Что такое импорт и экспорт файлов
Обновлено: 04.07.2024
Итак, пришло время перейти к реальным данным. Мы начнем с использования датасета (так мы будем называть любой набор данных) по супергероям. Этот датасет представляет собой табличку, каждая строка которой - отдельный супергерой, а столбик — какая-либо информация о нем. Например, цвет глаз, цвет волос, вселенная супергероя 11 , рост, вес, пол и так далее. Несложно заметить, что этот датасет идеально подходит под структуру датафрейма: прямоугольная табличка, внутри которой есть разные колонки, каждая из которой имеет свой тип (числовой или строковый).
6.1 Рабочая папка и проекты RStudio
Для начала скачайте файл по ссылке
Он, скорее всего, появился у Вас в папке “Загрузки.” Если мы будем просто пытаться прочитать этот файл (например, с помощью read.csv() — мы к этой функцией очень скоро перейдем), указав его имя и разрешение, то наткнемся на такую ошибку:
Это означает, что R не может найти нужный файл. Вообще-то мы даже не сказали, где искать. Нам нужно как-то совместить место, где R ищет загружаемые файлы и сами файлы. Для этого есть несколько способов.
- Магомет идет к горе: перемещение файлов в рабочую папку.
Для этого нужно узнать, какая папка является рабочей с помощью функции getwd() (без аргументов), найти эту папку в проводнике и переместить туда файл. После этого можно использовать просто название файла с разрешением:
Кроме того, путь к рабочей папке можно увидеть в RStudio во вкладке с консолью, в самой верхней части (прямо под надписью “Console”):

- Гора идет к Магомету: изменение рабочей папки.
Можно просто сменить рабочую папку с помощью setwd() на ту, где сейчас лежит файл, прописав путь до этой папки. Теперь файл находится в рабочей папке:
Этот вариант использовать не рекомендуется! Как минимум, это сразу делает невозможным запустить скрипт на другом компьютере. Ну а если все-таки вдруг повезет и получится, то ваш коллега будет очень недоволен, что ваш скрипт изменяет рабочую директорию.
- Гора находит Магомета по месту прописки: указание полного пути файла.
Этот вариант страдает теми же проблемами, что и предыдущий, поэтому тоже не рекомендуется!
Для пользователей Windows есть дополнительная сложность: знак / является особым знаком для R, поэтому вместо него нужно использовать двойной // .
- Магомет использует кнопочный интерфейс: Import Dataset.
Во вкладке Environment справа в окне RStudio есть кнопка “Import Dataset.” Возможно, у Вас возникло непреодолимое желание отдохнуть от написания кода и понажимать кнопочки — сопротивляйтесь этому всеми силами, но не вините себя, если не сдержитесь.
Многие функции в R, предназначенные для чтения файлов, могут прочитать файл не только на Вашем компьютере, но и сразу из интернета. Для этого просто используйте ссылку вместо пути:
- Каждый Магомет получает по своей горе: использование проектов в RStudio.
На первый взгляд это кажется чем-то очень сложным, но это не так. Это очень просто и ОЧЕНЬ удобно. При создании проекта создается отдельная папка, где у вас лежат данные, хранятся скрипты, вспомогательные файлы и отчеты. Кроме папки создается файл формата .Rproj, в котором хранятся настройки проекта. Если нужно вернуться к другому проекту — просто открываете другой проект, с другими файлами и скриптами. Можно даже иметь открытыми несколько окон RStudio таким образом. Это еще помогает не пересекаться переменным из разных проектов — а то, знаете, использование двух переменных data в разных скриптах чревато ошибками. Поэтому очень удобным решением будет выделение отдельного проекта под этот курс.
При закрытии проекта все переменные по умолчанию тоже будут сохраняться, а при открытии — восстанавливаться (а вот пакеты все равно придется подгружать заново). Это очень удобно, хотя некоторые рекомендуют от этого отказаться. Это можно сделать во вкладке Tool - Global Options.
6.2 Организация проектов
Даже если не пользоваться проектами RStudio (но я настоятельно рекомендую, это очень удобно), то все равно имеет смысл разделять различные свои проекты по отдельным папкам. Для небольших проектов этого уже может быть достаточно, но я рекомендую делать немного более сложную структуру папок внутри проекта. Например, такую:
В основной папке содержится автоматически созданный RStudio файл .Rproj, основной скрипт с формат .R (или же это может быть .Rmd файл — см. 12). Вспомогательные скрипты (например, с функциями) могут храниться в папке R. Если скриптов несколько, то их порядок стоит обозначить числами:
Данные стоит держать в отдельной папке, причем в некоторых ситуациях вы захотите создать отдельные подпапки, например, отдельные подпапки для данных на входе, временных файлов и данных на выходе. Результаты работы, например, отчеты, сгенерированные с помощью R Markdown (см. 12). Туда же можно поместить папку с графиками или же можно поместить эту папку в корневую директорию.
Это лишь пример структуры организации проектов, детали могут различаться, но такая структура позволит не заблудиться в собственных файлах, если тех накопилось достаточно много. Кроме того, другому человеку в такой структуре проекта будет разобраться значительно проще
При создании папок внутри основного проекта важно помнить о том, что теперь ваши файлы больше нельзя найти в вашей корневой директории: нужно искать их в соответствующих папках. Это значит, что путь до файла теперь будет не "heroes_information.csv" , а "data/heroes_information.csv" или даже "data/raw/heroes_information.csv" .
Пакет позволяет удобно работать с путями на любых операционных системах, создавая путь в зависимости от вашей корневой директории проекта.
Созданный путь можно использовать для чтения файлов:
Сами скрипты тоже лучше разделять на смысловые части. Для этого есть горячие клавиши Cmd + Shift + R . Это сочетание клавиш выведет окно, в котором вам нужно вписать название, после чего появится вот такой аккуратный комментарий:
Разделенный на такие части скрипт (да еще и с подробными комментариями) гораздо удобнее читать!
6.2.1 Табличные данные: текстовые и бинарные данные
Как Вы уже поняли, импортирование данных - одна из самых муторных и неприятных вещей в R. Если у Вас получится с этим справится, то все остальное - ерунда. Мы уже разобрались с первой частью этого процесса - нахождением файла с данными, осталось научиться их читать.
Здесь стоит сделать небольшую ремарку. Довольно часто данные представляют собой табличку. Или же их можно свести к табличке. Такая табличка, как мы уже выяснили, удобно репрезентируется в виде датафрейма. Но как эти данные хранятся на компьютере? Есть два варианта: в бинарном и в текстовом файле.
Текстовый файл означает, что такой файл можно открыть в программе “Блокнот” или аналоге (например, TextEdit на macOS) и увидеть напечатанный текст: скрипт, роман или упорядоченный набор цифр и букв. Нас сейчас интересует именно последний случай. Таблица может быть представлена как текст: отдельные строчки в файле будут разделять разные строчки таблицы, а какой-нибудь знак-разделитель отделять колонки друг от друга.
Для чтения данных из текстового файла есть довольно удобная функция read.table() . Почитайте хэлп по ней и ужаснитесь: столько разных параметров на входе! Но там же вы увидете функции read.csv() , read.csv2() и некоторые другие — по сути, это тот же read.table() , но с другими параметрами по умолчанию, соответствующие формату файла, который мы загружаем. В данном случае используется формат .csv, что означает “Comma Separated Values” (Значения, Разделенные Запятыми). Формат .csv — это самый известный способ хранения табличных данных в файде на сегодняшний день. Файлы с расширением .csv можно легко открыть в любой программе, работающей с таблицами, в том числе Microsoft Excel и его аналогах.
Файл с расширением .csv — это просто текстовый файл, в котором “закодирована” таблица: разные строчки разделяют разные строчки таблицы, а столбцы отделяются запятыми (отсюда и название). Вы можете вручную создать такие файлы в Блокноте и сохранять их с форматом .csv - и такая табличка будет нормально открываться в Microsoft Excel и других программах для работы с таблицами. Можете попробовать это сделать самостоятельно!
Как говорилось ранее, в качестве разделителя ячеек по горизонтали — то есть разделителя между столбцами — используется запятая. С этим связана одна проблема: в некоторых странах (в т.ч. и России) принято использовать запятую для разделения дробной части числа, а не точку, как это делается в большинстве стран мира. Поэтому есть альтернативный вариант формата .csv, где значения разделены точкой с запятой ( ; ), а дробные значения - запятой ( , ). В этом и различие функций read.csv() и read.csv2() — первая функция предназначена для “международного” формата, вторая - для (условно) “Российского.” Оба варианта формата имеют расширение .csv, поэтому заранее понять какой именно будет вариант довольно сложно, приходится либо пробовать оба, либо заранее открывать файл в текстовом редакторе.
В первой строчке обычно содержатся названия столбцов - и это чертовски удобно, функции read.csv() и read.csv2() по умолчанию считают первую строчку именно как название для колонок.
Кроме .csv формата есть и другие варианты хранения таблиц в виде текста. Например, .tsv — тоже самое, что и .csv, но разделитель - знак табуляции. Для чтения таких файлов есть функция read.delim() и read.delim2() . Впрочем, даже если бы ее и не было, можно было бы просто подобрать нужные параметры для функции read.table() . Есть даже функции, которые пытаются сами “угадать” нужные параметры для чтения — часто они справляются с этим довольно удачно. Но не всегда. Поэтому стоит научиться справляться с любого рода данными на входе.
Итак, прочитаем наш файл. Для этого используем только параметр file = , который идет первым, и для параметра stringsAsFactors = поставим значение FALSE :
Параметр stringsAsFactors = задает то, как будут прочитаны строковые значения - как уже знакомые нам строки или как факторы. По сути, факторы - это примерно то же самое, что и character, но закодированные числами. Когда-то это было придумано для экономии используемых времени и памяти, сейчас же обычно становится просто лишней морокой. Но некоторые функции требуют именно character, некоторые factor, в большинстве случаев это без разницы. Но иногда непонимание может привести к дурацким ошибкам. В данном случае мы просто пока обойдемся без факторов. Если у вас версия R выше 4.0.0, то stringsAsFactors = будет FALSE по умолчанию.
Можете проверить с помощью View(heroes) : все работает! Если же вылезает какая-то странная ерунда или же просто ошибка - попробуйте другие функции ( read.table() , read.delim() ) и покопаться с параметрами. Для этого читайте Help .
6.3 Проверка импортированных данных
При импорте данных обратите внимания на предупреждения (если таковые появляются), в большинстве случаев они указывают на то, что данные импортированы некорректно.
Проверим, что все прочиталось нормально с помощью уже известной нам функции str() :
Всегда проверяйте данные на входе и никогда не верьте на слово, если вам говорят, что данные вычищенные и не содержат никаких ошибок.
На что нужно обращать внимание?
Прочитаны ли пропущенные значения как NA . По умолчанию пропущенные значения обозначаются пропущенной строчкой или “NA,” но встречаются самые разнообразные варианты. Возможные варианты кодирования пропущенных значений можно задать в параметре na.strings = функции read.table() и ее вариантов. В нашем датасете как раз такая ситуация, где нужно самостоятельно задавать, какие значения будут прочитаны как NA . Попытайтесь самостоятельно догадаться, как именно.
Прочитаны ли те столбики, которые должны быть числовыми, как int или num . Если в колонке содержатся числа, а написано chr (= "character" ) или Factor (в случае если stringsAsFactors = TRUE ), то, скорее всего, одна из строчек содержит в себе нечисловые знаки, которые не были прочитаны как NA .
Странные названия колонок. Это может случиться по самым разным причинам, но в таких случаях стоит открывать файл в другой программе и смотреть первые строчки. Например, может оказаться, что первые несколько строчек — пустые или что первая строчка не содержит название столбцов (тогда для параметра header = нужно поставить FALSE )
Вместо строковых данных у вас кракозябры. Это означает проблемы с кодировкой. В первую очередь попробуйте выставить значение "UTF-8" для параметра encoding = в функции для чтения файла:
В случае если это не помогает, попробуйте разобрать, что это за кодировка.
Все прочиталось как одна колонка. В этом случае, скорее всего, неправильно подобран разделить колонок — параметр sep = . Откройте файл в текстовом редакторе, чтобы понять какой нужно использовать.
В отдельных строчках все прочиталось как одна колонка, а в остальных нормально. Скорее всего, в файле есть значения типа \ или " , которые в функциях read.csv() , read.delim() , read.csv2() , read.delim2() читаются как символы для закавычивания значений. Это может понадобиться, если у вас в таблице есть строковые значения со знаками , или ; , которые могут восприниматься как разделитель столбцов.
Появились какие-то новые числовые колонки. Возможно неправильно поставлен разделитель дробной части. Обычно это либо . ( read.table() , read.csv() , read.delim() ), либо , ( read.csv2() , read.delim2() ).
Конкретно в нашем случае все прочиталось хорошо с помощью функции read.csv() , но в строковых переменных есть много прочерков, которые обозначают отсутствие информации по данному параметру супергероя, т.е. пропущенное значение. А вот с числовыми значениями все не так просто: для всех супергероев прописано какое-то число, но во многих случаях это -99. Очевидно, отрицательного роста и массы не бывает, это просто обозначение пропущенных значений (такое часто используется). Таким образом, чтобы адекватно прочитать файл, нам нужно поменять параметр na.strings = функции read.csv() :
6.4 Экспорт данных
Представим, что вы хотите сохранить табличку с данными про супергероев из вселенной DC в виде отдельного файла .csv.
Функция write.csv() позволит записать датафрейм в файл формата .csv:
Обычно названия строк не используются, и их лучше не записывать, поставив для row.names = значение FALSE :
По аналогии с read.csv2() , write.csv2() позволит записать файлы формата .csv с разделителем ; .
6.5 Импорт таблиц в бинарном формате: таблицы Excel, SPSS
Тем не менее, далеко не всегда таблицы представлены в виде текстового файла. Самый распространенный пример таблицы в бинарном виде — родные форматы Microsoft Excel. Если Вы попробуете открыть .xlsx файл в Блокноте, то увидите кракозябры. Это делает работу с этим файлами гораздо менее удобной, поэтому стоит избегать экселевских форматов и стараться все сохранять в .csv.
Такие файлы не получится прочитать при помощи базового инструментария R. Тем не менее, для чтения таких файлов есть много дополнительных пакетов:
файлы Microsoft Excel: лучше всего справляется пакет readxl (является частью расширенного tidyverse), у него есть много альтернатив ( xlsx , openxlsx ).
файлы SPSS, SAS, Stata: существуют два основных пакета — haven (часть расширенного tidyverse) и foreign .
Что такое пакеты и как их устанавливать мы изучим очень скоро.
6.6 Быстрый импорт данных
Чтение табличных данных обычно происходит очень быстро. По крайней мере, до тех пор пока ваши данные не содержат очень много значений. Если вы попробуете прочитать с помощью read.csv() таблицу с миллионами строчками, то заметите, что это происходит довольно медленно. Впрочем, эта проблема эффективно решается дополнительными пакетами.
- Пакет readr (часть базового tidyverse) предлагает функции, очень похожие на стандартные read.csv() , read.csv2() и тому подобные, только в названиях используется нижнее подчеркивание: read_csv() и read_csv2() . Они быстрее и немного удобнее, особенно если вы работаете в tidyverse.
- Пакет vroom - это часть расширенного tidyverse. Это такая альтернатива readr из того же tidyverse, но еще быстрее (отсюда и название).
- Пакет data.table - это не просто пакет, а целый фреймворк для работы с R, основной конкурент tidyverse. Одна из основных фишек data.table - быстрота работы. Это касается не только процессинга данных, но и их загрузки и записи. Поэтому некоторые используют функции data.table для чтения и записи данных в отдельности от всего остального пакета - они даже и называются соответствующе: fread() и fwrite() , где f означет fast 12 .
Чем же пользоваться среди всего этого многообразия? Бенчмарки 13 показывают, что быстрее всех vroom и data.table . Если же у вас нет задачи ускорить работу кода на несколько миллисекунд или прочитать датасет на много миллионов строк, то стандартного read.csv() (если вы работаете в базовом R) и readr::read_csv() (если вы работаете в tidyverse) должно быть достаточно.
Все перечисленные пакеты повзоляют не только быстро импортировать данные, но и быстро (и удобно!) экспортировать их:
В плане скорости записи файлов соотношение сил примерно такое же, как и для чтения: vroom и data.table обгоняют всех, затем идет readr , и только после него - базовые функции R.
супергерои в комиксах, фильмах и телесериалах часто взаимодействуют друг с другом, однако обычно это взаимодействие происходит между супергероями одного издателя. Два крупнейших издателя комиксов — DC и Marvel, поэтому принято говорить о вселенной DC и Marvel.↩︎
А еще friendly: fread() обычно самостоятельно хорошо угадывает формат таблицы на входе. vroom тоже так умеет.↩︎
бенчмаркинг — это тест производительности, в данном случае — сравнение скорости работы конкурирующих пакетов.↩︎
Для помещения исходных файлов в проект необходимо воспользоваться командой "Импорт" (Import) пункта меню " Файл " (File). Чтобы избежать возникновения возможных проблем, напомним, что лучше будет скопировать все исходники в одну папку и на протяжении всей работы над проектом не перемещать их в другое место на диске и не переименовывать. Такое требование связано с тем, что Adobe Premiere не загружает в проект сами исходники, а хранит только ссылки на них. В противном случае объем проекта был бы чрезмерно большим.
- В диалоговом окне "Импорт" (Import) можно выбрать один или несколько необходимых файлов. Если требуется выбрать некую последовательность, то это можно сделать,удерживая клавишу Shift и выбирая левой кнопкой мыши первый и последний файлы последовательности. Если требуется выбрать насколько разрозненных файлов, то для этого удерживают нажатой клавишу Ctrl.
- Можно загрузить в проект папку целиком. Для этого воспользуйтесь кнопкой Import Folder (Импортировать папку).
- После загрузки файлов и папок в проект они появятся в окне "Проект" (Project).
Экспорт фильма
Смонтированный фильм может быть записан на пленку, CD- или DVD- диск или просто перезаписан в один из общепринятых универсальных видеоформатов. Для этого необходимо войти в меню Файл (File), выбрать пункт меню "Экспорт" а "Фильм" ( Export а Movie). Чтобы команда "Экспорт" ( Export ) стала доступна, необходимо, чтобы окно "Монтажный стол" (Timeline) было активным.
- Для просмотра параметров готового фильма нужно выбрать в диалоге "Экспорт" (Export) кнопку Settings ("Установки"), после чего откроется окно Exliort Settings ("Установки экспорта"). В закладках "Общие", "Видео" и "Аудио" можно выбрать нужные параметры итогового фильма.
- Формат будущего файла. Поскольку мы работаем с цифровым видео, то выбираем формат DV
- Какая область окна "Монтажный стол" (Timeline) включается в экспорт (вся последовательность (Entire Clip) или только рабочая область (In to Out)).
- Режим воспроизведения видео (телевизионный формат (в нашем случае – PAL), размер кадра (Frame Size), количество кадров (Frame Rate)).
Очень удобно производить экспорт через специальную встроенную программу Adobe Media Encoder ( меню " Файл " (File)). Выбирая окончательный формат фильма, здесь можно настраивать практически любые его характеристики.
Мастер экспорта и мастер импорта помогают переносить данные проекта между Microsoft Project и другими программами. Ниже приводится список форматов, которые вы экспортируете в формат или из них импортируете.
Microsoft Excel (как книга или Отчет сводной таблицы )
только текст (с делегированием табули).
Значения, разделенные запятой (CSV)
Определив или отредактировать карты экспорта или импорта этих мастеров, вы можете легко переносить данные в нужные задача, ресурсы или назначение из них.
В этой статье
Экспорт сведений о проекте
Выберите "Сохранить > как".
Выберите "Обзор". (Не применимо в Project 2010.)
В поле "Тип файла" выберите формат файла, в который вы хотите экспортировать данные.
В поле "Имя файла" введите имя экспортируемого файла.
Выберите Сохранить.
Следуйте инструкциям мастера экспорта, чтобы экспортировать нужные данные в правильные поля конечного файла.
Когда мастер запросит создать новую карту или использовать существующую, сделайте следующее:
Выберите "Создать карту", чтобы создать новую карту экспорта с нуля.
Выберите "Использовать существующую карту", чтобы использовать карту по умолчанию или карту, которую вы ранее определили и сохранили.
На странице "Сопоставление задач", "Сопоставлениересурсов" или "Сопоставление назначений" мастера экспорта проверьте или отредактйте предположения сопоставления для Project или создайте новую карту:
Чтобы экспортировать сведения о проекте, введите или выберите нужное поле в столбце "От" и нажмите ввод.
Чтобы добавить на карту экспорта все поля задач, ресурсов или назначений проекта, выберите "Добавить все".
Чтобы добавить на карту экспорта все поля задач или ресурсов конкретной таблицы, выберите вариант "Базировать по таблице". Выберите таблицу, а затем выберите "ОК".
Чтобы удалить все поля задач, ресурсов или назначений из карты экспорта, выберите "Очистить все".
Чтобы вставить новое поле над другим полем, выберите поле в столбце "От" и выберите "Вставить строку".
Чтобы вставить новое поле над другим полем, выберите поле в столбце "От" и выберите "Вставить строку".
Чтобы удалить поле, выберите его в столбце "От" и выберите "Удалить строку". Чтобы изменить имя поля в конечном файле, выберите его в столбце "На" и введите новое имя.
Чтобы экспортировать только определенные задачи или ресурсы, выберите нужный фильтр в поле фильтра экспорта.
Если вы хотите изменить порядок полей в конечном файле, выберите поле в столбце "На", а затем с помощью кнопок перемещения переместили поле в нужное место.
На последней странице мастера экспорта выберите "Готово", чтобы экспортировать данные.
В формат XML можно экспортировать только весь проект. Project автоматически сопоирует данные без мастера экспорта. Кроме того, чтобы уменьшить размер файла, поля, содержащие нуловые значения, не включаются в экспортируемом XML-файле.
На странице "Сопоставление задач", "Сопоставление ресурсов" или "Сопоставление назначений" мастера экспорта в области предварительного просмотра можно просмотреть макет схемы экспорта.
Если вы хотите использовать новую или измененную карту экспорта, ее можно сохранить снова. На последней странице мастера экспорта выберите "Сохранить карту" и введите имя в поле "Имя карты". Новая схема будет добавлена в список готовых схем.
Вы можете использовать существующую карту экспорта из другого проекта, если карта доступна в глобальном файле. С помощью организатор вы можете скопировать карту экспорта из файла проекта в глобальный файл.
При создании карты экспорта для сохранения данных в формате CSV или TXT при этом затеняется текстовый (а не расширение) тип файла. Например, если сохранить файл с именем Myproject.csv, но вы указали на карте один из них, вместо запятых в CSV-файле будут ячеек, даже если в расширении файла указаны запятые.
Импорт сведений о проекте
Вы можете импортировать данные в Project, используя поле ввода из формат файла другого продукта, например Microsoft Office Excel, Microsoft Office Access, XML, CSV или формат текста с разделением табуляцией.
Выберите "Файл>открыть >"Обзор".
(В Project 2010 выберите "Файл" >"Открыть".)
В поле "Тип файлов" выберите тип файла, из который вы хотите импортировать данные.
Перейдите к папке с файлом, который вы хотите импортировать, а затем выберите файл в списке файлов.
Выберите "Открыть".
Следуйте инструкциям мастера импорта, чтобы импортировать нужные данные в соответствующие поля Project.
На странице "Сопоставлениезадач", "Сопоставлениересурсов" или "Сопоставление назначений" мастера импорта проверьте или отредактируете предположения сопоставления для Project.
Чтобы импортировать данные из поля в источнике в другое поле Project, выберите поле в столбце "На", выберите новое поле и нажмите ввод.
Чтобы изменить имя поля в конечном файле, выберите его в столбце "На" и введите новое имя.
Чтобы удалить поле, выберите его в столбце "От" и выберите "Удалить строку".
Чтобы вставить новое поле над другим полем, выберите поле в столбце "От" и выберите "Вставить строку".
Чтобы удалить все поля задач, ресурсов или назначений из карты импорта, выберите "Очистить все".
Чтобы добавить на карту импорта все поля задач, ресурсов или назначений конечного файла, выберите "Добавить все".
Совет: На странице "Сопоставлениезадач", "Сопоставлениересурсов" или "Сопоставление назначений" мастера импорта в области предварительного просмотра можно просмотреть макет карты импорта.
Чтобы изменить порядок полей в конечном файле, выберите поле в столбце "На", а затем с помощью кнопок перемещения переместили поле в нужное место.
На последней странице мастера импорта выберите "Готово", чтобы импортировать данные.
Совет: Если вы хотите использовать новую или измененную карту импорта, ее можно сохранить снова. На последней странице мастера импорта выберите "Сохранить карту" и введите имя в поле "Имя карты". Новая схема будет добавлена в список готовых схем.
Вы можете использовать существующую карту импорта из другого проекта, если карта доступна в глобальном файле. С помощью организатор вы можете скопировать карту импорта из файла проекта в глобальный файл.
При создании карты импорта для включения данных из формата CSV или TXT при этом задаваем текстовый (а не с расширением) тип файла. Например, если вы импортируете файл с именем "Myproject.csv" и указали на карте один из них, вместо запятых в CSV-файле будут ячеек, даже если в расширении файла указаны запятые.
Хотя в некоторые вычисляются поля можно вводить значения, Project может пересчитать их автоматически или в задавное время.
В Project можно импортировать только данные XML, которые могут быть проверены в отношении схемы обмена данными.
Если вы используете Microsoft Project профессиональный и хотите импортировать сведения из другого формата файла в корпоративный проект, в который требуется ввести определенные сведения о задачах, вы не сможете сохранить проект, пока не введите всю необходимую информацию.
Если вы используете Microsoft Project профессиональный, помните, что поля затрат на ресурсы невозможно обновить в корпоративном проекте. Данные о затратах на ресурсы можно импортировать только в неинтеграммируемых проектах или для неинтеграммируемых ресурсов.
Люди часто сталкиваются с необходимостью переноса контактных данных между сотовыми. Чтобы не добавлять каждую запись заново и по отдельности предусмотрены функции экспорта и импорта. Иногда потребители путают эти понятия. Статья поможет разобраться, чем различаются два термина, и покажет, как совершаются такие процессы в современных смартфонах.
Что значит импорт и экспорт контактов в телефоне
Говоря простым языком, импорт — это добавление, а экспорт — изъятие.
Что такое импорт и зачем он нужен
Импорт — добавление контактных данных в приложение на девайсе с внутреннего хранилища, SIM- или MicroSD-карты.
Нужен он при смене пользователем мобильного устройства и необходимости перенести значения с SIM-карты. Этот процесс находит применение при восстановлении данных с резервной копии.
Экспорт и его функции
Экспортом называется перенос контактных данных на мобильном девайсе во внутренний или внешний накопитель либо на SIM-карту.
Основными его функциями являются перемещение текстовой информации между сотовыми либо на SIM-карту и создание Backup’а (резервной копии). Процесс бывает полезен при освобождении места на накопителе. Но это актуально лишь для старых сотовых, где максимальное количество имен в телефонной книге небольшое.
В чем ключевые отличия импорта от экспорта
Импорт и экспорт контактов в телефоне отличаются тем, что в первом происходит добавление информации в список номеров, а во втором сведения, наоборот, изымаются оттуда. Разница в том, что экспортировать данные обычно означает записать текст в память девайса, а импортировать контакты — это значит считать сведения с файла, находящегося на устройстве.
Как экспортировать и импортировать контакты
Экспортировать или импортировать контакты на Android-устройствах можно несколькими способами. Первый — через стандартное приложение « Контакты » на телефоне, второй — используя сторонний софт.
Используя Google-аккаунт
Перенести номера на аккаунт Google можно таким образом:
![Список контактов]()
![Переход в меню]()
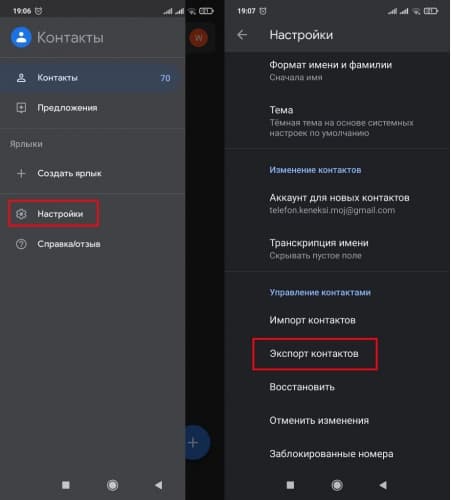
![Экспорт контактов]()
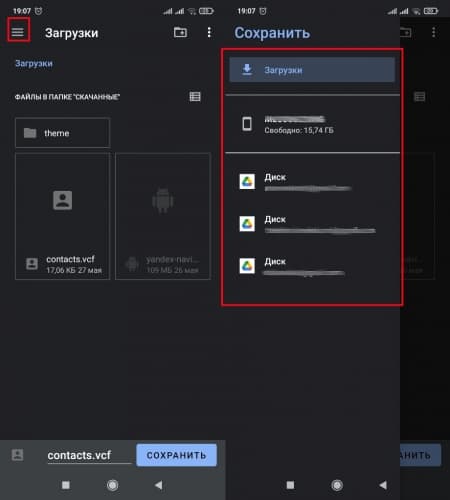
![Выбор места сохранения экспорта]()
- Коснуться « Экспортировать в VCF-файл » или « Сохранить ».
![Сохранение файла экспорта контактов]()
Внимание! Добавить данные на девайсах с ОС Android можно с SIM-карты или виртуальной карточки, находящейся в памяти аппарата.
Для извлечения с SIM понадобится произвести следующие действия:
- Вставить СИМ-карту в смартфон или планшет.
- Открыть программу, содержащую номера на Android-устройстве.
![Список контактов]()
![Вызов меню]()
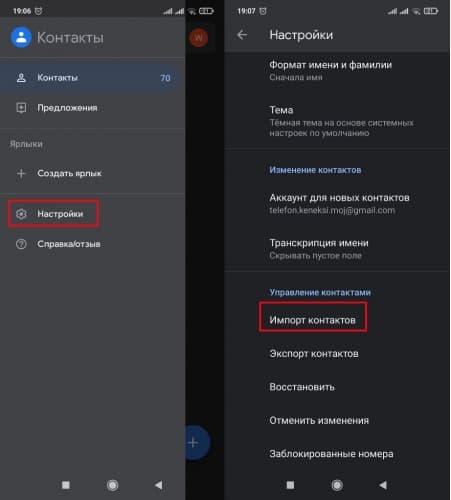
![Импорт контактов]()
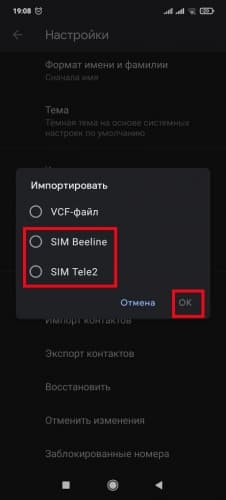
- Нажать на пункт « SIM-карта » (в некоторых версиях ОС предлагает выбор оператора). Указать аккаунт для сохранения материала.
![Выбор откуда импортировать]()
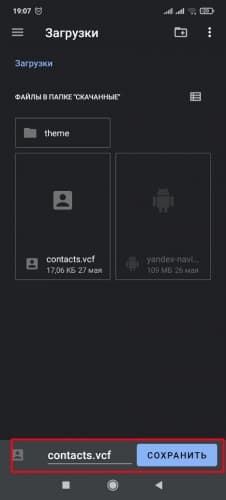
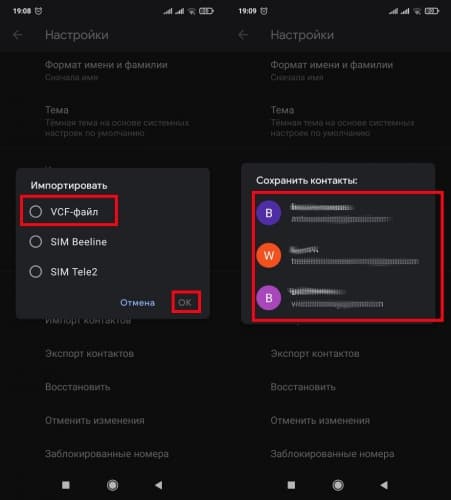
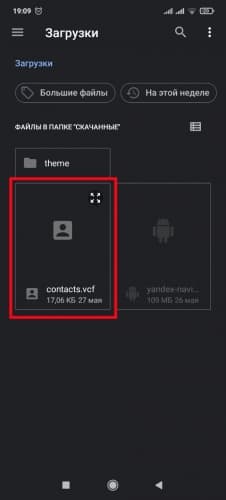
Если сведения находятся в специальном документе формата . vcf , импорт производится так:
![Список контактов]()
- Произвести нажатие на виртуальную кнопку « Меню » в левом верхнем углу экрана.
![Импорт контактов]()
- Выбрать « VCF-файл ». Из предложенных аккаунтов указать тот, где требуется сохранить контактные данные.
![Выбор аккаунта для экспорта]()
- Найти и открыть документ . vcf , откуда будут извлечены значения.
![Выбор файла экспорта]()
Через сторонние приложения
Перенос информации с мобильных устройств можно осуществить с помощью компьютерной программы MOBILedit .
Экспортировать контакты с помощью MOBILedit можно следующим образом:
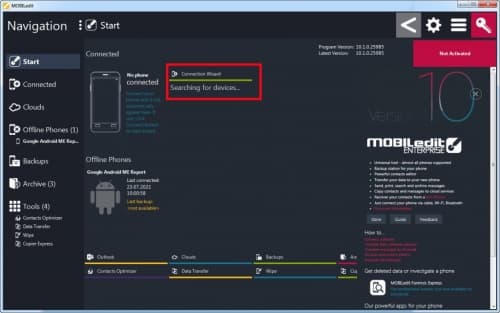
- В самой программе перейти на вкладку « Телефон/Phones », далее указать « Соединение/Connection Wizars » (в последней версии утилиты кнопка доступна на стартовой вкладке).
![Подключение к телефону]()
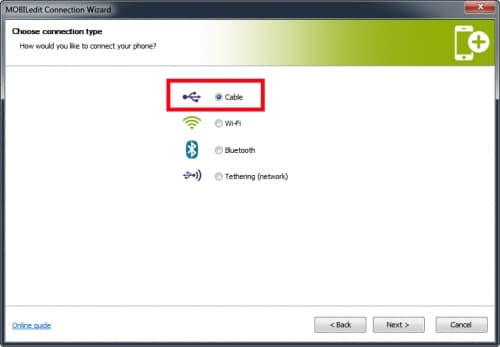
- В появившемся окне выбрать PC Sync или Cable (в зависимости от версии программы).
![Выбор типа подключения к телефону]()
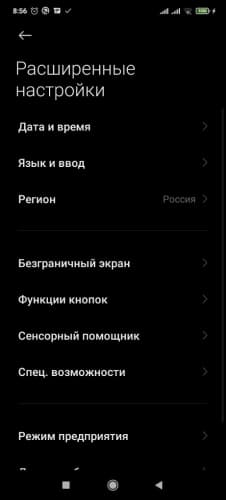
- Перейти в настройки мобильного телефона и кликнуть на пункт « Система » или « Расширенные настройки ».
![Переход в расширенные настройки]()
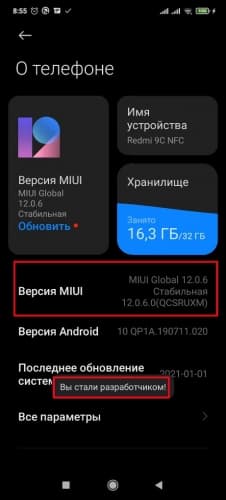
- Если этой надписи нет, открыть пункт « О телефоне » и тапнуть несколько раз на « Номер сборки » или « Версия MIUI » до появления соответствующего уведомления.
![Активация раздела "Для разработчиков"]()
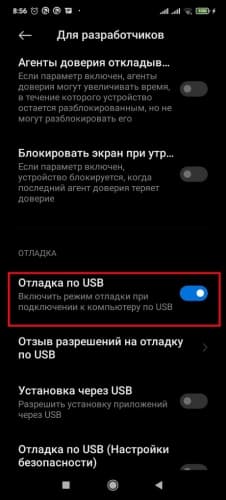
- После этого в настройках для разработчиков включить « Отладку по USB ».
![Активация раздела "Отладка по USB"]()
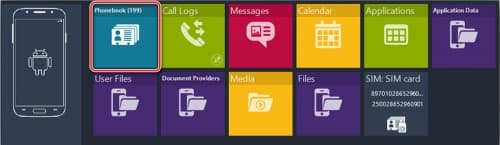
- Теперь с ПК кликнуть на пункт « Phonebook », находящийся на панели MOBILedit’а.
![Выбор пункта "Phonebook"]()
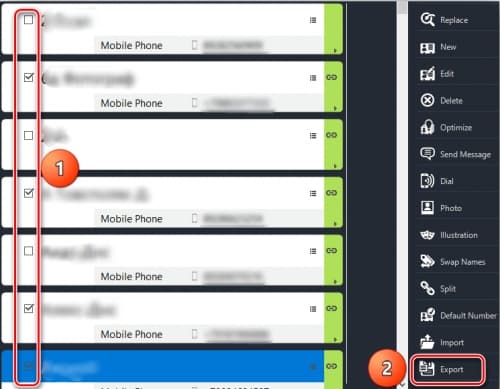
- Выбрать, какие именно нужно экспортировать контакты.
![Выбор типа контактов для экcпорта]()
- Выбрав контакты, нажать кнопку « Экспорт/Export ».
![Выбор контактов для экcпорта]()
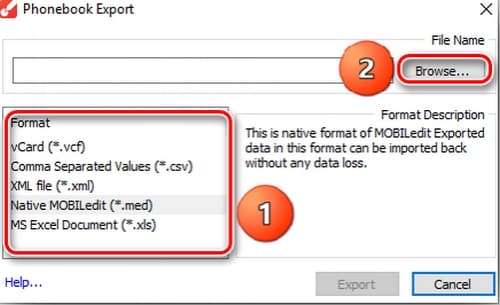
- Указать тип файла CSV и путь сохранения его на компьютере.
![Выбор типа файла для экcпорта]()
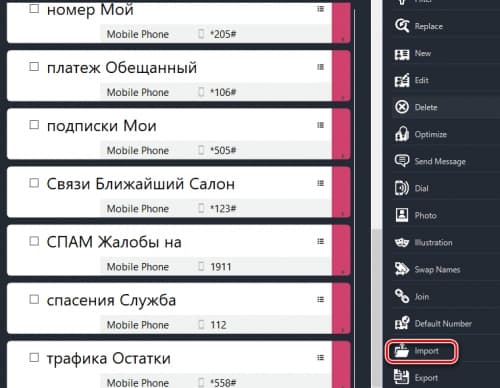
Импортировать контакты в данной утилите ещё проще. Требуется совершить следующие действия:
- Подключить смартфон к компьютеру.
- Открыть пункт « Импорт/Import » в программе MOBILedit .
![Выбор пункта "Импорт"]()
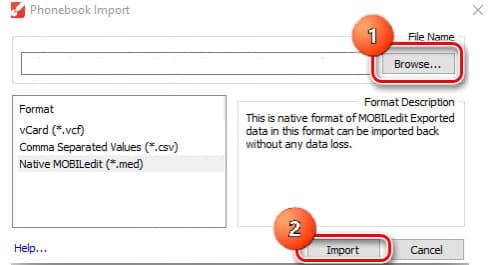
- Выбрать файл, полученный при экспорте, и кликнуть на « Import ».
![Выбор, откуда импортировать]()
Достоинствами программы MOBILedit являются поддержка большого количества моделей телефонов (не только смартфонов с ОС Android) и возможность экспорта в CSV-файл, который беспрепятственно открывается в Microsoft Excel. Но у приложения есть и недостатки: отсутствие русского языка и платная лицензия.
Читайте также: