
Сопоставление типов данных oracle с postgresql
Обновлено: 05.07.2024
В то время как в государственном секторе повсеместно и в обязательном порядке происходит переход на свободное программное обеспечение, все больше коммерческих компаний задумываются о добровольной миграции с Oracle на свободную систему управления базами данных PostgreSQL.
Что приобретают и теряют компании при таком переходе? Ответ на этот вопрос искали участники конференции PgConf, которая прошла в начале февраля в Москве.
Хорошо, давайте сравним. И начнем с основного, на наш взгляд, критерия.
Совокупная стоимость владения (Total Cost of Ownership или TCO).
Как известно, основными составляющими ТСО в мире софта являются цена приобретения и стоимость поддержки продукта. Определенное значение имеют и затраты на администраторов баз данных (DBA), но, согласно результатам исследований HeadHunter, эти расходы различаются в пределах 10%.
Стоит признать: цена приобретения Oracle высока, так же как и стоимость поддержки. Кроме того, каждую дополнительную функцию приходится приобретать отдельно, причем за немалые деньги. Об этом верно сказал Илья Космодемьянский: «Лицензии придумывают неглупые люди: Express и Standard-one выпущены для того, чтобы вы купили Enterprise и RAC».
Стоимость для ваших решений можно прикинуть в различных калькуляторах:
Как вы уже догадываетесь, именно TCO является ударным аргументом в пользу PostgreSQL, поскольку в случае выбора open-source СУБД цена приобретения является нулевой, аналогичная ситуация и со стоимостью сопровождения. Впрочем, об этом критерии стоит поговорить отдельно.
Сопровождение
Если вы думаете, что «бесплатно» – это синоним слова «плохо», то глубоко заблуждаетесь. Да, в случае с PostgreSQL возникшие проблемы будет решать «комьюнити», а не высокооплачиваемая (вами!) группа профессионалов. И потому вполне вероятно, что это будет сделано с некоторой задержкой, но она, как правило, не слишком критична, а значит, не приведет к серьезным последствиям. Для тех же компаний, кого такой подход не устраивает, есть выход: организации, которые занимаются профессиональной поддержкой PostgreSQL на высоком уровне. Их услуги, конечно, не бесплатны, но стоимость и условия более чем демократичны: нет годовых лицензий, штрафов за пропуск оплат и прочих «приятных» сюрпризов, которыми славится поддержка Oracle.
Кстати, а вы в курсе, что стоимость сопровождения Oracle в год составляет почти четверть стоимости лицензии? Причем эта сумма ежегодно возрастает на 3%-5%. В долларах, конечно. С более подробной информацией можно ознакомиться вот здесь:
Производительность
Илья Космодемьянский признает, что оспаривать техническое первенство Oracle глупо. В общем случае эта СУБД обеспечивает больше транзакций в секунду (TPS), чем PostgreSQL. Во сколько раз? А вот на этот вопрос точно ответить пока никто не смог. Для того чтобы сравнить производительность Oracle и PostgreSQL, необходимо провести их тестирование в идентичных условиях: на одинаковом «железе» с равной нагрузкой, используя оптимальные операционные и файловые системы, а также осуществив сопоставимый по уровню «тюнинг» СУБД.
Сложность соблюдений этих условий, их высокая трудоемкость, отсутствие квалифицированных DBA ограничивают подобные исследования.
Тем не менее, на сайте pgconf представлены некоторые цифры по производительности PostgreSQL, правда, без указания ссылок на источники:
Безопасность
О какой безопасности упоминал Марк Ривкин? Наверное, об опциях типа Oracle advanced security или Label security, которые входят только в самый дорогой пакет Enterprise edition. Это действительно «крутые «фичи», но они не столь актуальны в условиях ожидания новых санкций, которые могут привести к полному отказу в технической поддержке продукта или, что еще более катастрофично, к отключению наших облачных БД.
Масштабируемость
Теперь давайте посмотрим, как обстоят дела с масштабируемостью в Oracle. Начиная с версии Standard edition, предоставляется всем известный RAC (четыре сокета). Однако при работе с highload-проектами, вам, скорее всего, придется купить Enterprise edition, что влетит в копеечку.
В то же время сообщество PostgreSQL бесплатно предоставляет и расширения наподобие PL/Proxy от компании Skype, которое позволяет шардировать информацию по кластеру БД, и отдельные кластерные решения, базирующиеся на PostgreSQL – Postgres-XC и Postgres-XL.
Обновляемость
Oracle не гонится за частотой релизов. Как правило, новый релиз выходит раз в два-три года и отражает качественные изменения в соответствии с потребностями рынка. Проследим хронологию:
1998 год – выпущена версия 8i Release 1 (8.1.5), «i» в названии обозначает «internet», символизируя поддержку интернета.
2001 год – выпущена версия 9i Release 1 (9.0.1), поддержка XML, появление RAC.
2004 год – выпущена версия 10g Release 1 (10.1.0), «g» в названии обозначает «grid» («сеть»), символизируя поддержку грид-вычислений.
2007 год – выпущена версия 11g Release 1 (11.1.0.6).
2013 год – выпущена версия 12c (12.1.0.1), «с» в названии обозначает «cloud» («облако»). Основное новшество релиза – поддержка подключаемых баз данных, которая обеспечивает свойства мультиарендности и живой миграции БД.
Кроме того, ежеквартально выпускаются критические патчи.
Еще более нетороплив при смене номера версии PostgreSQL: релиз выходит примерно раз в пять лет. Но, в отличие от Oracle, добавление новых функций и обновление существующих происходит, по сути, постоянно. Так что, если вы готовы рискнуть стабильностью ради функциональности, обновлять СУБД можно хоть каждый день.
Объем изменений в межрелизных обновлениях можно косвенно оценить из того факта, что их краткое описание занимает несколько экранных страниц.
Ведущий разработчик PostgreSQL Олег Бартунов считает, что спектр возможностей этой СУБД расширяется намного быстрее, чем у Oracle. Поэтому вполне возможно, что в самое ближайшее время PostgreSQL займет лидирующие позиции в данном направлении.
Работа с очень большими данными
Так же как и в случае с производительностью, сравнивать СУБД по этому критерию достаточно сложно. С одной стороны, Enterprise версия Oracle при прочих равных условиях должна быть производительнее PostgreSQL по крайней мере за счет in-memory технологии, но для получения конкретных цифр необходимо сравнивать результаты на рабочих запросах. С другой – PostgreSQL не стоит на месте: в версии 9.4 появились huge pages, что дает прирост производительности от 10% до 30% на машинах с большим объемом памяти.
Для тех, кто хочет иметь некоторые опорные цифры, мы собрали статистику:
Итак, какой же совет мы можем дать тем, кто стоит перед выбором СУБД? PostgreSQL представляется достаточно зрелой системой, способной обеспечить потребности средних, а иногда и крупных корпораций (за примерами далеко ходить не надо – «Яндекс», «Авито», Skype). Поэтому, если ваш проект еще не выведен в «продуктив» или существует безболезненный вариант попробовать различные СУБД, то это стоит сделать. Как в таком случае минимизировать риски? На этот вопрос существует только один ответ: необходимо рассчитать, затем эмулировать боевую нагрузку и, в конце концов, оценить результат. Кстати, «Перфоманс Лаб» это умеет.
Если же перед вами стоит острая проблема «импортозамещения» уже работающей системы, то не стоит рисковать и, помолясь индийскому богу Ганеше, запускать скрипт миграции из Oracle в PostgreSQL (а такой скрипт есть). Как советует технический директор 404 Group Роман Друзягин, сначала нужно протестировать систему, зафиксировать все проблемы, найти пути их решения, провести несколько тестовых миграций и только затем, хорошенько выспавшись, устраивать час «Ч».
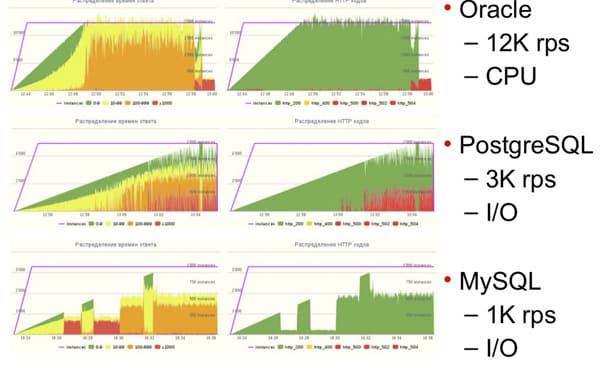
Сравнение PostgreSQL, Oracle и MySQL на боевой нагрузке
Если вы хотите подробнее ознакомиться с возможностями обеих СУБД, мы подобрали для вас ссылки:
В этом разделе рассматриваются различия между языками PostgreSQL PL/pgSQL и Oracle PL/SQL , чтобы помочь разработчикам, переносящим приложения из Oracle ® в PostgreSQL .
PL/pgSQL во многих аспектах похож на PL/SQL . Это блочно-структурированный, императивный язык, в котором все переменные должны объявляться. Присвоения, циклы и условные операторы в обоих языках похожи. Основные отличия, которые необходимо иметь в виду при портировании с PL/SQL в PL/pgSQL , следующие:
Если имя, используемое в SQL-команде, может быть как именем столбца таблицы, так и ссылкой на переменную функции, то PL/SQL считает, что это имя столбца таблицы. Это соответствует поведению PL/pgSQL при plpgsql.variable_conflict = use_column , что не является значением по умолчанию, как описано в Подразделе 41.10.1. В первую очередь, было бы правильно избегать таких двусмысленностей, но если требуется портировать большое количество кода, зависящее от данного поведения, то установка переменной variable_conflict может быть лучшим решением.
В PostgreSQL тело функции должно быть записано в виде строки. Поэтому нужно использовать знак доллара в качестве кавычек или экранировать одиночные кавычки в теле функции. (См. Подраздел 41.11.1.)
Имена типов данных часто требуют корректировки. Например, в Oracle строковые значения часто объявляются с типом varchar2 , не являющимся стандартным типом SQL. В PostgreSQL вместо него нужно использовать varchar или text . Подобным образом, тип number нужно заменять на numeric или другой числовой тип, если найдётся более подходящий.
Для группировки функций вместо пакетов используются схемы.
Так как пакетов нет, нет и пакетных переменных. Это несколько раздражает. Вместо этого можно хранить состояние каждого сеанса во временных таблицах.
Целочисленные циклы FOR с указанием REVERSE работают по-разному. В PL/SQL значение счётчика уменьшается от второго числа к первому, в то время как в PL/pgSQL счётчик уменьшается от первого ко второму. Поэтому при портировании нужно менять местами границы цикла. Это печально, но вряд ли будет изменено. (См. Подраздел 41.6.3.5.)
Циклы FOR по запросам (не курсорам) также работают по-разному. Переменная цикла должна быть объявлена, в то время как в PL/SQL она объявляется неявно. Преимущество в том, что значения переменных доступны и после выхода из цикла.
41.12.1. Примеры портирования
Пример 41.8 показывает, как портировать простую функцию из PL/SQL в PL/pgSQL .
Пример 41.8. Портирование простой функции из PL/SQL в PL/pgSQL
Функция Oracle PL/SQL :
Пройдемся по этой функции и посмотрим различия по сравнению с PL/pgSQL :
Имя типа varchar2 нужно сменить на varchar или text . В примерах данного раздела мы будем использовать varchar , но обычно лучше выбрать text , если не требуется ограничивать длину строк.
Ключевое слово RETURN в прототипе функции (не в теле функции) заменяется на RETURNS в PostgreSQL . Кроме того, IS становится AS , и нужно добавить предложение LANGUAGE , потому что PL/pgSQL — не единственный возможный язык.
В PostgreSQL тело функции является строкой, поэтому нужно использовать кавычки или знаки доллара. Это заменяет завершающий / в подходе Oracle.
Вот как эта функция будет выглядеть после портирования в PostgreSQL :
Пример 41.9 показывает, как портировать функцию, которая создаёт другую функцию, и как обрабатывать проблемы с кавычками.
Пример 41.9. Портирование функции, создающей другую функцию, из PL/SQL в PL/pgSQL
Следующая процедура получает строки из SELECT и строит большую функцию, в целях эффективности возвращающую результат в операторах IF .
В конечном итоге в PostgreSQL эта функция может выглядеть так:
Обратите внимание, что тело функции строится отдельно, с использованием quote_literal для дублирования кавычек. Эта техника необходима, потому что мы не можем безопасно использовать знаки доллара при определении новой функции: мы не знаем наверняка, какие строки будут вставлены из referrer_key.key_string . (Мы предполагаем, что referrer_key.kind всегда имеет значение из списка: host , domain или url , но referrer_key.key_string может быть чем угодно, в частности, может содержать знаки доллара.) На самом деле, в этой функций есть улучшение по сравнению с оригиналом Oracle, потому что не будет генерироваться неправильный код, когда referrer_key.key_string или referrer_key.referrer_type содержат кавычки.
Пример 41.10 показывает, как портировать функцию с выходными параметрами ( OUT ) и манипулирующую строками. В PostgreSQL нет встроенной функции instr , но её можно создать, используя комбинацию других функций. В Подраздел 41.12.3 приведена реализации instr на PL/pgSQL , которая может быть полезна вам при портировании ваших функций.
Пример 41.10. Портирование из PL/SQL в PL/pgSQL процедуры, которая манипулирует строками и содержит OUT параметры
Следующая процедура на языке Oracle PL/SQL разбирает URL и возвращает составляющие его элементы (сервер, путь и запрос).
Вот возможная трансляция в PL/pgSQL :
Эту функцию можно использовать так:
Пример 41.11 показывает, как портировать процедуру, использующую большое количество специфических для Oracle возможностей.
Пример 41.11. Портирование процедуры из PL/SQL в PL/pgSQL
Подобные процедуры легко преобразуются в функции PostgreSQL , возвращающие void . На примере этой процедуры можно научиться следующему:
В PL/pgSQL эту процедуру можно портировать так:
Основное функциональное отличие между этой процедурой и Oracle эквивалента в том, что монопольная блокировка таблицы cs_jobs будет продолжаться до окончания вызывающей транзакции. Кроме того, если впоследствии работа вызывающей программы прервётся (например из-за ошибки), произойдёт откат всех действий, выполненных в этой процедуре.
41.12.2. На что ещё обратить внимание
В этом разделе рассматриваются ещё несколько вещей, на которые нужно обращать внимание при портировании функций из Oracle PL/SQL в PostgreSQL .
41.12.2.1. Неявный откат изменений после возникновения исключения
В PL/pgSQL при перехвате исключения в секции EXCEPTION все изменения в базе данных с начала блока автоматически откатываются. В Oracle это эквивалентно следующему:
При портировании процедуры Oracle, которая использует SAVEPOINT и ROLLBACK TO в таком же стиле, задача простая: достаточно убрать операторы SAVEPOINT и ROLLBACK TO . Если же SAVEPOINT и ROLLBACK TO используются по-другому, то придётся подумать.
41.12.2.2. EXECUTE
PL/pgSQL версия EXECUTE работает аналогично версии в PL/SQL , но нужно помнить об использовании quote_literal и quote_ident , как описано в Подразделе 41.5.4. Без использования этих функций конструкции типа EXECUTE 'SELECT * FROM $1'; будут работать ненадёжно.
41.12.2.3. Оптимизация функций на PL/pgSQL
Для оптимизации исполнения PostgreSQL предоставляет два модификатора при создании функции: « изменчивость » (будет ли функция всегда возвращать тот же результат при тех же аргументах) и « строгость » (возвращает ли функция NULL, если хотя бы один из аргументов NULL). Для получения подробной информации обратитесь к справочной странице CREATE FUNCTION .
При использовании этих атрибутов оптимизации оператор CREATE FUNCTION может выглядеть примерно так:
41.12.3. Приложение
Этот раздел содержит код для совместимых с Oracle функций instr , которые можно использовать для упрощения портирования.
Типы данных Oracle и типы данных Microsoft SQL Server не всегда полностью совпадают. Там, где это возможно, выбор подходящего типа данных при публикации таблицы Oracle осуществляется автоматически. В случаях, когда выбор однозначного соответствия типов данных не очевиден, предлагаются альтернативные сопоставления типов данных. Сведения о выборе альтернативных соответствий типов данных см. ниже в разделе «Указание альтернативных сопоставлений типов данных».
Следующая таблица показывает, как по умолчанию осуществляется преобразование типов данных между Oracle и SQL Server , когда данные передаются издателем Oracle распространителю SQL Server . В столбце «Альтернатива» показано, допустимы ли альтернативные соответствия.
Вопросы сопоставления типов данных
При репликации данных из базы данных Oracle нужно помнить о следующих особенностях типов данных.
Неподдерживаемые типы данных
Следующие типы данных не поддерживаются; столбцы, имеющие эти типы, невозможно реплицировать.
Столбцы, использующие REF
Тип данных DATE
Даты в диапазоне SQL Server от 1753 нашей эры. до 9999 г. нашей эры, тогда как даты в Oracle распределяются в диапазоне от 4712 г. до нашей эры до 4712 г. нашей эры. Если столбец, имеющий тип DATE, содержит значения, выходящие за диапазон SQL Server, выберите для столбца альтернативный тип данных, которым является VARCHAR(19).
Типы FLOAT и NUMBER
Масштаб и точность, задаваемые при сопоставлении типов данных FLOAT и NUMBER, зависят от масштаба и точности, указанных для столбца, использующего этот тип данных в базе данных Oracle. Точность представляет собой количество цифр в числе. Масштаб представляет собой количество цифр справа от десятичной запятой в числе. Например, у числа 123,45 точность равна 5, а масштаб равен 2.
Oracle позволяет определять числа, имеющие масштаб больший, чем точность, например NUMBER(4,5), в то время как SQL Server требует, чтобы точность была не меньше масштаба. Чтобы исключить усечение данных, когда в данных издателя Oracle масштаб больше, чем точность, при преобразовании данных точность приравнивается к масштабу: тип данных NUMBER(4,5) преобразуется в NUMERIC(5,5).
Если для типа NUMBER не указать масштаб и точность, SQL Server будет использовать по умолчанию максимальные масштаб (8) и точность (38). Для оптимизации хранения данных и производительности при репликации данных рекомендуется установить специальные значения масштаба и точности в Oracle.
Типы больших объектов
Oracle поддерживает до 4 гигабайт (ГБ), в то время как SQL Server поддерживает до 2 ГБ. Реплицируемые данные свыше 2 ГБ усекаются.
Если таблица Oracle включает столбец типа BFILE, данные для этого столбца хранятся в файловой системе. Административной учетной записи репликации должно быть предоставлено право доступа в каталог, в котором хранятся данные. С этой целью должно использоваться следующее синтаксическое выражение:
GRANT READ ON DIRECTORY <directory_name> TO <replication_administrative_user_schema>
Дополнительные сведения о типах больших объектов см. в разделе с рекомендациями по большим объектам статьи Рекомендации по структуре и ограничения для издателей Oracle.
Указание альтернативных сопоставлений типов данных
Обычно целесообразно использовать сопоставление типов данных по умолчанию, но для многих типов данных Oracle вместо сопоставления по умолчанию можно выбрать тип данных из набора альтернативных вариантов. Существует два способа указания альтернативных сопоставлений:
Переопределяйте значения по умолчанию для каждой статьи отдельно, используя хранимые процедуры или мастер создания публикаций.
Глобальная замена значений по умолчанию для всех последующих статей с помощью хранимых процедур (значения по умолчанию для существующих статей не изменяются).
Чтобы указать альтернативные сопоставления типов данных, см. раздел Указание сопоставления типов данных для издателя Oracle.
Типы данных MySQL
Типы данных MySQL разделяются на следующие типы:
Типы данных Oracle
Типы данных Oracle разделяются на следующие группы:
ANSI SQL стандарт распознает только текст и число, в то время как большинство коммерческих программ используют другие специальные типы, такие как DATЕ и TIME — фактически почти стандартные типы. Некоторые пакеты также поддерживают такие типы, как, например, MONEY и BINARY. Типы данных, распознаваемые с помощью ANSI, состоят из строк символов и различных типов чисел, которые могут классифицироваться как точные числа и приблизительные числа.
CHARACTER(length) определяет спецификацию строк символов, где length задает длину строк заданного типа. Значения этого типа должны быть заключены в одиночные кавычки. Большинство реализаций поддерживают строки переменной длины для типов данных VARCHAR и LONG VARCHAR (или просто LONG).
В то время, как поле типа CHAR всегда может распределить память для максимального числа символов, которое может сохраняться в поле, поле VARCHAR при любом количестве символов может распределить только определенное количество памяти, чтобы сохранить фактическое содержание поля, хотя SQL может установить некоторое дополнительное пространство памяти, чтобы следить за текущей длиной поля. Поле VARCHAR может быть любой длины, включая реализационно-определяемый максимум. Этот максимум может меняться от 254 до 2048 символов для VARCHAR и до 16000 символов для LONG. LONG обычно используется для текста пояснительного характера или для данных, которые не могут легко сжиматься в простые значения полей; VARCHAR может использоваться для любой текстовой строки, чья длина может меняться.
Извлечение и модифицирование полей VARCHAR — более сложный, и, следовательно, более медленный процесс, чем извлечение и модифицирование полей CHAR. Кроме того, некоторое количество памяти VARCHAR, остается всегда неиспользованной для гарантии вмещения всей длины строки. При использовании таких типов следует предусматривать возможность полей к объединению с другими полями.
Точные числовые типы — это числа, с десятичной точкой или без десятичной точки, которые могут представляться в виде [+|-]<целое без знака>[.<целое без знака>] и специфицироваться как:
DECIMAL(precision [, scale]) — аргумент размера имеет две части: точность и масштаб. Масштаб не может превышать точность. Точность указывает сколько значащих цифр имеет число. Масштаб указывает максимальное число цифр справа от десятичной точки. Масштаб = нулю делает поле эквивалентом целого числа.
NUMERIC(precision [, scale]) — такое же как DECIMAL за исключением того, что максимальное десятичное не может превышать аргумента точности
INTEGER — число без десятичной точки. Эквивалентно DECIMAL, но без цифр справа от десятичной точки, т.е. с масштабом равным 0. Аргумент размера не используется (он автоматически устанавливается в реализационно-зависимое значение).
SMALLINT — такое же как INTEGER, за исключением того, что, в зависимости от реализации, размер по умолчанию может ( или не может ) быть меньше чем INTEGER.
Приблизительные числовые типы — это числа в показательной (экспоненциальной по основанию 10) записи, представляемые как <литеральное значение точного числа>Е<целое со знаком> и специфицирущиеся следующим образом:
FLOAT[(precision)] — число с плавающей запятой. Аргумент размера состоит из одного числа, определяющего минимальную точность.
REAL — такое же как FLOAT, за исключением того, что никакого аргумента размера не используется. Точность устанавливается реализационно-зависимой по умолчанию.
DOUBLE PRECISION — такое же как REAL, за исключением того, что реализационно-определяемая точность для DOUBLE PRECISION должна превышать реализационно-определяемую точность REAL.
Типы данных Access
Типы данных Access разделяются на следующие группы:
Типы данных SQL Server
Microsoft SQL Server поддерживает большинство типов данных SQL 2003. Также SQL Server поддерживает дополнительные типы данных, используемые для однозначной идентификации строк данных в таблице и на многих серверах, например UNIQUEIDENTIFIER , что соответствует аппаратной философии «роста в ширину», исповедуемой Microsoft (т. е. внедрение базы на множестве серверов на платформах Intel), вместо «роста в высоту» (т. е. внедрение на одном огромном мощном UNIX-сервере или Windows Data Center Server).
Типы данных, используемые в SQL Server:
Типы данных PostgreSQL
База данных PostgreSQL поддерживает большинство типов данных SQL2003 плюс огромный набор типов для хранения пространственных и геометрических данных. PostgreSQL может похвастаться богатым набором операторов и функций, специально предназначенных для геометрических типов данных. Сюда входят такие средства, как поворот, поиск пересечений и масштабирование. В PostgreSQL также есть поддержка дополнительных версий существующих типов данных, которые характерны тем, что занимают меньше места на диске, чем соответствующие исходные версии. Например, в PostgreSQL предлагается несколько вариантов типа INTEGER для хранения больших и небольших чисел, соответственно занимающих больше или меньше места.
Читайте также: