Что такое кэш в программировании
Обновлено: 04.07.2024
В этой статье мы поговорим о трех наиболее часто используемых типах кэша:
Кэш браузера
Каждый раз, когда вы посещаете веб-сайт впервые, браузер локально сохраняет ресурсы веб-страницы (например, html, css, js, изображения и так далее). Это нужно для более быстрой работы и меньшего потребления трафика при следующем посещении.
Инвалидация кэша браузера
Инвалидацию кэша также называют очисткой кэша. Под очисткой подразумевается просто удаление кэша. Это делается для того, чтобы пользователю показывались именно свежие ресурсы.
Сети доставки контента (CDN)
Сеть доставки контента (CDN) способна на больше, чем просто кэширование. Она хранит данные в географически распределенных местах, из-за чего время приема и передачи в конкретный географически локализованный браузер и обратно сокращается. Благодаря этому ваш браузер получает данные из ближайшего к вам узла сети CDN.
CDN следует тем же правилам, что и ваш браузер, и фактически просто становится еще одним посредником. Если срок действия кэша еще не истек, первый запрос от браузера в определенном временном окне достигает сервера, а затем последующие запросы уже будут обслуживаться из самой CDN.

Данный тип кэширования не только помогает сократить время отклика, но и снижает нагрузку на ваш сервер.
Инвалидация кэша в сетях доставки контента (CDN)
Кэширование в базах данных
В предыдущем разделе мы обсудили сети доставки контента (CDN) и тот факт, что они являются посредниками между клиентом и сервером. Аналогичным образом система кэширования базы данных является посредником между сервером и базой данных. Существует множество таких систем кэширования, например redis, memcache и т. д. Их работа объяснена ниже:

Инвалидация кэша в базах данных
Каждая из подобных систем предоставляет свои собственные методы уничтожения кэша. Обратитесь к их документации, чтобы узнать больше.
Теперь перейдем к вопросу, почему начинающим разработчикам приходится с этим бороться. Как правило, в современных стеках технологий применяются все три вида кэширования. И иногда разработчики застревают при отладке.
Представьте, что вы внесли некоторые изменения в свой веб-сайт, но они не отображаются. Если предположить, что с кодом все в порядке, виновником этого может быть любой из трех вышеописанных видов кэширования. Но это относительно небольшой недостаток (даже не недостаток, если вы о нем знаете) по сравнению с огромным положительным эффектом, который дает кэширование. Этот эффект выражен в масштабируемости, меньшем времени отклика и в целом лучшем пользовательском интерфейсе.
В сфере вычислительной обработки данных кэш – это высокоскоростной уровень хранения, на котором требуемый набор данных, как правило, временного характера. Доступ к данным на этом уровне осуществляется значительно быстрее, чем к основному месту их хранения. С помощью кэширования становится возможным эффективное повторное использование ранее полученных или вычисленных данных.
Как работает кэширование?
Данные в кэше обычно хранятся на устройстве с быстрым доступом, таком как ОЗУ (оперативное запоминающее устройство), и могут использоваться совместно с программными компонентами. Основная функция кэша – ускорение процесса извлечения данных. Он избавляет от необходимости обращаться к менее скоростному базовому уровню хранения.
Небольшой объем памяти кэша компенсируется высокой скоростью доступа. В кэше обычно хранится только требуемый набор данных, причем временно, в отличие от баз данных, где данные обычно хранятся полностью и постоянно.
Начните работу с кэшированием: ускорьте рабочие нагрузки вашего приложенияОбзор кэширования
ОЗУ и работающие в памяти сервисы. Поскольку ОЗУ и работающие в памяти сервисы обеспечивают высокие показатели скорости обработки запросов, или IOPS (количество операций ввода-вывода в секунду), кэширование повышает скорость извлечения данных и сокращает расходы при работе в больших масштабах. Чтобы обеспечить аналогичный масштаб работы с помощью традиционных баз данных и оборудования на базе жестких дисков, требуются дополнительные ресурсы. Использование этих ресурсов приводит к повышению расходов, но все равно не позволяет достигнуть такой низкой задержки, какую обеспечивает кэш в памяти.
Шаблоны проектирования. В среде распределенных вычислений выделенный уровень кэширования позволяет системам и приложениям работать независимо от кэша. При этом их жизненные циклы не влияют на кэш. Кэш служит центральным уровнем, к которому могут обращаться различные несвязанные между собой системы. Он имеет собственный жизненный цикл и архитектурную топологию. Это особенно важно для систем, в которых узлы приложений можно динамически масштабировать в обе стороны. Если кэш находится на том же узле, что и приложение или системы, которые им пользуются, масштабирование может разрушить целостность кэша. Кроме того, если используются локальные кэши, это дает преимущества только локальным приложениям, которые пользуются данными. В распределенной среде кэша данные могут охватывать множество серверов кэширования и находиться в центральном расположении, удобном для всех потребителей данных.
Рекомендации по кэшированию. При реализации уровня кэша необходимо принимать во внимание достоверность кэшируемых данных. Эффективный кэш обеспечивает высокую частоту попаданий, то есть наличия в кэше запрашиваемых данных. Промах кэша происходит, когда запрашиваемых данных в кэше нет. Для удаления из кэша неактуальных данных применяются такие механизмы, как TTL (время жизни). Следует также понимать, требуется ли для среды кэширования высокая доступность. Если она необходима, можно использовать сервисы в памяти, такие как Redis. В ряде случаев уровень в памяти можно использовать как отдельный уровень хранения данных, в отличие от кэширования из основного хранилища. Чтобы решить, подходит ли такой вариант, необходимо определить для данных в сервисе в памяти соответствующие значения RTO (требуемое время восстановления, то есть сколько времени требуется системе на восстановление после сбоя) и RPO (требуемая точка восстановления, то есть последняя восстанавливаемая точка или транзакция). Для соответствия большинству требований RTO и RPO можно применять характеристики и проектные стратегии разных сервисов в памяти.

Ускорение получения веб-контента от веб-сайтов (браузеры или устройства)
Кэширование с помощью Amazon ElastiCache
Веб-сервис Amazon ElastiCache упрощает развертывание, эксплуатацию и масштабирование в облаке хранилища или кэша в памяти. Сервис повышает производительность интернет-приложений, позволяя получать информацию из быстрых управляемых хранилищ данных, размещенных в памяти, а не только из баз данных, размещенных на дисках и работающих не так быстро. Информацию о том, как реализовать эффективную стратегию кэширования, см. в этом техническом описании по кэшированию в памяти.
Преимущества кэширования
Повышение производительности приложений
Поскольку память работает в разы быстрее диска (магнитного или SSD), чтение данных из кэша в памяти производится крайне быстро (за доли миллисекунды). Это значительно ускоряет доступ к данным и повышает общую производительность приложения.
Сокращение затрат на базы данных
Один инстанс кэша может обрабатывать тысячи операций ввода-вывода в секунду, потенциально заменяя несколько инстансов базы данных, что в результате дает снижение общих затрат. Это особенно важно, если плата взимается за пропускную способность базы данных. В таких случаях можно снизить затраты на десятки процентов.
Снижение нагрузки на серверную часть
Благодаря освобождению серверной базы данных от значительной части нагрузки на чтение, которая направляется на уровень памяти, кэширование может сократить нагрузку на базу данных и защитить ее от снижения производительности под нагрузкой и даже от сбоев при пиковых нагрузках.
Прогнозируемая производительность
Общей проблемой современных приложений является обработка пиков в использовании приложений. Примерами могут служить социальные сети во время Суперкубка или в день выборов, веб-сайты электронной коммерции в Черную пятницу и т. д. Повышенная нагрузка на базу данных приводит к повышению задержек при получении данных, и общая производительность приложения становится непредсказуемой. Эту проблему можно решить благодаря использованию кэша в памяти с высокой пропускной способностью.
Устранение проблемных мест в базах данных
Во многих приложениях небольшое подмножество данных, например профиль знаменитости или популярный продукт, может оказаться намного более востребованным, чем остальные данные. Это приводит к появлению проблемных мест в базе данных и требует избыточного выделения ее ресурсов, чтобы удовлетворить спрос на пропускную способность, которой достаточно для получения наиболее часто используемых данных. За счет хранения общих ключей в кэше в памяти можно избавиться от необходимости избыточного выделения ресурсов и обеспечить быструю и предсказуемую работу системы при обращении к самым востребованным данным.
Повышение пропускной способности операций чтения (количество операций ввода-вывода в секунду)
Помимо сокращения задержек, системы в памяти обеспечивают намного более высокую скорость выполнения запросов (количество операций ввода-вывода в секунду) по сравнению с базами данных на диске. Один инстанс, который используется как распределенный дополнительный кэш, может обслуживать сотни тысяч запросов в секунду.

Кэш - это временное хранилище для данных, которые с наибольшей вероятностью могут быть повторно запрошены. Загрузка данных из кэша осуществляется быстрее, чем из хранилища с исходными данными, но и его объём существенно ограничен.
Алгоритмы кэширования
Алгоритмы кэширования - это подробный список инструкций, который указывает, какие элементы следует отбрасывать в кэш. Их еще называют алгоритмами вытеснения или политиками вытеснения.
Когда кэш заполнен, алгоритм должен выбрать, какую именно запись следует из него удалить, чтобы записать новую, более актуальную информацию.
Least recently used - LRU (Вытеснение давно неиспользуемых)
LRU - это алгоритм, при котором вытесняются элементы, которые дольше всего не запрашивались. Соответственно, необходимо хранить время последнего запроса к элементу. И как только кэш становится заполненным, необходимо вытеснить из него элемент, который дольше всего не запрашивался.
Общая реализация этого алгоритма требует сохранения «бита возраста» для элемента и за счет этого происходит отслеживание наименее используемых элементов. В подобной реализации, при каждом обращении к элементу меняется его «возраст».

LRU на самом деле является семейством алгоритмов кэширования, в которое входит 2Q, а также LRU/K.
Для реализации понадобятся две структуры данных:
- Хеш-таблица, которая будет хранить закэшированные значения.
- Очередь, которая будет хранить приоритеты элементов и выполнять следующие операции:
- Добавить пару значение и приоритет.
- Извлечь (удалить и вернуть) значение с наименьшим приоритетом.
- Проверяем, есть ли значение в кэше:
- Если значение уже есть, то обновляем время последнего к нему запроса и возвращаем значение.
- Если значения нет в кэше - вычисляем его.
- Если кэш заполнен, то вытесняем самый старый элемент.
Достоинства:
- константное время выполнения и использование памяти.
Недостатки:
- алгоритм не учитывает ситуации, когда к определенным элементам обращаются часто, но с периодом, превышающим размер кэша (т.е. элемент успевает покинуть кэш).
Псевдо-LRU - PLRU
PLRU - это алгоритм, который улучшает производительность LRU тем, что использует приблизительный возраст, вместо поддержания точного возраста каждого элемента.
Most Recently Used - MRU (Наиболее недавно использовавшийся)
MRU - алгоритм, который удаляет самые последние использованные элементы в первую очередь. Он наиболее полезен в случаях, когда чем старше элемент, тем больше обращений к нему происходит.
Least-Frequently Used - LFU (Наименее часто используемый)
LFU - алгоритм, который подсчитывает частоту использования каждого элемента и удаляет те, к которым обращаются реже всего.
В LFU каждому элементу присваивается counter - счётчик. При повторном обращении к элементу его счётчик увеличивается на единицу. Таким образом, когда кэш заполняется, необходимо найти элемент с наименьшим счётчиком и заменить его новым элементом. Если же все элементы в кэше имеют одинаковый счётчик, то в этом случае вытеснение осуществляется по методу FIFO: первым вошёл - первым вышел.
Недостатки:
- много обращений к элементу за короткое время накручивает счётчик и в результате элемент зависает в кэше.
- алгоритм не учитывает “возраст” элементов.
Multi queue - MQ (Алгоритм многопоточного кэширования)
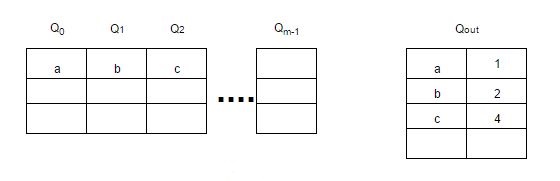
MQ - алгоритм, использующий несколько LRU очередей - Q0, Q1, …, Qn, между которыми элементы ранжируются/перемещаются в зависимости от частоты обращения к ним.
В дополнение к очередям используется буфер “истории” - Qout, где хранятся все идентификаторы элементов со счётчиками (частота обращения к элементу). При заполнении Qout удаляется самый старый элемент.
Элементы остаются в LRU очередях в течение заданного времени жизни, которое динамически определяется специальным алгоритмом.
Если к очереди не ссылались в течение её времени жизни, то её приоритет понижается с Qi до Qi-1 или удаляется из кэша, если приоритет равен 0 - Q0.
Каждая очередь также имеет максимальное количество обращений к её элементам. Поэтому если к элементу в очереди Qi обращаются более 2i раз, то этот элемент перемещается в очередь Qi+1.
При заполнении кэша, будет вытеснен элемент из очереди Q0, который дольше всех не использовался.
Картинка для наглядности:
![mq-replacement-algortithm.jpg]()
Другие алгоритмы
Алгоритмов кэширования достаточно много, поэтому на данный момент не все здесь рассмотрены. С полным списком можно ознакомиться здесь.
Со временем буду дополнять.
Полезные ссылки
Алгоритмы кэширования - статья на wiki.
LRU (Least Recently Used) - подробная статья о LRU с примерами реализации на C, C++, Java.
LRU, метод вытеснения из кэша - статья о том, как быстро реализовать алгоритм LRU.
Least Frequently Used (LFU) Cache Implementation - статья о LFU с примером на C++.
LFU cache in O(1) in Java - пример реализации LFU на Java.
Алгоритмы кэширования - что-то вроде презентации некоторых алгоритмов кэширования в формате PDF.![1]()
Общий процесс интернет-приложений (веб-сайт / приложение) можно резюмировать, как показано на рисунке:
Пользователь запрашивает из интерфейса (браузер / приложение) пересылку по сети, службы приложений в хранилище (базу данных или файловую систему), а затем возвращается к интерфейсу для представления контента.Как показано на рисунке 1, использование кэширования может появляться в каждой ссылке от 1 до 4. Схема кэширования и использование каждой ссылки имеют свои особенности.
1. Характеристики кеша
Кэш является объектом модели данных и имеет некоторые из его характеристик.
1.1 Скорость попадания
Частота совпадений = количество возвращенных правильных результатов / количество запросов к кешу
Проблема частоты совпадений - очень важная проблема в кэше, и это важный индикатор для измерения эффективности кеша. Чем выше частота попаданий, тем выше коэффициент использования кеша.1.2 Самый большой элемент (или самое большое пространство)
Максимальное количество элементов, которые могут быть сохранены в кеше. Когда количество элементов в кэше превышает это значение (или пространство, занимаемое кэшируемыми данными, превышает максимальное поддерживаемое пространство), кеш будет запущен. Пустая стратегия , Разумная установка максимального значения элемента в соответствии с различными сценариями часто может в определенной степени улучшить частоту попаданий в кэш, чтобы использовать кеш более эффективно.
1.3 Клиринговая стратегия
Объем кеш-памяти ограничен.Когда пространство кеш-памяти заполнено, как обеспечить стабилизацию службы и эффективное увеличение частоты обращений?
Это обрабатывается стратегией очистки кеша.
Общие общие стратегии:FIFO(first in first out)
Первые данные, которые попадают в кэш, будут очищены первыми, если места в кэше недостаточно (превышает максимальный предел элемента), чтобы освободить место для новых данных.
Алгоритм стратегии в основном сравнивает время создания элементов кеша. в Требования к эффективности данных Вы можете выбрать этот тип стратегии, чтобы отдать приоритет доступности последних данных.LFU(less frequently used)
Независимо от того, истек срок его действия или нет, он оценивается по количеству использований элемента, а менее используемые элементы очищаются, чтобы освободить место.
Алгоритм стратегии в основном сравнивает hitCount (количество совпадений) элементов. Гарантия Сценарии высокочастотной достоверности данных , Можете выбрать такую стратегию.LRU(least recently used)
Независимо от того, истекает ли срок его действия, в соответствии с меткой времени, когда элемент использовался в последний раз, очистите элемент с самой дальней используемой меткой времени, чтобы освободить место.
Алгоритм стратегии в основном сравнивает время, когда элемент последний раз использовался функцией get. в Сценарий горячих данных Более применимо, приоритет отдается обеспечению достоверности данных о точках доступа.Кроме того, есть несколько простых стратегий, таких как:
- По сроку годности убирать элементы с наибольшим сроком годности
- В соответствии со сроком действия очистите элементы, срок действия которых истекает недавно.
- Случайная уборка
- Очистите в соответствии с длиной ключевых слов (или содержанием элемента) и т. Д.
2. Кэшировать медиа
От Аппаратная среда С точки зрения памяти и жесткого диска;
из технологии Можно разделить на память, файл жесткого диска, базу данныхПамять: хранить кеш в памяти Самый быстрый s Выбор, Нет дополнительных накладных расходов ввода / вывода , Но недостатком памяти является Нет настойчивости Приземленный физический диск, после того, как приложение выйдет из строя и перезапустится, данные будет трудно или невозможно восстановить.
Жесткий диск: как правило, многие фреймворки кеширования используют память и жесткий диск в комбинации. Когда пространство выделения памяти заполнено или ненормально, оно может быть пассивным или активным. Сохранять данные о пространстве памяти на жестком диске , Для освобождения места или резервного копирования данных.
База данных: как упоминалось ранее, одна из целей увеличения стратегии кэширования - уменьшить нагрузку на ввод-вывод базы данных. Возвращается ли использование баз данных в качестве носителя кэш-памяти к старой проблеме? На самом деле существует множество типов баз данных, например, те специальные базы данных, которые не поддерживают SQL, но имеют простые структуры хранения значений ключа (например, BerkeleyDB и Redis). скорость ответа с участием Пропускная способность Они намного выше, чем наши обычно используемые реляционные базы данных.
3. Классификация кеша и сценарии приложений.
По степени связи между кешем и приложением он делится на локальный кеш с участием удаленный кеш (распределенный кеш) 。
Локальный кеш: Относится Кеширование компонентов в приложении , Его самым большим преимуществом является то, что приложение и кеш находятся в одном процессе, кэш запросов работает очень быстро и нет чрезмерных сетевых накладных расходов. Более целесообразно использовать локальный кеш в сценариях, когда отдельное приложение не требует поддержки кластера или когда узлам не нужно уведомлять друг друга. ; В то же время его недостатки Поскольку кеш связан с приложением, несколько приложений не могут напрямую совместно использовать кеш. Каждое приложение или узел кластера должны поддерживать свой собственный отдельный кеш, что является пустой тратой памяти. 。
Распределенный кеш: Относится к и Отдельный компонент или служба кэширования приложения , Его самым большим преимуществом является то, что это независимое приложение, Изолированные от локальных приложений, несколько приложений могут напрямую совместно использовать кеш 。
Вы можете рассмотреть ситуацию с локальным кешем: высокая частота доступа, небольшой объем данных, чувствительная задержка приложения и низкая стоимость восстановления. Локальный кеш затрудняет поддержание согласованности, поэтому при проектировании кеша, если можно использовать распределенный кеш, используйте как можно больше распределенного.
3.1 Локальный кеш
3.1.1 Программирование напрямую реализует кеш
В отдельных сценариях нам нужна только простая функция кэширования данных, не обращая внимания на такие подробные функции, как дополнительные стратегии доступа и опустошения.Прямое программирование для достижения кэширования является наиболее удобным и эффективным.
- Реализация переменной-члена или локальной переменной
- Реализация статической переменной
Наиболее часто используемый синглтон реализует статическое кэширование ресурсов:
Оценивается основная базовая информация о городе, обычно используемая в бизнесе O2O. Кэш-память получается за один раз с помощью статических переменных, что сокращает частое чтение статических переменных вводом-выводом для обеспечения совместного использования между классами, совместного использования внутри процессов, и производительность кеша в реальном времени немного хуже.
Чтобы решить проблему локально кэшированных данных в реальном времени, в настоящее время большое количество применений сочетается с механизмом автоматического обнаружения ZooKeeper для изменения кеша локальных статических переменных в реальном времени:
![2 Mtconfig]()
Компонент базовой конфигурации Meituan MtConfig использует аналогичный принцип, используя кэширование статических переменных в сочетании с унифицированным управлением ZooKeeper для автоматического динамического обновления кеша.
Преимущество этого типа кеша заключается в том, что он может читать и писать непосредственно в области кучи, что является самым быстрым и удобным.
На недостаток также влияет размер кучи, объем кэшированных данных очень ограничен, а на время кеширования влияет сборщик мусора.
в основном отвечает требованиям к небольшому объему кеша данных в автономных сценариях, и в то же время не нужно быть слишком чувствительным к изменениям в кэшированных данных, таких как общее управление конфигурацией, основные статические данные и другие сценарии.3.1.2 Ehcache
Ehcache - самая популярная среда кэширования с открытым исходным кодом на чистом Java. Она имеет простую конфигурацию, понятную структуру и мощные функции. Это очень легкая реализация кеширования. Наш обычно используемый Hibernate объединяет связанные функции кэширования.
![3 Ehcache]()
Основное определение Ehcache в основном включает:диспетчер кеша: диспетчер кеша, ранее разрешался только синглтон, теперь это может быть несколько экземпляров
cache: В диспетчере кешей можно разместить несколько кешей для хранения сути данных. Все кеши реализуют интерфейс Ehcache. Это реальный экземпляр кеша.
В режиме диспетчера кеша несколько экземпляров кеша можно легко изолировать в одном приложении, независимо обслуживая потребности различных бизнес-сценариев, данные кеша физически изолированы и могут совместно использоваться и используется при необходимости.element: Составная единица единичных данных кэша.
Система записи (SOR): компонент, который может извлекать реальные данные, которые могут быть реальной бизнес-логикой, вызовами внешнего интерфейса, базой данных, хранящей реальные данные и т. Д. Кэш считывается из SOR или записывается в SOR.
Основные особенности:
Быстрый, для крупномасштабных сценариев системы с высоким уровнем параллелизма, многопоточный механизм Ehcache имеет соответствующую оптимизацию и улучшение.
Простой, небольшой пакет jar, простая конфигурация может использоваться напрямую, без слишком многих других зависимостей служб в автономном сценарии
Поддержка различных стратегий кеширования, гибкость
Существует два уровня кеширования данных: память и диск. По сравнению с обычным кешем локальной памяти, с дисковым пространством для хранения, он сможет поддерживать больший объем требований к кэшированию данных.
Интерфейс мониторинга с кешем и диспетчером кеша, который может более легко и удобно отслеживать экземпляры кеша и управлять ими
Поддерживает несколько экземпляров диспетчера кеша и несколько областей кеша одного экземпляра
Параметр тайм-аута Ehcache в основном предназначен для установки общей стратегии тайм-аута для всего экземпляра кеша, но он не обрабатывает настройку тайм-аута для индивидуальности отдельного ключа лучше.
Поэтому при использовании следует учитывать, что сборщик мусора не может восстановить просроченные и недопустимые элементы кеша. Чем дольше время, тем больше кеш, тем больше используется память и тем выше вероятность утечки памяти.Для получения дополнительных инструкций по Ehcache перейдите по ссылке.
3.1.3 Guava Cache
Guava Cache - это инструмент кэширования в Guava, библиотеке набора инструментов повторного использования Java с открытым исходным кодом от Google. Реализованные функции кеширования:
Автоматически загружать входной узел в структуру кеша
Когда кэшированные данные превышают установленное максимальное значение, используйте алгоритм LRU для удаления
У него есть механизм истечения срока для вычисления узла входа на основе последнего доступа или записи.
Кэшированный ключ инкапсулирован в справке WeakReference
Кэшированное значение инкапсулируется в ссылки WeakReference или SoftReference.
Вычислить статистику, такую как частота попаданий, частота отклонений, частота ошибок и другие статистические данные во время использования кеша
Архитектурный дизайн Guava Cache вдохновлен ConcurrentHashMap.
Как мы упоминали ранее, в простых сценариях вы можете закодировать небольшой объем данных с помощью хэш-карты для кеширования небольшого объема данных, но если результат может измениться со временем или в пространстве данных, вы хотите сохранить управляемо, необходимо реализовать эту структуру данных самостоятельно.Guava Cache наследует идею ConcurrentHashMap и использует детализированные блокировки в нескольких сегментах для обеспечения безопасности потоков при поддержке сценариев с высоким уровнем параллелизма.
Кэш аналогичен Map, который представляет собой набор пар "ключ-значение". Разница в том, что он также должен обрабатывать логику алгоритма, такую как выселение, истечение срока действия и динамическая загрузка, а также требует некоторой дополнительная информация для выполнения этих операций. В связи с этим, согласно объектно-ориентированному мышлению, необходимо связывать методы и инкапсуляцию данных.На рисунке 5 показана модель данных кеш-памяти. Можно увидеть, что интерфейс ReferenceEntry используется для инкапсуляции Пара "ключ-значение" , И используйте ValueReference для инкапсуляции Ценность 。
ReferenceEntryЭто абстракция узла пары ключ-значение, который содержит абстрактный класс Key и Value ValueReference.
Кэш состоит из нескольких сегментов, каждый из которых содержит массив ReferenceEntry, а каждый элемент массива ReferenceEntry представляет собой цепочку ReferenceEntry. ReferenceEntry содержит поля key, hash, valueReference и next. В дополнение к цепочке, сформированной в элементах массива ReferenceEntry, в сегменте все ReferenceEntry также образуют цепочку доступа (accessQueue) и цепочку записи (writeQueue)
ReferenceEntry может быть ключом сильного ссылочного типа или ключом типа WeakReference. Чтобы уменьшить использование памяти, вы также можете определить, нужна ли вам цепочка записи, а цепочка доступа определяет конкретную ссылку, которая будет созданы: StrongEntry, StrongWriteEntry, StrongAccessEntry, StrongWriteAccessEntry и т. д.
Для некоторых других инструкций по Guava Cache, пожалуйста, перейдите по ссылкеЧитайте также: