
Что такое процессор и память
Обновлено: 04.07.2024
Инструмент проще, чем машина. Зачастую инструментом работают руками, а машину приводит в действие паровая сила или животное.
Компьютер тоже можно назвать машиной, только вместо паровой силы здесь электричество. Но программирование сделало компьютер таким же простым, как любой инструмент.
Процессор — это сердце/мозг любого компьютера. Его основное назначение — арифметические и логические операции, и прежде чем погрузиться в дебри процессора, нужно разобраться в его основных компонентах и принципах их работы.
Два основных компонента процессора
Устройство управления
Устройство управления (УУ) помогает процессору контролировать и выполнять инструкции. УУ сообщает компонентам, что именно нужно делать. В соответствии с инструкциями он координирует работу с другими частями компьютера, включая второй основной компонент — арифметико-логическое устройство (АЛУ). Все инструкции вначале поступают именно на устройство управления.
Существует два типа реализации УУ:
- УУ на жёсткой логике (англ. hardwired control units). Характер работы определяется внутренним электрическим строением — устройством печатной платы или кристалла. Соответственно, модификация такого УУ без физического вмешательства невозможна.
- УУ с микропрограммным управлением (англ. microprogrammable control units). Может быть запрограммирован для тех или иных целей. Программная часть сохраняется в памяти УУ.
УУ на жёсткой логике быстрее, но УУ с микропрограммным управлением обладает более гибкой функциональностью.
Арифметико-логическое устройство
Это устройство, как ни странно, выполняет все арифметические и логические операции, например сложение, вычитание, логическое ИЛИ и т. п. АЛУ состоит из логических элементов, которые и выполняют эти операции.
25–27 ноября, Онлайн, Беcплатно
Большинство логических элементов имеют два входа и один выход.
Ниже приведена схема полусумматора, у которой два входа и два выхода. A и B здесь являются входами, S — выходом, C — переносом (в старший разряд).
Схема арифметического полусумматора
Хранение информации — регистры и память
Как говорилось ранее, процессор выполняет поступающие на него команды. Команды в большинстве случаев работают с данными, которые могут быть промежуточными, входными или выходными. Все эти данные вместе с инструкциями сохраняются в регистрах и памяти.
Регистры
Регистр — минимальная ячейка памяти данных. Регистры состоят из триггеров (англ. latches/flip-flops). Триггеры, в свою очередь, состоят из логических элементов и могут хранить в себе 1 бит информации.
Прим. перев. Триггеры могут быть синхронные и асинхронные. Асинхронные могут менять своё состояние в любой момент, а синхронные только во время положительного/отрицательного перепада на входе синхронизации.
По функциональному назначению триггеры делятся на несколько групп:
- RS-триггер: сохраняет своё состояние при нулевых уровнях на обоих входах и изменяет его при установке единице на одном из входов (Reset/Set — Сброс/Установка).
- JK-триггер: идентичен RS-триггеру за исключением того, что при подаче единиц сразу на два входа триггер меняет своё состояние на противоположное (счётный режим).
- T-триггер: меняет своё состояние на противоположное при каждом такте на его единственном входе.
- D-триггер: запоминает состояние на входе в момент синхронизации. Асинхронные D-триггеры смысла не имеют.
Для хранения промежуточных данных ОЗУ не подходит, т. к. это замедлит работу процессора. Промежуточные данные отсылаются в регистры по шине. В них могут храниться команды, выходные данные и даже адреса ячеек памяти.
Принцип действия RS-триггера
Память (ОЗУ)
ОЗУ (оперативное запоминающее устройство, англ. RAM) — это большая группа этих самых регистров, соединённых вместе. Память у такого хранилища непостоянная и данные оттуда пропадают при отключении питания. ОЗУ принимает адрес ячейки памяти, в которую нужно поместить данные, сами данные и флаг записи/чтения, который приводит в действие триггеры.
Прим. перев. Оперативная память бывает статической и динамической — SRAM и DRAM соответственно. В статической памяти ячейками являются триггеры, а в динамической — конденсаторы. SRAM быстрее, а DRAM дешевле.
Команды (инструкции)
Команды — это фактические действия, которые компьютер должен выполнять. Они бывают нескольких типов:
- Арифметические: сложение, вычитание, умножение и т. д.
- Логические: И (логическое умножение/конъюнкция), ИЛИ (логическое суммирование/дизъюнкция), отрицание и т. д.
- Информационные: move , input , outptut , load и store .
- Команды перехода: goto , if . goto , call и return .
- Команда останова: halt .
Прим. перев. На самом деле все арифметические операции в АЛУ могут быть созданы на основе всего двух: сложение и сдвиг. Однако чем больше базовых операций поддерживает АЛУ, тем оно быстрее.
Инструкции предоставляются компьютеру на языке ассемблера или генерируются компилятором высокоуровневых языков.
В процессоре инструкции реализуются на аппаратном уровне. За один такт одноядерный процессор может выполнить одну элементарную (базовую) инструкцию.
Группу инструкций принято называть набором команд (англ. instruction set).
Тактирование процессора
Быстродействие компьютера определяется тактовой частотой его процессора. Тактовая частота — количество тактов (соответственно и исполняемых команд) за секунду.
Частота нынешних процессоров измеряется в ГГц (Гигагерцы). 1 ГГц = 10⁹ Гц — миллиард операций в секунду.
Чтобы уменьшить время выполнения программы, нужно либо оптимизировать (уменьшить) её, либо увеличить тактовую частоту. У части процессоров есть возможность увеличить частоту (разогнать процессор), однако такие действия физически влияют на процессор и нередко вызывают перегрев и выход из строя.
Выполнение инструкций
Инструкции хранятся в ОЗУ в последовательном порядке. Для гипотетического процессора инструкция состоит из кода операции и адреса памяти/регистра. Внутри управляющего устройства есть два регистра инструкций, в которые загружается код команды и адрес текущей исполняемой команды. Ещё в процессоре есть дополнительные регистры, которые хранят в себе последние 4 бита выполненных инструкций.
Ниже рассмотрен пример набора команд, который суммирует два числа:
- LOAD_A 8 . Это команда сохраняет в ОЗУ данные, скажем, <1100 1000> . Первые 4 бита — код операции. Именно он определяет инструкцию. Эти данные помещаются в регистры инструкций УУ. Команда декодируется в инструкцию load_A — поместить данные 1000 (последние 4 бита команды) в регистр A .
- LOAD_B 2 . Ситуация, аналогичная прошлой. Здесь помещается число 2 ( 0010 ) в регистр B .
- ADD B A . Команда суммирует два числа (точнее прибавляет значение регистра B в регистр A ). УУ сообщает АЛУ, что нужно выполнить операцию суммирования и поместить результат обратно в регистр A .
- STORE_A 23 . Сохраняем значение регистра A в ячейку памяти с адресом 23 .
Вот такие операции нужны, чтобы сложить два числа.
Все данные между процессором, регистрами, памятью и I/O-устройствами (устройствами ввода-вывода) передаются по шинам. Чтобы загрузить в память только что обработанные данные, процессор помещает адрес в шину адреса и данные в шину данных. Потом нужно дать разрешение на запись на шине управления.

У процессора есть механизм сохранения инструкций в кэш. Как мы выяснили ранее, за секунду процессор может выполнить миллиарды инструкций. Поэтому если бы каждая инструкция хранилась в ОЗУ, то её изъятие оттуда занимало бы больше времени, чем её обработка. Поэтому для ускорения работы процессор хранит часть инструкций и данных в кэше.
Если данные в кэше и памяти не совпадают, то они помечаются грязными битами (англ. dirty bit).
Поток инструкций
Современные процессоры могут параллельно обрабатывать несколько команд. Пока одна инструкция находится в стадии декодирования, процессор может успеть получить другую инструкцию.

Однако такое решение подходит только для тех инструкций, которые не зависят друг от друга.
Если процессор многоядерный, это означает, что фактически в нём находятся несколько отдельных процессоров с некоторыми общими ресурсами, например кэшем.

Для многих пользователей основополагающими критериями выбора процессора являются его тактовая частота и количество вычислительных ядер. А вот параметры кэш-памяти многие просматривают поверхностно, а то и вовсе не уделяют им должного внимания. А зря!
В данном материале поговорим об устройстве и назначении сверхбыстрой памяти процессора, а также ее влиянии на общую скорость работы персонального компьютера.
Предпосылки создания кэш-памяти
Любому пользователю, мало-мальски знакомому с компьютером, известно, что в составе ПК работает сразу несколько типов памяти. Это медленная постоянная память (классические жесткие диски или более быстрые SSD-накопители), быстрая оперативная память и сверхбыстрая кэш-память самого процессора. Оперативная память энергозависимая, поэтому каждый раз, когда вы выключаете или перезагружаете компьютер, все хранящиеся в ней данные очищаются, в отличие от постоянной памяти, в которой данные сохраняются до тех пор, пока это нужно пользователю. Именно в постоянную память записаны все программы и файлы, необходимые как для работы компьютера, так и для комфортной работы за ним.
Каждый раз при запуске программы из постоянной памяти, ее наиболее часто используемые данные или вся программа целиком «подгружаются» в оперативную память. Это делается для ускорения обработки данных процессором. Считывать и обрабатывать данные из оперативной памяти процессор будет значительно быстрей, а, следовательно, и система будет работать значительно быстрее в сравнении с тем, если бы массивы данных поступали напрямую из не очень быстрых (по меркам процессорных вычислений) накопителей.
Если бы не было «оперативки», то процесс считывания напрямую с накопителя занимал бы непозволительно огромное, по меркам вычислительной мощности процессора, время.

Но вот незадача, какой бы быстрой ни была оперативная память, процессор всегда работает быстрее. Процессор — это настолько сверхмощный «калькулятор», что произвести самые сложные вычисления для него — это даже не доля секунды, а миллионные доли секунды.
Производительность процессора в любом компьютере всегда ограничена скоростью считывания из оперативной памяти.
Процессоры развиваются так же быстро, как память, поэтому несоответствие в их производительности и скорости сохраняется. Производство полупроводниковых изделий постоянно совершенствуется, поэтому на пластину процессора, которая сохраняет те же размеры, что и 10 лет назад, теперь можно поместить намного больше транзисторов. Как следствие, вычислительная мощность за это время увеличилась. Впрочем, не все производители используют новые технологии для увеличения именно вычислительной мощности. К примеру, производители оперативной памяти ставят во главу угла увеличение ее емкости: ведь потребитель намного больше ценит объем, нежели ее быстродействие. Когда на компьютере запущена программа и процессор обращается к ОЗУ, то с момента запроса до получения данных из оперативной памяти проходит несколько циклов процессора. А это неправильно — вычислительная мощность процессора простаивает, и относительно медленная «оперативка» тормозит его работу.
Такое положение дел, конечно же, мало кого устраивает. Одним из вариантов решения проблемы могло бы стать размещение блока сверхбыстрой памяти непосредственно на теле кристалла процессора и, как следствие, его слаженная работа с вычислительным ядром. Но проблема, мешающая реализации этой идеи, кроется не в уровне технологий, а в экономической плоскости. Такой подход увеличит размеры готового процессора и существенно повысит его итоговую стоимость.

Объяснить простому пользователю, голосующему своими кровными сбережениями, что такой процессор самый быстрый и самый лучший, но за него придется отдать значительно больше денег — довольно проблематично. К тому же существует множество стандартов, направленных на унификацию оборудования, которым следуют производители «железа». В общем, поместить оперативную память прямо на кристалл процессора не представляется возможным по ряду объективных причин.
Как работает кэш-память
Как стало понятно из постановки задачи, данные должны поступать в процессор достаточно быстро. По меркам человека — это миг, но для вычислительного ядра — достаточно большой промежуток времени, и его нужно как можно эффективнее минимизировать. Вот здесь на выручку и приходит технология, которая называется кэш-памятью. Кэш-память — это сверхбыстрая память, которую располагают прямо на кристалле процессора. Извлечение данных из этой памяти не занимает столько времени, сколько бы потребовалось для извлечения того же объема из оперативной памяти, следовательно, процессор молниеносно получает все необходимые данные и может тут же их обрабатывать.
Кэш-память — это, по сути, та же оперативная память, только более быстрая и дорогая. Она имеет небольшой объем и является одним из компонентов современного процессора.
На этом преимущества технологии кэширования не заканчиваются. Помимо своего основного параметра — скорости доступа к ячейкам кэш-памяти, т. е. своей аппаратной составляющей, кэш-память имеет еще и множество других крутых функций. Таких, к примеру, как предугадывание, какие именно данные и команды понадобятся пользователю в дальнейшей работе и заблаговременная загрузка их в свои ячейки. Но не стоит путать это со спекулятивным исполнением, в котором часть команд выполняется рандомно, дабы исключить простаивание вычислительных мощностей процессора.
Спекулятивное исполнение — метод оптимизации работы процессора, когда последний выполняет команды, которые могут и не понадобиться в дальнейшем. Использование метода в современных процессорах довольно существенно повышает их производительность.
Речь идет именно об анализе потока данных и предугадывании команд, которые могут понадобиться в скором будущем (попадании в кэш). Это так называемый идеальный кэш, способный предсказать ближайшие команды и заблаговременно выгрузить их из ОЗУ в ячейки сверхбыстрой памяти. В идеале их надо выбирать таким образом, чтобы конечный результат имел нулевой процент «промахов».
Но как процессор это делает? Процессор что, следит за пользователем? В некоторой степени да. Он выгружает данные из оперативной памяти в кэш-память для того, чтобы иметь к ним мгновенный доступ, и делает это на основе предыдущих данных, которые ранее были помещены в кэш в этом сеансе работы. Существует несколько способов, увеличивающих число «попаданий» (угадываний), а точнее, уменьшающих число «промахов». Это временная и пространственная локальность — два главных принципа кэш-памяти, благодаря которым процессор выбирает, какие данные нужно поместить из оперативной памяти в кэш.
Временная локальность
Процессор смотрит, какие данные недавно содержались в его кэше, и снова помещает их в кэш. Все просто: высока вероятность того, что выполняя какие-либо задачи, пользователь, скорее всего, повторит эти же действия. Процессор подгружает в ячейки сверхбыстрой памяти наиболее часто выполняемые задачи и сопутствующие команды, чтобы иметь к ним прямой доступ и мгновенно обрабатывать запросы.
Пространственная локальность
Принцип пространственной локальности несколько сложней. Когда пользователь выполняет какие-то действия, процессор помещает в кэш не только данные, которые находятся по одному адресу, но еще и данные, которые находятся в соседних адресах. Логика проста — если пользователь работает с какой-то программой, то ему, возможно, понадобятся не только те команды, которые уже использовались, но и сопутствующие «слова», которые располагаются рядом.
Набор таких адресов называется строкой (блоком) кэша, а количество считанных данных — длиной кэша.
При пространственной локации процессор сначала ищет данные, загруженные в кэш, и, если их там не находит, то обращается к оперативной памяти.
Иерархия кэш-памяти
Любой современный процессор имеет в своей структуре несколько уровней кэш-памяти. В спецификации процессора они обозначаются как L1, L2, L3 и т. д.

Если провести аналогию между устройством кэш-памяти процессора и рабочим местом, скажем столяра или представителя любой другой профессии, то можно увидеть интересную закономерность. Наиболее востребованный в работе инструмент находится под рукой, а тот, что используется реже, расположен дальше от рабочей зоны.
Так же организована и работа быстрых ячеек кэша. Ячейки памяти первого уровня (L1) располагаются на кристалле в непосредственной близости от вычислительного ядра. Эта память — самая быстрая, но и самая малая по объему. В нее помещаются наиболее востребованные данные и команды. Для передачи данных оттуда потребуется всего около 5 тактовых циклов. Как правило, кэш-память первого уровня состоит из двух блоков, каждый из которых имеет размер 32 КБ. Один из них — кэш данных первого уровня, второй — кэш инструкций первого уровня. Они отвечают за работу с блоками данных и молниеносное обращение к командам.
Кэш второго и третьего уровня больше по объему, но за счет того, что L2 и L3 удалены от вычислительного ядра, при обращении к ним будут более длительные временные интервалы. Более наглядно устройство кэш-памяти проиллюстрировано в следующем видео.
Кэш L2, который также содержит команды и данные, занимает уже до 512 КБ, чтобы обеспечить необходимый объем данных кэшу нижнего уровня. Но на обработку запросов уходит в два раза больше времени. Кэш третьего уровня имеет размеры уже от 2 до 32 МБ (и постоянно увеличивается вслед за развитием технологий), но и его скорость заметно ниже. Она превышает 30 тактовых циклов.

Процессор запрашивает команды и данные, обрабатывая их, что называется, параллельными курсами. За счет этого и достигается потрясающая скорость работы. В качестве примера рассмотрим процессоры Intel. Принцип работы таков: в кэше хранятся данные и их адрес (тэг кэша). Сначала процессор ищет их в L1. Если информация не найдена (возник промах кэша), то в L1 будет создан новый тэг, а поиск данных продолжится на других уровнях. Для того, чтобы освободить место под новый тэг, информация, не используемая в данный момент, переносится на уровень L2. В результате данные постоянно перемещаются с одного уровня на другой.
Также при хранении одних и тех же данных могут задействоваться различные уровни кэша, например, L1 и L3. Это так называемые инклюзивные кэши. Использование лишнего объема памяти окупается скоростью поиска. Если процессор не нашел данные на нижнем уровне, ему не придется искать их на верхних уровнях кэша. В этом случае задействованы кэши-жертвы. Это полностью ассоциативный кэш, который используется для хранения блоков, вытесненных из кэша при замене. Он предназначен для уменьшения количества промахов. Например, кэши-жертвы L3 будут хранить информацию из L2. В то же время данные, которые хранятся в L2, остаются только там, что помогает сэкономить место в памяти, однако усложняет поиск данных: системе приходится искать необходимый тэг в L3, который заметно больше по размеру.
В некоторых политиках записи информация хранится в кэше и основной системной памяти. Современные процессоры работают следующим образом: когда данные пишутся в кэш, происходит задержка перед тем, как эта информация будет записана в системную память. Во время задержки данные остаются в кэше, после чего их «вытесняет» в ОЗУ.
Итак, кэш-память процессора — очень важный параметр современного процессора. От количества уровней кэша и объема ячеек сверхбыстрой памяти на каждом из уровней, во многом зависит скорость и производительность системы. Особенно хорошо это ощущается в компьютерах, ориентированных на гейминг или сложные вычисления.

Во всех центральных процессорах любого компьютера, будь то дешёвый ноутбук или сервер за миллионы долларов, есть устройство под названием «кэш». И с очень большой вероятностью он обладает несколькими уровнями.
Наверно, он важен, иначе зачем бы его устанавливать? Но что же делает кэш, и для чего ему разные уровни? И что означает «12-канальный ассоциативный кэш» (12-way set associative)?
Что такое кэш?
TL;DR: это небольшая, но очень быстрая память, расположенная в непосредственной близости от логических блоков центрального процессора.
Однако мы, разумеется, можем узнать о кэше гораздо больше…
Давайте начнём с воображаемой волшебной системы хранения: она бесконечно быстра, может одновременно обрабатывать бесконечное количество операций передачи данных и всегда обеспечивает надёжное и безопасное хранение данных. Конечно же, ничего подобного и близко не существует, однако если бы это было так, то структура процессора была бы гораздо проще.
Процессорам бы тогда требовались только логические блоки для сложения, умножения и т.п, а также система управления передачей данных, ведь наша теоретическая система хранения способна мгновенно передавать и получать все необходимые числа; ни одному из логических блоков не приходится простаивать в ожидании передачи данных.
Но, как мы знаем, такой волшебной технологии хранения не существует. Вместо неё у нас есть жёсткие диски или твердотельные накопители, и даже самые лучшие из них далеки от возможностей обработки, необходимых для современного процессора.

Великий Т'Фон хранения данных
Причина этого заключается в том, что современные процессоры невероятно быстры — им требуется всего один тактовый цикл для сложения двух 64-битных целочисленных значений; если процессор работает с частотой 4 ГГЦ, то это составляет всего 0,00000000025 секунды, или четверть наносекунды.
В то же время, вращающемуся жёсткому диску требуются тысячи наносекунд только для нахождения данных на дисках, не говоря уже об их передаче, а твердотельным накопителям — десятки или сотни наносекунд.
Очевидно, что такие приводы невозможно встроить внутрь процессоров, поэтому между ними будет присутствовать физическое разделение. Поэтому ещё добавляется время на перемещение данных, что усугубляет ситуацию.

Увы, но это Великий А'Туин хранения данных
Именно поэтому нам нужна ещё одна система хранения данных, расположенная между процессором и основным накопителем. Она должна быть быстрее накопителя, способна одновременно управлять множеством операций передачи данных и находиться намного ближе к процессору.
Ну, у нас уже есть такая система, и она называется ОЗУ (RAM); она присутствует в каждом компьютере и выполняет именно эту задачу.
Почти все такие хранилища имеют тип DRAM (dynamic random access memory); они способны передавать данные гораздо быстрее, чем любой накопитель.

Однако, несмотря на свою огромную скорость, DRAM не способна хранить такие объёмы данных.
Одни из самых крупных чипов памяти DDR4, разработанных Micron, хранят 32 Гбит, или 4 ГБ данных; самые крупные жёсткие диски хранят в 4 000 раз больше.
Итак, хоть мы и повысили скорость нашей сети данных, нам потребуются дополнительные системы (аппаратные и программные), чтобы разобраться, какие данные должны храниться в ограниченном объёме DRAM, готовые к обработке процессором.
DRAM могут изготавливаться в корпусе чипа (это называется встроенной (embedded) DRAM). Однако процессоры довольно малы, поэтому в них не удастся поместить много памяти.

10 МБ DRAM слева от графического процессора Xbox 360. Источник: CPU Grave Yard
Подавляющее большинство DRAM расположено в непосредственной близости от процессора, подключено к материнской плате и всегда является самым близким к процессору компонентом. Тем не менее, эта память всё равно недостаточно быстра…
DRAM требуется примерно 100 наносекунд для нахождения данных, но, по крайней мере, она способна передавать миллиарды битов в секунду. Похоже, нам нужна ещё одна ступень памяти, которую можно разместить между блоками процессора и DRAM.
На сцене появляется оставшаяся ступень: SRAM (static random access memory). DRAM использует микроскопические конденсаторы для хранения данных в виде электрического заряда, а SRAM для той же задачи применяет транзисторы, которые работают с той же скоростью, что и логические блоки процессора (примерно в 10 раз быстрее, чем DRAM).

Разумеется, у SRAM есть недостаток, и он опять-таки связан с пространством.
Память на основе транзисторов занимает гораздо больше места, чем DRAM: в том же размере, что чип DDR4 на 4 ГБ, можно получить меньше 100 МБ SRAM. Но поскольку она производится по тому же технологическому процессу, что и CPU, память SRAM можно встроить прямо внутрь процессора, максимально близко к логическим блокам.
С каждой дополнительной ступенью мы увеличивали скорость перемещаемых данных ценой хранимого объёма. Мы можем продолжить и добавлять новые ступени,, которые будут быстрее, но меньше.
И так мы добрались до более строгого определения понятия кэша: это набор блоков SRAM, расположенных внутри процессора; они обеспечивают максимальную занятость процессора благодаря передаче и сохранению данных с очень высокими скоростями. Вас устраивает такое определение? Отлично, потому что дальше всё будет намного сложнее!
Кэш: многоуровневая парковка

На приведённом выше изображении процессор (CPU) обозначен прямоугольником с пунктирной границей. Слева расположены ALU (arithmetic logic units, арифметико-логические устройства); это структуры, выполняющие математические операции. Хотя строго говоря, они не являются кэшем, ближайший к ALU уровень памяти — это регистры (они упорядочены в регистровый файл).
Каждый из них хранит одно число, например, 64-битное целое число; само значение может быть элементом каких-нибудь данных, кодом определённой инструкции или адресом памяти каких-то других данных.
Регистровый файл в десктопных процессорах довольно мал, например, в каждом из ядер Intel Core i9-9900K есть по два банка таких файлов, а тот, который предназначен для целых чисел, содержит всего 180 64-битных целых чисел. Другой регистровый файл для векторов (небольших массивов чисел) содержит 168 256-битных элементов. То есть общий регистровый файл каждого ядра чуть меньше 7 КБ. Для сравнения: регистровый файл потоковых мультипроцессоров (так в GPU называются аналоги ядер CPU) Nvidia GeForce RTX 2080 Ti имеет размер 256 КБ.
Регистры, как и кэш, являются SRAM, но их скорость не превышает скорость обслуживаемых ими ALU; они передают данные за один тактовый цикл. Но они не предназначены для хранения больших объёмов данных (только одного элемента), поэтому рядом с ними всегда есть более крупные блоки памяти: это кэш первого уровня (Level 1).

Одно ядро процессора Intel Skylake. Источник: Wikichip
На изображении выше представлен увеличенный снимок одного из ядер десктопного процессора Intel Skylake.
ALU и регистровые файлы расположены слева и обведены зелёной рамкой. В верхней части фотографии белым обозначен кэш данных первого уровня (Level 1 Data cache). Он не содержит много информации, всего 32 КБ, но как и регистры, он расположен очень близко к логическим блокам и работает на одной скорости с ними.
Ещё одним белым прямоугольником справа показан кэш инструкций первого уровня (Level 1 Instruction cache), тоже имеющий размер 32 КБ. Как понятно из названия, в нём хранятся различные команды, готовые к разбиению на более мелкие микрооперации (обычно обозначаемые μops), которые должны выполнять ALU. Для них тоже существует кэш, который можно классифицировать как Level 0, потому что он меньше (содержит всего 1 500 операций) и ближе, чем кэши L1.
Вы можете задаться вопросом: почему эти блоки SRAM настолько малы? Почему они не имеют размер в мегабайт? Вместе кэши данных и инструкций занимают почти такую же площадь на чипе, что основные логические блоки, поэтому их увеличение приведёт к повышению общей площади кристалла.
Но основная причина их размера в несколько килобайт заключается в том, что при увеличении ёмкости памяти повышается время, необходимое для поиска и получения данных. Кэшу L1 нужно быть очень быстрым, поэтому необходимо достичь компромисса между размером и скоростью — в лучшем случае для получения данных из этого кэша требуется около 5 тактовых циклов (для значений с плавающей запятой больше).

Кэш L2 процессора Skylake: 256 КБ SRAM
Но если бы это был единственный кэш внутри процессора, то его производительность наткнулась бы на неожиданное препятствие. Именно поэтому в ядра встраивается еще один уровень памяти: кэш Level 2. Это обобщённый блок хранения, содержащий инструкции и данные.
Он всегда больше, чем Level 1: в процессорах AMD Zen 2 он занимает до 512 КБ, чтобы кэши нижнего уровня обеспечивались достаточным объёмом данных. Однако большой размер требует жертв — для поиска и передачи данных из этого кэша требуется примерно в два раза больше времени по сравнению с Level 1.
Во времена первого Intel Pentium кэш Level 2 был отдельным чипом, или устанавливаемым на отдельной небольшой плате (как ОЗУ DIMM), или встроенным в основную материнскую плату. Постепенно он перебрался в корпус самого процессора, и, наконец, полностью интегрировался в кристалл чипа; это произошло в эпоху таких процессоров, как Pentium III и AMD K6-III.
За этим достижением вскоре последовал ещё один уровень кэша, необходимый для поддержки более низких уровней, и появился он как раз вовремя — в эпоху расцвета многоядерных чипов.

Чип Intel Kaby Lake. Источник: Wikichip
На этом изображении чипа Intel Kaby Lake в левой части показаны четыре ядра (интегрированный GPU занимает почти половину кристалла и находится справа). Каждое ядро имеет свой «личный» набор кэшей Level 1 и 2 (выделены белыми и жёлтым прямоугольниками), но у них также есть и третий комплект блоков SRAM.
Кэш третьего уровня (Level 3), хоть и расположен непосредственно рядом с одним ядром, является полностью общим для всех остальных — каждое ядро свободно может получать доступ к содержимому кэша L3 другого ядра. Он намного больше (от 2 до 32 МБ), но и намного медленнее, в среднем более 30 циклов, особенно когда ядру нужно использовать данные, находящиеся в блоке кэша, расположенного на большом расстоянии.
Ниже показано одно ядро архитектуры AMD Zen 2: кэши Level 1 данных и инструкций по 32 КБ (в белых прямоугольниках), кэш Level 2 на 512 КБ (в жёлтых прямоугольниках) и огромный блок кэша L3 на 4 МБ (в красном прямоугольнике).

Увеличенный снимок одного ядра процессора AMD Zen 2. Источник: Fritzchens Fritz
Но постойте: как 32 КБ могут занимать больше физического пространства чем 512 КБ? Если Level 1 хранит так мало данных, почему он непропорционально велик по сравнению с кэшами L2 и L3?
Не только числа
Кэш повышает производительность, ускоряя передачу данных в логические блоки и храня поблизости копию часто используемых инструкций и данных. Хранящаяся в кэше информация разделена на две части: сами данные и место, где они изначально располагаются в системной памяти/накопителе — такой адрес называется тег кэша (cache tag).
Когда процессор выполняет операцию, которой нужно считать или записать данные из/в память, то он начинает с проверки тегов в кэше Level 1. Если нужные данные там есть (произошло кэш-попадание (cache hit)), то доступ к этим данным выполняется почти сразу же. Промах кэша (cache miss) возникает, если требуемый тег не найден на самом нижнем уровне кэша.
В кэше L1 создаётся новый тег, а за дело берётся остальная часть архитектуры процессора выполняющая поиск в других уровнях кэша (при необходимости вплоть до основного накопителя) данных для этого тега. Но чтобы освободить пространство в кэше L1 под этот новый тег, что-то обязательно нужно перебросить в L2.
Это приводит к почти постоянному перемешиванию данных, выполняемому всего за несколько тактовых циклов. Единственный способ добиться этого — создание сложной структуры вокруг SRAM для обработки управления данными. Иными словами, если бы ядро процессора состояло всего из одного ALU, то кэш L1 был бы гораздо проще, но поскольку их десятки (и многие из них жонглируют двумя потоками инструкций), то для перемещения данных кэшу требуется множество соединений.

Для изучения информации кэша в процессоре вашего компьютера можно использовать бесплатные программы, например CPU-Z. Но что означает вся эта информация? Важным элементом является метка set associative (множественно-ассоциативный) — она указывает на правила, применяемые для копирования блоков данных из системной памяти в кэш.
Представленная выше информация кэша относится к Intel Core i7-9700K. Каждый из его кэшей Level 1 разделён на 64 небольших блока, называемые sets, и каждый из этих блоков ещё разбит на строки кэша (cache lines) (размером 64 байта). «Set associative» означает, что блок данных из системы привязывается к строкам кэша в одном конкретном сете, и не может свободно привязываться к какому-то другому месту.

Инклюзивный кэш L1+L2, victim cache L3, политики write-back, есть даже ECC. Источник: Fritzchens Fritz
Ещё один аспект сложности кэша связан с тем, как хранятся данные между разными уровнями. Правила задаются в inclusion policy (политике инклюзивности). Например, процессоры Intel Core имеют полностью инклюзивные кэши L1+L3. Это означает, что одни данные в Level 1, например, могут присутствовать в Level 3. Может показаться, что это пустая трата ценного пространства кэша, однако преимущество заключается в том, что если процессор совершает промах при поиске тега в нижнем уровне, ему не потребуется обыскивать верхний уровень для нахождения данных.
В тех же самых процессорах кэш L2 неинклюзивен: все хранящиеся там данные не копируются ни на какой другой уровень. Это экономит место, но приводит к тому, что системе памяти чипа нужно искать ненайденный тег в L3 (который всегда намного больше). Victim caches (кэши-жертвы) имеют похожий принцип, но они используются для хранения информации, переносимой с более низких уровней. Например, процессоры AMD Zen 2 используют victim cache L3, который просто хранит данные из L2.
Существуют и другие политики для кэша, например, при которых данные записываются и в кэш, и основную системную память. Они называются политиками записи (write policies); большинство современных процессоров использует кэши write-back — это означает, что когда данные записываются на уровень кэшей, происходит задержка перед записью их копии в системную память. Чаще всего эта пауза длится в течение того времени, пока данные остаются в кэше — ОЗУ получает эту информацию только при «выталкивании» из кэша.

Графический процессор Nvidia GA100, имеющий 20 МБ кэша L1 и 40 МБ кэша L2
Для проектировщиков процессоров выбор объёма, типа и политики кэшей является вопросом уравновешивания стремления к повышению мощности процессора с увеличением его сложности и занимаемым чипом пространством. Если бы можно было создать 1000-канальные ассоциативные кэши Level 1 на 20 МБ такими, чтобы они при этом не занимали площадь Манхэттена (и не потребляли столько же энергии), то у нас у всех бы были компьютеры с такими чипами!
Самый нижний уровень кэшей в современных процессорах за последнее десятилетие практически не изменился. Однако кэш Level 3 продолжает расти в размерах. Если бы десять лет назад у вас было 999 долларов на Intel i7-980X, то вы могли бы получить кэш размером 12 МБ. Сегодня за половину этой суммы можно приобрести 64 МБ.
Подведём итог: кэш — это абсолютно необходимое и потрясающее устройство. Мы не рассматривали другие типы кэшей в CPU и GPU (например, буферы ассоциативной трансляции или кэши текстур), но поскольку все они имеют такую же простую структуру и расположение уровней, разобраться в них будет несложно.
Был ли у вас компьютер с кэшем L2 на материнской плате? Как насчёт слотовых Pentium II и Celeron (например, 300a) на дочерних платах? Помните свой первый процессор с общим L3?
На правах рекламы
Наша компания предлагает в аренду серверы с процессорами от Intel и AMD. В последнем случае — это эпичные серверы! VDS с AMD EPYC, частота ядра CPU до 3.4 GHz. Максимальная конфигурация — 128 ядер CPU, 512 ГБ RAM, 4000 ГБ NVMe.
Если вы когда-нибудь задумывались, что это за процесс, за которым следует процессор и Оперативная память что он назначил для получения данных и инструкций, которые он должен выполнить, то вам повезло, потому что в этой статье мы собираемся объяснить, что это за процесс связи между двумя наиболее важными элементами ПК, с которыми общаются разное.
В этой статье мы не будем объяснять, какой тип оперативной памяти лучше or спецификации каждого , но процессор связывается с ним, чтобы иметь возможность выполнять программы.

Причина почему мы используем внешнюю память потому, что количество транзисторов, необходимых для хранения информации, не поместится в пространстве процессора , поэтому необходимо использовать память RAM, внешнюю по отношению к процессору, для хранения инструкций и данных, которые они будут выполнять.
Зачем процессору связь с ОЗУ?
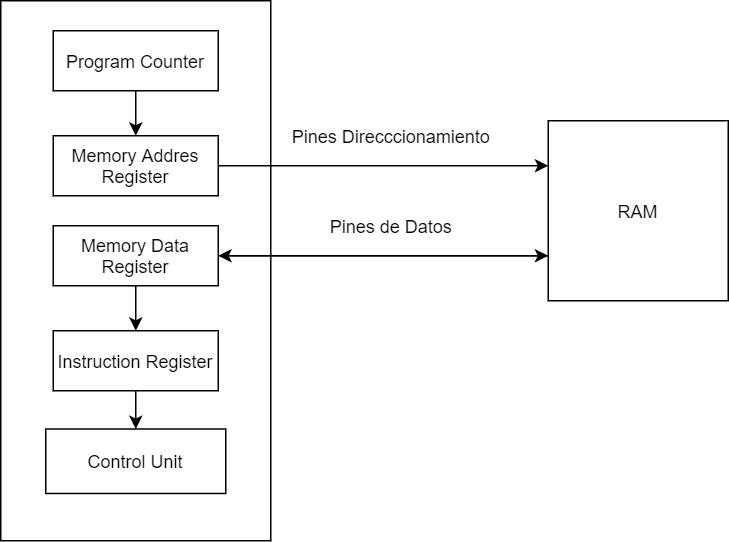
Стадия, на которой ЦП берет следующую инструкцию для выполнения из ОЗУ, называется «выборкой» и является одним из трех этапов, составляющих цикл команд: Fetch-Decode-Execute, о котором мы поговорим только в этой статье о первой, а о второй два будут оставлены на другой раз, так как оперативная память не вмешивается в них, кроме как для записи результата обратно.
- Счетчик команд: ПК указывает на следующую строку памяти, где находится следующая инструкция процессора. Его значение увеличивается на 1 каждый раз, когда завершается полный цикл команд или когда команда перехода изменяет значение программного счетчика.
- Регистр адреса памяти: MAR копирует содержимое ПК и отправляет его в RAM через адресные контакты ЦП, которые соединены с адресными контактами RAM.
- Регистр данных памяти : Если инструкция прочитана, то ОЗУ будет передавать через свою шину данных содержимое адреса памяти, на который указывал MAR.
- Реестр инструкций: Инструкция копируется в регистр инструкций, откуда блок управления расшифровывает ее, чтобы знать, как выполнить инструкцию.
Что такое память DRAM?
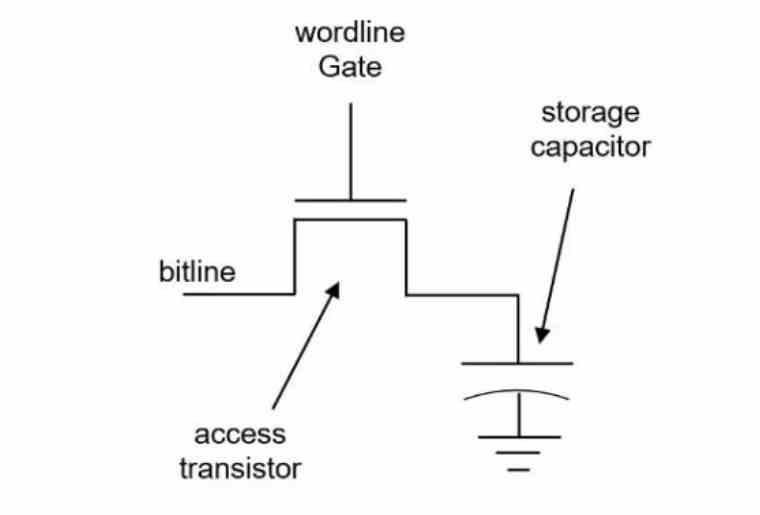
Освободи Себя тип памяти, используемой для RAM как системное ОЗУ, так и видеопамять или видеопамять. Память DRAM или 1T-DRAM . В этом типе памяти каждый бит хранится в комбинация конденсатора и транзистора , а не в нескольких транзисторах, таких как SRAM, отсюда и название 1T-DRAM.
Вся память RAM, используемая в настоящее время в ПК: DDR4, GDDR6, HBM2e, LPDDR4 и т. Д., Является памятью типа DRAM, в то время как внутренняя память процессоров, кеши регистров и блокноты относятся к типу SRAM.
Указанная комбинация конденсатора и транзистора называется Bitcell , когда конденсатор битовой ячейки заряжен, интерпретируется, что информация, содержащаяся в этой битовой ячейке, равна 1, когда она не заряжена, она интерпретируется как 0.
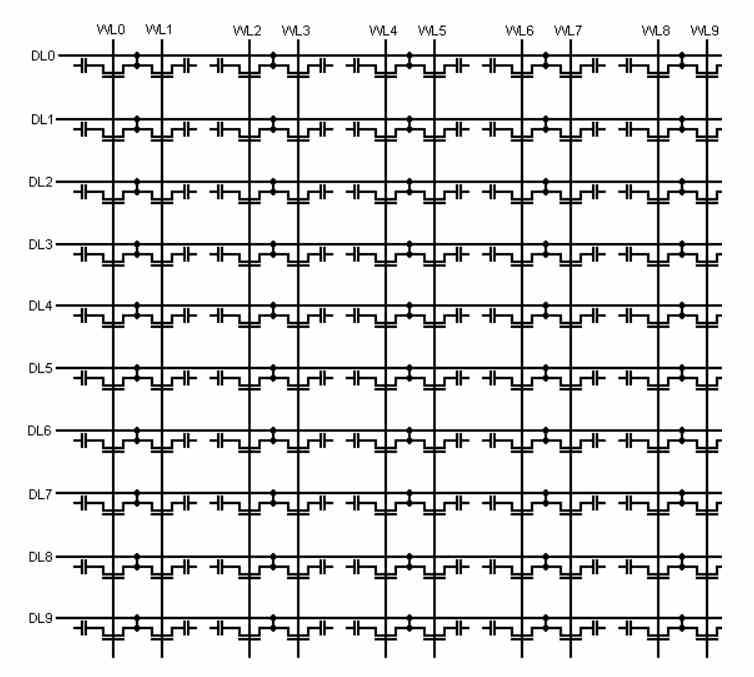
Битовые ячейки организованы в матрицу, в которой контакты адресации используются для доступа к ним следующим образом:
- Первая половина битов выбирает строку, к которой мы хотим получить доступ
- Вторая половина битов адресации содержит столбец, к которому мы хотим получить доступ,
Для этого между матрицей битовых ячеек и шиной адресации существует двоичный декодер, который позволяет выбрать соответствующую битовую ячейку.
Контакты для связи с RAM

- адресация штифты : Обычно обозначается от A0 до AN, где N - количество контактов и равно количеству бит адресации, которое всегда равно 2 ^ N.
- Контакты данных : Здесь данные передаются в оперативную память и из нее.
- Запись разрешена: Если вывод активен, передача данных осуществляется в память, запись, с другой стороны, если она не активна, то в сторону процессора, чтение.
Если наша система имеет несколько микросхем памяти RAM, то первые биты адресации используются для выбора, к какой из микросхем памяти мы хотим получить доступ в модуле памяти DIMM. Также были случаи, когда адрес и контакты данных совпадали. Это связано с тем, что адресация и доступ к данным не выполняются одновременно.
Но чтобы понять, как работает адресация, мы должны рассмотреть основную часть электроники - двоичный декодер.
Двоичный декодер и его роль в связи с RAM
В оперативной памяти адресация передается в двух циклах: сначала отправляется строка, к которой необходимо получить доступ, а затем столбец, а не одновременно.
По этой причине обращение к оперативной памяти происходит в два этапа.
Банки памяти
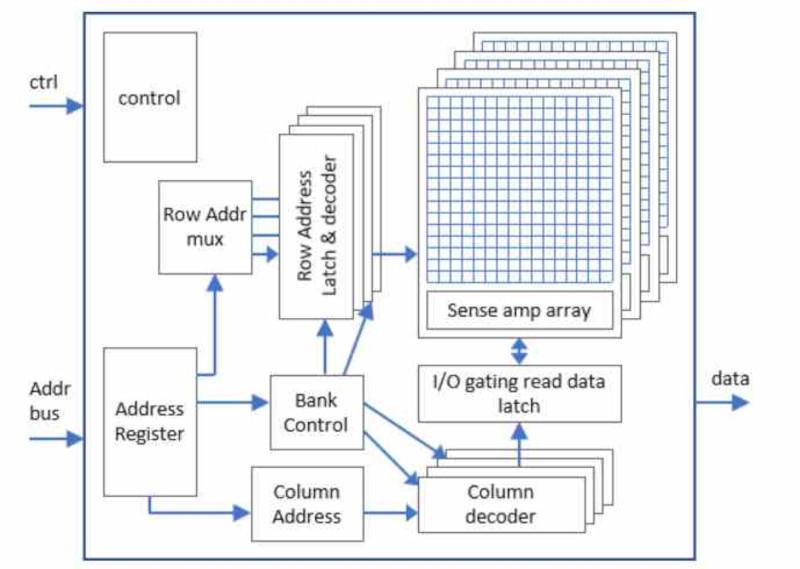
Данные в ОЗУ не хранятся последовательно , но в разных банках на одном чипе, каждый из банков содержит массив битовых ячеек , но если мы хотим передать, например, n битов данных, нам понадобится n массивов битовых ячеек, каждый из которых подключен к выводу шины данных.
Использование несколько банков , в той же микросхеме памяти, позволяет выбрать несколько бит одновременно с одним доступом к памяти , поскольку все банки разделяют адресацию . Таким образом, если у нас есть 8 банков памяти, выбор конкретной битовой ячейки приведет к одновременной передаче данных в 8 банков памяти и из них.
Стандартный размер банков в памяти RAM составляет 8 бит, поэтому максимальный объем памяти при адресации всегда считается как 2 ^ n байтов. Фактически, это 16-, 32-, 64-битные шины и т. Д. Они передают данные нескольких последовательных адресов памяти, начиная с первого.
Связь между RAM и CPU

- Выберите столбец (Адресация)
- Выберите строку (Адресация)
- Передача данных.
Для этого используется ряд специальных контактов, один из которых мы уже видели, и это запись Enable, а два других следующие:
- Строб доступа к колонке: Этот вывод активируется, когда мы указываем оперативной памяти, что указываем столбец, к которому хотим получить доступ.
- Строб доступа к строке :: Этот вывод активируется, когда мы указываем оперативной памяти, что указываем строку, к которой хотим получить доступ.
Обе операции можно резюмировать следующим образом:
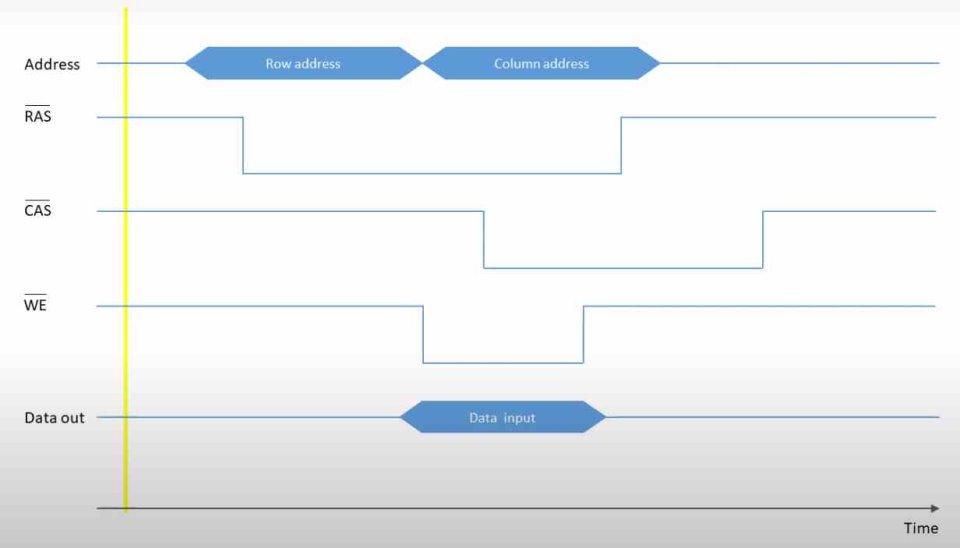
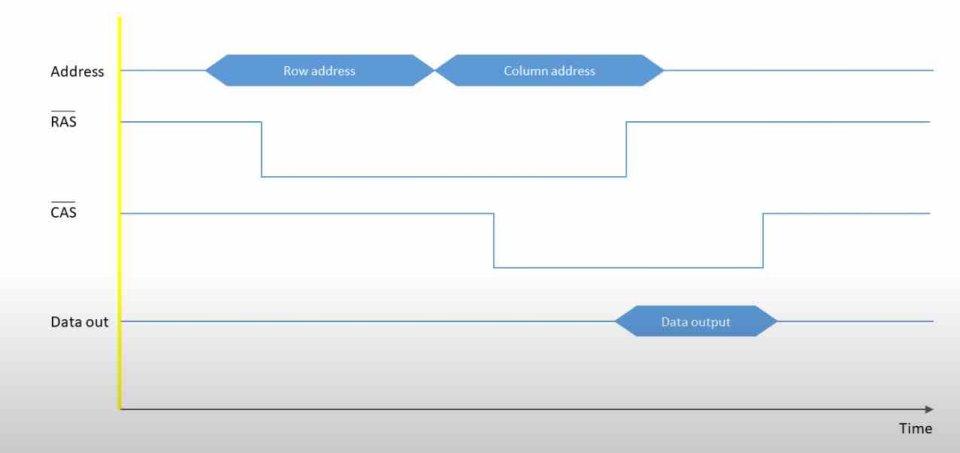
- Операция чтения очень проста, для этого у вас должен быть неактивен вывод WE, чтобы указать, что данные идут из ОЗУ в процессор, указать строку, а затем столбец, чтобы информация поступала к процессору из ОЗУ памяти. .
- Операция записи несколько отличается, для этого вывод WE должен быть активен, но данные передаются не после выбора столбца данных, а после выбора строки и одновременно с выбором столбца, в котором находятся данные.
Благодаря этому вы уже можете получить приблизительное представление о том, как работает связь между процессором и его оперативной памятью.
Читайте также: