
Сколько транзисторов в видеокарте
Обновлено: 30.06.2024
Транзисторы, которые не в чипе, а на самой видеокарте служат для преобразования питания. Из 12 вольт делают напряжение, необходимое для питания ядра. Чем мощнее видеокарта, тем больше их. Китайцы могут и сэкономить, но тогда на оставшиеся придется бОльшая нагрузка и соответственно - будут сильнее греться.
А их можно увидить на видеокарте (тоесь на текстолите)?
Ну вот в етой карте в 2 раза больше транзистров чем в етой.Что ето даёт?
Ну вот в етой карте в 2 раза больше транзистров чем в етой.Что ето даёт?
Nephilim Гуру (4524) ну она спроектирована иначе. больше ничего
сложней структура (схема) , больше возможностей у карты наверное.
Ну вот в етой карте в 2 раза больше транзистров чем в етой.Что ето даёт?
Хороший производитель старается всё убрать в микросхемы. И чем больше элементов на плате, тем хуже карта.
Ну вот в етой карте в 2 раза больше транзистров чем в етой.Что ето даёт?
на что влияет длинна проводки у вас в квартире?
на что влияет количество букв в слове?
транзистор это просто радиодеталь, позволяющий входным сигналам управлять током в электрической цепи.
Ну вот в етой карте в 2 раза больше транзистров чем в етой.Что ето даёт?
Ихаил Ыло Мастер (1297) это дает лишний геморрой производителям, которые их туда напаивают, и рассчитывают. судить о производительности карты по количеству транзисторов -имхо бред.
Ну вот в етой карте в 2 раза больше транзистров чем в етой.Что ето даёт?
На увеличении вероятности отказа или выхода из строя. чем больше транзисторов, тем больше вероятность))))
markus mak-frank Искусственный Интеллект (287780) Да чем сложнее система тем больше вероятность выхода её из строя.
Для тебя, как и любого другого пользователя-ни на что, кроме цены :) Видеокарту выбирают не по количеству транзисторов, а по другим критериям.
ни один ответ НЕПРАВИЛЬНЫЙ. Все топовые видеокарты содержат максимальное количество транзисторов в ЧИПЕ! а не на плате, где питанием управляют MOSFETы. А обрезки Чипов в среднем на 30% меньше транзисторов и они стоят в бюджетных видеокартах. Из транзисторов формируется, правильно, логика и управление процессами заложенные драйверами (не путать с софтом). Так вот все транзисторы на Чипе - это потоковые процессоры, текстурные блоки, кэш, ROPы и еще там чего-то. Количество транзисторов влияет очень сильно на скорость прорисовки кадра, обработку треугольников из которых состоит объект вывода, сглаживание, освещение. А уже на втором месте стоит критерий частоты на которой работает Чип и память. Так вот видюха более старая но с набором логики из 7 млрд. транзисторов но с частотой Чипа 800 мгц за один плевок уделывает в тестах более современную видеокарту с чипом из 4 млрд. транзисторов, но работающую на частоте 1100 мгц.
Первые 3D-видеокарты появились 25 лет назад, и с тех пор их мощность и сложность выросли в таком масштабе, как ни один другой чип компьютера. В те времена графические процессоры были меньше 100 мм2 размером, имели около 1 миллиона транзисторов и потребляли всего несколько ватт энергии.
Сегодня же типичная видеокарта может иметь 14 миллиардов транзисторов на кристалле размером 500 мм2 и потреблять более 200 Вт энергии. Возможности этих бегемотов будут неизмеримо больше, чем у их древних предшественников, но стали ли они эффективнее со всеми этими транзисторами и ваттами энергии?
Сказка о Двух Числах
В этой статье мы рассмотрим, насколько хорошо разработчики GPU смогли воспользоваться увеличением размеров кристалла и энергопотребления, чтобы предложить нам больше вычислительной мощности. Прежде чем идти дальше, вы можете освежить в памяти устройство видеокарты или пройтись по истории современного GPU. С этой информацией вам будет легче ориентироваться.
Чтобы понять, как менялась эффективность графического процессора, и менялась ли вообще, мы использовали отличную базу данных TechPowerUp, выбрав образцы процессоров за период последних 14 лет. Такой период обусловлен тем, что именно 14 лет назад GPU перешли на унифицированную структуру шейдеров.
Вместо того чтобы выделять отдельные вычислительные блоки процессора для обработки треугольников и пикселей, унифицированные шейдеры являются арифметическими логическими единицами, предназначенными для любых вычислений, связанных с трехмерной графикой. Благодаря этому, мы можем последовательно замерить относительную производительность каждого GPU по параметру количества его операций с плавающей точкой в секунду (FLOPS – FLoating-point Operations Per Second).
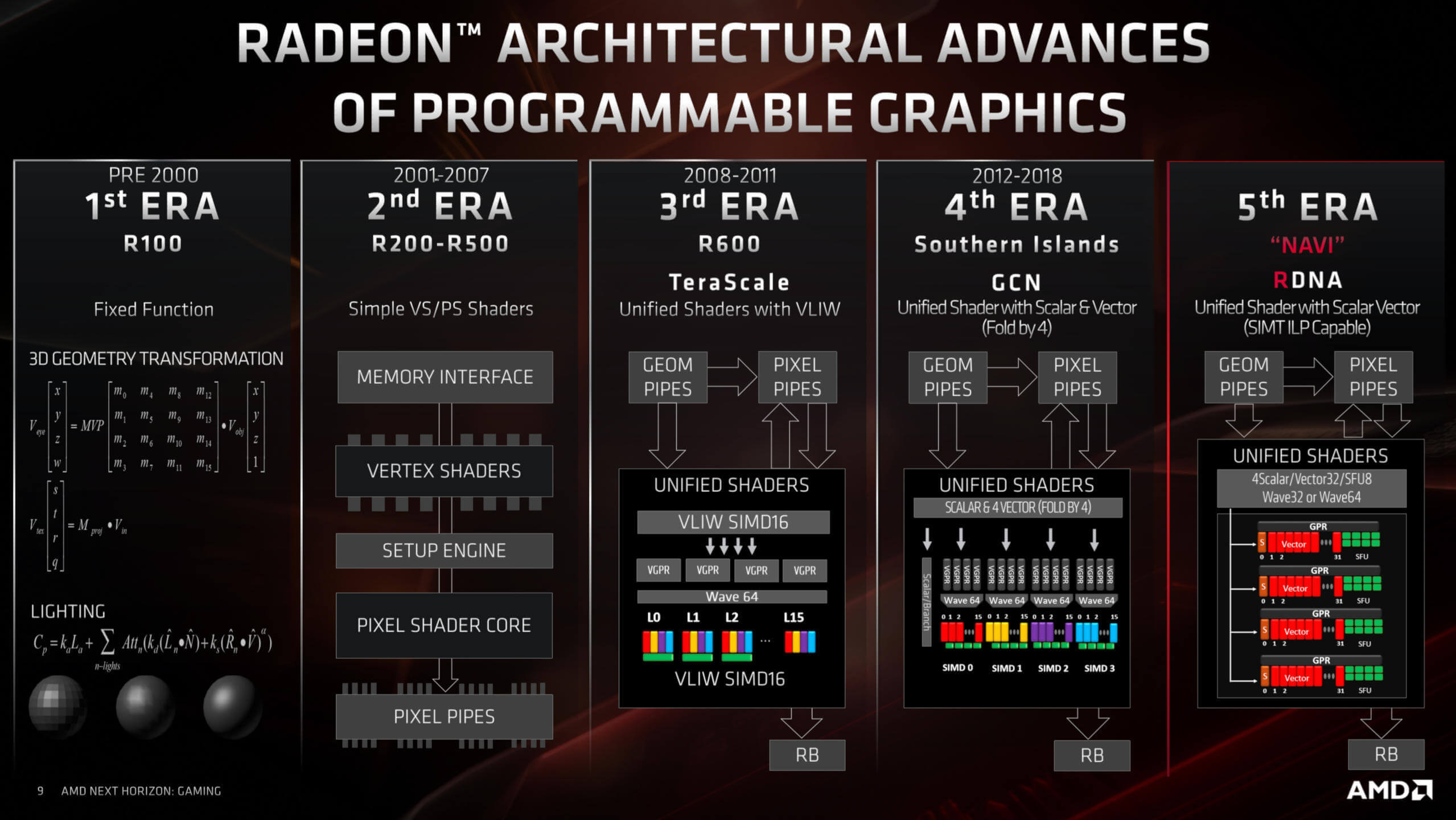
AMD использует унифицированную шейдерную архитектуру почти 12 лет
Вендоры часто стараются указывать значения FLOPS в качестве показателя максимальной производительности GPU. И хотя на самом деле это далеко не единственный показатель, определяющий скорость работы графического процессора, FLOPS дает нам цифры, с которыми мы можем работать.
То же касается и размеров кристалла, означающего рабочую площадь чипа. Однако чипы могут быть одинаковы по размеру, но сильно отличаться по количеству транзисторов.
Например, процессор Nvidia G71 (GeForce 7900 GT) 2005 года имеет размер 196 мм2 и имеет 278 миллионов транзисторов, а TU117, выпущенный в начале прошлого года (GeForce GTX 1650), всего лишь на 4 мм2 больше, но в нём 4,7 миллиарда этих маленьких переключателей.
Диаграмма основных GPU Nvidia, показывающая изменения в плотности транзисторов за последние годы
Естественно, из этого следует, что современные транзисторы намного меньше, чем в старых чипах, и это очень важно. Так называемый технологический процесс – общая разрешающая способность при изготовлении процессора, – используемый производителями оборудования, с годами менялся и постепенно становился все меньше и меньше. Поэтому мы проанализируем эффективность с точки зрения плотности кристалла, которая является мерой того, сколько миллионов транзисторов приходится на один мм2 площади кристалла.
Потребляемая кремниевыми чипами энергия действительно в основном превращается в тепло, но проблема использования TDP не в этом. Дело в том, что разные вендоры указывают это число при разных условиях, не обязательно во время пиковых FLOPS. Кроме того, это значение мощности для всей видеокарты в целом, включая встроенную память, а не только для основного её потребителя – собственно GPU. Можно измерить энергопотребление видеокарты напрямую, как это делали, например, TechPowerUp для своих обзоров GPU. Когда они тестировали GeForce RTX 2080 Super с заявленным производителем TDP 250 Вт, они обнаружили, что энергопотребление в среднем составило 243 Вт, и достигло максимума в 275 Вт во время тестирования.
Но всё-же мы решили учитывать показатель TDP в нашем анализе ради простоты и удобства, условившись весьма осторожно делать любые выводы касаемо производительности, основанные исключительно на её зависимости от номинальной тепловой мощности.
Сейчас мы проведем прямое сравнение по двум показателям: GFLOPS и плотность кристалла. Один GFLOPS равен 1000 миллионам операций с плавающей точкой в секунду, и мы имеем дело со значением для вычислений одинарной точности (FP32), выполняемых исключительно унифицированными шейдерами. Наше сравнение примет форму графика:
Ось X отображает GFLOPS на единицу TDP – чем больше, тем лучше. Чем меньше, тем нерациональней используется энергопотребление. То же справедливо для оси Y, где у нас GFLOPS на единицу плотности кристалла. Чем больше транзисторов удастся поместить на один квадратный мм, тем выше получится производительность. Таким образом, общая эффективность работы GPU (учитывая количество транзисторов, размер кристалла и TDP) возрастает по мере приближения к правому верхнему углу графика.
Все значения в районе верхнего левого угла в основном говорят о том, что «благодаря вычислительной мощности кристалла, этот GPU обеспечивает хорошую производительность, но за
счет использования относительно большого количества энергии». Идем к правому нижнему углу, и там у нас будут GPU, которые «очень энергоэффективные, но сравнительно слабенькие».
Короче говоря, мы оцениваем эффективность работы GPU исходя из его потребляемой мощности пропорционально количеству транзисторов.
Эффективность GPU: TDP vs количество транзисторов
Церемониться мы не будем, вот результаты:
Мы видим, что результаты довольно разбросанные, но имеют базовую закономерность: старые графические процессоры, такие как G80 или RV670, гораздо менее эффективны по сравнению с более современными решениями, такими как Vega 20 или GP102. Оно и понятно. В конце концов, чего бы стоили команды инженеров-электронщиков, изо всех сил старающихся постоянно создавать новые продукты, которые становились бы всё менее эффективными с каждым выпуском.
Но некоторые результаты представляют особый интерес. Прежде всего, это TU102 и GV100. Оба чипа сделаны Nvidia и используются в видеокартах GeForce RTX 2080 Ti и Titan V, соответственно.

Можно возразить, что ни один из них не был разработан для общепотребительского рынка. Особенно это касается GV100, поскольку он действительно предназначен для рабочих станций и вычислительных серверов. Поэтому, хотя они и являются самыми эффективными из всех процессоров, но они предназначены для специализированных рынков и стоят намного дороже стандартных.
Еще один GPU, который выделяется как белая ворона – это GP108. Этот чип от Nvidia чаще всего встречается в GeForce GT 1030 – недорогом продукте, выпущенном в 2017 году, и имеющем очень маленький размер. Процессор размером всего 74 мм2 с TDP всего 30 Вт. Однако его относительная производительность с плавающей точкой на самом деле не лучше, чем у Nvidia G80 – первого GPU с унифицированной шейдерной архитектурой (2006).

Графический процессор Nvidia G80. Источник
По другую сторону от GP108 находится чип AMD Fiji, который использовался в серии Radeon R9 Fury. Это получилось не слишком энергоэффективное решение, особенно учитывая, что использование HBM-памяти должно было помочь в этом отношении. Фиджи сильно греется, что плохо сказывается на экономичности полупроводников из-за возросшей утечки. Именно здесь потребляется электрическая энергия, а не в схеме как таковой. Все чипы имеют токи утечки, но с температурой скорость потерь увеличивается.
Но самым интересным моментом является, пожалуй, Navi 10. Это новейший GPU от AMD, производимый TSMC на их передовом 7-нм техпроцессе. В то же время, Vega 20 произведён на том же техпроцессе почти два года назад, но выглядит более эффективным. В чём же дело?

Под этими вентиляторами стоит GPU Vega 20. Источник
Vega 20 (AMD использовала его только в одной потребительской видеокарте – Radeon VII) был последним процессором, созданным AMD в архитектуре GCN (Graphics Core Next). Она объединяет огромное количество унифицированных шейдерных ядер в единый узел, в котором основное внимание уделено формату FP32. Однако программирование устройства для достижения этой производительности было нелегким делом, и ему не хватало гибкости.
Navi 10 использует новейшую архитектуру RDNA, которая решает эту проблему. Решение новое, созданное на относительно новом техпроцессе, поэтому можно ожидать повышения эффективности по мере того, как TSMC развивает свой техпроцесс, а AMD обновляет архитектуру.
Если брать во внимание только массовые продукты, то наиболее эффективные GPU на нашем графике – это GP102 и GP104. Это чипы Nvidia на архитектуре Pascal и мы найдём их в таких видеокартах как GeForce GTX 1080 Ti, GTX 1070 и GTX 1060. Рядом с GP102, не обозначенный меткой, расположился TU104. Это новейший Turing-чип от Nvidia, устанавливаемый в линейку GeForce RTX: 2060, 2070 Super, 2080, 2080 Super и многие другие.

Обзор и тестирование видеокарты MSI GeForce GTX 1080 Ti GAMING X TRIO
Они также изготовлены TSMC, но с использованием техпроцесса, специально разработанного для продуктов Nvidia, называемого 12FFN, который сам по себе является усовершенствованной версией 16FF.
Улучшения направлены на увеличение плотности кристалла при одновременном уменьшении утечек. Этим, возможно, объясняется то, что процессоры Nvidia выглядят более эффективными.
Эффективность GPU: TDP vs площадь кристалла
Если не учитывать техпроцесс, и вместо количества транзисторов на кристалле использовать в анализе лишь площадь кристалла, то мы увидим совершенно иную картину.

На этом графике эффективность увеличивается так же, но теперь мы видим, что некоторые ключевые позиции поменялись местами. TU102 и GV100 «осыпались», тогда как Navi 10 и Vega 20 подпрыгнули. Это связано с тем, что первые два процессора представляют собой огромные чипы (754 мм2 и 815 мм2), тогда как последние два от AMD намного меньше (251 мм2 и 331 мм2).
Оставим на графике только самые последние разработки, чтобы подчеркнуть различия:

Становится очевидным, что AMD пренебрегает энергоэффективностью в пользу уменьшения размеров кристалла.
Другими словами, AMD хотят получить больше GPU чипов с каждой произведённой кремниевой пластины, в то время как Nvidia, похоже, придерживается стратегии увеличения энергоэффективности каждого чипа в ущерб его размеру и, соответственно, стоимости изготовления (чем больше чип, тем меньше их можно разместить на одной пластине).
Продолжат ли AMD и Nvidia впредь следовать выбранным стратегиям? Первые уже заявили, что в RDNA 2.0 они намерены на 50% улучшить соотношение «производительность на ватт», поэтому мы ждём их новые GPU дальше справа, по нашему графику. А что насчет Nvidia?
А они, к сожалению, печально известны своей молчаливостью относительно своих планов. Но известно, что их новые процессоры будут производить TSMC и Samsung на том же техпроцессе, который использовался для Navi. Были некоторые заявления о том, что мы увидим значительное снижение энергопотребления, и в то же время большое увеличение количества унифицированных шейдеров. Поэтому, судя по всему, Nvidia также не нарушит тенденций на нашем графике.
Так как же повышалась эффективность GPU?
Вышесказанное довольно убедительно показало, что за прошедшие годы AMD и Nvidia повысили производительность на единицу плотности кристалла и на единицу TDP. Иногда рывки в производительности были впечатляющими.
Взять к примеру Nvidia G92 и TU102. Первый из них это сердце GeForce 8800 GT и 9800 GTX, на его кристалле площадью 324 мм2 размещено 754 миллиона транзисторов. Когда он появился в октябре 2007 года, он был высоко оценен за свою производительность и экономичность.
Через одиннадцать лет Nvidia предложила нам TU102 в виде GeForce RTX 2080 Ti. Этот процессор имеет почти 19 миллиардов транзисторов на площади 754 мм2 – то есть, в 25 раз больше микроскопических компонентов на поверхности, которая лишь в 2,3 раза больше.
Всё это не было бы возможным без усилий TSMC по совершенствованию своей производственной технологии. G92 в 8800 GT был построен на 65-нм техпроцессе, тогда как для производства новейшего TU102 используется специальный масштаб 12FFN. Названия этих методов производства на самом деле ничего не говорят нам о разнице между ними, но зато говорят показатели GPU. Плотность кристалла у нового процессора –24,67 миллиона транзисторов на мм2, тогда как у старого – 2,33 млн.
Более чем десятикратное увеличение плотности кристалла в основном и обуславливает огромную разницу в эффективности двух GPU. Меньшие логические блоки требуют меньше энергии для работы, а сокращение длины проводников между ними увеличивает и скорость обмена данными. Наряду с улучшением производства кремниевых чипов (уменьшение количества дефектов и совершенствование изоляции), всё это приводит к возможности работать на более высоких тактовых частотах при той же мощности, или наоборот – использовать меньшее энергопотребление при той же тактовой частоте.

Процессор AMD Vega 10 с двумя чипами HBM-памяти по 4 Гб слева.
Кстати о частотах. Давайте сравним RV670 от ноября 2007 года в Radeon HD 3870 с Vega 10 в Radeon RX Vega 64, выпущенной в августе 2017 года.
Первый имеет фиксированную тактовую частоту около 775 МГц, тогда как последний имеет как минимум три доступные частоты:
- 850 МГц – при обычной работе на компьютере, 2D-обработка.
- 1250 МГц – для сложных 3D-задач (базовая частота, «base clock»)
- 1550 МГц – для переменных легких/средних 3D-нагрузок («boost clock»)
Мы говорим «как минимум», потому что видеокарта динамически изменяет свою тактовую частоту и потребляемую мощность, между вышеуказанными значениями, в зависимости от текущей рабочей нагрузки и рабочей температуры. Это сегодня мы воспринимаем это как само собой разумеющееся, но 13 лет назад такого управления частотами просто не существовало. Оно, правда, никак не влияет на результаты наших анализов эффективности, поскольку мы брали только пиковую производительность обработки (т.е. на максимальных частотах), но оно влияет на оценку работы карты в глазах потребителя.
Но самым главным поводом постоянного повышения эффективности GPU в течение многих лет послужили изменения в использовании процессора как такового. В июне 2008 года лучшие суперкомпьютеры в мире были оснащены центральными процессорами от AMD, IBM и Intel; спустя одиннадцать лет к этой компании присоединился ещё один производитель: Nvidia.

Nvidia Tesla P100 с процессором GP100
Их процессоры GV100 и GP100 были разработаны почти исключительно для вычислительного сегмента рынка, в них заложено множество ключевых архитектурных функций, и многие из них очень похожи на CPU. Например, их внутренняя память (кэш) напоминает типичный серверный CPU:
- Регистровый файл (register file) на 1 SM = 256 кБ
- L0 кэш на 1 SM = 12 кБ инструкции
- L1 кэш на 1 SM = 128 кБ инструкции/данные
- L2 кэш на GPU = 6 МБ
Для сравнения: Intel Xeon E5-2692 v2, который использовался во многих вычислительных серверах:
- L1 кэш на ядро = 32 кБ инструкции/данные
- L2 кэш на ядро = 256 кБ
- L3 кэш на CPU = 30 МБ
Логические блоки внутри современного GPU поддерживают ряд форматов данных; некоторые имеют специализированные блоки для целочисленных вычислений, вычислений с плавающей точкой и матриц, в то время как другие имеют сложные структуры сразу для всех видов вычислений. Блоки соединены с кэшем и внутренней памятью широкими высокоскоростными интерконнектами. Безусловно, все эти нововведения положительно сказываются на обработке 3D-графики, но для большинства игр они избыточны. Но такие GPU разрабатывались не только для графики, а для более широкого спектра рабочих нагрузок, и для них есть специальное название: GPU общего назначения (GPGPU).
Machine Learning и Data Mining – это те две области, которые извлекли наибольшую выгоду из разработки GPGPU и поддерживаемых пакетов программного обеспечения и API (например, CUDA от Nvidia, FireStream от AMD, а также OpenCL), поскольку они объединяют в себе множество сложных массивно-параллельных вычислений.
Большие GPU, с тысячами унифицированных шейдерных блоков, идеально подходят для таких задач, и AMD с Nvidia (а теперь ещё и Intel присоединяется к их веселью) вкладывают миллиарды
долларов в разработку чипов, обеспечивающих все более высокую вычислительную производительность.

Первая дискретная видеокарта Intel за последние 20 лет. Превью видеокарт Intel Xe, часть 2
На данный момент обе компании разрабатывают универсальные архитектуры для своих GPU, которые могут использоваться в различных секторах рынка, как правило избегая создания полностью специфичных решений отдельно для графики и отдельно для вычислений. Это связано с тем, что основная часть прибыли от производства GPU по-прежнему поступает от продажи 3D-видеокарт, но уже неясно, сохранится ли такое положение дел в дальнейшем. Поскольку спрос на compute-мощности продолжает расти, вполне возможно, что AMD или Nvidia начнут выделять больше своих ресурсов на повышение эффективности чипов для этих рынков и меньше – на рендеринг.
Но что бы ни случилось дальше, мы знаем одно: на следующем этапе высокопроизводительные GPU с миллиардами транзисторов по-прежнему будут чуточку эффективнее своих предшественников. И это хорошая новость, независимо от того, кто это делает и для чего.
Продолжая историю развития видеокарт из предыдущей — статьи, видеоадаптеры 2000-х годов.
VSA-100 и новое поколение Voodoo

Видеокарта выпускалась с разными интерфейсами, такими, как AGP, PCI и т.д. Также была доступна версия под Macintosh, имеющая два разъема (DVI и VGA).

Осенью того же года 3dfx выпустила Voodoo4 4500 с объемом памяти 32 Мб, использовавшей один чип VSA-100. Модель оказалась довольно медленной и значительно уступала GeForce 2 MX и Radeon SDR.
Компания 3Dfx анонсировала выход производительной видеокарты Voodoo5 6000 на 4-х чипах VSA-100 и с 128 Мб памяти. Но окончательно реализовать проект так и не удалось — серьезные финансовые трудности обанкротили 3Dfx.
GeForce 2

В 2000-2001 годах компания NVIDIA выпустила серию видеокарт GeForce 2 (GTS, Ultra, Pro, MX и т. д.). У этих видеоадаптеров было 256-битное ядро — одно из самых производительных ядер того времени.
Radeon DDR и SDR
Компания ATI не отставала от прогресса и в 2000 году выпустила процессор Radeon R100 (изначально назывался Rage 6). Он изготавливался по 180-нм техпроцессу и поддерживал технологию ATI HyperZ.
На основе R100 вышли видеокарты Radeon DDR и SDR.

Упрощенная версия SDR отличалась от Radeon DDR типом используемой памяти и пониженными частотами (166 МГц). Объем памяти у Radeon SDR предоставлялся только на 32 Мб.
Radeon 8500 и Radeon 7500
В 2001 году на базе RV200 вышли два чипа Radeon 8500 и Radeon 7500.


Radeon 7500 изготавливался по тому же 150-нм техпроцессу, но с 30 миллионами транзисторов. Ядро работало на частоте 290 МГц, а память на 230 МГц. Пиксельных конвейеров было 2.
GeForce 3

Устройство поддерживало nFinite FX Engine, позволяющие создавать огромное количество различных спецэффектов. Была улучшенная архитектура памяти LMA (Lightspeed Memory Architecture).
Линейка видеокарт состояла из модификаций GeForce 3, GeForce 3 Ti 200 и Ti 500. Они отличались по тактовой частоте, производительности и пропускной способности памяти.

У GeForce 3 Ti 200: 175 МГц ядро, 200 МГц память; 700 миллиардов операций/сек; 6,4 Гб/с пропускная способность.

У GeForce 3 Ti 500: 240 МГц ядро и 250 МГц память; 960 миллиардов операций/сек; 8,0 Гб/с пропускная способность.
GeForce 4
Следующей видеокартой компании NVIDIA стала GeForce 4, которая вышла в 2002 году. C таким названием выпускались два типа графических карт: высокопроизводительные Ti (Titanium) и бюджетные MX.


Radeon 9700 Pro

Летом 2002 года ATI выпустила чип R300, который изготавливался по 150-нм техпроцессу и содержал около 110 миллионов транзисторов. У него было 8 пиксельных конвейеров. Также чип поддерживал улучшенные методы сглаживания.
На базе R300 вышла видеокарта Radeon 9700 с тактовыми частотами ядра 325 МГц и памяти 310 МГц. Объем памяти составлял 128 Мб. Шина памяти была 256-битная DDR.
В начале 2003 года Radeon 9700 сменила видеокарта Radeon 9800. Новые решения были построены на чипе R350, с увеличением тактовых частот и доработкой шейдерных блоков, контроллера памяти.
GeForce FX

GeForce FX была представлена в разных модификациях: еntry-level (5200, 5300, 5500), mid-range (5600, 5700, 5750), high-end (5800, 5900, 5950), еnthusiast (5800 Ultra, 5900 Ultra, 5950 Ultra). Использовалась шина на 126-бит и на 256-бит.

На базе NV30 было создано топовое устройство нового поколения — видеокарта GeForce FX 5800. Объем видеопамяти достигал 256 Мб, частота ядра — 400 МГц, а памяти — 800 МГц. В 5800 Ultra частота ядра повысилась до 500 МГц, а памяти — до 1000 МГц. Первые карты на основе NV30 оснащались инновационной системой охлаждения.
GeForce 6 Series

Развитие видеокарт активно продолжалось и в 2004 году вышел следующий продукт компании — GeForce 6 Series (кодовое название NV40).
Чип NV40 производился также по 130-нм техпроцессу, что не помешало ему стать более экономичным. Модификация пиксельных конвейеров дала возможность обрабатывать до 16 пикселей за такт. Всего было 16 пиксельных конвейеров. Видеокарты поддерживали пиксельные и вершинные шейдеры версии 3.0, технологию UltraShadow (прорисовка теней). Кроме этого, GeForce 6 Series с помощью технологии PureVideo декодировали видео форматов H.264, VC-1 и MPEG-2. NV40 работал через 256-битную шину, при этом использовались очень быстрые модули памяти типа GDDR3.
Одна из первых моделей, видеокарта GeForce 6800 была весьма производительной и тянула самые новые игры того времени. Она работала как через интерфейс AGP, так и через шину PCI Express. Частота ядра составляла 325 МГц, а частота памяти была 700 МГц. Объем памяти доходил 256 Мб или 512 Мб.
Radeon X800 XT

Компания ATI находилась в более выгодном положении. В 2004 году компания представила 130-нм чип R420 (усовершенствованная версия R300). Пиксельные конвейеры были разделены на четыре блока по четыре конвейера в каждом (в сумме 16 пиксельных конвейеров). Увеличилось до 6 количество вершинных конвейеров. Поскольку R420 не поддерживал работу шейдеров третьего поколения, он работал с обновленной технологией HyperZ HD.
Самая мощная и производительная видеокарта новой линейки Radeon была X800 XT. Карта оснащалась памятью типа GDDR3 объёмом 256 Mб и разрядностью шины 256-бит. Частота работы достигала 520 МГц по ядру и 560 МГц по памяти. Radeon X800 XT продавались в двух исполнениях: AGP и PCI Express. Помимо обычной версии существовал Radeon X800 XT Platinum Edition, обладающий более высокими частотами чипа и памяти.
GeForce 7800 GTX

В 2005 году вышел чип G70, который лег в основу видеокарт серии GeForce 7800. Количество транзисторов увеличилось до 302 миллионов.
Вдвое увеличилось количество пиксельных конвейеров — до 24 штук. В каждый конвейер были добавлены дополнительные блоки ALU, отвечающие за обработку наиболее популярных пиксельных шейдеров. Таким образом возросла производительность чипа в играх, делающих упор на производительность пиксельных процессоров.
GeForce 7800 GTX стала первой видеокартой на базе G70. Частота ядра составляла 430 МГц, памяти — 600 МГц. Использовалась быстрая GDDR3, а также 256-битная шина. Объем памяти составлял 256 Мб или 512 Мб. GeForce 7800 GTX работала исключительно через интерфейс PCI Express х16, который окончательно начал вытеснять устаревающий AGP.
GeForce 7950 GX2

Событием 2006 года для компании NVIDIA стал выпуск первой двухчиповой видеокарты GeForce 7950, созданной по 90-нм техпроцессу.Nvidia 7950 GX2 имела по одному чипу G71 на каждой из плат. Ядра видеокарты работали на частоте 500 МГц, память — на частоте 600 МГц. Объем видеопамяти типа GDDR3 составлял 1 Гб (по 512 Мб на каждый чип), шина 256-бит.
В новой карте было оптимизировано энергопотребление и доработана система охлаждения. Выпуск 7950 GX2 стал началом развития технологии Quad SLI, позволяющей одновременно использовать мощности нескольких видеокарт для обработки трёхмерного изображения.
Radeon X1800 XT, X1900

На базе R520 была разработана видеокарта Radeon X1800 XT. Карта оснащалась памятью типа GDDR3 объемом 256 Мб или 512 Mб, работающей на частоте 750 МГц. Использовалась 256-битная шина.

Видеокарты Radeon X1800 XT недолго пробыли на рынке. Вскоре им на смену пришли адаптеры серии Radeon X1900 XTХ на базе чипа R580. Процессором полностью поддерживались на аппаратном уровне спецификации SM 3.0 (DirectX 9.0c) и HDR-блендинг в формате FP16 с возможностью совместного использования MSAA. В новом чипе было увеличено количество пиксельных конвейеров — до 48. Частоты ядра составляла 650 МГц, а памяти — 775 МГц.
Еще через полгода вышел чип R580+ с новым контроллером памяти, работающий со стандартом GDDR4. Частота памяти была увеличена до 2000 МГц, при этом шина оставалась 256-битной. Основные характеристики чипа остались прежними: 48 пиксельных конвейеров, 16 текстурных и 8 вершинных конвейеров. Частота ядра составляла 625 МГц, памяти было больше — 900 МГц.
GeForce 8800 GTX

В 2006 году на базе процессора G80 было выпущено несколько видеокарт, самой мощной из которых являлась GeForce 8800 GTX. G80 был одним из самых сложных существующих чипом того времени. Он выпускался по 90-нм техпроцессу и содержал 681 миллион транзисторов. Ядро работало на частоте 575 МГц, память — на частоте 900 МГц. Частота унифицированных шейдерных блоков составляла 1350 МГц. У GeForce 8800 GTX было 768 Мб видеопамяти GDDR3, а ширина шины составляла 384-бит. Поддерживались новые методы сглаживания, которые позволили блокам ROP работать с HDR-светом в режиме MSAA (Multisample anti-aliasing). Получила развитие технология PureVideo.
Архитектура GeForce 8800 GTX оказалась особенно эффективной и на протяжении нескольких лет являлась одной из самых быстрых видеокарт.
Radeon HD2900 XT, HD 3870 и HD 3850

В 2007 года была представлена флагманская видеокарта Radeon HD2900 XT на базе чипа R600. Частота ядра видеокарты составляла 740 МГц, памяти GDDR4 — 825 МГц. Использовалась 512-битная шина памяти. Объем видеопамяти достигал 512 Мб и 1 Гб.
Более успешной разработкой вышел процессор RV670, выпущенный в том же году. Архитектурой он почти не отличался от предшественника, но изготавливался по 55-нм техпроцессу и с шиной памяти 256-бит. Появилась поддержка DirectX 10.1 и Shader Model 4.1. На базе процессора производились видеокарты Radeon HD 3870 (частота ядра 775 МГц, памяти 1125 МГц) и Radeon HD 3850 (частота ядра 670 МГц, памяти 828 МГц) с объемом видеопамяти 256 Мб и 512 Мб и шиной 256-бит.
GeForce 9800

Чип G92 лег в основу GeForce 9800 GTX — одной из самых быстрых и доступных видеокарт. Он изготавливался по 65-нм техпроцессу. Частота ядра составляла 675 МГц, частота памяти — 1100 МГц, а шина — 256-бит. Объем памяти предлагался в двух вариантах: на 512 Мб и на 1 Гб. Чуть позже появилась модель GTX+, которая отличалась 55-нм техпроцессом и частотой ядра — 738 МГц.
В данной линейке также появилась очередная двухчиповая видеокарта GeForce 9800 GX2. Каждый из процессоров имел спецификации, как у GeForce 8800 GTS 512 Мб, только с разными частотами.
GeForce GTX 280 и GTX 260

В 2008 году компания NVIDIA выпустила чип GT200, который использовался в видеокартах GeForce GTX 280 и GTX 260. Чип производился по 65-нм техпроцессу и содержал 1,4 миллиарда транзисторов, обладал 32 ROP и 80 текстурными блоками. Шина памяти увеличилась до 512-бит. Также была добавлена поддержка физического движка PhysX и платформы CUDA. Частота ядра видеокарты составляла 602 МГц, а памяти типа GDDR3 — 1107 МГц.

Radeon HD 4870

Старшая видеокарта новой линейки получила название Radeon HD 4870. Частота ядра составляла 750 МГц, а память работала на эффективной частоте 3600 МГц. С новой линейкой видеокарт компания продолжила свою новую политику выпуска устройств, которые могли успешно конкурировать в Middle-End-сегменте. Так, Radeon HD 4870 стал достойным конкурентом видеокарты GeForce GTX 260. А место лидера линейки HD 4000 вскоре заняло очередное двухчиповое решение Radeon HD 4870X2. Сама архитектура видеокарты соответствовала таковой у Radeon HD 3870X2, не считая наличия интерфейса Sideport, напрямую связывающего два ядра для наиболее быстрого обмена информацией.
GeForce GTX 480

В 2010 году NVIDIA представила GF100 с архитектурой Fermi, который лег в основу видеокарты GeForce GTX 480. GF100 производился по 40-нм техпроцессу и получил 512 потоковых процессоров. Частота ядра была 700 МГц, а памяти — 1848 МГц. Ширина шины составила 384-бит. Объем видеопамяти GDDR5 достигал 1,5 Гб.
Чипом GF100 поддерживались DirectX 11 и Shader Model 5.0, а также новая технология NVIDIA Surround, позволяющая развернуть приложения на три экрана, создавая тем самым эффект полного погружения.
Чипы Cypress и Cayman

Компания AMD выпустила 40-нм чип Cypress. Разработчики компании решили поменять подход и не использовать исключительно буквенно-цифровые значения. Поколению чипов начали присваивать собственные имена. Сам принцип архитектуры Cypress продолжал идеи RV770, но дизайн был переработан. Вдвое увеличилось количество потоковых процессоров, текстурных модулей и блоков ROP. Появилась поддержка DirectX 11 и Shader Model 5.0. В Cypress появились новые методы сжатия текстур, которые позволили разработчикам использовать большие по объему текстуры. Также AMD представила новую технологию Eyefinity, полным аналогом которой позже стала технология NVIDIA Surround.
Чип Cypress был реализован в серии видеокарт Radeon HD 5000. Вскоре AMD выпустила и двухчиповое решение Radeon HD 5970. В целом Cypress оказался очень успешным.

Серия видеокарт Radeon HD 6000, выпущенная в конце 2010 года, была призвана конкурировать с акселераторами GeForce GTX 500. В основе графических адаптеров лежал чип Cayman. В нем применялась немного другая архитектура VLIW4. Количество потоковых процессоров составляло 1536 штук. Возросло количество текстурных модулей — их стало 96. Также Cayman умел работать с новым алгоритмом сглаживания Enhanced Quality AA. Ширина шины памяти чипа составляла 256-бит. Видеокарты использовали GDDR5-память.
GeForce GTX 680

В 2013 года компания представила чип GK110, на котором основываются флагманские видеокарты GeForce GTX 780 и GeForce GTX Titan. Использовалась шина 384-бит GDDR5, а объем памяти повысился до 6 Гб.
Производительность ПК во многом зависит от видеокарты. Просмотр видео в высоком качестве, поддержка современных тяжеловесных геймов возможны при условии правильно выбранной видеокарты. В процессорах сейчас есть встроенные видеокарты, но их мощности не хватает для осуществления множества действий: поддержка изображения в формате 4К, использование технологии виртуальной реальности, 3D программ. Прежде чем купить графический адаптер, необходимо научиться разбираться в основных его параметрах.
Производители видеокарт
Есть два главных бренда, графические адаптеры которых пользуются наибольшей популярностью. Это AMD и NVIDIA. Эти компании делают лишь видеочипы для адаптеров, ведь на разработку дизайна уходит слишком много времени. Поэтому сначала для пользователей доступны референсные версии графических адаптеров. Далее другие компании вносят свою лепту в создание готовой видеокарты: меняют дизайн, разгоняют устройство, модернизируют систему охлаждения. Получившийся продукт называют кастомным графическим адаптером.
Вопрос о том, какой производитель лучше, до сих пор не решен в чью-то пользу. Продукция обеих компаний имеет свои преимущества и недостатки. У AMD видеокарты менее дорогие, при этом можно подобрать модель с хорошим уровнем производительности. Хотя очень часто наблюдаются проблемы с перегревом устройств. Компания NVIDIA производит высокотехнологичные устройства с мощными параметрами, но цены на них немного выше.
Определиться с выбором кастомных моделей ещё труднее. Компании стараются модернизировать дизайн, улучшить систему охлаждения, используют подсветку и другие фишки, чтобы выделиться среди конкурентов. Поэтому сложно определить одного производителя. Однако можно обратить внимание на ASUS, Gigabyte и MSI. Именно их продукция отличается высоким качеством.
Совместимость с блоком питания
Некоторые модели отличаются низким уровнем потребления электроэнергии, но многие современные мощные видеокарты потребляют много энергии. Поэтому устройство должно подойти по этим характеристикам к блоку питания. Производителем обязательно указываются требования к блоку питания, которые можно найти в характеристиках. Поэтому нужно заранее изучить параметры своего компьютера.
Ряд графических адаптеров имеют разъемы 6 pin и 8 pin. Для них можно купить специальные переходники, если блок питания не имеет такого коннектора.
Многие видеокарты отличаются большими размерами, особенно геймерские и оверклокерские устройства. Поэтому в процессоре должно хватать места для размещения адаптера. Стоит учитывать и размеры охлаждающей системы, если такая есть у видеокарты. Размеры ее также можно посмотреть в характеристиках, где указано длина, высота, ширина. Иногда эти параметры указываются отдельно для печатной платы и для платы уже вместе с кулером.
Основные характеристики видеопамяти
Объем видеопамяти является для многих первым критерием, по которому выбирается графический адаптер. И это неспроста, ведь именно благодаря данному параметру можно понять насколько хорошо покажет себя устройство в видеоиграх. Но на мощность видеоадаптера влияют и другие параметры, например, пиковая частота, разрядность шины памяти.
И всё же объем также влияет на удобство эксплуатации. Для реализации всех целей вполне хватает 4-8 Гб видеопамяти. Можно будет наслаждаться современными играми на высоких настройках.
Внимание стоит обратить и на тип памяти. DDR3 сейчас используется для стандартных офисных видеокарт. На игровых устройствах и топовых высокопроизводительных графических адаптерах обычно применяется тип памяти DDR5. Первый и второй вариант отличаются пропускной способностью информации, поступающей от видеоядра. Во втором случае показатель значительно выше, что положительно отражается на производительности видеокарты. Улучшенной версией DDR5 является память DDR5X, которой уже оснащены некоторые новинки. Есть тип памяти HBM, который из-за ограниченного объема не получил большого распространения.
Тактовые частоты
Каждый производитель старается максимально увеличить показатели тактовой частоты видеокарты, поскольку чем она больше, тем лучше устройство покажет себя в играх. Данный параметр больше влияет на производительность, чем перечисленные выше. В характеристиках важно обратить внимание на базовую и динамическую тактовые частоты. Среднее значение для GPU находится в пределах 900-1100 МГц. При таких показателях удается получить хорошую производительность видеокарты.
Система охлаждения и отвод тепла
Некоторые модели оснащены системой охлаждения, а некоторые требуют дополнительного оборудования для снижения температуры устройства. При перегреве GPU может быстро выйти из строя, да и на производительности это скажется не лучшим образом. Обычно устанавливаемых производителем элементов для охлаждения оказывается достаточно, что особенно касается фирм ASUS, Gigabyte и MSI. Эти компании отличаются созданием прекрасных систем охлаждения. Многие пользователи предпочитают устанавливать систему водного охлаждения, но это крайне редко бывает необходимо. Установкой таких устройств чаще всего занимаются оверклокеры.
GPU ASUS, Gigabyte и MSI оборудованы одним, двумя или тремя вентиляторами с диаметром от 90 до 120 мм. В большинстве моделей в режиме бездействия вентиляторы отключаются. Но не только хорошие кулеры должны быть на видеокарте. Конструкция ее должна быть разработана таким образом, чтобы обеспечить правильную циркуляцию воздуха. Тогда перегрев удастся избежать. Кстати, в характеристиках производители обычно указывают максимальную температуру видеокарты.
Техпроцесс и графический чип
На производительность влияет количество транзисторов, которые находятся на кристалле. Чем они меньше по размеру, тем больше их удается на нем разместить. А с увеличением числа транзисторов возрастает показатель тактовой частоты и снижается уровень энергопотребления. Техпроцесс отображает размер транзистора, то есть чем показатель меньше, тем больше их в видеокарте. Ну и число транзисторов также зависит от размеров кристалла. Раньше нормальным считался показатель технического процесса 28 нм и 20 нм. Но сейчас многие GPU имеют техпроцесс 16 нм и 14 нм.
Но этот параметр отражается не только на производительности. Техпроцесс 20 нм сильно ограничивал возможности игр с технологией виртуальной реальности, а современный техпроцесс оптимизирован под новые игры
SLI/Crossfire
В характеристиках видеокарты будет указано поддерживает ли она технологию SLI или Crossfire. Это по своей сути одинаковые технологии, которые были разработаны разными производителями. Первая - компанией Nvidia для серии GeForce, а вторая - компанией АМD для своих графических адаптеров Radeon. Цель разработки таких технологий в возможности установки от двух до четырех одинаковых моделей GPU на ПК. При их совмещении удается добиться максимальной мощности. Это идеальный вариант для игроманов, которые хотят прочувствовать всю красоту 3D игр. Но не каждая модель вышеназванных серий имеет такую возможность. Если это важный фактор, то следует обратить внимание на поддержку данной технологии.
Но кроме того, что эта технология должна быть доступна для графического адаптера, ее также должна суметь реализовать материнская плата. И кроме того у неё должно быть требуемое количество слотов PCI-Express. Вся информация об этом содержится в параметрах к материнской плате. Также важно знать, что не каждая игра поддерживает больше одного графического процессора, поэтому установка двух, трёх и более не всегда целесообразна.
Почему важен API и что это такое
API – это интерфейс прикладного программирования. Разработчики игр пишут их на определенном интерфейсе Application Programming Interface. Если графический процессор не поддерживает интерфейс, на котором разработана игра, то последняя на компьютере не запустится. Современные GPU поддерживают все основные интерфейсы АПИ. Самыми распространенными интерфейсами являются OpenGL и DirectX. В последнее время многие выпускаемые новинки поддерживают Vulcan, который часто в последнее время используется для создания игр. Vulcan отличается уменьшенной нагрузкой на ЦП. Игры с таким интерфейсом на современных GPU имеют гораздо большую производительность.
Вывод
Выбирая видеокарту нужно определиться со стоимостью, которая является оптимальной. Далее можно рассмотреть несколько моделей видеокарт разных производителей, серий, находящихся в одинаковом ценовом диапазоне. При их сравнении нужно обратить внимание на вышеперечисленные параметры. Важно не выбирать графический адаптер основываясь лишь на количестве памяти, поскольку нужно учитывать ещё и битность шины (не менее 128 бит). Нужно смотреть не на отдельные показатели, а на то, что они представляют из себя в совокупности.
В заключении можно сказать, что устройства от Nvidia отличаются лучшей производительностью и надежностью. Также это оперативно выпускаемые драйвера. AMD - это немного сниженные показатели производительности, но гораздо более приятные цены.
Читайте также: