, воспользовавшись переменной first.<by-переменная>. На этот раз не будем создавать новую переменную, а просто выведем всех старших пациентов в датасет Demo_old, а всех младших – в датасет Demo_young.
Таким образом, мы научились определять первую и последнюю строку в by-группе.
датасет должен быть отсортирован по переменным, указанным в by-операторе дата степа.
использование first.<by-переменная> и last.<by-переменная> не возможно без оператора by: на месте by-переменной могут стоять только переменные, указанные в by-операторе дата степа.
помним, что by-группы могут формировать несколько by-переменных. Поэтому, например, если бы мы хотели определить первую строку в каждой by-группе AGE, BRTHDTC, то дата степ выглядел бы следующим образом:
Как мы знаем, дата степ выполняется пошагово. За один шаг итерации обрабатывается только одна строка датасета, поэтому, в общем-то, у нас нет прямого доступа к предыдущим или последующим наблюдениям в дата степе. Тем не менее, существуют определенные инструменты, позволяющие «запоминать» значения переменных из предыдущих наблюдений. Среди таких инструментов вам уже должны быть знакомы функции lag и diff (Lesson 2.3). Здесь же мы рассмотрим оператор retain, который дает более широкие возможности.
Постановка задачи: В датасете LB хранятся результаты лабораторных тестов пациента, например это может быть анализ крови на содержание кровяных телец, уровень гемоглобина и т.д. Образцы крови для анализа берутся во время посещений (визитов) места, в котором проводят данное исследование (например, исследования могут проводиться на базе больниц). Такие визиты могут происходить несколько раз за исследование.
Рассмотрим пример датасета LB.
-
SUBJID – номер пациента;
- LBTESTCD – кодовое название теста;
- LBTEST – полное название теста с единицами измерения;
- VISIT – название визита;
- LBSTRESN – результат теста.
В данном исследовании мы имеем один визит до приема исследуемого лекарства (VISIT=”SCREENING”) и несколько после. Вы можете заметить, что не у всех пациентов набор визитов после SCREENING одинаков. Это естественно, ведь не все пациенты проходят до конца исследования, некоторые заканчивают свое участие раньше или просто пропускают какие-то визиты в середине исследования. Итак, в датасете LB содержится одна запись на каждую уникальную комбинацию значений пациент/тест/визит. Нашей задачей будет создать переменную BASE, которая ‘запомнит’ результаты теста пациента с первого визита для всех последующих. Вот таким образом будет выглядеть итоговый датасет:
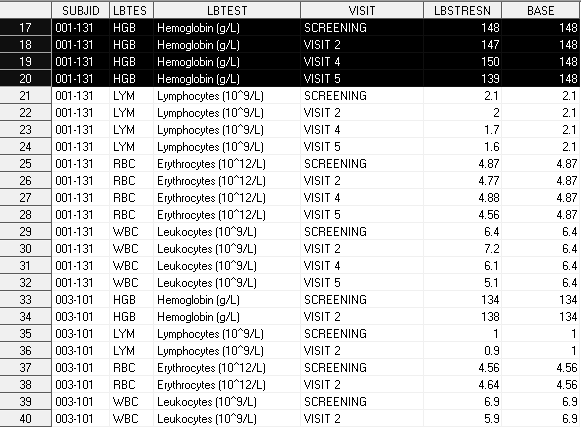
Возьмите любую by-группу пациент/тест, и вы увидите, что переменная BASE на всех визитах равна LBSTRESN с визита SCREENING. Например, уровень гемоглобина у пациента 001-131 на визите SCREENING (т.е. до приема лекарства) был 148 г/л, это значение сохранено на каждом последующем визите для того, чтобы иметь возможность сравнивать результаты до и после приема лекарства.
Решение: для решения данной задачи воспользуемся оператором retain.
Рассмотрим код пошагово.
I. Мы отсортировали датасет, зная ключ – пациент/тест/визит. Это очень важный шаг. Здесь мы располагаем строки датасета таким образом, чтобы
- подряд шли все возможные визиты для одного теста
- визиты в пределах одного теста располагались так, чтобы SCREENING всегда был первым в списке. Тут обратите особое внимание на то, что это расположение обуславливается только тем, что сортировка идет в алфавитном порядке, и для переменной VISIT имеются только значения SCREENING и VISIT X (где X = 2, 3, 4). В реальной жизни визиты могут называться по-другому, когда визит до приема лекарства по алфавиту будет стоять позже других визитов. Тогда, чтобы добиться правильной сортировки, приходится проделывать дополнительный шаг. Эту задачу мы рассмотрим на практическом занятии.
II. С помощью оператора retain мы создали переменную BASE, которая на каждой итерации дата степа будет повторять свое значение с предыдущего шага, если не задано иное. В данном случае у нас это ‘иное’ задано дважды:
В предыдущей статье мы познакомились с интерфейсом SAS UE, терминологией SAS Base, типами данных, основными требованиях к синтаксису SAS Base, а также рассмотрели распространенные синтаксические ошибки.
Сегодня я расскажу, как можно получить доступ к данным различных форматов. Обратите внимание, что в данной статье имеются ссылки на документацию, которая поможет вам подробнее ознакомиться с рассматриваемыми примерами.

Что такое библиотеки SAS?
Библиотека в SAS – это метод централизованного хранения и прозрачного использования данных в программах SAS. Библиотека может быть папкой или каталогом на вашем компьютере или располагаться на внешнем жестком диске, FLASH-накопителе или компакт-диске и так далее.
Существует два типа библиотек: постоянные и временные. Постоянные библиотеки SAS сохраняются до тех пор, пока вы их не удалите. Постоянная библиотека доступна для обработки в последующих сеансах SAS. Временная библиотека SAS существует только для текущего сеанса SAS.
Файлы SAS, созданные во время сеанса, хранятся в специальном рабочем пространстве, которое может быть или не быть внешним носителем. Это рабочее пространство обычно назначается по умолчанию с именем Work. Файлы во временной рабочей библиотеке могут использоваться на любом шаге в программе SAS, но они не доступны для последующих сессий SAS. Файлы, хранящиеся в рабочей библиотеке, удаляются в конце сеанса SAS.
Назначаем пользовательскую библиотеку.
Рассмотрим простой случай назначения библиотеки: наборы данных SAS находятся в одной директории c:\habrahabr. Есть два способа решения этой задачи.
1 способ:
Настроить библиотеку без программного кода. Во вкладке «Библиотеки» в SAS UE выбрать «Новая библиотека»:

Далее появится окно для настройки пользовательской библиотеки:

Имя библиотеки – library reference (или libref). Libref – это «псевдоним» (ссылка) для «хранилища», в котором находятся файлы. Название библиотеке задается в соответствии с правилами именования переменных в SAS (см. Урок 1), но на него выделяется не более 8 символов.
Правила именования библиотек, переменных, наборов данных и пр. в SAS можно изучить в справочнике SAS 9.4 and SAS Viya 3.3 Programming Documentation SAS Language Reference: Concepts в разделе Names in the SAS Language.
Обратите внимание, что библиотека назначена на все время сеанса SAS, но переопределять ее параметры можно.
Далее задаем путь к наборам данных SAS.

После назначения библиотеки она появляется в левой панели SAS UE.

2 способ:
Назначить библиотеку программным путем. Назначение библиотеки SAS реализуется с помощью глобального оператора LIBNAME. Информацию по указанному оператору можно изучить в справочнике SAS 9.4 and SAS Viya 3.3 Programming Documentation / Global Statements.
Рассмотрим общий синтаксис глобального оператора LIBNAME.
libref – имя библиотеки.
engine — имя «движка», например, для наборов данных SAS – это BASE (но его можно не указывать, он задан по умолчанию). Если вы хотите создать новую библиотеку с другим «движком», отличным от механизма по умолчанию, вы можете отменить автоматический выбор.
Справочники, которые могут вам пригодиться при изучении механизмов подключения: SAS/ACCESS for Relational Databases и SAS Engines.
«Движки» SAS/ACCESS являются механизмами оператора LIBNAME, которые обеспечивают доступ к чтению, записи и обновлению более чем 60 реляционных и нереляционных баз данных, файлов ПК, устройств хранения данных и распределенных файловых систем.
'SAS-library' – путь к библиотеке, если путь задается с помощью макропеременной (будет рассматриваться в данном цикле статей), используются парные двойные кавычки. Во всех остальных случаях можно использовать парные одинарные кавычки.
options — допустимые опции. Простейшим примером является опция ACCSESS=READONLY, которая назначает атрибут «только для чтения» для всей библиотеки SAS. Со всем перечнем допустимых опций можно ознакомиться в справочнике SAS 9.4 and SAS Viya 3.3 Programming Documentation /Global Statements.
engine/host-options — являются одним или несколькими параметрами, которые перечислены в общей форме keyword = value.
Рассмотрим синтаксис оператора LIBNAME на практике. Назначим библиотеку Habr только для чтения:
Запустим код и проверим Log:

Просматриваем содержимое библиотеки SAS.
Один из вариантов просмотра содержимого библиотеки – использование процедуры PROC CONTENTS. Ознакомиться с процедурами, используемыми в SAS, можно в справочнике SAS 9.4 Procedures by Name and Product.
Процедура PROC CONTENTS позволяет создавать вывод, который описывает либо содержимое библиотеки SAS, либо информацию дескриптора для отдельного набора данных SAS. Чтобы просмотреть содержимое библиотеки SAS, мы можем использовать следующую общую форму процедуры:
Параметр NODS (который означает «no details») подавляет печать подробной информации о каждом файле при указании опции _ALL_.
Для конкретной библиотеки код будет выглядеть следующим образом:
Фрагмент вывода процедуры:

Обратите внимание, что в библиотеке также хранятся другие типы файлов, например catalog, index. О них можно прочитать в справочнике SAS 9.4 Companion for Windows, Fifth Edition.
Файлы с member type DATA являются стандартными наборами данных SAS. Второй вариант просмотра содержимого библиотеки – использовать процедуру PROC DATASETS:
Просмотр информации о конкретном наборе данных SAS реализуется следующим образом:
Обратите внимание на обращение к таблице в пользовательской библиотеке. Имя после data= двухуровневое: имя_библиотеки.имя_таблицы. В случае набора данных, хранящемся во временной библиотеке WORK, в обращении после data= можно использовать одноуровневое имя.
Например, в случае кода:
выведется информация о наборе данных charities, находящемся во временной библиотеке WORK.
Рассмотрим вывод процедуры для набора данных charities в пользовательской библиотеке HABR:

Служебная информация о таблице, получаемая в результате вывода, называется дескриптором.
Дескриптор содежит общую информацию о наборе данных: его название и имя библиотеки, типе, «движке», дате и времени создания и последнего изменения, количестве наблюдений и переменных, общей длине наблюдений, индексах, сортировке, сжатии, размере страницы и их количестве, информацию об атрибутах переменных.
Читаем электронные таблицы.
Чтение файла EXCEL можно реализовать несколькими способами. В этой статье мы рассмотрим назначение библиотеки для файла excel.
Для назначения библиотеки SAS будем использовать электронную таблицу products.xlsx, хранящуюся в директории c:\workshop\habrahabr\products.xlsx. Данный документ выглядит следующим образом: он содержит 4 листа, каждый из которых станет отдельным набором данных SAS. Фрагмент данного документа представлен ниже:

Общий синтаксис назначения библиотеки такой же, как и в случае наборов данных SAS, меняется только механизм подключения:
Существует несколько механизмов для обработки файла excel, у всех свои особенности и настройки, с которыми можно ознакомиться в документации.
Результат выполнения оператора libname представлены ниже. Фрагмент Log:

Информацию о библиотеке посмотрим через процедуру PROC CONTENTS:
В зависимости от механизма дескриптор заполняется по-разному:

Результат выполнения оператора LIBNAME представлены ниже. Фрагмент Log:

Информацию о библиотеке посмотрим через PROC CONTENTS:
В зависимости от механизма дескриптор заполняется по-разному:

Результат выполнения оператора libname представлены ниже.

Информацию о библиотеке посмотрим через PROC CONTENTS:
В зависимости от механизма дескриптор заполняется по-разному:

Создаем детализированные отчеты.
После получения доступа к требуемым данным рассмотрим процедуру для создания отчетов PROC PRINT. Подробную информацию о ней можно получить в справочнике SAS 9.4 Procedures by Name and Product. Распечатаем детализированный отчет, используя таблицу German из системной библиотеки sasuser.
Для начала изучим дескриптор указанной таблицы, нас интересуют атрибуты столбцов:
Фрагмент вывода процедуры:

Создадим детализированный отчет, удовлетворяющий представленным ниже требованиям:
-
Не включайте переменные Change и Retain в отчет:
Оператор VAR определяет переменные для печати. Оператор выводит их в том порядке, в котором вы их перечислили.

В данном условии нам необходимо использовать фильтр в операторе WHERE.
Обратите внимание, что при работе с текстовыми переменными важен регистр, а также вы обязательно заключаете требуемое значение в парные кавычки (двойные или одинарные).
Вывод данной программы SAS:

По умолчанию процедура PROC PRINT выводит номера строк, для того, чтобы убрать данный столбец, можно использовать опцию NOOBS (‘no observation’). В этом случае программный код выглядит следующим образом:
Операторы сравнения вы можете записывать привычными символами, а можете использовать мнемоники, как представлено в примере. Вывод данной программы представлен ниже:

Идентификатором наблюдения можно определить любую переменную. Когда вы указываете одну или несколько переменных в операторе ID, он использует форматированные значения этих переменных для идентификации строк. Обратите внимание, что если одновременно переменная указана в операторе VAR и в операторе ID, то она выведется два раза. Также при использовании оператора ID нет необходимости в опции NOOBS.
В нашем случае программа SAS будет иметь следующий вид:
Результаты выполнения кода представлены ниже:

Стоит отметить, что при задании атрибутов таких как ярлык и формат, они будут использованы только на определенном шаге PROC для создания требуемого отчета.
Для задания ярлыка используется оператор LABEL.
Общий синтаксис оператора LABEL выглядит следующим образом:
В ярлыке вы можете использовать любые символы, в том числе и пробелы, количество символов не должно превышать 256. Ярлыки переменных будут использованы для создания отчетов.
Не все процедуры «видят» ярлыки. Для того, чтобы процедура PROC PRINT выводила в отчет ярлыки, а не имена переменных, в опциях необходимо указать label (или split=). Опция SPLIT указывает разделитель, который контролирует разрывы в заголовках столбцов. Используем оператор LABEL в нашем программном коде:
1 вариант

2 вариант
(с использованием опции split=)
В опции split= указывается разделитель (обязательно в кавычках). Код в данном случае выглядит следующим образом (обратите внимание на использование разделителей в операторе Label):

Оператор TITLE задает заголовок в отчете, оператор FOOTNOTE задает нижний колонтитул.
Как и в случае оператора LIBNAME, данные операторы являются глобальными и действуют во время всего сеанса SAS до тех пор, пока вы не переопределите их значения. Вы можете использовать TITLE и FOOTNOTE как вне шагов PROC, так и непосредственно в них.
Общий синтаксис операторов:
Text-string – данный аргумент является строкой, которая может содержать до 512 символов. Вам необходимо заключать такие строки в одиночные или двойные кавычки. Текст отображается точно так же, как вы вводите его в операторе, включая прописные, строчные буквы и пробелы.
Также для настройки заголовков и нижних колонтитулов можно использовать стили:

Итак, возвращаясь к разрабатываемому отчету:
Результат выполнения программы:

Формат – это правило вывода значений переменных в отчет. Необходимо понимать, что формат не меняет значения в наборе данных SAS. Типы форматов соответствуют типу данных, но разбиты на категории: числовые, символьные, даты, время, дата-время.
Всю информацию о форматах можно найти в справочнике SAS 9.4 Formats and Informats: Reference. Также поддерживается возможность создания пользовательских форматов, об этом мы поговорим в следующих статьях.
Общий синтаксис оператора FORMAT.
variable – одна или несколько переменных, к которым небходимо применить формат.
DEFAULT=default-format – определяет временный формат по умолчанию для отображения значений переменных, которые не указаны в операторе FORMAT, используется в шаге DATA.
format – определяет формат, который используется для отображения переменных.
Общий синтаксис использованиея формата в операторе FORMAT следующий:
$ — признак текстового формата
Format – название формата
w — ширина формата, количество всех выводимых символов в значении
d — количество десятичных знаков
Формат всегда оканчивается на точку или на количество десятичных знаков. Стоит отметить, что при неверном выборе ширины формата значения в выводе могут «обрезаться». Давайте рассмотрим пример:
| Значение переменной | Формат | Результат |
|---|---|---|
| 34566.78 | DOLLAR10.2 | $34,566.78 |
| 34566.78 | DOLLAR9.2 | $34566.78 |
| 34566.78 | DOLLAR8.2 | 34566.78 |
| 34566.78 | DOLLAR7.2 | 34566.8 |
| 34566.78 | DOLLAR6.2 | 34567 |
| 34566.78 | DOLLAR4.2 | 35E3 |
При этом значение в наборе данных SAS остается неизменным:
Результат выполнения шага:

Отчет выглядит следующим образом:

Для группировки переменных используется оператор BY. Группировка переменных по определенным значениям подразумевает сортировку таблицы. Это связано с обработкой данных SAS Base.
Отсортировать набор данных можно с помощью процедуры PROC SORT.
При сортировке набора данных вам необходимо указать источник (исходный набор данных), группирующую переменную или переменные, а также при необходимости выходной (промежуточный) набор данных.
Давайте проверим вышеизложенное. Если посмотреть на отчет, выводимый в п.7 данной статьи, столбец Gender отсортирован по полу по убыванию. Так ли это?
Результат выполнения процедуры представлен ниже:

Таким образом, мы получили требуемый детализированный отчет на основании набора German в библиотеке Sasuser.
SAS: как отключить «всегда создавать резервную копию» при экспорте в xlsx
When I output a dataset to excel (using either the libname method or the proc export) and create an Excel 2007 file, the 'always create backup' option is automaticaly checked. .
спросил 9 лет, 9 месяцев
Борьба с PROC REPORT и итоговыми строками
I am having trouble getting proc report to do quite what I want. .
спросил 9 лет, 9 месяцев
Есть ли способ остановить SAS при первом предупреждении или ошибке?
спросил 9 лет, 9 месяцев
Путем групповой обработки в SAS
У меня очень большая таблица с индексированным полем даты и времени. Я хочу выполнять групповую обработку набора данных по месяцам и выводить только последнее наблюдение за каждый месяц. .
спросил 9 лет, 9 месяцев
Как создавать красивые таблицы, используя PROC REPORT и ODS RTF output
Я хочу создать «красивую таблицу», используя вывод SAS ODS RTF и процедуру PROC REPORT. Проведя целый день в Google, мне удалось получить следующее: .
спросил 9 лет, 9 месяцев
Как я могу использовать Proc SQL, чтобы найти все записи, которые существуют только в одной таблице, но не существуют в другой?
Я пытаюсь сделать это в Enterprise Guide с задачей, иначе я бы просто использовал шаг данных. .
спросил 9 лет, 10 месяцев
Автоматически запланированные запросы SAS
Я выполняю несколько запросов SAS ежемесячно, и все они выполняются довольно долго. Мне было интересно, есть ли способ запланировать их запуск на определенную дату каждый месяц в определенном порядке? .
спросил 9 лет, 10 месяцев
SAS и операции с датой
Я пробовал поискать в Google, и мне не повезло с моей текущей проблемой. Может кому поможет? .
спросил 9 лет, 10 месяцев
Найдите максимальный выход за период переменной длины
У меня есть гипотетический набор данных с 3 столбцами, в котором есть данные о ежемесячной прибыли для набора машин с виджетами. Я пытаюсь рассчитать период максимальной прибыли за 2 года. .
спросил 9 лет, 10 месяцев
преобразование символа в число (SAS)
Я пытаюсь преобразовать символьный столбец в числовой, и я попытался использовать: .
спросил 9 лет, 10 месяцев
sas sql переход к макропеременной как символ
Как читать макропеременную как символ в сквозной передаче SAS SQL .
спросил 9 лет, 10 месяцев
создание временной таблицы в базе данных с использованием значений в наборе данных sas
может ли кто-нибудь помочь мне с синтаксисом создания временной таблицы в базе данных со значениями из набора данных SAS? Я хочу использовать эту временную таблицу рядом с другими таблицами в базе данных. .
спросил 9 лет, 10 месяцев
Вывести значение переменной в каждом наблюдении в макропеременную
У меня есть таблица с именем term_table, содержащая следующие столбцы .
спросил 9 лет, 10 месяцев
Я хотел бы объединить два файла в bash, используя общий столбец. Я хочу сохранить как все сопоставляемые, так и нежелательные строки из обоих файлов. К сожалению, используя соединение, я мог сохранить нежелательные поля только из одного файла, например. присоединиться -1 1 -2 2 -a1 -t "". .
спросил 9 лет, 10 месяцев
Экспорт набора данных SAS в Access с форматированными значениями
Я создаю таблицу в SAS и экспортирую ее в базу данных Microsoft Access (mdb). Прямо сейчас я делаю это, подключаясь к базе данных как к библиотеке: .
спросил 9 лет, 10 месяцев

сортировать и выводить записи с помощью SAS и R
У меня есть следующий набор данных .
спросил 9 лет, 10 месяцев
SAS - набор данных с меткой не открывается при одновременном импорте нескольких наборов
У меня проблемы с объединением двух наборов данных. Я использую SAS 9.2, и при импорте нескольких наборов данных они повреждаются, и я могу открыть только последний импортированный набор. .
спросил 9 лет, 10 месяцев
SAS ODBC с таблицей в локальной библиотеке
Что, если я запустил создание таблицы с использованием ODBC в SAS. Эта таблица теперь сохранена в моей постоянной библиотеке в SAS. Теперь я хочу взять эту таблицу, потому что она просматривала миллионы строк данных, и после того, как я закончил, я отфильтровал элементы, и эта таблица имеет 664 отдельных строки sys_id. .
спросил 9 лет, 10 месяцев
Как выполнить импорт из неочищенного файла CSV / различных входных переменных формата и заголовка в файле?
Мой входной файл находится в формате "CSV", но у меня здесь 2 проблемы .
спросил 9 лет, 10 месяцев
выходное наблюдение, если соответствует критериям
Вот мой набор данных: .
спросил 9 лет, 10 месяцев
SAS экспортирует значения 0 как период в Excel
У меня серьезная проблема. Я запускаю отчет в SAS, который сохраняет результаты в формате Excel. Проблема в том, что всякий раз, когда значение равно 0, sas заполняет столбец точкой (.) .
спросил 9 лет, 10 месяцев
Как получить формат даты sas "ГГГГММ"
Как получить формат даты sas "ГГГГММ" в SAS? .
спросил 9 лет, 10 месяцев
SASweave и сервер SAS? [закрыто]
спросил 9 лет, 10 месяцев
переупорядочивание столбца в sas
У меня следующая проблема: .
спросил 9 лет, 10 месяцев
Proc IML с sas
У меня есть следующая таблица: .
спросил 9 лет, 10 месяцев
Усечение символов при импорте с помощью SAS
У меня есть таблица Excel с данными и описаниями компании. Некоторые из ячеек в основном содержат мини-эссе, страницы и страницы прямого текста, содержащиеся в одной ячейке. SAS вызывает у меня проблемы, когда я импортирую файл, потому что он усекает некоторые из более длинных ячеек и .
спросил 9 лет, 11 месяцев
Реализация сортировки Radix для наборов данных в SAS
В своей повседневной работе я часто работаю с наборами данных, которые содержат миллионы строк, иногда сотни миллионов, а иногда более миллиарда. Эти наборы данных часто необходимо отсортировать. Ключи почти всегда представляют собой большие целые числа (обычно 100 цифр). Иногда наборы данных содержат составные ключи .
спросил 9 лет, 11 месяцев
Автоматическое использование заглавных букв в редакторе SAS и в Toad, SQLyog или HeidiSQL
Кто-нибудь знает, как разрешить редактору SAS автоматически ограничивать все ключевые слова / функции в этих редакторах: .
Читайте также: