
Как правильно создать кластер в датацентре vmware
Обновлено: 07.07.2024
Недавно вышла в свет редакция VMware Tanzu под названием Community Edition, пройти мимо было просто невозможно.
Под катом процедура инсталляции Tanzu Community Edition от первичной настройки до запуска первого контейнера в среде VMware vSphere 7.
Запуск первого кластера для рабочих нагрузок состоит из четырех этапов:
- Подготовка рабочей машины и установка Tanzu Community Edition;
- Настройка системы виртуализации VMware vSphere;
- Инсталляция Management кластера;
- Инсталляция Workload кластера.
Первый этап. Подготовка рабочей машины и установка Tanzu Community Edition:
В моем случае я выполняю настройки и инсталляцию из-под Ubuntu Server 20.04, хотя установку TCE можно выполнить как под Linux, так под Windows и Mac.
В чистой системе я выполняю все операции под пользователем tce, созданным на этапе инсталляции.
Выполним обновление системы:
Теперь установим docker и добавим в автозагрузку:
Добавим пользователя, от имени которого мы работаем, в группу docker для получения возможности запуска контейнеров без использования sudo:
Перезагрузка сервера после настроек и обновления:
Если к этому шагу все выполнено корректно, пользователь должен без каких-либо проблем запустить контейнер в Docker:
Теперь скачаем установочные файлы Tanzu Community Edition:
Разархивируем, затем запустим инсталляцию:
После установки TCE, в нашем распоряжении появляется новая команда tanzu :
Последним шагом на этом этапе скачаем kubectl:
На этом этап установки Tanzu Community Edition закончен.
Этап 2. Предварительная настройка VMware vSphere
Общие требования и рекомендации по использованию vSphere в качестве инфраструктурного провайдера:
- Запустить Tanzu Community Edition можно на vSphere 7, vSphere 6.7u3, VMware Cloud on AWS, либо на Azure VMware Solutions.
- В случае с классической vSphere должен быть доступен хост, либо кластер, в котором будут создаваться виртуальные машины Tanzu. В случае использования кластера, следует включить DRS, а также использовать минимум два хоста.
- Опционально следует создать пул ресурсов под кластер Tanzu;
- Также следует создать каталог, в котором будут размещены виртуальные машины;
- Хранилище в кластере должно обладать достаточным объемом емкости.
Требования к сети:
- Необходима сеть и DHCP сервер, который будет выделять адреса виртуальным машинам Tanzu;
- Необходимо выделить несколько статичных IP адресов из той же сети, что используется для DHCP (эти адреса раздаваться, конечно же не должны и должны быть исключены из пула). Адреса используются для Kubernetes Control Plane;
- С машины, на которой мы инсталлировали TCE, должен быть доступ по порту 6443 в сеть с кластерами Kubernetes;
- На всех хостах ESXi должна работать служба NTP.
В свою очередь я создал папку TGK на закладке VMs and Templates:

А также группу портов в Distributed Switch:

В данной портгруппе функционирует DHCP сервер, а также имеется ряд не задействованных IP адресов, не входящих в пул DHCP.
Теперь необходимо подготовить шаблон, из которого Tanzu будет создавать виртуальные машины для своих кластеров Kubernetes.
Хорошая новость: вручную готовить ничего не нужно, у VMware уже есть готовые образы. Для их загрузки необходима учетная запись на VMware Customer Connect.
Переходим на страницу Tanzu Community Edition и загружаем образ. Для vSphere доступны образы на базы Photon OS а так же на базе Ubuntu:

Я загрузил образ Photon OS 3 с пакетами Kubernetes 1.21.2.
Далее переходим в интерфейс vSphere и разворачиваем виртуальную машину из скачанного образа с помощью меню Deploy OVF Template:

Процесс создания VM из образа достаточно простой и не требует описания. Дожидаемся окончания:

И конвертируем виртуальную машину в шаблон:

Как результат, мы будем иметь готовый шаблон для дальнейшего создания виртуальных машин Tanzu на базе Photon OS:

Этап третий – настройка Management кластера Tanzu
Переходим в машину, на которой ранее были установлены пакеты Tanzu Community Edition.
Сперва сгенерируем пару SSH ключей:
Выведем содержимое публичного SSH ключа на экран, он пригодится в дальнейшем:
Запуск процедуры развертывания Management кластера Tanzu происходит в интерактивном режиме с помощью команды tanzu management-cluster create . Tanzu запускает сервер для конфигурации кластера, доступный на локальном адресе 127.0.0.1 по порту 8080. Доступ осуществляется через веб-браузер, установленный на этой же машине.
В моем случае на сервере, где установлены компоненты TCE, графики нет, так же нет возможности запустить браузер. На этот случай у нас имеются ключ –bind , который позволяет указать IP, на котором будет доступен веб-сервер с настройками TCE.
Откроем порт 8080 для внешних подключений:
И запустим процедуру создания Management кластера:
Если все настройки были выполнены верно, сервер будет запущен:
Теперь открываем веб-браузер и переходим по адресу, заданному выше:

Здесь мы видим всех инфраструктурных провайдеров, которых можно использовать для запуска кластеров Tanzu. Выбираем VMware vSphere и клик по Deploy:

В первую очередь указываем адрес vCenter Server, логин и пароль для доступа, затем нажимаем Connect.
После успешного подключения, появляется возможность выбрать нужный Datacenter, а также указать публичный ключ SSH, сгенерированный нами ранее. Указываем данные и продолжаем нажатием Next.
Следующим шагом выбираем тип инсталляции. Development, или Production. Разница в количестве виртуальных машин, которые будут задействованы под Control Plane – одна или три:

И указываем Instance Type, который зависит от размера инсталляции:

Здесь же ниже указываем параметры Management кластера:
Management Cluster Name – Имя кластера, соответственно;
Control Plane Endpoint Provider – Если имеется NSX, можно использовать его. Иначе используется Kube-vip;
Control Plane Endpoint – Адрес, по которому должен быть доступен Control Plane, т.е. Kubernetes API Server. Данный адрес должен быть исключен из DHCP пула, как говорилось ранее;
Worker Node Instance Type – Параметры Worker нод в будущем кластере.
Нажимаем Next и переходим к следующему шагу настройки – NSX Advanced Load Balancer Settings:
В моей инсталляции отсутствует NSX, данный шаг я пропускаю.
Следующим шагом мы можем указать какие-либо метаданные для будущего кластера. Данный шаг я тоже пропускаю:

Пятым шагом указываем каталог, в котором будут размещаться виртуальные машины, также указываем кластер и хранилище, где они будут размещены:

Далее мы выбираем сеть, к которой будут подключены виртуальные машины. Я указываю ранее созданную портгруппу:

Также мы можем задать сети для Cluster Services и Cluster POD. Я оставляю значения по умолчанию.
При необходимости имеется возможность указать прокси сервер для доступа в интернет. Следует корректно указать исключения для прокси, обязательно добавив адреса vSphere, а также сети, задействованные под Tanzu.
В следующем шаге отключаю необходимость в использовании Identity Manager:

Шаг 8 – OS Image. Здесь выбираем шаблон, который был загружен ранее:

Шаг с настройкой Tanzu Mission Control я пропускаю:

После нажатия Next, система предложит сверить настройки и применить их. Интересный момент: Настройки сохраняются в файле и применить их можно командой cli:
В указанной директории лежит yaml файл, который содержит все заданные ранее настройки. В случае чего, файл можно отредактировать и создать кластер с другими настройками.
Клик по Deploy Management Cluster запустит процедуру создания:

В это время на машине с TCE появится «временный кластер». В дальнейшем он будет удален, после того, как будет развернут Management:
Далее начинается создание Management кластера. В инфраструктуре появится ряд VM:

Через некоторое время настройка Management кластера заканчивается:

Проверить состояние кластера можно с помощью команды tanzu management-cluster get :
Этап четвертый. Создание Workload кластера
Создание кластера для рабочих нагрузок производится на базе уже имеющегося конфигурационного файла для Mgmt кластера, который был сгенерирован ранее.
Скопируем существующий файл конфигурации под новым именем:
В данном файле важно отредактировать следующие параметры – название кластера, а также адрес Control Plane:
Опционально можно указать параметры Worker ноды, а также их количество:
Запускаем создание кластера
Если посмотреть на состояние кластера в этот момент, можно увидеть текущие операции:
А вот и виртуальные машины нового кластера:

Через некоторое время мы получаем запущенный Workload кластер:

Теперь получим доступ к управлению данным кластером привычной утилитой kubectl
Запросим конфигурационный файл для подключения к кластеру через tanzu:
И сообщим kubectl какой конфигурационный файл использовать:
Проверим, как выглядит наш кластер:
Как и ожидалось, мы имеет 3 ноды под Control Plane и 3 Worker ноды.
Запустим какой-нибудь контейнер:
Контейнер работает:
Включаем перенаправление портов в контейнер:
Теперь заходим браузером на порт 8080 машины с TCE, где мы запустили kubectl, и смотрим на результат:

Установка Tanzu Community Edition полностью завершена.
Важные моменты в процессе инсталляции
Пользователь, от имени которого запускается утилита tanzu должен быть включен в группу docker, иначе могут возникнуть проблемы с развертыванием кластеров Kubernetes на самом начальном этапе.
На всех машинах должен быть доступ в интернет, либо необходимо использовать прокси.
При использовании прокси, следует корректно указывать исключения для адресов, где прокси не должен применяться.
В DHCP пуле должно быть достаточное количество свободных адресов. Отсутствие свободных адресов может сказаться на развертывании кластеров Tanzu.
Если на хостах не хватает ресурсов для запуска новых виртуальных машин, процедура создания кластера может быть прервана.
Публичный SSH ключ следует копировать внимательно, иначе на этапе развертывания кластеров могут возникнуть проблемы.

Мы установили новый vCenter 6.7. Создали на нём Datacenter. Что дальше? Создаём Cluster для группы хостов.
Ссылки
New Cluster
Заходим в vCenter через UI. Нажимаем правой кнопкой на Datacenter.

Выбираем в меню New Cluster. Открывается мастер.

Указываем название кластера, при необходимости устанавливаем дополнительные опции, мне они не потребуются. OK.

Кластер создан. На этом можно остановиться, но я хочу ещё заранее настроить VMware EVC Mode.
У меня все хосты одинаковые, смотрю название процессора. Это Intel Xeon Gold 6132.

Гуглю название поколения. Это Skylake.


Configure > Configuration > VMware EVC. Нажимаю Edit.

Включаю EVC — Enable EVC for Intel Hosts. Выбираю VMware EVC Mode — Intel "Skylake" Generation. OK.
Что такое общий диск Multi-writer в VMware ESXI
Сейчас уже очень сложно себе представить серьезный сервис без отказоустойчивости, которая может быть реализована на разных уровнях работы инфраструктуры. Очень частым решением выступает отказоустойчивый кластер, который подразумевает использование разных серверов для одного сервиса. Выход из строя одного из серверов не влияет на работоспособность предоставляемых услуг клиентам. Очень часто в кластерах используются общие диски, для хранения баз данных (Microsoft SQL или Oracle), файловые ресурсов. Общие диски могут презентованы, как отдельные LUN с СХД, через ISCSI протокол, через общий диск или RDM в случае с виртуальными машинами.
В данной заметке я опишу реализацию с помощью общего диска для виртуальных машин VMware ESXI 6.5. В некоторых случаях (как правило, в сценариях кластеризации) может потребоваться совместное использование одного и того же диска между двумя (или более) виртуальными машинами. Наиболее оптимальным способом является использование диска vmdk, физически расположенного на общем хранилище или локально на хосте ESXi. Если вы хотите использовать общие диски на разных хостах ESXi, то вы можете использовать только разделяемое хранилище
.На представленной ниже схеме вы видите:
- Storage Array, по сути это ваша система хранения данных, на которой реализован RAID массив, по рекомендации производителя.
- RAID массив порезан на LUN, это логически порезанное место на вашей системе хранения данных
- Далее LUN презентуется хостам VMware ESXI 6.5 и размечается файловой системой VMFS 6. Где из LUN получаются разделы (Datastore-Volume) для гипервизора.
- Далее на на Datastore уже разворачиваются виртуальные машины
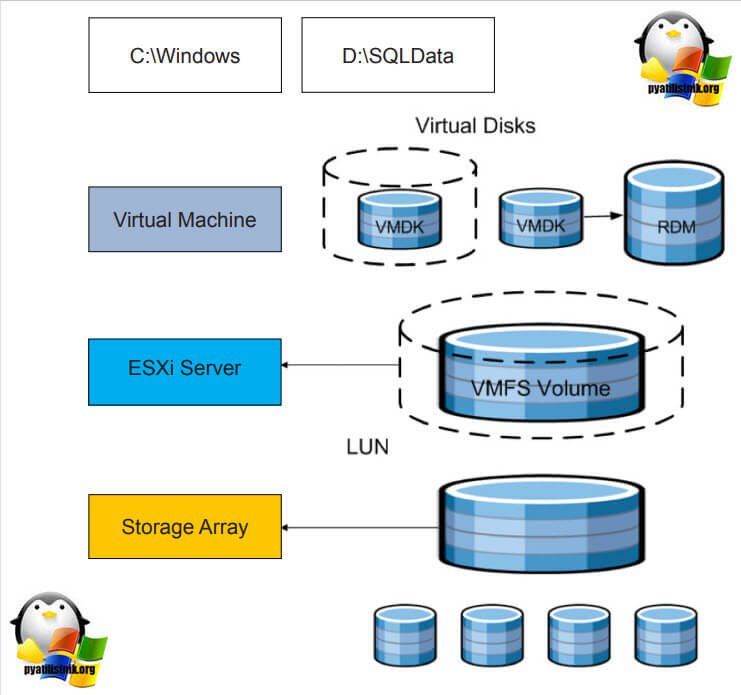
Вот на таком общем VMFS Volume диске вы создаете общий VMDK диск, который будет доступен двум и более виртуальным машинам под чтение и запись. Сами виртуальные машины могут находится на разных физических хостах и разных географических локациях.Такой режим называется Multi-Writer VMDK, его часто применяют в построении кластеров MS SQL, Oracle RAC, такой режим работы диска применяется в технологии VMware Fault Tolerance.
Для чего применяют Multi-Writer диск
- Во первых, как я и писал выше для отказоустойчивости различных сервисов, сервера которых могут быть в разных ЦОДах.
- Во вторых для возможности обслуживания важных серверов, без их простаивания. Например, чтобы была возможность своевременно производить обновление Windows пакетов, другого программного обеспечения, иметь возможность перезагружать сервер
- В целях тестирования кластерных технологий, когда у вас нет СХД и нет возможности реализовать общий диск, по FC или ISCSI протоколу
Ограничения общих дисков VMware ESXI
Без некоторых нюансов все же не обошлось, хочу выделить некоторые ограничения при использовании общих дисков:
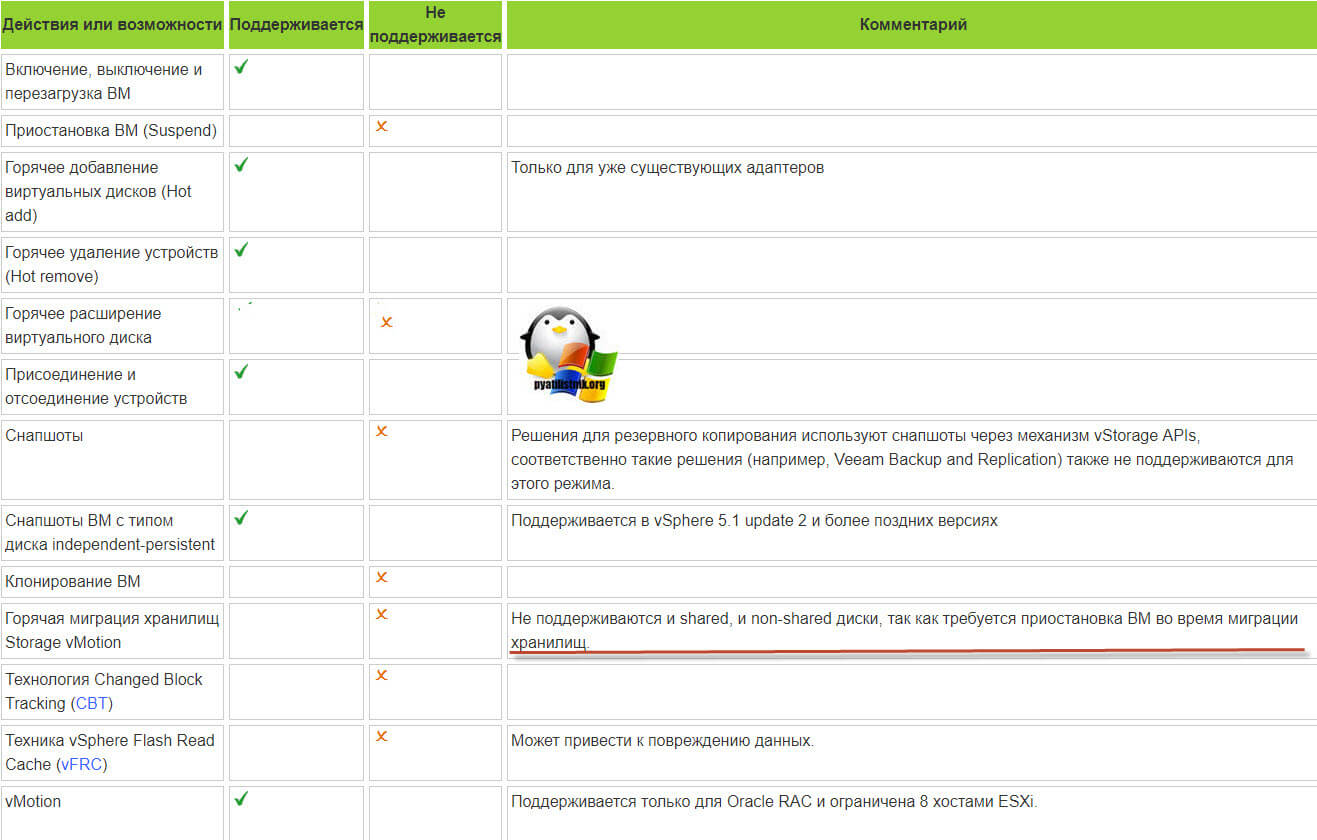
Например, при попытке сделать Storage vMotion вы получите ошибку:
Virtual machine is configured to use a device that prevents the operation: Device 'SCSI controller 1' is a SCSI controller engaged in bus-sharingЕсли нужно будет мигрировать, то придется выключать виртуалку.
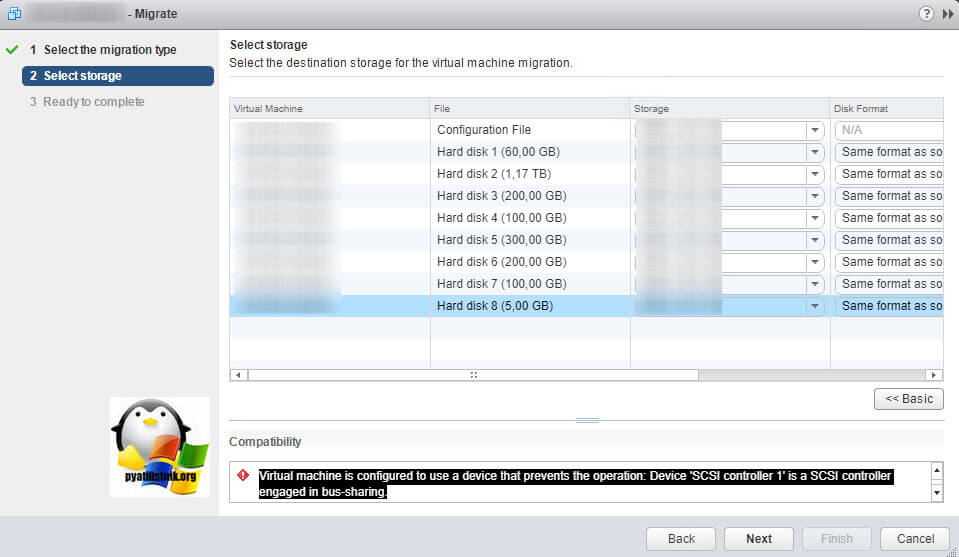
- Вы не сможете на живую произвести расширение дисков, при попытке вы получите вот такую ошибку:
- Если вы вдруг разметите оба диска в NTFS на двух хостах и попытаетесь на них писать, создав на одном одну папку, а на втором вторую, то хосты эти папки не увидят, каждый свою, учтите, это вам не общий диск с синхронизацией файлов, Multi-Writer VMDK именно нужен для кластеризации.
Как подключить общий диск в VMware ESXI 6.5 и выше
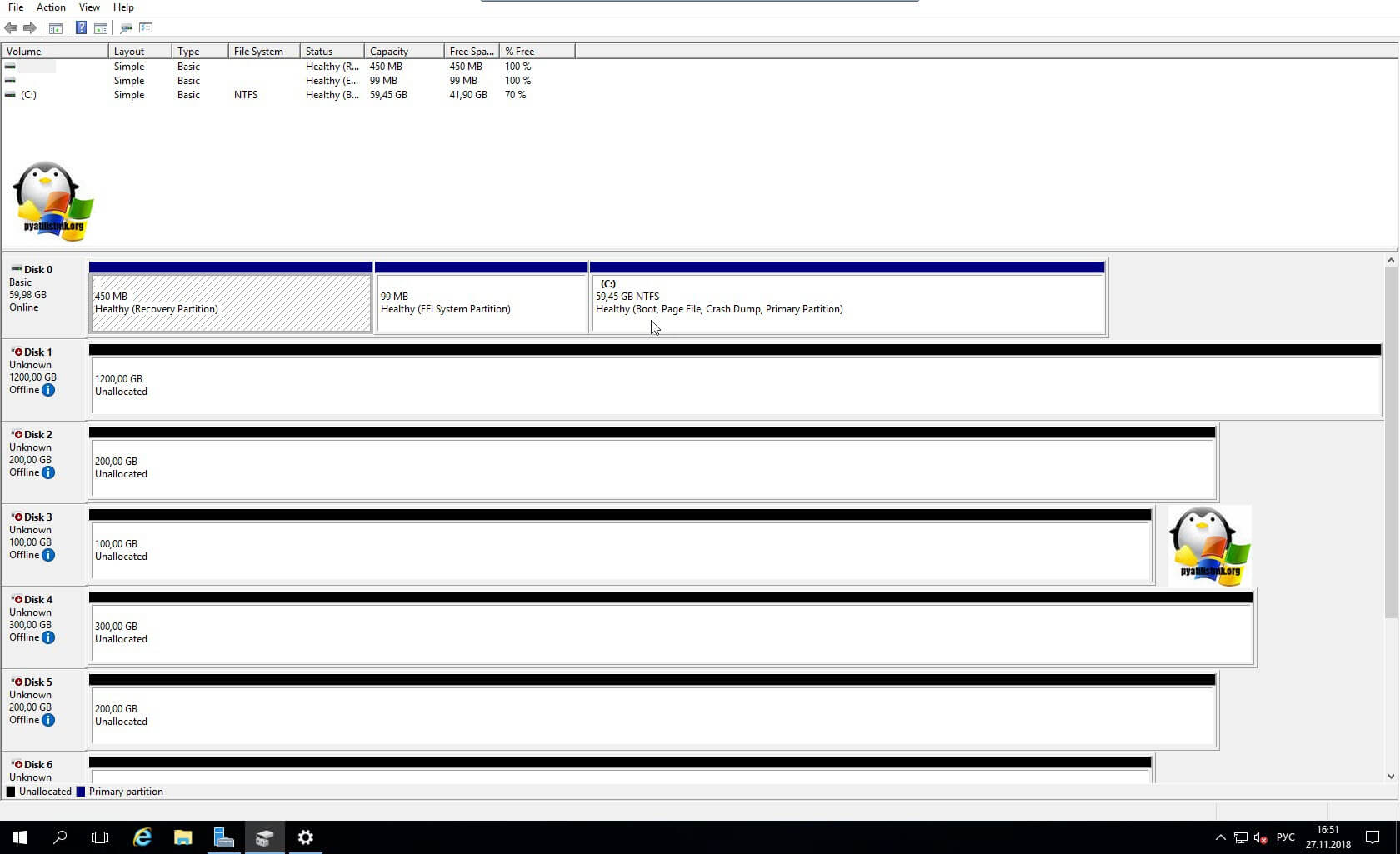
Поэтому нам первым делом необходимо в свойствах виртуальной машины добавить новый SCSI Controller.
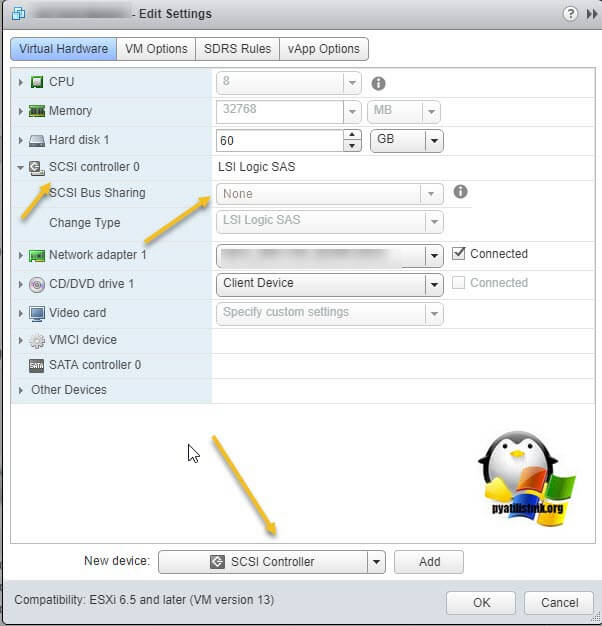
Если посмотреть подсказку у LSI Logic SAS контроллера, то вы увидите три его режима:
- None - для работы с не кластерными Multi-Writer дисками
- Physical - виртуальные диски могут быть общими для виртуальной машины и физическим сервером
- Virtual - для работы с общим диском для нескольких виртуальных машин
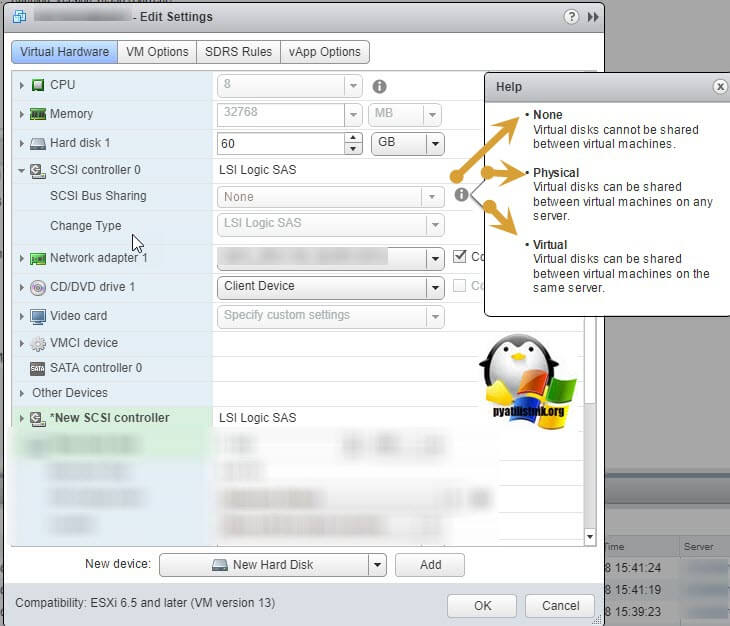
Делается это через пункт "New Device" и нажатии кнопки Add, для SCSI Controller.
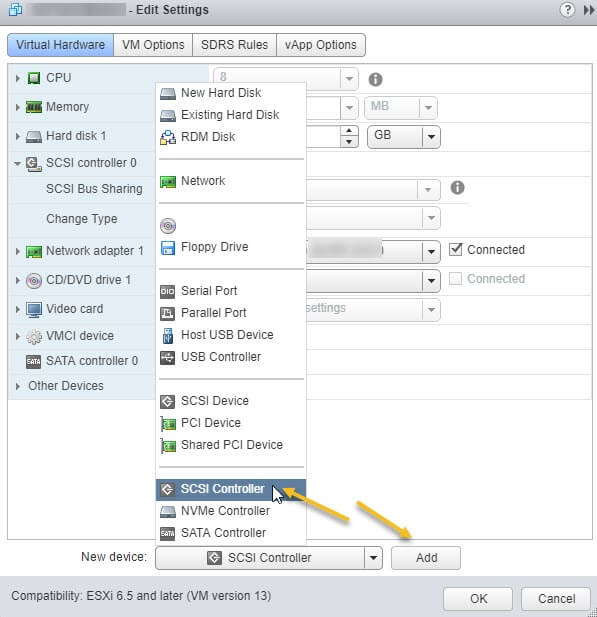
Далее у нового, добавленного контроллера вы в пункте "SCSI Bus Sharing" выберите тип "Virtual". Можете сохранить конфигурацию виртуальной машины, через нажатие кнопки "Ок"
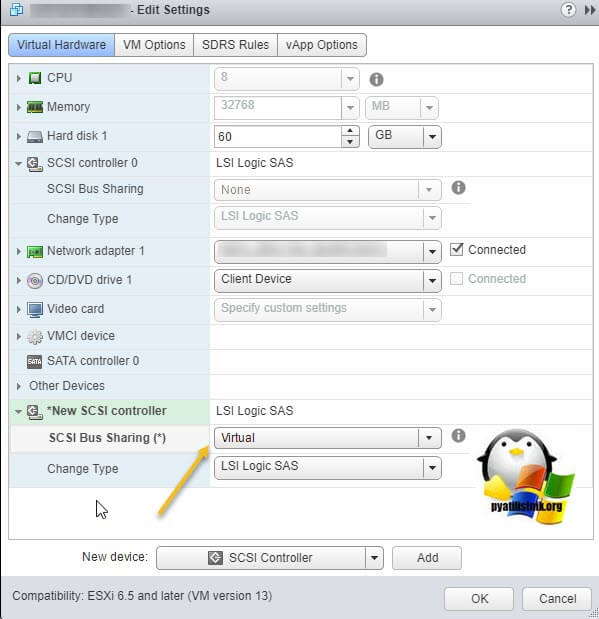
Далее на первой машине, где мы только что добавили новый контроллер, вам нужно создать новый виртуальный диск, делается это так же, через пункт "New Device"
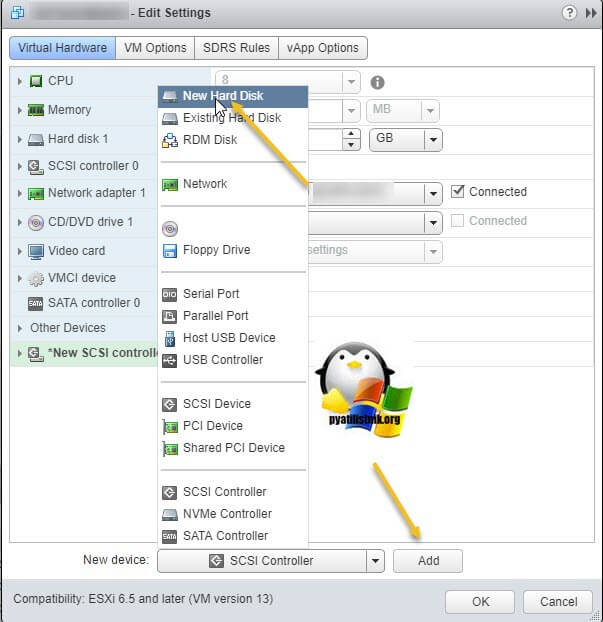
Откройте параметры нового виртуального диска. Для того, чтобы сделать его общим между виртуальными машинами VMware ESXI, вам необходимо выставить соответствующие настройки:
- Disk Provisioning - Делает толстый диск с занулением "Thick provision Eager zeroed thick disks", нужен для кластеризации, о типах дисков ESXI, читайте по ссылке.
- Sharing - тут вы как раз выбираете режим общего диска "Multi-Writer"
- Disk Mode - режим работы диска выставите "Independent Persistent" (Подробнее про режимы работы ESXI дисков), данный режим работы не позволит использовать vStorage APIs, что не даст создавать на таком диске снапшоты. Данный режим рекомендуется самим вендором VMware и его партнерами, такими как Oracle. Если бы мы разрешили создание снимков на этом диске, то это могло бы привести к потере данных. Так если у вас на этом диске быдет база SQL и вы будите использовать Veeam Backup, то у ваших резервных копий на уровне самого SQL могут быть проблемы при восстановлении из них, так как точка отсчета с которой нужно будет выстраивать цепочку бэкпов будет нарушена Veeam, который сдвинет точку бэкапа на себя. Если выставлен Independent Persistent, то в Veeam при создании бэкапа этой виртуальной машин можно исключить нужные диске, где стоят SQL или Oracle.
- Virtual Device Node - выберите наш новый LSI Logic SAS контроллер, работающий в режиме "SCSI Bus Sharing Virtual"
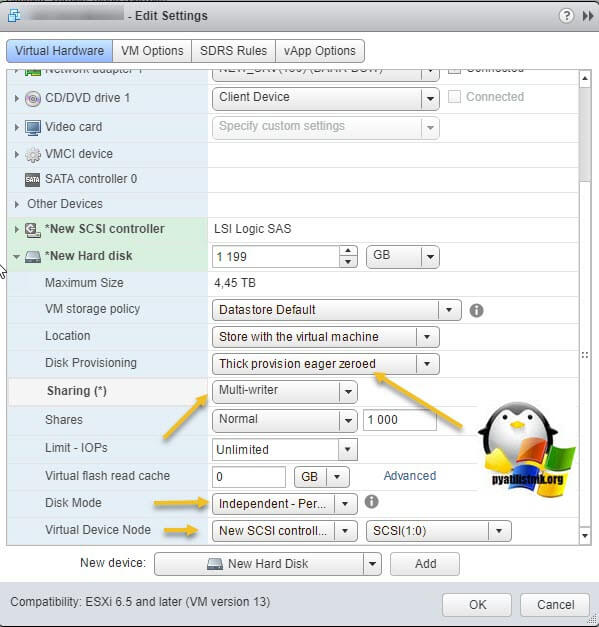

Далее я иду на датастор на котором находится виртуальная машина с общими дисками (Datastore - Browse Files).
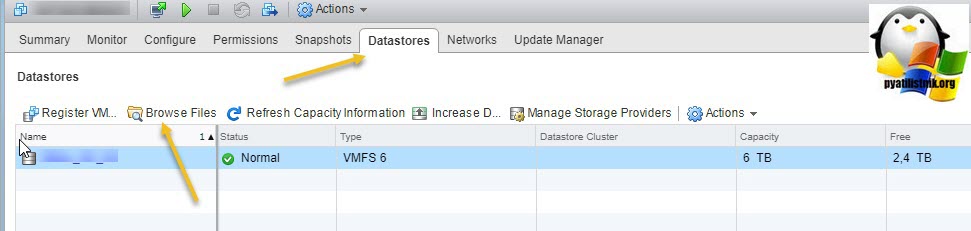
Нахожу нужные мне Multi-Writer диски. Создаю новую папку
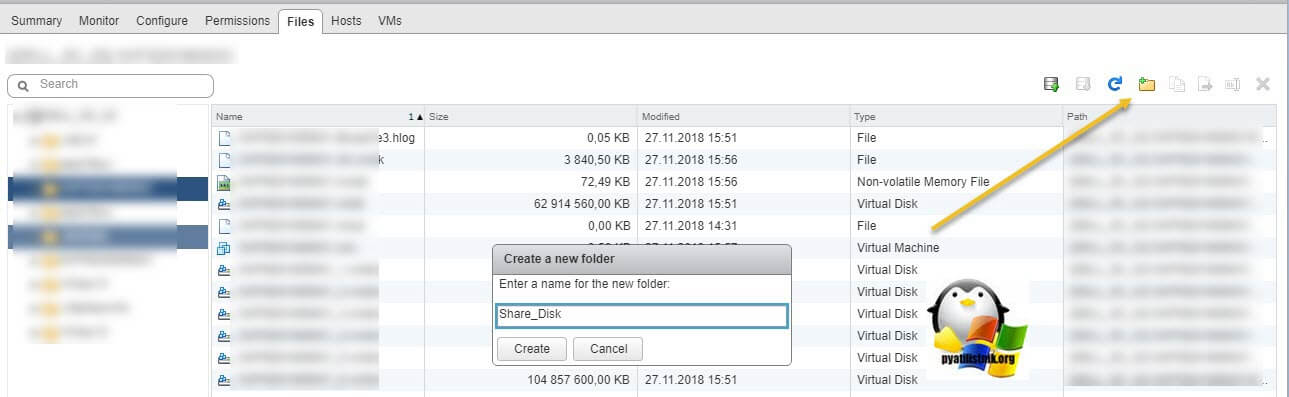
И перемещаю в новую папку общие диски, хочу отметить, что вы их можете переместить на любой общий между хостами ESXI датастор.
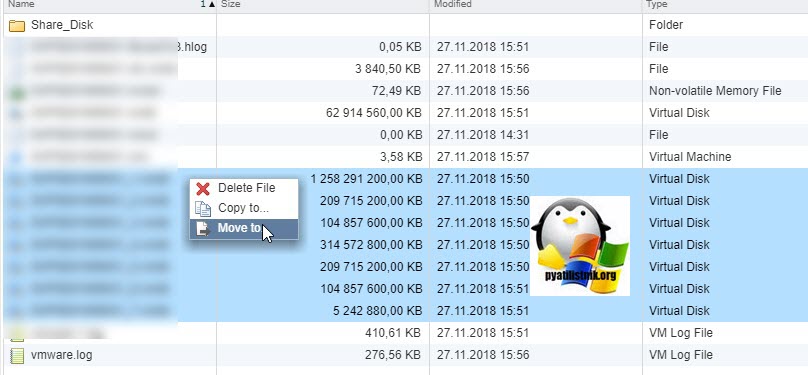
Я делаю "Move to" на тот же латасторе, но в новую папку. Этим я добьюсь, что буду видеть явным образом общие кластерные диски.
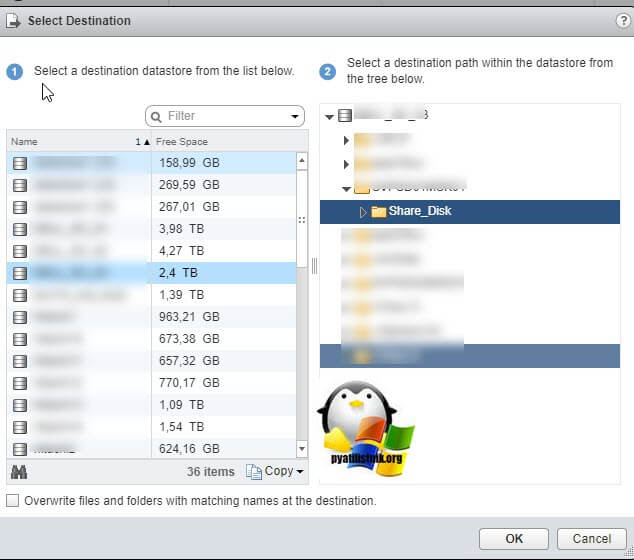
Так как я диски до этого удалил, для удобства, то мне их нужно заново добавить. Если вы до этого не удаляли, то сделайте эти действия только для второй виртуальной машины. Открываем настройки виртуальной машины и нажимаем добавить новое устройство, выбираем пункт "Existing Hard Disk", это у нас выбор существующего общего кластерного диска.
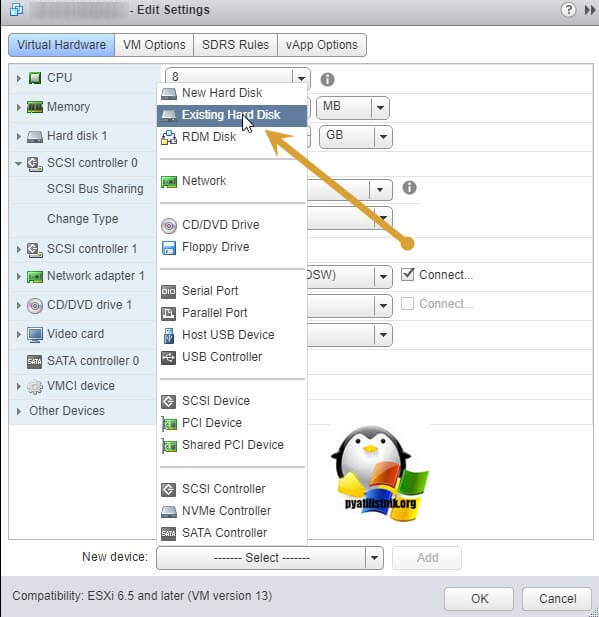
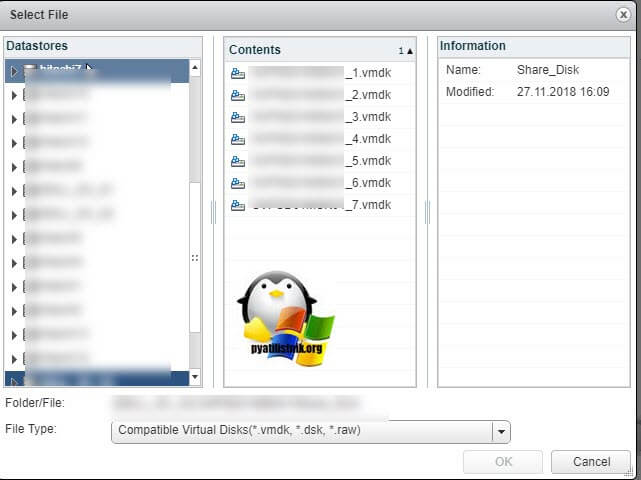
Указываем на каком датасторе у нас лежит Multi-Writer диск и выбираем нужный VMDK, в моем случае их семь.
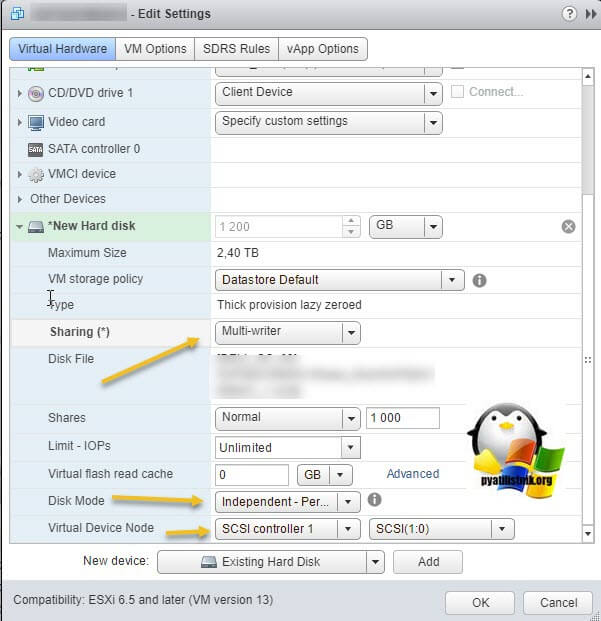
Выставляем нужные параметры:
- Disk Provisioning - "Thick provision Eager zeroed thick disks"
- Sharing - "Multi-Writer"
- Disk Mode - "Independent Persistent"
- Virtual Device Node - выберите наш новый LSI Logic SAS контроллер, работающий в режиме "SCSI Bus Sharing Virtual"
Если такой диск не один, то добавляем все за один раз для экономии времени. Проделываем такое добавление общих дисков на всех виртуальных машинах, где планируется использовать Multi-Writer.
Далее уже в операционной системе Windows Server, зайдя в оснастку "Управление дисками" вы обнаружите ваши диски. Остается их только разметить в GPT формат и отдать под кластер.
Включение общего диска для ESXI 5.5 и ниже
В более ранних версиях гипервизора Vmware ESXI 5.5 и ниже, общий кластерный диск выключается таким образом. Вы заходите так же в свойства виртуальной машины и добавляете там новый SCSI Controller с типом работы "Virtual".
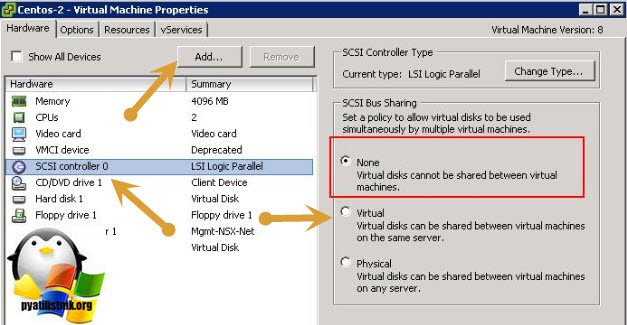
Затем вы создаете новый диск, указываете его размер и тип Thick Provision Eager Zeroed.
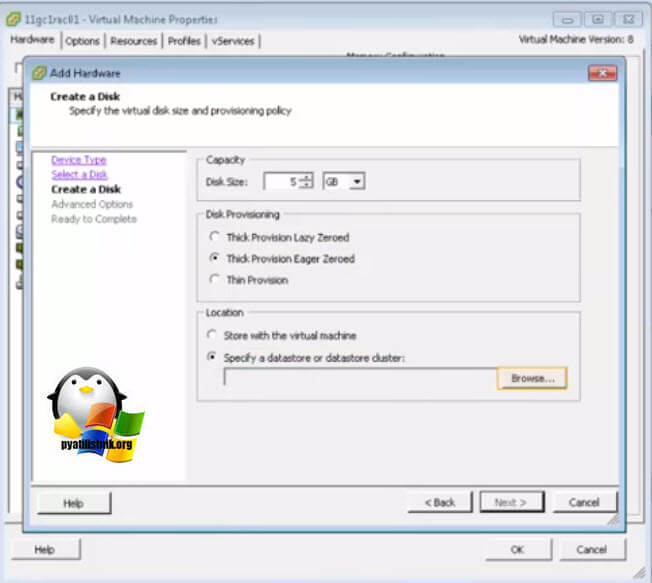
Далее Vmware ESXI 5.5 попросит вас выбрать Выбор LSI Logic SAS контроллер, обязательно укажите тот, что мы создали заранее и запомните порт SCSI к которому вы его подключаете в моем примере, это SCSI (1:0).
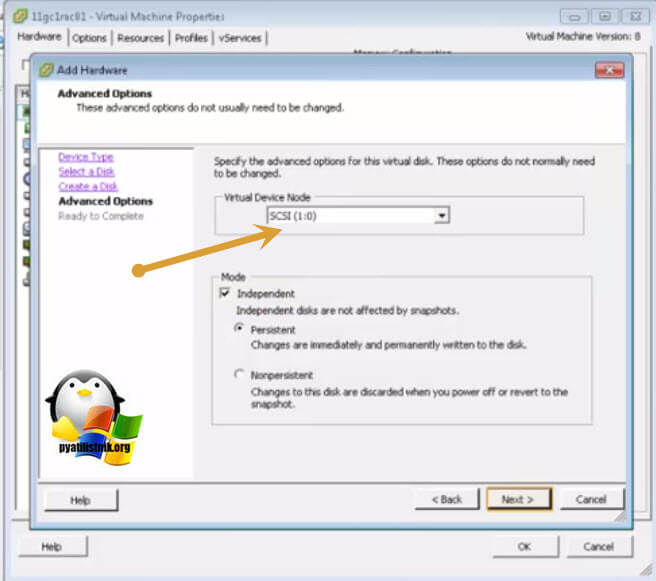
Далее в настройках виртуальной машины вам необходимо перейти на вкладку "Option - General" и нажать кнопку "Configuration Parameters".
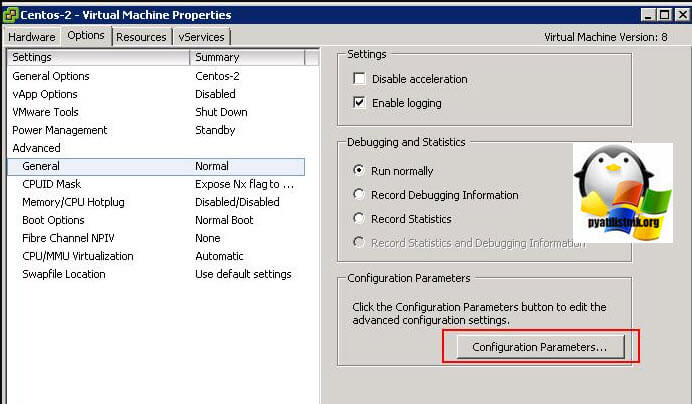
В самом конце для каждого общего диска пишем в имени номер SCSI порта SCSI1: 0.sharing в поле "Value" пишем multi-writer.
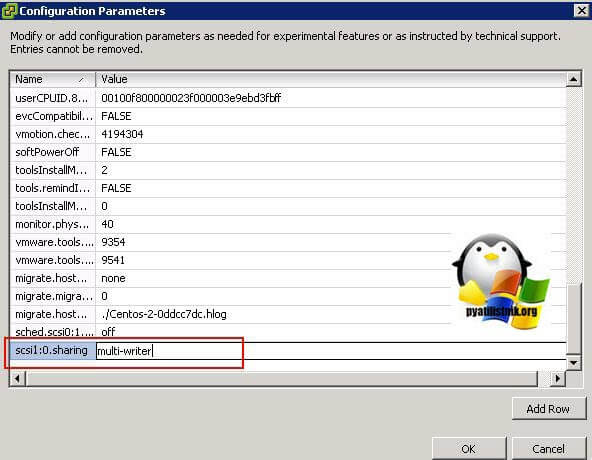
Для второй виртуальной машины делаем те же действия, единственное на этапе создания диска, выбираем пункт существующего "Use an existing virtual disk"
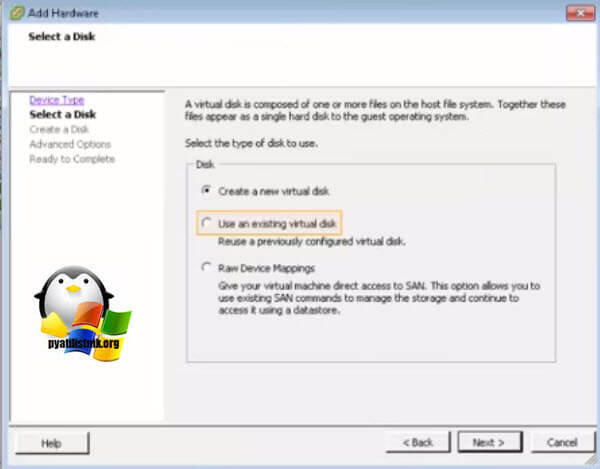
Через кнопку "Browse" указываем путь до него.

Выбираем сам VMDK диск. После чего не забываем так же прописать на вкладке "Option - General" и нажать кнопку "Configuration Parameters", для каждого общего диска пишем в имени номер SCSI порта SCSI1: 0.sharing в поле "Value" пишем multi-writer.
High Availability – технология кластеризации, созданная для повышения доступности системы, и позволяющая, в случае выхода из строя одного из узлов ESXi, перезапустить его виртуальные машины на других узлах ESXi автоматически, без участия администратора.
Общие сведения High Availability
В прошлый раз шла речь о технологиях, используемых в VMware для обеспечения отказоустойчивой системы, в этой же статье подробнее остановимся на VMware HA – VMware High Availability (механизме высокой доступности).
Для того чтобы создать HA кластер, нам необходимо, чтобы все виртуальные машины этого кластера хранились на общем хранилище данных*. При этом если у нас выходит из строя один из узлов ESXi, все виртуальные машины с этого узла будут запущены на свободных слотах (мощностях) других ESXi узлов кластера.
*Общее хранилище данных может представлять собой не только «железную» СХД, но и быть программным. У VMware для этой цели есть продукт vSAN (virtual storage area network). У RedHat есть GlusterFS и т.д.
Список терминов
Isolation response (IR) – параметр, определяющий действие ESXi-хоста при прекращении им получения сигналов доступности кластера. При создании кластера на каждый ESXi-хост устанавливается HA Agent, который будет обмениваться сигналами доступности (Heartbeat);
Reservation – параметр, рассчитывающийся на основе максимальных отдельных характеристик всех ВМ в кластере и в дальнейшем использующийся для расчета Failover Capacity;
Failover Capacity (FCap) – параметр, определяющий реальную отказоустойчивость. Измеряется в целых числах и обозначает, какое максимальное количество серверов в кластере может выйти из строя, после чего сам кластер всё еще будет продолжать функционировать;
Number of host failures allowed (NHF) – параметр задается администратором. Определяет целевой уровень отказоустойчивости. Такое количество узлов ESXi может одновременно выйти из строя;
Состояние Admission Control (состояние ADC) – автоматически рассчитывается как отношение Failover Capacity к Number of host failures allowed;
Параметр Admission Control (параметр ADC) – назначается администратором. Определяет поведение виртуальных машин при недостаточности слотов для их запуска;
Restart Priority (RP) – приоритет запуска машин после падения одного из узлов ESXi, входящих в кластер.
Последовательность создания VMware HA кластера
Определяем количество и размер слотов на узлах ESXi (Reservation); Устанавливаем значение Number of host failures allowed (NHF); Сравниваем NHF и FCap. Если NHF больше FCap, нам необходимо: Либо установить параметр ADC в Allow virtual machine to be started even if they violate availability constraints; Устанавливаем параметр Admission Control в одно из состояний; Определяем поведение хоста при прекращении получения сигналов доступности от остальных узлов (Isolation Response);Isolation Response
Действия при прекращении получения сигналов доступности в кластере HA определяются значением Isolation Response, определяющим действие узла ESXi при прекращении им получения сигналов доступности кластера (Heartbeat). Прекращение получения сигналов доступности происходит из-за «изоляции» ESXi, например, в случае отказа сетевой карты.
Существует несколько предполагаемых сценариев развития событий:
Сбой отправки/получения сигналов доступности, но сама сеть продолжает функционировать; Перестала работать сеть между узлом ESXi и остальными узлами кластера, но ESXi продолжает функционировать;В первом случае, стоит выбрать значение параметра Isolation Response - Leave powered on, тогда все машины, продолжат свою работу, невзирая на то, что прекратят получать сигналы доступности.
Во втором случае следует выбрать Isolation Response – Power off либо Shutdown (установлен по умолчанию), если ESXi-хост перестал получать сигналы доступности, HA перенесет с общего хранилища ВМ, хранившиеся на этом хосте ESXi, на свободные ESXi-хосты. ESXi-хост должен автоматически выключаться, чтобы не возникало конфликтов двух одинаковых хостов.
По умолчанию Isolation Response установлен в режиме Power off. Мы не знаем как будут развиваться события в момент гипотетического отказа, поэтому мы рекомендуем оставлять значение IR в состоянии Power off, чтобы избежать риска появления в сети конфликтующих машин с одинаковыми сетевыми настройками.
Резервация ресурсов (Reservation)
При расчете параметра Failover Capacity кластер HA сначала создает слоты, определяемые параметром Reservation. Этот параметр рассчитывается по размеру максимальной из виртуальных машин, работающих на узлах кластера.
Параметр Failover Capacity
После расчета слотов определяется сам параметр Failover Capacity. Он измеряется в целых числах и обозначает, какое максимальное количество узлов в кластере одновременно может выйти из строя. При этом все машины должны продолжать функционировать.
Иллюстрируем параметр Failover Capacity. Возьмем два случая (по вертикали: 1-й случай - отказ одного узла ESXi, 2-й случай - отказ 2-х узлов ESXi).
Первый случай: 3 узла ESXi, по 4 слота на каждом, 6 виртуальных машин.
В этом случае при выходе из строя одного узла (например, №3), ВМ 4,5,6 будут запущены на других узлах (в нашем случае №2, показаны стрелками), однако, при выходе из строя еще одного узла, свободных слотов под запуск ВМ не останется.
Второй случай: 3 узла ESXi, по 4 слота на каждом, 4 виртуальные машины.
В этом случае, свободных слотов хватит, даже если упадет сразу 2 узла ESXi(в нашем случае, ВМ перенесутся на хост №1).
Технически параметр Failover Capacity рассчитывается следующим образом: из количества всех узлов в кластере мы вычитаем отношение количества виртуальных машин в кластере к количеству слотов на одном узле ESXi. Если получается не целое число, округляем вниз.
Для первого случая: 3-6/4=1.5 Округляем до 1;
Для второго случая: 3-4/4=2 Так и остается 2;
Admission Control
Admission Control мы условно разделили на состояние Admission Control (состояние ADC) и параметр Admission Control (параметр ADC).
Состояние ADC определяется соотношением реального уровня отказоустойчивости (FCap) и установленного администратором (NHF). Если FCap больше NHF, то кластер настроен корректно и проблем ожидать не следует. Если наоборот, то мы должны устанавливать параметр ADC.
Параметр ADC определяется администратором и может иметь два состояния:
Do not power on virtual machines if they violate availability constraints – не включать виртуальные машины, если не достаточно слотов для обеспечения целевого уровня отказоустойчивости; Allow virtual machine to be started even if they violate availability constraints – разрешить запуск виртуальных машин, несмотря на возможную нехватку ресурсов для их запуска;При выборе параметра ADC следует заранее понять, как будет устроен кластер и для каких целей он необходим:
Если наша основная задача – это надежность самого кластера, несмотря на то, какие ВМ будут включены, нам следует установить Admission Control в состояние Do not power on….; Если же нам важно работа всех ВМ в кластере, нам придется установить Admission Control в состояние Allow VM to be started….;Во втором случае, поведение кластера может стать непредсказуемым (в худшем случае может дойти до такого, что ВМ опустят значение ADC до нулевого значения, тем самым сделав бесполезным технологию HA)
Рекомендации по созданию кластера vSphere HA
Мы представим общие рекомендации по созданию кластера HA:
Для кластера с включенной службой HA необходимо, чтобы все виртуальные машины и их данные находились на общем хранилище данных (Fibre Channel SAN, iSCSI SAN, or SAN iSCI NAS). Это необходимо, чтобы включать ВМ на любом из хостов кластера. Это также означает, что узлы должны быть настроены для доступа к тем же самым сетям виртуальной машины, совместно используемой памяти и другим ресурсам; Каждый сервер ESXi в кластере HA производит мониторинг узлов сети для обнаружения сбоев серверов. Чтобы сигналы доступности не прерывались, рекомендуется устанавливать резервные сетевые пути. Если первое сетевое соединение узла перестало функционировать, сигналы доступности (heartbeats) начнут передаваться по второму соединению. Для повышения отказоустойчивости, рекомендуется использовать два и более физических сетевых адаптерах на каждом узле; Если нужно использовать службу DRS совместно с HA для распределения нагрузок по узлам, узлы кластера должны быть частью сети vMotion. Если узлы не включены в vMotion, то DRS может неверно распределять нагрузку на узлы;esxi cluster
| Backup для виртуальных машин | Arcserve для VMware |

Работая с нами Вы, получите:
Наши цены ниже по целому ряду причин:
V-GRADE - является Официальным Партнером VMware уровня Advanced;
Работаем без посредников , напрямую с VMware, Veeam, Arcserve для VMware.
Наши эксперты:
У нас есть конфигуратор VMware, лучшие цены, актуальные статьи. лучшие эксперты.
Читайте также: