
Фильтрация url в браузере
Обновлено: 08.07.2024
Начать видимо стоит с DPI. Они в некотором количестве на сети имеются, но поставить их на весь трафик стоило бы РТК несколько десятков миллионов долларов и постоянно требовало бы новых инвестиций в связи с ростом потребления скучающим населением. Ни предыдущие, ни теперешние руководители на такое не решились (возможно лишь пока), потому как никаких новых услуг с осязаемыми объемами доходов внедрение DPI не обещает.
Поскольку блокировать разные ресурсы РТК должен был и раньше (суды вершат без оглядки на законы), то и делал это по IP’ческим адресам. Соответственно, простейшая фильтрация на границах решала проблему. Аналогично стали решать и проблему с реестром запрещенных ресурсов: специально обученный человек выгружал реестр, там есть и URL и IP и дальше добавлял записи в списочек, а скрипт правил access list.
ПО управления фильтрацией
Мы автоматизировали общение с реестром и тут, как всем понятно, магии никакой (ее и дальше то особо нет). Запротоколировали внесение изменений в реестре и реализацию цензуры на сети. Добавили мелкие рюшечки, связанные с распределенной структурой ответственности на сети РТК, исключением из действия фильтра части абонентов (в частности запредельных операторов). Ну и суды никто не отменял, поэтому есть возможность внести любой ресурс из судебного решения. Помимо этого, управляющее ПО настраивает перенаправление трафика на узлы фильтрации, готовит отчеты о поисковых запросах пользователей, мониторит узлы фильтрации и протоколирует все активности.
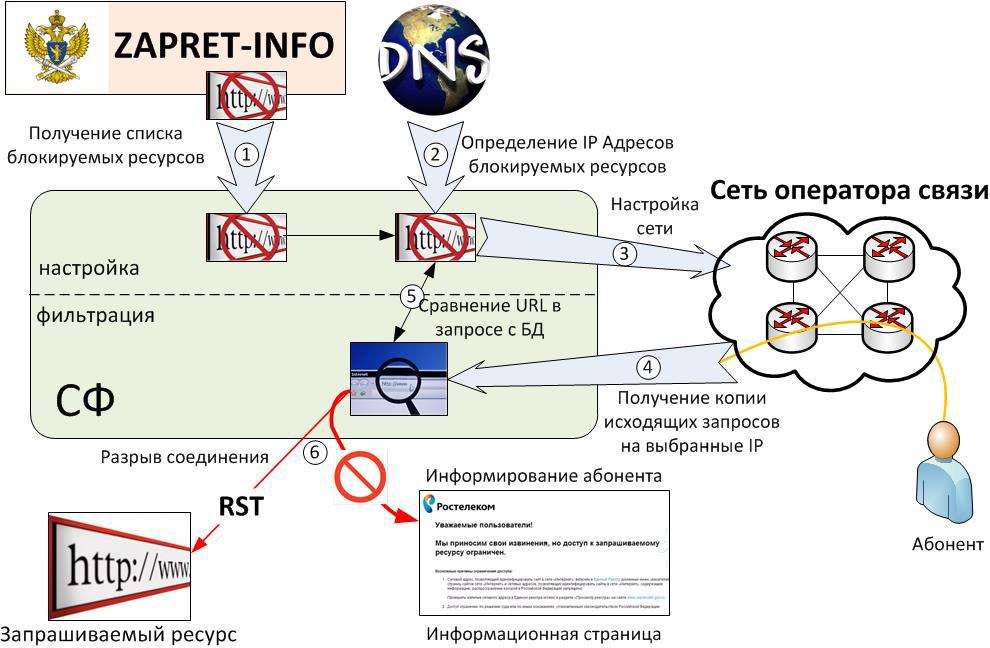
Поворот трафика и фильтрация
Трафик направляемый абонентами на IP адреса соответсвующие блокированным URL'ам на PE поворачивали в специальный VPN, где defult смотрит на пару рутеров в центре. Используя SCU/DCU (похожая функциональность вроде и на кисках имеется) на границе же исключали по адресам источника трафик от абонентов, фильтрации не подлежащих. Софт управления формировал /32 маршруты по IP адресам реестра, правил конфиг на центральном маршрутизаторе и изменения вступали в силу. От посылки BGP апдейтов, помнится, отказались, потому как нехорошо это.
На двух центральных маршрутизаторах настраивали копирование проходящего трафика уже с учетом портов. Соответственно на весь РТК получалось от силы несколько мегабит. Копировать можно было либо на внешний сервер, либо на MS-DPC. И там и там принцип дальнейшей обработки был одинаков. ПО фильтрации ловит пакет, если в нем get с URL’ом из списка, то в сторону сервера шлем сброс, а в сторону браузера редирект на сайт с рассказом про то, как важны моральные принципы для современного российского общества.
Минимальное время ответа от серверов, входивших в реестр год назад, превышало 100 мс, а софтина, анализирующая URL, выдавала ответ за 5-6 мс при нагрузке в 3 Гб/с. Посему решили, что городить прокси, обеспечивать его надежность и прочее в том же духе смысла не имеет. При сбое ПО фильтрации все будет работать, кроме фильтрации понятно. Правда по просьбе РТК запроектировали все равно по паре серверов фильтрации.
Сейчас понятно, что можно было и чуть проще сделать, использовать маленький DPI в центре вместо своего ПО фильтрации. Но так мы уже другому оператору сделали. Может статься, что выбранные внедренцы скомбинируют свое ПО работы с реестром с обычным DPI, через который пойдет только выбранный трафик. Нам же на тот момент хотелось понять есть ли хоть какая-то задача, которую стоило бы реализовывать на сервисных модулях в маршрутизаторе, а не снаружи. То, что Juniper закрыл для внешних разработчиков доступ к модулям, дает четкий ответ на этот вопрос, но нас тогда еще мучили сомнения.
Что касается стоимости, то из того миллиона, о котором идет речь, больше половины составляли серверы, так что большой прибыли на софте там не планировалось.
Администратор Chrome Enterprise может добавлять URL в списки запрещенных или разрешенных адресов, чтобы пользователи могли посещать только определенные сайты.
Формат фильтров
В правилах URLBlocklist и URLAllowlist используется следующий формат фильтров:
Это необязательное поле. Указанное значение должно заканчиваться символами ://. Подробнее….
Регистр не учитывается.
Действительное имя хоста или IP-адрес. Также может быть указано специальное значение: *. Перед указанным значением можно поставить символ . (точка), чтобы не учитывать субдомены.
Регистр не учитывается.
Можно указать любую строку.
Перечень токенов "ключ-значение" и "только ключ", разделенных символом &. Токены "ключ-значение" разделяются символом =. Чтобы задать сопоставление по префиксу, в конце маркера запроса укажите символ *. Порядок маркеров значения не имеет.
Доступные схемы
Можно использовать любую из стандартных схем или настроить собственную. Поддерживаются следующие стандартные схемы:
Любые другие схемы обрабатываются как пользовательские. При этом для них разрешены только шаблоны схема:* и схема://*, что позволяет охватить все URL. Значения для схемы и хоста указываются без учета регистра, а для пути и запроса регистр учитывается.
Примеры схем
Исключения для формата URL
Формат фильтров очень похож на формат URL. Применяются следующие исключения:
Выбор фильтра
К URL применяется фильтр, имеющий самое близкое соответствие.
Примечания
Процесс выбора фильтра
- Выбираются фильтры, в которых обнаружены самые длинные совпадения с адресом хоста, кроме тех, где не совпадает схема или номер порта.
- Выбираются фильтры, в которых обнаружены самые длинные совпадения пути.
- Выбираются фильтры, в которых обнаружены самые длинные совпадения маркеров запроса. Если на этом этапе не осталось ни одного подходящего фильтра, из адреса хоста удаляется крайний левый субдомен, после чего процесс повторяется с шага 1.
- Если какой-то из фильтров ещё доступен, принимается решение о запрете или разрешении, соответствующее этому фильтру. Если не обнаружено соответствия ни одному из фильтров, запрос по умолчанию разрешается.
Примеры списков запрещенных URL
Запрещает все запросы, содержащие следующие значения:
Запрещает видео на YouTube с идентификатором xyz.
При запрете достаточно любого вхождения пары "ключ-значение".
При разрешении каждому вхождению этого ключа должно соответствовать значение.
Cтатья \"Современные интернет-атаки\" предоставлена Sophos Plc и SophosLabs.
В веб-приложениях также обычно применяется какая-либо форма классификации URL-адресов. При этом запросы к заведомо вредоносным адресам или доменам могут блокироваться вне зависимости от того, был ли обнаружен вредоносный контент. Безусловно, это полезно с учетом того, что хакеры активно используют автоматизацию для постоянного изменения угроз с целью избежать обнаружения. Успех блокирования запросов к заведомо вредоносным доменам зависит от своевременного обновления списка подобных сайтов. Эффективность применения такого списка определяется рядом факторов, в числе которых:
Релевантность данных. Сбор необходимой информации о вредоносных интернет-программах для выявления новых атак должен производиться максимально быстро. Системы должны иметь глобальный охват. В таких решениях могут использоваться автоматические интернет-боты или совместная работа с партнерами, позволяющая собрать максимальный объем данных об интернет-угрозах.
Серверная поддержка. Для обработки поступающих данных о URL-адресах, проверки контента и оперативной публикации необходимых данных, используемых соответствующими продуктами, требуются сложные системы обработки и публикации. Такие системы должны быть способны отслеживать угрозы и вести анализ вредоносных интернет-программ в реальном времени, гарантируя выявление всех используемых в атаке файлов и блокирование всех задействованных URL-адресов.
Фильтрация URL-адресов также может использоваться для управления типами сайтов, которые пользователям разрешается посещать. Сайты, относящиеся к порнографическим, игровым или развлекательным, могут быть закрыты в пределах организации (поскольку они опасны или мешают работе). Точность классификационных данных определяет, насколько успешной окажется фильтрация URL-адресов. По этой причине в некоторых продуктах по лицензии используются данные от сторонних компаний, что повышает их способность к классификации URL-адресов.
Данная статья представляет из себя скорее более FAQ, чем полноценный мануал. Впрочем, многое уже написано на хабре и для того присутствует поиск по тегам. Смысла переписывать всё заново большого нет.
В последнее время наше государство, к счастью или не к счастью, принялась за интернет и его содержимое.
Многие, несомненно, скажут что нарушаются права, свободы и т.п. Конечно, думаю мало у кого возникнуть сомнения по поводу того, что то что придуманные законы сделаны мало понимающими людьми в деле интернетов, да и основная их цель это не защита нас от того, что там есть. Будучи ответственным человеком да подгоняемый и прокурорами в некоторых учреждениях, встаёт вопрос ограничения поступающей информации. К таким учреждениям, к примеру, относятся школы, детсады, университеты и т.п. им учреждения. Да и бизнесу то-же надо заботится об информационной безопасности.
И первый наш пункт на пути к локальному контент фильтру-это
Анализ того, что такое есть интернет и как он работает.
- Имени сайта
- url страницы
- По содержанию написанного на страничке сайта
- По ip адресу.
- Это плохое
- Это неизвестное
- Это хорошее.
- Разрешаем только то, что хорошее и запрещаем плохое и неизвестное. Данный путь носит название — БООЛЬШОЙ(а бывает и маленький) Белый список
- Разрешаем только то, что хорошее и неизвестное. Запрещаем только плохое. Данный путь носит гордое имя Чёрный список.
Cредства их осуществления.
Тут опять два пути:
Где происходит фильтрация.
Возможны следующие варианты:
- На компьютерах пользователя без централизованного управления, в качестве системного компонента или приложения.
- То-же, что и первое, но с централизованным управлением(как пример KASPERSKY ADMINISTRATION KIT).
- Компонент к браузеру. Есть для хрома и лиса соответствующие плагины
- На отдельном компьютере или кластере компьютеров(включая вариант-на шлюзе).
- Распределёнка.
Теперь следующий вопрос:
Надёжность фильтрации.
Думаю, ясно. Защиту нужно делать многоуровневой, ибо то, что просочится на одном уровне защиты, перекроется другим уровнем.
Давайте поговорим о
О недостатках уровней защиты.
Возможность обхода пользователем контентной фильтрации.
- Запретить прямой выход в сеть, за исключением прохода через прокси сервер(на прокси надо и метод CONNECT ограничить списком доменов или/и ip или mac адресов.) Это делаем или при помощи iptables, или просто в sysctl.conf пишем net.ipv4.ip_forward=0. Ну iptables — это вопрос уже отдельной статьи.
- Запретить пользователям на рабочих местах что-то ставить. Ясно дело: нет программы-нет обхода.
Вопрос-производительность.
Тут более или менее всё ясно-больше памяти, больше герц, больше кэша. И очень полезно для тех, у кого мощности маленькие, использовать оптимизацию по CFLAGS. Это позволяют делать все линуксы и фряхи, но особо удобны gentoo, calculate linux, slackware, freebsd.
У кого многоядерные процессоры, то используйте OPEMNP(dansguardian пригодный для оного можете взять у меня 93.190.205.100/main/dlya-dansguardian. Кстати, в нём-же исправлена ошибка с невозможностью загрузки данных в интернет.) CFLAGS="-fopenmp". LDFLAGS="-lgomp". Не забудьте включить -O3 -mfpmath=sse+387. Про автопатчинг здесь.
Вопрос-иерархия кэшей и прокси.
Анализ по спискам пусть будут делать squid1 и squid2.
Проверку на вирусы пусть будет делать squidclamav через c-icap на squid2. Белые списки вешаем на squid1.
Всё, что в белом списке, должно идти напрямую в интернет, минуя родительские прокси.
DNS сервер обязательно используем свой, в котором используем перенаправление на skydns или dns от yandex. Если есть локальные ресурсы провайдера, то добавляем зону forward на dns провайдера. Так-же в dns сервере прописываем локальную зону для нужных внутрисетевых ресурсов(а что-бы было красиво, они нужны). Указываем nosslsearch поиска google. В конфигах squid обязательно используем свой dns.
Для всего используем вебку Webmin и командную строчку. На windows серверах всё делаем через мышку.
Настройка локальной сети
К нам идёт проверка.
В данном случае-все ползунки в максимум.
Дополнительно-запрещаем все видеосайты, контакт, социальные сети, музыкальные порталы, файлообменники и файлообменные сети.
Запрещаем mp3.
Ставим галочку напротив безопасного поиска в личном кабинете SKYDNS.
Обязательно приводим в порядок документацию.
Читайте также: