
Способы организации файловых операций
Обновлено: 06.07.2024
Файловая система ОС должна предоставлять пользователю набор операций для работы с файлами, оформленные в виде системных вызовов. Набор состоит из: создание файла, чтение из файла и т. д.
Какие бы операции не выполнялись над файлом ОС необходимо выполнить ряд универсальных для всех операций действий:
1. по символьному имени файла найти характеристики, которые хранятся в физической системе на диске;
2. скопировать характеристики файла в оперативную память, чтобы программный код мог их использовать;
3. на основании характеристик файла проверить права пользователя на выполнение запрошенной информации;
4. очистить область памяти, отведенную на временное хранение характеристик файлов.
Кроме того, каждая операция включает ряд уникальных действий:
а) чтение определенного набора кластеров диска;
б) удаление файлов и т.д.
ОС может выполнять последовательность действий над файлами двумя способами:
1. для каждой операции выполняется как универсальные, так и уникальные действия, такая схема называется схема без запоминания состояния операции.. он более устойчив к сбоям в работе системы, так как каждая операция является самодостаточной и не зависит от операции предыдущей. Применяется в распределенных сетевых файловых системах.
2. все универсальные действия выполняются в начале и конце последовательности операций, а для промежуточной операции выполняются только уникальные действия, подавляющее большинство файловых систем поддерживает этот метод как более экономный и быстрый.
Стандартные файлы ввода и вывода, перенаправление вывода
Ввод/вывод в операционных системах может быть организован двумя принципиально разными способами. Первый способ- это прямое программирование устройств ввода/вывода (дисковода, экрана, модема, клавиатуры). Он может быть организован на различных уровнях (непосредственное программирование устройств, использование сервисных средств операционной системы, смешанный подход и т.д.), но суть его при этом не меняется. Каждая программа, написанная с использованием этого способа, может работать только с этим устройством и ни с каким другим. В настоящее время используется именно этот способ. Именно с помощью этого подхода (точнее, путем "косвенного" программирования периферийных устройств через драйверы этих устройств) и реализован классический WIMP - интерфейс. Он позволяет создавать красивые и довольно содержательные средства общения с пользователем (меню, окна и тому подобное), а современные технологии позволяют программе при установке автоматически настраиваться на установленное на компьютере оборудование. Но у этих систем есть недостаток: они не могут принять данные с устройств и передать данные устройствам, для работы с которыми они не созданы. Например, нельзя данные вводить с модема, если программа работает только с клавиатурой. Чтобы осуществить это, используют другой способ: ввод/вывод с использованием потоков. В этом случае каждое устройство рассматривается операционной системой как файл, куда можно поместить и откуда можно взять информацию. Так же, как информация, записанная в файл, рассматривается операционной системой как единое целое, не зависимо от способа записи его на диске, так и физическая реализация процесса ввода/вывода информации устройством никак не отражается на работе пользователя.
Как правило, эффект, достигаемый прямым программированием устройств, невозможно реализовать на уровне потоков (нельзя даже поменять цвет символов, не говоря уж о применении графики!) Но выигрыш в унификации процессов иногда оказывается более существенным, например, при работе с текстовой информацией, при автоматическом проведении эксперимента и тому подобное.
Поток, представляет собой некоторый буфер в памяти, куда поступает или откуда выбирается информация. Существуют следующие стандартные потоки:
1. Стандартный поток ввода - это обычно клавиатура.
2. Стандартный поток вывода - это обычно монитор.
Символы переадресации очень удобны, но иногда бывает необходимо организовать последовательность программ, выполняющих обработку информации, причем результат предыдущей программы является исходным для следующей. При этом промежуточные данные желательно никуда не записывать. Чтобы организовать такую обработку, используют знак '|' конвейера. Команды - "цепочки" такой обработки данных просто записываются в одну строку в порядке их вызова для обработки данных, и отделяются одна от другой знаком конвейера '|'. Пример:
sort < mylist | more.
В этом примере данные из файла mylist сортируются программой sort и постранично выводятся на экран программой more.
В UNIX тоже возможна переадресация потока с одновременным выводом данных на экран, и даже переадресация на два разных устройства. Для переадресации стандартного вывода в файл с одновременной выдачей информации на экран используется команда tee. Например, команда cat в UNIX позволяет просматривать файл. Следующая конструкция:
cat first | tee second
копирует файл first в файл second, одновременно показывая его на экране.
Для вывода данных на принтер используются конструкции:
в DOS > prn в UNIX lpr
Еще один пример: команда
cat first | tee second | lpr
копирует файл first в файл second, одновременно распечатывая его на принтере.
Файловая система ОС должна предоставлять пользователям набор операций для работы с файлами, оформленный в виде системных вызовов. В различных ОС имеются различные наборы файловых операций. Наиболее часто встречающимися системными вызовами для работы с файлами являются [13, 17]:
- Create (создание). Файл создается без данных. Этот системный вызов объявляет о появлении нового файла и позволяет установить некоторые его атрибуты;
- Delete (удаление). Ненужный файл удаляется, чтобы освободить пространство на диске;
- Open (открытие). До использования файла его нужно открыть. Данный вызов позволяет прочитать атрибуты файла и список дисковых адресов для быстрого доступа к содержимому файла;
- Close (закрытие). После завершения операций с файлом его атрибуты и дисковые адреса не нужны. Файл следует закрыть, чтобы освободить пространство во внутренней таблице;
- Read (чтение). Файл читается с текущей позиции. Процесс, работающий с файлом, должен указать (открыть) буфер и количество читаемых данных;
- Write (запись). Данные записываются в файл в текущую позицию. Если она находится в конце файла, его размер автоматически увеличивается. В противном случае запись производится поверх существующих данных;
- Append (добавление). Это усеченная форма предыдущего вызова. Данные добавляются в конец файла;
- Seek (поиск). Данный системный вызов устанавливает файловый указатель в определенную позицию;
- Get attributes (получение атрибутов). Процессам для работы с файлами бывает необходимо получить их атрибуты;
- Set attributes (установка атрибутов). Этот вызов позволяет установить необходимые атрибуты файлу после его создания;
- Rename (переименование). Этот системный вызов позволяет изменить имя файла. Однако такое действие можно выполнить копированием файла. Поэтому данный системный вызов не является необходимым;
- Execute (выполнить). Используя этот системный вызов, файл можно запустить на выполнение.
Рассмотрим примеры файловых операций в ОС Windows 2000 и UNIX . Как и в других ОС, в Windows 2000 есть свой набор системных вызовов, которые она может выполнять. Однако корпорация Microsoft никогда не публиковала список системных вызовов Windows , кроме того, она постоянно меняет их от одного выпуска к другому [17]. Вместо этого Microsoft определила набор функциональных вызовов, называемый Win 32 API ( Win 32 Application Programming Interface ). Эти вызовы опубликованы и полностью документированы. Они представляют собой библиотечные процедуры, которые либо обращаются к системным вызовам, чтобы выполнить требуемую работу, либо выполняют ее прямо в пространстве пользователя.
Философия Win 32 API заключается в предоставлении всеобъемлющего интерфейса, с возможностью выполнить одно и то же требование несколькими (тремя-четырьмя) способами. В ОС UNIX все системные вызовы формируют минимальный интерфейс : удаление даже одного из них приведет к снижению функциональности ОС.
Многие вызовы API создают объекты ядра того или иного типа (файлы, процессы, потоки, каналы и т.д.). Каждый вызов, создающий объект , возвращает вызывающему процессу результат, называемый дескриптором (небольшое целое число ). Дескриптор используется впоследствии для выполнения операций с объектами. Он не может быть передан другому процессу и использован им. Однако при определенных обстоятельствах дескриптор может быть дублирован и передан другому процессу защищенным способом, что предоставляет второму процессу контролируемый доступ к объекту, принадлежащему первому процессу. С каждым объектом ассоциирован дескриптор безопасности, описывающий, кто и какие действия может, а какие не может выполнять с данным объектом.
Основные функции Win 32 API для файлового ввода-вывода и соответствующие системные вызовы ОС UNIX приведены ниже.
Аналогично файловым операциям обстоит дело с операциями управления каталогами. Основные функции Win 32 API и системные вызовы UNIX для управления каталогами приведены ниже.
Способы выполнения файловых операций
Чаще всего с одним и тем же файлом пользователь выполняет не одну, а последовательность операций. Независимо от набора этих операций операционной системе необходимо выполнить ряд постоянных (универсальных) для всех операций действий.
- По символьному имени файла найти его характеристики, которые хранятся в файловой системе на диске.
- Скопировать характеристики в оперативную память, поскольку только в этом случае программный код может их использовать.
- На основании характеристик файла проверить права пользователя на выполнение запрошенной операции.
- Очисть область памяти, отведенную под временное хранение характеристик файла.
Кроме того, каждая операция включает ряд уникальных для нее действий, например, чтение определенного набора кластеров диска, удаление файла , изменение его атрибутов и т.п.
ОС может выполнить последовательность действий над файлами двумя способами (см. рис. рис. 7.22).
- Для каждой операции выполняются как универсальные, так и уникальные действия. Такая схема иногда называется схемой без заполнения состояния операции ( stateless ).
- Все универсальные действия выполняются в начале и конце последовательности операций, а для каждой промежуточной операции выполняются только уникальные действия.
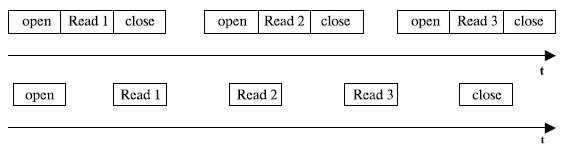
Рис. 7.22. Варианты выполнения последовательности действий над файлами
Подавляющее большинство файловых систем поддерживает второй способ, как более экономичный и быстрый. Однако первый способ более устойчив к сбоям в работе системы, так как каждая операция является самодостаточной и не зависит от результата предыдущей. Поэтому первый способ иногда применяется в распределенных сетевых файловых системах, когда сбои из-за потерь пакетов или отказов одного из сетевых узлов более вероятны, чем при локальном доступе к данным.
При втором способе в ФС вводится два специальных системных вызова: open и close. Первый выполняется перед началом любой последовательности операций с файлом, а второй – после окончания работы с файлом.
Основной задачей вызова open является преобразование символьного имени файла в его уникальное числовое имя, копирование характеристик файла из дисковой области в буфер оперативной памяти и проверка прав пользователя на выполнение запрошенной операции . Вызов close освобождает буфер с характеристиками файла и делает невозможным продолжение операций с файлами без его повторного открытия.
Приведем несколько примеров системных вызовов для работы с файлами. Системный вызов create в ОС UNIX работает с двумя аргументами: символьным именем открываемого файла и режимом защиты. Так команда
создает файл abc с режимом защиты, указанным в переменной mode . Биты mode определяют круг пользователей, которые могут получить доступ к файлам, и уровень предоставляемого им доступа. Системный вызов create не только создает новый файл , но также открывает его для записи. Чтобы последующие системные вызовы могли получить доступ к файлу, успешный системный вызов create возвращает небольшое неотрицательное целое число – дескриптор файла – fd . Если системный вызов выполняется с существующим файлом, длина этого файла уменьшается до 0, а все содержимое теряется.
Чтобы прочитать данные из существующего файла или записать в него данные, файл сначала нужно открыть с помощью системного вызова open с двумя аргументами: символьным именем файла и режимом открытия файла (для записи, чтения или того т другого), например
Для ввода-вывода данных с помощью стандартных потоков в библиотеке Си определены функции:
- getchar ( )/putchar ( ) – ввод-вывод отдельного символа;
- gets ( )/ puts ( ) – ввод-вывод строки;
- scanf ( )/ printf ( ) – ввод-вывод в режиме форматирования данных.
Процесс в любое время может организовать ввод данных из стандартного файла ввода, выполнить символьный вызов:
Аналогично организуется вывод в стандартный файл вывода
При работе в Windows 2000 с помощью функции CreateFile можно создать файл и получить дескриптор к нему. Эту же функцию следует применять и для открытия уже существующего файла, так как в Win 32 API нет специальной функции File Open . Параметры функций, как правило, многочисленны, например, функция CreateFile имеет семь параметров:
Небольшие каталоги (small indexes). Если количество файлов в каталоге невелико, то список файлов может быть резидентным в записи в MFT, являющейся каталогом. Для резидентного хранения списка используется единственный атрибут — Index Root. Список файлов содержит значения атрибутов файла. По умолчанию — это имя файла, а также номер записи MTF, содержащей начальную запись файла.
Большие каталоги (large indexes). По мере того как каталог растет, список файлов может потребовать нерезидентной формы хранения. Однако начальная часть списка всегда остается резидентной в корневой записи каталога в таблице MFT. Имена файлов резидентной части списка файлов являются узлами так называемого В-дерева (двоичного дерева). Остальные части списка файлов размещаются вне MFT. Для их поиска используется специальный атрибут Index Allocation, представляющий собой адреса отрезков, хранящих остальные части списка файлов каталога. Одни части списков являются листьями дерева, а другие являются промежуточными узлами, то есть содержат наряду с именами файлов атрибут Index Allocation, указывающий на списки файлов более низких уровней.
Поиск в каталоге уникального имени файла, которым в NTFS является номер основной записи о файле в MFT, по его символьному имени происходит следующим образом. Сначала искомое символьное имя сравнивается с именем первого узла в резидентной части индекса. Если искомое имя меньше, то это означает, что его нужно искать в первой нерезидентной группе, для чего из атрибута Index Allocation извлекается адрес отрезка (VCN,, LCNj, Kj), хранящего имена файлов первой группы. Среди имен этой группы поиск осуществляется прямым перебором имен и сравнением до полного совпадения всех символов искомого имени с хранящимся в каталоге именем. При совпадении из каталога извлекается номер основной записи о файле в MFT и остальные характеристики файла берутся уже оттуда.
Если же искомое имя больше имени первого узла резидентной части индекса, то его сравнивают с именем второго узла, и если искомое имя меньше, то описанная процедура применяется ко второй нерезидентной группе имен, и т. д.
В результате вместо перебора большого количества имен (в худшем случае — всех имен каталога) выполняется сравнение с гораздо меньшим количеством имен узлов и имен в одной из групп каталога.
Файловые операции. Два способа организации файловых операций
Чаще всего с одним и тем же файлом пользователь выполняет не одну операцию, а последовательность операций. Например, при работе текстового редактора с файлом, в котором содержится некоторый документ, пользователь обычно считывает несколько страниц текста, редактирует эти данные и записывает их на место считанных, а затем считывает страницы из другой области файла, и т. п. После большого количества операций чтения и записи пользователь завершает работу с данным файлом и переходит к другому.
Какие бы операции не выполнялись над файлом, ОС необходимо выполнить ряд универсальных для всех операций действий:
1)По символьному имени файла найти его характеристики, которые хранятся в файловой системе на диске.
2)Скопировать характеристики файла в оперативную память, так как только таким образом программный код может их использовать.
3)На основании характеристик файла проверить права пользователя на выполнение запрошенной операции (чтение, запись, удаление, просмотр атрибутов файла).
4)Очистить область памяти, отведенную под временное хранение характеристик файла.
Операционная система может выполнять последовательность действий над файлом двумя способами:
- Для каждой операции выполняются как универсальные, так и уникальные действия. Такая схема иногда называется схемой без запоминания состояния операций (stateless).
- Все универсальные действия выполняются в начале и конце последовательности операций, а для каждой промежуточной операции выполняются только уникальные действия.
Подавляющее большинство файловых систем поддерживает второй способ организации файловых операций как более экономичный и быстрый. Первый способ обладает одним преимуществом — он более устойчив к сбоям в работе системы, так как каждая операция является самодостаточной и не зависит от результата предыдущей. Поэтому первый способ иногда применяется в распределенных сетевых файловых системах (например, в Network File System, NFS компании Sun), когда сбои из-за потерь пакетов или отказов одного из сетевых узлов более вероятны, чем при локальном доступе к файлам.
При втором способе в файловой системе вводятся два специальных системных вызова: open — открытие файла, и close — закрытие файла.
Открытие файла
Системный вызов open в ОС UNIX работает с двумя аргументами: символьным именем открываемого файла и режимом открытия файла. Режим открытия говорит системе, какие операции будут выполняться над файлом в последовательности операций до закрытия файла по системному вызову close, например: только чтение, только запись или чтение и запись.
При открытии файла ОС сначала выполняет преобразование первого аргумента системного вызова, то есть символьного имени файла, в его уникальное числовое имя, которым в традиционных файловых системах UNIX является номер индексного дескриптора.
По номеру индексного дескриптора inode файловая система находит нужную запись на диске и копирует из нее характеристики файла в оперативную память.
Для хранения копии индексного дескриптора используются буферные области системного виртуального пространства. Характеристики индексного дескриптора, перенесенные в оперативную память, помещаются в структуру так называемого виртуального дескриптора vnode (virtual node). Структура vnode включает поля индексного дескриптора файла inode, а также несколько перечисленных ниже дополнительных полей, полезных при выполнении операций с файлом.
- Состояние индексного дескриптора в памяти, отражающее:
o заблокирован ли файл;
o ждет ли снятия блокировки с файла какой-либо процесс;
o отличается ли представление характеристик файла в памяти от своей дисковой копии в результате изменения содержимого индексного дескриптора;
o отличается ли представление файла в памяти от своей дисковой копии в результате изменения содержимого файла;
o является ли файл точкой монтирования.
- Логический номер устройства файловой системы, содержащей файл.
- Номер индексного дескриптора. В дисковом индексном дескрипторе это поле отсутствует, так как номер определяется положением дескриптора относительно начала области индексных дескрипторов.
- Счетчик ссылок на данную структуру vnode.
С одним и тем же файлом в какой-то период времени могут работать различные процессы, но операционная система не создает для каждого процесса отдельную копию структуры vnode, а для каждого файла, с которым в данный момент работает хотя бы один процесс, хранит ровно одну копию виртуального дескриптора. При очередном открытии файла ОС проверяет, имеется ли в системной памяти структура vnode открываемого файла (по номеру логического устройства и номеру индексного дескриптора, которые определяются при преобразовании символьного имени), и если имеется, то счетчик ссылок на нее увеличивается на единицу. При очередном закрытии этого файла счетчик ссылок уменьшается на единицу, и если он становится равным 0, то буфер, хранящий данный vnode, считается свободным.
При каждом открытии процессом файла ОС проверяет права пользовательского процесса на выполнение запрошенной операции с файлом и, если проверка прошла успешно, создает в системной области памяти новую структуру file, которая описывает как открытый файл, так и операции, которые процесс собирается производить с файлом (например, чтение).
Структура file содержит такие поля, как:
- признак режима открытия (только для чтения, для чтения и записи и т. п.);
- указатель на структуру vnode;
- текущее смещение в файле (переменная offset) при операциях чтения/записи;
- счетчик ссылок на данную структуру;
- указатель на структуру, содержащую права процесса, открывшего файл (эта структура находится в дескрипторе процесса);
- указатели на предыдущую и последующую структуры file, связывающие все такие структуры в двойной список.
Переменная offset, хранящаяся в структуре file, позволяет ОС запоминать текущее положение условного указателя в последовательности байт файла
Системный вызов open возвращает в пользовательский процесс дескриптор файла, который представляет собой номер записи в таблице открытых файлов процесса. Дескриптор файла имеет локальное значение только для того процесса, который открыл файл, для разных процессов одно и то же значение дескриптора указывает на разные операции, в общем случае над разными файлами.
После открытия файла его дескриптор используется во всех дальнейших операциях с файлом вплоть до явного закрытия файла. Таким образом, дескриптор файла является временным уникальным именем, но не файла, а определенной последовательности операций с этим файлом.
Для открытия файла /bin/prog 1.ехе в режиме «только для чтения» прикладной программист может использовать следующее выражение на языке С:
fd = open("/bin/progl exe". 0_RDONLY);
Здесь fd — это целочисленная переменная, сохраняющая значение дескриптора открытого файла. Ее значение должно использоваться в операциях обмена данными с файлом /bin/progI.exe. При неудачной попытке открытия файла (нет прав для выполнения затребованной операции, неверное имя файла) переменной fd присваивается значение -1, которое является индикатором ошибки для всех системных вызовов UNIX.
Обмен данными с файлом
Для обмена данными с предварительно открытым файлом в ОС UNIX существуют системные вызовы read и write. В том случае, когда необходимо явным образом указать, с какого байта файла необходимо читать или записывать данные, используется также системный вызов Т seek.
Системный вызов чтения данных из файла read имеет три аргумента:
read(fd buffer nbytes):
Первый аргумент fd является целочисленной переменной, имеющей значение дескриптора открытого файла. Второй аргумент buffer является указателем на область пользовательской памяти, в которую система должна поместить считанные данные.Количество байт этой области памяти задается третьим целочисленным аргументом nbytes. Функция read возвращает действительное количество считанных байт (оно может отличаться от заданного, если, например, была задана область чтения, выходящая за пределы файла) или же код ошибки -1. Начало дисковой области, которую нужно прочитать с помощью вызова read, явно в этом системном вызове не указывается. Чтение начинается с того байта, на который указывает смещение offset в структуре file. На это смещение указывает запись с номером fd в таблице открытых файлов процесса. После выполнения вызова read смещение offset наращивается на количество прочитанных байт. Вид системного вызова записи данных write аналогичен вызову read: wnte(fd buffer.nbytes).
Функция write записывает nbytes из буфера оперативной памяти buffer в файл, описываемый дескриптором fd. Функция write, так же как и read, возвращает вызвавшей ее программе значение реально переданных ею байт или код ошибки.
Рассмотрим пример, в котором прикладная программа работает с файлом, состоящем из записей фиксированной длины в 50 байт:
fd = open("/doc/qwery/base12. txt" 0_RDWR).
read(fd bufferl,50):
read(fd.buffer2, 2500):
Iseek(fd, 150, 0):
write (fd, output, 300):
В приведенном фрагменте программы после открытия файла /doc/query/base12.txt для чтения и записи выполняется чтение первой записи файла, а затем читается область файла, включающая еще 50 записей, начиная со 2 по 51. После обработки считанных записей (эти инструкции опущены) производятся перемещение указателя смещения в файле на начало четвертой записи и запись результатов в шесть последовательных записей, начиная с четвертой. Завершается фрагмент закрытием файла с помощью системного вызова close.
Все описанные системные вызовы являются синхронными, то есть пользовательский процесс переводится в состояние ожидания до тех пор, пока операция ввода-вывода не завершится.
Блокировки файлов
Блокировки файлов и отдельных записей в файлах являются средством синхронизации между работающими в кооперации процессами, пытающимися использовать один и тот же файл одновременно.
Процессы могут иметь соответствующие права доступа к файлу, но одновременное использование этих прав (в особенности права записи) может привести к некорректным результатам. Примером такой ситуации является одновременное редактирование одного и того же документа несколькими пользователями. Если доступ к файлу не управляется блокировками, то каждый пользователь, который имеет право записи в файл, работает со своей копией данных файла.
В обязательном режиме запрет на выполнение операции с заблокированным файлом поддерживает операционная система, поэтому процесс в любом случае не получит доступа к такому файлу. Однако при работе в этом режиме операционная система тратит много усилий и времени на его поддержание, поэтому обычно он не рекомендуется

Файловая система . На каждом носителе информации (гибком, жестком или лазерном диске) может храниться большое количество файлов. Порядок хранения файлов на диске определяется используемой файловой системой.
Каждый диск разбивается на две области: обла сть хранения файлов и каталог. Каталог содержит имя файла и указание на начало его размещения на диске. Если провести аналогию диска с книгой, то область хранения файлов соответствует ее содержанию, а каталог - оглавлению. Причем книга состоит из страниц, а диск - из секторов.
Для дисков с небольшим количеством файлов (до нескольких десятков) может использоваться одноуровневая файловая система , когда каталог (оглавление диска) представляет собой линейную последовательность имен файлов (табл. 1.2). Такой каталог можно сравнить с оглавлением детской книжки, которое содержит только названия отдельных рассказов.
Если на диске хранятся сотни и тысячи файлов, то для удобства поиска используется многоуровневая иерархическая файловая система , которая имеет древовидную структуру. Такую иерархическую систему можно сравнить, например, с оглавлением данного учебника, которое представляет собой иерархическую систему разделов, глав, параграфов и пунктов.
Начальный, корневой каталог содержит вложенные каталоги 1-го уровня, в свою очередь, каждый из последних может содержать вложенные каталоги 2-го уровня и так далее. Необходимо отметить, что в каталогах всех уровней могут храниться и файлы.
Например, в корневом каталоге могут находиться два вложенных каталога 1-го уровня (Каталог_1, Каталог_2) и один файл (Файл_1). В свою очередь, в каталоге 1-го уровня (Каталог_1) находятся два вложенных каталога второго уровня (Каталог_1.1 и Каталог_1.2) и один файл (Файл_1.1) - рис. 1.3.
Файловая система - это система хранения файлов и организации каталогов.
Рассмотрим иерархическую файловую систему на конкретном примере. Каждый диск имеет логическое имя (А:, В: - гибкие диски, С:, D:, Е: и так далее - жесткие и лазерные диски).
Пусть в корневом каталоге диска С: имеются два каталога 1-го уровня (GAMES, TEXT), а в каталоге GAMES один каталог 2-го уровня (CHESS). При этом в каталоге TEXT имеется файл proba.txt, а в каталоге CHESS - файл chess.exe (рис. 1.4).
| Рис. 1.4. Пример иерархической файловой системы |
Путь к файлу . Как найти имеющиеся файлы (chess.exe, proba.txt) в данной иерархической файловой системе? Для этого необходимо указать путь к файлу. В путь к файлу входят записываемые через разделитель "\" логическое имя диска и последовательность имен вложенных друг в друга каталогов, в последнем из которых содержится нужный файл. Пути к вышеперечисленным файлам можно записать следующим образом:
Путь к файлу вместе с именем файла называют иногда полным именем файла.
Пример полного имени файла:
Представление файловой системы с помощью графического интерфейса . Иерархическая файловая система MS-DOS, содержащая каталоги и файлы, представлена в операционной системе Windows с помощью графического интерфейса в форме иерархической системы папок и документов. Папка в Windows является аналогом каталога MS-DOS
Однако иерархическая структура этих систем несколько различается. В иерархической файловой системе MS-DOS вершиной иерархии объектов является корневой каталог диска, который можно сравнить со стволом дерева, на котором растут ветки (подкаталоги), а на ветках располагаются листья (файлы).
В Windows на вершине иерархии папок находится папка Рабочий стол. Следующий уровень представлен папками Мой компьютер, Корзина и Сетевое окружение (если компьютер подключен к локальной сети) - рис. 1.5.
| Рис. 1.5. Иерархическая структура папок |
Если мы хотим ознакомиться с ресурсами компьютера, необходимо открыть папку Мой компьютер.
1. В окне Мой компьютер находятся значки имеющихся в компьютере дисков. Активизация (щелчок) значка любого диска выводит в левой части окна информацию о его емкости, занятой и свободной частях.
Читайте также: