
В чем преимущества базовой блочной организации файлов
Обновлено: 06.07.2024
Файловая система позволяет программам обходиться набором достаточно простых операций для выполнения действий над некоторым абстрактным объектом, представляющим файл . При этом программистам не нужно иметь дело с деталями действительного расположения данных на диске, буферизацией данных и другими низкоуровневыми проблемами передачи данных с запоминающего устройства. Все эти функции файловая система берет на себя. Файловая система распределяет дисковую память , поддерживает именование файлов, отображает имена файлов в соответствующие адреса во внешней памяти, обеспечивает доступ к данным, поддерживает разделение, защиту и восстановление данных.
Таким образом, файловая система играет роль промежуточного слоя, экранизирующего все сложности физической организации долговременного хранилища данных и создающего для программ более простую логическую модель этого хранилища, а затем предоставляет им набор удобных в использовании команд для манипулирования файлами.
Классическая схема организации программного обеспечения файловой системы представлена на рис. 7.6.
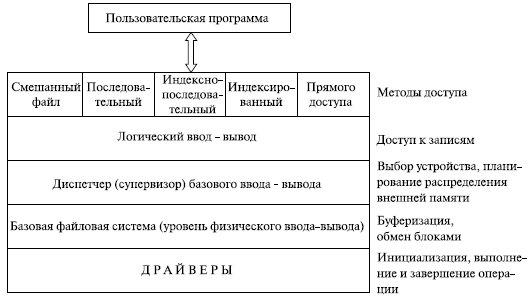
Рис. 7.6. Организация программного обеспечения файловой системы
На нижнем уровне драйверы устройств непосредственно связаны с периферийными устройствами или их котроллерами либо каналами. Драйвер устройства отвечает за начальные операции ввода-вывода устройства и за обработку завершения запроса ввода-вывода. При файловых операциях контролируемыми устройствами являются дисководы и стримеры (накопители на МЛ). Драйверы устройств рассматриваются как часть операционной системы.
Следующий уровень называется базовой файловой системой, или уровнем физического ввода-вывода. Это первичный интерфейс с окружением (периферией) компьютерной системы. Он оперирует блоками данных, которыми обменивается с дисками, магнитной лентой и другими устройствами. Поэтому он связан с размещением и буферизацией блоков в оперативной памяти. На этом уровне не выполняется работа с содержимым блоков данных или структурой файлов. Базовая файловая система обычно рассматривается как часть операционной системы (в MS- DOS эти функции выполняет BIOS , не относящийся к ОС).
Диспетчер базового ввода-вывода отвечает за начало и завершение файлового ввода-вывода. На этом уровне поддерживаются управляющие структуры, связанные с устройством ввода-вывода, планированием и статусом файлов. Диспетчер осуществляет выбор устройства, на котором будет выполняться операция файлового ввода-вывода, планирование обращения к устройству (дискам, лентам), назначение буферов ввода-вывода и распределение внешней памяти. Диспетчер базового ввода-вывода является частью ОС.
Логический ввод- вывод предоставляет приложениям и пользователям доступ к записям. Он обеспечивает возможности общего назначения по вводу-выводу записей и поддерживает информацию о файлах. Наиболее близкий к пользователю уровень ФС часто называется методом доступа. Он обеспечивает стандартный интерфейс между приложениями и файловыми системами и устройствами, содержащими данные. Различные методы доступа отражают различные структуры файлов и различные пути доступа и обработки данных.
7.13. Организация файлов и доступ к ним
Типы, именование и атрибуты файлов
Файловые системы поддерживают несколько функционально различных типов файлов, в число которых входят обычные файлы, содержащие информацию произвольного характера (текст, графика , звук и др.), файлы-каталоги, специальные файлы, именованные конвейеры, отображаемые в память файлы и др.
Обычные файлы, или просто файлы, или регулярные файлы, содержат информацию, которую в них заносит пользователь или которая образуется в результате работы системных и пользовательских программ. Большинство ОС не контролируют содержимое и структуру регулярных файлов , которые в основном являются ASCII-файлами либо двоичными файлами. ASCII-фалы состоят из текстовых строк. Они могут отображаться на экране и выводиться на печать без какого-либо преобразования, и могут редактироваться практически любым текстовым редактором. Двоичные файлы имеют определенную внутреннюю структуру, которая известна программе, использующей данный файл . При выводе двоичного файла на принтер получается случайный набор символов.
Каталоги – это системные файлы, обеспечивающие поддержку структуры файловой системы. Они содержат системную справочную информацию о наборе файлов, сгруппированных пользователем по какому-либо неформальному признаку (договоры, рефераты, курсовые проекты и т.п.). Во многих ОС в каталог могут входить другие файлы, в том числе другие каталоги, за счет чего образуется древовидная структура, удобная для поиска требуемого файла. Каталоги устанавливают соответствие между именами файлов и их характеристиками, используемыми файловой системой для управления файлами. В число таких характеристик входят тип файла , права доступа к файлу, его распоряжение на диске, размер, дата и время создания и др.
Специальные файлы – это фиктивные файлы, ассоциированные с устройствами ввода-вывода, которые используются для унификации механизма доступа к последовательным устройствам ввода-вывода, таким как терминалы, принтеры и др. (например, MS- DOS рассматривает монитор и клавиатуру как файлы со стандартным именем con – консоль , а принтер – как файл prn ). Блочные специальные файлы используются для моделирования дисков.
Именованные конвейеры (каналы) представляют собой циклические буферы, позволяющие выходной файл одной программы соединить со входным файлом другой программы.
Наконец, отображаемые файлы – это обычные файлы, отображенные на адресное пространство процесса по указанному виртуальному адресу.
Файлы относятся к абстрактному механизму. Они предоставляют способ сохранять информацию на запоминающем устройстве и считывать ее позднее снова. При этом от пользователя должны скрываться такие детали, как способ и место хранения информации, а также детали работы устройства.
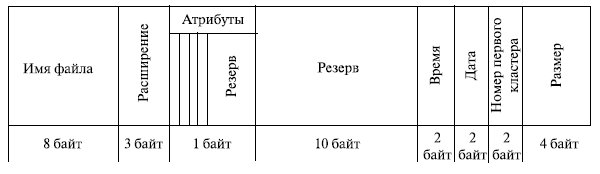
Во многих операционных системах имя файла состоит из двух частей, разделенных точкой. Часть имени после точки называется расширением файла и обычно означает его тип. Так, в MS- DOS имя файла может содержать от 1 до 8 символов, а расширение от 0 (отсутствует) до 3.
В некоторых ОС, например, Windows , расширение указывает на программу, создавшую файл . Другие ОС, например, UNIX , не принуждают пользователя строго придерживаться расширений. Некоторые типичные расширения файлов приведены ниже.
В иерархически организованных файловых системах обычно используются три типа имен файлов: простые, составные и относительные.
Простое (короткое) символьное имя идентифицирует файл в пределах одного каталога. Несколько файлов могут иметь одно и то же простое имя , если они принадлежат разным каталогам.
Составное (полное) символьное имя представляет собой цепочку, содержащую имя диска и имена всех каталогов, через которые проходит путь от корневого каталога до данного файла.
Относительное имя файла определяется через текущий каталог , т.е. каталог, в котором в данный момент времени работает пользователь . Таким образом, относительных имен у файла может быть достаточно много, и все они являются частью полного имени.
Понятие файла включает не только хранимые им данные и имя, но и информацию, описывающую свойства файла. Эта информация составляет атрибуты файла. Список атрибутов может быть различным в различных ОС. Пример возможных атрибутов приведен ниже.
Пользователь может получить доступ к атрибутам, используя средства, предоставляемые для этой цели файловой системой. Обычно разрешается читать значение любых атрибутов, а изменять – только некоторые.
Значения атрибутов файлов могут содержаться в каталогах, как это сделано, например, в MS- DOS (рис. 7.7). Другим вариантом является размещение атрибутов в специальных таблицах, в этом случае в каталогах содержатся ссылки на эти таблицы.
Логическая организация файла
В общем случае данные, содержащиеся в файле, имеют некоторую логическую структуру. Эта структура (организация) файла является базой при разработке программы, предназначенной для обработки этих данных. Поддержание структуры данных может быть целиком возложено на приложение либо в той или иной степени эту работу может взять на себя файловая система .
В первом случае, когда все действия, связанные со структуризацией и интерпретацией содержимого файла, целиком относятся к ведению приложения, файл представляется файловой системе неструктурированной последовательностью данных. Приложение формирует запросы к файловой системе на ввод- вывод , используя общие для всех приложений системные средства, например, указывая смещение от начала файла и количество байт , которые необходимо считать или записать. Поступивший к приложению поток байт интерпретируется в соответствии с заложенной в программе логикой. Следует подчеркнуть, что интерпретация данных никак не связана с действительным способом их хранения в файловой системе.
Модель файла, в соответствии с которой содержимое файла представляется неструктурированной последовательностью байт , стала популярной вместе с ОС UNIX , и теперь широко используется в современных ОС. Неструктурированная модель файла позволяет легко организовать разделение файла между несколькими приложениями, поскольку разные приложения могут по -своему структурировать и интерпретировать данные, содержащиеся в файле.
Другая модель файла – структурированный файл . В этом случае поддержание структуры файла поручается файловой системе. Файловая система видит файл как упорядоченную последовательность логических записей. ФС предоставляет приложению доступ к записи, а вся дальнейшая обработка данных, содержащихся в этой записи, выполняется приложением!
Известно пять фундаментальных способов организации файлов [10]:
- смешанный файл,
- последовательный файл ,
- индексно- последовательный файл ,
- индексируемый файл,
- файл прямого доступа.
При выборе способа организации файла нужно учитывать несколько критериев:
- быстрота доступа,
- легкость обновления,
- экономность хранения,
- простота обслуживания,
- надежность.
Смешанный файл . Это наименее сложная форма организации файла. Данные накапливаются в порядке поступления. Запись состоит из одного пакета данных. Записи могут иметь различные или одинаковые поля, расположенные в различном порядке (рис. 7.8). Каждое поле описывает само себя, включая как имя, так и значение . Длина каждого поля должна быть указана явно либо посредством применения разделителя.

Поскольку смешанный файл не имеет никакой структуры, доступ к записи осуществляется полным перебором всех записей файла. Смешанные файлы применяются в том случае, когда данные накапливаются и сохраняются перед обработкой, или если данные неудобны для организации. Файлы этого типа рационально используют дисковое пространство , хорошо подходят для полного набора. Обновление записей достаточно сложно, так же как и вставка записи.
Последовательный файл . Для записей используется фиксированный формат. Все записи имеют одинаковую длину (но иногда и не одинаковую) и состоят из одинакового количества полей фиксированной длины, организованных в определенном порядке (рис. 7.9). Поскольку длина и позиция каждого поля известны, сохранению подлежат только значения полей. Атрибутами файловой структуры является имя и длина каждого поля.
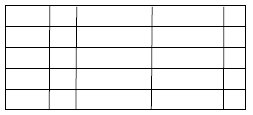
Одно определенное поле (или несколько полей) называется ключевым. Оно однозначно идентифицирует запись , так как это поле различно для каждой записи. Более того, записи сохраняются в "ключевой" последовательности: в алфавитном порядке для текстового ключа и в числовом – для числового. Последовательные файлы часто используются пакетными приложениями и обычно являются оптимальным вариантом, если эти приложения выполняют обработку всех записей. Удобно и то, что такой файл можно хранить как на ленте, так и на магнитном диске.
Для диалоговых приложений последовательный файл малоэффективен, поскольку для нахождения нужной записи требуется последовательный перебор записи файла. Правда, если в оперативную память загрузить весь файл , возможен более эффективный метод поиска. Дополнения к файлу или изменения в записях создают проблемы.
Обычно последовательный файл сохраняется с последовательной организацией записей внутри блока, т.е. физическая организация файла в точности соответствует логической. Новые записи размещаются в отдельном смешанном файле, называемом журнальным файлом, или файлом транзакции. Периодически в пакетном режиме выполняется слияние основного и журнального файлов в новый файл с корректной последовательностью ключей.
Альтернативной организацией может быть физическая организация в виде списка с использованием указателей. В каждом физическом блоке сохраняется одна или несколько записей, и каждый блок содержит указатель на следующий блок. Для вставки новых записей достаточно изменить указатели, и нет необходимости в том, чтобы новые записи занимали определенную физическую позицию. Это удобство достигается за счет определенных накладных расходов и дополнительной работы. Если в последовательном файле записи имеют одну и ту же длину, то можно вычислить адрес требуемой записи по ее номеру, номеру текущей записи и длине записи. Если записи имеют переменную длину, такой подход невозможен.
Индексно- последовательный файл . Одним из методов преодоления недостатков последовательного файла является индексно-последовательная организация файла. В этом случае файл состоит из трех частей (файлов): главный файл , содержащий записи с последовательно идущими ключами, индексный файл , содержащий индексное поле , и указатель в главный с ключами, файл переполнения (рис. 7.10).
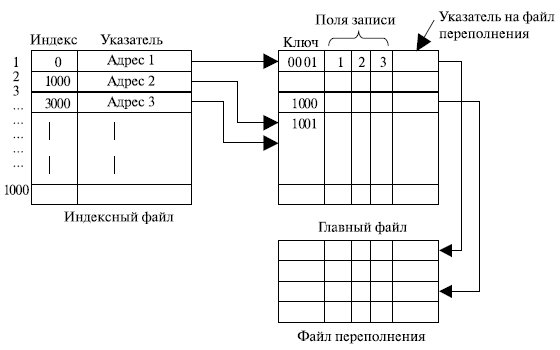
Для поиска нужной записи по ее ключу сначала выполняется поиск в индексном файле. После того как в нем найдено наибольшее значение ключа, которое не превышает искомое, продолжается поиск в главном файле. Например, пусть последовательный файл (главный) содержит 1 млн записей. Для поиска определенного ключевого значения необходимо в среднем 0,5 млн операций доступа к записям. Если создать индексный файл , содержащий 1000 элементов, то потребуется в среднем 500 операций доступа к индексному файлу, после чего еще нужно в среднем 500 операций доступа к главному файлу. В результате средняя длина поиска уменьшилась с 0,5 млн до 1000. Еще лучшего результата можно достичь, используя многоуровневую индексацию. При этом нижний уровень индексного файла рассматривается как последовательный файл , для которого создается индексный файл верхнего уровня.
Дополнения к файлу обрабатываются следующим образом. В каждой записи главного файла содержится дополнительное поле , невидимое для приложения и являющееся указателем на файл переполнения. Если в файле производится вставка новой записи, она добавляется в файл переполнения. Запись в главном файле, непосредственно предшествующая новой записи в логической последовательности, обновляется и указывает на новую запись в файле переполнения. Время от времени выполняется слияние индексно- последовательного файла с файлом переполнения.
Индексированный файл . Индексно- последовательный файл сохраняет одно ограничение последовательного файла : эффективная работа с файлом ограничена работой с ключевым полем. Если необходимо производить поиск записи по какой-либо иной характеристике, отличной от ключевого поля, то оказываются непригодными обе организации последовательного файла , в то время как в некоторых приложениях эта гибкость крайне желательна.
Для достижения гибкости необходимо применение большого количества индексов, по одному для каждого типа поля, которое может быть объектом поиска. В обобщенном индексированном файле доступ к записям осуществляется только по их индексам. В результате в размещении записей нет никаких ограничений до тех пор, пока указатель по крайней мере в одном индексе ссылается на эту запись . Кроме того, в таком файле легко реализуются записи переменной длины.
Используется два типа индексов. Полный индекс содержит по одному элементу для каждого типа записей главного файла. Сам по себе индекс организовывается в виде последовательного файла для облегчения поиска. Частный индекс содержит элементы для записей, в которых имеется интересующее пользователя поле . При добавлении новой записи в главный файл необходимо обновлять все индексные файлы.
Индексированные файлы применяются теми приложениями, в которых время доступа к информации является критической характеристикой и редко требуется обработка всех записей в файле.
Файл прямого доступа. Такой файл использует возможность прямого доступа к блоку с известным адресом при хранении файлов на диске. В каждой записи в этом случае также имеется ключевое поле .
Существует три основных способа организации систем хранения данных (СХД) в корпоративных ИТ-системах и в системах облачных провайдеров:
- Блочные системы (Block Storage). (File Storage). (Object Storage).

Блочные системы называются так потому, что хранимые в них данные разбиваются на блоки одинакового размера. Блок данных – это не файл, не законченный объект, а просто некие данные в куске фиксированного размера (по-английски – chunk). Файл данных может быть размещен в конечном числе блоков, и если последний из этих блоков остается незаполненным, то он все равно будет иметь тот же фиксированный размер, что и заполненные блоки. Сервер получает доступ к этим блокам через сеть хранения данных SAN (storage attached network).
Блочная СХД может быть использована любой операционной системой как дисковый том этой системы. Каждому серверу может быть предоставлен практически неограниченный размер диска. Пользователь видит этот диск в интерфейсе операционной системы сервера. ОС сервера может подключаться к блокам данных через высокоскоростные интерфейсы FC (Fiber Channel) или iSCSI. Поэтому основное достоинство блочных систем – высокое быстродействие.
Операционная система сервера может быть как физической (хост), так и виртуальной (виртуальная машина). Следует отметить, что физическим серверам нужны дополнительные контроллеры для того, чтобы получать доступ к исходным блокам.
Размер блоков определяется производителем оборудования. Однако архитектор, разрабатывающий дизайн корпоративной ИТ-системы, может определять размер блока данных в зависимости от требований конфигурации и сценария применения. Размер блока может зависеть и от типа физических дисков в системах хранения (жесткие диски HDD или флеш-накопители SSD), а также от типа самих данных клиентов. Правильный выбор размера диска во многих случаях помогает оптимизировать параметры работы корпоративной ИТ-системы в целом.
Операционная система сервера присваивает каждому блоку данных простой идентификатор расположения (location ID), по которому его можно быстро найти в SAN, именно поэтому блочная СХД имеет высокое быстродействие.
Заметим, что, например, в объектных системах хранения в качестве такого идентификатора используются метаданные (тип файла, название файла, дата и пр). Понятно, что при таком механизме время поиска объекта в системе увеличивается, хотя объектные системы хранения имеют много преимуществ для других ситуаций.
Когда нужны блочные системы
Обычно блочные системы хранения выбирают, когда при проектировании ИТ-системы критичными являются такие параметры, как скорость ввода-вывода данных IOPS (input output operations per second), а также задержка (latency) доступа к данным через SAN. Например, это могут быть серверы баз данных или бизнес-критичных приложений, требующих высокого быстродействия и высокой надежности.
В таких базах данных, как Oracle или SAP Hana, используются именно блочные системы. Виртуальные машины VMware также по умолчанию используют блочное хранение, поскольку при этом можно построить быстродействующую и многофункциональную виртуальную инфраструктуру. Блочное хранение может быть также использовано практически во всех архитектурах ЦОД, будь то единичный сервер или же высоконадежные кластерные серверные решения.
Блочные системы хранения в настоящий момент являются безусловным лидером по доле в корпоративном хранении данных как в малых предприятиях, так и в ИТ-системах крупных корпораций.
Наиболее употребительные области применения блочных СХД:
- Бизнес-приложения и СУБД (сервер баз данных SQL), корпоративные системы CRM/ERP, такие как серверы1С, SAP, Navision и другие.
- Хранение данных компаний интернет-коммерции, различных госорганов и пр.
- Различные системы виртуализации: рабочих мест, сетевых функций, контейнерные технологии и пр.
- Хранение «сырых» данных, получаемых от систем «Интернета вещей» (IoT).
Блочное хранение в облаке
Блочное хранение данных – очень популярная услуга облачных провайдеров. Она дает возможность использовать такое полезное качество, как эластичность. То есть пользователю нет необходимости закупать оборудование для СХД с «запасом на будущее». Он может заказать у провайдера емкость хранения в соответствии с текущими потребностями и потом быстро «дозаказать» ее при необходимости. В большинстве случаев этот процесс может занять несколько минут. При этом данные будут хорошо защищены высокой доступностью услуги облачного хранения и технологией репликации в облаке. Кроме того, шифрование, которое обеспечивает облачный провайдер, не позволит другим серверам, использующим ту же облачную СХД, получить доступ к чужим данных. Таким образом, когда нужно быстро и недорого расширить имеющееся блочное хранилище, использование услуги блочной СХД в облаке может быть оптимальным вариантом.
Если говорить не о публичном, а о частном облаке ИТ-системы или дата-центра (центров) крупной организации, то и здесь можно использовать сходные механизмы блочного хранения. При этом вместо разных заказчиков, данные которых нужно разделять в облаке, будут выступать подразделения (отделы, сервисы, филиалы) этой организации. И здесь использование блочного хранения чаще всего будет предпочтительным вариантом, поскольку эта технология обеспечивает высокую скорость бизнес-процессов организации, а также достаточную гибкость перераспределения ресурсов в масштабах организации.
Достоинства и недостатки блочной СХД
В современных ЦОДах блочное хранение очень распространено вследствие следующих достоинств:
- Производительность: быстродействие блочной CХД. Для приложений, требующих высоких скоростей ввода-вывода (IOPS), таких как серверы баз данных, блочная СХД является оптимальным выбором. Производительность вкупе с низкой задержкой доступа является главным преимуществом блочной СХД.
- Гибкость: тома с блоками данных можно быстро переносить, расширять и добавлять по мере роста организации, без какого-либо влияния на быстродействие. Кроме того, блочную СХД можно легко переносить с одного сервера на другой путем простого редактирования маршрута назначения.
- Легкость модификации файлов: в блочной СХД при изменении файла необходимо изменять только те блоки, которые затронуты этими изменениями. В файловой и объектной СХД для этого необходимо перезаписывать весь файл или объект.
- Загружаемость операционной системы: ОС может загружаться непосредственно из блочной СХД через SAN. Для этого нужно, чтобы BIOS сервера (физического или виртуального) могла работать с SAN.
- Работа с разрешениями: легкость управления доступом к данным.
Недостатки у блочной СХД тоже есть. К ним можно отнести следующее:
- Привязка к серверу: блочная СХД жестко привязана к одному серверу в каждый момент времени и не может в этот момент разрешать доступ от другого сервера в ИТ-системе. Конечно, есть некоторые программные решения, которые могут устранить данный недостаток, но это требует повышения нагрузки (overhead) на файловую систему.
- Ограниченность метаданных: объем метаданных (определяющих, что именно хранится) гораздо меньше, чем в файловой или объектной СХД. Это может повлиять на производительность работы некоторых приложений, критичных к использованию метаданных.
- Стоимость: она в блочных СХД достаточно высока. Хотя для заказчиков сервисов облачная услуга блочного хранения весьма доступна по стоимости, однако для облачных провайдеров и для корпоративных ИТ-систем это очень затратно, поскольку системы SAN довольно дороги и часто требуют наличия высококвалифицированного персонала для их обслуживания. Кроме того, со стороны заказчиков облачных услуг всегда необходима оплата объема блочного СХД, даже если используется не весь объем.
Итоги сравнения блочных СХД с файловыми и объектными можно свести в следующую таблицу:
Блочные
Файловые
Объектные
Интерфейс
Операционная система
Программа через API
Относительная стоимость
Высокая
Быстродействие
Очень высокое
Ареал применения
Часть ИТ-системы, охват FC/iSCSI
Вся ИТ-система, LAN
Сценарии
ОС, базы данных
Общий пользовательский контент, веб-контент
Медиафайлы, сети доставки контента
Масштабируемость
Ограничена ареалом применения
Все ведущие мировые производители предлагают своим заказчикам широкие линейки блочных систем хранения, которые очень условно можно разделить на 4 группы:
Международный рынок гипермасштабируемых дата-центров растет с ежегодными темпами в 11%. Основные «драйверы» — предприятия, подключенные устройства и пользователи — они обеспечивают постоянное появление новых данных. Вместе с объемом рынка растут и требования к надежности хранения и уровню доступности данных.
Ключевой фактор, влияющий на оба критерия — системы хранения. Их классификация не ограничивается типами оборудования или брендами. В этой статье мы рассмотрим разновидности хранилищ — блочное, файловое и объектное — и определим, для каких целей подходит каждое из них.

/ Flickr / Jason Baker / CC
Типы хранилищ и их различия
Хранение на уровне блоков лежит в основе работы традиционного жесткого диска или магнитной ленты. Файлы разбиваются на «кусочки» одинакового размера, каждый с собственным адресом, но без метаданных. Пример — ситуация, когда драйвер HDD пишет и считывает блоки по адресам на отформатированном диске. Такие СХД используются многими приложениями, например, большинством реляционных СУБД, в списке которых Oracle, DB2 и др. В сетях доступ к блочным хостам организуется за счет SAN с помощью протоколов Fibre Channel, iSCSI или AoE.
Файловая система — это промежуточное звено между блочной системой хранения и вводом-выводом приложений. Наиболее распространенным примером хранилища файлового типа является NAS. Здесь, данные хранятся как файлы и папки, собранные в иерархическую структуру, и доступны через клиентские интерфейсы по имени, названию каталога и др.

/ Wikimedia / Mennis / CC
При этом следует отметить, что разделение «SAN — это только сетевые диски, а NAS — сетевая файловая система» искусственно. Когда появился протокол iSCSI, граница между ними начала размываться. Например, в начале нулевых компания NetApp стала предоставлять iSCSI на своих NAS, а EMC — «ставить» NAS-шлюзы на SAN-массивы. Это делалось для повышения удобства использования систем.
Что касается объектных хранилищ, то они отличаются от файловых и блочных отсутствием файловой системы. Древовидную структуру файлового хранилища здесь заменяет плоское адресное пространство. Никакой иерархии — просто объекты с уникальными идентификаторами, позволяющими пользователю или клиенту извлекать данные.
Марк Горос (Mark Goros), генеральный директор и соучредитель Carnigo, сравнивает такой способ организации со службой парковки, предполагающей выдачу автомобиля. Вы просто оставляете свою машину парковщику, который увозит её на стояночное место. Когда вы приходите забирать транспорт, то просто показываете талон — вам возвращают автомобиль. Вы не знаете, на каком парковочном месте он стоял.
Большинство объектных хранилищ позволяют прикреплять метаданные к объектам и агрегировать их в контейнеры. Таким образом, каждый объект в системе состоит из трех элементов: данных, метаданных и уникального идентификатора — присвоенного адреса. При этом объектное хранилище, в отличие от блочного, не ограничивает метаданные атрибутами файлов — здесь их можно настраивать.

/ 1cloud
Применимость систем хранения разных типов
Блочные хранилища
Блочные хранилища обладают набором инструментов, которые обеспечивают повышенную производительность: хост-адаптер шины разгружает процессор и освобождает его ресурсы для выполнения других задач. Поэтому блочные системы хранения часто используются для виртуализации. Также хорошо подходят для работы с базами данных.
Недостатками блочного хранилища являются высокая стоимость и сложность в управлении. Еще один минус блочных хранилищ (который относится и к файловым, о которых далее) — ограниченный объем метаданных. Любую дополнительную информацию приходится обрабатывать на уровне приложений и баз данных.
Файловые хранилища
Среди плюсов файловых хранилищ выделяют простоту. Файлу присваивается имя, он получает метаданные, а затем «находит» себе место в каталогах и подкаталогах. Файловые хранилища обычно дешевле по сравнению с блочными системами, а иерархическая топология удобна при обработке небольших объемов данных. Поэтому с их помощью организуются системы совместного использования файлов и системы локального архивирования.
Пожалуй, основной недостаток файлового хранилища — его «ограниченность». Трудности возникают по мере накопления большого количества данных — находить нужную информацию в куче папок и вложений становится трудно. По этой причине файловые системы не используются в дата-центрах, где важна скорость.
Объектные хранилища
Что касается объектных хранилищ, то они хорошо масштабируются, поэтому способны работать с петабайтами информации. По статистике, объем неструктурированных данных во всем мире достигнет 44 зеттабайт к 2020 году — это в 10 раз больше, чем было в 2013. Объектные хранилища, благодаря своей возможности работать с растущими объемами данных, стали стандартом для большинства из самых популярных сервисов в облаке: от Facebook до DropBox.
Такие хранилища, как Haystack Facebook, ежедневно пополняются 350 млн фотографий и хранят 240 млрд медиафайлов. Общий объем этих данных оценивается в 357 петабайт.
Хранение копий данных — это другая функция, с которой хорошо справляются объектные хранилища. По данным исследований, 70% информации лежит в архиве и редко изменяется. Например, такой информацией могут выступать резервные копии системы, необходимые для аварийного восстановления.
Но недостаточно просто хранить неструктурированные данные, иногда их нужно интерпретировать и организовывать. Файловые системы имеют ограничения в этом плане: управление метаданными, иерархией, резервным копированием — все это становится препятствием. Объектные хранилища оснащены внутренними механизмами для проверки корректности файлов и другими функциями, обеспечивающими доступность данных.
Плоское адресное пространство также выступает преимуществом объектных хранилищ — данные, расположенные на локальном или облачном сервере, извлекаются одинаково просто. Поэтому такие хранилища часто применяются для работы с Big Data и медиа. Например, их используют Netflix и Spotify. Кстати, возможности объектного хранилища сейчас доступны и в сервисе 1cloud.
После отправки к файлу добавляются необходимые метаданные. Для этого есть такой запрос:
Богатая метаинформация объектов позволит оптимизировать процесс хранения и минимизировать затраты на него. Эти достоинства — масштабируемость, расширяемость метаданных, высокая скорость доступа к информации — делают объектные системы хранения оптимальным выбором для облачных приложений.
Однако важно помнить, что для некоторых операций, например, работы с транзакционными рабочими нагрузками, эффективность решения уступает блочным хранилищам. А его интеграция может потребовать изменения логики приложения и рабочих процессов.
Историческим шагом стал переход к использованию систем управления файлами. С точки зрения прикладной программы файл – это именованная область внешней памяти, в которую можно записывать и из которой можно считывать данные. Правила именования файлов, способ доступа к данным, хранящимся в файле, и структура этих данных зависят от конкретной системы управления файлами и, возможно, от типа файла. Система управления файлами берет на себя распределение внешней памяти, отображение имен файлов в соответствующие адреса внешней памяти и обеспечение доступа к данным.
В этом разделе мы рассмотрим историю файловых систем, их основные черты и области разумного применения. Однако сначала сделаем два замечания. Во-первых, в области управления файлами исторически существует некоторая терминологическая путаница. Термин файловая система (file system) используется для обозначения программной системы, управляющей файлами, и архива файлов, хранящегося во внешней памяти. Было бы лучше в первом случае использовать термин система управления файлами, оставив за термином файловая система только второе значение. Однако принятая практика заставляет нас использовать термин файловая система в обоих смыслах. Будем надеяться, что точный смысл термина будет понятен из контекста. (Заметим, что среди непрофессионалов аналогичная путаница возникает при использовании терминов база данных и система управления базами данных. В этом курсе мы будем строго разделять эти термины.) Во-вторых, мы ограничимся описанием свойств так называемых традиционных файловых систем, не обсуждая особенности современных систем с повышенной надежностью, поскольку это заставило бы нас сильно отклониться от основной темы курса.
Первая развитая файловая система была разработана специалистами IBM в середине 60-х гг. для выпускавшейся компанией серии компьютеров «360». В этой системе поддерживались как чисто последовательные, так и индексно-последовательные файлы, а реализация во многом опиралась на возможности только появившихся к этому времени контроллеров управления дисковыми устройствами. Контроллеры обеспечивали возможность обмена с дисковыми устройствами порциями данных произвольного размера, а также индексный доступ к записям файлов, и эти функции контроллеров активно использовались в файловой системе ОS/360.
Файловая система ОS/360 обеспечила будущих разработчиков уникальным опытом использования дисковых устройств с подвижными головками, который отражается во всех современных файловых системах.
1.3.1. Структуры файлов
Практически во всех современных компьютерах основными устройствами внешней памяти являются магнитные диски с подвижными головками, и именно они служат для хранения файлов. Как отмечалось ранее, аппаратура магнитных дисков допускает выполнение обмена с дисками порциями данных произвольного размера. Однако возможность обмениваться с магнитными дисками порциями, размеры которых меньше полного объема блока, в настоящее время в файловых системах не используется. Это связано с двумя обстоятельствами.
Во-первых, как указывалось в разделе 1.2 «Устройства внешней памяти», считывание или запись только части блока не приводит к существенному выигрышу в суммарном времени обмена. Во-вторых, для работы с частями блоков файловая система должна обеспечить буферы оперативной памяти соответствующего размера, что существенно усложняет распределение оперативной памяти. Алгоритмы распределения памяти порциями произвольного размера плохи тем, что любой из них рано или поздно приводит к внешней фрагментации памяти. В памяти образуется большое число маленьких свободных фрагментов. Их совокупный размер может быть больше размера любого требуемого буфера, но его можно выделить, только если произвести сжатие памяти, т. е. подвижку всех занятых фрагментов таким образом, чтобы они располагались вплотную один к другому. Во время выполнения операции сжатия памяти нужно приостановить выполнение обменов, а сама эта операция занимает много времени.
Поэтому во всех современных файловых системах явно или неявно выделяется уровень, обеспечивающий работу с базовыми файлами, которые представляют собой наборы блоков, последовательно нумеруемых в адресном пространстве файла и отображаемых на физические блоки диска (рис. 1.2). Размер логического блока файла совпадает с размером физического блока диска или кратен ему; обычно размер логического блока выбирается равным размеру страницы виртуальной памяти, поддерживаемой аппаратурой компьютера совместно с операционной системой.
В некоторых файловых системах базовый уровень был доступен пользователю, но чаще он прикрывался некоторым более высоким уровнем, стандартным для пользователей. Существуют два основных подхода. При первом подходе, свойственном, например, файловым системам операционных систем компании DEC RSX и VMS, пользователи представляют файл как последовательность записей. Каждая запись – это последовательность байтов, имеющая постоянный или переменный размер. Можно читать или писать записи последовательно либо позиционировать файл на запись с указанным номером. Некоторые файловые системы позволяют структурировать записи на поля и объявлять некие поля ключами записи.
Рис. 1.2. Схематичное изображение базового файла
В таких файловых системах можно потребовать выборку записи из файла по ее заданному ключу. Естественно, в этом случае файловая система поддерживает в том же (или другом, служебном) базовом файле дополнительные, невидимые пользователю, служебные структуры данных. Распространенные способы организации ключевых файлов основываются на технике хэширования и B-деревьев. Существуют и многоключевые способы организации файлов (у одного файла объявляется несколько ключей, и можно выбирать записи по значению каждого ключа).
Второй подход, получивший распространение вместе с операционной системой UNIX, состоит в том, что любой файл представляется как непрерывная последовательность байтов. Из файла можно прочитать указанное число байтов, либо начиная с его начала, либо предварительно выполнив его позиционирование на байт с указанным номером. Аналогично можно записать указанное число байтов либо в конец файла, либо предварительно выполнив позиционирование файла. Тем не менее заметим, что скрытым от пользователя, но существующим во всех разновидностях файловых систем ОС UNIX является базовое блочное представление файла.
Конечно, в обоих случаях можно обеспечить набор преобразующих функций, приводящих представление файла к другому виду. Примером тому может служить поддержка стандартной файловой среды UNIX в среде операционных систем компании DEC.
1.3.2. Логическая структура файловых систем и именование файлов
Во всех современных файловых системах обеспечивается многоуровневое именование файлов за счет наличия во внешней памяти каталогов – дополнительных файлов со специальной структурой. Каждый каталог содержит имена каталогов и/или файлов, хранящихся в данном каталоге. Таким образом, полное имя файла состоит из списка имен каталогов плюс имя файла в каталоге, непосредственно содержащем данный файл.
Поддержка многоуровневой схемы именования файлов обеспечивает несколько преимуществ, основным из которых является простая и удобная схема логической классификации файлов и генерации их имен. Можно сопоставить каталог или цепочку каталогов с пользователем, подразделением, проектом и т. д. и затем образовывать в этом каталоге файлы или каталоги, не опасаясь коллизий с именами других файлов или каталогов.
Разница между способами именования файлов в разных файловых системах состоит в том, с чего начинается эта цепочка имен. В любом случае первое имя должно соответствовать корневому каталогу файловой системы. Вопрос заключается в том, как сопоставить этому имени корневой каталог – где его искать? В связи с этим имеются два радикально различных подхода.
Во многих системах управления файлами требуется, чтобы каждый архив файлов (полное дерево каталогов) целиком располагался на одном дисковом пакете или логическом диске – разделе физического дискового пакета, логически представляемом в виде отдельного диска с помощью средств операционной системы. В этом случае полное имя файла начинается с имени дискового устройства, на котором установлен соответствующий диск. Такой способ именования использовался в файловых системах компаний IBM и DEC; очень близки к этому и файловые системы, реализованные в операционных системах семейства Windows компании Microsoft. Можно назвать такую организацию поддержкой изолированных файловых систем.
Другой крайний вариант был реализован в файловых системах операционной системы Multics [3.2]. Эта система заслуживает отдельного разговора, в ней был реализован целый ряд оригинальных идей, но мы остановимся только на особенностях организации архива файлов. В файловой системе Multics пользователям обеспечивалась возможность представлять всю совокупность каталогов и файлов в виде единого дерева. Полное имя файла начиналось с имени корневого каталога, и пользователь не обязан был заботиться об установке на дисковое устройство каких-либо конкретных дисков. Сама система, выполняя поиск файла по его имени, запрашивала у оператора установку необходимых дисков. Такую файловую систему можно назвать полностью централизованной.
Конечно, во многом централизованные файловые системы удобнее изолированных: система управления файлами выполняет больше рутинной работы. В частности, администратор файловой системы автоматически оповещается о потребности установки требуемых дисковых пакетов; система обеспечивает равномерное распределение памяти на известных ей дисковых томах; возможна организация автоматического перемещения редко используемых файлов на более медленные носители внешней памяти; облегчается рутинная работа, связанная с резервным копированием.
Но в таких системах возникают существенные проблемы, если требуется перенести поддерево файловой системы на другую вычислительную установку. Поскольку файлы и каталоги любого логического поддерева могут быть физически разбросаны по разным дисковым пакетам и даже магнитным лентам, для такого переноса требуется специальная утилита, собирающая все объекты требуемого поддерева на одном внешнем носителе, не входящем в состав штатных устройств централизованной файловой системы. Конечно, даже при наличии такой утилиты выполнение процедуры физической сборки требует существенного времени.
Компромиссное решение применяется в файловых системах ОС UNIX [3.1]. На базовом уровне в этих файловых системах поддерживаются изолированные архивы файлов. Один из таких архивов объявляется корневой файловой системой. Это делается на этапе генерации операционной системы, и после запуска операционная система «знает», на каком дисковом устройстве (физическом или логическом) располагается корневая файловая система. После запуска системы можно «смонтировать» корневую файловую систему и ряд изолированных файловых систем в одну общую файловую систему. Технически это осуществляется посредством создания в корневой файловой системе специальных пустых каталогов (точек монтирования).
Специальный системный вызов mount ОС UNIX позволяет подключить к одному из пустых каталогов корневой каталог указанного архива файлов. Выполнение такого действия приводит к «наложению» корневого каталога монтируемой файловой системы на каталог точки монтирования; корневой каталог приобретает имя каталога точки монтирования. После монтирования общей файловой системы именование файлов производится так же, как если бы она с самого начала была централизованной. Если учесть, что обычно монтирование файловой системы производится при раскрутке системы (при выполнении стартового командного файла), пользователи ОС UNIX, как правило, и не задумываются о происхождении общей файловой системы.
Кроме того, поддерживается системный вызов unmount , «отторгающий» ранее смонтированную файловую систему от общей иерархии. Конечно, все это заметно облегчает перенос частей файловой системы на другие установки.
1.3.3. Авторизация доступа к файлам
1.3.4. Синхронизация многопользовательского доступа
Последнее, на чем мы остановимся в связи с файлами, – это способы применения файлов в многопользовательской среде. Если операционная система поддерживает многопользовательский режим, может возникнуть ситуация, когда два или более пользователей одновременно пытаются работать с одним и тем же файлом. Если все эти пользователи собираются только читать файл, ничего страшного не произойдет. Но если хотя бы один из них будет изменять файл, для корректной работы этой группы требуется взаимная синхронизация.
В файловых системах обычно применялся следующий подход. В операции открытия файла (первой и обязательной операции, с которой должен начинаться сеанс работы с файлом) помимо прочих параметров указывался режим работы (чтение или изменение). Если к моменту выполнения этой операции от имени некоторого процесса A файл уже был открыт некоторым другим процессом B, причем существующий режим открытия был несовместим с требуемым режимом (совместимы только режимы чтения), то в зависимости от особенностей системы либо процессу A сообщалось о невозможности открытия файла в нужном режиме, либо процесс A блокировался до тех пор, пока процесс B не выполнит операцию закрытия файла.
1.3.5. Области разумного применения файлов
После краткого экскурса в историю и современное состояние файловых систем обсудим возможные области их применения. Прежде всего, конечно, файлы используются для хранения текстовых данных: документов, текстов программ и т. д. Такие файлы обычно создаются и модифицируются с помощью различных текстовых редакторов. Эти редакторы могут быть очень простыми, такими, как ed в мире UNIX или утилиты редактирования Norton Commander, FAR Manager и других интерактивных сред Windows. Они могут быть сложными и многофункциональными, синтаксически ориентированными, как, например, GNU Emacs. Но обычно структура текстовых файлов очень проста (c точки зрения файловой системы): это либо последовательность записей, содержащих строки текста, либо последовательность байтов, среди которых встречаются специальные символы (например, символы конца строки). Конечно же, сложность логической структуры текстового файла определяется текстовым редактором, но в любом случае файловой системе она не видна.
Файлы, содержащие тексты программ, используются как входные файлы компиляторов (чтобы правильно воспринять текст программы, компилятор должен понимать логическую структуру текстового файла), которые, в свою очередь, формируют файлы, содержащие объектные модули. С точки зрения файловой системы объектные файлы также обладают очень простой структурой – последовательность записей или байтов. Система программирования накладывает на такую структуру более сложную и специфичную для этой системы структуру объектного модуля. Подчеркнем, что логическая структура объектного модуля файловой системе неизвестна; эта структура поддерживается инструментами системы программирования.
Аналогично обстоит дело с файлами, формируемыми редакторами связей (редактор связей должен понимать логическую структуру файлов объектных модулей) и содержащими образы выполняемых программ. Логическая структура таких файлов остается известной только редактору связей и загрузчику – программе операционной системы. Общая схема взаимодействия программных компонентов при построении программы показана на рис. 1.3. Мы кратко обозначили способы использования файлов в процессе разработки программ, но можно сказать, что ситуация аналогична и в других случаях: например, при образовании и использовании файлов, содержащих графическую, аудио- и видеоинформацию.
Одним словом, файловые системы обычно обеспечивают хранение слабо структурированной информации, оставляя дальнейшую структуризацию прикладным программам. В перечисленных выше случаях использования файлов это даже хорошо, потому что при разработке любой новой прикладной системы, опираясь на простые, стандартные и сравнительно дешевые средства файловой системы, можно реализовать те структуры хранения, которые наиболее точно соответствуют специфике данной прикладной области.
Рис. 1.3. Связи между программными компонентами по пониманию логической структуры файлов
Читайте также: