
1с как уменьшить когнитивную сложность
Обновлено: 06.07.2024
Коллеги, подскажите пожалуйста способы, которыми можно уменьшить когнитивную сложность метода, средствами Java 8
Хотелось бы какое то элегантное решение, может быть предикатами или лямбдами переделать. Есть какие идеи ?
HAX>Коллеги, подскажите пожалуйста способы, которыми можно уменьшить когнитивную сложность метода, средствами Java 8
HAX>Хотелось бы какое то элегантное решение, может быть предикатами или лямбдами переделать. Есть какие идеи ?
Зачем тут лямбды?
Вынести request.getColumns() в локальную переменную наружу цикла.
Тело цикла вынести в отдельный метод.
Строчку формирования List<String> products вынести в отдельный метод.
formatDate вынести в отедьный сервис и туда заинжектить зависимости zoneId/dateFormat, чтобы не приходилось повсюду отдельно протаскивать эти параметры.
Здравствуйте, HAXT, Вы писали:
HAX>Коллеги, подскажите пожалуйста способы, которыми можно уменьшить когнитивную сложность метода, средствами Java 8
HAX>Хотелось бы какое то элегантное решение, может быть предикатами или лямбдами переделать. Есть какие идеи ?
Сильно лучше тут не сделать.
Но:
Я бы сделал extract method того, что внутри цикла. И этот метод бы принимал columns и IndexedDraftOrderDto, а возвращал набор строк, которые добавляются в csvBuilder. Было бы немножко почище, основное мясо бы уже имело поменьше зависимостей и было бы покомпактней. То, что внутри if, возможно бы тоже выделил в методы отдельного класса extractors или convertors, скорее всего статические. И к ним комментарии почему именно так и далее на эти экстракторы можно отдельно тесты писать.
И дополнительно — мне не очень понравилось черти сколько аргументов метода, я бы постарался рефакторнуть даже уровнем выше.
Соответственно в соответствии с SRP выделил бы отдельно:
1) extractor или трансформаторы для каждого варианта столбца;
2) трансформатор для строки целиком
3) трансформатор для всех строк целиком в удобное для преобразования в csv представление. И далее это представление можно реюзать для записи не в CSV, в в другую таблицу, в excel, в Json, в xml — куда угодно. Хоть это сейчас и не надо — но может быть полезно.
4) собственно генератор csv
Но это ИМХО, именно мой вкус — я очень не люблю логику внутри for и когда что то нетривиальное внутри if. Начитался в свое время Макконела на свою голову и выработал привычку, делаю такое на автомате даже не задумываясь. А сам метод не такой уж и монструозный чтоб сильно заморачиваться чем то еще.
Здравствуйте, HAXT, Вы писали:
HAX>Коллеги, подскажите пожалуйста способы, которыми можно уменьшить когнитивную сложность метода, средствами Java 8
Оборачивать всё это дело в лямбды, думаю, не всегда удачная идея. Помимо накладных расходов на конструирование лямбд и их вызов, теряется гибкость в использовании операторов типа if/else, for и т.д. В своих проектах иногда использую следующую конструкцию:
| Скрытый текст |
То есть, если в некой конфигурации установлены флаги "foo" и "bar", но не "baz", вывод будет следующим:
В этой статье я бы хотел поделиться простой и практической рекомендацией о том, как программистам перестать спорить о качестве кода, а вместо этого аргументированно доказывать необходимость рефакторинга, упрощения, добавления комментариев и документации к коду. Автору никто "не заносил", но в статье я укажу на конкретный инструмент статического анализа кода, который поможет в этом, благо он бесплатный.
Цель этой статьи: рассказать не об инструменте, а о метрике, о которой пока написано и рассказано совсем немного. Уверен, что это поможет улучшить качество многих проектов и немного облегчит жизнь программистов.
Самодокументированный код
Когда мы просим программистов предоставить документацию к своему коду, или хотя бы дописать комментарии, очень часто в ответ слышится что-то вроде:
«Читай код, там всё написано»
Очень многие программисты считают свой код самодокументированным автоматически, как бы по-умолчанию.
По определению, самодокументированный код — это код, спроектированный (designed) и написанный (implemented) таким образом, что он не требует дополнительной отдельной документации. Из определения следует, что нужно применить специальные навыки проектирования (design) и потратить дополнительные усилия, чтобы этого достичь. На практике же оказывается, что самодокументированный код – это сложная задача проектирования.
Почему это так? Давайте посмотрим на то, как мы вникаем в чужой код. Сильно упростив, этот процесс можно разбить на две важные части:
Сначала нам нужно узнать, что код должен вообще делать, какова конечная задача и цель? Мы пытаем собрать некоторые знания о проекте, или части проекта, и о решаемой задачи. Как правило, для этого мы "ходим" по тикетам, опрашиваем коллег, и выясняем ЧТО нужно сделать (а особенно опытные коллеги ещё и выясняют ПОЧЕМУ).
Зная это, мы начинаем читать код и выяснять КАК именно он выполняет поставленную задачу.
Иначе говоря, читая код, мы узнаем, КАК задача решена, а не ЧТО за задача была поставлена (или ПОЧЕМУ). Узнать какую задачу код решает тоже можно, но чтобы это перестало быть предположением, вам нужно будет потратить очень много усилий (например, запустить, протестировать, и т.д.).
Некоторые утверждают, что языки вроде SQL и HTML отвечают на оба вопроса сразу. Это может быть и так, но я позволю себе это утверждение проигнорировать, так как в статье речь больше идёт о компилируемых general-purpose языках.
Программисту, читающему код, нужно "распутать ниточку", понять какую именно задачу решает код. Это принято называть "ментальной моделью решаемой проблемы". Даже если код написан откровенно плохо, быстро, без применения каких-либо специальных навыков проектирования, в нём всё равно есть какая-то задумка автора, ментальная модель. Это может быть доменная модель (если вы применяете Domain Driven Design), или же либо другой способ отражения мыслительного процесса программиста.
На хабре ранее было несколько статей о том, что такое самодокументированный код и даны конкретные рекомендации по его написанию (например, вот, вот и вот). Правильные комментарии (описывающие «ЧТО» или «ПОЧЕМУ», а не очевидное «КАК»), правильно использованные конструкции языка, чистый код – всё это также важные характеристики самодокументированного кода. Но если суммировать, то единственный способ писать самодокументированный код – это писать такой код, который в большей мере раскрывает детали модели проблемы и при этом скрывает несущественные детали имплементации.
К сожалению, зачастую происходит наоборот: детали имплементации выпячиваются наружу (например то, какая база данных применяется, протокол коммуникации, технология отображения на UI, и т.д.), не давая читателю понять, что же конкретно мы пытаемся достичь.
Ментальная модель отвечает на вопрос «ЧТО?» (то есть, какая задача, цель, почему код писали), а сам код отвечает на вопрос «КАК?».

Измеряем читаемость кода
Фредерик Брукс, автор всемирно известной книги «Мифический человеко-месяц», в своём фундаментальном труде No Silver Bullet – Essence and Accident in Software Engineering) выделил два типа сложности в программном обеспечении:
Essential complexity – необходимая сложность, которая определяется самой проблемой и никак не может быть удалена.
Accidental complexity – непреднамеренная сложность, которая добавляется программистами во время проектирования и написания кода, и которая самими программистами и может быть устранена или хотя бы достаточно снижена.
Оказывается, мы уже научились измерять непреднамеренную сложность.
В 1976 году была изобретена метрика цикломатической сложности кода (Cyclomatic Complexity). К сожалению, эта метрика тесно связана со строками кода, и поэтому хорошо помогает нам в подсчёте покрытия кода тестами, но никак не помогает узнать о сложности кода. Проиллюстрирую проблему на примере:

Пример подсчёта цикломатической сложности кода
Как видите, с точки зрения программиста, пример кода слева гораздо сложнее понять, чем код справа. Однако, величина метрики эквивалентна. Вероятно, код слева ищет сумму всех простых чисел до некоторого указанного максимального числа. Задача хорошо известна, но представьте что этот код решает не такую широкоизвестную проблему. Вам нужно будет ещё проверить, что код действительно верный:
Действительно ли название метода совпадает с поставленной задачей?
Действительно ли он решает задачу?
Какие ограничения у этого кода?
В 2017 году компания Sonar Source изобрела новую метрику под названием Cognitive Complexity. Как видно из примера ниже, она отлично решает поставленную задачу, явно указывая на сильно большую сложность кода слева.

Пример подсчёта когнитивной сложности кода
О деталях реализации этой метрики отлично описано в документе, а также сам автор метрики об этом рассказывает на youtube. Если коротко, метрика основана на трех простых правилах:
Игнорировать структуры языков программирования, позволяющих сокращать написание кода и делать его более читаемым (это касается обновлённого синтаксиса любого из языков).
Увеличивать метрику на единицу для каждого оператора, прерывающего поток исполнения кода
a. Циклические конструкции for, while, do while, .
Увеличивать метрику на единицу в случае вложенных (nested) конструкций
Как известно, компания Sonar Source производит статические анализаторы кода, вроде SonarQube и SonarCloud, а также расширения для IDE, позволяющие более быстро получить метрики о коде. И важно то, что все эти инструменты доступны и в бесплатных версиях.
В Sonar Cloud найти эту метрику можно так: Project -> Issues -> Rules -> Cognitive Complexity
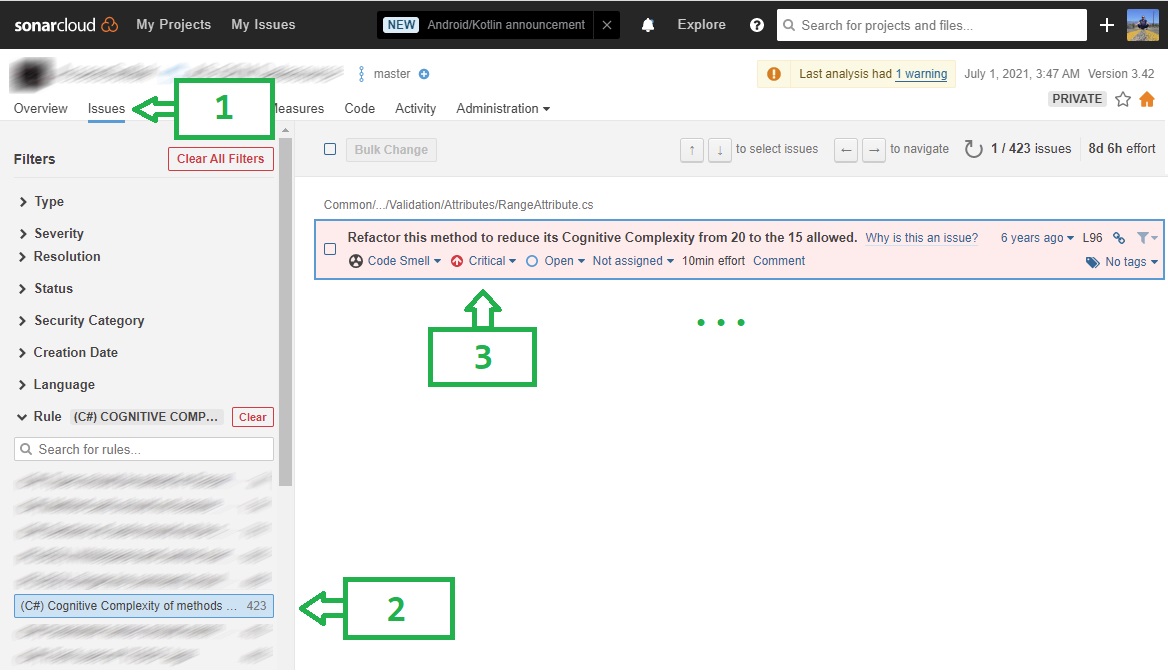
Как найти метрику Cognitive Complexity
А вот как выглядит детальный отчет на командном портале SonarCloud:
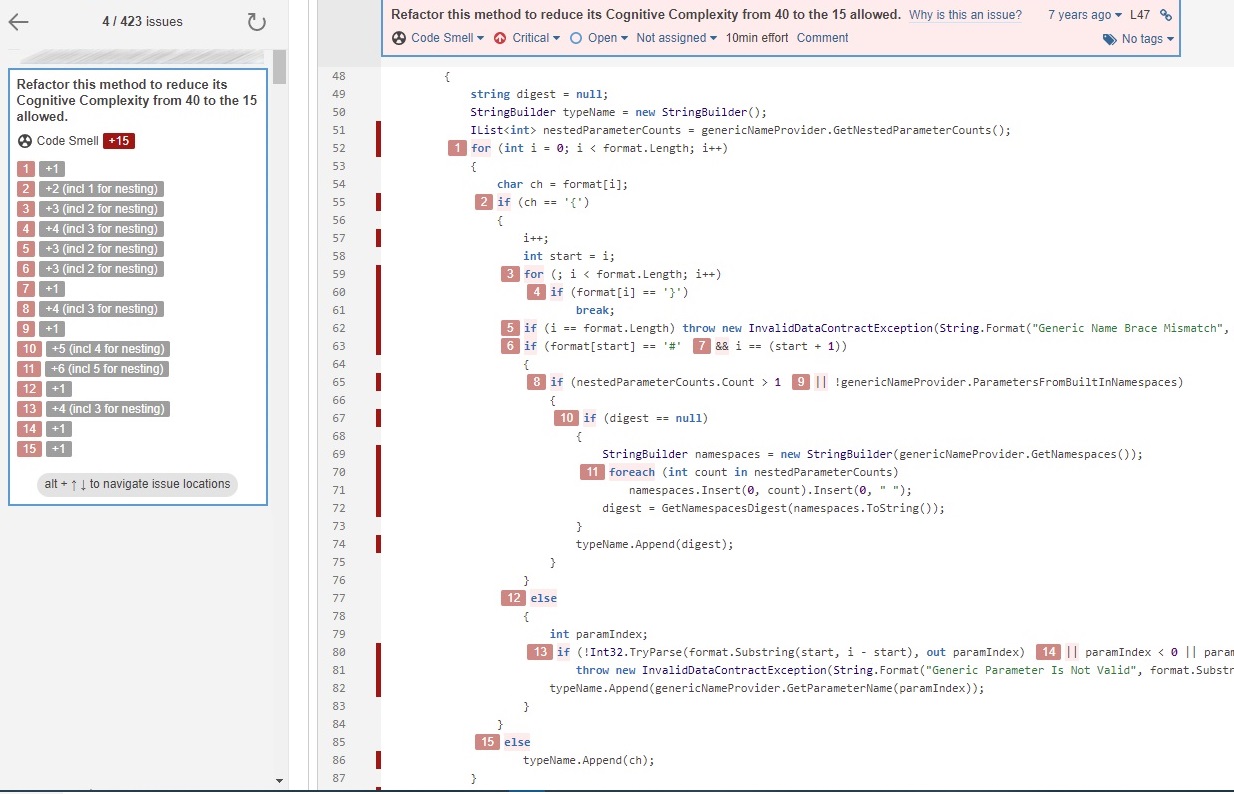
Как выглядит детальное построчное вычисление метрики
В каждой строке кода указано правило, согласно которому метрика была увеличина. Это позволяет нам более гибко подходить к оценке и потенциальному рефакторингу.
К сожалению, в расширении Sonar Lint для Visual Studio 2019 эту метрику пока не успели добавить. Или просто я не умею искать :).
По-умолчанию, показателями хорошего кода являются следующие отсечки (default threshold):
15 (все остальные языки)
Cyclomatic Complexity = 10 (все языки)
Я добавил Cyclomatic Complexity сюда для сравнения, так как эти метрики зачастую очень сильно отличаются. Давайте взглянем на простой пример (нужно просто зайти в Sonar Cloud -> Measures -> выбрать группу Complexity):
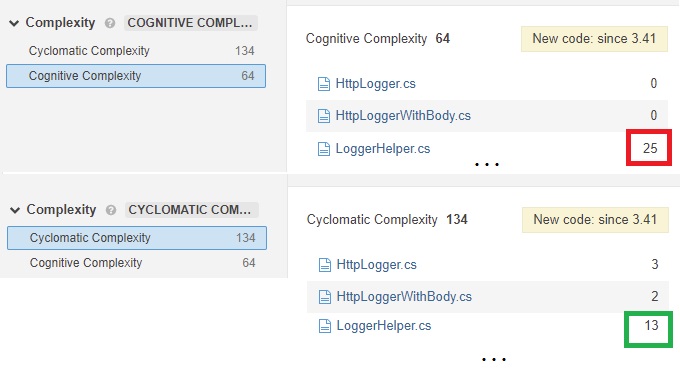
Сравнение показателей метрик Cyclomatic и Cognitive complexity
Слева видна суммарная сложность в одной из папок с файлами кода. Тут мы уже видим разницу в 2 раза: 134 против 64. Если посмотреть на конкретные файлы, то на примере простого LoggerHelper’а видно, что мы сильно превысили когнитивную сложность кода, хотя с точки зрения цикломатической сложности - всё не так плохо. И наоборот, там, где когнитивная нагрузка равна нулю, цикломатическая сложность выше.
Выводы
Итак, мы вычислили сложность кода. Что дальше?
Теперь мы всегда сможем сказать насколько код читаемый, а самое главное - насколько он НЕчитаемый. Используя эту информацию мы можем:
Аргументированно подходить к руководству для выделения ресурсов (времени, бюджетов и т.д.) на рефакторинг, указывая на метрики и даже конкретные части проекта
Планировать рефакторинг: видеть самые плохие участки кода, с которых стоило бы начать рефакторинг в первую очередь
В случае отсутствия возможности рефакторить, увидеть участки кода, которые необходимо лучше прокомментировать и задокументировать как можно скорее
Перестать спорить с коллегами и начать избегать излишней сложности кода на ранних этапах разработки
Упростить жизнь нашим коллегам, читающим и поддерживающим наш код
В конце концов, увеличить качество продукта
К сожалению, это всё ещё не позволяет нам ответить на вопрос насколько хорошо код отражает модель решаемой проблемы. Но мне кажется это тот первый необходимый толчок, который позволит программистам начать рефакторить и приводить свой код в нужное состояние. В итоге, программисты смогут лучше отражать модели решаемых проблем в коде.
Надеюсь, я предоставил достаточно информации, чтобы заинтересовать аудиторию и начать использовать метрику Cognitive Complexity в ежедневной практике.
Как уменьшить сложность данного фрагмента кода? Я получаю эту ошибку в Sonarqube ---> Выполните рефакторинг этого метода, чтобы снизить его когнитивную сложность с 21 до 15 разрешенных.
3 ответа
Все эти || просто сложите, и это будет плохой практикой. Вы можете переключить this.deviceDetails = <. на его собственную функцию сопоставления для быстрого решения.
Немного информации о том, как работает цикломатическая сложность и почему вы должны ее поддерживать на низком уровне
Прежде всего, важно понять, как « когнитивная сложность » работает по сравнению с « цикломатической сложностью ». Когнитивная сложность учитывает сложность, воспринимаемую человеческим мозгом. Вот почему он не просто указывает количество условных путей (упрощенное количество условных операторов плюс 1 для оператора возврата).
С другой стороны, цикломатическая сложность также учитывает вложенные условия (например, если внутри оператора if), что еще больше затрудняет чтение и понимание кода из-за человеческого перспектива.
Так что имейте в виду, что бинарные операции увеличивают сложность, но вложенные условия добавляют балл плюс 1 за каждое вложенное условие. Здесь когнитивная сложность будет равна 6, а цикломатическая сложность - только 4 (по одному для каждого условного и одного для обратного пути);
Если вы сделаете свой код более читабельным для человека, например извлекая методы из строк, содержащих условные выражения, вы добиваетесь как лучшей читаемости, так и меньшей цикломатической сложности.
Хотя в предоставленном вами коде нет вложенных условных выражений, я думаю, что важно сначала понять, как работает вычисление цикломатической сложности и почему рекомендуется сохранять его на низком уровне.
[TL; DR] Возможный подход к преобразованию кода в менее сложную и более читаемую версию
Давайте сначала посмотрим, как выполняется расчет сложности для вашего кода, как указано в комментариях:
Это может быть отредактированная версия вашего кода, которая (из быстрого ручного подсчета без реального анализа SonarQube) должна снизить когнитивную сложность до 12. (Имейте в виду, что это всего лишь ручной расчет).
С помощью рефакторинга простого метода извлечения много дублирования (см. Функцию getInfoItem ()) также было устранено , что позволяет легко уменьшить сложность и повысить удобочитаемость .
Честно говоря, я бы даже пошел дальше и реструктурировал ваш код еще больше, чтобы логика проверки пустых элементов и установки значения по умолчанию (здесь пустая строка) при предоставлении сведений об устройстве выполнялась классом устройства или сам класс деталей устройства, чтобы обеспечить лучшую согласованность данных и логики, которая работает с этими данными. Но поскольку я не знаю остальной части кода, этот начальный рефакторинг должен сделать вас еще на один шаг вперед к лучшей читаемости и меньшей сложности.
Если вы используете машинописный текст 3.7 или новее, вы можете использовать необязательную цепочку просто для некоторых из ваших условий.
Мне интересно, могу ли я снизить когнитивную сложность? Сейчас это 4 балла.
353 1 1 золотой значок 4 4 серебряных значка 12 12 бронзовых знаков своего рода игрушечный вопрос: полностью зависит от того, что на самом деле означает «делать что-то». Вложенные условные выражения могут быть даже неправильным выбором для маршрутизации вызовов. Я не думаю, что можно уменьшить сложность. С двумя логическими переменными у вас всегда есть 4 разных пути кода. Какой инструмент вы используете, чтобы оценить сложность кода? Было бы интересно узнать - может, добавлю это к вопросуЯ бы сказал, что лучший способ снизить когнитивную сложность - это использовать функции. Это похоже на исходный ответ @GuerricP, но обрабатывает множественный случай do somthing 2
Это снижает сложность, потому что не очевидно, что в исходной версии есть 2 маршрута для doSomething2.
16.3k 2 2 золотых значка 20 20 серебряных значков 34 34 бронзовых знакаНу, у вас может быть только один уровень глубины:

Я считаю, что это правильный и самый чистый способ.
Предполагая, что вы делаете одну и только одну вещь для каждого случая, вы можете попробовать расшифровать синтаксис:
- Для однострочных if операторов фигурные скобки не нужны.
- Вы можете избежать if , else if и т.д. с ранним возвращением
В этом случае я предпочитаю использовать вложенные троичные файлы. Что-то, что обычно считается «плохой практикой» создателями инструментов и лидерами общественного мнения в отрасли, но я думаю, что при правильном отступе они предлагают больше возможностей для избавления от беспорядка:
Читайте также: