
Vmware ha cluster настройка
Обновлено: 02.07.2024
High Availability – технология кластеризации, созданная для повышения доступности системы, и позволяющая, в случае выхода из строя одного из узлов ESXi, перезапустить его виртуальные машины на других узлах ESXi автоматически, без участия администратора.
Общие сведения High Availability
В прошлый раз шла речь о технологиях, используемых в VMware для обеспечения отказоустойчивой системы, в этой же статье подробнее остановимся на VMware HA – VMware High Availability (механизме высокой доступности).
Для того чтобы создать HA кластер, нам необходимо, чтобы все виртуальные машины этого кластера хранились на общем хранилище данных*. При этом если у нас выходит из строя один из узлов ESXi, все виртуальные машины с этого узла будут запущены на свободных слотах (мощностях) других ESXi узлов кластера.
*Общее хранилище данных может представлять собой не только «железную» СХД, но и быть программным. У VMware для этой цели есть продукт vSAN (virtual storage area network). У RedHat есть GlusterFS и т.д.
Список терминов
Isolation response (IR) – параметр, определяющий действие ESXi-хоста при прекращении им получения сигналов доступности кластера. При создании кластера на каждый ESXi-хост устанавливается HA Agent, который будет обмениваться сигналами доступности (Heartbeat);
Reservation – параметр, рассчитывающийся на основе максимальных отдельных характеристик всех ВМ в кластере и в дальнейшем использующийся для расчета Failover Capacity;
Failover Capacity (FCap) – параметр, определяющий реальную отказоустойчивость. Измеряется в целых числах и обозначает, какое максимальное количество серверов в кластере может выйти из строя, после чего сам кластер всё еще будет продолжать функционировать;
Number of host failures allowed (NHF) – параметр задается администратором. Определяет целевой уровень отказоустойчивости. Такое количество узлов ESXi может одновременно выйти из строя;
Состояние Admission Control (состояние ADC) – автоматически рассчитывается как отношение Failover Capacity к Number of host failures allowed;
Параметр Admission Control (параметр ADC) – назначается администратором. Определяет поведение виртуальных машин при недостаточности слотов для их запуска;
Restart Priority (RP) – приоритет запуска машин после падения одного из узлов ESXi, входящих в кластер.
Последовательность создания VMware HA кластера
Определяем количество и размер слотов на узлах ESXi (Reservation); Устанавливаем значение Number of host failures allowed (NHF); Сравниваем NHF и FCap. Если NHF больше FCap, нам необходимо: Либо установить параметр ADC в Allow virtual machine to be started even if they violate availability constraints; Устанавливаем параметр Admission Control в одно из состояний; Определяем поведение хоста при прекращении получения сигналов доступности от остальных узлов (Isolation Response);Isolation Response
Действия при прекращении получения сигналов доступности в кластере HA определяются значением Isolation Response, определяющим действие узла ESXi при прекращении им получения сигналов доступности кластера (Heartbeat). Прекращение получения сигналов доступности происходит из-за «изоляции» ESXi, например, в случае отказа сетевой карты.
Существует несколько предполагаемых сценариев развития событий:
Сбой отправки/получения сигналов доступности, но сама сеть продолжает функционировать; Перестала работать сеть между узлом ESXi и остальными узлами кластера, но ESXi продолжает функционировать;В первом случае, стоит выбрать значение параметра Isolation Response - Leave powered on, тогда все машины, продолжат свою работу, невзирая на то, что прекратят получать сигналы доступности.
Во втором случае следует выбрать Isolation Response – Power off либо Shutdown (установлен по умолчанию), если ESXi-хост перестал получать сигналы доступности, HA перенесет с общего хранилища ВМ, хранившиеся на этом хосте ESXi, на свободные ESXi-хосты. ESXi-хост должен автоматически выключаться, чтобы не возникало конфликтов двух одинаковых хостов.
По умолчанию Isolation Response установлен в режиме Power off. Мы не знаем как будут развиваться события в момент гипотетического отказа, поэтому мы рекомендуем оставлять значение IR в состоянии Power off, чтобы избежать риска появления в сети конфликтующих машин с одинаковыми сетевыми настройками.
Резервация ресурсов (Reservation)
При расчете параметра Failover Capacity кластер HA сначала создает слоты, определяемые параметром Reservation. Этот параметр рассчитывается по размеру максимальной из виртуальных машин, работающих на узлах кластера.
Параметр Failover Capacity
После расчета слотов определяется сам параметр Failover Capacity. Он измеряется в целых числах и обозначает, какое максимальное количество узлов в кластере одновременно может выйти из строя. При этом все машины должны продолжать функционировать.
Иллюстрируем параметр Failover Capacity. Возьмем два случая (по вертикали: 1-й случай - отказ одного узла ESXi, 2-й случай - отказ 2-х узлов ESXi).
Первый случай: 3 узла ESXi, по 4 слота на каждом, 6 виртуальных машин.
В этом случае при выходе из строя одного узла (например, №3), ВМ 4,5,6 будут запущены на других узлах (в нашем случае №2, показаны стрелками), однако, при выходе из строя еще одного узла, свободных слотов под запуск ВМ не останется.
Второй случай: 3 узла ESXi, по 4 слота на каждом, 4 виртуальные машины.
В этом случае, свободных слотов хватит, даже если упадет сразу 2 узла ESXi(в нашем случае, ВМ перенесутся на хост №1).
Технически параметр Failover Capacity рассчитывается следующим образом: из количества всех узлов в кластере мы вычитаем отношение количества виртуальных машин в кластере к количеству слотов на одном узле ESXi. Если получается не целое число, округляем вниз.
Для первого случая: 3-6/4=1.5 Округляем до 1;
Для второго случая: 3-4/4=2 Так и остается 2;
Admission Control
Admission Control мы условно разделили на состояние Admission Control (состояние ADC) и параметр Admission Control (параметр ADC).
Состояние ADC определяется соотношением реального уровня отказоустойчивости (FCap) и установленного администратором (NHF). Если FCap больше NHF, то кластер настроен корректно и проблем ожидать не следует. Если наоборот, то мы должны устанавливать параметр ADC.
Параметр ADC определяется администратором и может иметь два состояния:
Do not power on virtual machines if they violate availability constraints – не включать виртуальные машины, если не достаточно слотов для обеспечения целевого уровня отказоустойчивости; Allow virtual machine to be started even if they violate availability constraints – разрешить запуск виртуальных машин, несмотря на возможную нехватку ресурсов для их запуска;При выборе параметра ADC следует заранее понять, как будет устроен кластер и для каких целей он необходим:
Если наша основная задача – это надежность самого кластера, несмотря на то, какие ВМ будут включены, нам следует установить Admission Control в состояние Do not power on….; Если же нам важно работа всех ВМ в кластере, нам придется установить Admission Control в состояние Allow VM to be started….;Во втором случае, поведение кластера может стать непредсказуемым (в худшем случае может дойти до такого, что ВМ опустят значение ADC до нулевого значения, тем самым сделав бесполезным технологию HA)
Рекомендации по созданию кластера vSphere HA
Мы представим общие рекомендации по созданию кластера HA:
Для кластера с включенной службой HA необходимо, чтобы все виртуальные машины и их данные находились на общем хранилище данных (Fibre Channel SAN, iSCSI SAN, or SAN iSCI NAS). Это необходимо, чтобы включать ВМ на любом из хостов кластера. Это также означает, что узлы должны быть настроены для доступа к тем же самым сетям виртуальной машины, совместно используемой памяти и другим ресурсам; Каждый сервер ESXi в кластере HA производит мониторинг узлов сети для обнаружения сбоев серверов. Чтобы сигналы доступности не прерывались, рекомендуется устанавливать резервные сетевые пути. Если первое сетевое соединение узла перестало функционировать, сигналы доступности (heartbeats) начнут передаваться по второму соединению. Для повышения отказоустойчивости, рекомендуется использовать два и более физических сетевых адаптерах на каждом узле; Если нужно использовать службу DRS совместно с HA для распределения нагрузок по узлам, узлы кластера должны быть частью сети vMotion. Если узлы не включены в vMotion, то DRS может неверно распределять нагрузку на узлы;esxi cluster
| Backup для виртуальных машин | Arcserve для VMware |

Работая с нами Вы, получите:
Наши цены ниже по целому ряду причин:
V-GRADE - является Официальным Партнером VMware уровня Advanced;
Работаем без посредников , напрямую с VMware, Veeam, Arcserve для VMware.
Наши эксперты:
У нас есть конфигуратор VMware, лучшие цены, актуальные статьи. лучшие эксперты.
Практическим применением знаний о работе с массивами EVA и iLO в серверах ProLiant, которые вы получили чуть раньше, может стать развертывание высокодоступного кластера на vSphere.
Кластер может использоваться для предприятий среднего и крупного размера, чтобы уменьшить время внеплановых простоев. Поскольку для бизнеса важны такие параметры как доступность его сервиса или услуги клиенту в режиме 24x7, то такое решение основывается на кластере высокой доступности. В кластер всегда входят как минимум 2 сервера. В нашем решении серверы под управлением VMware отслеживают состояние друг друга, при этом в каждый момент времени ведущим будет только один из них, на нем будет разворачиваться виртальная машина с нашим бизнес-приложением. В случае отказа ведущего сервера его роль автоматически принимает второй, при этом для заказчика доступ к бизнес-приложению практически не прерывается.
1. Описание задачи
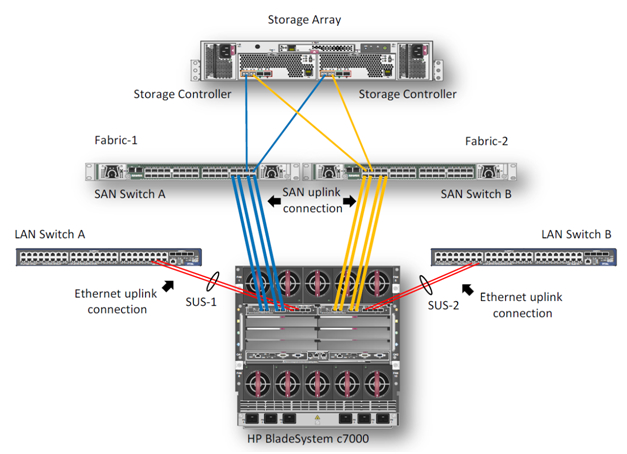
В данном примере мы опишем процесс создания высокодоступного кластера VMware на блейд-серверах BL460c G7. Оборудование состоит из блейд-корзины HP c7000 и двух блейд-серверов BL460c G7, где скофигурирован VMware HA(High Available)-кластер. В демо-центре HP в Москве сейчас доступны только модели блейд-серверов G7, но на основе описанного примера можно собрать кластер и на новых блейд-серверах Gen8. Конфигурирование, в целом, не будет различаться. Система хранения – HP EVA 4400. Для Ethernet и Fibre Channel подключений в корзине c7000 установлены 2 модуля HP Virtual Connect Flex Fabric в отсеках 1 и 2.
2. Описание компонентов

Virtual Connect FlexFabric — конвергентный виртуализированный модуль ввода/вывода для блейд-корзины с7000.
Модуль HP Virtual Connect FlexFabric использует технологии Flex-10, FCoE, Accelerated iSCSI для коммутации блейд-серверов и сетевой инфраструктуры (SAN и LAN) со скоростью 10Gb.
Из возможностей: перенос «профилей» (таблица MAC и WWN серверов) не только между разными лезвиями в шасси, но и на удалённые сайты, где есть такой же блейд-сервер.
Так же при использовании Virtual Connect каждый из двух портов сетевой карты блейд-сервера можно делить на 4 виртуальных порта 1GbE/10GbE/8Gb FC/iSCSI общей пропускной способностью 10GbE на порт. Это позволяет получить от 8 виртуальных портов на сервер (на BL460с G7), которые необходимо задавать при первой инициализации.
Единственное ограничение в том, что HP Virtual Connect FlexFabric не являются полноценными коммутаторами. Это аггрегаторы, для работы которых необходимо иметь отдельные Ethernet- и SAN-свитчи (в последней прошивке, правда, появилась возможность Direct Connect с HP P10000 3PAR).
Общий вид использованного оборудования отражается в Onboard Administrator.

Интегрированная в ProLiant BL460c G7 карта NC553i Dual Port FlexFabric 10Gb может работать с модулями HP Virtual Connect FlexFabric напрямую, без дополнительных мезонин-карт. Два модуля HP Virtual Connect FlexFabric установлены для отказоустойчивости путей связи связи блейд-серверов с системой хранения EVA 4400 и Ethernet-коммутаторами.
В данном примере будем рассматривать сценарий, когда трафик от модуля HP Virtual Connect FlexFabric разделяется на Ethernet-коммутаторы и FC-фабрику. FCoE в этом случае используется для коммутации модулей с блейд-серверами внутри корзины.
Для работы с различными протоколами модулям HP Virtual Connect FlexFabric необходимы трансиверы. В этом примере 4 Gb FC SFP трансиверы были установлены в порты 1 и 2 на каждом из модулей, а 10 Gb SFP+ трансиверы были установлены в порты 4 и 5. 10GbE-каналы использованы в данном тесте чтобы задействовать сетевое оборудование в нашем демо-центре.
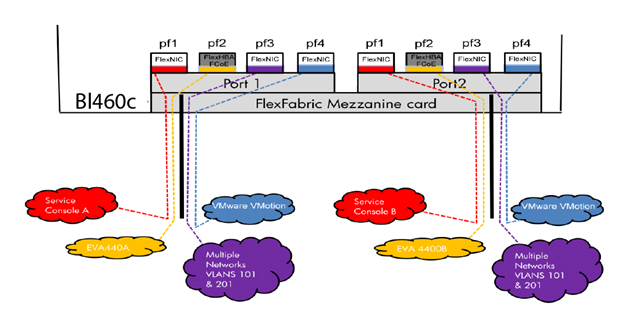
Диаграмма показывает, что 3 порта сетевого адаптера NC553i Dual Port FlexFabric 10Gb сконфигурированы как FlexNIC для взаимодействия виртуальных машин между собой и для подключения к сетевой инфраструктуре. Оставшийся порт был сконфигурирован как FCoE для связи с SAN-инфраструктурой и системой хранения EVA 4400.
Вместе с каждым Virtual Connect модулем поставляется ПО для управления HP Virtual Connect Manager, для Enterprise модулей – HP Virtual Connect Enterprise Manager. С помощью Enterprise Manager можно управлять из одной консоли до 256 доменами (1 домен — 4 Blade системы с Virtual Connect).
После подключения модуля необходимо его сконфигурировать. Делается это либо подключением к Onboard Administrator самой корзины, либо по IP-адресу, который назначается модулю по умолчанию на заводе.
3. Настройка профилей в Virtual Connect Manager
После подключения HP FlexFabric мы должны определить домен, Ethernet-сеть, SAN-фабрику и серверные профили для хостов. Эти настройки производятся в HP Virtual Connect Manager или в командной строке. В нашем примере домен уже был создан, поэтому следующим шагом будет определение VC Sharing Uplink Sets для поддержки Ethernet сетей виртуальных машин с именами HTC-77-A и HTC-77-B. Включаем “Map VLAN tags” функцию в мастере установки.
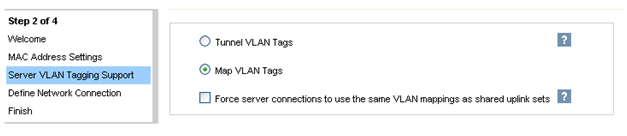
Функция “Map VLAN tags” дает возможность использовать один физический интерфейс для работы с множеством сетей, используя Shared Uplink Set. Таким образом можно настроить множество VLANs на интерфейсе сетевой карты сервера. Параметры Shared Uplink Sets были заданы в мастере установки VCM. Пример задания SUS:
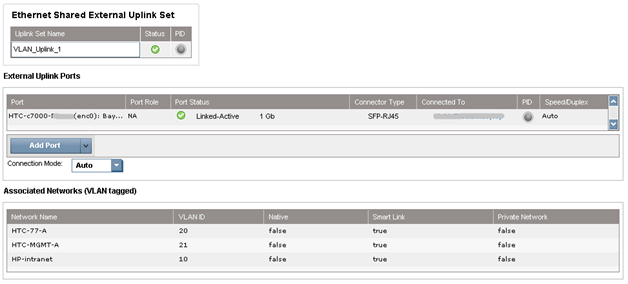
Обе сети «HTC-77-A» и «HTC-MGMT-A» были назначены: VLAN_Uplink_1 на порт 5 модуля 1; второй Shared Uplink Set (VLAN_Uplink_2) был назначен на порт 5 модуля 2, и включает в себя сети HTC-77-B (VLAN 20) и HTC-MGMT-B (VLAN 21). Пример создания сетей Ethernet в VCM:
Модуль HP Virtual Connect может создавать внутренную сеть без аплинков, используя высокопроизводительные 10Gb соединения с бэкплейном корзины с7000. Внутренняя сеть может быть использована для VMware vMotion, а также для организации отказоустойчивости сети. Трафик этой сети не выходит на внешние порты корзины c7000. В нашем случае были настроены 2 сети VMware vMotion. Для консоли управления были настроены две сети с именами HP-MGMT-A и HP-MGMT-B. Порт 6 модулей HP Virtual Connect FlexFabric в отсетках 1 и 2 был использован для подключения к консоли управления.

После этого начинается настройка фабрики SAN. Все довольно просто: в VCM выбрать Define – SAN Fabric. Выбираем SAN-1 модуль в отсеке 1, порт X1. Для второго модуля SAN-2 порт также X1. Пример настройки SAN:

Последним шагом будет «склеивание» всех ранее сделанных настроек в серверный профиль. Это можно сделать несколькими способами: например, через web-интерфейс VCM или через командную строку Virtual Connect – Virtual Connect Scripting Utility (VCSU). Перед установкой ОС необходимо проверить, что все системные, NIC и FC драйверы обновлены, а все параметры сети заданы. Пример создания профиля в CVM:
В VCM выбираем Define – Server Profile, вводим имя профиля и выбираем сетевые подключения профиля из созданных ранее.
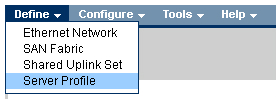
В нашем случае все порты были назначены нами заранее: 6 Ethernet портов и 2 SAN порта на каждый профиль. Профили для отсека 11 и 12 идентичны, т.е. каждый сервер видит один и тот же набор портов. Суммарная скорость не превышает 10Гб/с на каждый порт сетевой карты сервера.
Если в будущем планируется расширение сети, то рекомендуется назначить нераспределенные (unassigned) порты в профиле. Делая так, можно в дальнейшем активировать эти порты без выключения и перезагрузки сервера.
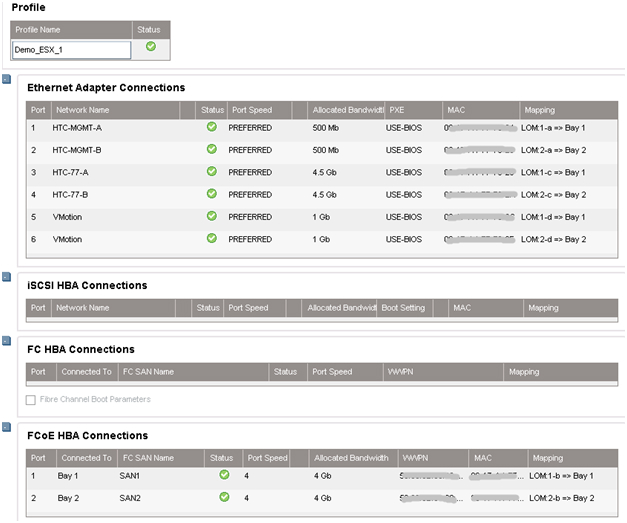
При создании профиля по умолчанию доступны только 2 порта в разделе Ethernet. Чтобы добавить больше, необходимо вызвать контекстное меню правой кнопкой мыши и выбрать “Add connection”.
Назначаем скорость для каждого типа портов: портам управления – 500Mb/s, портам vMotion – 1Gb/s, портам SAN – 4Gb/s и портам виртуальных машин – 4.5Gb/s.
После создания профилей они привязываются к блейд-отсеку корзины в этом же меню.

4. Настройка кластера VMware
На этом настройки корзины завершены. Далее происходит удаленное подключение к самим блейдам и разворачивание VMware ESX 5.0, пример удаленной установки ОС на серверы ProLiant через iLO уже был описан.
В нашем случае вместо Windows в выпадающем меню установщика выбирается VMware и указывается путь к дистрибутиву.
После установки сервер перезагружается и можно приступать к настройке виртуальных машин. Для этого подключаемся к серверу ESX. Заходим в раздел Configuration, создаем 6 vmnics на каждый хост, как и в модуле Virtual Connect: Service Console (vSwitch0), VM Network (vSwitch1), vMotion (vSwitch2). Таким образом мы получаем отказоустойчивую конфигурацию, где каждой сети соответствую 2 vmnics.
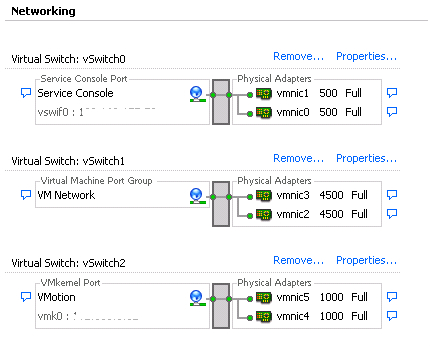
Как только добавляются vmnics можно заметить, что каждому адаптеру автоматически задается скорость, заданная в серверном профиле, при конфигурации в Virtual Connect Manager.
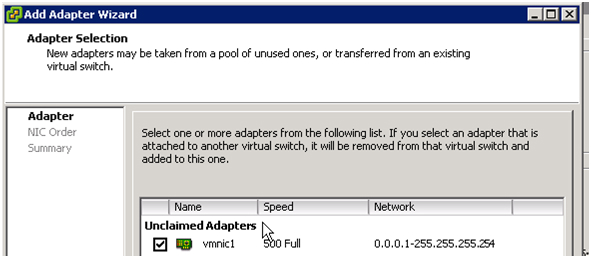
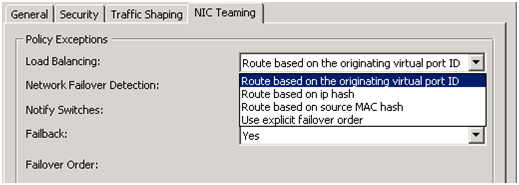
После добавления vmnics объединяем их в группу с помощью vSwitch: вкладка Port – в поле Configuration выбираем vSwitch – Edit, выбираем NIC Teaming, убеждаемся, что оба vmnics видны. Балансировку нагрузки выбираем «Route based on the originating virtual port ID» — эти настройки рекомендуется ставить по умолчанию (подробнее об этом методе можно прочесть на сайте VMware.
5. Настройка дискового массива EVA 4400
В предыдущем обзоре было рассказано как работать с интерфейсом управления дисковыми массивами EVA — Command View.
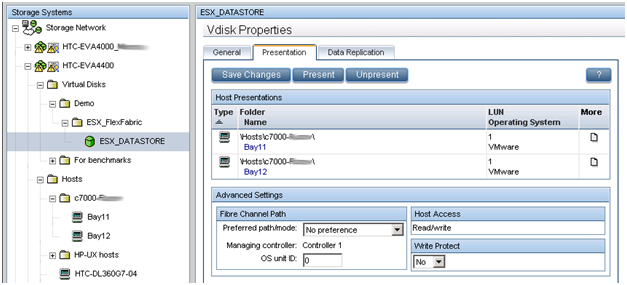
В данном примере мы создаем LUN размером в 500 ГБ, который разделяется между двумя хостами виртуальных машин. По описанному в предыдущей статье методу создается виртуальный диск и презентуется двум хостам ESX. Размер LUN определяется типом ОС и ролями, которые данный кластер будет выполнять. Обязательным условием для кластера (в частности, для VMware vMotion) – LUN должен быть разделяемым. Новый LUN должен быть отформатирован в VMFS, и функция Raw Device mappings (RDMs) для виртуальных машин должна быть задействована.
6. Внедрение VMware HA и VMware vMotion
HP Virtual Connect в сочетании с VMware vMotion дает тот же уровень избыточности, как при использовании двух модулей VC-FC и двух модулей VC-Eth, за исключением того, что только 2 модуля HP FlexFabric необходимы. HP Virtual Connect FlexFabric дает возможность организовать отказоустойчивые пути к общему LUN и отказоустойчивого объединения сетевых интерфейсов (NIC Teaming) для работы в сети. Все настройки VMware vSphere отвечают Best Practices описанным в документе.
Была проведена проверка на доступность кластера. На одном из хостов была развернута виртуальная машина Windows 2008 Server R2.
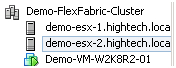
Виртуальная машина вручную несколько раз была смигрирована с одного сервера на другой, во время мигации кластер оставался доступным.
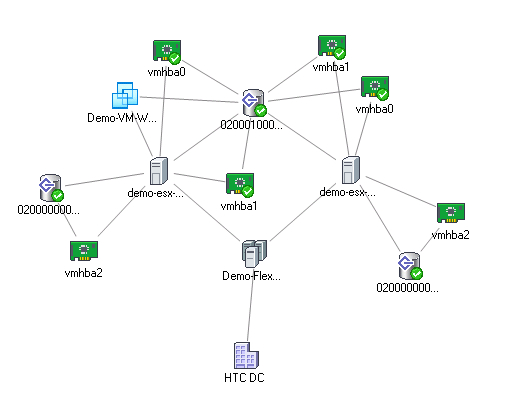
HTC DC – наш DC, Demo-FlexFabric Cluster – наш кластер, Demo-ESX1 и Demo-ESX2 – хосты VMware, vmhba2 – SAS контроллеры блейд-серверов, подключенные к внутренней дисковой подсистеме. Vmhba0 и vmhba1 – два порта встроенных сетевых карт NC553i Dual Port FlexFabric 10Gb Adapter, подключенных к разделяемому LUN EVA 4400. Demo-VM-W2K8R2-01 – виртуальная машина.
Естественно, все не так просто, и перед HA , было произведено немало настроек, посмотреть можно тут.

У меня тут два сервера ESXi, которые управляются через vCenter server. Создано 2 виртуальные машины, файлы которых лежат на LUN-е системы хранения данных FreeNAS (все это было описано ранее). И я создаю новый кластер.

Название кластера, и галочка только напротив HA. Про DRS будет отдельная статья.


тут все по-умолчанию



Сохранять файл подкачки в папке виртуальной машины.

Все готово, кластер почти создан

Создан успешно. Слева вверху видим сам кластер и наши ESXi серверы отдельно. Теперь нужно перенести хосты в кластер. Действуем мышкой, Drug-and-Drop

На каждый сервер ESXi во время добавления в кластер устанавливается агент HA. Если интересно, как именно работает, HA, как установленные агенты обмениваются информацией и устравают выборы мастера, погуглите. Мне важно, что HA работает теперь лучше чем в VMware vSphere 4.1

Теперь чтобы посмотреть, на каком из серверов ESXi в данный момент работает виртуальная машина, нужно смотреть в ее свойства. WinXp закреплена за 106 хостом.

Пришло время проверить, как работает кластер высокой доступности HA, выключаем один из хостов.

Да мы уверены, что хотим выключить, хоть он и не в Maintenance mode. Этот режим нужен, чтобы корректно выводить сервер из эксплуатации, чтобы нечаянно не погасить ВМ, а мне именно это и нужно сейчас.

Выключаешь, укажи причину.

Сначала агент HA, забил тревогу. Потом на виртуальной машине появился красный восклицательный знак.

Отвалился ESXi хост

WinXP почти вернулся в сторой.


Видим что запустился WindowsXP на 115 хосте.

Включил обратно хост 106, но виртуальные машины остались на 115. Чтобы они вернулись обратно нужно делать миграцию vMotion руками . Чтобы они вернулись автоматически требуется DRS.

Давайте уберем надоедливую ошибку "This host currently has no management network redundancy", она говорит о том, что вся отказоустойчивость у нас кончается на одной единственной сетевой карточке. Можно двумя путями пойти, добавить второй сетевой интерфейс (на 106 хосте так сделаю) или просто отключить ошибку, чтобы не отображаласть (для всего кластера).

Заходим в настройки виртуального коммутатора vSwitch0

Во вкладке Network Adapters -> Add

Выбираю свободный сетевой интерфейс vmnic1

В этой вкладке можно указать, какие сетевые интерфейсы будут активны, а какие будут в запасе, ждать пока активные сломаются.


Готово, две сетевые карты подключены к виртуальному коммутатору, а ошибка все так же горит.

Чтобы кластру стало понятно, что этот хост теперь заполучил нормальную отказоустойчивость, необходимо его переконфигурировать.

Ошибка исчезла, теперь отключим отображение этого предупреждения для всего кластера HA
В данной статье мы рассмотрим настройку кластера HA, DRS в Vsphere6.
Открываем Vcenter web client, переходим в раздел Hosts and clusters.

Вводим имя кластера и нажимаем Ok.

Далее перемещаем хосты в кластер

Выбираем хосты и жмем Ok.

Рассмотрим пример включения HA.


Далее нажимаем Edit и настраиваем HA.

Включаем HA, мониторинг хостов ESXI, также можно включить мониторинг виртуальных машин и приложений внутри VM. Для работы последних необходимы установленные vmware tools на виртуальной машине.

Теперь, если один из хостов ESXI (размещенных в кластере) выйдет из строя, vm будут перезапущены на соседнем хосте ESXI.
Важно чтобы на всех серверах размещенных в кластере хватало ресурсов для перезапуска VM.
Так же важно чтобы совпадали инструкции процессоров. Если в вашем случае на хостах используются разные процессоры, поможет функция EVC.
Для включения данной функции перейдем в раздел Manage, расположенный в настройках кластера.

Нажимаем Edit, и включаем данную функцию.
Выбираем тип процессора, и EVC mode.

Рассмотрим настройку DRS.
Отличие DRS в том что Vcenter сам определяет на каких хостах какие VM хранить. В данном случае Vcenter распределяет VM по хостам в зависимости от нагрузки.
Переходим в раздел Manage нашего кластера.
Выбираем Vsphere DRS.

Нажимаем Edit и настраиваем DRS.

Можно выбрать уровень автоматизации DRS.

Так же возможно настроить расписание работы DRS.
Настроить его можно в разделе Manage.

В расписании можно указать когда DRS будет выполнять свои задачи.

Также в DRS возможно настроить управление питанием хостов ESXI.
Например если один из хостов израсходовал ресурсы, DRS может перенести с него VM, перезагрузить хост, вернуть VM обратно. Таким образом DRS освободит часть ресурсов.
Настроить это можно в настройках DFS, в пункте Power management.

В режиме manual, Vcenter будет рекомендовать как поступать с нагруженными хостами
В режиме Automatic, Vcenter будет управлять питанием хостов самостоятельно.
Для корректной работы данного режима Vcenter использует технологии WOL, IPMI, ILO.
Для использования этих технологий используется DPM, для его корректной работы требуется дистрибутив ESXI от производителя вашего сервера.
На этом все. В следующей статье мы рассмотрим технологию fault tolerance, ручное распределение ресурсов хоста для виртуальной машины.
Читайте также: