
Какая из программ предоставляет возможность оптического распознавания текстов ms word
Обновлено: 07.07.2024
У вас есть отсканированные документы или другие файлы, созданные когда-то давно и заархивированные, но вы возобновили эти документы и хотите знать, как можно изменить их содержимое? Этот вопрос больше не будет вас волновать, потому что функция оптического распознавания символов (OCR) сделала это возможным. Вы можете получить эту функцию во многих инструментах, используемых для создания документов, например, некоторые из инструментов оптического распознавания символов Microsoft. Функция оптического распознавания символов не широко извества среди инструментов Microsoft. С этой точки зрения, эта статья проинформирует вас об Office Lens, MS Word и Office 365, а так же об общих проблемах, связанных с инструментами оптического распознавания символов, и как их решить.
Есть ли у Office Lens функция оптического распознавания символов?
Office lens - это один из инструментов Microsoft, который существует уже давно и вы можете использовать его для оцифровки документов в своем кабинете и менять их на устройствах с iOS, Mac или PC.
Оптическое распознавание символов в Office lens использует заднюю камеру на iPhone, iPad или iPod touch, чтоб запечатлеть изображение любого документа. Затем применяется сложный алгоритм масштабирования, чтобы выровнять заснятое содержимое, и далее получается делиться содержимым, экспортировать или редактировать его. Заметьте, что по умолчанию оно сохранит изображение документа, но если у вас также устновлен Word на вашем i-устройстве, оптическое распознавание символов Office экспортирует изображение как функционирующий Word-документ, и вы сможете менять содержимое этого документа прямо со своего устройства iOS.
Без хлопот, вот как пользоваться оптическим распознаванием символов Office lens:
Во-первых, скачайте Office OCR из App Store и установите его на своем i-устройстве. Дайте ему доступ к камере и следуйте пошаговой инструкции, как сканировать бумажный документ, а затем редактировать его в Word для iOS.
Шаг 1: В оптическом распознавании символов Microsoft lens перемещайтесь через селекторный диск над кнопкой затвора и выберите "Документ". Затем наведите камеру вашего i-устройства на документ, чтобы текст выглядел наиболее четко, и наблюдайте за тем, как оптическое распознавание символов Office lens создает документ.
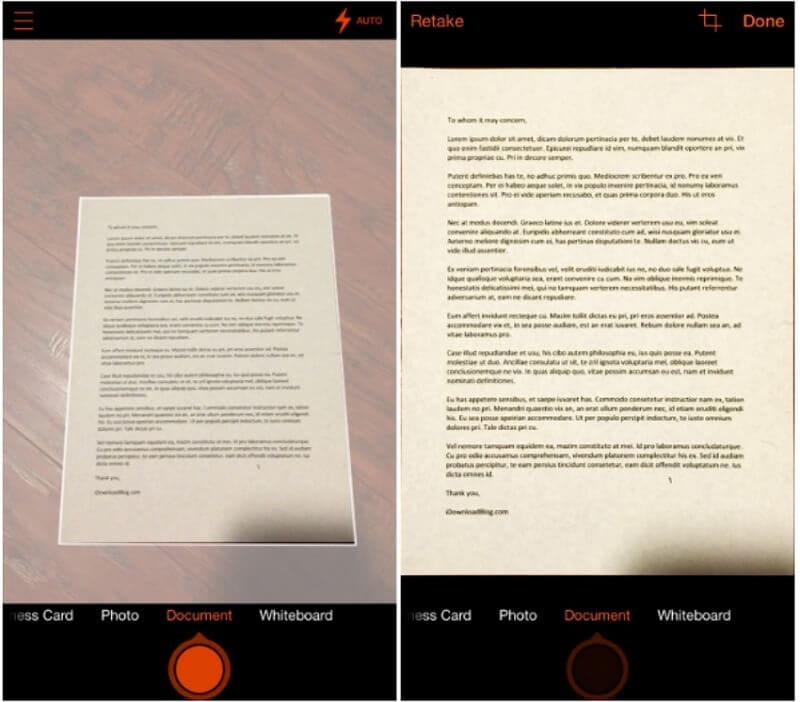
Шаг 2: Как только снимки выровняются с документом, нажмите кнопку "Снять", чтобы запечатлеть изображение документа, и оптическое распознавание символов Office Lens автоматически определит масштаб документа и уберет нечеткие углы при выравнивании. Вы также можете настроить обрамление вручную, нажав кнопку "Обрезать" слева от кнопки "Готово".

Шаг 3: После того, как вы завершили обрамление документа, вам будут предложены несколько вариантов экспорта документа. Выберите "Word" и оптическое распознавание символов Microsoft Lens запустит обработку отсканированного документа и преобразует его в DOCX-файл для word.

Шаг 4: После завершения обработки, Word запустит и скачает файл, а затем обработает его. Когда файл откроется, меняйте его соответственно.
Решение этой проблемы - наличие быстрого интернет-соединения или попытка не работать с большим объемом данных за один раз.
Есть ли в Word функция оптического распознавания символов?
Microsoft Word - это широко используемый инструмент среди пользователей Windows для создания заметок напрямую в программе. Но есть ли в Word функция оптического распознавания символов? Поискав и прочитав ответы на форумах Microsoft, становится понятно, что у MS Word скорее всего не получается осуществить функцию оптического распознавания символов. Поэтому становится сложно создавать заметки из файлов с изображениями.
Еще в Windows 2003 и ранее, Microsoft Office Document Imaging (MODI), что является тем же самым, что и функция оптического распознавания символов, была функцией, установленной по умолчанию. Благодаря ей удавалось конвертировать текст в отсканированном изображении в Word-документ. Тем не менее, ее убрали в Office 2010 и пока еще не вернули обратно.
Есть ли в Office 365 функция оптического распознавания символов?
Тем не менее, эта функция в некоторых случаях не работала. Поэтому мы не можем с точностью утверждать, что в Office 365 есть функция оптического распознавания символов.
Лучшая альтернатива оптическому распознаванию символов Microsoft
PDFelementэто мощный инструмент, который вы можете использовать для работы с PDF-файлами, создавая, форматируя и внося изменения. Важно, что вы можете использовать PDFelement как лучшую альтернативу оптическому распознаванию символов Microsoft и, не прикладывая усилий, менять содержимое файлов с изображениями.
- Сделайте текст в изображении, редактируемом оптическим распознаванием символов.
- Утверждайте документы и добавляйте подписи электронно.
- Обрабатывайте документы обновременно, чтобы конвертировать, изымать данные, добавлять нумерацию и водные знаки.
- Защищайте PDF-файлы паролем.
- Конвертируйте PDF-файлы в Word, HTML и изображения.
Давайте пройдемся по инструкции, как провести оптическое распознавание символов в PDF, используя программу:
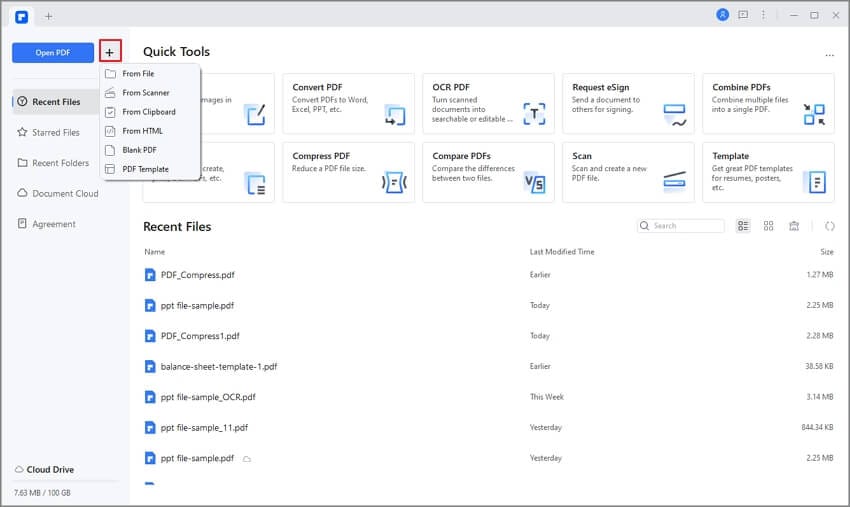
Шаг 1: Импорт документа
Вы можете импортировать уже созданный PDF-файл, нажав на "Открыть файл. " или "Создать PDF", чтобы сделать ваши файлы PDF-файлами. Следуйте инструкциям на экране, чтобы завершить процесс загрузки.
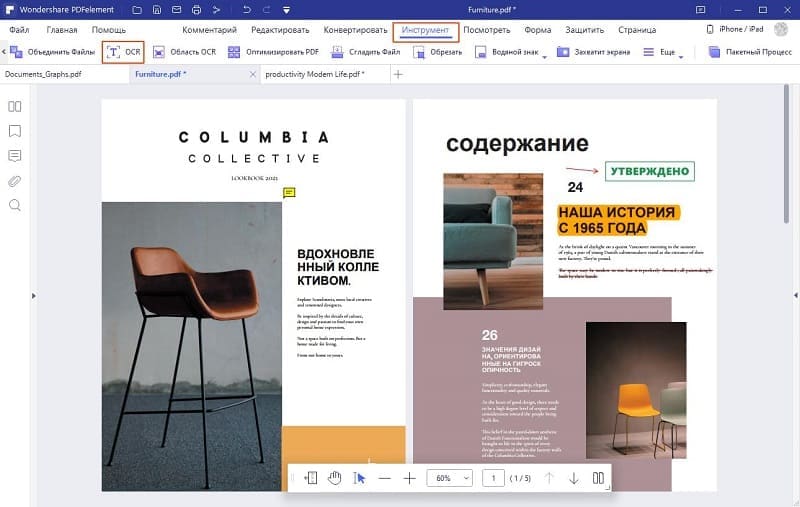
Шаг 2: Проведите оптическое распознавание символов
Когда PDF-файл загружен, нажмите на вкладку "Конвертировать" в строке меню. И опять, нажмите "Оптическое распознавание символов", чтобы перевести программу в режим оптического распознавания символов.
Шаг 3: Настройки для оптического распознавания символов
Во всплывающем окошке, выберите "Редактируемый текст". Определите язык для содержимого загруженого PDF-файла, нажав "Изменить язык". По необходимости, настройте страницы загруженого содержимого, нажав "Настроить страницы". Когда вы закончили настройку, нажмите кнопку "OK" чтобы начать оптическое распознавание символов в PDF-файле.
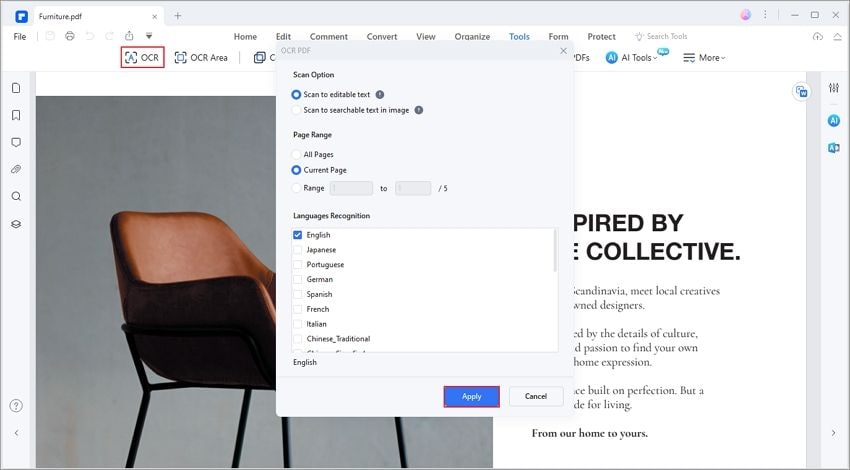
Шаг 4: Отредактируйте документ после оптического распознавания символов
Когда процесс оптического распознавания символов PDF-файла завершен, загруженый текст появится в новом окне. Нажмите на вкладку "Изменить" в строке меню и установите необходимые настройки. Зачем начните редактирование и форматирование загруженного текста по своему усмотрению.
В наши дни почти все (например, фотографии, музыка, видео) стали цифровыми, и это имеет смысл, поскольку цифровым контентом можно удобно управлять. Так как же текстовые документы могут остаться позади? Благодаря достижениям в Оптическое распознавание символов (OCR) техники, теперь стало проще, чем когда-либо оцифровывать печатные или рукописные тексты. Для этого вам нужны действительно хорошие приложения для распознавания текста, и именно об этом и рассказывается в этой статье. Это программное обеспечение может либо получать источник со сканирующих устройств, либо вы можете вводить свои собственные изображения или файлы PDF для преобразования в редактируемый текст. Заинтригованный? Ну, тогда давайте не будем биться вокруг, и перейдем к 8 лучшим программам для распознавания текста, которые вы должны использовать в 2020 году.
Лучшее программное обеспечение для распознавания текста для Windows, MacOS и Linux
1. ABBYY FineReader
Когда дело доходит до оптического распознавания символов, вряд ли найдется что-то, что даже близко подходит к ABBYY FineReader. ABBYY FineReader позволяет загружать текст со всех видов изображений на одном дыхании.
Несмотря на широкий набор функций, ABBYY FineReader очень прост в использовании. Он может извлекать текст практически из всех популярных форматы изображений, такие как PNG, JPG, BMP и TIFF. И это еще не все. ABBYY FineReader также может извлекать текст из файлов PDF и DJVU. После загрузки исходного файла или изображения (которое предпочтительно должно иметь разрешение не менее 300 т / д для оптимального сканирования) программа анализирует его и автоматически определяет различные разделы файла, имеющие извлекаемый текст. Вы можете либо извлечь весь текст, либо выбрать только некоторые конкретные разделы. После этого все, что вам нужно сделать, это использовать опцию Сохранить, чтобы выбрать формат вывода, а ABBYY FineReader позаботится обо всем остальном. Поддерживаются многочисленные форматы вывода, такие как TXT, PDF, RTF и даже EPUB.
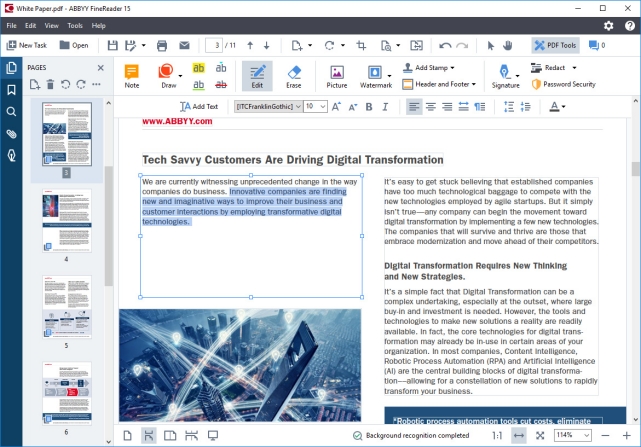
Выводимый текст является полностью редактируемым, и текст даже из самых содержательных документов (например, имеющих несколько столбцов и сложные макеты) извлекается безупречно. Другие функции включают в себя обширная языковая поддержка, многочисленные стили шрифтов / размеры и инструменты коррекции изображения для файлов, полученных из сканеров и камер.
Сказав все это, то, что отличает ABBYY FineReader от остальных программ, это его почти идеальная точность. С новым обновлением Finereader 15, теперь программное обеспечение использует AI для улучшения распознавания символов, AI особенно используется при извлечении текстов из документов, написанных на японском, корейском и китайском языках. Таким образом, если вы хотите получить абсолютно лучшее программное обеспечение для оптического распознавания текста с расширенными функциями, расширенным форматом ввода-вывода и поддержкой обработки, выберите ABBYY FineReader.
Доступность платформы: Windows и macOS
Цена: Платные версии начинаются с $ 199, доступна 30-дневная бесплатная пробная версия
2. Тессеракт
Тессеракт, пожалуй, самое мощное и передовое программное обеспечение для распознавания текста в этом списке, и я скажу вам почему. Прежде всего, немного истории. Он был разработан HP в 1994 году, но вскоре компания выпустила его под лицензией Apache для разработки с открытым исходным кодом. В 2006 году Google принял проект и спонсировал разработчиков для работы над Tesseract. Перенесемся вперед, и Tesseract стал самым мощным Механизм распознавания текста, который использует Deep Learning для извлечения текстов из изображений (BMP, PNG, JPEG, TIFF и т. Д.) И файлов PDF., Существует множество онлайн-сервисов, которые используют OCR API Tesseract для распознавания и преобразования больших массивов изображений и файлов PDF. И самое приятное, что он доступен для всех основных операционных систем, включая Windows, macOS и Linux. Не говоря уже о том, что в отличие от ABBYY и Adobe, Tesseract совершенно бесплатно и вы можете использовать его для преобразования тысяч изображений в текст, не платя ни копейки.
Доступность платформы: Интернет, Windows, macOS и Linux
Цена: Свободно
3. OmniPage Ultimate от Kofax
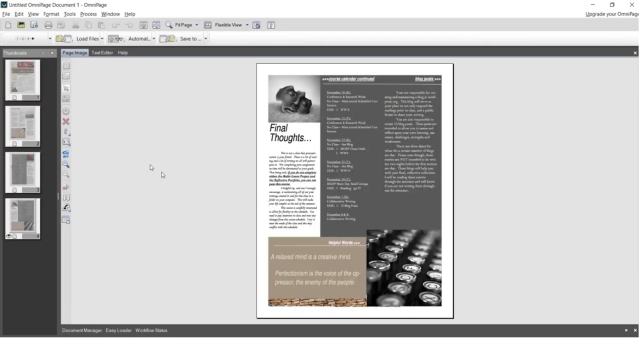
Кроме того, OmniPage Ultimate использует свою запатентованную технологию для определения макета изображений и автоматически поворачивает документ в правильной ориентации. Кроме того, вы можете запланировать большие объемы файлов PDF для пакетной обработки, используя инструмент автоматизации. Не говоря уже о том, что может обнаружить более 120 языков и может обрабатывать изображения и документы соответственно. Что касается форматов выходного файла, он поддерживает PDF, DOC, EXCL, PPT, CDR, HTML, ePUB и другие. Учитывая все вышесказанное, OmniPage Ultimate представляется надежным решением для оптического распознавания текста для корпоративных пользователей.
Доступность платформы: Windows
Цена: Бесплатная пробная версия на 15 дней, платная версия за 183 $
4. Readiris
В поисках чрезвычайно мощного программного обеспечения для оптического распознавания символов, которое имеет множество функций, но не требует ли много усилий, чтобы начать работу? Посмотрите на Readiris, так как это может быть именно то, что вам нужно.
Приложение профессионального уровня Readiris имеет обширный набор функций, который в значительной степени идентичен ранее обсуждавшемуся ABBYY FineReader. Readiris поддерживает несколько форматов изображений: от BMP до PNG и от PCX до TIFF. Кроме этого, PDF и DJVU файлы могут быть обработаны так же хорошо. Изображения могут быть получены из устройств сканера, и приложение также позволяет вам задавать пользовательские параметры обработки для исходных файлов / изображений, такие как сглаживание и регулировка DPI, перед их анализом. Хотя Readiris может обрабатывать изображения с более низким разрешением очень хорошо, оптимальное разрешение должно быть не менее 300 dpi.
Как только анализ завершен, Readiris определяет текстовые разделы (или зоны), и текст может быть извлекается из определенных зон или всего файла, Извлеченный текст доступен для редактирования и поиска и может быть сохранен в различных форматах, таких как PDF, DOCX, TXT, CSV и HTM.
Более того, облачная функция сохранения в Readiris Pro позволяет напрямую сохранять извлеченный текст в различные облачные службы хранения, такие как Dropbox, OneDrive, Google Drive и другие. Существует также множество полезных функций редактирования / обработки текста, и даже штрих-коды можно сканировать.
В общем, вы должны использовать Readiris, если хотите надежные функции извлечения / редактирования текста в простом в использовании пакете, в комплекте с обширной поддержкой формата ввода / вывода. Однако Readiris немного колеблется, когда дело доходит до обработки документов со сложными макетами, такими как несколько столбцов, таблиц и т. Д.
Доступность платформы: Windows и macOS
Цена: Платные версии начинаются с $ 49, доступна 10-дневная бесплатная пробная версия
5. Adobe Acrobat Pro DC
Доступность платформы: Windows и macOS
Цена: Бесплатная пробная версия на 7 дней, платная версия начинается с $ 12.99 / месяц
6. Microsoft OneNote
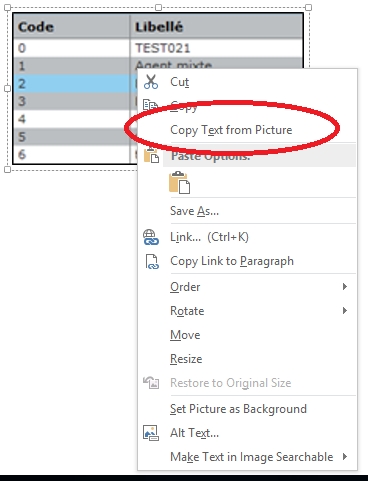
Использование OneNote для извлечения текста из изображений смехотворно просто. Если вы используете настольное приложение, все, что вам нужно сделать, это использовать Вставить Возможность добавить изображение в любой из блокнотов или разделов. Как только это будет сделано, просто щелкните правой кнопкой мыши на изображение и выберите Копировать текст с картинки вариант. Весь текстовый контент с изображения будет скопирован в буфер обмена и может быть вставлен (и, следовательно, отредактирован) куда угодно, согласно требованию. Будь то PNG, JPG, BMP или TIFF, OneNote поддерживает практически все основные форматы изображений.
Однако возможности OneNote по извлечению текста весьма ограничены, и он не может работать с изображениями, имеющими сложные макеты текстового содержимого, такие как таблицы и подразделы. Так что это то, что вы должны иметь в виду.
Доступность платформы: Windows и macOS
Цена: Свободно
7. Amazon Textract
В 2019 году Amazon запустила свое программное обеспечение для оптического распознавания текста Textract, которое имеет модель машинного обучения и обучено использованию миллионов документов. Он может автоматически определять печатный текст из изображений (JPG и PNG) и файлов PDF и отображать его в цифровом виде с почти идеальной точностью. Хотя Textract в основном доступен в веб-браузере, вы также можете загрузить его и использовать службу через командную строку. Кроме того, Textract кажется довольно мощным программным обеспечением для распознавания текста. он может извлекать не только тексты, но также таблицы, поля, числа и ключевые значения. Мне особенно нравится извлечение таблиц из отсканированных изображений, так как это может упростить процесс редактирования текста. Textract хранит данные таблицы, используя предопределенную схему, где он извлекает все данные в виде строк и столбцов.
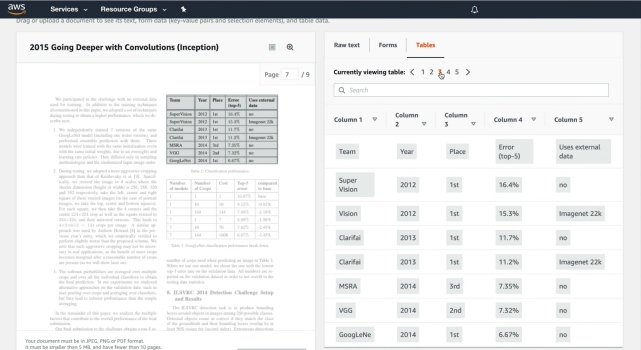
Сказав все это, Amazon Textract предлагает свои услуги как для частных лиц, так и для предприятий. Как домашний пользователь, вы можете зарегистрировать бесплатную учетную запись уровня AWS и использовать эту услугу, но имейте в виду, что вы можете конвертировать только 1000 страниц в месяц. В целом, Amazon Textract делает отличное программное обеспечение для распознавания текста и может использоваться как обычными пользователями, так и предприятиями.
Доступность платформы: Интернет, Windows, macOS, Linux
Цена: Бесплатно в течение первых 3 месяцев, Премиум план начинается с $ 1,50 за 1000 страниц
8. Документы Google
Теперь вы можете редактировать весь текст, искать его, редактировать и, наконец, сохранять файл в нескольких форматах, которые изначально поддерживаются Документами Google. В моем тестировании это работало довольно хорошо для файлов PDF которые были созданы с помощью текстовых процессоров. Однако имейте в виду, что он не может конвертировать изображения или отсканированные изображения в виде файлов PDF. Итак, если вам нужен бесплатный и простой инструмент OCR для преобразования PDF-файлов в редактируемый текст, Google Docs предоставит вам все необходимое.
Доступность платформы: Интернет, Windows, macOS, Linux
Цена: Свободно
Все готово для преобразования изображений и PDF-файлов в текст?
Оцифровка печатного и рукописного текстового содержимого чрезвычайно полезна, поскольку делает хранение, редактирование и обмен чрезвычайно легкими. И вышеупомянутое программное обеспечение для распознавания текста делает быструю работу по выполнению именно этого, независимо от того, насколько сложны или сложны ваши потребности в извлечении текста. Нужны функции извлечения текста профессионального уровня с лучшими инструментами пост-обработки? Перейти на ABBYY FineReader, Tesseract или OmniPage. Вы бы предпочли более простое программное обеспечение для оптического распознавания текста, которое только делает основы? Используйте OneNote или Google Docs. Попробуйте их, и посмотрите, как они работают для вас. Знаете ли вы о каком-либо другом программном обеспечении OCR, которое могло бы быть включено в приведенный выше список? Кричите в комментариях ниже.
Для быстрого перевода текста с бумажных носителей в электронный вид используют сканеры и программы распознавания символов .
После обработки документа сканером получается графическое изображение документа (графический образ). Но графический образ еще не является текстовым документом. Человеку достаточно взглянуть на лист бумаги с текстом, чтобы понять, что на нем написано. С точки зрения компьютера, документ после сканирования превращается в набор разноцветных точек, а вовсе не в текстовый документ.
Проблема распознавания текста в составе точечного графического изображения является весьма сложной. Подобные задачи решают с помощью специальных программных средств, называемых средствами распознавания образов.
Наиболее широко известна и распространена такая программа отечественных производителей — ABBYY FineReader .
Эта программа предназначена для распознавания текстов на русском, английском, немецком, украинском, французском и многих других языках (на 179 языках), а также для распознавания смешанных двуязычных текстов.
Возможности программы ABBYY FineReader:
- Работает с разными моделями сканеров.
- Позволяет из бумажных документов, PDF-файлов и цифровых фото сделать редактируемый текст.
- Позволяет объединять сканирование и распознавание в одну операцию, работать с пакетами документов (многостраничными документами) и с бланками.
- Позволяет редактировать распознанный текст и проверять его орфографию.
- Сохраняет внешний вид документа, а также его структуру, то есть, расположение слов, абзацев, таблиц, изображений, заголовков и нумерация страниц останутся такими же, как и в оригинале.
- Экспортирует тексты в Word, Excel, PowerPoint или Outlook.
Преобразование бумажного документа в электронный вид происходит в пять этапов. Каждый из этих этапов программа FineReader может выполнять как автоматически, так и под контролем пользователя. Если все этапы проводятся автоматически, то преобразование документа происходит за один прием.
Пять этапов процесса обработки документа с помощью программы ABBYY FineReader:
- Сканирование документа (кнопка Сканировать).
- Сегментация документа (кнопка Сегментировать).
- Распознавание документа (кнопка Распознать).
- Редактирование и проверка результата (кнопка Проверить).
- Сохранение документа (кнопка Сохранить).
1) На этапе сканирования производится получение изображений при помощи сканера и сохранение их в виде, удобном для последующей обработки. Чтобы начать сканирование, надо включить сканер и щелкнуть на кнопке Сканировать.
2) Второй этап работы — сегментация , разбиение страницы на блоки текста. Если страница содержит колонки, иллюстрации, врезки, подрисуночные подписи или таблицы, то порядок распознавания требует коррекции. Содержимое страницы разбивается на блоки, внутри каждого из которых распознавание осуществляется в естественном порядке. Блоки нумеруются, исходя из порядка включения их в документ. При автоматической сегментации (кнопка Сегментировать) определение границ блоков осуществляется автоматически. При этом учитываются поля документа, просветы между колонками, рамки.
3) Процесс распознавания текста после сегментации начинается с щелчка на кнопке Распознать и полностью автоматизирован.
4) Когда распознавание данной страницы завершается, полученный текстовый документ отображается в окне Текст. Заключительные этапы работы позволяют отредактировать полученный текст с помощью средств, напоминающих текстовый редактор WordPad. Провести проверку орфографии с учетом трудностей распознавания позволяет кнопка Проверить.
5) По щелчку на кнопке Сохранить запускается Мастер сохранения результатов. Он позволяет сохранить распознанный текст или передать его в другую программу (например, в Microsoft Word) для последующей обработки полученный текст можно сохранить в виде форматированного или неформатированного документа.
Необходимость работы с текстом, представленным в виде графических файлов, появляется довольно часто. Будь то картинка, отсканированный документ или фотокопия, ручной набор информации, представленной в них, может занять довольно продолжительное время.
Чтобы избавиться от ненужной работы и сохранить свое время, и было создано большое количество программ, способных распознать текст и преобразовать его в более удобный формат, готовый для редактирования и копирования.
Обзор программ

Программ для этой цели существует большое количество. Для начала работы с ними достаточно иметь изображение или отсканированный документ, который нужно перевести в текст. Большинство из них похожи своими функциями, но в то же время обладают и уникальными инструментами, подходящими для конкретных целей. Как не потеряться в их разнообразии, и на какие из них стоит обратить свое внимание? Это мы рассмотрим далее.
CuneiForm
Первой и программ, на которой мы остановимся, является CuneiForm. Это свободно распространяемый софт от компании Cognitive Technologies. Его основное предназначение – оптическое распознавание текстов, представленных в виде электронных копий или картинок. Он быстро переводит графический файл в текст, с которым можно работать в любом офисном приложении.

Основные особенности программы:
F reemore OCR
Подобной по своим функциям является и Freemore OCR. Это простая и находящаяся в свободном доступе программа, с помощью которой можно извлечь текст из изображений в разных форматах и PDF документов. После завершения сканирования полученный результат можно сохранить в файле, который открывается блокнотом или Word.
Freemore OCR – это:
Обратите внимание! Работа подобных приложений с документами в формате PDF может занимать больше времени, чем с обычным графическим файлом, что объясняется большим объемом исходного материала.
FreeOCR
FreeOCR – еще одно удобное приложение для оптического распознавания текста. Обладает интуитивно понятным интерфейсом и содержит набор всех необходимых для этого инструментов. Стоит заметить, что меню программы на английском языке, но благодаря необычному подходу к его дизайну, оно понятно каждому пользователю. Утилита поддерживает работу с множеством изображений в разных форматах и PDF-файлами.

Особенности FreeOCR:
Важно! Для установки FreeOCR необходимо подключение к сети Интернет. После запуска программа в автоматическом режиме обновит свою базу данных и скачает недостающие словари из онлайн-хранилища. Во время работы, при обнаружении незнакомых символов или языка, FreeOCR также может предложить обновление.
Видео: распознаем текст с картинки
SimpleOCR
SimpleOCR – аналогичная программа для распознавания текста после сканирования. Она отлично подходит для работы с иностранными языками, так как обладает большим и постоянно совершенствующимся словарем. Помимо стандартного набора функций, обладает возможностью поиска слова или сочетания в полученном тексте и расширенными опциями форматирования. Хорошо подходит для обработки объемных текстов.
Отличительные черты SimpleOCR:
RiDoc
RiDoc – приложение, основной функцией которого является работа с отсканированными копиями документов и их конвертации в обычный текст. В нем все готово для сканирования – достаточно подключить принтер и начать работу, после чего программа начнет обработку выбранных файлов.

Кроме этого, оно позволяет уменьшить размер документа без потери качества исходного материала. Функции RiDoc:
img2txt
img2txt – стандартное приложение, преобразующее различные виды графических файлов в текстовый материал. Программа поддерживает большинство известных форматов, легка в использовании и находится в свободном доступе.

Основные функции и особенности:
Обратите внимание! img2txt, как и другие подобные приложения, имеет свою онлайн-версию, на разработке и улучшении которой сейчас сосредоточили свое внимание ее создатели.
SunnyPage
SunnyPage – удобная утилита, позволяющая загружать и конвертировать различные виды изображений, будь то отсканированная копия документа, картинка или же фото в хорошем качестве. Поддерживает она и работу с PDF-документами. В состав программы входит обширный словарь и функция автоматического распознавания языка.

Помимо этого, SunnyPage:
Программа для сканирования и распознавания текста Abbyy Finereader
ABBYY FineReader – заслуженно лучшая в своем роде программа для распознавания текста. Ее популярность обусловлена наличием всех необходимых функций, которые пользователь ищет в подобных приложениях. Она полностью совместима с Microsoft Office, что позволяет начать работу с документом сразу поле окончания процесса конвертации.
Что может ABBYY FineReader?

Capture2Text
Capture2Text – портативное приложение, обладающее большим набором функций для работы с документами. Его отличительной особенностью является возможность создания снимка экрана или его части и сохранение в виде изображения. После этого можно приступать к работе, перенося полученную информацию в документ традиционных форматов.
Capture2Text не требует установки и может запускаться с флеш-накопителя. Это делает ее применимой во многих сферах и просто незаменимой для тех, кому всегда необходимо иметь под рукой простой и мощный конвертер.

Capture2Text обладает множеством интересных функций:
Google Документы
Помимо всех вышеперечисленных утилит, функция оптического распознавания текстовых фрагментов присутствует в Google Документах. Данный сервис поддерживает работу как с файлами в форматах JPG, PNG и GIF, так и многостраничными PDF –документами. Исходниками могут служить изображения, полученные с помощью сканеров, а также обычные фотографии.

Стоит заметить, что при использовании данного сервиса, в результате не всегда сохраняется оригинальное форматирование. Некоторые структуры, как, например, списки, колонки и сноски, могут быть утеряны.
На это в значительной степени влияет качество загружаемого графического файла. Полученные документы могут быть сохранены на сервисе Google Диск, затем скачаны на компьютер или отосланы на электронную почту.
Читайте также: