
Vmware drs что такое
Обновлено: 07.07.2024
Основные компоненты и возможности VMware vSphere
Первая в отрасли ОС для «облачных» вычислений VMware vSphere™ включает следующие компоненты.
- Службы инфраструктуры — набор компонентов, обеспечивающих комплексную виртуализацию ресурсов серверов, хранилищ и сетей, их объединение и выделение в точном соответствии с запросами приложений и приоритетами бизнеса.
- Службы приложений — набор компонентов, предоставляющих встроенные средства управления уровнями обслуживания для всех приложений в среде VMware vSphere™ — независимо от ОС или типа приложения.
VMware vCenter™ Server обеспечивает администрирование служб инфраструктуры и приложений и автоматизацию повседневных эксплуатационных задач с полной визуализацией всех аспектов больших и малых сред VMware vSphere™. VMware vCenter Server — обязательный компонент для управления средами VMware vSphere, который приобретается отдельно.
Службы инфраструктуры: виртуализация и объединение аппаратных ресурсов
Службы инфраструктуры VMware vSphere™ преобразуют отдельные аппаратные ресурсы в общую отказоустойчивую вычислительную платформу, которая действует как мейнфрейм и обеспечивает высокую производительность самых требовательных приложений. VMware vSphere™ предлагает службы инфраструктуры следующих типов:
VMware vCompute : службы инфраструктуры, обеспечивающие эффективную виртуализацию серверных ресурсов и их объединение в логические пулы, которые можно назначить приложениям в точном соответствии с их запросами.
- VMware ESX™ и VMware ESXi предоставляют надежный уровень виртуализации, проверенный в производственных средах. Этот уровень абстрагирует аппаратные ресурсы серверов и обеспечивает их совместное использование несколькими виртуальными машинами. Уникальные возможности управления памятью и расширенного планирования в продуктах VMware ESX и ESXi обеспечивают максимальные уровни консолидации и лучшую производительность приложений, во многих случаях превосходящую физические серверы.
- VMware Distributed Resource Scheduler (DRS) объединяет физические ресурсы множества кластеров и динамически выделяет их виртуальным машинам в соответствии с приоритетами бизнеса, упрощая управление за счет автоматизации. Компонент VMware Distributed Power Management (DPM) , входящий в VMware DRS, автоматически обеспечивает энергетическую эффективность кластеров VMware DRS путем непрерывной оптимизации энергопотребления серверов в каждом из них.
VMware vStorage: службы инфраструктуры, которые отделяют ресурсы хранения данных от сложного базового оборудования, обеспечивая максимальные коэффициенты использования емкости хранилища в виртуализированной среде.
- VMware vStorage Virtual Machine File System (VMFS) – это высокопроизводительная кластерная файловая система, которая обеспечивает эффективное совместное использование файлов и контроль одновременного доступа виртуализированных серверов к хранилищу.
- VMware vStorage Thin Provisioning выполняет динамическое выделение емкости хранилища, что позволяет закупать ресурсы хранилища, только когда они действительно нужны. Это сокращает общие затраты на хранилище – в некоторых случаях на 50%.
VMware vNetwork: службы инфраструктуры, которые обеспечивают оптимальное администрирование сети в виртуализированной среде.
- VMware vNetwork Distributed Switch упрощает и улучшает процессы инициализации, администрирования и контроля сетей виртуальных машин в средах VMware vSphere™. Кроме того, Distributed Switch дает компаниям возможность использовать распределенные виртуальные коммутаторы сторонних поставщиков, такие как Cisco Nexus 1000v, в средах VMware vSphere™, предоставляя администраторам знакомые интерфейсы для контроля качества обслуживания на уровне виртуальной машины.
Службы приложений: встроенные элементы управления уровнями обслуживания приложений
Службы приложений VMware vSphere™ предлагают встроенные элементы управления уровнями обслуживания приложений, например, относящиеся к доступности, безопасности и масштабируемости, и могут легко и согласованно внедряться для любых приложений, работающих на виртуальных машинах VMware.
Доступность: службы доступности дают ИТ-отделам возможность предоставлять приложениям различные уровни доступности в соответствии с их приоритетами и требованиями без необходимости в сложном резервном оборудовании и ПО для кластеризации.
- VMware vMotion™ устраняет необходимость в плановых простоях приложений из-за регламентного технического обслуживания серверов за счет оперативного переноса виртуальных машин между серверами без нарушения работы пользователей и прерывания обслуживания.
- VMware Storage vMotion™ устраняет необходимость в плановых простоях приложений из-за регламентного технического обслуживания систем хранения данных за счет оперативного переноса дисков виртуальных машин без нарушения работы пользователей и прерывания обслуживания.
- VMware High Availability (HA) выполняет экономичный автоматизированный перезапуск всех приложений в течение нескольких минут при отказах оборудования и ОС.
- VMware Fault Tolerance обеспечивает постоянную доступность любых приложений при отказах оборудования, исключая простои и потери данных.
- VMware Data Recovery предлагает простое экономичное резервное копирование и восстановление виртуальных машин без использования агентов для малых сред.
Безопасность: службы безопасности дают ИТ-отделам возможность применять политики безопасности соответствующего уровня для приложений оптимальным способом.
- VMware vShield Zones упрощает обеспечение безопасности приложений за счет применения корпоративных политик безопасности в общей среде на уровне приложений и поддерживает отношения доверия и сегментацию сети для пользователей и конфиденциальных данных.
- VMware VMsafe™ обеспечивает поддержку защитного ПО, работающего в сочетании с уровнем виртуализации, для предоставления повышенных уровней безопасности виртуальных машин — даже по сравнению с физическими серверами.
Масштабируемость: службы масштабируемости дают ИТ-отделам возможность выделять необходимый объем ресурсов каждому приложению в соответствии с его потребностями и без прерывания работы.
- VMware DRS выполняет динамическую балансировку нагрузки на серверные ресурсы для предоставления нужного ресурса нужному приложению в соответствии с приоритетами бизнеса, обеспечивая увеличение или уменьшение среды приложений по мере необходимости.
- Возможность «горячего» добавления ЦП и памяти к виртуальным машинам при необходимости без прерываний или простоев.
- Возможность «горячего» подключения обеспечивает добавление виртуального хранилища и сетевых устройств к виртуальной машине и их удаление без прерываний работы или простоев.
- Возможность «горячего» расширения виртуальных дисков обеспечивает добавление виртуального хранилища к работающим виртуальным машинам без прерываний работы или простоев.
vApp: прозрачное перемещение приложений и возможность выбора инфраструктуры «облачных» вычислений

В начале обозначим, что в рамках данной статьи мы будем понимать под кластером группу хостов (физических серверов) под управлением единого сервиса для совместного выполнения определенных функций как целостная система, связывающаяся через сеть.
На платформе виртуализации VMware vSphere можно построить 2 разновидности кластеров: High-availability кластер (HA) и Distributed Resource Scheduler кластер (DRS).
HA-кластер будет означать, что определенное количество физических серверов объединяется в кластер и на них запускаются виртуальные машины. В случае выхода из строя одного из хостов, виртуальные машины запускаются на других серверах из группы, на которых предварительно было выделено для этого место. В итоге время простоя равно времени загрузки операционной системы «виртуалки».
Если необходимо сократить время простоя до минимального времени рекомендуется использовать технологию VMware Fault Tolerance. Основную идею опции можно описать как создание синхронно работающей реплики виртуальной машины на другом сервере и мгновенное переключение на неё при выходе из строя основного хоста.
Fault Tolerance
Технология VMware DRS используется для выравнивания нагрузки в кластере. Для этого на первоначальном этапе ресурсы кластера объединяются в пул и затем происходит балансировка нагрузки между хостами путем перемещения виртуальных машин. DRS может рекомендовать перемещение с необходимым подтверждением от администратора или делать это в автоматическом режиме. Происходит это с использованием утилиты «живой миграции» vMotion, благодаря которой миграция не требует остановки ВМ. Пользователи продолжают работать с одним экземпляром ВМ до тех пор, пока данные не будут перенесены на другой хост. В последний момент копируются последние изменения из оперативной памяти, пользователь видит незначительное кратковременное снижение быстродействие системы и через мгновение уже работает с той же ВМ, которая по факту уже находится на другом физическом сервере.
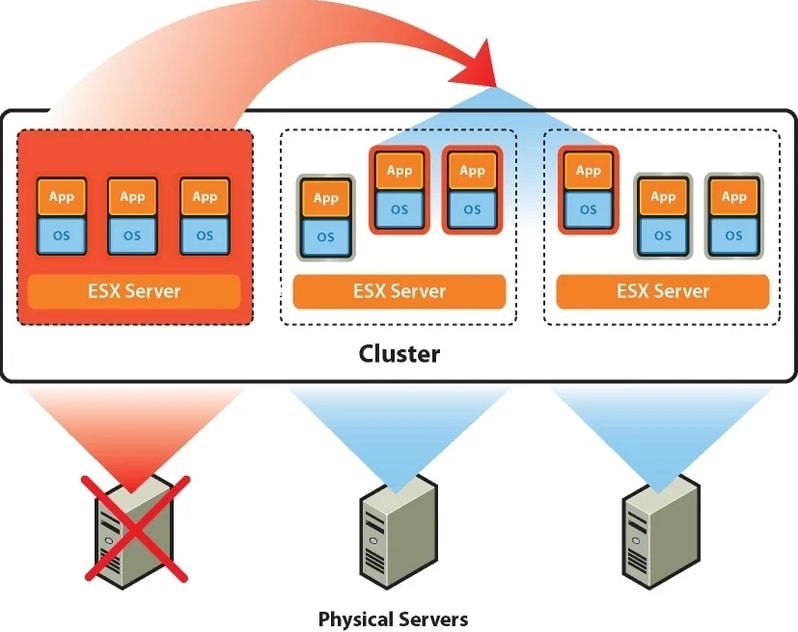
Принцип работы VMware HA + DRS
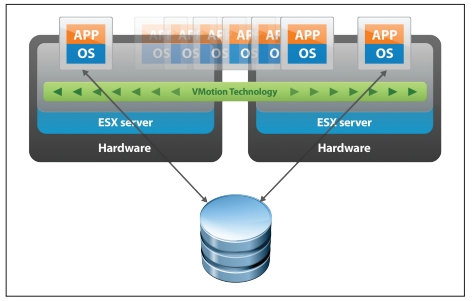
В случае с кластером VMware группа из 2-х и более серверов ESXi находится под централизованным управлением VMware vCenter Server. Собственно, создавать виртуальные машины можно и на одном хосте с установленным гипервизором VMware ESXi, но возможностей HA, DRS и прочих у вас не будет. Вы просто сможете «нарезать» ваш физический сервер на несколько виртуальных, а его неработоспособность будет означать простой всех ВМ.
Чтобы пользоваться всеми кластерными возможностями необходимо использовать платформу VMware vSphere, которая включает в себя сервер управления ESXi-хостами и СХД, так называемый и упомянутый выше, vCenter Server. Также для построения кластера потребуется подключение системы хранения данных. В ней в особенной кластерной файловой системе VMFS хранятся разделы с файлами виртуальных машин, которые доступны для чтения и записи всем ESXi-хостам кластера. По причине хранения в одном месте и независимости виртуальной машины от физической платформы достигается быстрое перемещение и восстановление при помощи HA, DRS, FT, vMotion.
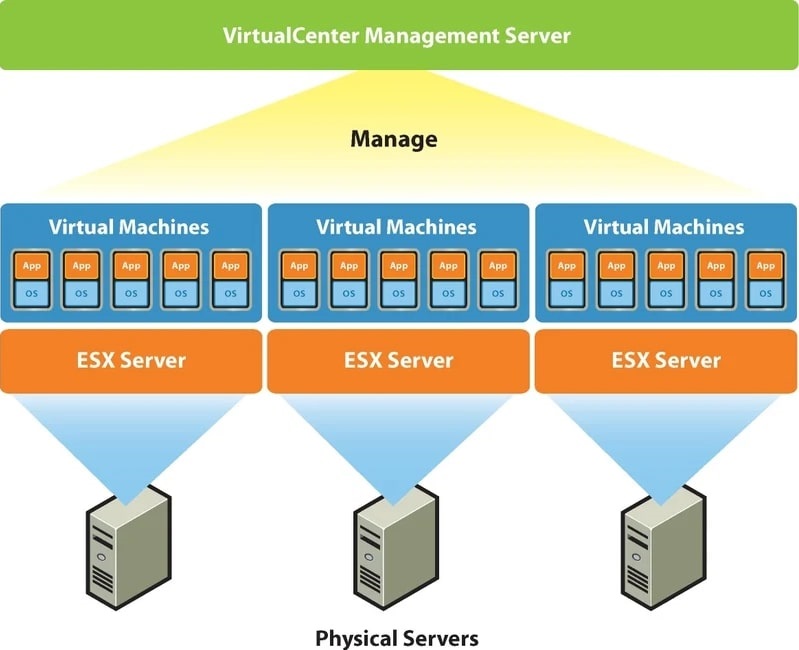
Платформа VMware vSphere
VMware vCenter Server, если говорить упрощенно, является набором служб и базой данных. Каждая из служб занимается своим конкретным списком задач и взаимодействует с другими службами и/или хостами ESXi. vCenter Server – это некий командный пункт, которому подчиняются гипервизоры ESXi на хостах. Общение между ними происходит через хостовых агентов VPXA. Из панели управления vCenter Server можно делать даже больше, чем подключившись напрямую к ESXi. Если в ESXi вы сможете создавать/удалять виртуальные машины, то с помощью vCenter Server вы можете дополнительно создать и настроить для них кластер и все необходимые кластерные опции, часть из которых описана выше.
VMware vCenter Server может работать как на отдельной физическом сервере, так и внутри виртуальной машины на том же хосте, которым сам же и управляет.
Тема безусловно интересная и обширная, однако для развертывания подобных инфраструктур требуются большие материальные затраты. Если мы хотим пользоваться всеми возможностями, которые повышают отказоустойчивость и надежность системы, необходимо приобрести минимум два сервера и СХД, купить лицензию на платформу VMware VSphere у одного из дистрибьюторов. Установка, настройка и администрирование кластера VMware также потребует от вас временных и финансовых вложений.
Что делать в случае, если от вашей IT-инфраструктуры требуется высокая надежность, которую предоставляет платформа VMware vSphere, но нет возможности понести значительные капитальные вложения? Ответом на этот вопрос для многих корпоративных клиентов стало использование облачных технологий, а именно услуга аренды инфраструктуры (IaaS). Облачный провайдер обладает необходимым сетевым и серверным оборудованием, которое расположено в безопасных дата-центрах. IT-специалисты провайдера оказывают техническую поддержку 24*7, а бизнес может воспользоваться всеми преимуществами виртуализации в кластере VMware.
Клиенты не используют VMware vCenter Server. За управление кластерами и физическим оборудованием отвечает провайдер. Клиенты получают значительное количество возможностей управления своим виртуальным ЦОДом с помощью удобного портала самообслуживания VMware vCloud Director. Создание vЦОДа для клиента происходит в кратчайшие сроки, при этом может быть создано необходимое количество виртуальных машин с нужными характеристиками и операционными системами, маршрутизируемые и изолированные сети с любой топологией, настроены гибкие правила Firewall и многое другое.
Если вашему бизнесу требуется надежное IT-решение на основе кластера VMware, для принятия решения рекомендуем воспользоваться тестовым доступом к облаку Cloud4Y.

Совсем недавно в Сан-Франциско прошла ежегодная конференция VMworld 2019, на которой, в числе прочего, была анонсирована версия планировщика ресурсов VMware Distributed Resource Scheduler (DRS) 2.0. Поскольку вторая версия инструмента содержит несколько фундаментальных нововведений, мы решили выпустить подробную обзорную статью о VMware DRS и рассказать о принципах его работы, которые могут быть неизвестны многим читателям.
Но для начала повторим основную теорию.
Как работает VMware DRS
VMware DRS (Distributed Resource Scheduler)
используется для балансировки рабочей нагрузки в виртуальной среде. Задача этого механизма — определить оптимальный хост для миграции функционирующей виртуальной машины или запуска новой. Основная цель DRS — выровнять нагрузку на хостах, находящихся внутри DRS-кластера, так, чтобы виртуальные машины и их приложения всегда получали вычислительные ресурсы и работали с максимальной эффективностью. Все виртуальные машины обеспечиваются ресурсами вскоре после включения, а ресурсы в рамках кластера утилизируются равномерно. При использовании режима fully automated процесс балансировки происходит автоматически и может регулироваться несколькими правилами, задаваемыми администратором. К работе с правилами мы еще вернемся чуть ниже. Время от времени рабочие нагрузки виртуальных машин могут меняться, что может вызвать в кластере «перекос» и, соответственно, ухудшить производительность. DRS решает эти проблемы: раз в 5 минут определяет сбалансированность кластера и в случае дисбаланса производит необходимые миграции или дает рекомендации относительно необходимых перемещений в зависимости от выбранного уровня автоматизации. Далее мы подробнее рассмотрим, как именно DRS определяет, чего не хватает виртуальным машинам для «полного счастья».
Размещение виртуальных машин
Как только в кластере DRS запускается новая виртуальная машина, DRS с помощью специального алгоритма определяет наиболее подходящий для нее ESXi-хост. Это решение принимается на основании ожидаемых изменений в распределении ресурсов на хосте. Вновь запущенная машина должна на старте получить все требуемые ресурсы. К примеру, чтобы определить необходимое количество RAM для машины, применяется следующая формула:
Требуемое значение RAM для ВМ = Function (Active memory used, Swapped, Shared) + 25% (RAM, потребляемая в простое)
Хорошо сбалансированным считается кластер, в котором ресурсы хоста используются более-менее равномерно. Для принятия решений о распределении нагрузки DRS использует метрику сбалансированности кластера. Показатель баланса рассчитывается из стандартного отклонения данных об использовании ресурсов из хостов в кластере. Раз в 5 минут запускается процесс оценки дисбаланса. Если необходимо изменить расположение виртуальных машин, DRS использует vMotion для их миграции с одного ESXi-хоста на другой.

Уровни автоматизации DRS
Во время первоначального размещения и балансировки нагрузки DRS генерирует рекомендации по размещению и миграции машин. Этот процесс можно полностью автоматизировать, выбрав режим Fully automated, или превратить в ручной труд администратора. Всего же DRS имеет три уровня автоматизации:
Уровни агрессивности DRS (миграционный порог)
Изменение агрессивности DRS позволяет установить уровень допустимого дисбаланса в кластере. Всего доступно 5 уровней агрессии. Минимальный (консервативный) допускает больший дисбаланс, максимальный (агрессивный) инициирует больше миграций, но позволяет добиться наиболее равномерного распределения нагрузки. Средний (3) уровень агрессивности, установленный по умолчанию, в большинстве случаев является оптимальным. На минимальном уровне (1) DRS будет применять только те рекомендации, которые необходимы для соблюдения жестких ограничений — правил привязки или развязки (affinity/antiaffinity rules), а также сможет эвакуировать виртуальные машины с хоста, входящего в режимы обслуживания или ожидания.
Индивидуальные настройки и правила
Несмотря на всю внешнюю простоту работы утилиты и малое количество настроек, имеющиеся опции позволяют гибко регулировать распределение виртуальных машин по хостам или группам. В идеале расположение каждой машины в кластере контролируется DRS (режим Fully automated). Тем не менее иногда вам может понадобиться запускать некоторые ВМ только на определенных хостах или держать группу ВМ всегда вместе. Чаще всего это требуется для соблюдений правил лицензирования, когда виртуальные машины должны работать исключительно на определенных физических серверах, или в тех случаях, когда следует жестко определить совместное или раздельное нахождение виртуальных машин на хостах. Что же касается возможных ошибок — у DRS не так много настроек, это простой инструмент, работа которого регулируется режимами, уровнем агрессивности и набором правил. При этом глобальных настроек нет, ошибки могут возникать именно в резервации ресурсов для машин. Ошибочная резервация ресурсов может привести к проблемам при миграции: например, если выделить для машины оперативной памяти больше, чем в принципе бывает свободно на хосте, DRS не сможет мигрировать эту машину и сбалансировать нагрузку.
5 причин установить режим Fully Automated
Можно выделить только один сценарий, при котором необходимо использовать частично автоматизированный (Partially automated) или ручной (Manual) режим работы DRS вместо полной автоматизации. Это рационально, если в кластере существует некий «проблемный» хост и вы не хотите, чтобы виртуальные машины могли переезжать на него. В этом случае DRS будет отслеживать состояние виртуальных машин и хостов и выдавать рекомендации по миграции, которые можно выполнять вручную. Во всех остальных случаях оптимальным будет режим Fully Automated. Давайте рассмотрим 5 ключевых преимуществ его использования.
Миграция на основе множества факторов и актуальных данных
Ни один, даже самый опытный администратор, физически не сможет отслеживать работу тысяч виртуальных машин и хостов, постоянно просчитывать актуальную и потенциальную нагрузку и производить миграцию с той же скоростью, что и DRS. DRS имеет постоянный доступ к информации о загруженности хостов внутри кластера, о ресурсах, потребляемых виртуальными машинами, и их резервациях. Так что сравнивать производительность DRS с производительностью человека вряд ли имеет смысл. Это всё равно, что соревноваться с микропроцессором в скорости счета.
Гибкая настройка правил
Если в рамках виртуальной инфраструктуры требуется соблюдение определенных правил относительно совместного или, наоборот, несовместного нахождения виртуальных машин, нет необходимости использовать ручной или полуавтоматизированный режим работы VMware DRS. Гибкие опции позволяют соблюсти необходимые требования и в полностью автоматическом режиме.
Повышение утилизации ресурсов
Балансировщик следит за ровной нагрузкой на всех хостах, снижая простои и повышая утилизацию имеющихся ресурсов. Грамотное взаимодействие с VMware DRS позволит вам эффективно использовать имеющиеся мощности и задумываться о масштабировании только тогда, когда появится реальная необходимость.
Защита от ошибок клиентов
Если вы продаете инфраструктуру как решение, а ваши клиенты самостоятельно распределяют нагрузки, размеры виртуальных машин и другие параметры, вы оказываетесь в ситуации, когда уже невозможно отследить взаимодействие клиента с виртуальной инфраструктурой и его возможные ошибки. Например, клиент может создать машину и выделить для нее чрезмерное количество оперативной памяти. DRS отслеживает подобные моменты и балансирует нагрузку.
Делегирование задач миграции
Использование DRS в автоматическом режиме снимает с администратора задачи по миграции машин в целях балансировки нагрузки. Благодаря этому специалист может посвятить свое время более важным задачам.
Ручная балансировка возможна, но исключительно в рамках небольшой и ненагруженной инфраструктуры. Если ВМ при максимальной нагрузке загружают хост на 50%, смысла в DRS нет. Машины чувствуют себя комфортно, в миграции для балансировки просто нет необходимости. Также DRS не обязателен, если вы можете перевести ВМ на другой хост вручную — например, при технических работах на этом хосте. Если вы четко знаете, сколько машины будут потреблять и до какого объема они могут вырасти, DRS не пригодится.
Что появится в DRS 2.0
Теперь, когда стали более-менее понятны задачи, поставленные перед DRS, и способы их решения, пришло время рассмотреть новую версию DRS, анонсированную на VMworld 2019. В первую очередь стоит сказать об изменении самой парадигмы: ранее DRS концентрировался на балансировке ресурсов в рамках кластера. В DRS 2.0 основным элементом дата-центра станет виртуальная машина, которая может мигрировать как между кластерами, так и между разными физическими дата-центрами. Также в новой версии введена новая модель cost-benefit model (затраты — преимущества). Она расширяет понятие «счастья ВМ» и является сложной метрикой, сформированной из нескольких основных показателей виртуальных машин. Среди них: Host CPU Cache Cost, VM CPU Ready Time, VM Memory Swapped и Workload Burstiness. Новая метрика VM Happiness фактически является основным KPI, к которому будет стремиться DRS при миграции машин. Еще одно значительное изменение коснулось времени срабатывания: DRS 2.0 активируется 1 раз в минуту вместо 1 раза в 5 минут. Это нововведение вытекает из предыдущего пункта: если ранее для создания рекомендаций DRS требовалось создавать снапшоты кластера, то теперь есть показатель VM Happiness. Помимо этого, пользователи получат возможность устанавливать интервал опроса «счастья ВМ». В DRS 2.0 также появилась возможность производить сетевую балансировку нагрузки при перемещении машин. Теперь это полноценная метрика, которая позволит DRS принимать решения при балансировке.

Другие изменения коснулись механизма установки пороговых значений при миграции. Пока не известно, когда DRS 2.0 станет доступен для всех, однако известно, что он уже почти год работает в облаке VMware Cloud on AWS и пока не вызвал нареканий. Мы обязательно будем следить за развитием событий и держать вас в курсе.
Прошел уже почти год с момента как я опубликовал последнюю запись на тему документа по Best Practices в VMware 7.0. Изначально я не планировал разбирать его дальше раздела, посвященного виртуальным машинам, однако результаты посещаемости сайта говорят о том, что данный цикл интересен читателю и было бы неплохо его закончить.
В течение следующих частей мы посмотрим на рекомендации VMware по управлению виртуальной инфраструктурой. Сегодня на очереди vCenter Server, vMotion, DRS, DPM.
Еще раз напоминаю, что это вольное изложение и часть информации из документа будет опущена, а что-то может быть сформулировано не совсем корректно. Не забудьте ознакомиться с оригинальным документом.
Для тех, кто здесь впервые, рекомендую предварительно ознакомиться с другими частями:
General Resource Management
Гипервизор ESXi предоставляет пользователю несколько механизмов для конфигурации и распределения ресурсов между виртуальными машинами. При этом ручное распределение вычислительных ресурсов может оказать значительное влияние на производительность виртуальных машин. Отсюда следует ряд рекомендаций:
- Следует использовать Reservation, Shares и Limits только в случае необходимости;
- Если ожидаются частые изменения в инфраструктуре, которые могут влиять на общее количество доступных ресурсов, стоит использовать Shares, а не Reservation для честного распределения ресурсов между виртуальными машинами;
- При использовании Reservation, рекомендуется указывать минимально необходимое количество CPU или RAM, а не резервировать все ресурсы для виртуальной машины. После того, как резерв будет удовлетворен, оставшиеся ресурсы будут распределены на основании показателя Shares. Не стоит выставлять большие значения Reservations, это может помещать запуску других виртуальных машин, которым не остается свободных ресурсов в пуле;
- При использовании резервов, всегда необходимо оставлять свободные ресурсы для работы гипервизора и прочих служб, например, DRS и миграции;
- Чтобы полностью изолировать пул ресурсов, необходимо использовать тип Fixed, а также включить для него Reservation и Limit;
- Если сервис состоит из нескольких виртуальных машин (multi-tier service), стоит группировать данные виртуальные машины в рамках одного пула ресурсов для управления потребностями на уровне сервиса целиком.
VMware vCenter
- vCenter Server должен получать достаточное количество вычислительных и дисковых ресурсов для функционирования;
- Количество потребляемых ресурсов и производительность напрямую зависит от размера инфраструктуры (количество хостов, виртуальных машин и т.п.), а также от количества подключенных клиентов. Превышение допустимых максимумов однозначно скажется на производительности в худшую сторону, и к тому же не поддерживается;
- Для получения минимальных задержек при работе vCenter с базой данных, следует минимизировать количество сетевых узлов между ними;
- Сетевые задержки между vCenter Server и хостами ESXi могут влиять на производительность операций, в которые вовлечены данные хосты.
VMware vCenter Database Considerations
Работа vCenter напрямую зависит от работоспособности и производительности базы данных, в которой он хранит конфигурационную информацию о всем окружении, статистику, задачи, события и т.д.
VMware vCenter Database Network and Storage Considerations
- Если vCenter Appliance использует thin или lazy-zeroed диски, процесс загрузки может быть дольше, чем в случае использования дисков в формате eager-zeroed;
- В крупных инсталляциях могут генерироваться большие объемы данных и хорошей практикой будет наблюдение за утилизацией дискового пространства. Как настроить оповещения сказано в соответствующей KB.
VMware vCenter Database Configuration and Maintenance
- Следует использовать statistic level в соответствии с текущими требованиями. Данное значение может варьироваться от 1 до 4, но 1 достаточно в большинстве случаев. Более высокие значения могут замедлить работу vCenter, а также увеличится потребление дискового пространства. В случае, если необходим более высокий уровень статистики, например, при отладке, по окончанию данного процесса его следует снизить;
- При запуске vCenter формирует пул из 50 потоков для подключения к БД. Размер данного пула меняется динамически в зависимости от работы vCenter и не требует модификации. Однако, при необходимости, размер данного пула может быть изменен до 128 потоков, при этом следует учитывать, что это увеличит потребление ОЗУ и может снизить скорость загрузки VC;
- При необходимости подключения к БД VCSA следует воспользоваться материалом из данной KB;
- В случае, если наблюдается медленное выполнение запросов, производительность может быть увеличена с помощью выполнения процедуры Vacuum and Analyze на базе данных VCDB.
PostgreSQL (vPostgres) Database Recommendations
В качестве базы данных vCenter использует PostgreSQL (vPosgress). Несмотря на то, что на этапе инсталляции, оптимизация работы базы данных выполняется автоматически, есть некоторые моменты на которые стоит обратить внимание:
- vCenter Server Appliance создает несколько виртуальных дисков в момент инсталляции. Для улучшения производительности в больших окружениях следует убедиться, что виртуальные диски с партициями /storage/db, /storage/dblog и /storage/seat располагаются на разных физических дисках;
- На виртуальном диске /storage/dblog хранятся транзакционные логи базы данных. vCenter особенно чувствителен к производительности данной партиции, в связи с чем виртуальный диск с данным разделом рекомендуется располагать на высокопроизводительном хранилище с наименьшим временем отклика;
- Несмотря на то, что у PostgreSQL имеется свой собственный кэш, данные так же кэшируются на уровне операционной системы. Таким образом, производительность может быть улучшена за счет увеличения кэша ОС. Сделать это можно увеличив объем ОЗУ, выделенный виртуальной машине с vCenter Server, после чего, часть выделенной оперативной памяти будет задействована под кэш;
- При достижении размера партиции /storage/dblog примерно до 90%, происходит сброс транзакционных логов. Чем быстрее заполняется этот раздел – тем чаще происходит операция сброса, увеличивая при этом количество дисковых операций. Увеличение размеров данной партиции снижает частоту сброса логов и уменьшает общий ввод-вывод. Это может помочь в больших инфраструктурах, однако, здесь есть и минусы – в случае необходимости восстановления после сбоя, данная процедура может занять большее время;
- Для мониторинга дискового пространства можно использовать параметры vpxd.vdb.space.errorPercent и vpxd.vdb.space.warningPercent в расширенных настройках vCenter Server;
- Так же для мониторинга можно использовать плагин pgtop для vCenter Server Appliance.
VMware vMotion and Storage vMotion
VMware vMotion Recommendations
- Виртуальные машины, создаваемые в vSphere 7.0, имеют версию vHardware 17 (а в более свежих апдейтах – 18). Поскольку виртуальные машины с vHardware версии 17 могут запускаться только на хостах ESXi 7.0 и выше, vMotion для данных VM будет функционировать только в рамках хостов, поддерживающих данную версию;
- Начиная с версии 6.5 vSphere поддерживает шифрование при выполнении операций миграции vMotion. Шифрование выполняется как на источнике, так и на приемнике, поэтому в случае миграции виртуальной машины на хост, версия которого ниже, чем 6.5, шифрования траффика при операциях vMotion производиться не будет;
- Производительность vMotion со включенным шифрованием будет значительно выше, в случае если хост поддерживает инструкции AES_NI (Intel’s Advanced Encryption Standard New Instruction Set). Без поддержки данных инструкций, производительность vMotion может быть неприемлемой;
- Зашифрованные виртуальные машины всегда используют Encrypted vMotion при миграции. Для нешифрованных виртуальных машин, шифрование может быть отключено (Disabled), обязательно (Required) и «по возможности» (Opportunistic);
- Производительность vMotion напрямую зависит от скорости сети, поэтому рекомендуется иметь сетевое подключение 10GB/s и выше для сети, которая задействована под миграцию;
- Все vmknic для vMotion следует располагать на одном и том же виртуальном свитче, при этом каждая из подгрупп, к которым они подключены, должна использовать разные физические интерфейсы в качестве активного аплинка;
- В случае использования сети 40GB/s, рекомендуется сконфигурировать минимум 3 vMotion vmknics. Использование нескольких vmknic позволяет создавать множество потоков vMotion, утилизируя при этом большее количество процессорных ядер и увеличивая общую производительность;
- При выполнении операций vMotion, ESXi старается зарезервировать процессорные ресурсы на источнике и приемнике, с целью максимальной утилизации пропускной способности сети. Количество резервируемого CPU зависит от количества vMotion NICs и их скорости, и составляет 10% производительности процессорного ядра за каждый 1Gb/s сетевого интерфейса, или же 100% процессорного ядра за каждый 10GB/s сетевой интерфейс, c минимальным резервом в 30%. Из этого вытекает то, что всегда следует держать незарезервированные процессорные ресурсы, чтобы процессы vMotion могли полностью утилизировать доступный сетевой канал и выполнять миграции быстрее;
- Производительность vMotion может быть снижена, если swap уровня хоста размещен на локальных дисках (SSD или HDD).
VMware Storage vMotion Recommendations
- Производительность Storage vMotion напрямую зависит от инфраструктуры хранения данных, от скорости подключения ESXi к хранилищам, от скорости работы хранилища-источника и хранилища-приемника. В момент операции миграции происходит чтение данных виртуальной машины из источника и запись в приемник, при этом виртуальная машина продолжает функционировать;
- Storage vMotion будет иметь максимальную производительность в моменты низкой активности в сети хранения и если перемещаемые виртуальные машины при этом не создают большого дискового ввода-вывода;
- Одна операция миграции позволяет перемещать до 4-х дисков виртуальной машины одновременно, но при этом на один Datastore будет копироваться не более одного диска одновременно. Например, перемещение 4-х дисков VMDK с хранилища A в хранилище B будет выполняться последовательно диск за диском, в то время, как перемещение четырех дисков VMDK с хранилищ A, B, C, D в хранилища E, F, G, H будут идти параллельно;
- Как вариант, можно использовать anti-affinity правила для дисков виртуальных машин, тем самым выполнять операции svMotion на разные Datastore параллельно;
- При выполнении операции Storage vMotion на более быстрое хранилище, эффект будет заметен только по окончанию процедуры миграции. В то же время эффект от перемещения на более медленное хранилище будет проявляться постепенно с операцией копирования;
- Storage vMotion работает значительно лучше на массивах, поддерживающих VAAI.
VMware Cross-Host Storage vMotion Recommendations
Cross-host Storage vMotion позволяет перемещать виртуальные машины одновременно между хостами и хранилищами.
- Cross-host Storage vMotion оптимизирован для работы с блоками размером 1MB, который уже достаточно давно является размером блока, выбираемым по умолчанию для VMFS. Однако, при создании хранилищ VM на VMFS3 размер блока мог быть выбран другой и при апгрейде хранилища до VMFS5 он не изменялся. В таком случае, самым верным вариантом будет пересоздать хранилище;
- При использовании 40GB/s интерфейсов, применяются те же правила, что и для обычного vMotion, и рекомендуется использовать 3 vMotion vmknics;
- Аналогичным образом одновременно копируется 4 диска и применяются те же правила, что и при Storage vMotion;
- В большинстве своем, Cross-host Storage vMotion для миграции виртуальных дисков использует сеть vMotion. Однако, если оба хоста, между которыми выполняется миграция, подключены к одному и тому же массиву, поддерживающему VAAI, и хост-источник имеет доступы к Datastore, на который будет мигрирована виртуальная машина, в таком случае будет задействован VAAI функционал массива. Если же VAAI не поддерживается, будет задействована сеть хранения данных для копирования дисков, а не сеть vMotion;
При миграции выключенных виртуальных машин, Cross-host Storage vMotion будет использовать технологию Network File Copy (NFC). Однако, как и в случае со включенными виртуальными машинами, NFC будет задействовать VAAI, если это возможно, или же сеть хранения данных (нужно помнить, что это будет возможно только в случае, если хост-источник имеет доступ к хранилищу, куда перемещается машина).
Примечание: до vSphere 6.0 NFC использовал только management сеть. Начиная с vSphere 6.0, NFC траффик все так же использует сеть управления по умолчанию, однако, теперь для нужд NFC можно выделить отдельный интерфейс (vmknic Storage Replication).
VMware Distributed Resource Scheduler (DRS)
DRS in General
- Следует следить за рекомендациями DRS, особенно в случае использования ручных ограничений и правил. В некоторых случаях невыполнение текущих рекомендаций может помешать генерации новых;
- В случае использования affinity rules, следует наблюдать за DRS Faults и ошибками в работе DRS, которые могут возникать из-за препятствия существующих правил балансировке. Устранение текущих ошибок может значительно помочь с балансировкой существующей нагрузки;
- Начиная с vSphere 7.0 привычная метрика cluster-level balance была заменена на новую – Cluster DRS Score, которая является индикатором состояния кластера и виртуальных машин в данном кластере.
DRS Cluster Configuration Setting
DRS affinity rules позволяют обеспечивать нахождение группы виртуальных машин в рамках одного хоста (VM/VM affinity), в то время как anti-affinity rules, препятствуют этому (VM/VM anti-affinity). Правила DRS так же позволяют явно указать хосты, на которых будут запускаться виртуальные машины (VM/Host affinity), или наоборот не будут (VM/Host anti-affinity).
В большинстве случаев, отказ от использования affinity rules позволит получить наилучший эффект от работы DRS, однако в некоторых случаях, данные правила могут улучшить производительность и обеспечить высокую доступность для сервисов.
Доступны следующие правила:
- Keep Virtual Machines Together – позволяет достичь повышения производительности за счет уменьшения задержек при взаимодействии между виртуальными машинами в группе;
- Separate Virtual Machines – Использование данного правила для группы VM, предоставляющих один и тот же сервис, позволит повысить доступность сервиса, за счет исключения ситуации, при которой все виртуальные машины, обеспечивающие один и тот же сервис оказались на одном хосте, с которым возникли неполадки;
- Virtual Machines to Hosts – Включает в себя правила Must run on, Should run on, Must not run on и Should not run on, которые могут применяться, например, в случае с лицензированием, поскольку ограничивают круг хостов, на которых могут запускаться VM.
DRS Cluster Sizing and Resource Settings
- Превышение допустимых максимумов по количеству хостов, виртуальных машин, пулов ресурсов не поддерживается. Несмотря на то, что система с превышенными максимумами может оставаться работоспособной, это может повлиять на производительность vCenter Server и DRS;
- С осторожностью следует подходить к установке reservations, shares и limits. Слишком большой резерв может оставить мало незарезервированных ресурсов в кластере, что повлияет на DRS. В то же время слишком низкие лимиты могут препятствовать виртуальной машине в использовании свободных ресурсов, что скажется на ее производительности;
- DRS учитывает NetIOC (NIOC) при расчетах рекомендаций;
- Как уже упоминалось выше, для операций vMotion следует оставлять свободные ресурсы CPU на хостах.
DRS Performance Tuning
Начиная с vSphere 7.0 реакция механизма DRS зависит от типа нагрузок и настраивается соответственно нагрузкам в кластере. Всего таких уровней 5:
Level 1 – Только необходимая миграция, например, при вводе хоста в режим Maintenance. На текущем уровне DRS не предлагает миграцию с целью улучшения производительности;
Level 2 – Используется для стабильных рабочих нагрузок. DRS рекомендует миграцию виртуальных машин, только в моменты нехватки ресурсов;
Level 3 – Уровень по умолчанию. Подходит для большинства стабильных нагрузок;
Level 4 – Для систем, которым свойственны всплески при потреблении ресурсов и требуется реакция DRS;
Level 5 – Данный уровень следует использовать для динамичных нагрузок, потребление ресурсов которых постоянно изменяется.
В vSphere имеется ряд функций, которые могут упростить управление кластером:
- VM Distribution – DRS старается равномерно распределять виртуальные машины в кластере, тем самым косвенно повышая доступность систем;
- Начиная с vSphere 7.0 в дополнении к процессорным ресурсам и оперативной памяти, DRS учитывает так же и пропускную способность сети, когда формирует рекомендации по перемещению VM.
Обще вышеуказанных опции доступны в разделе Additional Options настроек DRS.
Для получения высоких показателей DRS Score, возможно, следует ослабить действующие в кластере правила, изменить уровень реагирования DRS, либо снизить потребление ресурсов в кластере.
Есть несколько причин, по которым DRS Score может быть занижен:
- Миграции препятствуют affinity и anti-affinity правила;
- Миграции препятствуют несовместимые хосты в кластере;
- Затраты ресурсов на миграцию могут быть выше, чем ожидаемые преимущества после ее выполнения;
- На всех хостах в кластере повышенная загрузка сетевых интерфейсов;
- В кластере нет свободных ресурсов, чтобы удовлетворить потребности виртуальных машин.
VMware Distributed Power Management (DPM)
VMware Distributed Power Management позволяет экономить электроэнергию, в моменты, когда хосты в кластере не утилизированы и не находятся под нагрузкой. Данный функционал позволяет консолидировать виртуальные машины на группе хостов, после чего переводит высвободившиеся гипервизоры в Standby режим. DPM поддерживает достаточную вычислительную емкость в кластере, чтобы удовлетворить нужды всех виртуальных машин. В моменты, когда потребность в ресурсах увеличивается, DPM включает дополнительные хосты и переносит на них виртуальные машины, приводя кластер к сбалансированному состоянию.
Начиная с vSphere 7.0, DPM учитывает всю выделенную оперативную память для виртуальных машин и поскольку эти значения достаточно стабильны, в большинстве случаев работа DPM зависит от процессорной утилизации.
DPM использует DRS, а значит большинство практик, применяемых к DRS, применяются и к DPM.
VMware предусматривает широкий спектр служб и программ для повышения отказоустойчивости.
Есть как службы, работающие автономно, так и службы, управляемые администраторами.
В данном разделе поподробнее остановимся на пяти из них:
Подходы к обеспечению отказоустойчивости
VMware High Availability (HA)
VMware High Availability (HA) – функция высокой доступности.
Возможности VMware HA позволяют повысить отказоустойчивость виртуальной инфраструктуры и сделать непрерывным бизнес компании.
Суть возможностей VMware HA заключается в перезапуске виртуальной машины отказавшего сервера VMware ESX с общего хранилища (собственно, сам VMware HA), а также рестарте зависшей виртуальной машины на сервере при потере сигнала от VMware Tools (VM Monitoring).

Данная функция, несомненно, повышает отказоустойчивость, однако для нее существует ряд ограничений, а имeнно:
Виртуальных машин на хост с числом хостов VMware ESX 8 и менее - максимально 100; Виртуальных машин на хост с числом хостов VMware ESX 8 и менее для vSphere 4.0 Update 1 - максимально 160; Виртуальных машин на хост с числом хостов VMware ESX 9 и более - максимально 40;Для крупных компаний такие числа могут быть недостаточными, так что эта функция полезна для малого и среднего бизнеса, однако, стоит заметить, что компания VMware объявила о своих намерениях в ближайшем будущем эти показатели повысить. Сейчас в кластере HA может быть только 5 primary хостов ESX, чего явно недостаточно для создания катастрофоустойчивого решения на уровне possible failure domain. Кроме того, на данный момент нет прозрачного механизма назначения хостов как primary или secondary, что тоже вызывает иногда проблемы. В этом плане компания VMware уже прилагает усилия, чтобы сделать такие кластеры VMware HA, которые будут переживать неограниченное число отказов хостов VMware ESX.
Другими словами High Availability - средство отказоустойчивости виртуальных машин, позволяющее в случае отказа физического хост-сервера автоматически перезапустить его виртуальные машины с общего хранилища
VM Monitoring
VM Monitoring, как уже говорилось выше, - служба мгновенной перезагрузки виртуальной машины при потери тактовых импульсов от утилиты VMTools, установленной на эту ВМ.
VM Monitoring довольно долго были в статусе experimental, но сегодня они уже доступны для промышленного использования. Однако VMware пока не спешит их ставить по умолчанию - неудивительно, ведь пользователи не раз сталкивались с ситуацией, когда VM Monitoring на ранних этапах своего развития давал сбой и попусту перезагружал виртуальные машины.
Здесь задача VMware состоит в техническом усовершенствовании возможностей VM Monitoring, а также постепенное завоевание доверия пользователей.
VMware Fault Tolerance (FT)
VMware Fault Tolerance (FT) – средство непрерывной доступности виртуальных машин, позволяющее поддерживать резервную работающую копию виртуальной машины на другом сервере, которая мгновенно переключает на себя нагрузку в случае отказа основной машины.
Она позволяет защитить виртуальные машины с помощью кластеров непрерывной доступности, позволяющих в случае отказа хоста с основной виртуальной машиной мгновенно переключиться на ее «теневую» работающую копию на другом сервере ESX.
Иными словами, данная функция создает такую же ВМ, но назначенную параметром Backup VM, которая мгновенно становится Primary VM после прекращения приема пакета тактовых импульсов, отсылающихся пакетом VMTools виртуальной машины, сервером.

Теневые ВМ должны находиться на разных машинах ESX с основной ВМ:
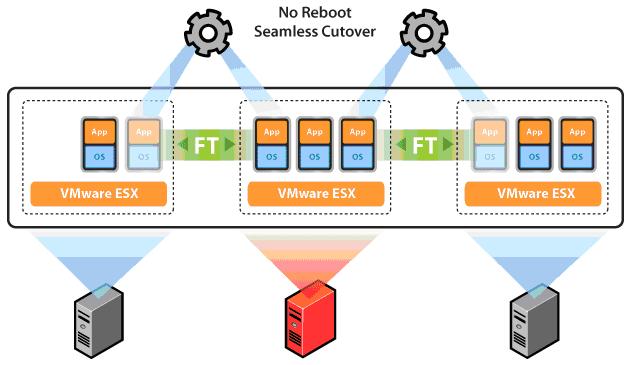
У такой технологии есть как свои положительные стороны, так и отрицательные.
Данная технология позволяет максимизировать отказоустойчивость отдельных ВМ, что, конечно же, обрадует заказчика.
Но представьте, если создать каждой ВМ такую теневую машину.
Теневая ВМ это такая же ВМ с такими же характеристиками, что и основная, только готовая в любой момент времени встать на ее место. При увеличении в два раза ВМ, также увеличатся и потребляемые ресурсы При включении данной технологии будут наложены существенные ограничения на отношения ВМ и хостов, систему хранения и сетевые параметры данной ВМ.
У ВМ как Primary, так и Secondary есть несколько ограничений:
Эксперты выделяют несколько правил, при которых технология FT будет применяться с наибольшим коэффициентом полезного действия:
На саму ВМ с включенным FT также будут наложены ограничения. Основные из них:
VMware FT рекомендован к использованию к следующим ВМ:
Следует отметить, что данная служба (FT) недоступна пользователям, купившим пакет Essentials и Essentials Plus
Distributed Resource Scheduler (DRS)
Distributed Resource Scheduler (DRS) – технология, выравнивающая нагрузку серверов ESX. Данная функция необходима, если в системе образуется сервер с максимальными нагрузками на нем. DRS перебрасывает ресурсы на более низко используемые серверы, таким образом, усредняя коэффициент использования всех серверов.
В следующей версии VSphere Client’а будет доступна также технология DRS for Storage.
VMware Site Recovery Manager (SRM)
VMware Site Recovery Manager (SRM) – продукт автоматизирующий процессы аварийного восстановления, создания и тестирования планов восстановления после катастроф.
Данный продукт предлагает передовые возможности управления аварийным восстановлением, тестирования без прерывания работы и автоматизированного аварийного переключения.
VMware vCenter Site Recovery Manager поддерживает управление аварийным переключением на резервные инфраструктуры, а также между двумя инфраструктурами с активными рабочими нагрузками.
Более того, возможно восстановление нескольких инфраструктур из одной общей резервной системы.
Site Recovery Manager также помогает обеспечить плановое аварийное переключение ЦОД, например при их переносе.
Управление аварийным восстановлением:
Тестирование без прерывания работы:
Автоматизированное аварийное переключение:
Преимущества перехода на виртуальную среду
При виртуализации есть несколько серьезных преимуществ, по сравнению с физическим аналогом построения инфраструктуры:
Эксплуатационная гибкость
С помощью виртуализации мы добьемся оперативного реагирования на изменения рынка благодаря динамическому управлению ресурсами, ускоренной инициализации серверов и улучшенного развертывания настольных компьютеров и приложений.
Увеличение отдачи от существующих ресурсов
Возможность объединения общих ресурсов инфраструктуры в пулы и уход от устаревшей модели «один сервер — одно приложение» с помощью консолидации серверов.
Софтверная поддержка
В случае виртуализации ВМ используют ресурсы серверов, на которых они находятся.
Но сама идея виртуализации в том, что на ВМ, например не стоят ЦПУ от компании Intel или AMD, виртуализация поддерживает серверы с разными конфигурациями, а, следовательно, на ВМ на данный момент идет большинство ОС и почти весь поддерживаемый софт этими ОС.
Следовательно, на одних и тех же по характеристикам серверах, возможно, развертывать совершенно независимые друг от друга, и разные по характеристикам ВМ, также и наоборот, серверы с разными характеристиками будут поддерживать один кластер, в котором будут находиться несколько ВМ.
Планирование
С помощью удобного клиента управления всей структурой vSphere администратор сможет полностью отслеживать процессы, происходящие с серверами, а также при внедрении дальнейшего оборудования, это поможет гораздо упростить и сделать более прозрачной всю структуру виртуальных систем.
Сокращение расходов
Виртуализация позволяет уменьшать число физических серверов по сравнению с числом растущих виртуальных машин, что позволит сократить расходы на оборудование, энергопотребление, а также персонал, который будет все это обслуживать.
Отказоустойчивость
При внедрении виртуализации, благодаря технологиям VMware, а именно: HA FT DRS и т.д., возможно не только сохранить свой уровень отказоустойчивости до консолидирования ВМ, но и повысить его.
Ниже описаны технологии обеспечения надежности виртуальной системы, а также пути их внедрения.
На ранних этапах консолидирования виртуальных технологий, будет сохранен тот же уровень надежности, но в дальнейшим при достаточно большой инфраструктуре серверного оборудования, данная инфраструктура, основанная на физическом решении, будет постепенно терять надежность с увеличением оборудования, в то время как виртуальная будет его всегда удерживать на определенном уровне.
Итак, мы рассмотрели 5 параметров, повышающих отказоустойчивость системы до максимума.
Такие параметры, как HA, FT и DRS являются возможностями платформы, наличие которых будет зависеть от комплектации купленного пакета VMware.
VM Monitoring присутствует во всех версиях платформ, а SRM является отдельным полноценным продуктом компании VMWare, который поставляется также с vCenter Server.
Для более полного представления о том, как их совмещать и где использовать, заказчику следует предварительно проконсультироваться со специалистами, для того, чтобы они исследовали все его характеристики серверного оборудования, и дали более полную оценку консолидации виртуализации в данном проекте.
Читайте также: