
Способы отображения основной памяти на кэш
Обновлено: 07.07.2024
Кэш-память (cache) – это способ совместного функционирования двух типов запоминающих устройств, который позволяет ускорить доступ за счет динамического копирования часто используемой информации из “медленного” в “быстрое” запоминающее устройство (ЗУ).
Свойство кэш-памяти – это прежде всего прозрачность для программ и пользователей. Другими словами функционирование кэш происходит незаметно для программ.
Кэш-памятью или кэшем, также часто называют одно из устройств – “быстрое” ЗУ. Оно дороже и быстрее.
Принцип действия кэш – памяти
Рис.1. Принцип действия кэш – памяти.
Как видно из рисунка запись в кэш выполняется при чтении, в том случае, если эти данные в кэш отсутствуют. Если же в кэш данные есть, то обращение к основной памяти не происходит и в этом случае они считываются из кэш.
Содержание кэш-памяти представляет собой совокупность записей обо всех данных из основной памяти (ОП), загруженных в нее
Рис.2 Содержание кэш – памяти.
Время доступа пропорционально вероятности попадания в кэш, которая составляет не менее 90%. Чем объясняется такая высокая степень попадания.
Объективные свойства данных, объясняющие высокую вероятность кэш-попадания
Высокая степень попадания в кэш объясняется некоторыми объективными свойствами компьютерных данных. К таким свойствам относятся:
Временная локальность
Если произошло обращение по некоторому адресу, то следующее обращение с большой вероятностью произойдет в ближайшее время
Пространственная локальность
Если произошло обращение по некоторому адресу, то с высокой степенью вероятности в ближайшее время произойдет обращение к соседним адресам
Временная локальность позволяет надеяться, что имеет смысл копировать данные в кэш, т.к. вскоре вероятно все равно к ним будет обращение.
Свойство пространственной локальности делает целесообразным копировать в кэш не одну единицу данных, а целый блок данных.
Алгоритм действия кэш-памяти
Рис.3 Алгоритм действия кэш – памяти.
Проблема согласования данных
Две копии данных: в памяти и кэше порождает проблему согласования. Т.е. версии данных в памяти и КЭШе в конечном итоге должны совпадать.
Применяется два подхода при записи в память:
- Сквозная запись (write through) – если данные находятся в кэше, то запись производится и в кэш и в память(анимация)
- Обратная запись (write back) - если данные находятся в кэше, то запись производится только в кэш и устанавливается признак модификации (в кэш)(анимация)
Способы отображения основной памяти на кэш.
Существует два основных способа отображения : случайное и детерминированное.
Случайное . Элемент памяти находится в произвольном месте кэша. Элемент хранится вместе с адресом. Поиск ведется по адресу. Это сравнительно дорогой способ.
Детерминированный . Элемент памяти отображается всегда в одно и тоже место кэша. Строки кэша и элементы памяти соотносятся как “один ко многим”. Преобразование адреса элемента в номер строки кэша выполняется некоторой функцией. Этот способ более дешевый.
Случайное отображение
Недостаток этого способа в больших временных затратах на поиск нужного элемента.
Для преодоления недостатка применяется так называемый ассоциативный поиск, при котором сравнение выполняется параллельно со всеми записями кэша
Признак, по которому выполняется сравнение (например адрес) называется тегом (tag)
Электронная реализация удорожает память, поэтому используется в кэше небольшой емкости
На днях решил систематизировать знания, касающиеся принципов отображения оперативной памяти на кэш память процессора. В результате чего и родилась данная статья.
Кэш память процессора используется для уменьшения времени простоя процессора при обращении к RAM.
Основная идея кэширования опирается на свойство локальности данных и инструкций: если происходит обращение по некоторому адресу, то велика вероятность, что в ближайшее время произойдет обращение к памяти по тому же адресу либо по соседним адресам.
Логически кэш-память представляет собой набор кэш-линий. Каждая кэш-линия хранит блок данных определенного размера и дополнительную информацию. Под размером кэш-линии понимают обычно размер блока данных, который в ней хранится. Для архитектуры x86 размер кэш линии составляет 64 байта.
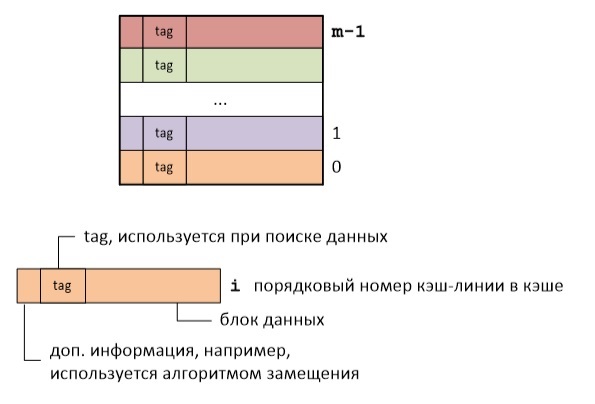
Так вот суть кэширования состоит в разбиении RAM на кэш-линии и отображении их на кэш-линии кэш-памяти. Возможно несколько вариантов такого отображения.
DIRECT MAPPING
Основная идея прямого отображения (direct mapping) RAM на кэш-память состоит в следующем: RAM делится на сегменты, причем размер каждого сегмента равен размеру кэша, а каждый сегмент в свою очередь делится на блоки, размер каждого блока равен размеру кэш-линии.

Блоки RAM из разных сегментов, но с одинаковыми номерами в этих сегментах, всегда будут отображаться на одну и ту же кэш-линию кэша:
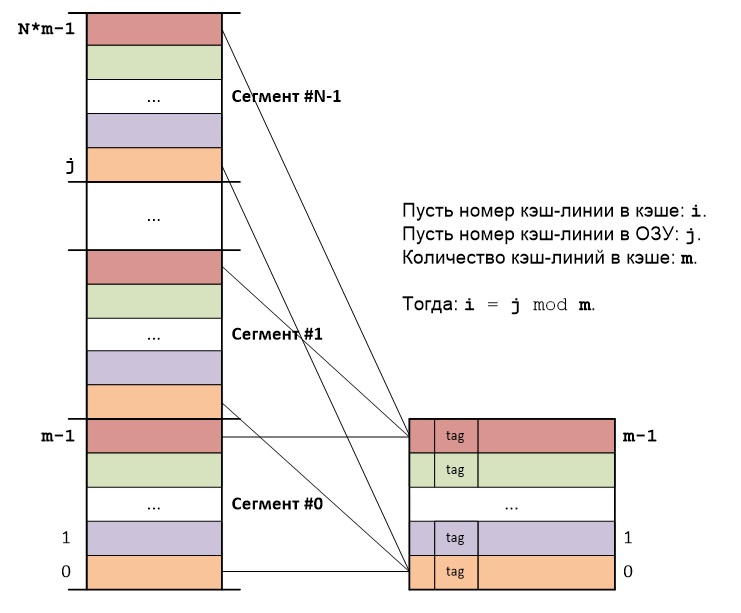
Адрес каждого байта представляет собой сумму порядкового номера сегмента, порядкового номера кэш-линии внутри сегмента и порядкового номера байта внутри кэш-линии. Отсюда следует, что адреса байт различаются только старшими частями, представляющими собой порядковые номера сегментов, а порядковые номера кэш-линий внутри сегментов и порядковые номера байт внутри кэш-линий — повторяются.
Таким образом нет необходимости хранить полный адрес кэш-линии, достаточно сохранить только старшую часть адреса. Тэг (tag) каждой кэш-линии как раз и хранит старшую часть адреса первого байта в данной кэш-линии.
b — размер кэш-линии.
m — количество кэш-линий в кэше.
Для адресации b байт внутри каждой кэш-линии потребуется: log2b бит.
Для адресации m кэш-линий внутри каждого сегмента потребуется: log2m бит.
m = Объем кэш-памяти/Размер кэш линии.
Для адресации N сегментов RAM: log2N бит.
N = Объем RAM/Размер сегмента.
Для адресации байта потребуется: log2N + log2m + log2b бит.
Этапы поиска в кэше:
1. Извлекается средняя часть адреса (log2m), определяющая номер кэш-линии в кэше.
2. Тэг кэш-линии с данным номером сравнивается со старшей частью адреса (log2N).
Если было совпадение по одному из тэгов, то произошло кэш-попадание.
Если не было совпадение ни по одному из тэгов, то произошел кэш-промах.
FULLY ASSOCIATIVE MAPPING
Основная идея полностью ассоциативного отображения (fully associative mapping) RAM на кэш-память состоит в следующем: RAM делится на блоки, размер которых равен размеру кэш-линий, а каждый блок RAM может сохраняться в любой кэш-линии кэша:
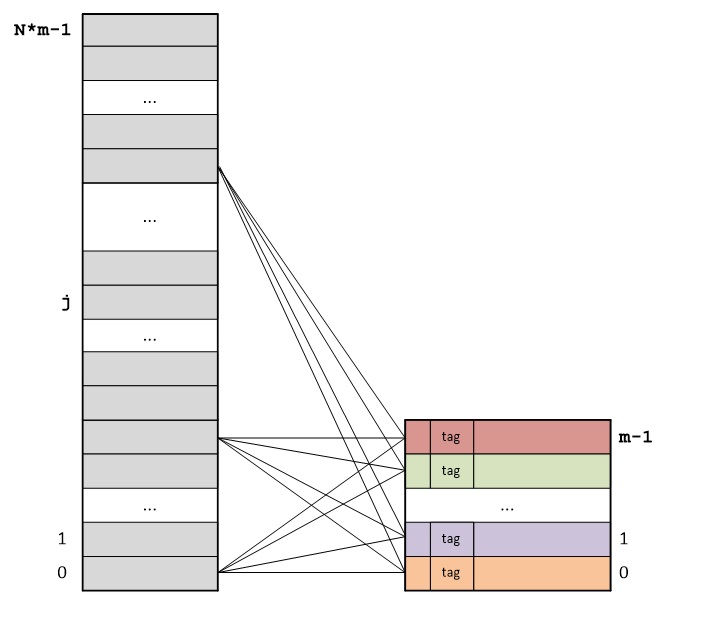
Адрес каждого байта представляет собой сумму порядкового номера кэш-линии и порядкового номера байта внутри кэш-линии. Отсюда следует, что адреса байт различаются только старшими частями, представляющими собой порядковые номера кэш-линий. Порядковые номера байт внутри кэш-линий повторяются.
Тэг (tag) каждой кэш-линии хранит старшую часть адреса первого байта в данной кэш-линии.
b — размер кэш-линии.
m — количество кэш-линий, умещающихся в RAM.
Для адресации b байт внутри каждой кэш-линии потребуется: log2b бит.
Для адресации m кэш-линий: log2m бит.
m = Размер RAM/Размер кэш-линии.
Для адресации байта потребуется: log2m + log2b бит.
Этапы поиска в кэше:
1. Тэги всех кэш-линий сравниваются со старшей частью адреса одновременно.
Если было совпадение по одному из тэгов, то произошло кэш-попадание.
Если не было совпадение ни по одному из тэгов, то произошел кэш-промах.
SET ASSOCIATIVE MAPPING
Основная идея наборно ассоциативного отображения (set associative mapping) RAM на кэш-память состоит в следующем: RAM делится также как и в прямом отображении, а сам кэш состоит из k кэшей (k каналов), использующих прямое отображение.
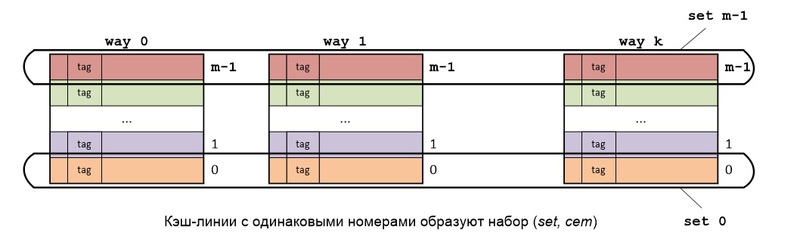
Кэш-линии, имеющие одинаковые номера во всех каналах, образуют set (набор, сэт). Каждый set представляет собой кэш, в котором используется полностью ассоциативное отображение.
Блоки RAM из разных сегментов, но с одинаковыми номерами в этих сегментах, всегда будут отображаться на один и тот же set кэша. Если в данном сете есть свободные кэш-линии, то считываемый из RAM блок будет сохраняться в свободную кэш-линию, если же все кэш-линии сета заняты, то кэш-линия выбирается согласно используемому алгоритму замещения.
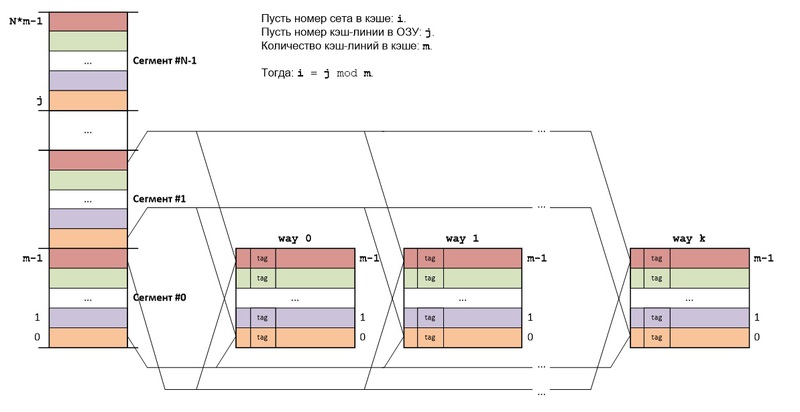
Структура адреса байта в точности такая же, как и в прямом отображении: log2N + log2m + log2b бит, но т.к. set представляет собой k различных кэш-линий, то поиск в кэше немного отличается.
Этапы поиска в кэше:
1. Извлекается средняя часть адреса (log2m), определяющая номер сэта в кэше.
2. Тэги всех кэш-линий данного сета сравниваются со старшей частью адреса (log2N) одновременно.
Если было совпадение по одному из тэгов, то произошло кэш-попадание.
Если не было совпадение ни по одному из тэгов, то произошел кэш-промах.
Т.о количество каналов кэша определяет количество одновременно сравниваемых тэгов.
Сущность отображения блока основной памяти на кэш-память состоит в копировании этого блока в какую-то строку кэш-памяти, после чего все обращения к блоку в ОП должны переадресовываться на соответствующую строку кэш-памяти.
Способ отображения должен одновременно отвечает трем требованиям:
1. обеспечивать быструю проверку кэш-памяти на наличие в ней копии блока основной памяти;
2. обеспечивать быстрое преобразование адреса блока ОП в адрес строки кэша;
3. реализовывать достижение первых двух требований наиболее экономичными средствами.
Способы отображения оперативной памяти на кэш-память будем рассматривать на следующем примере:
• емкость основной памяти 256 Кслов;
• емкость кэш-памяти 2 Кслова;
• ОП разбивается на блоки по 16 слов в каждом (размер строки кэш-памяти 16 слов).
В свою очередь, для адресации любого слова в кэш-памяти требуется 11-разрядный адрес (2К = 211). Кэш-память содержит 2К/16 = 211/24 = 27 = 128 строк. 11-разрядный адрес слова в кэш-памяти также можно представить состоящим из двух частей: адреса слова в строке – 4 младших разряда и адреса строки кэш-памяти – 7 старших разрядов.
Известные варианты отображения основной памяти на кэш можно свести к трем видам:
1. прямое отображение;
2. полностью ассоциативное;
Прямое отображение. При прямом отображении адрес строки i кэш-памяти, на которую может быть отображен блок j из ОП, однозначно определяется выражением:
где m – общее число строк в кэш-памяти.
В нашем примере i =j mod 128, где адрес строки i может принимать значения от 0 до 127, а адрес блока – от 0 до 16383.
Такое отображение означает, что на строку кэша с номером i отображается каждый m-й блок ОП, если отсчет начинать с блока, номер которого равен i.

При реализации такого отображения 14-разрядный адрес блока основной памяти условно разбивается на дваполя: 7-разрядный номер страницы и 7-разрядное поле строки. Поле строки указывает на одну из 128 = 2 7 строку кэш-памяти, в которую может быть отображен блок с заданнымадресом. Номер страницы определяет, какой именно блок из закрепленных за данной строкой кэша, отображается в этой строке. Когда блок фактически заносится в памятьданных кэша, в память теговкэш-памяти записывается номер страницы,которой принадлежит этот блок. Таким образом, семь старших разрядов адреса блока ОП служат тегом.
Прямое отображение – простой и недорогой в реализации способ отображения. Основной его недостаток – жесткое закрепление за определенными блоками ОП одной строки в кэш-памяти. Поэтому если программа поочередно обращается к словам из двух различных блоков, отображаемых на одну и тут же строку кэш-памяти, то постоянно будет происходить обновление данной строки и вероятность попадания будет низкой.
Полностью ассоциативное отображение. Полностью ассоциативное отображение позволяет преодолеть недостаток прямого отображения, разрешая загрузку любого блока ОП в любую строку кэш-памяти. При этом в адресе ОП выделяются два поля: поле адреса блока и поле слова вблоке. Когда блок фактически заносится в память данных кэша, в память теговкэш-памяти записывается адрес этого блока (рис. 30). Таким образом, адрес блока ОП служат тегом. Для проверки наличия копии блока вкэш-памяти контроллер кэш-памяти должен одновременно проверить теги всех строк на совпадение с полем адреса блока. Этому требованию наилучшим образом отвечает ассоциативная память.
Рисунок 30 – Организация кэш-памяти с полностью ассоциативным отображением Ассоциативное отображение обеспечивает гибкость при выборе строки для вновь записываемого блока. Принципиальный недостаток этого способа – необходимость использования дорогостоящей ассоциативной памяти.
Множественно-ассоциативное отображение. Множественно-ассоциативное отображение относится к группе методов частично- ассоциативного отображения. Оно является одним из возможных компромиссов, сочетающим достоинства прямого и ассоциативного способов отображения и, в известной мере, свободным от их недостатков.
Кэш-память (как тегов, так и данных) разбивается на v подмножеств (наборов), каждое из которых содержит k строк (принято говорить, что набор имеет k входов). Зависимость между набором и блоками ОП такая же, как и при прямом отображении:на строки, входящие в набор i, могут быть отображены только вполне определенные блоки основной памяти, в соответствии с соотношением i = j mod v,где j – адрес блока ОП. Вто же время размещение блоков по строкам набора – произвольное,и для поиска нужной строки в пределах набора используется ассоциативный принцип.
Рассмотрим пример 4-входовой кэш-памяти с множественно-ассоциативным отображением (рис. 31). Память данных кэш-памяти разбита на 32 набора по 4 строки в каждом. Память тегов также содержит 32 набора, в каждом из которых можетхраниться 4 значения теговпо одному на каждую строку набора. 14-разрядный адрес блока ОП представляется в виде двух полей: 9- разрядного поля тега и 5-разрядного поля номера набора. Номер набора однозначно указывает на один из наборов кэш-памяти.
Он также позволяет определить номера тех блоков ОП, которые можно отображать на этот набор. Такими являются блоки ОП, номера которых при делении на 2 5 = 32 дают в остатке число, совпадающее с номером данного набора кэш-памяти. Так, блоки 0, 32, 64,96 и т.д. основной памяти отображаютсяна набор с номером 0; блоки 1, 33, 65,97 и т.д. отображаются на набор 1 и т. д. Любой из блоков в последовательности может быть загружен в любую из четырех строк соответствующего набора.

Рисунок 31 – Организация кэш-памяти с четырехканальным наборно-ассоциативным отображением
Роль тега выполняют 9 старших разрядов адреса блокаОП, в которых содержится порядковый номер блока в последовательности блоков, отображаемых на один и тот же набор кэш-памяти. Например, блок 65 в последовательности блоков, отображаемых на набор 1, имеет порядковый номер 2 (отсчет ведется от 0).
При обращении к кэш-памяти 5-разрядный номер набора указывает на конкретный набор памяти тегов (это соответствует прямому отображению). Далее производится параллельное сравнение каждого из четырех тегов,хранящихся в этом наборе, с полем тега поступившего адреса, т.е. поиск нужного тега среди четырех возможных осуществляется ассоциативно.
В предельных случаях,когда v = m, k = 1, множественно-ассоциативное отображение сводится к прямому, а при v = 1, k = m – к ассоциативному.
Упрощенно можно считать,что кэш с множественно-ассоциативным отображениемпредставляет собой несколько параллельно и согласовано работающих каналов прямого отображения, в которых строки с одинаковыми номерами образуют соответствующий набор.
В зависимости от способа отображения основной памяти на кэш-память различают три архитектуры кэш-памяти:
1.кэш прямого отображения (direct-mapped cache);
2.полностью ассоциативный кэш (fully associative cache);
3.наборно- (частично- или множественно-) ассоциативный кэш (set associative cache).
Кэш прямого отображения имеет самую простую аппаратную реализацию, так как кэш-память имеет структуру обычной прямо адресуемой памяти и необходимо всего одно устройство сравнения. Поэтому такой кэш может иметь большой объем. Кэш-память этого типа в основном применяется во внешнем вторичном кэше, который подключается к системной шине процессора.
Реализация полностью ассоциативного кэша является сложной аппаратной задачей, которая решается только для небольших объемов, т.е. полностью ассоциативный кэш из-за своей сложности не может иметьбольшой объем и используется, как правило, для вспомогательных целей.Например, в процессорах Intel Pentium MMX полностью ассоциативный кэш используется в блоке страничной переадресации (осуществляет трансляцию линейного адреса в физический страницами размером 4 Кбайт или 4 Мбайт) для построения буфера ассоциативной трансляции TLB (Translation Look aside Buffer), предназначенного для ускорения доступа кинтенсивно используемым страницам размером 4 Кбайт: TLB команд – 32 вхождения, TLB данных – 64 вхождения.
Кэш- память представляет собой быстродействующее ЗУ, размещенное на одном кристалле с ЦП или внешнее по отношению к ЦП. Кэш служит высокоскоростным буфером между ЦП и относительно медленной основной памятью. Идея кэш-памяти основана на прогнозировании наиболее вероятных обращений ЦП к оперативной памяти . В основу такого подхода положен принцип временной и пространственной локальности программы .
Если ЦП обратился к какому-либо объекту оперативной памяти , с высокой долей вероятности ЦП вскоре снова обратится к этому объекту. Примером этой ситуации может быть код или данные в циклах. Эта концепция описывается принципом временной локальности , в соответствии с которым часто используемые объекты оперативной памяти должны быть "ближе" к ЦП (в кэше ).
Для согласования содержимого кэш-памяти и оперативной памяти используют три метода записи:
- Сквозная запись (write through) - одновременно с кэш-памятью обновляется оперативная память .
- Буферизованная сквозная запись (buffered write through) - информация задерживается в кэш-буфере перед записью в оперативную память и переписывается в оперативную память в те циклы, когда ЦП к ней не обращается.
- Обратная запись (write back) - используется бит изменения в поле тега, и строка переписывается в оперативную память только в том случае, если бит изменения равен 1.
Как правило, все методы записи, кроме сквозной, позволяют для увеличения производительности откладывать и группировать операции записи в оперативную память .
В структуре кэш-памяти выделяют два типа блоков данных:
- память отображения данных (собственно сами данные, дублированные из оперативной памяти );
- память тегов (признаки, указывающие на расположение кэшированных данных в оперативной памяти ).
Пространство памяти отображения данных в кэше разбивается на строки - блоки фиксированной длины (например, 32, 64 или 128 байт ). Каждая строка кэша может содержать непрерывный выровненный блок байт из оперативной памяти . Какой именно блок оперативной памяти отображен на данную строку кэша , определяется тегом строки и алгоритмом отображения. По алгоритмам отображения оперативной памяти в кэш выделяют три типа кэш-памяти:
- полностью ассоциативный кэш ;
- кэш прямого отображения;
- множественный ассоциативный кэш .
Для полностью ассоциативного кэша характерно, что кэш-контроллер может поместить любой блок оперативной памяти в любую строку кэш-памяти (рис. 9.1). В этом случае физический адрес разбивается на две части: смещение в блоке (строке кэша ) и номер блока. При помещении блока в кэш номер блока сохраняется в теге соответствующей строки. Когда ЦП обращается к кэшу за необходимым блоком, кэш-промах будет обнаружен только после сравнения тегов всех строк с номером блока.
Одно из основных достоинств данного способа отображения - хорошая утилизация оперативной памяти , т.к. нет ограничений на то, какой блок может быть отображен на ту или иную строку кэш-памяти. К недостаткам следует отнести сложную аппаратную реализацию этого способа, требующую большого количества схемотехники (в основном компараторов), что приводит к увеличению времени доступа к такому кэшу и увеличению его стоимости.
увеличить изображение
Рис. 9.1. Полностью ассоциативный кэш 8х8 для 10-битного адреса
Альтернативный способ отображения оперативной памяти в кэш - это кэш прямого отображения (или одновходовый ассоциативный кэш ). В этом случае адрес памяти (номер блока) однозначно определяет строку кэша , в которую будет помещен данный блок. Физический адрес разбивается на три части: смещение в блоке (строке кэша ), номер строки кэша и тег . Тот или иной блок будет всегда помещаться в строго определенную строку кэша , при необходимости заменяя собой хранящийся там другой блок. Когда ЦП обращается к кэшу за необходимым блоком, для определения удачного обращения или кэш-промаха достаточно проверить тег лишь одной строки.
Очевидными преимуществами данного алгоритма являются простота и дешевизна реализации. К недостаткам следует отнести низкую эффективность такого кэша из-за вероятных частых перезагрузок строк. Например, при обращении к каждой 64-й ячейке памяти в системе на рис. 9.2 кэш-контроллер будет вынужден постоянно перегружать одну и ту же строку кэш-памяти, совершенно не задействовав остальные.
увеличить изображение
Рис. 9.2. Кэш прямого отображения 8х8 для 10-битного адреса
Несмотря на очевидные недостатки, данная технология нашла успешное применение, например, в МП Motorola MC68020, для организации кэша инструкций первого уровня (рис. 9.3). В данном микропроцессоре реализован кэш прямого отображения из 64 строк по 4 байт . Тег строки, кроме 24 бит , задающих адрес кэшированного блока, содержит бит значимости , определяющий действительность строки (если бит значимости 0, данная строка считается недействительной и не вызовет кэш-попадания). Обращения к данным не кэшируются.
увеличить изображение
Рис. 9.3. Схема организации кэш-памяти в МП Motorola MC68020
Компромиссным вариантом между первыми двумя алгоритмами является множественный ассоциативный кэш или частично-ассоциативный кэш (рис. 9.4). При этом способе организации кэш-памяти строки объединяются в группы, в которые могут входить 2, 4, : строк. В соответствии с количеством строк в таких группах различают 2-входовый, 4-входовый и т.п. ассоциативный кэш . При обращении к памяти физический адрес разбивается на три части: смещение в блоке (строке кэша ), номер группы (набора) и тег . Блок памяти , адрес которого соответствует определенной группе, может быть размещен в любой строке этой группы, и в теге строки размещается соответствующее значение . Очевидно, что в рамках выбранной группы соблюдается принцип ассоциативности. С другой стороны, тот или иной блок может попасть только в строго определенную группу, что перекликается с принципом организации кэша прямого отображения. Для того чтобы процессор смог идентифицировать кэш-промах, ему надо будет проверить теги лишь одной группы (2/4/8/: строк).
увеличить изображение
Рис. 9.4. Двухвходовый ассоциативный кэш 8х8 для 10-битного адреса
Данный алгоритм отображения сочетает достоинства как полностью ассоциативного кэша (хорошая утилизация памяти, высокая скорость), так и кэша прямого доступа (простота и дешевизна), лишь незначительно уступая по этим характеристикам исходным алгоритмам. Именно поэтому множественный ассоциативный кэш наиболее широко распространен (табл. 9.2).
Примечания: В Intel-486 используется единый кэш команд и данных первого уровня. В Pentium Pro L1 кэш данных - 8 Кбайт 2-входовый ассоциативный, в остальных моделях P6 - 16 Кбайт 4-входовый ассоциативный. В Pentium 4 вместо L1 кэша команд используется L1 кэш микроопераций ( кэш трассы).
Для организации кэш-памяти можно использовать принстонскую архитектуру (смешанный кэш для команд и данных, например, в Intel-486). Это очевидное (и неизбежное для фон-неймановских систем с внешней по отношению к ЦП кэш-памятью) решение не всегда бывает самым эффективным. Разделение кэш-памяти на кэш команд и кэш данных ( кэш гарвардской архитектуры) позволяет повысить эффективность работы кэша по следующим соображениям:
- Многие современные процессоры имеют конвейерную архитектуру, при которой блоки конвейера работают параллельно. Таким образом, выборка команды и доступ к данным команды осуществляется на разных этапах конвейера, а использование раздельной кэш-памяти позволяет выполнять эти операции параллельно.
- Кэш команд может быть реализован только для чтения, следовательно, не требует реализации никаких алгоритмов обратной записи, что делает этот кэш проще, дешевле и быстрее.
Именно поэтому все последние модели IA-32 , начиная с Pentium, для организации кэш-памяти первого уровня используют гарвардскую архитектуру.
Критерием эффективной работы кэша можно считать уменьшение среднего времени доступа к памяти по сравнению с системой без кэш-памяти. В таком случае среднее время доступа можно оценить следующим образом:
где Thit - время доступа к кэш-памяти в случае попадания (включает время на идентификацию промаха или попадания), Tmiss - время, необходимое на загрузку блока из основной памяти в строку кэша в случае кэш-промаха и последующую доставку запрошенных данных в процессор , Rhit - частота попаданий.
Очевидно, что чем ближе значение Rhit к 1, тем ближе значение Tср к Thit . Частота попаданий определяется в основном архитектурой кэш-памяти и ее объемом. Влияние наличия и отсутствия кэш-памяти и ее объема на рост производительности ЦП показано в табл. 9.3.
Читайте также: