
Что такое файлы с неплотным индексом или индексно последовательные файлы
Обновлено: 02.07.2024
Несмотря на высокую эффективность хэш-адресации, в файловых структурах далеко не всегда удается найти соответствующую функцию, поэтому при организации доступа по первичному ключу широко используются индексные файлы. В некоторых коммерческих системах индексными файлами называются также и файлы, организованные в виде инвертированных списков, которые используются для доступа по вторичному ключу. Мы будем придерживаться классической интерпретации индексных файлов и надеемся, что если вы столкнетесь с иной интерпретацией, то сумеете разобраться в сути, несмотря на некоторую путаницу в терминологии. Наверное, это отчасти связано с тем, что область баз данных является достаточно молодой областью знаний, и несмотря на то, что здесь уже выработалась определенная терминология, многие поставщики коммерческих СУБД предпочитают свой упрощенный сленг при описании собственных продуктов. Иногда это связано с тем, что в целях рекламы они не хотят ссылаться на старые, хорошо известные модели и методы организации информации в системе, а изобретают новые названия при описании своих моделей, тем самым пытаясь разрекламировать эффективность своих продуктов. Хорошее знание принципов организации данных поможет вам объективно оценивать решения, предлагаемые поставщиками современных СУБД, и не попадаться на рекламные крючки.
Индексные файлы можно представить как файлы, состоящие из двух частей. Это не обязательно физическое совмещение этих двух частей в одном файле, в большинстве случаев индексная область образует отдельный индексный файл, а основная область образует файл, для которого создается индекс. Но нам удобнее рассматривать эти две части совместно, так как именно взаимодействие этих частей и определяет использование механизма индексации для ускорения доступа к записям.
Мы предполагаем, что сначала идет индексная область, которая занимает некоторое целое число блоков, а затем идет основная область, в которой последовательно расположены все записи файла.
В зависимости от организации индексной и основной областей различают 2 типа файлов: с плотным индексом и с неплотным индексом. Эти файлы имеют еще дополнительные названия, которые напрямую связаны с методами доступа к произвольной записи, которые поддерживаются данными файловыми структурами.
Файлы с плотным индексом называются также индексно-прямыми файлами, а файлы с неплотным индексом называются также иидексно-последовательными файлами. Смысл этих названий нам будет ясен после того, как мы более подробно рассмотрим механизмы организации данных файлов.
Знаете ли Вы, в чем фокус эксперимента Майкельсона? Эксперимент А. Майкельсона, Майкельсона - Морли - действительно является цирковым фокусом, загипнотизировавшим физиков на 120 лет.Дело в том, что в его постановке и выводах произведена подмена, аналогичная подмене в школьной шуточной задачке на сообразительность, в которой спрашивается:
- Cколько яблок на березе, если на одной ветке их 5, на другой ветке - 10 и так далее
При этом внимание учеников намеренно отвлекается от того основополагающего факта, что на березе яблоки не растут, в принципе.
В эксперименте Майкельсона ставится вопрос о движении эфира относительно покоящегося в лабораторной системе интерферометра. Однако, если мы ищем эфир, как базовую материю, из которой состоит всё вещество интерферометра, лаборатории, да и Земли в целом, то, естественно, эфир тоже будет неподвижен, так как земное вещество есть всего навсего определенным образом структурированный эфир, и никак не может двигаться относительно самого себя.
Удивительно, что этот цирковой трюк овладел на 120 лет умами физиков на полном серьезе, хотя его прототипы есть в сказках-небылицах всех народов всех времен, включая барона Мюнхаузена, вытащившего себя за волосы из болота, и призванных показать детям возможные жульничества и тем защитить их во взрослой жизни. Подробнее читайте в FAQ по эфирной физике.
Попробуем усовершенствовать способ хранения файла: будем хранить его в упорядоченном виде и применим алгоритм двоичного поиска для доступа к произвольной записи. Тогда время доступа к произвольной записи будет существенно меньше. Для нашего примера это будет:
T = log2KBO = log212500 = 14 обращений к диску .
И это существенно меньше, чем 12 500 обращений при произвольном хранении записей файла. Однако и поддержание основного файла в упорядоченном виде также операция сложная.
Неплотный индекс строится именно для упорядоченных файлов. Для этих файлов используется принцип внутреннего упорядочения для уменьшения количества хранимых индексов. Структура записи индекса для таких файлов имеет следующий вид:
В индексной области мы теперь ищем нужный блок по заданному значению первичного ключа. Так как все записи упорядочены, то значение первой записи блока позволяет нам быстро определить, в каком блоке находится искомая запись. Все остальные действия происходят в основной области. На рис. 9.8 представлен пример заполнения основной и индексной областей, если первичным ключом являются целые числа.

Рис. 9.8. Пример заполнения индексной и основной области при организации неплотного индекса
Время сортировки больших файлов весьма значительно, но поскольку файлы поддерживаются сортированными с момента их создания, накладные расходы в процессе добавления новой информации будут гораздо меньше.
Оценим время доступа к произвольной записи для файлов с неплотным индексом. Алгоритм решения задачи аналогичен.
Сначала определим размер индексной записи. Если ранее ссылка рассчитывалась исходя из того, что требовалось ссылаться на 100 000 записей, то теперь нам требуется ссылаться всего на 12 500 блоков, поэтому для ссылки достаточно двух байт. Тогда длина индексной записи будет равна:
LI = LK + 2 = 14 + 2 = 14 байт .
Тогда количество индексных записей в одном блоке будет равно:
KIZB = LB/LI = 1024/14 = 73 индексные записи в одном блоке .
Определим количество индексных блоков, которое необходимо для хранения требуемых индексных записей:
KIB = KBO/KZIB = 12500/73 = 172 блока .
Тогда время доступа по прежней формуле будет определяться:
Tпоиска = log2KIB + 1 = log2172 + 1 = 8 + 1 = 9 обращений к диску .
Мы видим, что при переходе к неплотному индексу время доступа уменьшилось практически в полтора раза. Поэтому можно признать, что организация неплотного индекса дает выигрыш в скорости доступа.
Рассмотрим процедуры добавления и удаления новой записи при подобном индексе.
Здесь механизм включения новой записи принципиально отличен от ранее рассмотренного. Здесь новая запись должна заноситься сразу в требуемый блок на требуемое место, которое определяется заданным принципом упорядоченности на множестве значений первичного ключа. Поэтому сначала ищется требуемый блок основной памяти, в который надо поместить новую запись, а потом этот блок считывается, затем в оперативной памяти корректируется содержимое блока и он снова записывается на диск на старое место. Здесь, так же как и в первом случае, должен быть задан процент первоначального заполнения блоков, но только применительно к основной области. В MS SQL server этот процент называется Full-factor и используется при формировании кластеризованных индексов . Кластеризованными называются как раз индексы, в которых исходные записи физически упорядочены по значениям первичного ключа. При внесении новой записи индексная область не корректируется.
Количество обращений к диску при добавлении новой записи равно количеству обращений, необходимых для поиска соответствующего блока плюс одно обращение, которое требуется для занесения измененного блока на старое место.
Tдобавления = log2N +1 + 1 обращений .
Уничтожение записи происходит путем ее физического удаления из основной области, при этом индексная область обычно не корректируется, даже если удаляется первая запись блока. Поэтому количество обращений к диску при удалении записи такое же, как и при добавлении новой записи.
Организация индексов в виде B-tree (В-деревьев)
Калькированный термин "B-дерево", в котором смешивается английский символ "B" и добавочное слово на русском языке, настолько устоялся в литературе, посвященной организации физического хранения данных, что я не решусь его корректировать.
Встретив как-то термин "Б-дерево", я долго его трактовала, потому что привыкла уже к устоявшемуся обозначению. Поэтому будем работать с этим термином.
Построение В-деревьев связано с простой идеей построения индекса над уже построенным индексом. Действительно, если мы построим неплотный индекс, то сама индексная область может быть рассмотрена нами как основной файл, над которым надо снова построить неплотный индекс, а потом снова над новым индексом строим следующий и так до того момента, пока не останется всего один индексный блок.
Мы в общем случае получим некоторое дерево, каждый родительский блок которого связан с одинаковым количеством подчиненных блоков, число которых равно числу индексных записей, размещаемых в одном блоке. Количество обращений к диску при этом для поиска любой записи одинаково и равно количеству уровней в построенном дереве. Такие деревья называются сбалансированными (balanсed) именно потому, что путь от корня до любого листа в этом древе одинаков. Именно термин "сбалансированное" от английского "balanced" — "сбалансированный, взвешенный" и дал название данному методу организации индекса.
Построим подобное дерево для нашего примера и рассчитаем для него количество уровней и, соответственно, количество обращений к диску.
На первом уровне число блоков равно числу блоков основной области, это нам известно, — оно равно 12 500 блоков. Второй уровень образуется из неплотного индекса, мы его тоже уже строили и вычислили, что количество блоков индексной области в этом случае равно 172 блокам. А теперь над этим вторым уровнем снова построим неплотный индекс.
Мы не будем менять длину индексной записи, а будем считать ее прежней, равной 14 байтам. Количество индексных записей в одном блоке нам тоже известно, и оно равно 73. Поэтому сразу определим, сколько блоков нам необходимо для хранения ссылок на 172 блока.
KIB3 = KIB2/KZIB = 172/73 = 3 блока
Мы снова округляем в большую сторону, потому что последний, третий, блок будет заполнен не полностью.
И над третьим уровнем строим новый, и на нем будет всего один блок, в котором будет всего три записи. Поэтому число уровней в построенном дереве равно четырем, и соответственно количество обращений к диску для доступа к произвольной записи равно четырем (рис. 9.9). Это не максимально возможное число обращений, а всегда одно и то же, одинаковое для доступа к любой записи.

Механизм добавления и удаления записи при организации индекса в виде В-дерева аналогичен механизму, применяемому в случае с неплотным индексом.
И наконец, последнее, что хотелось бы прояснить, — это наличие вторых названий для плотного и неплотного индексов.
В случае плотного индекса после определения местонахождения искомой записи доступ к ней осуществляется прямым способом по номеру записи, поэтому этот способ организации индекса и называется индексно-прямым.
В случае неплотного индекса после нахождения блока, в котором расположена искомая запись, поиск внутри блока требуемой записи происходит последовательным просмотром и сравнением всех записей блока. Поэтому способ индексации с неплотным индексом называется еще и индексно-последовательным.
Попробуем усовершенствовать способ хранения файла: будем хранить его в упорядоченном виде и применим алгоритм двоичного поиска для доступа к произвольной записи. Тогда время доступа к произвольной записи будет существенно меньше. Для нашего примера это будет:
Т = log 2 KBO = log 2 12500 = 14 обращений к диску.
И это существенно меньше, чем 12 500 обращений при произвольном хранении записей файла. Однако и поддержание основного файла в упорядоченном виде также операция сложная.
Неплотный индекс строится именно для упорядоченных файлов. Для этих файлов используется принцип внутреннего упорядочения для уменьшения количества хранимых индексов. Структура записи индекса для таких файлов имеет следующий вид:
Значение ключа первом записи блока
Номер блока с этой записью
В индексной области мы теперь ищем нужный блок по заданному значению первичного ключа. Так как все записи упорядочены, то значение первой записи блока позволяет нам быстро определить, в каком блоке находится искомая запись. Все остальные действия происходят в основной области. На рис. 9.8 представлен пример заполнения основной и индексной областей, если первичным ключом являются целые числа.
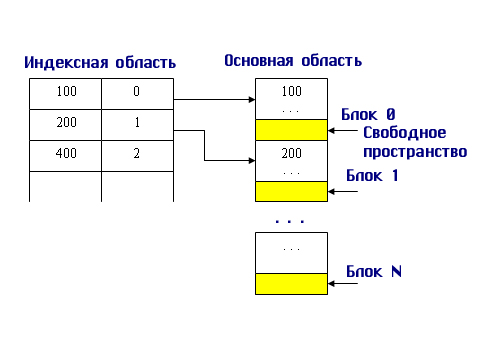
Рис. 9.8. Пример заполнения индексной и основной области при организации неплотного индекса
Время сортировки больших файлов весьма значительно, но поскольку файлы поддерживаются сортированными с момента их создания, накладные расходы в процессе добавления новой информации будут гораздо меньше. Оценим время доступа к произвольной записи для файлов с неплотным индексом. Алгоритм решения задачи аналогичен.
Сначала определим размер индексной записи. Если ранее ссылка рассчитывалась исходя из того, что требовалось ссылаться на 100000 записей, то теперь нам требуется ссылаться всего на 12 500 блоков, поэтому для ссылки достаточно двух байт. Тогда длина индексной записи будет равна:
LI = LK + 2 = 14 + 2 - 14 байт.
Тогда количество индексных записей в одном блоке будет равно:
KIZB = LB/LI = 1024/14 = 73 индексные записи в одном блоке.
Определим количество индексных блоков, которое необходимо для хранения требуемых индексных записей:
KIB = KBO/KZIB = 12500/73 = 172 блока.
Тогда время доступа по прежней формуле будет определяться:
Т поиска = log 2 KIB + 1 = log 2 172 + 1=8+1=9 обращений к диску.
Мы видим, что при переходе к неплотному индексу время доступа уменьшилось практически в полтора раза. Поэтому можно признать, что организация неплотного индекса дает выигрыш в скорости доступа.
Рассмотрим процедуры добавления и удаления новой записи при подобном индексе.
Здесь механизм включения новой записи принципиально отличен от ранее рассмотренного. Здесь новая запись должна заноситься сразу в требуемый блок на требуемое место, которое определяется заданным принципом упорядоченности на множестве значений первичного ключа. Поэтому сначала ищется требуемый блок основной памяти, в который надо поместить новую запись, а потом этот блок считывается, затем в оперативной памяти корректируется содержимое блока и он снова записывается на диск на старое место. Здесь, так же как и в первом случае, должен быть задан процент первоначального заполнения блоков, но только применительно к основной области. В MS SQL server этот процент называется Full-factor и используется при формировании кластеризованных индексов. Кластеризованными называются как раз индексы, в которых исходные записи физически упорядочены по значениям первичного ключа. При внесении новой записи индексная область не корректируется.
Количество обращений к диску при добавлении новой записи равно количеству обращений, необходимых для поиска соответствующего блока плюс одно обращение, которое требуется для занесения измененного блока на старое место.
Т добавлений = log 2 N +1 + 1 обращений.
Уничтожение записи происходит путем ее физического удаления из основной области, при этом индексная область обычно не корректируется, даже если удаляется первая запись блока. Поэтому количество обращений к диску при удалении записи такое же, как и при добавлении новой записи.
Знаете ли Вы, что, как и всякая идолопоклонническая религия, релятивизм ложен в своей основе. Он противоречит фактам. Среди них такие:1. Электромагнитная волна (в религиозной терминологии релятивизма - "свет") имеет строго постоянную скорость 300 тыс.км/с, абсурдно не отсчитываемую ни от чего. Реально ЭМ-волны имеют разную скорость в веществе (например,
200 тыс км/с в стекле и
3 млн. км/с в поверхностных слоях металлов, разную скорость в эфире (см. статью "Температура эфира и красные смещения"), разную скорость для разных частот (см. статью "О скорости ЭМ-волн")
2. В релятивизме "свет" есть мифическое явление само по себе, а не физическая волна, являющаяся волнением определенной физической среды. Релятивистский "свет" - это волнение ничего в ничем. У него нет среды-носителя колебаний.
3. В релятивизме возможны манипуляции со временем (замедление), поэтому там нарушаются основополагающие для любой науки принцип причинности и принцип строгой логичности. В релятивизме при скорости света время останавливается (поэтому в нем абсурдно говорить о частоте фотона). В релятивизме возможны такие насилия над разумом, как утверждение о взаимном превышении возраста близнецов, движущихся с субсветовой скоростью, и прочие издевательства над логикой, присущие любой религии.
4. В гравитационном релятивизме (ОТО) вопреки наблюдаемым фактам утверждается об угловом отклонении ЭМ-волн в пустом пространстве под действием гравитации. Однако астрономам известно, что свет от затменных двойных звезд не подвержен такому отклонению, а те "подтверждающие теорию Эйнштейна факты", которые якобы наблюдались А. Эддингтоном в 1919 году в отношении Солнца, являются фальсификацией. Подробнее читайте в FAQ по эфирной физике.
Попробуем усовершенствовать способ хранения файла: будем хранить его в упорядоченном виде и применим алгоритм двоичного поиска для доступа к произвольной записи. Тогда время доступа к произвольной записи будет существенно меньше. Для нашего примера это будет:
T = log2KBO = log212500 = 14 обращений к диску .
И это существенно меньше, чем 12 500 обращений при произвольном хранении записей файла. Однако и поддержание основного файла в упорядоченном виде также операция сложная.
Неплотный индекс строится именно для упорядоченных файлов. Для этих файлов используется принцип внутреннего упорядочения для уменьшения количества хранимых индексов. Структура записи индекса для таких файлов имеет следующий вид:
В индексной области мы теперь ищем нужный блок по заданному значению первичного ключа. Так как все записи упорядочены, то значение первой записи блока позволяет нам быстро определить, в каком блоке находится искомая запись. Все остальные действия происходят в основной области. На рис. 9.8 представлен пример заполнения основной и индексной областей, если первичным ключом являются целые числа.
Рис. 9.8. Пример заполнения индексной и основной области при организации неплотного индекса
Время сортировки больших файлов весьма значительно, но поскольку файлы поддерживаются сортированными с момента их создания, накладные расходы в процессе добавления новой информации будут гораздо меньше.
Оценим время доступа к произвольной записи для файлов с неплотным индексом. Алгоритм решения задачи аналогичен.
Сначала определим размер индексной записи. Если ранее ссылка рассчитывалась исходя из того, что требовалось ссылаться на 100 000 записей, то теперь нам требуется ссылаться всего на 12 500 блоков, поэтому для ссылки достаточно двух байт. Тогда длина индексной записи будет равна:
LI = LK + 2 = 14 + 2 = 14 байт .
Тогда количество индексных записей в одном блоке будет равно:
KIZB = LB/LI = 1024/14 = 73 индексные записи в одном блоке .
Определим количество индексных блоков, которое необходимо для хранения требуемых индексных записей:
KIB = KBO/KZIB = 12500/73 = 172 блока .
Тогда время доступа по прежней формуле будет определяться:
Tпоиска = log2KIB + 1 = log2172 + 1 = 8 + 1 = 9 обращений к диску .
Мы видим, что при переходе к неплотному индексу время доступа уменьшилось практически в полтора раза. Поэтому можно признать, что организация неплотного индекса дает выигрыш в скорости доступа.
Рассмотрим процедуры добавления и удаления новой записи при подобном индексе.
Здесь механизм включения новой записи принципиально отличен от ранее рассмотренного. Здесь новая запись должна заноситься сразу в требуемый блок на требуемое место, которое определяется заданным принципом упорядоченности на множестве значений первичного ключа. Поэтому сначала ищется требуемый блок основной памяти, в который надо поместить новую запись, а потом этот блок считывается, затем в оперативной памяти корректируется содержимое блока и он снова записывается на диск на старое место. Здесь, так же как и в первом случае, должен быть задан процент первоначального заполнения блоков, но только применительно к основной области. В MS SQL server этот процент называется Full-factor и используется при формировании кластеризованных индексов . Кластеризованными называются как раз индексы, в которых исходные записи физически упорядочены по значениям первичного ключа. При внесении новой записи индексная область не корректируется.
Количество обращений к диску при добавлении новой записи равно количеству обращений, необходимых для поиска соответствующего блока плюс одно обращение, которое требуется для занесения измененного блока на старое место.
Tдобавления = log2N +1 + 1 обращений .
Уничтожение записи происходит путем ее физического удаления из основной области, при этом индексная область обычно не корректируется, даже если удаляется первая запись блока. Поэтому количество обращений к диску при удалении записи такое же, как и при добавлении новой записи.
Организация индексов в виде B-tree (В-деревьев)
Калькированный термин "B-дерево", в котором смешивается английский символ "B" и добавочное слово на русском языке, настолько устоялся в литературе, посвященной организации физического хранения данных, что я не решусь его корректировать.
Встретив как-то термин "Б-дерево", я долго его трактовала, потому что привыкла уже к устоявшемуся обозначению. Поэтому будем работать с этим термином.
Построение В-деревьев связано с простой идеей построения индекса над уже построенным индексом. Действительно, если мы построим неплотный индекс, то сама индексная область может быть рассмотрена нами как основной файл, над которым надо снова построить неплотный индекс, а потом снова над новым индексом строим следующий и так до того момента, пока не останется всего один индексный блок.
Мы в общем случае получим некоторое дерево, каждый родительский блок которого связан с одинаковым количеством подчиненных блоков, число которых равно числу индексных записей, размещаемых в одном блоке. Количество обращений к диску при этом для поиска любой записи одинаково и равно количеству уровней в построенном дереве. Такие деревья называются сбалансированными (balanсed) именно потому, что путь от корня до любого листа в этом древе одинаков. Именно термин "сбалансированное" от английского "balanced" — "сбалансированный, взвешенный" и дал название данному методу организации индекса.
Построим подобное дерево для нашего примера и рассчитаем для него количество уровней и, соответственно, количество обращений к диску.
На первом уровне число блоков равно числу блоков основной области, это нам известно, — оно равно 12 500 блоков. Второй уровень образуется из неплотного индекса, мы его тоже уже строили и вычислили, что количество блоков индексной области в этом случае равно 172 блокам. А теперь над этим вторым уровнем снова построим неплотный индекс.
Мы не будем менять длину индексной записи, а будем считать ее прежней, равной 14 байтам. Количество индексных записей в одном блоке нам тоже известно, и оно равно 73. Поэтому сразу определим, сколько блоков нам необходимо для хранения ссылок на 172 блока.
KIB3 = KIB2/KZIB = 172/73 = 3 блока
Мы снова округляем в большую сторону, потому что последний, третий, блок будет заполнен не полностью.
И над третьим уровнем строим новый, и на нем будет всего один блок, в котором будет всего три записи. Поэтому число уровней в построенном дереве равно четырем, и соответственно количество обращений к диску для доступа к произвольной записи равно четырем (рис. 9.9). Это не максимально возможное число обращений, а всегда одно и то же, одинаковое для доступа к любой записи.
Механизм добавления и удаления записи при организации индекса в виде В-дерева аналогичен механизму, применяемому в случае с неплотным индексом.
И наконец, последнее, что хотелось бы прояснить, — это наличие вторых названий для плотного и неплотного индексов.
В случае плотного индекса после определения местонахождения искомой записи доступ к ней осуществляется прямым способом по номеру записи, поэтому этот способ организации индекса и называется индексно-прямым.
В случае неплотного индекса после нахождения блока, в котором расположена искомая запись, поиск внутри блока требуемой записи происходит последовательным просмотром и сравнением всех записей блока. Поэтому способ индексации с неплотным индексом называется еще и индексно-последовательным.
Читайте также: