
Субд работающие с удаленными базами данных по способу работы с файлами делятся на два типа
Обновлено: 07.07.2024
Заметил, что когда спрашиваешь кого-нибудь, особенно на собеседовании, какие типы СУБД существуют, то первое что вспоминают многие – это реляционные базы данных, и NoSQL, а вот про разновидности часто забывают или не могут сформулировать их отличие. Поэтому начнем с простого перечисления наиболее используемых.
Тем, кому не хочется долго читать, может сразу перейти на итоговую таблицу .
Нужно обязательно сделать ремарку, что некоторые крупные производители, имеют в своем арсенале несколько типов СУБД, как в виде отдельных продуктов, так и в виде внутренней реализации. Например, у Oracle на самом деле чего только нет, начиная с классической реляционной СУБД, продолжая с отдельным продуктом Oracle NoSQL Database, который может использоваться и как документная, и как колоночная, и как ключ-значение. Отдельное решение от того же Oracle, Autonomous Data Warehouse – это уже специализированное решение для хранилищ данных. Еще один отдельный продукт от Oracle – Oracle Graph Server для работы с графами, и еще много другого. Этому можно посвятить отдельную серию статей.
Реляционные СУБД
Начнем по порядку, классические, реляционные СУБД чаще всего используются для построения решений OLTP (Online Transaction Processing). В таких решениях СУБД работает с небольшими по размерам транзакциями, но идущими большим потоком, и при этом от системы требуется минимальное время отклика, а так же возможность, при определенных условиях, отменить любые изменения выполняемых в рамках транзакции. Если вы строите систему, в рамках которой требуется хранить значительное количество сущностей (таблиц), с различными типами связей между ними (один-к-одному, один-к-многим, многие-ко-многим), то это скорее всего про реляционные СУБД.
Наиболее известные СУБД такого типа - Oracle, Microsoft SQL, PostgreSQL, MySQL.
Когда выбирать реляционную СУБД
Один из основных признаков, который говорит о том что нужно выбирать реляционную СУБД – это высокая нормализация данных. Дополнительными признаками будет необходимость обработки большого кол-ва коротких транзакций, с большей долей операций на вставку
Когда не выбирать реляционную СУБД
Если предполагается хранить не структурируемые данные, или наоборот очень простые структуры типа ключ-значение, то лучше посмотреть в сторону документных СУБД и специализированных СУБД типа ключ-значение соответственно.
Так же один из признаков, что имеет смысл подумать не о реляционных СУБД, это такой факт как необходимость часто обновлять значения в одних и тех же строках. Обычно это обходится "дорого" в реляционных СУБД, и нужно применять "продвинутую магию" что бы делать это корректно.
Конечно, тут есть много «но», или «а если очень хочется», и других ситуаций, когда данные рекомендации можно игнорировать. Это нормально, особенно когда за дело берется эксперт, который знает как это сделать.
СУБД типа ключ-значение
Наверное один из самых простых типов СУБД. В упрощенном виде, это некая таблица с уникальным ключом и собственно связанным с ним значением, в котором может быть что угодно. Чаще всего такие СУБД используют для кэширования, т.к. они очень быстро работают, а это и не сложно, когда есть уникальный ключ, и запрос возвращает только одно значение. У некоторых представителей данных СУБД есть возможность работать полностью в памяти, а так же есть возможность задавать срок жизни записи, после истечения которого, записи будут автоматически удаляться.
Наиболее известные СУБД такого типа - Redis и Memcached.
Когда выбирать СУБД ключ-значение
Когда не выбирать СУБД ключ-значение
Если вы предполагаете хранить в базе данных много сущностей (таблиц), а у сущностей будут сложные структуры с разными типами данных. Так же, если вы предполагаете делать из этой таблицы сложные запросы которые возвращают множества строк.
Документные СУБД
Документные или документно-ориентированные СУБД - это одна из наиболее популярных разновидностей NoSQL СУБД, где основной единицей логической модели данных является документ - структурированный текст, с определенным синтаксисом.
Иногда встречаются мнения что модель данных в документных БД похожа на модель данных в объектно-ориентированных базах данных. В этом есть доля правды, единственная реальная разница между ними заключается в том, что базы данных документов только сохраняют состояние, но не поведение.
Так же, само название "документо-ориентированная" подчас вводит в заблуждение, и мне встречались коллеги, которые считали, что это база для систем документооборота. Нет, это не так.
Интересно, что документные СУБД развиваются достаточно активно, и сейчас некоторые из них, в том числе, поддерживают проверку схемы.
Известными представителями таких СУБД являются CouchDB, MongoDB, Amazon DocumentDB.
Когда выбирать документную СУБД
Если нужно хранить объекты в одной сущности, но с разной структурой. Если нужно хранит структуры, включая объекты, списки и словари, особенно в формате близкому к JSON.
На самом деле область применения документных СУБД очень широкая. Их можно использовать как компактную базу данных для отдельно взятого микро-сервиса, так и для вполне масштабных решений, в качестве хранилища состояний чего-либо.
Когда не выбирать документную СУБД
Не самое лучшее решение для реализации транзакционная модели, и точно не лучший вариант для формирования отчетности.
Графовые СУБД
Графовые СУБД - специфичный тип, предназначены для работы с графами, с их узлами, свойствами, и произвольными отношениями между узлами.
Очень простой пример, это организация связей в различного типа социальных сетях, где нужно хранить связи между пользователями (узлами) по разным критериям (родственные связи, коллеги, общие интересы).
Известные представители этого типа субд - Neo4j, Amazon Neptune, InfiniteGraph, InfoGrid.
Когда выбирать графовые СУБД
Точно стоит обратить внимание на графовые СУБД, если строите какое-то подобие социальной сети, или реализуете систему оценок и рекомендаций. Ну и во всех случаях когда вы хорошо понимаете что такое графы, и для чего это нужно.
Когда не выбирать графовые СУБД
Практически во всех остальных случаях, кроме указанных выше, лучше воздержаться от использования графовых СУБД.
Колоночные СУБД
Колоночные СУБД очень похожи на реляционные. Они так же состоят из строк, которые имеют атрибуты, а строки группируются в таблицах. Различия в логических моделях несущественные, а вот на уровне физического хранения данных различия значительные.
В реляционных СУБД данные хранятся "построчно", это означает что для считывания значения определенной колонки, придется прочитать практически всю строку, как минимум от первой до нужной колонки. В колоночной СУБД данные хранятся "поколоночно", т.е. колонка - это как отдельная таблица. Соответственно чтение будет происходить из конкретного столбца сразу. На практике это реально работает очень быстро (проверено мной на нескольких реализованных хранилищах данных).
Основные преимущества колоночных СУБД – эффективное выполнения сложных аналитических запросов на больших объемах, и легкое, практически мгновенное, изменение структуры таблиц с данными, плюс существенная компрессия и сжатие, которое позволяет значительно экономить место.
Яркие представители колоночных СУБД - Sybase IQ (ныне SAP IQ), Vertica, ClickHouse, Google BigTable, InfoBright, Cassandra.
Когда выбирать колоночные СУБД
Один из весомых аргументов за использование именно колоночной СУБД - это если вы хотите построить хранилище данных, и планируете делать выборки со сложными аналитическими вычислениями. Косвенный признак, который так же может сигнализировать о том, что имеет смысл, хотя бы посмотреть в сторону колоночных СУБД - это если количество строк, из которых делаются выборки, превышает сотни миллионов.
Когда не выбирать колоночные СУБД
Учитывая специфику колоночных СУБД, будет не эффективно ее использовать, если выборки достаточно простые, параметры выборки статичны, и если преобладают выборки по ключевым значениям. Так же, если количество строк в таблице, из которой делается выборка, меньше сотен миллионов строк, то скорее всего не будет большого преимущества, по сравнению с реляционной СУБД.
Нужно так же иметь ввиду, что в колоночных СУБД могут быть и другие ограничения. Например, может отсутствовать поддержка транзакций, а язык запросов может отличаться от классического SQL, и прочее.
Итоги
Важное замечание – не пытайтесь сразу все задачи решить в рамках одной СУБД. Это более чем нормально иметь несколько разных типов СУБД. Так же, не пытайтесь сразу определиться с производителем СУБД, или связать свою жизнь с одним конкретным брендом.
При выборе типа СУБД следует, прежде всего, исходить из типа решаемых задач, типов обрабатываемых данных, перспектив роста и масштабирования.
Обращайте так же внимание на популярность и наличие широкого круга разработчиков и средств разработки – это даст вам возможность, при необходимости, найти ответ на возникший вопрос быстро.
В данной статье я намеренно не делаю акцент на выбор между облачными и on-premise решениями - эта тема одной из следующих статей.
Итак, в таблице представленной ниже, кратко собрано то, что описано выше в статье.
Тип СУБД
Когда выбирать
Примеры популярных СУБД
Нужна транзакционность; высокая нормализация; большая доля операций на вставку
Oracle, MySQL, Microsoft SQL Server, PostgreSQL
Для хранения объектов в одной сущности, но с разной структурой; хранение структур на основе JSON
CouchDB, MongoDB, Amazon DocumentDB
Задачи подобные социальным сетям; системы оценок и рекомендаций
Neo4j, Amazon Neptune, InfiniteGraph, InfoGrid
Хранилища данных; выборки со сложными аналитическими вычислениями; количество строк в таблице превышает сотни миллионов
Vertica, ClickHouse, Google BigTable, Sybase \ SAP IQ, InfoBright, Cassandra
Надеюсь данная статья оказалась полезной.
В следующих статьях посмотрим на выбор между облачными и on-premise СУБД, платными и бесплатными, и многое другое.
Источник 1
Типы баз данных по способу доступа
По способу доступа различают:
Клиент-серверные БД. Доступ к данным осуществляется путем запроса к серверу БД, который и осуществляет непосредственные операции с данными. Главное достоинство данного способа — возможность работы с одной БД любого количества пользователей, минимизация передаваемого по сети трафика. Недостаток — требуется отдельный сервер для полноценного функционирования данной модели
Встраиваемые БД. Работа с данными осуществляется путем подключения к программе библиотек реализующих работу с БД и передачи требуемых вызовов данным библиотекам. Сама БД, обычно, располагается на том же компьютере, что и клиентская программа. Главное достоинство — скорость работы (при относительно небольших объемах данных) и компактность системы. Недостатки — невозможно масштабирование, катастрофическое падение производительности на крупных выборках.
Файл-серверные БД. Устаревший тип БД. Имеет смысл применять только в случае наследования большого количества существующего кода. По сути - некая смесь двух вышеприведенных способов. Данные хранятся на файловом сервере, доступ к ним осуществляют клиенты БД установленные на каждом локальном компьютере. Достоинств в данный момент нет. Недостатки — большой сетевой трафик, частые взаимные блокировки со стороны различных клиентов.
Источник 2
По способу доступа к данным БД разделяются на БД с локальным доступом и БД с удаленным (сетевым) доступом.
Система централизованных БД с сетевым доступом предполагает различные архитектуры подобных систем
файл – сервер
клиент – сервер
1. Архитектура файл – сервер.
Выделяется одна из машин сети в качестве центральной (сервер файлов) . Все другие машины сети выполняют функции рабочих станций, с помощью которых поддерживается доступ пользовательской системы централизованных БД. Совместно используемая централизованная БД хранится на одной из машин. Файлы БД в соответствии с пользовательскими запросами передаются на рабочие станции, где в основном и производится обработка.
2. Архитектура клиент – сервер.
В этой концепции помимо хранения централизованной БД центральная машина (сервер БД) должна обеспечивать выполнение основного объема обработки данных. Запросы на данные, выдаваемые клиентом (рабочей станцией) порождают поиск и извлечение данных на сервере. Извлеченные данные (но не файлы) транспортируются по сети от сервера к клиенту. Спецификой архитектуры «клиент – сервер» является использование языка запросов SQL.

Основные понятия. СУБД -- Система Управления Базами Данных (DBMS -- DataBase Management System). Программа, либо комплекс программ, предназначенных для полнофункциональной работы с данными. Как правило, включает в себя инструменты для создания и изменения структуры хранения наборов данных, а также средства доступа к хранимым данным, с возможностью их чтения, добавления, изменения и удаления. При этом, у большинства СУБД имеется собственный встроенный язык (возможно не один) для работы с данными. Сама база данных (БД) обычно находится просто в файлах закрытого, либо открытого формата.
Отличие «серверной» и «настольной» СУБД. Под настольной (desktop) обычно подразумевается СУБД, которая всегда запускается на компьютере пользователя, хотя сама база данных может находиться в другом месте. В результате несколько копий СУБД могут обращаться к одной базе данных. Серверная (server) СУБД, как правило, запускается в на той же машине (сервере баз данных), где находятся файлы БД. Непосредственно к базе данных обращается лишь один экземпляр СУБД. Пользовательские приложения общаются только с этой СУБД через ее API, независимо от того, работают они на той же машине или на другой. Для многопользовательских баз данных более эффективным и надежным вариантом является серверная СУБД. В ней гораздо быстрее происходит доступ к данным, и значительно проще решаются конфликты между разными пользователями.
Понятие реляционной базы данных. Реляционная (relational) БД отличается способом представления информации, находящейся в ней. Данные в такой базе хранятся в плоских таблицах. Каждая таблица имеет собственный, заранее определенный набор именованных колонок (полей). Поля таблицы обычно соответствуют атрибутам сущностей, которые необходимо хранить в базе. Количество строк (записей) в таблице неограниченно, и каждая запись соответствует отдельной сущности. Каждая таблица должна иметь первичный ключ (ПК) -- поле или набор полей, содержимое которых однозначно определяет запись в таблице и отличает ее от других. Связь между двумя таблицами обычно образуется при добавлении в первую таблицу поля, содержащего значение первичного ключа второй таблицы. Реляционные СУБД (РСУБД) предоставляют средства для всевозможных пересечений и объединений любых таблиц, отбора записей по разнообразным условиям, группировки и сортировки результатов. Реляционная база данных сочетает наглядность представления информации с простотой (относительной) реализации своей концепции и является наиболее популярной структурой для хранения данных на сегодняшний день.
Хранение реляционной БД. Данные в реляционной БД хранятся в плоских таблицах. Каждая таблица имеет собственный, заранее определенный набор именованных колонок (полей). Поля таблицы обычно соответствуют атрибутам сущностей, которые необходимо хранить в базе. Количество строк (записей) в таблице неограниченно, и каждая запись соответствует отдельной сущности.
Отличие записей от друг друга. Записи в таблице отличаются только содержимым их полей. Две записи, в которых все поля одинаковы, считаются идентичными. Каждая таблица должна иметь первичный ключ (ПК) -- поле или набор полей, содержимое которых однозначно определяет запись в таблице и отличает ее от других. Отсутствие первичного ключа и наличие идентичных записей в таблице обычно возможно, но крайне нежелательно.
Связывание таблиц между собой. Простейшая связь между двумя таблицами образуется при добавлении в первую таблицу поля, содержащего значение первичного ключа второй таблицы. В общем случае, реляционные БД предоставляют очень гибкий механизм для всевозможных пересечений и объединений любых таблиц, с разнообразными условиями. Для описания множеств, получающихся при пересечении и объединении таблиц, используется специальный математический аппарат -- реляционная алгебра.
Понятие «нормализация». Упорядочивание модели БД. Грубо говоря, нормализацией называют процесс выявления отдельных независимых сущностей и вынесения их в отдельные таблицы. При этом, связи с такими таблицами, обычно организуют по их первичному ключу. В результате нормализации, увеличивается гибкость работы с БД. Также, уменьшается содержание дублирующей информации в БД, а это сильно понижает вероятность возникновения ошибок.
Имеет ли значение порядковый номер записи в таблице. Нет. Реляционная алгебра оперирует множествами, в которых порядковый номер элемента не несет никакой смысловой нагрузки. Записи отличатся только содержимым их полей. Две записи, в которых все поля одинаковы, будут абсолютно идентичны в реляционной БД.
Понятие SQL-сервер. Сервер для управления реляционными БД обычно называют SQL-сервером. SQL (Structured Query Language -- язык структурированных запросов) является стандартным языком для работы с реляционными БД. Кроме стандартных реляционных операций, этот язык предоставляет возможности для изменений структуры таблиц. Различные варианты SQL используются во всех, как серверных, так и в настольных реляционных СУБД.
Понятие пост-реляционной базы данных. Пост-реляционными, часто называют многомерные базы данных. Данные в многомерных базах, представляются в виде разреженных многомерных массивов, а не плоских таблиц, как в реляционных базах. Для определенных задач, многомерные базы могут давать значительный выигрыш в быстродействии, по сравнению с реляционными. Наиболее известные многомерные СУБД:
· Cache
· Teradata
Разновидности СУБД. Кроме реляционных, объектно-ориентированных и многомерных СУБД, также давно известны иерархические и сетевые базы данных. Данные и связи между ними, в иерархических БД представлены в виде деревьев. Для некоторых задач, такая форма представления данных может оказаться гораздо более эффективной, чем любая другая. В сетевых базах, данные могут быть связаны произвольным образом, но эти связи должны создаваться предварительно, вместе со структурой данных. По сравнению с реляционными БД, сетевая модель может давать выигрыш в быстродействии, при некоторой потере гибкости.
Понятие «сервер баз данных». Под сервером БД обычно подразумевается СУБД, запущенная на той же машине, где находятся файлы БД, и монопольно распоряжающаяся этими файлами. При этом, все пользовательские приложения должны работать с базой только через эту СУБД, используя ее язык запросов.
Понятие «Клиент». Клиентом к БД, обычно называют пользовательское приложение, которое общается с сервером БД. Модель работы, в которой клиент общается непосредственно с сервером, не используя промежуточных приложений, называется архитектурой клиент-сервер.
Как клиент общается с сервером. На пользовательских машинах, обычно устанавливаются специальные программы-шлюзы, которые, через сетевой протокол, обеспечивают связь с сервером БД. Через эти шлюзы, приложения передают запросы серверу и получают результаты. Часто, дополнительно устанавливается библиотека (ODBC, OLE DB и т.п.), предоставляющая приложениям API для работы с сервером БД.
Назначение сервера приложений. Сервер приложений может использоваться для многих целей. Как правило, сервер приложений находится на отдельной машине. На него можно переложить всю функциональность программы, оставив клиенту только интерфейсную часть. Это разгрузит клиента и сервер БД от вычислений. Также, при большом количестве пользователей, можно использовать несколько серверов приложений для распределения нагрузки. А для ускорения доступа к часто используемым таблицам, их обычно кэшируют на сервере приложений.
Объектно-ориентированная СУБД. В объектно-ориентированных БД (ООБД), данные представлены в виде объектов различных классов. Как правило, имеются возможности создавать новые классы, наследовать их от уже имеющихся, задавать произвольные атрибуты и методы для классов. Для доступа к объектам, в каждой ООБД обычно предусматривается свой собственный язык, либо расширение другого языка. Пока еще ООБД недостаточно развиты и не представляют серьезной конкуренции SQL-серверам, хотя и выглядят более предпочтительными для разработчиков. Производители SQL-серверов тоже, в свою очередь, иногда делают попытки соорудить над реляционным ядром сервера объектно-ориентированную надстройку.
Достаточно распространены следующие ООБД: Cache, FastObjects, GemStone/S, Jasmine, ObjectStore, Objectivity/DB, Versant.
Что можно делать при помощи SQL. SQL (Structured Query Language -- язык структурированных запросов) является стандартным языком для работы с реляционными БД. Разделяется на две основные части: DDL (Data Definition Language -- язык определения данных) и DML (Data Manipulation Language -- язык обработки данных). DDL предоставляет средства для создания и изменения структуры хранения данных (БД, таблиц, процедур, типов данных и т.п.). DML предназначен для чтения и изменения данных. Основные операторы DML: select -- выборка, insert -- вставка, update -- изменение, delete -- удаление. Также, с помощью SQL, часто реализован доступ к служебным функциям SQL-сервера (заведение пользователей, создание резервных копий БД и т.д.).
Зачем нужны транзакции. Во многих случаях, необходимо проведение группы операций по изменению данных таким образом, чтобы эта группа обладала свойством атомарности (либо вся целиком выполняется, либо вся целиком не выполняется). Такая группа операций называется транзакцией. В SQL-серверах существуют операторы, позволяющие обозначить начало транзакции (begin transaction), ее успешное завершение (commit transaction), либо откат транзакции (rollback transaction).
Журнал транзакций. Любые изменения данных, проведенные внутри транзакции, записываются в специальный журнал транзакций (transaction log). При откате транзакции, данные восстанавливаются в прежнем виде, а записи об изменениях удаляются из журнала транзакций.
Блокировки. При изменении данных внутри транзакции, модифицируемые записи блокируются сервером до окончания этой транзакции. Если какая-нибудь другая транзакция пытается изменить заблокированные записи, то ее выполнение останавливается, пока не будет снята блокировка, то есть, пока не завершится первая транзакция. Некоторые сервера имеют неприятную особенность блокировать данные не отдельными записями, а целыми страницами, которые могут содержать довольно много записей.
Отличие «версионников» от «блокировочников». Классические «блокировочники» не дают возможности разным транзакциям одновременно изменять одни и те же записи, блокируя их на время транзакции. В результате, при попытке изменить заблокированную запись, другая транзакция будет простаивать, пока не завершиться первая. В свою очередь, «версионники» позволяют одновременно модифицировать одни и те же записи, создавая при этом разные версии одной записи.
Почему возникает deadlock. Перекрестная блокировка (deadlock) двух транзакций возникает при изменении одних и тех же записей в разном порядке. Последовательность действий, приводящая к перекрестной блокировке:
1. Транзакция A изменяет запись X. Заблокирована X.
2. Транзакция B изменяет запись Y. Заблокирована Y.
3. Транзакция A пытается изменить запись Y. Остановлена A.
4. Транзакция B пытается изменить запись X. Остановлена B.
Сервер определяет перекрестную блокировку и откатывает одну из транзакций, возвращая ошибку соответствующему соединению. Аминь. Чтобы не выводить ошибку пользователю, обломанное соединение должно молча повторить транзакцию.
Понятие «индексы». Для ускорения операций выборки данных. При поиске полей с определенным значением, сервер вынужден перебирать все записи в таблице. В этом случае, время поиска линейно зависит от размера таблицы. Индекс по полю, обычно представляющий собой бинарное дерево, дает возможность резко сократить время поиска, превратив эту зависимость в логарифмическую. Однако, наличие индексов в таблице, замедляет операции модификации данных.
Необходимость первичного ключа в таблице. Первичный ключ (ПК) -- поле или набор полей, содержимое которых однозначно определяет запись в таблице и отличает ее от других. Служит для однозначной идентификации записей и в таблице может быть только один. Обычно, при определении первичного ключа, по нему автоматически создается уникальный индекс.
Что такое триггер. Триггер -- процедура, выполняемая сервером автоматически при модификации данных в таблице. В основном, триггеры используются для поддержания целостности дублирующей информации в денормализованной БД.
Можно ли использовать свою функцию в SQL-запросе. Можно, практически во всех современных SQL-серверах. Различия только в синтаксисе определения и вызова функции. Кроме того, некоторые сервера позволяют использовать функции, написанные на других языках (не SQL).
Представление (view) -- это запрос на выборку, хранящийся на сервере, как отдельный объект. Так как, результат этого запроса можно рассматривать в качестве таблицы, представление допускается использовать в других запросах, также как любую обычную таблицу.
Материализованное представление хранится на сервере в виде таблицы, которая автоматически обновляется при изменении данных, имеющих отношение к этому представлению.
Хранимые процедуры (SP -- Stored Procedure) представляют собой последовательность команд на расширениях SQL, либо на других языках, поддерживаемых сервером. Могут принимать параметры и возвращать значение заданного типа. Часто используются для выполнения операций, напрямую связанных с логикой задачи, для которой проектировалась БД. Иногда, используются вместе с представлениями, для обеспечения безопасности БД (все изменения через SP, все выборки через view).
Типы данных есть в SQL-сервере. Обычно, для полей в таблицах могут использоваться только самые простые типы: числа (целые и дробные), строки (сильно ограниченные по длине), дата (и время), бинарные данные большого размера (для текста, графики и т.п.). В некоторых серверах допускается использование массивов и самодельных структур.
Необходимость внешнего ключа. Внешний ключ (FK -- Foreign Key) используется для создания жесткой связи (многие к одному) между двумя таблицами. Внешний ключ задается только в том случае, если в первой таблице есть поле, содержащее значение первичного ключа из второй таблицы. При изменении значения первичного ключа во второй таблице, могут быть изменены все соответствующие значения связанного поля в первой таблице. При удалении записи с определенным первичным ключом из второй таблице, могут быть удалены все записи с соответствующим значением связанного поля в первой таблице. Обычно, при определении внешнего ключа, по нему автоматически создается индекс, который используется в запросах при объединении этих двух таблиц.
Репликацией обычно называют процесс синхронизации данных между несколькими БД. Наиболее развитые SQL-сервера содержат встроенные средства репликации. Для остальных могут быть использованы продукты сторонних фирм. Одностороняя репликация подразумевает изменение данных только в одной базе, с последующей передачей изменений на остальные. Соответственно, довольно проста в реализации и надежна в работе. Двустороняя репликация предоставляет гораздо более мощный инструмент распределенной работы между SQL-серверами. Плата за это -- сложность и большая вероятность конфликтов при работе.
Типы SQL серверов и их особенности
Какой тип сервера лучше выбрать? На какой хватит денег.:) Вообще-то это может сильно зависеть от постановки задачи, количества пользователей и прихотей заказчика. Ниже приведена таблица самых распространенных SQL-серверов в порядке (примерно) убывания их возможностей:
IBM DB2 Universal Database
Самый навороченный язык запросов, лучший оптимизатор, возможность писать функции на других языках.
Цель лекции: Ознакомиться с комплексом основных понятий классификации БД и СУБД . Ознакомиться с функциями и функциональными возможностями СУБД .
Классификация - разделение множества на подмножества по неформально предложенному признаку. В силу многогранности баз данных и СУБД (комплекса технических и программных средств, для хранения, поиска, защиты и использования данных) имеется множество классификационных признаков. Классификация БД по основным признакам приведена на рис. 2.1.
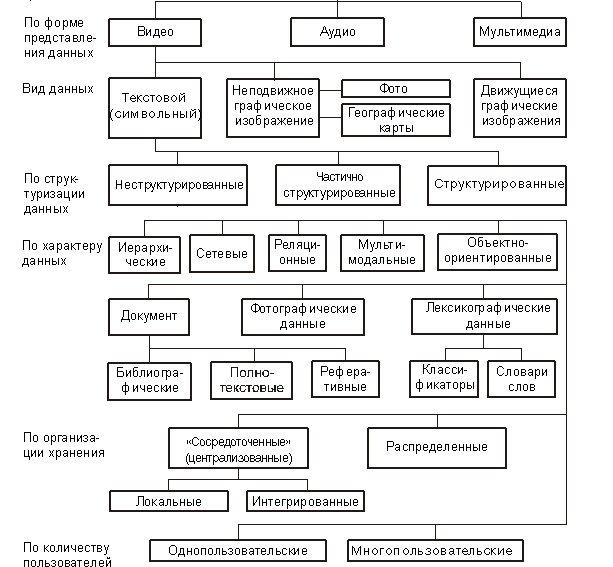
Базы данных могут классифицироваться и с точки зрения экономической: по условиям предоставления услуг - бесплатные и платные (бесприбыльные, коммерческие); по форме собственности - государственные, негосударственные; по степени доступности - общедоступные, с ограниченным кругом пользователей.
Классификация баз данных
В мире существует множество СУБД . Несмотря на их различие, все они опираются на единый устоявшийся комплекс основных понятий.
СУБД носит централизованный характер. Что предполагает необходимость существования некоторого лица (группы лиц), на которое возлагаются функции администрирования данными, хранимыми в базе.
По технологии обработки данных БД делятся на централизованные БД и распределённые БД.
Централизованная БД хранится в памяти одной вычислительной системы (применяется в локальных сетях ПК).
Централизованные БД могут быть с сетевым доступом.
Архитектуры систем централизованных БД с сетевым доступом подразделяются на файл-сервер и клиент- сервер .
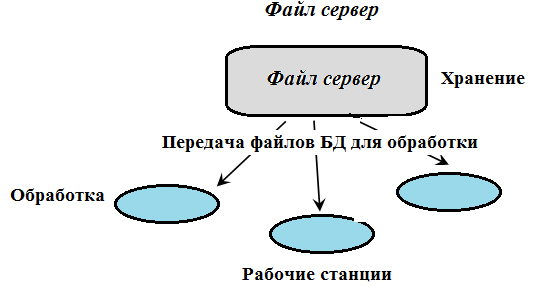
Архитектура систем БД с сетевым доступом ( Файл-сервер ) как показано на рис. 2.2 предполагает выделение одной из машин сети в качестве центральной ( сервер файлов). На ней хранится совместно используемая централизованная БД . Все другие машины сети являются рабочими станциями. Файлы БД в соответствии с пользовательскими запросами передаются на рабочие станции, где и производится обработка. При большой интенсивности доступа к одним и тем же данным производительность системы падает.
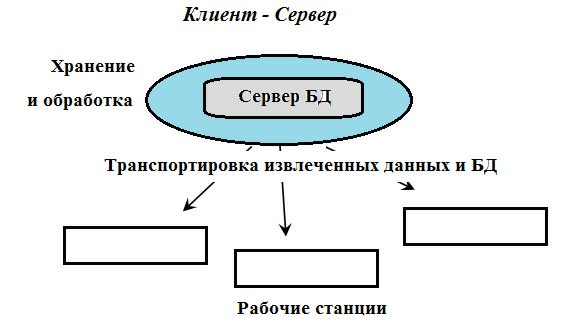
В архитектуре Клиент-сервер ( рис. 2.3) подразумевается, что помимо хранения централизованной БД центральная машина ( сервер базы данных ) должна обеспечивать выполнение основного объёма обработки данных. Запрос на данные клиента, порождает поиск и извлечение данных на сервере. Извлечённые данные (но не файлы) транспортируются по сети от сервера к клиенту.
Пример БД - деловой ежедневник, в котором каждому календарному дню выделено по странице. Даже в отсутствии там записей, он не перестаёт быть ежедневником, т.к. имеет структуру, отличающую его от записных книжек, рабочих тетрадей и т.п. Другие примеры БД : база данных больных в поликлинике, БД по видеофильмам (видеотека), БД по сотрудникам организации (Ф.И.О., пол, дата рождения, место жительство, телефон, состав семьи и т.д.).
Распределённая БД состоит из нескольких частей, хранимых в различных ЭВМ вычислительной сети (работа с такой БД происходит с помощью СУБД ).
По способу доступа к данным БД разделяются на БД с локальным и удаленным доступом.
БД с локальным доступом называется, если эта вычислительная система является компонентом сети ЭВМ, возможен распределённый доступ к такой базе. Такой способ использования БД часто применяют в локальных сетях ПК.
БД с удалённым (сетевым) доступом называется когда, части БД могут пересекаться или даже дублироваться, но хранятся в различных ЭВМ вычислительной сети.
Для работы с созданной БД пользователю или администратору БД следует иметь перечень файлов-таблиц с описанием состава их данных (структуры, схемы). Для этого создается специальный файл , называемый словарем данных (депозитарием, словарем-справочником, энциклопедией). Описание БД относится к метаинформации.
В качестве технических средств могут выступать супер- или персональные компьютеры с соответствующими периферийными устройствами.
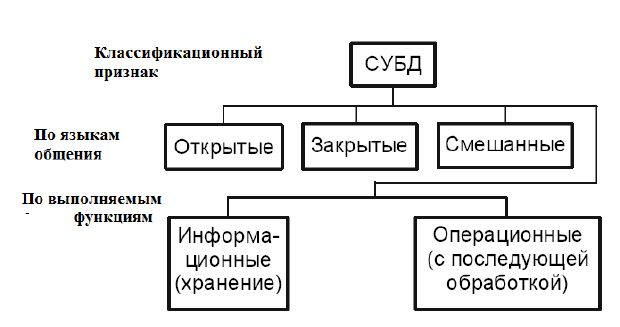
Классификация СУБД
Система управления базами данных (СУБД) - это совокупность языковых и программных средств, предназначенных для создания, ведения и совместного использования БД многими пользователями.
Системы управления базами данных следует классифицировать отдельно ( рис. 2.4).
Состав СУБД и работа БД
СУБД представляет собой оболочку, с помощью которой при организации структуры таблиц и заполнения их данными получается та или иная база данных . В связи с этим полезно поговорить о системе программно-технических, организационных и "человеческих" составляющих ( рис. 2.5). Программные средства включают систему управления, обеспечивающую ввод-вывод, обработку и хранение информации, создание, модификацию и тестирование БД , трансляторы .
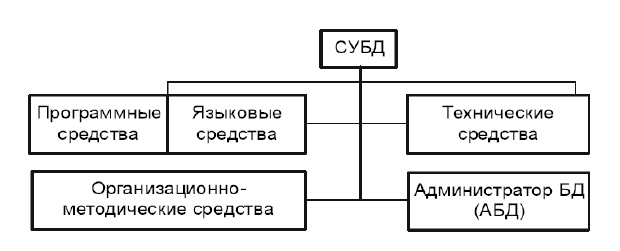
Базовыми внутренними языками программирования являются языки четвертого поколения. В качестве базовых языков могут использоваться C, C++, Pascal , Object Pascal . Язык C++ позволяет строить программы на языке Visual Basic с широким спектром возможностей, более близком и понятном даже пользователю-непрофессионалу, и на непроцедурном ( декларативном) языке структурированных запросов SQL . Следует отметить, что исторически для системы управления базой данных сложились три языка:
- язык описания данных (ЯОД), называемый также языком описания схем, - для построения структуры ("шапки") таблиц БД;
- язык манипулирования данными (ЯМД) - для заполнения БД данными и операций обновления (запись, удаление, модификация);
- язык запросов - язык поиска наборов величин в файле в соответствии с заданной совокупностью критериев поиска и выдачи затребованных данных без изменения содержимого файлов и БД (язык преобразования критериев в систему команд).
В настоящее время функции всех трех языков выполняет язык SQL , относящийся к классу языков, базирующихся на исчислении кортежей ( кортеж чаще всего является единицей информации), языки СУБД FoxPro, Visual Basic for Application ( СУБД Access) и т.д.
Вместе с тем сохранились и языки запросов , например язык запросов по примеру Query By Example ( QBE ) класса исчисления доменов . Отметим, что эти языки в качестве "информационной единицы" БД используют отдельную запись . С помощью языков БД создаются приложения, базы данных и интерфейс пользователя, включающий экранные формы , меню , отчеты. При создании БД на базе СУБД FoxPro эти элементы (объекты) фиксируются в отдельных файлах, которые, в свою очередь , сосредоточиваются в одном файле, называемом проектом. После отработки БД проект преобразуется в приложение . В СУБД Access все созданные объекты размещаются в одном файле.
Читайте также: