
В файле robots txt нельзя использовать кириллицу
Обновлено: 07.07.2024
Полностью разбираем один из самых важных файлов сайта - robots.txt, ведь от него зависит корректная индексация страниц и продвижение всего сайта в целом.
Закрыть и открыть сайт
Закрыть от индексации сайт
Запрещаем индексацию сайта всем роботам:
Открыть к индексации сайт
Разрешаем всем роботам индексацию сайта:
Директива – это некое указание для поисковых роботов на то, что необходимо индексировать.
Кроме файла robots.txt закрыть или открыть сайт (страницы сайта) можно с помощью специального meta тега robots, однако данный тег не освобождает владельца сайта от необходимости иметь на сервере отдельный файл robot.txt
Директива User-agent
User-agent – самая первая директива, которая позволяет обратиться к роботам поисковых систем. Рядом с ней указывается название поисковой системы или * (звездочка).
* (звездочка) в директиве User-agent позволяет обращаться ко всем поисковым системам сразу.
| Система | Запись в User-agent | Описание |
| GoogleBot | Робот Google | |
| Яндекс | YandexBot | Основной робот Яндекса |
| Яндекс | YandexMobileBot | Мобильный робот Яндекса |
| Яндекс | Yandex | Робот, который будет использовать все другие боты от Яндекса (основной и мобильый) – используется чаще всего. |
| Bing | BingBot | Основной робот от поисковой системы bing.com |
| Mail.ru | Mail.ru | Робот от поисковой системы mail |
| Rambler | StackRambler | Робот от поисковой системы rambler |
В большинстве своих проектов нам достаточно лишь:
Директива Disallow
Директива Disallow – означает запрет к индексации страницы, раздела или файла.
* (звездочка) означает то, что перед нашим названием файла (папки) может стоять все, что угодно.
Директива Allow
Директива Allow – означает допуск к индексации страницы, раздела или файла.
Как открыть к индексации страницу или раздел:
На данном примере мы открыли раздел /uploads.
Как открыть файл из закрытого раздела:
В этом примере мы запрещаем индексировать все страницы, в которых содержится слово bitrix, но разрешаем индексировать страницы, в которых есть и bitrix и jpg, однако все другие страницы со словом bitrix в url адресе, которые не содержат символов jpg будут закрыты.
Директива Host
Директива Host – ранее в ней указывалось главное зеркало, но сейчас данная директива не используется поисковыми системами и ее можно не прописывать в файле robots.txt, т.к. сейчас все роботы смотрят на корректную настройку 301 редиректа, а не на то, что написано в директиве host. Информацию по этому поводу можно прочитать в статье Яндекса. Если вы добавите данную директиву в свой файл robots.txt, то ничего страшного от этого не произойдет, главное не забудьте настроить правильно зеркала.
Директива Sitemap
Sitemap – директива, служащая для указания на xml карту сайта, которая также обязательно должна быть на любом сайте (даже одностраничном). В карте сайта указывается список страниц, которые должны быть проиндексированы поисковой системой.
Директива указывается в самом конце файла robots.txt в виде url-адреса до файла карты сайта .xml
Спецсимволы *, $ в robots.txt
В файле robots.txt при указании путей можно использовать символы * и $ , задавая определенные регулярные выражения.
* означает любую последовательность символов. По-умолчанию к концу каждого правила, описанного в файле роботс тхт, приписывается спецсимвол *
$ данный спецсимвол служит для отмены * на конце.
Примеры:
Disallow /*visit/
Для данного правила:
Disallow /*visit/$
Как проверить robots.txt
Чтобы проверить правильное заполнение файла robots.txt можно воспользоваться сервисом Яндекс.Webmaster, в который уже должен быть добавлен ваш сайт.
На странице Инструменты -> Анализ robots.txt
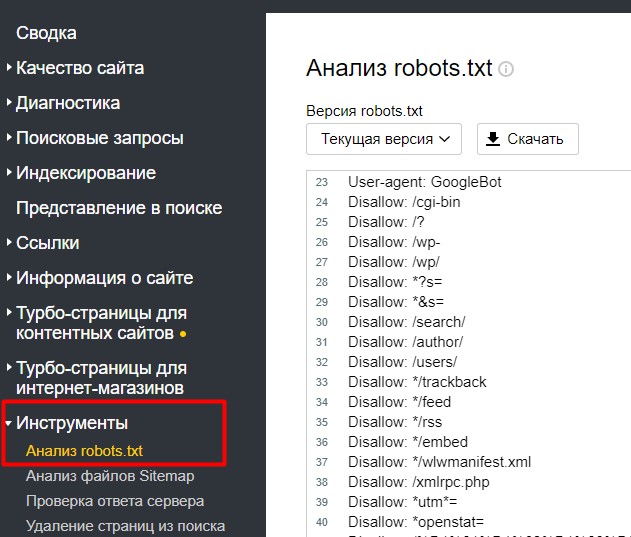
Внизу есть поле для проверки страницы (доступна она для индексации или нет).
Вы можете скопировать интересующий вас url адрес вашего сайта в данную форму и проверить – доступна страница к индексации или нет.
Например, для одного нашего туристического проекта на кириллическом домене «рф» проскакивали адреса на латинице вида cashback.html на конце (это была особенность разработки и системы управления). Эти url-адреса нужно было, во-первых закрыть от индексации, во-вторых настроить 301 редирект.
и вот, что получилось:
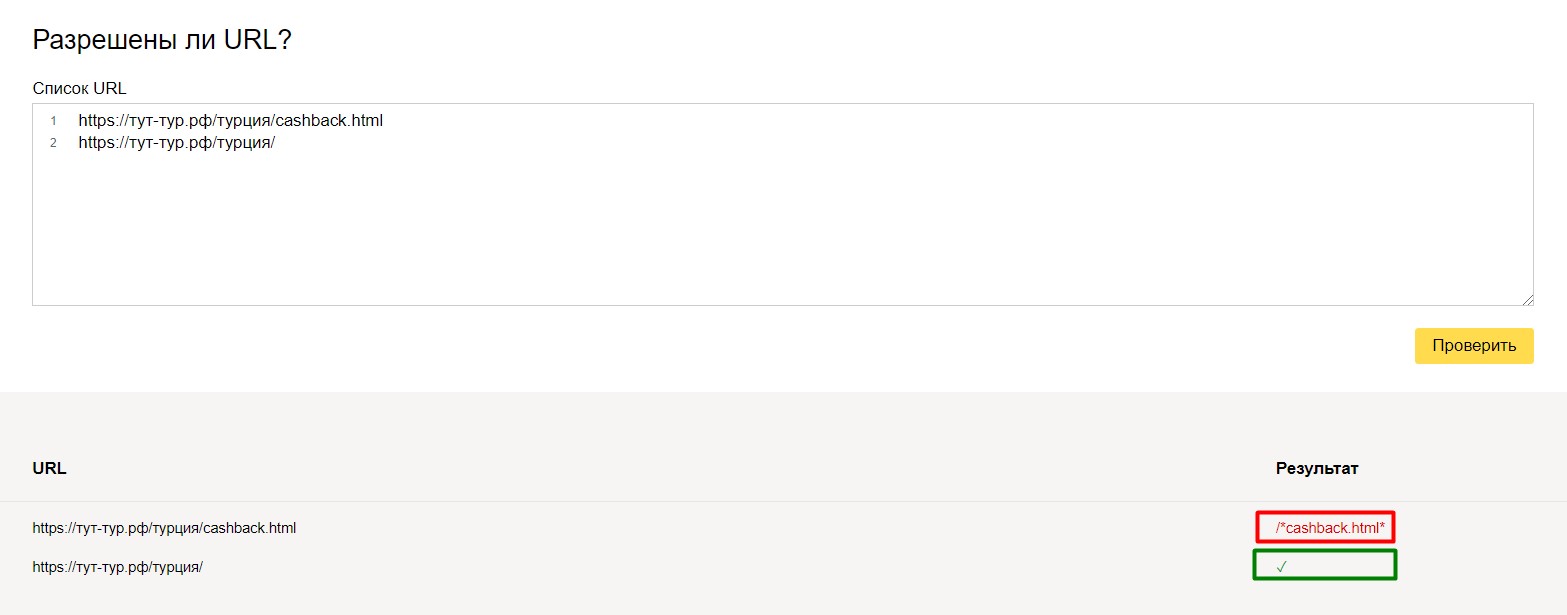
url адрес с cashback.html выдал ошибку (то, что нам и нужно было), а url-адрес с обычным url – проверку прошел. Всего-лишь одной небольшой командой мы избавились от проблемы. И в идеальном случае нужно было бы доработать систему и отфильтровать адреса (эта задача поставлена на будущее), но на данный момент мы отделались «малой кровью», настроив корректно редиректы и установив запрет к индексации.
Для перепроверки, можно производить различные тесты над вашим файлом robots.txt.
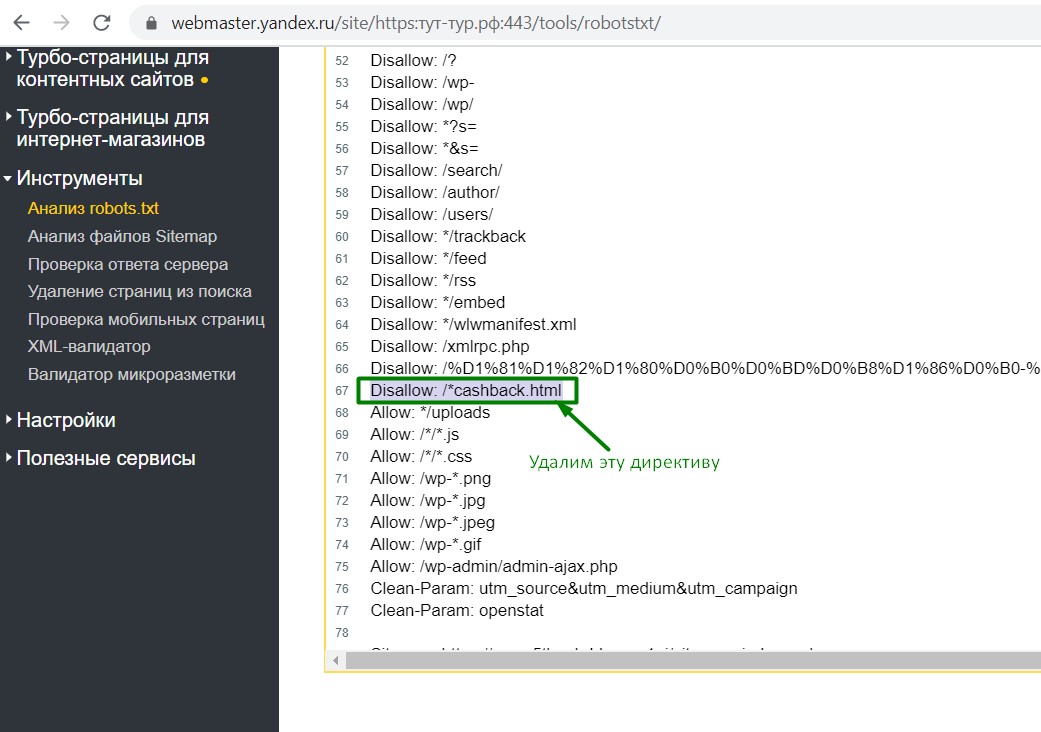
и вот, что у нас получилось:
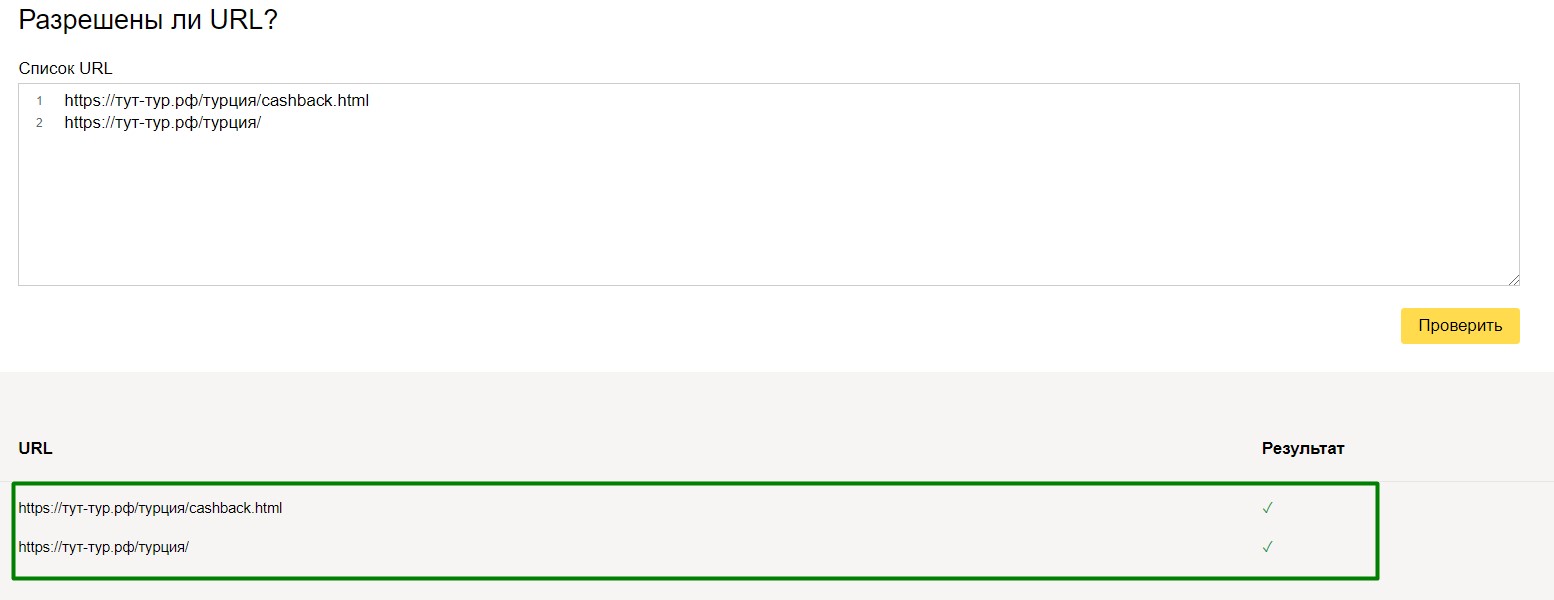
Все страницы доступны к индексации.
Данные методы тестирования применимы как к небольшим, так и к крупным проектам. Особенно, если есть мультиязычная версия и добавлено много правил.
Например, нам нужно, чтобы не индексировалась страница /travelguides/, но индексировалась travelguides/austria/. В этом случае мы создаем такое правило:
Кириллица в файле Robots
Что нужно обязательно закрывать в robots.txt
В файле robots.txt обязательно закрываем дубли страниц (в том числе дубли главной страницы), служебные страницы, неинформативные страницы, «хвосты» платных каналов и рекламы, динамические url, которых нет в структуре сайта.
Динамические страницы можно закрыть с помощью «маски», то есть с помощью шаблона, который применим для определенного количества страниц сайта.
Например, мы видим, что в платном канале используются url с хвостами, где содержится параметр param=id
Мы не будем закрывать каждую страницу от индексации, а используем маску:
то есть мы закрыли тем самым от индексации станицы, которые содержат param=id , т.к. это является дублями.
Также, необходимо закрывать от индексации страницы с результатами поиска, фильтрации, страницам печати, страницы пагинации и т.п.
Например, закрываем страницу с выводами результатов поиска:
Для данного примера конструкция закрытия от индексации будет:
тем самым мы закрыли страницу результатов поиска и все дополнительные «хвосты», связанные с ней.
Также, необходимо закрыть «служебные» страницы, например, страницу с корзиной.
Иностранная версия сайта
Если сайт содержит в себе иностранную версию страниц и контент на этих страницах полностью дублирует русскоязычную версию, то обязательно нужно закрывать данную страницу от индексации (если только это не является русскоязычным переводом).
На любом сайте есть не только контент для пользователей, но и различные системные файлы. Когда поисковый робот начинает сканировать сайт, для него нет разницы, системный перед ним файл или нет — он просканирует все. Но на посещение сайта у робота отведено ограниченное количество времени, поэтому важно, чтобы он проиндексировал именно те страницы, которые должны быть в поиске. Иначе робот посчитает сайт бесполезным и понизит его в поисковой выдаче. Именно поэтому обязательно нужно создавать файл robots.txt.
Файл robots.txt – это текстовый файл, который размещается в корневой папке сайта и содержит инструкции по индексации страниц для роботов поисковых систем. В нем есть своя структура, директивы, и в целом он в некотором роде выполняет функцию «фильтра». Говоря проще, именно при помощи robots.txt мы указываем, какие страницы сайта робот должен сканировать, а какие – нет. robots.txt является важным и нужным инструментом взаимодействия с поисковыми роботами и один из важнейших инструментов SEO. Он нужен в случае, когда вы хотите, чтобы индексация сайта проходила максимально качественно, то есть чтобы в поиск попали действительно полезные страницы.
Когда робот заходит на сайт, то в первую очередь он ищет именно этот файл. При этом поисковики в любом случае проиндексируют сайт — независимо от того, есть ли на нем robots.txt или нет. Просто если он есть, то роботы будут следовать правилам, прописанным в нем. А если он есть, но при этом неправильно настроен, то сайт и вовсе может выпасть из поиска или просто не будет проиндексирован.
При работе с файлом robots.txt важно понимать отличия между терминами «директива» и «директория»:
Директория — это папка, в которой находятся файлы вашей системы управления.
Директива — это список команд, инструкции в robots.txt для одного или нескольких поисковых роботов при помощи которых производится управление индексацией сайта.
Создание robots.txt
Чтобы самостоятельно создать файл robots.txt не потребуется никаких дополнительных программ. Достаточно будет любого текстового редактора, например, стандартного Блокнота.
Чтобы создать robots.txt просто сохраните файл под таким именем и с расширением .txt., и уже после этого вносите в него все необходимые инструкции в зависимости от стоящих перед вами задач.
Файл нужно разместить в корневой папке, то есть в той, которая называется так же, как и ваш движок и содержит в себе индексный файл index.html и файлы системы управления, на базе которой и сделан сайт.
Чтобы загрузить в эту папку файл robots.txt можно использовать панель управления сервером, админку в CMS, Total Commander или другие способы.
На некоторых движках уже есть встроенная функция, которая позволяет создать robots.txt. Если у вас ее нет, то можно использовать специальные модули или плагины. Но в целом, нет никакой разницы, каким именно способом вы создадите robots.txt.
В случае, когда у вас не один, а несколько сайтов, и создание файлов robots.txt будет занимать долгое время, можно воспользоваться онлайн-сервисами, которые генерируют robots.txt. автоматически. Но учтите, что такие файлы могут требовать ручной корректировки, поэтому все равно нужно понимать правила их составления и знать особенности синтаксиса.
В интернете также можно найти и готовые шаблоны robots.txt для разных CMS, но в них добавлены лишь стандартные директивы, а значит и эти файлы потребуют корректировки.
Общие правила составления robots.txt
Внимание следует уделить следующим моментам:
- наличие файла robots.txt на сайте;
- в правильном ли месте он расположен;
- грамотно ли он составлен;
- насколько он работоспособен, т.е. доступны ли указанные в нем документы для индексации.
Насколько грамотно составлен ваш robots.txt можно оценить, проанализировав его по следующим пунктам:
- Файл должен быть один для каждого сайта и называться он должен robots.txt. Заглавные буквы в названии не используются.
- Запрещено использовать кириллицу в директориях robots.txt. Чтобы указывать названия кириллических доменов, нужно использовать Punycode для их преображения. Адреса сайтов также указывают в кодировке UTF-8, включающей коды символов ASCII. Например:

Четкое соблюдение вышеописанных правил при создании и настройке файла robots.txt имеет огромное значение. Незамеченный или пропущенный слэш, звездочка или запятая могут привести к тому, что сайт закроется от индексации полностью. То есть даже незначительная разница в синтаксисе приводит к существенным отличиям в функционале.
закрывает весь сайт от индексации.
запрещает сканирование разделов calendar и junk.
В то время, как конструкция:
открывает весь сайт для индексации.
Основные директивы в robots.txt
Директивы, используемые в robots.txt:

1. Правильный robots.txt начинается с директивы User-agent, которая указывает, к какому роботу обращены конкретные директивы.
Примеры User-agent в robots.txt:
Через robots.txt можно обратиться не только к главному роботу поисковой системы, но и к вспомогательным роботам, например, в Яндексе есть робот, который индексирует изображения: YandexImages или робот, который индексирует видео: YandexVideo.
Существует мнение, что роботы лучше индексируют сайт, если к ним обращаться напрямую, а не через общую инструкцию, но с точки зрения синтаксиса разницы нет никакой.
Кроме того, в robots.txt не имеет значения регистр символов. То есть одинаково правильно будет записать: User-agent: Googlebot или User-agent: googlebot.
Таким образом, директива User-agent указывает только на робота (или на всех сразу), а уже после нее должна идти команда или команды с непосредственным указанием команд для выбранного робота.
2. Disallow — запрещающая директива. Она запрещает индексацию каталогов, адресов или файлов сайта. Путь к тем файлам, каталогам или адресам, которые не нужно индексировать, прописываются после специального символа “/”:
Пример как в robots.txt запретить индексацию сайта:
Данный пример закрывает от индексации весь сайт для всех роботов.
Пример, как robots.txt запретить индексацию папки wp-includes для всех роботов:
Данный пример закрывает для индексации все файлы, которые находятся в этом каталоге.
А вот если вам, например, нужно запретить индексирование всех страниц с результатами поиска только от робота Яндекс, то в файле robots.txt прописывается следующее правило:
Запрет на индексацию в этом случае распространяется именно на страницы, у которых в URL есть «/search/» (именно с двумя знаками “/”).
3. Allow — разрешающая директива, логически противоположная директиве Disallow. То есть она принудительно открывает для индексирования указанные каталоги, файлы, адреса. Директива имеет синтаксис, сходный с Disallow.
Пример, как в robots.txt запретить индексацию сайта кроме некоторых страниц:
Запрещается индексировать весь сайт, кроме страниц, начинающихся с /blog.
Если же необходимо разрешить индексировать все страницы, в адресе которых присутствует вхождение /blog, то следует использовать конструкцию:
Иногда директивы Allow и Disallow используются в паре. Это может понадобиться для того, чтобы открыть роботу доступ к подкаталогу, который расположен в каталоге с запрещенным доступом.
4. В директиве Sitemap указывают ссылку на карту сайта: sitemap.xml. Она нужна для ускорения индексации.
Пример robots.txt с указанием адреса карты сайта:
5. Директиву Crawl-delay с 22 февраля 2018 года Яндекс перестал учитывать.
6. Директива Clean-param позволяет исключить из индексации страницы с динамическими get-параметрами. Такие страницы могут отдавать одинаковое содержимое, имея различные URL (например, UTM). Данная директива позволяет сэкономит крауленговый бюджет за счёт исключения из индексирования страниц дублей.
- Иногда для закрытия таких страниц используется директива Disallow. Рекомендуем использовать Clean-param, так как эта директива позволяет передавать основному URL или сайту некоторые накопленные показатели, например ссылочные.
- Директива Clean-Param может быть указана в любом месте файла robots.txt. В случае, если директив указано несколько, все они будут учтены роботом.
Синтаксис директивы Clean-param:
Пример robots.txt с использованием Clean-param:
Директива Clean-param применима только для Яндекса (Google выдаст ошибку), поэтому без особой надобности её использовать не рекомендуется.
Маски в robots.txt: для чего нужны и как правильно использовать
Маска в robots.txt — это условная запись, в которую входят названия целой группы папок или файлов. Маски используются для того, чтобы одновременно совершать операции над несколькими файлами (или папками) и обозначаются спецсимволом-звездочкой — “*”.
На самом деле, использование масок не только упрощает работу, оно зачастую просто необходимо. Предположим, у вас на сайте есть список файлов в папке /documents/. Среди этих файлов есть презентации в формате .pdf, и вы не хотите, чтобы их сканировал робот. Значит эти файлы нужно исключить из поиска.
Как это сделать? Можно перечислить все файлы формата .pdf вручную:
Disallow: /documents/admin.pdf
Disallow: /documents/town.pdf
Disallow: /documents/leto.pdf
Disallow: /documents/sity.pdf
Disallow: /documents/europe.pdf
Disallow: /documents/s-112.pdf
Но если таких файлов сотни, то указывать их придется очень долго, поэтому куда быстрее просто указать маску *.pdf, которая скроет все файлы в формате pdf в рамках одной директивы:
Специальный символ “*”, который используется при создании масок, обозначает любую последовательность символов, в том числе и пробел.
Ошибки в файле robots.txt
В процессе проверки правильности составления файла robots.txt чаще всего встречаются следующие ошибки:
- robots.txt отсутствует или он закрыт от индексирования (Disallow: /).
- Несколько файлов robots.txt. Для одного сайта должен быть создан только один файл.
- Неверное расположение. Файл robots.txt должен располагаться в корневой папке сайта. Если он расположен в другом месте, то роботы его не увидят и будут индексировать весь сайт (включая файлы, которые индексировать не нужно).
- Правило начинается с неверных символов. В robots.txt правила должны начинаться только с * или /
- Есть несколько правил для одного агента, например, несколько правил “User-agent: Yandex”. В правильно составленном файле такое правило может быть только одно.
- Превышен допустимый размер. Максимальное количество правил — 2048. Максимальная длина одного правила — 1024 символа. Но такая ошибка встречается довольно редко.
- Перед правилом отсутствует директива User-agent. Любое правило в robots.txt всегда начинается с User-agent.
- Некорректные адреса. Например, путь к файлу Sitemap должен указываться полностью, включая протокол.
- Пустые строки между директивами. Правильная настройка robots.txt запрещает наличие пустых строк между директивами «User-agent», «Disallow» и директивами, следующими за «Disallow» в рамках текущего «User-agent».
Пример правильного перевода строки в robots.txt:
User-agent: Yandex
Disallow: /*utm_
Allow: /*id=User-agent: *
Disallow: /*utm_
Allow: /*id=
Robots.txt - это текстовый файл, в котором прописаны указания (директивы) по индексации страниц сайта. С помощью данного файла можно указывать поисковым роботам, какие страницы или разделы на веб-ресурсе нужно сканировать и заносить в индекс (базу данных поисковой системы), а какие - нет.
Почему robots.txt важен для продвижения?
Этот файл дает поисковым системам важные указания, которые напрямую будут влиять на результативность продвижения сайта. Использование robots.txt может помочь:
- предотвращению сканирования дублированного контента и бесполезных для пользователей страниц (результаты внутреннего поиска, технические страницы и др.);
- сохранению конфиденциальности разделов веб-сайта (например, можно закрыть системную информацию CMS);
- избежать перегрузки сервера;
- эффективно расходовать краулинговый бюджет на обход полезных страниц.
С другой стороны, если robots.txt содержит ошибки, то поисковые системы будут неправильно индексировать сайт, и в результатах поиска окажется не та информация, которая нужна.
Можно случайно запретить индексирование важных для продвижения страниц, и они не попадут в результаты поиска.
Ниже приведены ссылки на инструкции по использованию файла robots.txt:
Содержание отчета

- Кнопка «обновить» - при нажатии на неё данные о наличии ошибок в файле robots.txt обновятся.
- Содержимое строк файла robots.txt.
- При наличии в какой-либо директиве ошибки Labrika дает её описание.
Ошибки robots.txt, которые определяет Labrika
Сервис находит следующие виды ошибок:
Директива должна отделятся от правила символом ":".
Пустая директива и пустое правило.
Недопустимо делать пустую строку в директиве User-agent. Это основная директива, которая указывает, для какого поискового робота прописаны дальнейшие правила индексации.
Не указан пользовательский агент.
Каждое правило должно содержать не менее одной директивы «Allow» или «Disallow». Disallow закрывает раздел или страницу от индексации, Allow открывает страницы сайта для индексации (например, разрешает сканирование подкаталога или страницы в закрытом для обработки каталоге). Эти директивы задаются в формате: directive: [path], где значение [path] (путь к странице или разделу) указывать не обязательно. Однако роботы игнорируют директивы Allow и Disallow без указания пути. В этом случае они могут сканировать весь контент. Пустая директива Disallow: равнозначна директиве Allow: / , то есть "не запрещать ничего".
Пример ошибки в директиве Sitemap:
Не указан путь к карте сайта.
Перед правилом нет директивы User-agent
Правило должно всегда стоять после директивы User-agent. Размещение правила перед первым именем пользовательского агента означает, что никакие сканеры не будут ему следовать.
Найдено несколько правил вида "User-agent: *"
Запись вида User-agent: * означает, что правило задается для всех поисковых роботов.
запрещает всем поисковым роботам индексирование всего сайта.
Должна быть только одна директива User-agent для одного робота и только одна директива вида User-agent: * для всех роботов. Если в файле robots.txt несколько раз указан один и тот же пользовательский агент с разными списками правил, то поисковым роботам будет сложно определить, какие из этих правил нужно учитывать. В результате возникает большая неопределенность в действиях роботов.
Неизвестная директива
Обнаружена директива, которая не поддерживается поисковой системой (например, не описана в правилах использования robots.txt Яндекса).
Причины этого могут быть следующие:
- была прописана несуществующая директива;
- допущены ошибки синтаксиса, использованы запрещенные символы и теги;
- эта директива может использоваться роботами других поисковых систем.
Директивы «Disalow» не существует, допущена ошибка в написании слова.
Количество правил в файле robots.txt превышает максимально допустимое
Поисковые роботы будут корректно обрабатывать файл robots.txt, если его размер не превышает 500 КБ. Допустимое количество правил в файле - 2048. Контент сверх этого лимита игнорируется. Чтобы не превышать его, вместо исключения каждой отдельной страницы применяйте более общие директивы.
Например, если вам нужно заблокировать сканирование файлов PDF, не запрещайте каждый отдельный файл. Вместо этого запретите все URL-адреса, содержащие .pdf, с помощью директивы:
Правило превышает допустимую длину
Правило не должно содержать более 1024 символов.
Некорректный формат правила
В файле robots.txt должен быть обычный текст в кодировке UTF-8. Поисковые системы могут проигнорировать символы, не относящиеся к UTF-8. В таком случае правила из файла robots.txt не будут работать.
Чтобы поисковые роботы корректно обрабатывали инструкции в файле robots.txt, все правила должны быть написаны согласно стандарту исключений для роботов (REP), который поддерживают Google, Яндекс и большинство известных поисковых машин.
Использование кириллицы и других национальных языков
Использование кириллицы запрещено в файле robots.txt. Согласно утверждённой стандартом системе доменных имен название домена может состоять только из ограниченного набора ASCII-символов (буквы латинского алфавита, цифры от 0 до 9 и дефис). Если домен содержит символы, не относящиеся к ASCII (в том числе буквы национальных алфавитов), его нужно преобразовать с помощью Punycode в допустимый набор символов.
Возможно, был использован недопустимый символ
Допускается использование спецсимволов «*» и «$». Они применяются для указания шаблонов адресов при объявлении директив, чтобы не прописывать большой перечень конечных URL для блокировки. Например:
запрещает индексировать любые php файлы.
- Звездочка «*» обозначает любую последовательность и любое количество символов.
- Знак доллара «$» означает конец адреса и ограничивает действие знака «*».
Например, если /*.php соответствует всем путям, которые содержат .php., то /*.php$ соответствует только тем путям, которые заканчиваются на .php.
Символ «$» прописан в середине значения
Знак "$" можно использовать только один раз и только в конце правила. Он показывает, что стоящий перед ним символ должен быть последним.
Правило начинается не с символа "/" и не с символа "*".
Правило может начинаться только с символов «/» и «*».
Значение пути указывается относительно корневого каталога сайта, на котором находится файл robots.txt, и должно начинаться с символа слэш «/», обозначающего корневой каталог.
Правильным вариантом будет:
в зависимости от того, что вы хотите исключить из индексации.
Некорректный формат URL файла Sitemap
Sitemap - это карта сайта для поисковых роботов, которая содержит рекомендации того, какие страницы необходимо обходить в первую очередь и с какой частотой. Наличие карты сайта помогает роботам быстрее индексировать нужные страницы.
Некорректное имя главного зеркала сайта
Директива Host указывала роботу Яндекса главное зеркало сайта, если к веб-ресурсу был доступ по нескольким доменам. Остальные поисковые роботы её не воспринимали.
С марта 2018 года Яндекс отказался от директивы Host. Вместо неё используется раздел «Переезд сайта» в Вебмастере и 301 редирект.
Некорректный формат директивы «Crawl-delay»
Директива Crawl-delay задает роботу минимальный период времени между окончанием загрузки одной страницы и началом загрузки следующей.
Использовать директиву Crawl-delay следует в тех случаях, когда сервер сильно загружен и не успевает обрабатывать запросы поискового робота. Чем больше устанавливаемый интервал, тем меньше будет количество загрузок в течение одной сессии.
При указании интервала можно использовать как целые значения, так и дробные. В качестве разделителя применяется точка. Единица измерения – секунды:
К ошибкам относят:
- несколько директив Crawl-delay;
- некорректный формат директивы Crawl-delay.
С 22 февраля 2018 года Яндекс перестал учитывать директиву Crawl-delay. Чтобы задать скорость, с которой роботы будут загружать страницы сайта, используйте раздел «Скорость обхода сайта» в Яндекс.Вебмастере.
Google также не поддерживает эту директиву. Для Google-бота установить частоту обращений можно в панели вебмастера Search Console. Однако роботы Bing и Yahoo соблюдает директиву Crawl-delay.
Некорректный формат директивы «Clean-param»
Директива используется только для робота Яндекса. Google и другие роботы не поддерживают Clean-param.
Директива указывает, что URL страниц содержат GET-параметры, которые не влияют на содержимое, и поэтому их не нужно учитывать при индексировании. Робот Яндекса, следуя инструкциям Clean-param, не будет обходить страницы с динамическими параметрами, которые полностью дублируют контент основных страниц.
Labrika определяет некорректный формат директивы Clean-param, например:
В именах GET-параметров встречается два или более знака амперсанд "&" подряд:
Правило должно соответствовать виду "p0[&p1&p2&..&pn] [path]". В первом поле через символ «&» перечисляются параметры, которые роботу не нужно учитывать. Во втором поле указывается префикс пути страниц, для которых применяется правило. Параметры отделяются от префикса пути пробелом.
Имена GET-параметров должны содержать только буквы латинского алфавита, цифры, нижнее подчеркивание и дефис.
Префикс PATH URL для директивы Clean-param может включать только буквы латинского алфавита, цифры и некоторые символы: ".", "-", "/", "*", "_".
Ошибкой считается и превышение допустимой длины правила — 500 символов.
Строка содержит BOM (Byte Order Mark) — символ U+FEFF
BOM (Byte Order Mark - маркер последовательности байтов) — символ вида U+FEFF, который находится в самом начале текста. Этот Юникод-символ используется для определения последовательности байтов при считывании информации.
При создании и редактировании файла с помощью стандартных программ редакторы могут автоматически присвоить ему кодировку UTF-8 с BOM меткой.
BOM – это невидимый символ. У него нет графического выражения, поэтому большинство редакторов его не показывает. Но при копировании этот символ может переноситься в новый документ.
При использовании маркера последовательности байтов в файлах .html сбиваются настройки дизайна, сдвигаются блоки, могут появляться нечитаемые наборы символов, поэтому рекомендуется удалять маркер из веб-скриптов и CSS-файлов.
Как избавиться от BOM меток?
Избавиться от ВОМ довольно сложно. Один из простых способов это сделать - открыть файл в редакторе, который может изменять кодировку документа, и пересохранить его с кодировкой UTF-8 без BOM.
Например, вы можете бесплатно скачать редактор Notepad++, открыть в нём файл с ВОМ меткой и выбрать во вкладке меню «Кодировки» пункт «Кодировать в UTF-8 (без BOM)».
Robots.txt – это обычный текстовый файл в формате .txt. Этот файл содержит инструкции и директивы для поисковых роботов. Он может содержать директивы, запрещающие к индексации определённые файлы сайта, папки целиком и документы. Файл служит для ограничения доступа ботам поисковых систем к определённым частям сайта.
Robots.txt был принят стандартом — консорциумом W3C 30 января 1994 года, и с тех пор используется большинством известных поисковых машин. Следование стандарту добровольное.
Влияние Robots.txt на SEO
Поисковые роботы при каждом сканировании сайта обращаются именно к Robot.txt для того, чтобы узнать, можно ли сканировать те или иные разделы вашего сайта, поэтому именно этот файл оказывает непосредственное влияние на SEO. На любом сайте может содержаться конфиденциальный контент либо служебный, сканирование которого никак не идёт на пользу SEO.
В Robot.txt также указывается путь к Sitemap . Если допустить ошибку в инструкциях и директивах, сайт может полностью пропасть из поискового индекса. Важно уметь корректно настраивать данный файл, так как от этого зависит видимость вашего сайта в поисковых системах и дальнейший рост объема трафика на проекте, именно поэтому и написана эта статья.
Первое, что изучает любой SEO-специалист – это правильность написания Robots.
Где находится и как создать Robots.txt
Файл robots.txt располагается в корневой директории сайта. На большинстве хостингов в папке public_html.
Проверить его наличие довольно просто. Надо перейти по ссылке:
Ручное создание robots.txt
Для ручного создания файла достаточно воспользоваться любым текстовым редактором. Лучше всего:
Не рекомендуется использовать для написания этого файла Microsoft Word, поскольку Word зачастую использует много служебных скрытых символов, которые могут быть перенесены в файл robots.txt и помешать его созданию.
После написания файла его загружают в корневой каталог сайта, чаще всего public_html. Проверить это тоже легко. Рядом с ним находятся файлы .htaccess и index.php.
Для загрузки используют:
- панель управления сервером (обратитесь к своим хостерам с вопросом, как это проще сделать);
- консоль, админку в CMSв WordPress – при помощи плагинов, например, Yoast;
- FTP-клиент, например, TotalCommander или FileZilla.
Не имеет значения, какой из способов вы выберете.
Создание robots.txt при помощи онлайн генератора
Лучше не пользоваться этим вариантом, либо подходить к процессу творчески. У каждого сайта свои правила создания этого файла. Отличаются они и для Яндекс и Google. В любом случае, лучше проверить, подходит автоматический вариант вашему сайту или нет. Например, CY-PR В WordPress для этого есть плагин ClearflyPro. Готовые шаблоны В сети существует масса готовых шаблонов robots.txt для популярных CMS WordPress, Joomla, Drupal и так далее, но в любом случае, они не решают конкретно ваших проблем, и всё равно их надо проверять и творчески относиться к написанию своего файла, который подходит для вашего сайта.
Как редактировать?
В процессе работы у вас может возникнуть необходимость в дальнейшем редактировании Robots.txt. Делается это прямо в самом файле. Не забывайте, что это простой текстовый файл. В различных CMS существует много плагинов для редактирования Robots.txt прямо из административной панели. Например, Yoast в WordPress
Директивы Robots.txt
В Robots.txt прописываются директивы для роботов поисковых систем, эти директивы помогают им понять, какие страницы или разделы индексировать, а какие – нет. Рассмотрим, какие директивы что означают.
User-agent — это обязательная директива. Она определяет, к какому роботу будут применяться прописанные ниже правила. Это обращение к конкретному роботу или всем поисковым ботам. Все файлы начинаются именно с этой строчки.
Disallow — запрещает индексирование разделов или отдельных страниц сайта. Чаще всего запрещают индексировать:
- страницы пагинации;
- страницы с личными данными пользователей;
- страницы с результатами поиска внутри ресурса;
- дублирующиеся страницы;
- логи;
- архивы дат и авторов, если там невозможно сгенерировать Descriptions;
- служебные/технические страницы.
В ней можно применять специальные символы * и $.
Sitemap — указывает путь к файлу Sitemap, который размещен на сайте. Эта директива очень важна, потому что сообщает ботам расположение XML карты сайта. Нужно указывать полный URL. Она важна для поисковых машин Google и Яндекс, так как при обходе сайта в первую очередь они обращаются именно к Sitemap, где показана структура ресурса с внутренними ссылками, приоритетами индексации страниц и датами их создания или изменения.
Несмотря на существование этой директивы, рекомендуется добавить адреса файлов Sitemap в Яндекс Webmaster и Google Search Console. Это ускорит их обработку.
Читайте также: