
Если в процессе компиляции программы возникла ошибка то
Обновлено: 08.07.2024
Одна из самых неприятных ошибок - это ошибка компиляции для платы Аrduino Nano, с которой вам придется столкнуться не раз.
Синтаксические ошибки
Ардуино – одна из наиболее комфортных сред для начинающих инженеров, в особенности программистов, ведь им не приходится проектировать свои системы управления и делать множество других действий.
Сразу же при покупке они получают готовый набор библиотек на С99 и возможность, по необходимости, подтянуть необходимые модули в опен-соурс источниках.
Но и здесь не избежать множества проблем, с которыми знаком каждый программист, и одна из самых неприятных – ошибка компиляции для платы Аrduino nano, с которой вам придется столкнуться не раз. Что же эта строчка означает, какие у неё причины появления, и главное – как быстро решить данную проблему?
Для начала стоит немного окунуться в теорию, чтобы вы понимали причину возникновения данной строчки с текстом и не грешили лишний раз, что Ардуино уно не видит компьютер.
Как несложно догадаться, компиляция – приведение кода на языке Си к виду машинного (двоичного) и преобразование множественных функций в простые операции, чтобы те смогли выполняться через встроенные операнды процессора. Выглядит всё достаточно просто, но сам процесс компиляции происходит значительно сложнее, и поэтому ошибка во время проведения оной может возникать по десяткам причин.

Мы узнали, к чему приводит данный процесс, давайте разберёмся, как он происходит:
- Первое, что делает компилятор – подгружает все инклуднутые файлы, а также меняет объявленные дефайны на значения, которое для них указано. Это необходимо затем, чтобы не нужно было по нескольку раз проходиться синтаксическим парсером в пределах одного кода. Также, в зависимости от среды, компилятор может подставлять функции на место их объявления или делать это уже после прохода синтаксическим парсером. В случае с С99, используется второй вариант реализации, но это и не столь важно.
- Далее он проверяет первичный синтаксис. Этот процесс проводится в изначальном компилируемом файле, и своеобразный парсер ищет, были ли описаны приведенные функции ранее, подключены ли необходимые библиотеки и прочее. Также проверяется правильность приведения типов данных к определенным значениям. Не стоит забывать, что в С99 используется строгая явная типизация, и вы не можете засунуть в строку, объявленную integer, какие-то буквенные значения. Если такое замечается, сразу вылетает ошибка.
- В зависимости от среды разработки, иногда предоставляется возможность последний раз протестировать код, который сейчас будет компилироваться, с запуском интерпретатора соответственно.
- Последним идет стек из различных действий приведения функций, базовых операнд и прочего к двоичному коду, что может занять какое-то время. Также вся структура файлов переносится в исполняемые exe-шники, а затем происходит завершение компиляции.
Как можно увидеть, процесс не так прост, как его рисуют, и на любом этапе может возникнуть какая-то ошибка, которая приведет к остановке компиляции. Проблема в том, что, в отличие от первых трех этапов, баги на последнем – зачастую неявные, но всё ещё не связанные с алгоритмом и логикой программы. Соответственно, их исправление и зачистка занимают значительно больше времени.
А вот синтаксические ошибки – самая частая причина, почему на exit status 1 происходит ошибка компиляции для платы Аrduino nano. Зачастую процесс дебагинга в этом случае предельно простой.

Вам высвечивают ошибку и строчку, а также подсказку от оператора EXCEPTION, что конкретно не понравилось парсеру. Будь то запятая или не закрытые скобки функции, проблема загрузки в плату Аrduino возникнет в любом случае.
Ошибки компиляции плат Arduino uno
Другая частая оплошность пользователя, которая порождает вопросы вроде, что делать, если Аrduino не видит порт, заключается в том, что вы попросту забываете настроить среду разработки. IDE Ардуино создана под все виды плат, но, как мы указывали, на каждом контроллере помещается лишь ограниченное количество библиотек, и их наполнение может быть различным.
Соответственно, если в меню среды вы выбрали компиляцию не под тот МК, то вполне вероятно, что вызываемая вами функция или метод просто не будет найдена в постоянной памяти, вернув ошибку. Стандартно, в настройках указана плата Ардуино уно, поэтому не забывайте её менять. И обратная ситуация может стать причиной, по которой возникает проблема загрузки в плату на Аrduino uno.
Ошибка exit status 1 при компиляции для плат uno, mega и nano
Ошибки библиотек
Ведь банально причина может быть в устаревшем синтаксисе скачанного плагина и, чтобы он заработал, необходимо переписать его практически с нуля. Это единственный выход из сложившейся ситуации. Но бывают и более банальные ситуации, когда вы подключили библиотеку, функции из которой затем ни разу не вызвали, или просто перепутали название.
Ошибки компилятора Ардуино
Ранее упоминался финальный стек действий, при прогонке кода через компилятор, и в этот момент могут произойти наиболее страшные ошибки – баги самого IDE. Здесь конкретного решения быть не может. Вам никто не запрещает залезть в ядро системы и проверить там всё самостоятельно, но куда эффективнее будет откатиться до предыдущей версии программы или, наоборот, обновиться.
Основные ошибки
Ошибка: "avrdude: stk500_recv(): programmer is not responding"
Решение:
В Arduino IDE в меню "Сервис" выбираем плату. В меню "Сервис → Последовательный порт" выбираем порт.
Ошибка: "a function-definition is not allowed here before ‘
Забыли в коде программы (скетча) закрыть фигурную скобку >.
Решение:
Обычно в Ардуино IDE строка с ошибкой подсвечивается.
Ошибка: "No such file or directory / exit status 1"
Подключаемая библиотека отсутствует в папке libraries.
Решение:
Ошибка: "expected initializer before ‘>’ token / expected ‘;’ before ‘>’ token"
Забыли открыть фигурную скобку , если видим "initializer before". Ошибка "expected ‘;’ before ‘>’ token" - забыли поставить точку с запятой в конце командной строки.
Решение:
Обычно в Ардуино IDE строка с ошибкой подсвечивается.
Ошибка: ". was not declared in this scope"
Arduino IDE видит в коде выражения или символы, которые не являются служебными или не были объявлены переменными.
Решение:
Проверить код на использование неизвестных выражений или лишних символов.

Вывести самые распространенные мужские и женские имена
Имеется массив записей о студентах, каждая из которых включает поля: фамилия, имя, отчество, пол.
Вывести самые распространенные женские и мужские имена
Помогите решить задачу пожалуйста! Написать программу, которая формирует файл записей данной.
Ошибки после компиляции на Visual Express 2012.Ошибки в теме
Добрый вечер ребят помогите пожалуйста.Программа написана на Visual Express 2012.Обясните что.
Неожиданное закрытие окна
Когда консольное приложение запускается непосредственно из среды программирования,
то после выполнения последнего оператора программы ( return 0; ) окно закрывается.
Вставляйте оператор, ожидающий ввода символа с клавиатуры перед return:
или с использованием библиотеки низкоуровневого ввода conio.h
(на *NIX системах она не используется):
Двойная перестановка строк или элементов массива
Рассмотрим на примере инвертирования строки
Когда мы дойдем до L/2, то строка уже перевернута.
Последующие итерации до L-1 вернут буквы на прежние места.
Аналогичные ошибки бывают и при перестановке строк матрицы,
при транспонировании матрицы и т.п.
*** Updated:
Дополнительные варианты переворота:
Попытка модифицировать константу через указатель
Неправильное понятие приведения
Для приведения типов данных в C++ часто используются операции static_cast и reinterpret_cast .
Обратите внимание, что круглые скобки вокруг выражения ( d ) ставятся всегда!
В этом случае только сам программист может вникнуть в суть преобразования и взять ответственность за преобразование на себя.
Вот пример, требующий приведение такого типа:
К тому же и имена полей у них разные.
Но внутренне устройство одинаковое.
Т.е. мы понимаем, что типы данных абсолютно совместимы.
Осталось доказать это компилятору, что мы и делаем с помощью явного преобразования
Ошибки в логических выражениях
Использование присваивания (=) вместо сравнения (==).
всегда истина, т.к. переменной a присваивается двойка, что при приведению к bool дает true (подробное объяснение)
Рекомендации:
Читайте предупреждения компилятора, о таком присваивании он может сообщить (но не обязательно).
Можно в операции сравнения поменять местами левую и правую часть, тогда возникнет
ошибка компиляции (невозможно присвоить значение константе):
Здесь n в двоичном представлении равно 00000010, а k равно 00000001.
При их побитовом (поразрядном) умножении получим везде нули 00000000, что при приведении к bool даст false.
Во втором случае каждая переменная сначала приводится к bool,
в обоих случаях получается true, а потом выполняется логическое умножение.
С Вашего позволения оставлю это (Условия Йоды, или нотация Йоды) здесь.
Использование символа цифры вместо числа
Например, такой код
Это все из-за того, что в таблице кодировки ASCII символу '9' соответствует код 57 и подставляется код этого символа. Чтобы избежать этого, т.е., именно получить число 9, а не код символа, необходимо вычесть код символа '0', который равен 48.
Можно вычесть и код как есть, но понятнее будет вычесть символ '0'.
Выделение памяти без дальнейшего освобождения или неверное освобождение
а) При выделении памяти через оператор new - освобождайте её с помощью оператора delete в конце программы
При отсутствии явного освобождения программа может вызывать утечку памяти.
Несмотря на то, что программа скомпилируется, попытка освобождения с помощью неверного оператора вызывает UB (неопределённое поведение), что приводит к трудноуловимым ошибкам.
Возврат ссылки/указателя на локальную переменнуюЛокальные переменные, созданные на стеке, уничтожаются при выходе из области видимости (в данном случае это выход из функции), таким образом, память получает статус свободный и туда могут записаться какие-либо данные, либо, если это еще не успело произойти, там будет по прежнему находиться 42.
Использование неинициализированной переменной
Пожалуй, одна из самых распространённых ошибок.
d:\current\cpp\test\test.c(9) : warning C4700: использована неинициализированная локальная переменная "fp"Однако, этого не произойдет, если предупреждения об ошибках отключены. В Visual Studio эта настройка регулируется командой:
Проект -> Свойства -> Свойства конфигурации -> С/С++ -> Общие -> Уровень предупреждений
Вариаций на эту тему много, приведу пару примеров:
Чаще всего почему-то встречается вариант с использованием неинициализированного счётчика или переменной для подсчёта суммы, как показано ниже:Да, статические и глобальные переменные таки инициализируются нулём по-умолчанию, но если вы это знаете, то наверняка и с проблемой выше не сталкивались
Также эта проблема кроется в частичной инициализации объектов.
Некоторые программисты советуют всегда инициализировать переменные при объявлении какими-нибудь дефолтными значениями. Это особенно важно при использовании указателей, отладка которых занимает много драгоценных часов. Также могу посоветовать объявлять переменные как можно ближе к месту их использования, это поможет отследить проблему.
Выведет число 10. А не последовательность от 0 до 9. В данном случае просто 10 раз выполнится пустой цикл.
Такая же ошибка очень часто встречается в определении функций:
Неверный тип функции main()
Согласно стандарту функция main() должна возвращать целочисленное значение:Замечание.
Для некоторых компиляторов (в том числе и Visual Studio) допускаются и другие возвращаемые типы.
И вариант:
может использоваться.
Однако, следует помнить, что он может восприниматься как ошибка другими компиляторами. Отсутствие точки с запятой после определения классового типа
1>d:\current\cpp\test\tset.cpp(10) : error C2628: недопустимый 'A' с последующим 'int' (возможно, отсутствует ';')
1>d:\current\cpp\test\tset.cpp(11) : error C3874: возвращаемый тип 'main' должен быть 'int', а не 'A'
1>d:\current\cpp\test\tset.cpp(12) : error C2143: синтаксическая ошибка: отсутствие ";" перед "."
1>d:\current\cpp\test\tset.cpp(12) : error C2143: синтаксическая ошибка: отсутствие ";" перед "."
1>d:\current\cpp\test\tset.cpp(13) : error C2664: A::A(const A &): невозможно преобразовать параметр 1 из 'int' в 'const A &'
1> Причина: невозможно преобразовать 'int' в 'const A'
1> Ни один конструктор не смог принять исходный тип, либо разрешение перегрузки конструктора неоднозначно
Сравнение вещественных чисел при вычислениях
Поскольку арифметические вычисления для чисел с плавающей запятой выполняются с некоторой погрешностью, то их сравнение на равенство будет некорректным, например:
Сравнение символьных массивов
При сравнение char массивов через операторы < , == , != , > , <= , >= мы на самом деле сравниваем не содержимое, а указатели.
Для правильного сравнения стоит использовать специальную функцию strcmp .
Использование чисел, записанных в других системах счисления
Может показаться, что значения следующих двух переменных одинаковые:
Однако это совсем не так. Первое число ( 123 ) записано в десятичной системе счисления. Т.к. по умолчанию (и чаще всего) мы работаем с десятичной системой счисления, то x так и будет равен 123 .
Второе же число ( 0123 ) записано в восьмеричной системе счисления и при переводе в десятичную будет равно 83 , а не 123 . Если вы работаете с десятичной системой счисления, то не добавляйте цифру "0" перед числом.
Проверка на принадлежность значения определенному интервалу
Иногда при проверке принадлежности значения переменной определенному интервалу можно увидеть нечто подобное
Несмотря на кажущуюся логичность, этот код не проверяет на то, что x лежит между 0 и 10 .Если разбить на шаги, то они будут следующими:
Т.к. оператор сравнения <= левоассоциативен (т.е., выполняется слева направо), то первым шагом будет сравнение 0 и x
1. 0 <= x . Результат сравнения - true или false , которые будут преобразованы в 1 или 0 соответственно.
2. сравниваем полученный результат с 10 . 10 больше и 1 , и 0 . Следовательно, условие всегда истинно.
В общем случае, можно сказать, что при сравнении подобным образом, если последнее число (в примере это число 10 ) больше или равно 1 , то условие всегда истинно.
Проверку на принадлежность интервалу правильно записывать с помощью логического оператора И. Ошибкой также является использование запятой, вместо логического И
В этом случае, значения выражения 0 <= x никак не используется. Результатом будет значение выражения x <= 10 .
Иногда вместо логического И используют логическое ИЛИ.
Выражение
В решениях запрещается:
Решения выполняются в специальном окружении, обеспечивающем безопасный запуск, и попытка выполнить какие-либо из указанных действий закончится, скорее всего, получением вердикта «Ошибка во время выполнения».
Ввод и вывод данных
Во всех задачах необходимо считывать входные данные из текстового файла и выводить результат в текстовый файл. Имена файлов указаны в условии задачи. Предполагается, что файлы располагаются в текущем каталоге программы, поэтому в решениях можно и нужно использовать только их имена без абсолютных путей в файловой системе тестирующего сервера.
Можно считать, что изначально при запуске решения выходной файл будет отсутствовать, и решение должно его создать и записать туда ответ.
Внимательно проверяйте имена файлов в решениях на соответствие условию задачи.
Если в коде решения имена файлов указаны неверно, это может приводить к непредсказуемым последствиям. Так, если имя выходного файла указано неверно и требуемый по условию файл не создаётся, система, скорее всего, выдаст вердикт «Ошибка представления». В случае, когда в решении на Java перепутано имя входного файла и делается попытка открыть несуществующий файл, выбрасывается исключение. Если автор решения не перехватывает его, программа завершается с вердиктом «Ошибка во время выполнения». Если же исключение обрабатывается, то вполне возможны и другие вердикты в зависимости от того, отработает ли программа и что окажется в выходном файле. Если в решении на C++ неправильно указан входной файл и ошибки специально не обрабатываются, чтение из файла может приводить к чтению произвольных данных («мусора»). Если в программе вместо чтения из файла делается попытка считать данные со стандартного ввода (stdin, который обычно связан с клавиатурой консоли), программа заблокируется («повиснет») в ожидании ввода и будет завершена с вердиктом «Превышен предел времени».
Решение может выводить произвольные данные «в консоль», то есть в стандартные потоки stdout, stderr, которые обычно связаны с консольным окном (например для отладки). Это не запрещается и не влияет на результат. Проверяется только содержимое выходного файла. Следует помнить, что на вывод тратится дополнительное время, поэтому большой объём отладочной информации может критически замедлить вашу программу. Вывод в stderr медленнее, чем в stdout, поскольку не буферизируется.
Тестирование решений
Каждое отправленное решение проходит на сервере проверку на нескольких тестах. Задача считается решённой только в случае прохождения всех тестов. Решение запускается на всех тестах, которые есть по задаче, и процесс тестирования не прерывается на первом непройденном тесте, как это делается в соревнованиях типа ACM.
Тесты по каждой задаче не упорядочены по сложности, по размеру входных данных, по какому-то иному критерию, а следуют в исторически сложившемся порядке их добавления в систему.
Не гарантируется, что первый тест в системе будет совпадать с тестом из условия (зачастую это не так).
CE — Ошибка компиляции (Compilation Error)
Не удалось скомпилировать решение и получить исполняемый файл для запуска. Решение в таком случае, очевидно, не может быть проверено ни на одном тесте.
Время работы компилятора ограничено 30 секундами. Если он не успел отработать по каким-либо причинам, также будет выставлен вердикт «Ошибка компиляции».
TLE — Нарушен предел времени (Time Limit Exceeded)
Для каждого теста установлено своё ограничение по времени (Time Limit) в секундах. Для разных тестов по одной задаче ограничение по времени может быть разным.
Тестирующая система учитывает так называемое процессорное время (CPU Time) выполнения процесса в операционной системе. Нет смысла делать решение задачи многопоточным, потому что распараллеливание хоть и позволяет сократить реальное время работы (Wall Time), но не уменьшает процессорное время.
Процесс-решение запускается на тесте, и если процесс не успевает завершиться в течение отведённого времени, он принудительно завершается и выставляется вердикт «Нарушен предел времени». В качестве времени работы решения на тесте указывается то время, которое процесс фактически проработал до того, как был приостановлен. Нет возможности узнать, сколько бы программа проработала, если бы не была снята по времени. Если при ограничении по времени на тест в 1 секунду вы видите, что решение получает вердикт «Нарушен предел времени» и работает 1015 мс, то нельзя это понимать как «решение чуть-чуть не успевает, надо ускорить его на 15 мс». Если решение останавливается по времени, то вывод программы никак не проверяется на предмет его правильности.
Возможные причины появления ошибки «Нарушен предел времени»:
Не рекомендуется «пропихивать» медленное решение, отправляя его многократно, пока система не «согласится» его принять. Решение в любой момент может быть перетестировано и, соответственно, может перестать быть принятым из-за нарушения предела времени.
ILE — Нарушен предел ожидания (Idleness Limit Exceeded)
Программа зависла в ожидании, не потребляя при этом ресурсы процессора.
Такое может быть, например, если согласно условию чтение входных данных осуществляется из файла, а решение выполняет ввод с консоли. В этом случае процесс решения заблокируется в ожидании нажатия клавиш на клавиатуре. Через некоторое время система тестирования принудительно завершит этот процесс и выставит вердикт ILE.
MLE — Нарушен предел памяти (Memory Limit Exceeded)
Ограничение по памяти есть не для всех задач. Гарантируется, что для всех тестов в рамках одной задачи ограничение по памяти одинаково.
Как и в случае нарушения ограничения по времени, программа при нарушении ограничения по памяти аварийно завершается тестирующей системой, её вывод не проверяется на правильность. Точно так же не следует воспринимать размер памяти, использованной до момента аварийного завершения, как объём, которого решению хватило бы для успешной работы. Более точно, вердикт MLE, полученный с использованием 257 МБ памяти, говорит о том, что приложение успело использовать 257 МБ памяти и было принудительно остановлено, но ничего не говорит о том, сколько памяти использовало бы приложение, не будучи принудительно остановленным.
RTE — Ошибка во время выполнения (Run-time Error)
Укажем типичные причины ошибок во время выполнения.
PE — Ошибка представления (Presentation Error)
Наиболее частая причина возникновения этой ошибки — не найден выходной файл. Возможно, вы забыли создать выходной файл и выводите ответ в консоль (он в таком случае игнорируется). Проверьте имена входного и выходного файла в вашей программе на соответствие условию задачи. Исторически сложилось, что в разных задачах входной и выходной файл именуются по разным правилам: input.txt и output.txt, in.txt и out.txt, input.in и output.out (обратите внимание, что нет расширения txt), [задача].in и [задача].out.
Также имейте в виду, что отлавливание исключений и других ошибок не должно быть самоцелью. Если исключение не обрабатывается каким-либо образом, обычно нет смысла его ловить по следующей причине. Аварийное завершение работы программы в результате ошибки во время выполнения приводит к вердикту «Ошибка во время выполнения», только если соответствующее исключение было «проброшено» наружу, а не «заглушено» на каком-то этапе. Если исключение отлавливается, но никак не обрабатывается, то в результате возникновения соответствующей ошибки следует ожидать вердикт «Ошибка представления» или же «Неправильный ответ» (реже).
WA — Неправильный ответ (Wrong Answer)
Для многих задач ответ однозначен, и проверяется просто побайтовое совпадение вашего выходного файла и сохранённого правильного ответа. Такая проверка требует строгого соблюдения формата файла, не допускает незначащих пробелов и пустых строк. Например, если правильный ответ имеет вид (пробелы обозначены символом ␣)
и решение вывело
(лишний пробел в конце второй строки), то будет получен вердикт «Неправильный ответ». Для некоторых задач написаны проверяющие программы (checker), которые к таким различиям лояльны и засчитывают ответы с лишними пробелами как правильные. Всегда точно следуйте формату файла и не выводите лишних пробелов, и проблем не будет.
После последней строки файла можно выводить или не выводить перевод строки — не важно. Есть две точки зрения в зависимости от того, с какой стороны смотреть на символ перевода строки:
- каждая строка завершается переводом строки, поэтому \n в конце файла нужен;
- перевод строки является разделителем между соседними строками, поэтому \n в конце файла не нужен.
Поэтому рекомендуется придерживаться первого подхода и завершать все строки переводами строк.
Другие очевидные причины получения неправильного ответа:
- неверный алгоритм;
- ошибка в программе.
Бывает такое, что решение от запуска к запуску даёт разные ответы, или же правильно работает на одном компьютере и неправильно на другом. Такие случаи, как правило, связаны с ошибками в решениях.
OK — Принято (Accepted)
Программа работает правильно и прошла все тесты с соблюдением всех ограничений.
Если решение принято системой, это ещё не означает, что в его основе лежит правильный алгоритм. В любой момент могут появиться новые наборы входных данных, на которых будут заново протестированы все решения по задаче. Если ваше решение на самом деле не полностью верно и прошло только из-за недостаточно сильного набора тестов, оно может в будущем потерять статус «Принято».
CF — Ошибка тестирования (Check Failed)
Если указан номер теста, то программа успешно завершается на предложенном тесте (укладывается в отведённые время и память и не совершает ошибок во время выполнения), но результат не удаётся проверить из-за ошибок в программе проверки. Вашей ошибки в этом случае, возможно, никакой нет и после исправления программы проверки будет получен вердикт OK. Не исключены ещё два варианта: WA, PE.
Имейте в виду, что если ошибка тестирования возникает на первом же тесте, то на остальных Ваше решение не запускается вовсе. Соответственно, в этом случае после устранения ошибок программы проверки вердикты TLE, MLE, RTE также могут возникнуть в любом тесте, кроме первого.
SV — Нарушение безопасности (Security Violation)
Ошибка означает, что программа попыталась выполнить запрещённые действия.
К их числу относится попытка создания новых процессов. Вашим решениям запрещено запускать на выполнение другие программы. Например, в коде
порождается новый процесс командной оболочки cmd.exe и в нём выполняется команда pause. Пожалуйста, не пишите так, для достижения аналогичного эффекта можно использовать другие приёмы.
Особенности языков программирования
У каждого конкретного языка программирования есть свои особенности, о которых полезно знать. Далее рассмотрены отдельные особенности написания решений на разных языках программирования:
Выбор языка программирования
Конфигурация тестирующего сервера
Сервер, на котором осуществляется запуск решений, является виртуальной машиной, выполняющейся внутри Microsoft Hyper-V Server 2012 R2. Виртуальный компьютер работает под управлением Windows 7 Professional x64, оснащён процессором Intel® Core™ i3-4130 (Haswell, кэш 3 МБ, 3,40 ГГц, доступно только одно ядро) и 4 ГБ оперативной памяти. Для хранения входных и выходных файлов используется RAM-диск, чтобы обеспечить максимальную производительность ввода-вывода.
Языки программирования
На странице учебного курса в системе на вкладке «Компиляторы» можно ознакомиться с актуальным списком доступных языков программирования, версиями компиляторов и параметрами командной строки их вызова.
Размер системного стека явно не задаётся (используется размер по умолчанию). При компиляции кода на C++ включен режим оптимизации O2.

Компиляция исходных текстов на Си в исполняемый файл происходит в три этапа.
Препроцессинг
Эту операцию осуществляет текстовый препроцессор.
Исходный текст частично обрабатывается — производятся:
Компиляция
Процесс компиляции состоит из следующих этапов:
- Лексический анализ. Последовательность символов исходного файла преобразуется в последовательность лексем.
- Синтаксический анализ. Последовательность лексем преобразуется в дерево разбора.
- Семантический анализ . Дерево разбора обрабатывается с целью установления его семантики (смысла) — например, привязка идентификаторов к их декларациям, типам, проверка совместимости, определение типов выражений и т. д.
- Оптимизация . Выполняется удаление излишних конструкций и упрощение кода с сохранением его смысла.
- Генерация кода . Из промежуточного представления порождается объектный код.
Результатом компиляции является объектный код.
Объектный код — это программа на языке машинных кодов с частичным сохранением символьной информации, необходимой в процессе сборки.
При отладочной сборке возможно сохранение большого количества символьной информации (идентификаторов переменных, функций, а также типов).
Компоновка
Также называется связывание, сборка или линковка.
Это последний этап процесса получения исполняемого файла , состоящий из связывания воедино всех объектных файлов проекта.
При этом возможны ошибки связывания.
Если, допустим, функция была объявлена, но не определена, ошибка обнаружится только на этом этапе.
Особенность подключения пользовательских библиотек в Си
Подключение пользовательской библиотеки в Си на самом деле не так просто, как кажется.
Рассмотрим пример: есть желание вынести часть кода в отдельный файл — пользовательскую библиотеку.
program.c
int main()
int number = read_number();
int Divisor[MAX_DIVISORS_NUMBER];
size_t Divisor_top = 0;
factorize(number, Divisor, &Divisor_top);
print_array(Divisor, Divisor_top);
return 0;
>
Сама библиотека должна состоять из двух файлов: mylib.h и mylib.c.
mylib.h
//считываем число
int read_number();
//получаем простые делители числа
// сохраняем их в массив, чей адрес нам передан
void factorize(int number, int *Divisor, int *Divisor_top);
//выводим число
void print_number(int number);
//распечатывает массив размера A_size в одной строке через TAB
void print_array(int A[], size_t A_size);
mylib.c
//считываем число
int read_number()
int number;
scanf("%d", &number);
return number;
>
//получаем простые делители числа
// сохраняем их в массив, чей адрес нам передан
void factorize(int x, int *Divisor, int *Divisor_top)
for (int d = 2; d <= x; d++) while (x%d == 0) Divisor[(*Divisor_top)++] = d;
x /= d;
>
>
>
//выводим число
void print_number(int number)
printf("%d\n", number);
>
//распечатывает массив размера A_size в одной строке через TAB
void print_array(int A[], size_t A_size)
for(int i = A_size-1; i >= 0; i--)
printf("%d\t", A[i]);
>
printf("\n");
>
Файл mylib.c компилируется отдельно.
А на этапе компоновки полученный файл mylib.o должен быть включен в исполняемый файл program.exe.
Cреда разработки обычно скрывает весь этот процесс от программиста, но для корректного анализа ошибок сборки важно представлять себе как это делается.
Прелесть компилятора Си заключается в том, что он автоматически вылавливает различные синтаксические ошибки и указывает на них программисту.
Рассмотрим теперь вопросы компиляции в среде Visual C++ 6.0.
Если вы уже набрали программный код листинга 1, то нажмите клавишу F7 для компиляции. Внизу экрана появится окно, в которое выводятся результаты компиляции (рис. 10).
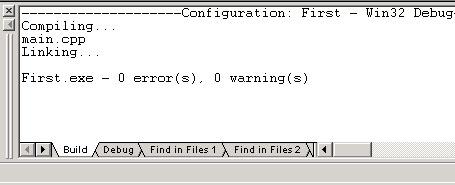
Если программный код набран без ошибок, то процесс компиляции завершается строкой:
Имя проекта.exe – 0 error(s), 0 warning(s)
Попробуем теперь сделать различные ошибки и посмотрим на реакцию компилятора.

При попытке скомпилировать программу компилятор выдаст ошибку «'printf' : undeclared identifier». Если в дальнейшем вы будете сталкиваться с ошибкой «undeclared identifier» в отношении какой-либо стандартной функции, то это, как правило, будет означать, что вам необходимо подключить соответствующую библиотеку.
Верните код программы в исходное сотояние и удалите символ «;» в конце строкиprintf() рис. 12. Попытайтесь скомпилировать программу.


Компилятор также выдаст соответствующую ошибку. Вы можете отследить местоположения ошибок в программном коде, дважды щелкнув мышкой по соответствующей ошибке в окне результатов компиляции.
Следует отметить, что очень часто интеллектуальная мощь компилятора Си++ приводит к возникновению у начинающих программистов заблуждения, заключающегося в том, что, дескать, компилятор умный он все ошибки найдет. Это неверно. Ни один компилятор в мире не найдет ошибку в слове «собака» если правильным является слово «кошка». Компилятор способен контролировать синтаксис программы. За ее логику должен отвечать программист.
Запуск программы на выполнение и ее останов
Запуск любой программы производится тогда, когда вы добились безошибочной компиляции этой программы. Продолжим работу с программой «Hello,world!». Если вы находитесь в средеVisual C++ 6.0нажмите клавишуF5. В вы, возможно, заметите на экране быструю смену каких-то окон, но в целом придете к выводу, что ничего не произошло. Это объясняется тем, что в программе не предусмотрена пауза перед завершением работы. Фактически, после печати слов «Hello,world!» программа сразу же закрывается, и вы просто не успеваете посмотреть результат ее работы.
В среде Visual C++ 6.0 данная проблема решается нажатием комбинации клавишCtrl + F5вместоF5.
Довольно часто в ходе отладки сложных программ, возникает необходимость остановить работу программы. Иногда это невозможно сделать обычными методами. Например, в программе может возникнуть, так называемый «вечный цикл» из-за которого можно наблюдать эффект «зависания» программы. В этом случае программа не реагирует на команды, подаваемые мышью.
Если вы работаете со средой Visual C++ 6.0то вам необходимо переключиться в окно редактора кода. После этого вам необходимо нажать комбинациюShift + F5.
Читайте также: