
Количество ошибок в программе
Обновлено: 07.07.2024
Привет, Вы узнаете про статистическая модель миллса -оценка количества ошибок в программном коде , Разберем основные ее виды и особенности использования. Еще будет много подробных примеров и описаний. Для того чтобы лучше понимать что такое статистическая модель миллса -оценка количества ошибок в программном коде , настоятельно рекомендую прочитать все из категории Качество и тестирование программного обеспечения. Quality Assurance.
Модель Миллса — способ оценки количества ошибок в программном коде, созданный в 1972 году программистом Харланом Миллсом. Он получил широкое распространение благодаря своей простоте и интуитивной привлекательности .
Методология
Допустим, имеется программный код, в котором присутствует заранее неизвестное количество ошибок (багов), требующее максимально точной оценки. Для получения этой величины можно внести в программный код дополнительных ошибок, о наличии которых ничего не известно специалистам по тестированию[3][1].
Предположим, что после проведения тестирования было обнаружено n естественных ошибок (где n[1][4].
Из которого следует, что оценка полного количества естественных ошибок в коде равна, а количество все еще не выловленных багов кода равно разности [1][5]. Сам Миллс полагал, что процесс тестирования необходимо сопровождать постоянным обновлением графиков для оценки количества ошибок[6].
Очевидно, что такой подход не лишен недостатков. Например, если найдено 100% искусственных ошибок, то значит и естественных ошибок было найдено около 100%. Причем, чем меньше было внесено искусственных ошибок, тем больше вероятность того, что все они будут обнаружены. Из чего следует заведомо абсурдное следствие: если была внесена всего одна ошибка, которая была обнаружена при тестировании, значит ошибок в коде больше нет[6].
В целях количественной оценки доверия модели был введен следующий эмпирический критерий:
Уровень значимости оценивает вероятность, с которой модель будет правильно отклонять ложное предположение[7][6]. Выражение для было сконструировано Миллсом[7], но в силу своей эмпирической природы при необходимости оно допускает некоторую вариативность в разумных пределах[8].
Исходя из формулы для можно получить оценку количества искусственно вносимых багов для достижения нужной меры доверия . Это количество дается выражением вида [8].
Статистическая модель Миллса позволяет оценить не только количество ошибок до начала тестирования, но и степень отлаженности программ. Для применения модели до начала тестирования в программу преднамеренно вносят ошибки . Далее считают, что обнаружение преднамеренно внесенных и так называемых собственных ошибок программы равновероятно.
Для оценки количества ошибок в программе до начала тестирования используется выражение

(2.2.1)
Если продолжать тестирование до тех пор, пока все ошибки из числа преднамеренно внесенных не будут обнаружены, степень отлаженности программы С можно оценить с помощью выражения

(2.2.2)
где SиW=V(равенство значенийWиVв данном случае имеет место, поскольку считается, что все преднамеренно внесенные ошибки обнаружены) имеют тот же смысл, что и в предыдущем выражении (2.2.1), аr означает верхний предел (максимум) предполагаемого количества «собственных» ошибок в программе.
Выражения (2.2.1) и (2.2.2) представляют собой статистическую модель Миллса. Необходимо заметить, что если тестирование будет закончено преждевременно (т. е. раньше, чем будут обнаружены все преднамеренно внесенные ошибки), то вместо выражения (2.2.2) следует использовать более сложное комбинаторное выражение (2.2.3). Если обнаружено только Vошибок изWпреднамеренно внесенных, используется выражение

. (2.2.3)
где в круглых скобках записаны обозначения для числа сочетаний из Sэлементов поV— 1 элементов в каждой комбинации и числа сочетаний изS+r+ 1 элементов поr+Vэлементов в каждой комбинации.
2.2.2. Задачи по применению модели Миллса
Задача 1
В программу преднамеренно внесли (посеяли) 10 ошибок. В результате тестирования обнаружено 12 ошибок, из которых 10 ошибок были внесены преднамеренно. Все обнаруженные ошибки исправлены. До начала тестирования предполагалось, что программа содержит не более 4 ошибок. Требуется оценить количество ошибок до начала тестирования и степень отлаженности программы.
Решение задачи
Для оценки количества ошибок до начала тестирования используем формулу (2.2.1).
• количество внесенных в программу ошибок W= 10;
• количество обнаруженных ошибок из числа внесенных V= 10;
• количество «собственных» ошибок в программе S= 12 — 10 = 2.
Подставив указанные значения в формулу, получим оценку количества ошибок:
Таким образом, из результатов тестирования следует, что до начала тестирования в программе имелось 2 ошибки.
Для оценки отлаженности программы используем уравнение (2.2.2). Нам известно:
• количество обнаруженных «собственных» ошибок в программе S=2;
• количество предполагаемых ошибок в программе r= 4;
• количество преднамеренно внесенных и обнаруженных ошибок W= 10.
Очевидно, что обнаружено меньшее число «собственных» ошибок, чем количество предполагаемых ошибок в программе (S<r). Для оценки отлаженности программы используем уравнение
Степень отлаженности программы равна 0,67, что составляет 67%.
Задача 2
В программу было преднамеренно внесено (посеяно) 14 ошибок. Предположим, что в программе перед началом тестирования было 14 ошибок. В процессе четырех тестовых прогонов было выявлено следующее количество ошибок.
Продолжение к посту модель Миллса.
Парная оценка
Данная модель требует тестирование программы двумя специалистами (или группами специалистов). Зато не требует внесение в программу искусственных ошибок. Итак, пусть программу тестируют независимо друг от друга две группы специалистов. Предположим, что в программе содержится N ошибок. Пусть первая группа нашла N1 ошибок, а вторая — N2. Часть ошибок обнаружена обеими группами. Пусть таких ошибок N12.

Эффективность работы групп оценим через процент обнаруженных ими ошибок:
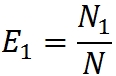
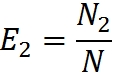
Обаружение всех ошибок считаем равновероятным (что, на мой взгляд, уменьшает доверие к этой модели, как и в случае с миллсовой). Тогда, в силу равновероятности нахождения любой из ошибок, любое случайным образом выбранное подмножество из N можно рассматривать как аппроксимацию всего множества N. Это значит, что если первая группа обнаружила 10% всех ошибок, она должна обнаружить примерно 10% из любого случайным образом выбранного подмножества.
В качестве такого случайным образом выбранного подмножества возьмём множество ошибок, найденных второй группой. Доля всех ошибок, найденных первой группой, равна N1/N. Доля ошибок, найденных первой группой среди тех ошибок, которые были найденны второй группой, равна N12/N2. Согласно такому рассуждению, эти две величины должны быть равны:
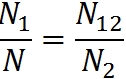
Отсюда количество ошибок в программе:

Количество нанайденных ошибок равно (N-N1-N2+N12).
Например, пусть первая группа нашла 8 ошибок, вторая 9. Обеими группами были найдены 3 ошибки. Тогда количество ошибок в программе N=(8*9/3)=24. Из них уже найденно (8+9-3)=14. Следовательно осталось найти 10 штук.
Исторический опыт
Данная модель появилась в процессе работы над OS/360 компанией IBM. Была использованна следущая формула для оценки числа ошибок: N=2*ИМ+23*МИМ. Здесь
N — полное число исправлений изза ошибок,
ИМ — количество исправляемых модулей,
МИМ — число многократно исправляемых модулей.
Многократно исправляемыми модулями считались модули, которые потребовали 10 или более исправлений. ИМ оценивалось как 90% новых модулей и 15% старых. МИМ — как 15% новых и 6% старых. При подстановке таких оценок в формулу получаем вид:
Таким образом, если в системе 140 модулей, а в процесее обновления предстоит добавить ещё 20, то количество ошибок, которое при этом будет обнаружено, оценивается следующим образом:
2*(0.9*20+0.15*140)+21*(0.15*20+0.06*140) = 2*(18+21)+23*(3+8.4) = 78+262.2 = 340.2
Стоит иметь в виду, что такая модель разрабатывалась для конкретной системы. Не факт, что её можно напрямую применять в других случаях.
В программу преднамеренно внесли (посеяли) 10 ошибок. В результате тестирования обнаружено 12 ошибок, из которых 10 ошибок были внесены преднамеренно. Все обнаруженные ошибки исправлены. До начала тестирования предполагалось, что программа содержит не более 4 ошибок. Требуется оценить количество ошибок до начала тестирования и степень отлаженности программы.
Решение задачи
Для оценки количества ошибок до начала тестирования используем формулу (1). Нам известно:
· количество внесенных в программу ошибок S = 10;
· количество обнаруженных ошибок из числа внесенных V =10;
· количество «собственных» ошибок в программе n = 12 - 10 = 2.
Подставив указанные значения в формулу, получим оценку количества ошибок:
N=(S*n)/ V= (10*2)/10 = 2
Таким образом, из результатов тестирования следует, что до начала тестирования в программе имелось 2 ошибки.
Для оценки отлаженности программы используем уравнение (2). Нам известно:
· количество обнаруженных «собственных» ошибок в программе n = 2;
· количество предполагаемых ошибок в программе K= 4;
· количество преднамеренно внесенных и обнаруженных ошибок S= 10.
Очевидно, что обнаружено меньшее число «собственных» ошибок, чем количество предполагаемых ошибок в программе (n<K).Для оценки отлаженности программы используем уравнение
С= S/(S+K+1) = 10/(10 + 4+ 1) = 0,67
Степень отлаженности программы равна 0,67, что составляет 67%.
Задача 2
В программу было преднамеренно внесено (посеяно) 7 ошибок. В результате тестирования обнаружено 11 ошибок, из которых 7 ошибок были внесены преднамеренно. Все обнаруженные ошибки исправлены. До начала тестирования предполагалось, что программа содержит не более 5 ошибок. Требуется оценить количество ошибок до начала тестирования и степень отлаженности программы.
Решение задачи
Для оценки количества ошибок до начала тестирования используем формулу (1). Нам известно:
· количество внесенных в программу ошибок S= 7;
· количество обнаруженных ошибок из числа внесенных V=7;
· количество «собственных» ошибок в программе n=11-7 = 4.
Подставив указанные значения в формулу, получим оценку:
Таким образом, из результатов тестирования следует, что до начала тестирования в программе имелось 4 ошибки.
Для оценки отлаженности программы используем уравнение (2). Нам известно:
· количество обнаруженных «собственных» ошибок в программе n = 4;
· количество предполагаемых ошибок в программе K= 5;
· количество преднамеренно внесенных и обнаруженных ошибок S=7.
Очевидно, что обнаружено меньшее число «собственных» ошибок, чем количество предполагаемых ошибок в программе (n < K).Для оценки отлаженности программы используем уравнение
С= S/(S+K+ 1) =7/(7 + 5 + 1) = 0,54
Степень отлаженности программы равна 0,54, что составляет 54%.
Задача 3
В программу было преднамеренно внесено (посеяно) 14 ошибок. Предположим, что в программе перед началом тестирования было 14 ошибок. В процессе четырех тестовых прогонов было выявлено следующее количество ошибок.
| Номер прогона |
| V |
| n |
Необходимо оценить количество ошибок перед каждым тестовым прогоном. Оценить степень отлаженности программы после последнего прогона. Построить диаграмму зависимости возможного числа ошибок в данной программе от номера тестового прогона.
Решение задачи
Количество ошибок перед каждым прогоном будем оценивать в соответствии с выражением (1). Перед каждой последующей оценкой количества ошибок и степени отлаженности программы необходимо корректировать значения внесенных Sи предполагаемых Kошибок с учетом выявленных и устраненных после каждого прогона тестов. Степень отлаженности программы на всех прогонах, кроме последнего, рассчитывается по комбинаторной формуле.
Определяя показатели программы по результатам первого прогона, необходимо учитывать, что S1 = 14; n1=4; V1 = 6, тогда
По результатам второго прогона корректируем исходные данные для оценки параметров: K2 = 14 - 4 = 10; S2 = 14 - 6 = 8; n2 = 2; V2 = 4, следовательно,
Корректировка исходных данных после третьего прогона дает следующие данные: K3 = 10 - 2 = 8, S3 = 8 - 4 = 4; n3= 1; V3 = 2,откуда количество ошибок определится следующим образом:
После четвертого прогона программы получим следующие исходные данные: K4 = 8 - 1 = 7, S4 = 4 - 2 = 2; n4 = 1; V4 = 2, тогда
Поскольку после четвертого прогона все «посеянные» ошибки выявлены и устранены, то для оценки отлаженности программы можно воспользоваться упрощенной формулой
C=S/(S+K+ 1) = 2/(2 + 7+ 1) = 0,2.
Таким образом, в предположении, что до начала четвертого прогона в программе оставалось 7 ошибок, степень отлаженности программы составляет 20%.
Результат по количеству ошибок в программе до начала каждого прогона приведен ниже.
| Номер прогона |
| N |
Графически динамика количества ошибок по результатам тестирования программы показана на рисунке 2.
На приведенном графике дополнительно отображена линия тренда, характеризующая тенденцию снижения количества ошибок в программе по результатам тестовых прогонов.
Рисунок 2. Динамика количества ошибок при тестировании программы
В программу было преднамеренно внесено (посеяно) 14 ошибок. В результате тестирования обнаружено 9 ошибок, из которых 6 ошибок были внесены преднамеренно. Все обнаруженные ошибки исправлены. До начала тестирования предполагалось, что программа содержит не более 4 ошибок. Требуется оценить степень отлаженности программы на момент завершения тестирования.
Если тестирование закончено раньше, чем обнаружены все преднамеренно внесенные ошибки, то следует применять более сложное комбинаторное выражение (6).
Из условия задачи нам известно:
· количество внесенных в программу ошибок S=14;
· количество обнаруженных ошибок из числа внесенных V= 6;
· количество «собственных» ошибок в программе n = 9-6 = 3;
Подставив значения в формулу, получим оценку количества ошибок:
N=(S*n)/ V= (14*3)/6 = 7
Таким образом, из результатов тестирования следует, что до начала тестирования в программе имелось 7 ошибок.
Для оценки отлаженности программы используем уравнение (7). Нам известно:
· количество обнаруженных «собственных» ошибок в программе n = 3;
· количество предполагаемых ошибок в программе K= 4;
· количество преднамеренно внесенных и обнаруженных ошибок S= 14.
Очевидно, что обнаружено меньшее число «собственных» ошибок, чем количество предполагаемых ошибок в программе (n<K).Для оценки отлаженности программы используем уравнение
С= S/(S+K+1) = 14/(14 + 4+ 1) = 0,74
Степень отлаженности программы равна 0,74, что составляет 74%.
Заключение
В проделанной нами работе была достигнута первоначально поставленная цель. Мы изучили статические модели и метрики для определения качества ПО. Для достижения данной цели мы ознакомились с показателями качества программного обеспечения по стандарту ГОСТ Р 9126-93. Изучили статические модели и метрики. Для лучшего представления и анализа рассмотрели модели Миллса и простую интуитивную модель на конкретных примерах.
Следует признать, что абсолютно надежных программ не существует, так как абсолютная степень надежности не может быть теоретически доказана и, следовательно недостижима. Однако важно знать, насколько надежно конкретное ПО. Описанные модели представляют теоретический подход и, как правило, имеют ограниченное применение. До сих пор не предложено ни одного надежного количественного метода оценки надежности ПО, не содержащего чрезмерного количества ограничений.
Практика разработки ПО предполагает приоритет задачи обеспечения надежности над задачей её оценки. Ситуации выглядит парадоксально: совершенно очевидно, что прежде чем обеспечивать надежность, следует научиться её измерять. Но для этого нужно иметь практически приемлемую единицу измерения надежности ПО и модели её расчета.
Из всех областей программной инженерии надежность ПС является самой исследованной областью. Ей предшествовала разработка теории надежности технических средств, оказавшая влияние на развитие надежности ПС. Вопросами надежности ПС занимались разработчики ПС, пытаясь разными системными средствами обеспечить надежность , удовлетворяющую заказчика, а также теоретики, которые, изучая природу функционирования ПС, создали математические модели надежности, учитывающие разные аспекты работы ПС (возникновение ошибок, сбоев, отказов и др.) и позволяющие оценить реальную надежность . В результате надежность ПС сформировалась как самостоятельная теоретическая и прикладная наука [10.5-10.10, 10.16-10.24].
Надежность сложных ПС существенным образом отличается от надежности аппаратуры. Носители данных (файлы, сервер и т.п.) обладают высокой надежностью, записи на них могут храниться длительное время без разрушения, поскольку физическому разрушению они не подвергаются.
С точки зрения прикладной науки надежность - это способность ПС сохранять свои свойства ( безотказность , устойчивость и др.), преобразовывать исходные данные в результаты в течение определенного промежутка времени при определенных условиях эксплуатации. Снижение надежности ПС происходит из-за ошибок в требованиях, проектировании и выполнении. Отказы и ошибки зависят от способа производства продукта и появляются в программах при их исполнении на некотором промежутке времени.
Для многих систем (программ и данных) надежность - главная целевая функция реализации. К некоторым типам систем (реального времени, радарные системы, системы безопасности, медицинскоеоборудование со встроенными программами и др.) предъявляются высокие требования к надежности, такие, как отсутствие ошибок, достоверность , безопасность и др.
Таким образом, оценка надежности ПС зависит от числа оставшихся и не устраненных ошибок в программах. В ходе эксплуатации ПС ошибки обнаруживаются и устраняются. Если при исправлении ошибок не вносятся новые или, по крайней мере, новых ошибок вносится меньше, чем устраняется, то в ходе эксплуатации надежность ПС непрерывно возрастает. Чем интенсивнее проводится эксплуатация , тем интенсивнее выявляются ошибки и быстрее растет надежность системы и соответственно ее качество.
Надежность является функцией от ошибок, оставшихся в ПС после ввода его в эксплуатацию. ПС без ошибок является абсолютно надежным. Но для больших программ абсолютная надежность практически недостижима. Оставшиеся необнаруженные ошибки проявляют себя время от времени при определенных условиях (например, при некоторой совокупности исходных данных) сопровождения и эксплуатации системы.
Для оценки надежности ПС используются такие статистические показатели, как вероятность и время безотказной работы, возможность отказа и частота ( интенсивность) отказов . Поскольку в качестве причин отказов рассматриваются только ошибки в программе, которые не могут самоустраниться, то ПС следует относить к классу невосстанавливаемых систем.
При каждом проявлении новой ошибки, как правило, проводится ее локализация и исправление. Строго говоря, набранная до этого статистика об отказах теряет свое значение , так как после внесения изменений программа , по существу, является новой программой в отличие от той, которая до этого испытывалась.
В связи с исправлением ошибок в ПС надежность , т.е. ее отдельные атрибуты, будут все время изменяться, как правило, в сторону улучшения. Следовательно, их оценка будет носить временный и приближенный характер. Поэтому возникает необходимость в использовании новых свойств, адекватных реальному процессу измерения надежности, таких, как зависимость интенсивности обнаруженных ошибок от числа прогонов программы и зависимость отказов от времени функционирования ПС и т.п.
К факторам гарантии надежности относятся:
- риск как совокупность угроз, приводящих к неблагоприятным последствиям и ущербу системы или среды;
- угроза как проявление неустойчивости, нарушающей безопасность системы;
- анализ риска - изучение угрозы или риска, их частота и последствия;
- целостность - способность системы сохранять устойчивость работы и не иметь риска;
Риск преобразует и уменьшает свойства надежности, так как обнаруженные ошибки могут привести к угрозе, если отказы носят частотный характер.
10.2.1. Основные понятия в проблематике надежности ПС
Формально модели оценки надежности ПС базируются на теории надежности и математическом аппарате с допущением некоторых ограничений, влияющих на эту оценку. Главным источником информации, используемой в моделях надежности, является процесс тестирования, эксплуатации ПС и разного вида ситуации, возникающие в них. Ситуации порождаются возникновением ошибок в ПС, требуют их устранения для продолжения тестирования.
Базовыми понятиями, которые используются в моделях надежности ПС, являются [10.5-10.10].
Отказ ПC (failure) - это переход ПС из работающего состояния в нерабочее или когда получаются результаты, которые не соответствуют заданным допустимым значениям. Отказ может быть вызван внешними факторами (изменениями элементов среды эксплуатации) и внутренними - дефектами в самой ПС.
Дефект (fault) в ПС - это последствие использования элемента программы, который может привести к некоторому событию, например, в результате неверной интерпретации этого элемента компьютером (как ошибка (fault) в программе) или человеком (ошибка (error) исполнителя). Дефект является следствием ошибок разработчика на любом из процессов разработки - в описании спецификаций требований, начальных или проектных спецификациях, эксплуатационной документации и т.п. Дефекты в программе, не выявленные в результате проверок, являются источником потенциальных ошибок и отказов ПС. Проявление дефекта в виде отказа зависит от того, какой путь будет выполнять специалист, чтобы найти ошибку в коде или во входных данных. Однако не каждый дефект ПС может вызвать отказ или может быть связан с дефектом в ПС или среды. Любой отказ может вызвать аномалию от проявления внешних ошибок и дефектов.
Ошибка (error) может быть следствием недостатка в одном из процессов разработки ПС, который приводит к неправильной интерпретации промежуточной информации, заданной разработчиком или при принятии им неверных решений.
Интенсивность отказов - это частота появления отказов или дефектов в ПС при ее тестировании или эксплуатации.
При выявлении отклонения результатов выполнения от ожидаемых во время тестирования или сопровождения осуществляется поиск, выяснение причин отклонений и исправление связанных с этим ошибок.
Модели оценки надежности ПС в качестве входных параметров используют сведения об ошибках, отказах, их интенсивности, собранных в процессе тестирования и эксплуатации.
10.2.2. Классификация моделей надежности
Как известно, на данный момент времени разработано большое количество моделей надежности ПС и их модификаций. Каждая из этих моделей определяет функцию надежности, которую можно вычислить при задании ей соответствующих данных, собранных во время функционирования ПС. Основными данными являются отказы и время. Другие дополнительные параметры связаны с типом ПС, условиями среды и данных.
Ввиду большого разнообразия моделей надежности разработано несколько подходов к классификации этих моделей. Такие подходы в целом основываются на истории ошибок в проверяемой и тестируемой ПС на этапах ЖЦ. Одной из классификаций моделей надежности ПО является классификация Хетча [10.10]. В ней предлагается разделение моделей на прогнозирующие, измерительные и оценочные (рис. 10.4).
Прогнозирующие модели надежности основаны на измерении технических характеристик создаваемой программы: длина, сложность, число циклов и степень их вложенности, количество ошибок на страницу операторов программы и др.
Например, модель Мотли-Брукса основывается на длине и сложности структуры программы (количество ветвей, циклов, вложенность циклов), количестве и типах переменных, а также интерфейсов. В этих моделях длина программы служит для прогнозирования количества ошибок, например, для 100 операторов программы можно смоделировать интенсивность отказов .
Модель Холстеда прогнозирует количество ошибок в программе в зависимости от ее объема и таких данных, как число операций ( " />
) и операндов ( " />
), а также их общее число ( ,N_" />
).
Время программирования программы предлагается вычислять по следующей формуле:


где - число Страуда (Холстед принял равным 18 - число умственных операций в единицу времени).
Объем вычисляется по формуле:


- максимальное число различных операций.
Измерительные модели предназначены для измерения надежности программного обеспечения, работающего с заданной внешней средой. Они имеют следующие ограничения:
- программное обеспечение не модифицируется во время периода измерений свойств надежности;
- обнаруженные ошибки не исправляются;
- измерение надежности проводится для зафиксированной конфигурации программного обеспечения.
Типичным примером таких моделей являются модели Нельсона и РамамуртиБастани и др.Модель оценки надежности Нельсона основывается на выполнении k-прогонов программы при тестировании и позволяет определить надежность
![R(k) = exp [-\sum<\nabla t_<j></p>
\lambda(t)>],](https://intuit.ru/sites/default/files/tex_cache/b49eac2e774618b741148f322ba28c63.jpg)
где " />
- время выполнения -прогона, )\nablaj]" />
и при \le 1" />
она интерпретируется как интенсивность отказов .

прогонах оценка надежности вычисляется по формуле


где - число прогонов программы.
Таким образом, данная модель рассматривает полученные количественные данные о проведенных прогонах.
Оценочные модели основываются на серии тестовых прогонов и проводятся на этапах тестирования ПC. В тестовой среде определяется вероятность отказа программы при ее выполнении или тестировании.
Эти типы моделей могут применяться на этапах ЖЦ. Кроме того, результаты прогнозирующих моделей могут использоваться как входные данные для оценочной модели. Имеются модели (например, модель Муссы), которые можно рассматривать как оценочную и в то же время как измерительную модель [10.16, 10.17].
Другой вид классификации моделей предложил Гоэл [10.18, 10.19], согласно которой модели надежности базируются на отказах и разбиваются на четыре класса моделей:
- без подсчета ошибок;
- с подсчетом отказов;
- с подсевом ошибок;
- модели с выбором областей входных значений.
Модели без подсчета ошибок основаны на измерении интервала времени между отказами и позволяют спрогнозировать количество ошибок, оставшихся в программе. После каждого отказа оценивается надежность и определяется среднее время до следующего отказа. К таким моделям относятся модели Джелински и Моранды, Шика Вулвертона и Литвуда-Вералла [10.20, 10.21].
Модели с подсчетом отказов базируются на количестве ошибок, обнаруженных на заданных интервалах времени. Возникновение отказов в зависимости от времени является стохастическим процессом с непрерывной интенсивностью, а количество отказов является случайной величиной. Обнаруженные ошибки, как правило, устраняются и поэтому количество ошибок в единицу времени уменьшается. К этому классу моделей относятся модели Шумана, Шика- Вулвертона, Пуассоновская модель и др. [10.21-10.24].
Модели с подсевом ошибок основаны на количестве устраненных ошибок и подсеве, внесенном в программу искусственных ошибок, тип и количество которых заранее известны. Затем определяется соотношение числа оставшихся прогнозируемых ошибок к числу искусственных ошибок, которое сравнивается с соотношением числа обнаруженных действительных ошибок к числу обнаруженных искусственных ошибок. Результат сравнения используется для оценки надежности и качества программы. При внесении изменений в программу проводится повторное тестирование и оценка надежности. Этот подход к организации тестирования отличается громоздкостью и редко используется из-за дополнительного объема работ, связанных с подбором, выполнением и устранением искусственных ошибок.
Модели с выбором области входных значений основываются на генерации множества тестовых выборок из входного распределения, и оценка надежности проводится по полученным отказам на основе тестовых выборок из входной области. К этому типу моделей относится модель Нельсона и др.
Таким образом, классификация моделей роста надежности относительно процесса выявления отказов, фактически разделена на две группы:
- модели, которые рассматривают количество отказов как марковский процесс;
- модели, которые рассматривают интенсивность отказов как пуассоновский процесс.
Фактор распределения интенсивности отказов разделяет модели на экспоненциальные, логарифмические, геометрические, байесовские и др.
Читайте также: