Как создать файл c
Обновлено: 04.07.2024
Хедер fstream предоставляет функционал для считывания данных из файла и для записи в файл. В целом он очень похож на хедер iostream , который работает с консолью, поскольку консоль это тоже файл. Поэтому все основные операции такие же, за мелкими отличиями, как в предыдущей теме по iostream.
Наиболее частые операции следующее:
- Методы проверки открыт ли файл is_open() и достигнут ли конец файла eof()
- Настройка форматированного вывода для >> с помощью width() и precision()
- Операции позиционирования tellg(), tellp() и seekg(), seekp()
Это не все возможности, которые предоставляет библиотека fstream. Рассматривать все сейчас мы не будем, поскольку их круг применения достаточно узок. Познакомимся с вышеперечисленными. Начнем с класса чтения.
Класс ifstream
Открытие файла в конструкторе выглядит так:
ifstream file ( "d:\\1\\файл.txt" ) ; // открываем файл в конструктореТак мы просим открыть файл txt с именем файл.txt, который лежит в папке с названием 1, а папка находится на диске d.
Использование метода open() удобно, если программист не хочет сразу привязываться к файлу. Вдруг нужно свойство класса или глобальную переменную, ну а открывать файл уже потом. Если же нужно открыть файл внутри некой функции, поработать с ним и закрыть, то можно прописать путь к файлу прямо в конструкторе. В общем зависит от ситуации.
Так все отработает нормально и файл откроется:
![библиотека fstream, работа с файлами в с++, программирование для начинающих]()
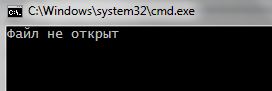
Второй вариант проверки с использованием метода is_open() :
Метод is_open() вернет 1, если файл найден и успешно открыт. Иначе вернет 0 и сработает код прописанный в блоке else .
Если файл успешно открыт, из него можно производить чтение.
Оператор считывания >>
Так же как и в iostream считывание можно организовать оператором >> , который указывает в какую переменную будет произведено считывание:
Считает вещественное, целое и строку. Считывание строки закончится, если появится пробел или конец строки. Стоит отметить, что оператор >> применяется к текстовым файлам. Считывание из бинарного файла производить лучше всего с помощью метода read().
Кстати этот оператор достаточно удобен, если стоит задача разделить файл на слова:
Методы getline() и get()
Считывание целой строки до перевода каретки производится так же как и в iostream методом getline(). Причем рекомендуется использовать его переопределеную версию в виде функции, если считывается строка типа string:
Если же читать нужно в массив символов char[], то либо get() либо getline() именно как методы:
Принцип в общем тот же, что и в аналогах из iostream: Указывается в параметрах буфер (переменная, куда будет производиться чтение), или точнее указатель на блок памяти (если переменная объявлена статически: char buffer[255] к примеру, то пишется в параметры &buffer), указывается максимальное количество считываемого (в примере это n), дабы не произошло переполнение и выход за пределы буфера и по необходимости символ-разделитель, до которого будет считка (в примере это пробел). Надеюсь я не больно наступлю на хобот фанатикам Си, если сажу что эти две функции на 99% взаимозаменяемы, и на 95% могут быть заменены методом read() .
Метод read()
Похож на предыдущий пример?
Метод close()
Метод eof()
Проверяет не достигнут ли конец файла. Т.е. можно ли из него продолжать чтение. Выше пример с считкой слов оператором >> как раз использует такую проверку.
Метод seekg()
Производит установку текущей позиции в нужную, указываемую числом. В этот метод так же передается способ позиционирования:
Некоторые сведения относятся к предварительной версии продукта, в которую до выпуска могут быть внесены существенные изменения. Майкрософт не предоставляет никаких гарантий, явных или подразумеваемых, относительно приведенных здесь сведений.
Создает или перезаписывает файл в указанном пути.
Перегрузки
Создает или перезаписывает файл в указанном пути.
Создает или перезаписывает файл по заданному пути с указанием размер буфера.
Создает или перезаписывает файл по заданному пути с указанием размера буфера и параметров, которые описывают, как создавать или перезаписывать файл.
Создает или перезаписывает файл по заданному пути с указанием размера буфера и параметров, которые описывают, как создавать или перезаписывать файл. Также указывается значение, определяющее контроль доступа и безопасность аудита для файла.
Create(String)
Создает или перезаписывает файл в указанном пути.
Параметры
Путь и имя создаваемого файла.
Возвращаемое значение
FileStream, обеспечивающий доступ для чтения и записи к файлу, указанному в path .
Исключения
У вызывающего объекта отсутствует необходимое разрешение.
-или- Параметр path указывает файл, доступный только для чтения.
-или- path указывает файл, который скрыт.
path имеет значение null .
Указанный путь, имя файла или оба значения превышают максимальную длину, заданную в системе.
Указан недопустимый путь (например, он ведет на несопоставленный диск).
Ошибка ввода-вывода при создании файла.
Параметр path задан в недопустимом формате.
Примеры
В следующем примере создается файл по указанному пути, записываются некоторые сведения в файл и считываются из файла.
Комментарии
FileStreamОбъект, созданный этим методом, имеет значение по умолчанию FileShare None ; никакие другие процессы или код не могут получить доступ к созданному файлу, пока не будет закрыт исходный маркер файла.
Этот метод эквивалентен Create(String, Int32) перегрузке метода, используя размер буфера по умолчанию 4 096 байт.
path Параметр может указывать сведения относительного или абсолютного пути. Сведения об относительном пути интерпретируется как относительно текущего рабочего каталога. Сведения о получении текущего рабочего каталога см. в разделе GetCurrentDirectory .
Если указанный файл не существует, он создается; Если он существует и не доступен только для чтения, содержимое перезаписывается.
По умолчанию всем пользователям предоставляется полный доступ на чтение и запись к новым файлам. Файл открыт с доступом на чтение и запись и должен быть закрыт, прежде чем его можно будет открыть другим приложением.
Для удобства обращения информация в запоминающих устройствах хранится в виде файлов.
Файл – именованная область внешней памяти, выделенная для хранения массива данных. Данные, содержащиеся в файлах, имеют самый разнообразный характер: программы на алгоритмическом или машинном языке; исходные данные для работы программ или результаты выполнения программ; произвольные тексты; графические изображения и т. п.
Каталог ( папка , директория ) – именованная совокупность байтов на носителе информации, содержащая название подкаталогов и файлов, используется в файловой системе для упрощения организации файлов.
Файловой системой называется функциональная часть операционной системы, обеспечивающая выполнение операций над файлами. Примерами файловых систем являются FAT (FAT – File Allocation Table, таблица размещения файлов), NTFS, UDF (используется на компакт-дисках).
Существуют три основные версии FAT: FAT12, FAT16 и FAT32. Они отличаются разрядностью записей в дисковой структуре, т.е. количеством бит, отведённых для хранения номера кластера. FAT12 применяется в основном для дискет (до 4 кбайт), FAT16 – для дисков малого объёма, FAT32 – для FLASH-накопителей большой емкости (до 32 Гбайт).
Рассмотрим структуру файловой системы на примере FAT32.Файловая структура FAT32
Устройства внешней памяти в системе FAT32 имеют не байтовую, а блочную адресацию. Запись информации в устройство внешней памяти осуществляется блоками или секторами.
Сектор – минимальная адресуемая единица хранения информации на внешних запоминающих устройствах. Как правило, размер сектора фиксирован и составляет 512 байт. Для увеличения адресного пространства устройств внешней памяти сектора объединяют в группы, называемые кластерами.
Кластер – объединение нескольких секторов, которое может рассматриваться как самостоятельная единица, обладающая определёнными свойствами. Основным свойством кластера является его размер, измеряемый в количестве секторов или количестве байт.
![Файловая система FAT32]()
Файловая система FAT32 имеет следующую структуру.
Нумерация кластеров, используемых для записи файлов, ведется с 2. Как правило, кластер №2 используется корневым каталогом, а начиная с кластера №3 хранится массив данных. Сектора, используемые для хранения информации, представленной выше корневого каталога, в кластеры не объединяются.
Минимальный размер файла, занимаемый на диске, соответствует 1 кластеру.Загрузочный сектор начинается следующей информацией:
- EB 58 90 – безусловный переход и сигнатура;
- 4D 53 44 4F 53 35 2E 30 MSDOS5.0;
- 00 02 – количество байт в секторе (обычно 512);
- 1 байт – количество секторов в кластере;
- 2 байта – количество резервных секторов.
Кроме того, загрузочный сектор содержит следующую важную информацию:
- 0x10 (1 байт) – количество таблиц FAT (обычно 2);
- 0x20 (4 байта) – количество секторов на диске;
- 0x2С (4 байта) – номер кластера корневого каталога;
- 0x47 (11 байт) – метка тома;
- 0x1FE (2 байта) – сигнатура загрузочного сектора ( 55 AA ).
Сектор информации файловой системы содержит:- 0x00 (4 байта) – сигнатура ( 52 52 61 41 );
- 0x1E4 (4 байта) – сигнатура ( 72 72 41 61 );
- 0x1E8 (4 байта) – количество свободных кластеров, -1 если не известно;
- 0x1EС (4 байта) – номер последнего записанного кластера;
- 0x1FE (2 байта) – сигнатура ( 55 AA ).
Таблица FAT содержит информацию о состоянии каждого кластера на диске. Младшие 2 байт таблицы FAT хранят F8 FF FF 0F FF FF FF FF (что соответствует состоянию кластеров 0 и 1, физически отсутствующих). Далее состояние каждого кластера содержит номер кластера, в котором продолжается текущий файл или следующую информацию:- 00 00 00 00 – кластер свободен;
- FF FF FF 0F – конец текущего файла.
Корневой каталог содержит набор 32-битных записей информации о каждом файле, содержащих следующую информацию:- 8 байт – имя файла;
- 3 байта – расширение файла;
Корневой каталог содержит набор 32-битных записей информации о каждом файле, содержащих следующую информацию:- 8 байт – имя файла;
- 3 байта – расширение файла;
- 1 байт – атрибут файла:
- 1 байт – зарезервирован;
- 1 байт – время создания (миллисекунды) (число от 0 до 199);
- 2 байта – время создания (с точностью до 2с):
- 2 байта – дата создания:
- 2 байта – дата последнего доступа;
- 2 байта – старшие 2 байта начального кластера;
- 2 байта – время последней модификации;
- 2 байта – дата последней модификации;
- 2 байта – младшие 2 байта начального кластера;
- 4 байта – размер файла (в байтах).
В случае работы с длинными именами файлов (включая русские имена) кодировка имени файла производится в системе кодировки UTF-16. При этого для кодирования каждого символа отводится 2 байта. При этом имя файла записывается в виде следующей структуры:- 1 байт последовательности;
- 10 байт содержат младшие 5 символов имени файла;
- 1 байт атрибут;
- 1 байт резервный;
- 1 байт – контрольная сумма имени DOS;
- 12 байт содержат младшие 3 символа имени файла;
- 2 байта – номер первого кластера;
- остальные символы длинного имени.
Далее следует запись, включающая имя файла в формате 8.3 в обычном формате.
Работа с файлами в языке Си
Для программиста открытый файл представляется как последовательность считываемых или записываемых данных. При открытии файла с ним связывается поток ввода-вывода . Выводимая информация записывается в поток, вводимая информация считывается из потока.
Когда поток открывается для ввода-вывода, он связывается со стандартной структурой типа FILE , которая определена в stdio.h . Структура FILE содержит необходимую информацию о файле.
Открытие файла осуществляется с помощью функции fopen() , которая возвращает указатель на структуру типа FILE , который можно использовать для последующих операций с файлом.
- "r" — открыть файл для чтения (файл должен существовать);
- "w" — открыть пустой файл для записи; если файл существует, то его содержимое теряется;
- "a" — открыть файл для записи в конец (для добавления); файл создается, если он не существует;
- "r+" — открыть файл для чтения и записи (файл должен существовать);
- "w+" — открыть пустой файл для чтения и записи; если файл существует, то его содержимое теряется;
- "a+" — открыть файл для чтения и дополнения, если файл не существует, то он создаётся.
Функция fclose() закрывает поток или потоки, связанные с открытыми при помощи функции fopen() файлами. Закрываемый поток определяется аргументом функции fclose() .
Возвращаемое значение: значение 0, если поток успешно закрыт; константа EOF , если произошла ошибка.
Чтение символа из файла:
Аргументом функции является указатель на поток типа FILE . Функция возвращает код считанного символа. Если достигнут конец файла или возникла ошибка, возвращается константа EOF .Запись символа в файл:
Аргументами функции являются символ и указатель на поток типа FILE . Функция возвращает код считанного символа.
Функции fscanf() и fprintf() аналогичны функциям scanf() и printf() , но работают с файлами данных, и имеют первый аргумент — указатель на файл.
Функции fgets() и fputs() предназначены для ввода-вывода строк, они являются аналогами функций gets() и puts() для работы с файлами.
Копирует строку в поток с текущей позиции. Завершающий нуль- символ не копируется.
Пример Ввести число и сохранить его в файле s1.txt. Считать число из файла s1.txt, увеличить его на 3 и сохранить в файле s2.txt.
Но что если файл уже существует и нам нужно считать с него информацию для обработки? К счастью это тоже достаточно просто. Напоминаю, что вариантов для реализации этой задачи существует несколько, мною описан только один из. Описан тот, который лично мне почему-то кажется наиболее простым для восприятия.
Пишем код Как считать строки из файла на C++ ?
ofstream out ( Имя файла );
out << ( Записываемая строка );
out . close ();
=============================ifstream in ( Имя файла );
in >> ( Считываем строку );
in. close (); ( Закрываем файл )
============================
Напишем простую программу, которая будет считывать ввод с клавиатуры текста и записывать его в файл:int main ()
char a [ 255 ], b [ 255 ], c [ 255 ]; \\ 3 будущие строки
clrscsr (); // Очищаем экранfor (int i = 0 ; i <= 255 ; i ++)
/*Считываем посимвольно первую строку и выводим её на экран*/ /*Считываем посимвольно вторую строку и выводим её на экран*/ /*Считываем посимвольно третью строку и выводим её на экран*/В приведенных выше примерах есть один такой ОГРОМНЫЙ недостаток. Если мы будем пытаться ввести строчку, содержащую пробелы, то программа будет срабатывать не так как нам нужно. Наверное, на эту ошибку наткнулся не только я, но и многие другие люди. Поэтому я оставляю неверно приведенный код, чтобы было видно с чем можно столкнуться.
Так как книжек дома нет, я снова стал рыскать в интернете и понаходил много всякой мудреной ерунды. Но всё-таки как-то подобрал решение своей проблемы.
Помогло то, что читал о том, что cout поддерживает свои методы. И в интернете все советы идут на использование функции getline К моему счастью как использовать эту функцию я нашел очень быстро и потом использовал ее в коде.
Вообще стоит упомянуть и описать эту функцию, но пока что я не особо её понимаю, просто понимаю, что её нужно использовать и понимаю как, поэтому привожу более правильный пример нашей разрабатываемой программы:int main ()
char a [ 255 ], b [ 255 ], c [ 255 ]; \\ 3 будущие строки
clrscsr (); // Очищаем экранfor (int i = 0 ; i <= 255 ; i ++)
/*Считываем посимвольно первую строку и выводим её на экран*/ /*Считываем посимвольно вторую строку и выводим её на экран*/ /*Считываем посимвольно третью строку и выводим её на экран*/В этом материале разобран пример посимвольного чтения информации. Так как я не описывал работу с перемнными типа char , то у начинающих могут возникнуть некоторые неудобства воспринятия кода. Просто я не знал, что тип char имеет какие-то особенности и думал всё проще. Поэтому некоторые непонятные моменты приведенной программы можно прочитать в следующей статье работа с char в C++ для начинающих
В остальном, приведенный пример, как в C++ считать строки из текстового файла должен быть доступен и вполне понятен. Это сейчас не оптимальный вариант реализации, и я упустил некоторые важные моменты, но так как у нас начало изучения языка C++, то этого пока вполне достаточно. Попозже я наверняка дойду до упущенного, а сейчас нужно воспринимать только самое необходимое.
Если мы вместе с вами поняли этот материал, то значит продвинулись на маленький шажок к своему профессионализму.
Дальше в материале использованы функции. Если вы знаете, что это и как их используют, то материал по теме:
C++ Для начинающих вывести текст из файла на экран
Без понимания работы функции будет тяжело понятьЧитайте также: