
Что такое критичная персональная компьютерная наработка
Обновлено: 07.07.2024
В современном постоянно движущемся мире сбои в работе и технические инциденты становятся как никогда важными. Ошибки и простои ведут к реальным последствиям. Пропущенные сроки. Задержки оплаты. Задержки работы по проектам.
Вот почему для компаний важно количественно оценивать и отслеживать показатели безотказной работы, времени перебоя работы и того, как быстро и эффективно команды решают проблемы.
Некоторые из наиболее часто отслеживаемых в отрасли метрик: MTBF (средняя наработка на отказ), MTTR (среднее время восстановления, исправления, реагирования или устранения), MTTF (средняя наработка до отказа) и MTTA (среднее время подтверждения) — эти метрики предназначены для того, чтобы помочь техническим командам понять, как часто происходят инциденты и как быстро команда справляется с ними.
Многие эксперты спорят о действительной пользе этих метрик, если использовать их в отрыве от остальных показателей, потому что они не дают ответа на сложные вопросы о том, как устраняются инциденты, что работает, а что нет, и как, когда и почему проблемы обостряются или ослабляются.
С другой стороны, MTTR, MTBF и MTTF могут быть хорошей основой или эталоном, с которых стоит начинать обсуждение более глубоких и важных вопросов.

Как профессионалы реагируют на крупные инциденты
Получите наше бесплатное руководство по управлению инцидентами. Изучите все инструменты и методы, которые Atlassian использует для управления крупными инцидентами.
Оговорка об MTTR
Говоря об MTTR, можно предположить, что это один показатель с одним значением. В действительности за ним скрываются четыре разных показателя. «R» может означать решение (repair), реагирование (respond), устранение (resolve) или восстановление (recovery), и хотя эти четыре показателя перекрываются, каждый имеет собственный смысл и особенности.
Поэтому если вашей команде нужно отслеживать MTTR, рекомендуется уточнить, какой именно MTTR имеется в виду и как его определить. Прежде чем вы начнете отслеживать успехи и неудачи, у вашей команды должно быть общее понимание того, что именно вы отслеживаете.
MTBF: средняя наработка на отказ
Что такое средняя наработка на отказ?
MTBF (средняя наработка на отказ) — это среднее время между исправляемыми сбоями технологического продукта. Эта метрика используется для отслеживания как доступности, так и надежности продукта. Чем больше времени проходит между отказами, тем надежнее система.
Цель для большинства компаний — сохранить наработку на отказ как можно выше, достигнув сотни тысяч (или даже миллионов) часов между инцидентами.
Как рассчитать среднюю наработку на отказ
MTBF рассчитывается с использованием среднего арифметического. По сути, вы должны взять данные за период, на который вы хотите рассчитать MTBF (можно за шесть месяцев, год, за пять лет), и поделить общее время работы за этот период на количество сбоев.
Итак, предположим, что мы оцениваем 24-часовой период и за этот период мы потеряли два часа из-за двух отдельных инцидентов. Наше общее время безотказной работы составляет 22 часа. Разделим на два и получаем 11 часов. Итак, наша наработка на отказ составляет 11 часов.
Поскольку эта метрика используется для отслеживания надежности, наработка на отказ не учитывает ожидаемое время простоя во время планового технического обслуживания. Вместо этого она фокусируется на неожиданных простоях и проблемах.
Происхождение понятия средней наработки на отказ
MTBF берет свое начало в авиационной отрасли, где системные сбои означают особенно серьезные последствия не только с точки зрения стоимости, но и человеческой жизни. С тех пор эта аббревиатура пробралась в различные технические и механические отрасли промышленности и особенно часто используется в производстве.
Как и когда использовать среднюю наработку на отказ
Время наработки на отказ полезно для покупателей, которые хотят быть уверены, что получают самый надежный продукт, полетят на самом надежном самолете или выберут самое безопасное производственное оборудование для своего завода.
Для внутренних команд эта метрика помогает выявлять проблемы и отслеживать успехи и неудачи. Она также может помочь компаниям разработать подробные рекомендации для клиентов, чтобы они знали, когда они должны заменить деталь, обновить систему или принести продукт на техническое обслуживание.
MTBF — это метрика для сбоев в восстанавливаемых системах. Для сбоев, требующих замены системы, обычно используют термин MTTF (средняя наработка до отказа).
Например, представьте двигатель автомобиля. При расчете времени между внеплановыми техническими обслуживаниями двигателя следует использовать MTBF (среднюю наработку на отказ). При расчете времени до полной замены двигателя вы должны использовать MTTF (среднюю наработку до отказа).
MTTR: среднее время исправления
Что такое среднее время исправления?
MTTR (среднее время ремонта) — это среднее время, необходимое для ремонта системы (обычно технического или механического). Оно включает в себя как время ремонта, так и любое время тестирования. В этой метрике учитывается все время до тех пор, пока система не будет снова полностью работоспособна.
Как рассчитать среднее время исправления
Вы можете рассчитать MTTR, суммируя общее время, затраченное на ремонт в течение любого заданного периода, а затем разделив это время на количество ремонтов.
Итак, предположим, мы считаем эту метрику для ремонта в течение недели. За это время было 10 простоев, и системы активно ремонтировались в течение четырех часов. Четыре часа — это 240 минут. 240 делим на 10 и получаем 24. Что означает, что среднее время ремонта в этом случае будет составлять 24 минуты.
Ограничения среднего времени исправления
Среднее время ремонта не всегда совпадает с тем же временем, что и время сбоя работы системы. В некоторых случаях ремонт начинается в течение нескольких минут после сбоя продукта или сбоя системы. В других случаях между собственно инцидентом, обнаружением инцидента и началом ремонта бывает некоторая задержка.
Эта метрика наиболее полезна при отслеживании того, как быстро обслуживающий персонал может устранить проблему. Она не предназначена для выявления проблем с системными оповещениями или задержками перед восстановлением, которые также являются важными факторами при оценке успехов и сбоев программы управления инцидентами.
Как и когда использовать среднее время исправления
MTTR — это метрика, которую используют команды поддержки и технического обслуживания для обеспечения восстановительных работ на нужном уровне. Цель состоит в том, чтобы этот показатель был как можно ниже за счет повышения эффективности процессов восстановления и продуктивности команд.
MTTR: среднее время восстановления
Что такое среднее время восстановления?
MTTR (среднее время восстановления или среднее время стабилизации) — это среднее время восстановления после сбоя работы продукта или системы. Оно включает в себя полное время простоя с момента выхода из строя системы или продукта до момента, когда они снова становятся полностью работоспособными.
Это основной показатель DevOps, который, по мнению программы DevOps Research and Assessment (DORA), можно использовать для оценки стабильности команды DevOps.
Как рассчитать среднее время восстановления
Среднее время восстановления рассчитывается путем суммирования всего времени простоя в работе за определенный период и деления его на количество инцидентов. Итак, предположим, что наши системы были отключены на 30 минут в течение двух отдельных инцидентов за 24-часовой период. 30 делим на два, получаем 15, так что наш MTTR составляет 15 минут.
Ограничения среднего времени восстановления
MTTR используется для измерения скорости полного процесса восстановления. Достаточно ли она высокая? А по сравнению с вашими конкурентами?
Эта общая метрика помогает определить, есть ли у вас проблемы. Однако если вы хотите диагностировать, в какой именно части вашего процесса есть проблема (проблема в вашей системе оповещений? команда слишком много времени работает над исправлением? кто-то слишком долго отвечает на запрос на исправление?), то вам понадобится больше данных. Потому что между сбоем и восстановлением может произойти много чего.
Проблема может быть связана с вашей системой оповещения. Существует ли задержка между сбоем и отправкой оповещения? Достаточно ли быстро оповещения доходят до нужного человека?
Проблема может быть в диагностике. Можете ли вы быстро выяснить, в чем проблема? Существуют ли процессы, которые можно было бы улучшить?
Или проблема может быть с самим процессом исправления. Достаточно ли эффективны ваши команды технического обслуживания? Если они тратят все свое время на исправление, то что именно их тормозит?
Вам нужно будет копнуть глубже, чем MTTR, чтобы ответить на эти вопросы, но среднее время восстановления может стать отправной точкой для диагностики того, существует ли проблема в процессе восстановления и требует ли она более глубокого анализа.
Как и когда использовать среднее время восстановления
MTTR является хорошей метрикой для оценки скорости общего процесса восстановления.
MTTR: среднее время разрешения
Что такое среднее время разрешения?
MTTR (среднее время разрешения) — это среднее время, необходимое для полного устранения сбоя. Оно включает в себя не только время, затраченное на обнаружение сбоя, диагностику проблемы и ее устранение, но и время, затраченное на предотвращение повторения проблемы.
Эта метрика расширяет ответственность команды, обрабатывающей исправление: она задает ожидания в плане повышения ее продуктивности в долгосрочной перспективе. В этом и заключается разница между простым тушением пожара и тушением пожара с последующей установкой противопожарной системы.
Существует сильная связь между этим MTTR и удовлетворенностью клиентов, так что этой метрике нужно уделить особое внимание.
Как рассчитать среднее время разрешения
Чтобы рассчитать этот MTTR, рассчитайте полное время разрешения в течение периода, который вы хотите отслеживать, и разделите на количество инцидентов.
Таким образом, если ваши системы были отключены в общей сложности 2 часа за 24-часовой период из-за одного инцидента и команды потратили еще 2 часа на исправление, чтобы гарантировать, что сбой системы не повторится, в сумме получается 4 часа, потраченных на решение проблемы. Это означает, что ваш MTTR составляет 4 часа.
Заметка об отслеживании среднего времени разрешения
Имейте в виду, что MTTR чаще всего рассчитывается с использованием рабочих часов (поэтому если вы восстановите работу в конце рабочего дня и потратите время на исправление основной проблемы первым делом на следующее утро, ваш MTTR не будет включать 16 часов, в течение которых вы не работали). Если у вас есть команды в разных часовых поясах и вы работаете круглосуточно или если у вас есть дежурные сотрудники, работающие во внеурочное время, важно определить, как вы будете отслеживать время для этой метрики.
Как и когда использовать среднее время разрешения
MTTR обычно используется, когда речь идет о незапланированных инцидентах, а не о запросах на обслуживание (которые обычно планируются).
MTTR: среднее время реагирования
Что такое среднее время реагирования?
MTTR (среднее время реагирования) — это среднее время, необходимое для восстановления после сбоя продукта или системы с момента первого оповещения об этом сбое. Оно не включает время задержки в вашей системе оповещения.
Как рассчитать среднее время реагирования
Чтобы рассчитать этот MTTR, рассчитайте полное время отклика с момента получения оповещения до того, когда продукт или услуга снова полностью функционируют. Затем разделите его на количество инцидентов.
Например: если у вас было 4 инцидента за 40-часовую рабочую неделю и вы потратили на них 1 час (от оповещения до исправления), то MTTR за эту неделю будет составлять 15 минут.
Как и когда использовать среднее время реагирования
MTTR часто используется в кибербезопасности при измерении успеха команды в нейтрализации атак на систему.
MTTA: среднее время подтверждения
Что такое среднее время подтверждения?
MTTA (среднее время подтверждения) — это среднее время, которое проходит с момента отправки оповещения до начала работы над исправлением. Эта метрика полезна для измерения скорости реагирования вашей команды и эффективности вашей системы оповещения.
Как рассчитать среднее время подтверждения
Чтобы рассчитать MTTA, посчитайте время между отправкой оповещения и подтверждением его получения, а затем разделите на количество инцидентов.
Например: если у вас было 10 инцидентов и в общей сложности прошло 40 минут между отправкой оповещения и подтверждением его получения для всех 10, вы поделите 40 на 10 и получите в среднем 4 минуты.
Как и когда использовать среднее время подтверждения
MTTF: средняя наработка до отказа
Что такое средняя наработка до отказа?
MTTF (средняя наработка до отказа) — среднее время между неремонтируемыми отказами технологического продукта. Например, если автомобильные двигатели марки X исправно работают в среднем 500 000 часов, до того как они полностью выйдут из строя и будут подлежать замене, MTTF двигателей будет составлять 500 000.
Эта метрика помогает понять, как долго система будет исправно работать, и определить, превосходит ли новая версия системы старую. Метрика позволяет предоставить клиентам информацию об ожидаемом сроке исправной работы и о том, когда следует запланировать проверку системы.
Как рассчитать среднюю наработку до отказа
Средняя наработка до отказа — это среднее арифметическое, которое определяется как сумма общего времени работы оцениваемых продуктов, деленная на общее количество устройств.
Например: предположим, вы рассчитываете MTTF лампочек. Как долго лампочки бренда Y в среднем работают, прежде чем они перегорают? Далее предположим, что для расчета у вас есть четыре лампочки (если вам нужны статистически значимые данные, вам понадобится гораздо больше, но, чтобы не перегружать вас расчетами, давайте возьмем всего четыре).
Лампочка А горит 20 часов. Лампочка B — 18. Лампочка C —21. И лампочка D —21 час. Это в общей сложности 80 часов горения лампочки. Делим на четыре и получаем MTTF в 20 часов.

Проблема, связанная со средней наработкой до отказа
Для таких случаев, как лампочки, смысл MTTF совершенно ясен. Мы можем включить лампочки и ждать до тех пор, пока не перегорит последняя, а затем использовать полученную информацию, чтобы сделать выводы о времени работы наших лампочек.
Но что происходит, когда мы измеряем что-то, что не перегорает так быстро? Что-то, что должно бесперебойно работать в течение долгих лет? Хотя MTTF часто используется и для этих случаев, эта метрика — не лучший выбор. Потому что мы не держим продукт включенным до тех пор, пока он не выйдет из строя; в основном мы запускаем продукт на определенный период времени и измеряем количество выходов из строя.
Например: предположим, что мы пытаемся получить статистику MTTF на планшетах бренда Z. Планшеты по-хорошему рассчитаны на долгие годы, но у бренда Z есть всего шесть месяцев для сбора данных. Поэтому тестируют 100 планшетов в течение шести месяцев. Допустим, один планшет ломается ровно на шестимесячной отметке.
Итак, мы умножаем общее время работы (полгода, умноженное на 100 планшетов) и получаем 600 месяцев. Только один планшет вышел из строя, так что мы разделим значение на один, и наш MTTR будет составлять 600 месяцев, то есть 50 лет.
Прослужат ли планшеты Brand Z в среднем 50 лет каждый? Маловероятно. И поэтому эта метрика не подходит в таких случаях.
Как и когда использовать среднюю наработку до отказа
MTTF хорошо работает, когда вы пытаетесь оценить средний срок службы продуктов и систем с коротким сроком службы (например, лампочек). Показатель предназначен только для случаев, когда оценивается полное прекращение работы продукта. При расчете времени между инцидентами, требующими восстановления, предпочтительной аббревиатурой является MTBF (средняя наработка на отказ).
MTBF, MTTR, MTTF и MTTA
Итак, какую метрику лучше использовать, когда дело доходит до отслеживания и улучшения управления инцидентами?
Хотя они иногда используются взаимозаменяемо, каждая метрика позволяет рассмотреть ситуацию с разных сторон. При совместном использовании они могут показать более полную картину и дать вам понять, насколько успешна ваша команда в управлении инцидентами и что она может улучшить.
![]()
Среднее время восстановления показывает, как быстро у вас получается возобновить работу ваших систем.
Рассчитайте среднее время реагирования, и вы получите представление о том, сколько времени восстановления тратится на работу вашей команды и сколько — на получение оповещения.
Потом рассчитайте среднее время исправления, и вы поймете, сколько времени команда тратит на исправление, а сколько на диагностику.
Теперь рассчитайте среднее время разрешения, и вы начнете понимать весь процесс исправления и решения проблем, выходящий за рамки самого простоя, который они вызывают.
Посчитайте среднюю наработку на отказ, и картина станет еще шире: вы увидите, насколько успешна ваша команда в предотвращении или сокращении будущих проблем.
А затем добавьте среднюю наработку до отказа, чтобы понять полный жизненный цикл продукта или системы.

Просто удивительно то, насколько велико непонимание вокруг такого широко распространенного понятия, как MTBF (Mean Time Between Failure — «Время между сбоями» или «наработка на отказ» ), насколько смысла этой величины не понимают, зачастую, даже специалисты в области хранения данных.
Казалось бы — что может быть проще. «Наработка на отказ» это время беспроблемной работы, от первого включения нового диска, до момента отказа, посчитанная в часах.
Почти любой, кто поинтересуется значением, приводимым производителями, в качестве MTBF современных дисков, и с легкостью сделает несложные подсчеты, будет удивлен странной его величиной.
На сегодня величина MTBF приводится в миллион или даже полтора миллиона часов.
В году — примерно 8760 часов, значит, исходя из нашего понимания «физического смысла» этого значения, производитель планирует «наработку на отказ» для любого такого диска более ста лет (114 лет, для миллиона часов MTBF), что является очевидной нелепостью для каждого, у кого подыхали жесткие диски.
Тогда что это за «миллион часов», где и каким образом он измерен?
Конечно же производитель не гоняет диск 114 лет, оценка производится искусственно, но откуда вообще взялась величина в «миллион часов»?
Дело в том, что MTBF измеряется для всей эксплуатируемой «дисковой популяции», и распространяется на период объявленного гарантийного срока для данного типа дисков. Оба выделенных момента являются важными, и часто опускаются в описании, что и приводит к принципиальному непониманию.
Или же представим себе чуть более приближенную к реальности ситуацию.
Допустим, для простоты подсчета, у нас есть система хранения на 115 дисков. Для каждого диска производитель приводит MTBF равный миллиону часов. Но надо принять во внимание то, что в большой дисковой популяции общий MTBF, то есть вероятность отказа, растет, с увеличением количества используемых дисков.
Для 115 дисков, исходя из приводимой вендором величины MTBF, мы вправе ожидать, что хотя бы один диск из популяции в 115 выйдет из строя до конца трехлетнего гарантийного срока.
Этот вариант уже куда более похож на правду.
Строго говоря, на практике, вместо MTBF гораздо практичнее пользоваться параметром AFR — Annual Failure Rate, или «ежегодная вероятность сбоев», выводимом из MTBF.
Он вычисляется как: AFR = 1-exp(-8760/MTBF)
Величина AFR для диска с миллионом часов MTBF составляет 0,87%, что, в принципе, хоть и чуть завышено (Google в известном исследовании 2007 года показывает для новых дисков в пределах гарантийного срока как раз AFR в районе 1%), но, все же уже довольно хорошо согласуется с практикой.
Любопытно, что, например, такой производитель жестких дисков как WD теперь вовсе перестал указывать величину MTBF, перейдя на указание другого параметра: «power on/off cycles», по видимому не в последнюю очередь именно в связи с явно видимым непониманием и неочевидностью применения указываемой величины MTBF пользователями.
Когда в разговорах возникает фраза «банковская система», воображение рисует сверхнадёжную систему, построенную на самом дорогом оборудовании, кластеризованную на всех возможных уровнях и ограждённую от окружающего мира доступными и недоступными средствами защиты. Действительно, такие системы существуют. Но…

Если посмотреть вакансии разработчиков в банке, то вполне можно увидеть там среди требований знания Cassandra, MongoDB и других платформ, которые никак не внушают мыслей о 100% доступности. Да и такие СУБД как Oracle или Microsoft SQL Server где-то устанавливают на кластер из дорогих серверов, подключённых к самым надёжным и высокопроизводительным массивам, а где-то – на обычную виртуальную машину в ферме из самого что ни на есть commodity.
Причины очевидны – избыточные решения дороги. Но как найти компромисс между стоимостью платформы и её надёжностью?
Давным-давно, когда информационных систем на предприятии было немного, инфраструктура для каждой системы была произведением искусства. Со временем систем стало больше, поддерживать несколько сотен разных конфигураций оборудования и программного обеспечения стало накладно, и инфраструктурные подразделения пришли к стандартизации. Например, набор инфраструктурных решений для реляционной СУБД, которые могут использовать приложения, может выглядеть так:
- серверы класса hi-end с дисковыми массивами класса hi-end плюс синхронная репликация;
- серверы класса midrange с дисковыми массивами класса midrange плюс синхронная репликация;
- серверы класса midrange с дисковыми массивами класса midrange плюс асинхронная репликация;
- commodity-серверы с дисковыми массивами класса midrange без репликации.
Можно составить список «самых важных приложений, которые должны работать во что бы то ни стало». При этом возникает две проблемы:
Конфигурация оборудования для оставшихся приложений зависит от «веса» владельца системы. В результате какой-нибудь сервис электронных больничных листов работает на самом дорогом оборудовании, потому что это любимое детище главного бухгалтера, с которым никому не хочется ссориться. Налицо неразумная трата денег.
Некоторые приложения могут не войти в список «самых важных» потому, что про них не подумали. Например, все помнят про процессиниг банковских карт, но никто не помнит про проверку клиентов по «чёрным спискам», которая должна работать при каждой операции. В результате отказ такой системы становится неприятной неожиданностью и приводит к серьёзным проблемам.
Существует формальная методика, позволяющая сделать правильный выбор и защитить то, что нуждается в защите, не переплатив за то, за что можно не переплачивать.
Для начала вводится классификация приложений по уровню критичности. Как правило, этих уровней четыре. Называться они могут, например, так:
- Mission critical;
- Business critical;
- Business operational;
- Office productivity.
При оценке важно соблюдать два правила:
Систему оценивает бизнес, а не обслуживающее её подразделение IT. Критичность не должна определяться тем, насколько долго или трудоёмко обслуживание системы. Единственный критерий – убытки, которые понесёт бизнес от простоя системы.
Что определяет уровень критичности?
- Приоритет обслуживания при массовых инцидентах. Безусловно, любую систему нужно восстанавливать после аварии, но если авария задела несколько систем, то сначала нужно восстановить наиболее критичные.
- Типовые значения SLA (service level agreement). Если простой системы приносит убытки, то правильный путь – не жаловаться на администраторов, а повышать её уровень критичности.
- Стандартные инфраструктурные решения. Каждое из перечисленных выше решений обладает определёнными характеристиками надёжности, обеспечивающими скорость восстановления при сбоях, а также определённой стоимостью.

Это не значит, что на вашем предприятии распределение систем по классам должно быть именно таким. Но в любом случае – если в класс Mission critical попало больше 15% эксплуатируемых систем, это повод серьёзно задуматься.
На вопрос «насколько нужна та или иная система», любой владелец ответит «очень». Следовательно, нужно задавать другой вопрос: а что случится, если система остановится? Класс критичности системы зависит от тяжести последствий остановки системы и скорости их наступления.
Давайте рассмотрим несколько банковских систем.
Расчётная система обеспечивает (сюрприз!) расчёты между клиентами – юридическими лицами. Если вдруг крупный корпоративный клиент не сможет сделать платёж контрагенту, то банк потеряет весьма существенную сумму, поэтому расчётная система, без сомнения, попадёт в высший класс критичности.
Возьмём карточный процессинг. Если сотня-другая клиентов не смогут расплатиться картой, потери банка будут невелики, но такой массовый отказ в обслуживании недопустим сам по себе.
Теперь возьмём систему, которая ведёт вклады. Если остановится эта система, то убытки банка вновь будут невелики, а отказ в обслуживании не будет столь массовым, как в случае процессинга. Но нужна ли нам передовица в газете с заголовком «Банк отказывается выдавать вклады»? Вопрос риторический.
Наконец, возьмём главную бухгалтерскую книгу. Если вдруг с ней что-то случится, то клиенты ничего не заметят, т. к. эта система в обслуживании клиентов вообще не участвует. Но стоит задержать сдачу баланса, как санкции Центробанка не заставят себя ждать.
Итак, негативные последствия от простоя системы можно разделить на 4 класса:
- Экономические (непосредственные убытки);
- Клиентские (отказ в обслуживании);
- Репутационные (негативные реакции в средствах массовой информации);
- Юридические (от предупреждений и штрафов до судебных исков и отзыва лицензии).
| 0 | 1 | 2 | 3 | 4 | |
|---|---|---|---|---|---|
| Экономические | нет | <0.1% плановой прибыли | 0.1%..0.5% плановой прибыли | 0.5%..1% плановой прибыли | >1% плановой прибыли |
| Клиентские | нет | 1 клиент | >1% клиентов | >5% клиентов | >10% клиентов |
| Репутационные | нет | огласка маловероятна | огласка в локальных СМИ | огласка в региональных СМИ | огласка в федеральных СМИ |
| Юридические | нет | предупреждения регуляторов | штрафы регуляторов | гражданские иски | риск отзыва лицензии |
Разумеется, все цифры условны, все методики подсчёта основываются исключительно на экспертной оценке, а простор для споров, что считать «региональными СМИ» и как относиться к негативным статьям в популярных блогах, поистине безграничен. Но в крупной корпорации наверняка найдётся и юридический отдел, и PR-служба, которые с готовностью выскажут компетентное мнение.
Следующим шагом нужно выбрать временные интервалы, на которых мы будем оценивать убытки. Например, час, 4 часа, 8 часов, 24 часа. Эти интервалы произвольны и не имеют никакого отношения к SLA, заключённым на оцениваемые системы. Хотя в дальнейшем было бы правильно привязать типовые SLA именно к этим интервалам.
Теперь владелец каждой системы заполняет матрицу из 16 клеток. В таблице ниже числа даны для примера. Единственное, что принципиально важно, – оценка последствий для более длинного интервала не может быть меньше, чем оценка для более короткого интервала.
| до 1 часа | 1..4 часа | 4..8 часов | 8..24 часа | |
|---|---|---|---|---|
| Экономические | 1 | 1 | 3 | 3 |
| Клиентские | 1 | 2 | 2 | 3 |
| Репутационные | 0 | 0 | 1 | 2 |
| Юридические | 1 | 2 | 3 | 4 |
Чтобы из этой матрицы получить окончательную оценку, осталось выполнить три шага.
Шаг первый – для каждого временного интервала выбираем максимальную оценку:
| до 1 часа | 1..4 часа | 4..8 часов | 8..24 часа | |
|---|---|---|---|---|
| МАКСИМУМ | 1 | 2 | 3 | 4 |
Шаг второй: по матрице транслируем полученные оценки в классы критичности:
| Баллы | до 1 часа | 1..4 часа | 4..8 часов | 8..24 часа |
|---|---|---|---|---|
| 4 | MC | MC | BC | BC |
| 3 | MC | BC | BC | BO |
| 2 | BO | BO | BO | OP |
| 1 | BO | BO | OP | OP |
Для данной системы получаем следующие оценки:
| до 1 часа | 1..4 часа | 4..8 часов | 8..24 часа | |
|---|---|---|---|---|
| КЛАСС | BO | BO | BC | BC |
И, наконец, из всех полученных оценок выбираем максимальную – в данном случае оцениваемая система должна быть отнесена к классу Business critical.
Получив эти оценки, мы вполне можем обоснованно выбирать для каждой системы то или иное инфраструктурное решение.
Осталось несколько нюансов, без которых описанная методология была бы неполной.
Если система обеспечивает работоспособность другой системы, то её класс критичности не может быть ниже, чем класс зависимой системы. Например, Active Directory вообще никак не относится к бизнесу. Но если вдруг она встанет, то последствия для многих бизнес-приложений будут самые печальные, и поэтому AD однозначно относится к классу Mission critical.
Убытки, понесённые в результате простоя системы, не могут быть ниже, чем убытки, нанесённые прерыванием бизнес-процесса, который эта система обеспечивает. В свете этого правила очень интересно бывает оценить корпоративную систему электронной почты, ибо внезапно оказывается, что на неё завязан обмен критичной информацией.
Если в компании одну систему используют несколько блоков, и оценки этих блоков для системы отличаются, то следует использовать максимальную оценку. Мало того, даже критерии оценки могут быть разными. Так, например, оценка невозможности обслужить одного клиента может сильно отличаться в зависимости от того, что это за клиент – обычный «физик», VIP или крупный корпоративный клиент.
Снабдите свои системы ярлыками – и да будет ваша инфраструктура не менее надёжна, чем нужно, но и не дороже, чем можно!

Задача: в Техническом Задании на комплексную IT-систему был пункт – «выполнить расчет коэффициента готовности системы».
Решение: использовать материалы из ГОСТ, запросить дополнительные данные у вендоров по элементам оборудования и использовать несложную математику для выполнения итогового расчета.
Нормативные ссылки:
ГОСТ Р 27.002-2009 («Надежность в технике (ССНТ). Термины и определения»)
ГОСТ Р 27.003-2011 Надежность в технике (ССНТ). Управление надежностью. Руководство по заданию технических требований к надежности
ГОСТ 27.002-89 Надежность в технике (ССНТ). Основные понятия. Термины и определения
Согласно ГОСТ Р 27.002-2009 («Надежность в технике (ССНТ). Термины и определения») коэффициент готовности (в области надежности в технике) — это вероятность того, что изделие в данный момент времени находится в работоспособном состоянии, определенная в соответствии с проектом при заданных условиях функционирования и технического обслуживания.
Таким образом, готовность отражает способность системы непрерывно выполнять свои функции.
В общем случае, для информационных и компьютерных устройств, коэффициент готовности – это вероятность того, что компьютерная система в любой (произвольный) момент времени будет находиться в рабочем состоянии.
Коэффициент готовности (K) определяется по формуле:
K = MTBF/(MTBF+MTTR),
где:
— MTBF (Mean Time Between Failure) — среднее время наработки на отказ (средняя наработка между отказами);
— MTTR (Mean Time To Repair) — среднее время восстановления работоспособности (среднее время до восстановления).
В отличие от надежности, величина которой определяется только значением MTBF, готовность зависит еще и от времени, необходимого для возврата системы в рабочее состояние.
Итак, у нас есть определенная IT-система (сервера стоечного исполнения, блейд-сервера, система хранения данных).
Отказоустойчивость на уровне оборудования такой IT-системы позволяет ее сервисам продолжить работу в случае аппаратной неисправности отдельных компонентов серверного оборудования, системы хранения данных или инфраструктуры.
Отказоустойчивость функционирования внутренних компонентов IT-системы достигается применением следующих технологий:
- резервирование блоков питания серверного оборудования, систем хранения данных;
- резервирование сетевых адаптеров серверов;
- резервирование оптических адаптеров серверов;
- резервирование линий кабельных соединений коммутации серверов и сети передачи данных и сети хранения данных;
- дублирование модулей блэйд-шасси: блоки питания, модули управления, вентиляторы, модули коммутации;
- размещение информации на дисковых системах хранения данных с применением отказоустойчивых групп дисков (RAID).
Электропитание оборудования IT-системы осуществляется от двух независимых источников. Подключение оборудования IT-системы к внешним сетям передачи данных и сетям хранения данных также дублируется.
Все подсистемы IT-системы имеют резервирование, поэтому при отказе любого элемента оборудование IT-системы в целом останется в работоспособном состоянии. Более того, замена отказавшего элемента возможна без остановки оборудования IT-системы.
Вероятность (P) выхода одного компонента из строя в течение одного года составляет:
P = 1/MTBF.
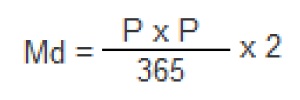
Отказ дублированного компонента приведет к отказу оборудования только при условии, что компонент-дублер тоже выйдет из строя в течение времени, необходимого для «горячей» замены компонента, отказавшего первым. Если гарантированное время замены компонента составляет 24 часа (1/365 года) (что соответствует сложившейся практике обслуживания серверного оборудования), то вероятность такого события в течение года:
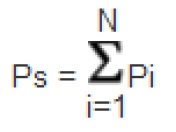
Вычислив вероятность отказа всех N компонентов оборудования IT-системы, можно рассчитать вероятность отказа оборудования IT-системы в течение одного года путем суммирования каждой вероятности отказа:
Так как отказы компонентов обычно распределены во времени равномерно, то, зная вероятность отказа оборудования IT-системы в течение года, можно определить время его наработки на отказ:
MTBFs = 1/Ps.
Коэффициент готовности оборудования IT-системы будет равен:
Kit = MTBFs/(MTBFs+MTTR).
Выполним расчет коэффициента готовности оборудования IT-системы из 26 компонентов (каждый из компонентов имеет несколько элементов).
Основная проблема в таблице ниже – актуальные данные по параметру MTBF для каждого компонента. Эти данные очень неохотно предоставляют вендоры. Часто приходится вступать в переписку с представителями вендоров для просьбы предоставления и уточнения этих данных.
В таблице ниже выполнен расчет для «устаревшей» IT-системы, но сейчас она функционирует уже почти пятый год в боевом режиме без отказа компонентов, но уже Заказчик планирует миграцию на новые компоненты не дожидаясь крайний сроков из итоговых расчетных данных.

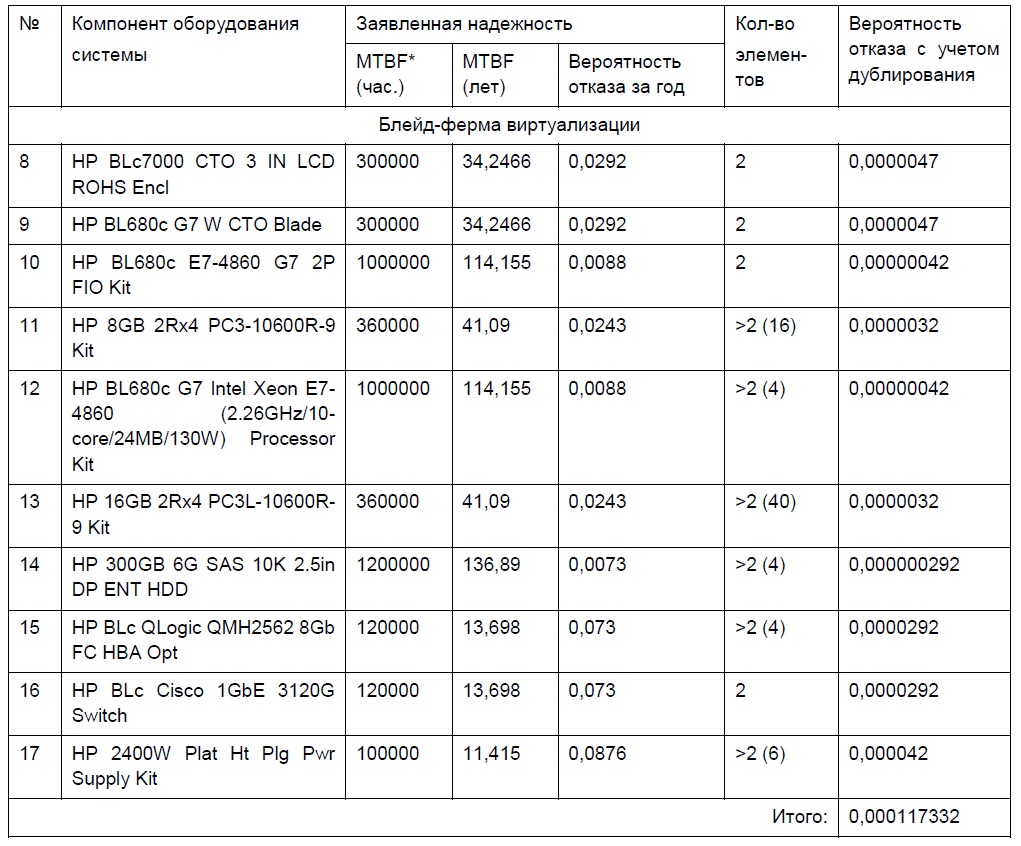

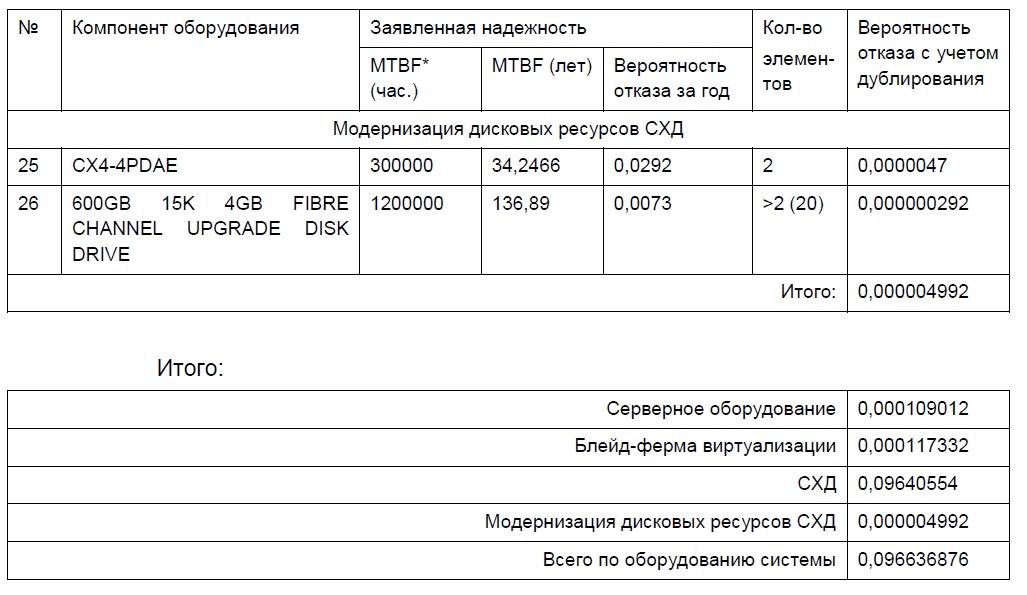
(*) – исходные данные по MTBF являются оценочными, предоставленными по данным позициям оборудования производителя или их аналогам.
В итоге расчетные данные по оборудованию нашей системы:
- вероятность отказа оборудования системы в течение года: 0,0966;
- MTBF оборудования системы (лет): 10,35 (90666 часов);
- среднее время устранения неисправности (часов): 24;
- коэффициент готовности оборудования системы (%): 99,97;
- среднее время простоя в год (часов):2,61 (156 минут).
Этот расчет, конечно, очень оценочный. Но основное понимание, что система оптимальна или нуждается в дополнительных элементах, может предоставить.
По факту данные таблицы с расчетами заносятся в нужный раздел проектной документации и выдаются Заказчику.
Интересно выполнить такой расчет для комплекта сетевого оборудования (с максимальным разбиением на элементы до SFP-модуля и блоков питания) и сравнить с разными вендорами данные итоговые.
Читайте также: