
Coth в r studio как записать
Обновлено: 06.07.2024
Для работы с R необходимо его сначала скачать и установить.
-
R
- Общая функция
- Математическая функция
- Статистическая функция
- Название: нормализовать.
- количество аргументов: нам нужен только один аргумент, который является столбцом, который мы используем в наших вычислениях.
- Тело: это просто формула, которую мы хотим вернуть.
- числовой (numeric);
- целочисленный (integer);
- текстовый (character);
- категориальный (Factor);
- логический (logical).
- После имени таблицы пространство внутри квадратных скобок следует разделить на две части запятой.
- Все, что находится до запятой, относится к строчкам, все что после - к столбцам.
- Поставьте минус перед номером столбца или номером строки, которую собираетесь удалить.
- Если таких элементов несколько, используйте функцию c(. ) : внутри скобок перечисление элементов через запятую.
- сайт http://stackoverflow.com/ (уже подробно разобраны тысячи вопросов по этой теме)
- книгу-справочник "R book" by Michael J. Crawley (легко найти бесплатную PDF версию в интернете).
-
, найдите большую кнопку Download R (номер версии) for Windows. , если маку меньше, чем 5 лет, то смело ставьте *.pkg файл с последней версией. Если старше, то поищите на той же странице версию для вашей системы. , также можно добавить зеркало и установить из командной строки:
В данной книге используется следующая версия R:
После установки R необходимо скачать и установить RStudio:
Если вдруг что-то установить не получается (или же вы просто не хотите устанавливать на компьютер лишние программы), то можно работать в облаке, делая все то же самое в веб-браузере:
Первый и вполне закономерный вопрос: зачем мы ставили R и отдельно еще какой-то RStudio? Если опустить незначительные детали, то R – это сам язык программирования, а RStudio – это среда (IDE), которая позволяет в этом языке очень удобно работать.
RStudio – это не единственная среда для R, но, определенно, самая удобная на сегодняшний день. Почти все пользуются именно ею и не стоит тратить время на поиск чего-то более удобного и лучшего. Если же вы привыкли работать с Jupyter Notebook, то в R обычно вместо него используется великолепный RMarkdown – с помощью которого и написан этот онлайн-учебник, кстати говоря. И с RMarkdown мы тоже будем разбираться!
2.2 Знакомство с RStudio
Так, давайте взглянем на то, что нам тут открылось:

В первую очередь нас интересуют два окна: 1 - Code Editor (окно для написания скриптов) 1 и 2 - R Console (консоль). Здесь можно писать команды и запускать их. При этом работа в консоли и работа со скриптом немного различается.
В 2 - R Console вы пишите команду и запускаете ее нажиманием Enter . Иногда после запуска команды появляется какой-то результат. Если нажимать стрелку вверх на клавиатуре, то можно выводить в консоль предыдущие команды. Это очень удобно для запуска предыдущих команд с небольшими изменениями.
В 1 - Code Editor для запуска команды вы должны выделить ее и нажать Ctrl + Enter ( Cmd + Enter на macOS). Если не нажать эту комбинацию клавиш, то команда не запустится. Можно выделить и запустить сразу несколько команд или даже все команды скрипта. Все команды скрипта можно выделить с помощью сочетания клавиш Ctrl + A на Windows и Linux, Cmd + A на macOS. 2 Как только вы запустите команду (или несколько команд), соответствующие строчки кода появятся в 2 - R Console, как будто бы вы запускали их прямо там.
Обычно в консоли удобно что-то писать, чтобы быстро что-то посчитать. Скрипты удобнее при работе с длинными командами и как способ сохранения написанного кода для дальнейшей работы. Для сохранения скрипта нажмите File - Save As. . R скрипты сохраняются с разрешением .R, но по своей сути это просто текстовые файлы, которые можно открыть и модифицировать в любом текстовом редакторе а-ля “Блокнот.”
3 - Workspace and History – здесь можно увидеть переменные. Это поле будет автоматически обновляться по мере того, как Вы будете запускать строчки кода и создавать новые переменные. Еще там есть вкладка с историей всех команд, которые были запущены.
4 - Plots and files. Здесь есть очень много всего. Во-первых, небольшой файловый менеджер, во-вторых, там будут появляться графики, когда вы будете их рисовать. Там же есть вкладка с вашими пакетами ( Packages ) и Help по функциям. Но об этом потом.
2.3 R как калькулятор
R – полноценный язык программирования, который позволяет решать широкий спектр задач. Но в первую очередь R используется для анализа данных и статистических вычислений. Тем не менее, многими R до сих пор воспринимается как просто продвинутый калькулятор. Ну что ж, калькулятор, так калькулятор.
Давайте начнем с самого простого и попробуем использовать R как калькулятор с помощью арифметических операторов + , - , * , / , ^ (степень), () и т.д.
Самое простое, что вы можете делать с программным продуктом, – это использовать его в качестве калькулятора.
Например, посчитаем, чему равняется 5 плюс 7.
Создаем новый файл типа « R script » через панель управления: File – New File – R script. Можно воспользоваться кнопкой на панели инструментов, которая на рис. 1 обведена под номером 1.
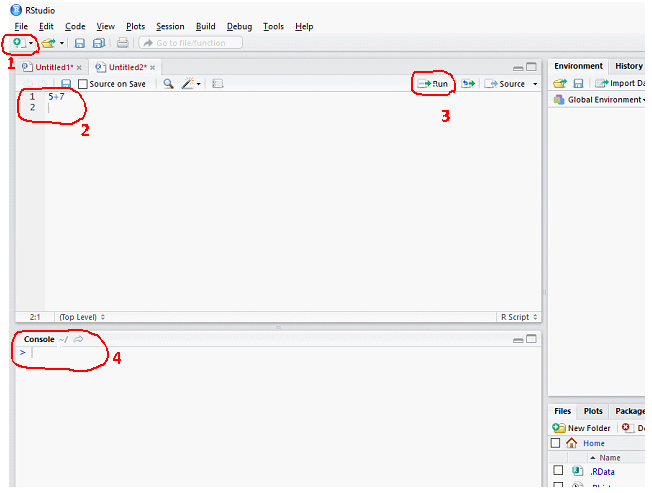
Рис. 1. Начало работы с R-Studio
Иным способом расчета – является запись выражения сразу в Консоли ( Console) – помечено на рис. 1 под номером 4 . После нажатия Enter программа выдаст ниже ответ. Вернуться же к выражению и изменить его не получится. При нажатии на клавиатуре кнопки «Стрелка верх» (↑) в новой строке (после >) появится предыдущая запись. Нажимая несколько раз, вы выбираете нужное выражение из предыдущих записей и в случае необходимости вносите изменения.
Ввод выражения
Если же нужно присвоить значение величине, то используется оператор
который получается путем набора знака меньше « < » и минус (тире) «-».
чтобы убедиться в том, что величина x теперь равняется 5, можно напечатать далее в консоли
Очистить консоль
Чтобы очистить консоль воспользуйтесь меню Edit , где выберите команду Clear Console , или сочетанием клавиш Ctlr+L.
График
Графики – это важный инструмент разведочного анализа данных, с помощью которого можно выявлять характеристики (паттерны) и тренды, делать понятными результаты статистического анализа.
Главной функцией для построения графиков является
Подключите данные по скорости выведения индометацина из организма человека (Kwan K.C. et al. (1976) Kinetics of Indomethacin absorption, elimination, and enterohepatic circulation in man. Journal of Pharmacokinetics and Biopharmaceutics 4, 255-280) с помощью команды
Индометацин представляет собой один из наиболее активных противовоспалительных препаратов. Результаты этого исследования входят в базовый набор данных R и доступны по команде.
Если просто ввести
получим весь набор данных.
видим, что в состав таблицы Indometh входят переменные Subject (испытуемый), time (время с момента введения препарата) и conc (концентрация препарата в крови). Чтобы облегчить дальнейшую работу, прикрепим таблицу Indometh к поисковому пути R:
Благодаря этому, напрямую обращаемся к переменным таблицы Indometh (т.е. использовать их имена непосредственно, например, time вместо Indometh$time, о чем будем говорить дальше).
Зависимость концентрации индометацина в крови от времени можно легко изобразить при помощи следующей команды:
График виден в правом нижнем углу окна R во вкладке Plots (рис. 2).
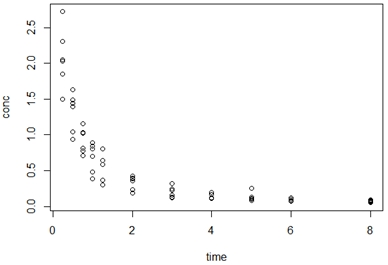
Рис. 2. График зависимости концентрации в крови от времени
Построим график функции генерирования значений случайной величины на основе нормального закона распределения. Математическое ожидание равно 3, а стандартное отклонение – 0,25.
С помощью функций plot() и rnorm(n, mean, sd) записываем
Получаем график, содержащий 1000 значений случайной величины с нормальным распределением и заданными параметрами, как показано на рис. 3.
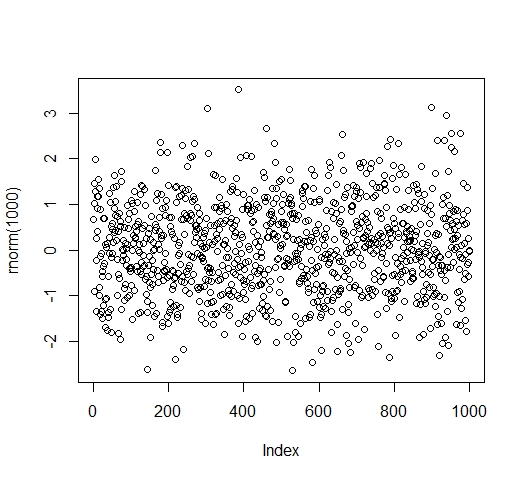
Рис. 3. График случайной величины с нормальным законом распределения, mean = 3 и sd = 0.25
выдает на экран график 1000 значений, распределенных случайным образом по нормальному закону при мат. ожидании, равном 0, и стандартном отклонении, – 1.
Общий подход к функции состоит в том, чтобы использовать часть аргумента в качестве входных данных , передать часть тела и, наконец, вернуть выходные данные . Синтаксис функции следующий:
В этом уроке мы узнаем
R важные встроенные функции
В R. Есть много встроенных функций в R. R сопоставляет ваши входные параметры с аргументами функции, либо по значению, либо по положению, а затем выполняет тело функции. Аргументы функции могут иметь значения по умолчанию: если вы не укажете эти аргументы, R примет значение по умолчанию.
Примечание . Исходный код функции можно увидеть, запустив имя самой функции в консоли.

Мы увидим три группы функций в действии
Общие функции
Мы уже знакомы с общими функциями, такими как функции cbind (), rbind (), range (), sort (), order (). Каждая из этих функций имеет определенную задачу, принимает аргументы для возврата вывода. Ниже приведены важные функции, которые нужно знать:
функция diff ()
Если вы работаете с временными рядами , вам нужно фиксировать ряды, принимая их значения запаздывания . Стационарный процесс позволяет постоянно среднее значение, дисперсия и автокорреляция с течением времени. Это в основном улучшает прогнозирование временного ряда. Это легко сделать с помощью функции diff (). Мы можем построить случайные данные временных рядов с трендом, а затем использовать функцию diff () для стационарного ряда. Функция diff () принимает один аргумент, вектор и возвращает подходящую задержанную и повторенную разницу.
Примечание : нам часто нужно создавать случайные данные, но для изучения и сравнения мы хотим, чтобы числа были одинаковыми на разных машинах. Чтобы все мы генерировали одни и те же данные, мы используем функцию set.seed () с произвольными значениями 123. Функция set.seed () генерируется в процессе генерации псевдослучайных чисел, которая заставляет все современные компьютеры иметь одинаковую последовательность чисел. Если мы не используем функцию set.seed (), мы все будем иметь разную последовательность чисел.

функция length ()
Во многих случаях мы хотим знать длину вектора для вычисления или для использования в цикле for. Функция length () считает количество строк в векторе x. Следующие коды импортируют набор данных автомобилей и возвращают количество строк.
Примечание : length () возвращает количество элементов в векторе. Если функция передается в матрицу или фрейм данных, возвращается число столбцов.
Вывод:
Вывод:
Математические функции
R имеет массив математических функций.
| оператор | Описание |
|---|---|
| абс (х) | Принимает абсолютное значение х |
| Журнал (х, база = у) | Принимает логарифм x с основанием y; если база не указана, возвращает натуральный логарифм |
| ехр (х) | Возвращает экспоненту х |
| SQRT (х) | Возвращает квадратный корень из х |
| факториала (х) | Возвращает факториал x (x!) |
Вывод:
Вывод:
Вывод:
Статистические функции
Стандартная установка R содержит широкий спектр статистических функций. В этом уроке мы кратко рассмотрим наиболее важную функцию.
Основные статистические функции
Среднее значение х
Стандартное отклонение х
Стандартные оценки (Z-оценки) х
Резюме x: среднее, минимальное, максимальное и т. Д.
Вывод:
Вывод:
Вывод:
Вывод:
Вывод:
Вывод:
Вывод:
До этого момента мы узнали много встроенных функций R.
Примечание : будьте осторожны с классом аргумента, то есть с числовым, логическим или строковым. Например, если нам нужно передать строковое значение, нам нужно заключить строку в кавычку: «ABC».
Написать функцию в R
В некоторых случаях нам нужно написать собственную функцию, потому что мы должны выполнить определенную задачу, а готовой функции не существует. Пользовательская функция включает в себя имя , аргументы и тело .
Примечание . Рекомендуется называть пользовательскую функцию отличной от встроенной функции. Это позволяет избежать путаницы.
Функция с одним аргументом
В следующем фрагменте мы определяем простую квадратную функцию. Функция принимает значение и возвращает квадрат значения.
Объяснение кода:
Когда вы закончите использовать функцию, мы можем удалить ее с помощью функции rm ().
Окружающая среда
В R среда представляет собой набор объектов, таких как функции, переменные, фрейм данных и т. Д.
R открывает окружение каждый раз, когда запрашивается Rstudio.
Доступной средой верхнего уровня является глобальная среда , называемая R_GlobalEnv. И у нас есть местная среда.
Мы можем перечислить содержимое текущей среды.
Вывод
Вы можете увидеть все переменные и функции, созданные в R_GlobalEnv.
Приведенный выше список будет отличаться для вас в зависимости от исторического кода, который вы выполняете в R Studio.
Обратите внимание, что аргумент функции square_function n не находится в этой глобальной среде .
Новая среда создается для каждой функции. В приведенном выше примере функция square_function () создает новую среду внутри глобальной среды.
Чтобы прояснить разницу между глобальной и локальной средой , давайте изучим следующий пример
Эти функции принимают значение x в качестве аргумента и добавляют его к y, определяемому снаружи и внутри функции.

Функция f возвращает результат 15. Это потому, что у определяется в глобальной среде. Любая переменная, определенная в глобальной среде, может использоваться локально. Переменная y имеет значение 10 во время всех вызовов функций и доступна в любое время.
Посмотрим, что произойдет, если переменная y определена внутри функции.
Нам нужно сбросить `y` перед запуском этого кода, используя rm r

Выход также равен 15, когда мы вызываем f (5), но возвращает ошибку, когда мы пытаемся вывести значение y. Переменная y не находится в глобальной среде.
Наконец, R использует самое последнее определение переменной для передачи внутри тела функции. Давайте рассмотрим следующий пример:

R игнорирует значения y, определенные вне функции, потому что мы явно создали переменную y внутри тела функции.
Функция нескольких аргументов
Мы можем написать функцию с более чем одним аргументом. Рассмотрим функцию под названием «раз». Это простая функция, умножающая две переменные.
Вывод:
Когда мы должны написать функцию?
Специалист по данным должен сделать много повторяющихся задач. Большую часть времени мы копируем и вставляем куски кода многократно. Например, нормализация переменной настоятельно рекомендуется, прежде чем мы запустим алгоритм машинного обучения. Формула для нормализации переменной:
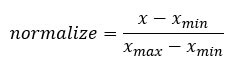
Мы продолжим в два шага, чтобы вычислить функцию, описанную выше. На первом шаге мы создадим переменную с именем c1_norm, которая будет масштабировать c1. На втором шаге мы просто копируем и вставляем код c1_norm и меняем его на c2 и c3.
Деталь функции со столбцом c1:
Номинатор:: data_frame $ c1 -min (data_frame $ c1))
Знаменатель: max (data_frame $ c1) -min (data_frame $ c1))
Следовательно, мы можем разделить их, чтобы получить нормализованное значение столбца c1:
Мы можем создать c1_norm, c2_norm и c3_norm:
Вывод:
Оно работает. Мы можем скопировать и вставить
затем измените c1_norm на c2_norm и c1 на c2. Мы делаем то же самое, чтобы создать c3_norm
Мы отлично перемасштабировали переменные c1, c2 и c3.
Однако этот метод подвержен ошибкам. Мы могли бы скопировать и забыть изменить имя столбца после вставки. Поэтому рекомендуется писать функцию каждый раз, когда вам нужно вставить один и тот же код более двух раз. Мы можем преобразовать код в формулу и вызывать его всякий раз, когда это необходимо. Чтобы написать нашу собственную функцию, нам нужно дать:
Мы продолжим шаг за шагом, чтобы создать функцию нормализации.
Шаг 1) Создаем номинатор , который есть. В R мы можем хранить знаменатель в переменной следующим образом:
Шаг 2) Вычислим знаменатель: . Мы можем повторить идею шага 1 и сохранить вычисления в переменной:
Шаг 3) Мы выполняем разделение между знаменателем и знаменателем.
Шаг 4) Чтобы вернуть значение вызывающей функции, нам нужно передать нормализацию внутри return (), чтобы получить выходные данные функции.
Шаг 5) Мы готовы использовать функцию, завернув все в скобки.
Давайте проверим нашу функцию с переменной c1:
Работает отлично. Мы создали нашу первую функцию.
Функции являются более всеобъемлющим способом выполнения повторяющихся задач. Мы можем использовать формулу нормализации для разных столбцов, как показано ниже:
Хотя пример прост, мы можем вывести силу формулы. Приведенный выше код легче читается и особенно позволяет избежать ошибок при вставке кодов.
Функции с условием
Иногда нам нужно включить условия в функцию, чтобы код мог возвращать разные выходные данные.
В задачах машинного обучения нам нужно разделить набор данных между набором поездов и тестовым набором. Набор поездов позволяет алгоритму учиться на данных. Чтобы протестировать производительность нашей модели, мы можем использовать тестовый набор для возврата показателя производительности. R не имеет функции для создания двух наборов данных. Мы можем написать нашу собственную функцию для этого. Наша функция принимает два аргумента и называется split_data (). Идея проста: мы умножаем длину набора данных (т.е. количество наблюдений) на 0,8. Например, если мы хотим разделить набор данных 80/20, а наш набор данных содержит 100 строк, тогда наша функция умножит 0,8 * 100 = 80. 80 строк будут выбраны, чтобы стать нашими данными обучения.
Мы будем использовать набор данных airquality для проверки нашей пользовательской функции. Набор данных airquality состоит из 153 строк. Мы можем видеть это с кодом ниже:
Вывод:
Мы будем действовать следующим образом:
Наша функция имеет два аргумента. Поезд аргументов является логическим параметром. Если установлено значение TRUE, наша функция создает набор данных train, в противном случае создает тестовый набор данных.
Мы можем действовать так же, как и в случае с функцией normalize (). Мы пишем код, как если бы это был только одноразовый код, а затем помещаем все с условием в тело для создания функции.
Шаг 1:
Нам нужно вычислить длину набора данных. Это делается с помощью функции nrow (). Nrow возвращает общее количество строк в наборе данных. Мы называем переменную длину.
Вывод:
Шаг 2:
Умножаем длину на 0,8. Он вернет количество строк для выбора. Должно быть 153 * 0,8 = 122,4
Вывод:
Мы хотим выбрать 122 строки среди 153 строк в наборе данных качества воздуха. Мы создаем список, содержащий значения от 1 до total_row. Мы сохраняем результат в переменной с именем split
Вывод:
split выбирает первые 122 строки из набора данных. Например, мы можем видеть, что наша переменная split собирает значения 1, 2, 3, 4, 5 и так далее. Эти значения будут индексом, когда мы выберем строки для возврата.
Шаг 3:
Нам нужно выбрать строки в наборе данных airquality на основе значений, хранящихся в переменной split. Это делается так:
Вывод:
Шаг 4:
Вывод:
Шаг 5:
Мы можем создать условие внутри тела функции. Помните, у нас есть последовательность аргументов, которая по умолчанию имеет логическое значение TRUE для возврата набора поездов. Чтобы создать условие, мы используем синтаксис if:
Вот и все, мы можем написать функцию. Нам нужно только изменить airquality на df, потому что мы хотим попробовать нашу функцию для любого фрейма данных, а не только для airquality:
Давайте попробуем нашу функцию для набора данных airquality. у нас должен быть один поезд с 122 рядами и тестовый набор с 31 строкой.

В прошлый раз мы говорили о том, как загрузить данные в среду R. Следующим важным этапом является их подготовка к визуализации и статистическому анализу. Для этого нам, как правило, необходимо внести некоторые изменения в таблицу, например: удалить столбец или строку, переименовать колонку, произвести сортировку или фильтрацию данных. Многие из этих операций можно сделать в Excel. Однако, зачастую возникают ситуации, когда необходимо изменить структуру или содержание таблицы прямо в ходе анализа. И вот тут у начинающих пользователей R могут возникнуть проблемы. В этой статье мы научимся их решать.
Структура таблицы и изменение типов данных
Лучший способ для закрепления новых знаний - это практика. Поэтому мы продолжим работать с таблицей физических данных студентов одного из военных вузов "voenvuz". Итак, загрузим знакомую уже нам таблицу в Rgui (таблицу можно скачать здесь).
Функции head и str
Для того, чтобы посмотреть правильно ли загрузились данные, введем команду head(voenvuz) , которая покажет первые 6 строчек нашей таблицы. Если все загрузилось нормально, то переходим к команде str(voenvuz) , которая выведет в консоль структуру таблицы.

Итак, в поле "data.frame" мы видим, что наша таблица состоит из 20 строк и 6 столбцов. Под ним располагается список названий столбцов, тип данных и первые шесть элементов каждого столбца. Обратите внимание, что колонки "Name" и "Rhesus.factor" сейчас хранят в себе категориальный тип данных (Factor), а остальные - целочисленный. Компьютер вычислил это автоматически, но в нашем случае - вычислил неверно. Прежде чем мы исправим типы этих данных, немного теоретической информации.
О типах данных
Почему важно правильно распознать тип данных в столбцах таблицы? Потому что при проведении статистических тестов, информация о типе данных учитывается и влияет на результат.
В языке R можно выделить 5 основных типов данных, хранящихся в столбцах таблицы:
Есть также комплексный (complex) и сырой (raw) типы данных, но они редко встречаются, и поэтому я о них здесь писать не буду. Пропущенные данные обозначаются как "NA" (от англ. not available - недоступно), и тогда R игнорирует их.
Изменим типы данных на практике
Посмотрим еще раз на таблицу. Логично предположить, что столбец "Name" с именами студентов не содержит никаких категорий, поэтому, преобразуем эту колонку в обычный текстовый тип данных:
Идем дальше, столбец "Age" был правильно идентифицирован как целочисленный. А вот столбцы "Height" и "Weight" являются скорее числовыми, т.к. могут содержать промежуточные значения, например 182.5. Переделаем их из типа Integer в тип Numeric:
Последнее, что нам нужно - это изменить тип данных в столбце "Blood.group". Каждый из студентов так или иначе имеет одну из 4 групп крови, соответственно, этот столбец содержит четыре категории: "1", "2", "3", "4". Другими словами, в нем должен находиться категориальный тип данных:
В итоге, повторив команду str(voenvuz) , мы должны получить вот такую картинку.

Редактирование элементов таблицы
Иногда возникают ситуации, когда необходимо вставить в таблицу столбец или строку, изменить значение элемента или название колонки. Наша таблица - не исключение и нуждается в доработке.
Добавление строк
Добавим в таблицу данные о двух новых студентах: Иване и Олеге. Для этого необходимо создать новую структуру - список (list) , В список мы по порядку вносим параметры, совпадающие со структурой таблицы (напомню, что в кавычках мы пишем нечисловые типы данных):
После, при помощи функции rbind (от англ. row bind, что дословно означает "связать строчки") мы объединим эти два списка с нашей таблицей:
Добавление столбцов
Теперь у нас в таблице два Ивана и два Олега. В данном случае хорошо было бы прописать для каждого студента свой идентификационный номер (ID), чтобы не запутаться, кто есть кто. Для этого создадим структуру, которая называется вектор (последовательность элементов одного типа). В него мы запишем последовательность от 1 до 22, так, чтобы у каждого из наших 22 студентов был свой уникальный ID:
Теперь объединим наш вектор с таблицей, воспользовавшись функцией cbind (от англ. column bind):
Не забудьте поменять тип данных нового столбца на символьный:
В качестве еще одного примера добавления новых столбцов с данными в таблицу, рассчитаем индекс массы тела (BMI) для каждого студента. Для этого, мы воспользуемся новым способом: напишем математическую формулу индекса на языке R и присвоим ей новое имя столбца "BMI" внутри нашей таблицы:
Проверьте, что получилось, используя уже знакомые нам функции head и str
Удаление строк и столбцов
Существует относительно "универсальная формула" для удаления элементов таблицы: new.data <- my.data[ , ]
Для того, чтобы корректно ее использовать необходимо запомнить несколько правил:
В нашем случае, удалять из таблицы ничего не надо, но я покажу пару примеров, назвав "укороченные" таблицы именами "trash1", "trash2", "trash3", "trash4":
Изменение имен столбцов и данных в ячейках:
Переименуем колонку "Rhesus.factor" на укороченное "Rhesus". Для этого нужно вызвать функцию names , написать в параметрах функции имя таблицы и номер столбца, и присвоить ему новое имя :
Изменение данные в ячейках таблицы не представляет особой сложности. В квадратных скобках прописываем координаты нужной ячейки (до запятой - строка, после запятой - столбец) и присваиваем новое значение:

После всех наших манипуляций мы должны получить вот такую таблицу данных:
Фильтрация и сортировка данных
В качестве примера, исключим из таблицы данных студентов, чей возраст больше 23 лет. Существует множество способов решения подобного рода задач, включая циклы if-else, for или while (о них будет написана отдельная статья). Однако в нашем случае хватит простого фильтра, основанного на логическом операторе "< wp-block-preformatted"> voenvuz.final <- voenvuz[voenvuz$Age <= 23, ]
Того же результата мы добьемся, если будем использовать логические операторы ">" (больше) и "!" (исключить):
Итак, мы получили финальную версию таблицы "voenvuz.final ". Осталось лишь упорядочить столбцы:
И произвести сортировку данных по имени студентов, используя функцию order :

После завершения редактирования таблицы, обновим имена строк, т.к. сейчас они не соответствуют действительности, и выведем таблицу на экран, введя имя таблицы в консоль:
Заключение
Описанные выше способы редактирования данных в таблице не уникальны, существует множество других методов и команд, позволяющих получить желаемый результат. Я рассказал лишь о наиболее простых и часто используемых. Для более детального ознакомления с этой темой я хотел бы порекомендовать два источника на английском языке:
Если у Вас возникли вопросы или проблемы с редактированием таблиц данных, Вы всегда можете оставить комментарий под этой статьей, и он не останется без внимания. А в качестве продолжения, читайте следующую статью, посвященную сохранению данных в среде R.
kod col.x col.y delta
1 00046949 1,000 1,000 2
2 00047069 3,000 3,000 2
3 00047070 19,000 19,000 2
4 00047071 49,000 49,000 2
5 00047072 21,000 21,000 2
356 CB128164 2,000 2
252 CB164884 1,000 2
Всем привет! Только начал изучать R и столкнулся с некой проблемой: Есть такая волшебная таблица. И задача, вывести в последний столбец разницу 2 и 3 го, и с учетом того что данные в последних строках NA, соответственно вывести в последний столбец NA2 или NA3, в зависимости от того где стоит NA. Проблема в том, что стандартные функции(о которых я еще мало знаю) удаляют строки с NA, а мне важно их сохранить и обработать.
Если у кого то будут мысли по теме, буду рад помощи. Да и еще, у меня типы данных факторы в первых трех столбцах, а последний число.
((ETH1567:0.07723012967,((ETH1478:0.03477412382,ETH1481:0.03998172409)100:0.01982264043,(LAV2470:0.04453502013,LAV2519:0.04666678739) и т.д. без пробелов.
Мне нужно извлечь блоки содержащие буквы и последующие цифры до знака двоеточия, т.е.: ETH1567 ETH1478 ETH1481 LAV2470 LAV2519
Я подобрал регулярку для этого: ([A-z]6*)
treenames <- grep("([A-z]5*)", tree, value = TRUE)
treenames
named character(0)
Перерыд весь stackoverflow и иже с ним, но ответа не нашел.
Буду благодарен за подсказку.
Здравствуйте, Данила! Вот одно из возможных решений Вашей задачи:
P.S. я мало анализирую текстовые данные, поэтому это решение вероятно не самое элегантное, но должно работать.
Отлично, все работает, большое спасибо!
Добрый день!
После преобразования матрицы в таблицу, провожу моделирование.
Выходит такая вещь:
Warning messages:
1: In log(b$y) : NaNs produced
2: In log(b$x1) : NaNs produced
3: In log(b$x2) : NaNs produced
4: In log(b$x4) : NaNs produced
5: In log(b$x5) : NaNs produced
6: In log(b$x6) : NaNs produced
Подскажите, пожалуйста, где ошибка? Голова кипит, не получается(
Доброго дня, Эсмира!
Сегодня все посмотрю и надеюсь смогу помочь ;)
Здравствуйте. Как пропустить заголовок таблицы; учесть, что заголовка нет?
В скобках функции read.table вставьте аргумент header = FALSE.
Здравствуйте! Подскажите как правильно оформить цикл и получить агрегированные данные из нескольких ресурсов гугл аналитики.
Потом я хочу взять в цикле каждый ресурс и получить агрегированные данные в объекте gaData по всем ресурсам функцией:
gaData <- get_ga(profileId = "resource_id",
start.date = "2019-09-01",
end.date = "2019-10-21",
metrics = "ga:sessions",
dimensions = "ga:date",
samplingLevel = "HIGHER_PRECISION",
max.results = 1000,
token = rga_auth)
Здравствуйте! Сходу ответить не смогу. Сейчас дописываю диссертацию, к сожалению совсем нет свободного времени.
Samoedd приветствую.
Вопрос
После расчетов на экране отображается таблица в таком формате
Qtr1 Qtr2 Qtr3 Qtr4
2000 119.28993 118.89396 118.10201 116.91410
2001 115.33021 114.48457 114.37718 115.00804
2002 116.37716 117.13394 117.27839 116.81051
2003 115.73031 114.20610 112.23790 109.82569
2004 106.96949 105.67921 105.95486 107.79644
2005 111.20394 112.48537 111.64071 108.66998
Сам пробовал искать ответ, но видимо это настолько просто, что об этом ни где не пишут. :-)
Заранее спасибо.
Здравствуйте, Alex! Извините, был в отпуске, не смог ответить. Ваш вопрос еще актуален или уже решен?
Читайте также: