
Откуда браузер узнает как оформлять заголовки и гиперссылки
Обновлено: 30.06.2024
Гиперссылки действительно важны — они делают Интернет Интернетом. В этой статье представлен синтаксис, необходимый для создания ссылки, а также обсуждаются лучшие практики обращения со ссылками.
| Предварительные требования: | Базовое знакомство с HTML, описанное в статье Начало работы c HTML. Форматирование текста в HTML, описанное в статье Основы редактирования текста в HTML. |
|---|---|
| Задача: | Научиться эффективно использовать гиперссылки и связывать несколько файлов вместе. |
Что такое гиперссылка?
Гиперссылки — одно из самых интересных нововведений Интернета. Они были особенностью Сети с самого начала, но именно они превращают Интернет в Интернет. Они позволяют нам связывать наши документы с любым другим документом (или ресурсом), с которым мы хотим. С их помощью мы также можем связывать документы с их конкретными частями, и мы можем сделать приложения доступными на простом веб-адресе (сравните это с локальными приложениями, которые должны быть установлены, и другими такими же вещами). Почти любой веб-контент может быть преобразован в ссылку, так что когда вы кликаете по ней (или иным образом активируете), она заставляет веб-браузер перейти на другой веб-адрес (URL.)
Примечание: URL-адрес может указывать на файлы HTML, текстовые файлы, изображения, текстовые документы, видео и аудиофайлы и все остальное, что может жить в Интернете. Если веб-браузер не знает, как отображать или обрабатывать файл, он спросит вас, хотите ли вы открыть файл (в этом случае обязанность открытия или обработки файла передаётся в соответствующее локальное приложение на устройстве) или загрузить файл (в этом случае вы можете попытаться разобраться с ним позже).
Например, домашняя страница BBC содержит большое количество ссылок, которые указывают не только на множество новостей, но и на различные области сайта (меню), страницы входа / регистрации (пользовательские инструменты) и многое другое.

Анатомия ссылки
Простая ссылка создаётся путём обёртывания текста (или другого содержимого, смотрите Ссылки-блоки ), который вы хотите превратить в ссылку, в элемент <a> , и придания этому элементу атрибута href (который также известен как гипертекстовая ссылка, или цель), который будет содержать веб-адрес, на который вы хотите указать ссылку.
Это дало нам следующий результат:
Добавляем информацию через атрибут title
Другим атрибутом, который вы можете добавить к своим ссылкам, является — title . Он предназначен для хранения полезной информации о ссылке. Например, какую информацию содержит страница или другие вещи, о которых вам нужно знать. Например:
Вот что получилось (описание появится, если навести курсор на ссылку):
Примечание: Описание из атрибута title отображается только при наведении курсора, значит люди, полагающиеся на клавиатурные элементы управления для навигации по веб-страницам, будут испытывать трудности с доступом к информации, которую содержит title. Если информация заголовка действительно важна для удобства использования страницы, то вы должны представить её таким образом, который будет доступен для всех пользователей, например, поместив её в обычный текст.
Активное изучение: создаём собственную ссылку
Время упражнения: мы хотели бы, чтобы вы создали любой HTML-документ в текстовом редакторе на своём компьютере (наш базовый пример подойдёт.)
- Попробуйте добавить в тело HTML один или несколько абзацев или другие элементы, о которых вы уже знаете.
- Теперь превратите некоторые фрагменты документа в ссылки.
- Добавьте ссылкам атрибут title .
Ссылки-блоки
Как упоминалось ранее, вы можете превратить любой элемент в ссылку, даже блочный элемент. Если у вас есть изображение, которые вы хотели бы превратить в ссылку, вы можете просто поместить изображение между тегами <a></a>.
Примечание: вы узнаете гораздо больше об использовании изображений в Интернете в следующей статье.
Краткое руководство по URL-адресам и путям
Чтобы полностью понять адреса ссылок, вам нужно понять несколько вещей про URL-адреса и пути к файлам. Этот раздел даст вам информацию, необходимую для достижения этой цели.
URL-адреса используют пути для поиска файлов. Пути указывают, где в файловой системе находится файл, который вас интересует. Давайте рассмотрим простой пример структуры каталогов (смотрите каталог creating-hyperlinks.)

Корень структуры — каталог creating-hyperlinks . При работе на локальном веб-сайте у вас будет один каталог, в который входит весь сайт. В корне у нас есть два файла — index.html и contacts.html . На настоящем веб-сайте index.html был бы нашей домашней, или лендинг-страницей (веб-страницей, которая служит точкой входа для веб-сайта или определённого раздела веб-сайта).
В корне есть ещё два каталога — pdfs и projects . У каждого из них есть один файл внутри — project-brief.pdf и index.html , соответственно. Обратите внимание на то, что вы можете довольно успешно иметь два index.html файла в одном проекте, пока они находятся в разных местах файловой системы. Многие веб-сайты так делают. Второй index.html , возможно, будет главной лендинг-страницей для связанной с проектом информации.
Тот же каталог: Если вы хотите подключить ссылку внутри index.html (верхний уровень index.html ), указывающую на contacts.html , вам просто нужно указать имя файла, на который вы хотите установить ссылку, так как он находится в том же каталоге, что и текущий файл. Таким образом, URL-адрес, который вы используете — contacts.html :
Перемещение вниз в подкаталоги: Если вы хотите подключить ссылку внутри index.html (верхний уровень index.html ), указывающую на projects/index.html , вам нужно спуститься ниже в директории projects перед тем, как указать файл, который вы хотите. Это делается путём указания имени каталога, после которого идёт слеш и затем имя файла. Итак, URL-адрес, который вы используете - projects/index.html :
Перемещение обратно в родительские каталоги: Если вы хотите подключить ссылку внутри projects/index.html , указывающую на pdfs/project-brief.pdf , вам нужно будет подняться на уровень каталога, затем спустится в каталог pdf . "Подняться вверх на уровень каталога" обозначается двумя точками — .. — так, URL-адрес, который вы используете ../pdfs/project-brief.pdf :
Примечание: вы можете объединить несколько экземпляров этих функций в сложные URL-адреса, если необходимо, например:
../../../сложный/путь/к/моему/файлу.html .
Фрагменты документа
Можно ссылаться на определённую часть документа HTML (известную как фрагмент документа), а не только на верхнюю часть документа. Для этого вам сначала нужно назначить атрибут id элементу, с которым вы хотите связаться. Обычно имеет смысл ссылаться на определённый заголовок, поэтому это выглядит примерно так:
Затем, чтобы связаться с этим конкретным id , вы должны включить его в конец URL-адреса, которому предшествует знак решётки, например:
Вы даже можете использовать ссылку на фрагмент документа отдельно для ссылки на другую часть того же документа:
Абсолютные и относительные URL-адреса
Два понятия, с которыми вы столкнётесь в Интернете, — это абсолютный URL и относительный URL:
Абсолютный URL всегда будет указывать на одно и то же местоположение, независимо от того, где он используется.
Советуем вам основательно разобраться в этой теме!
Практика написания хороших ссылок
При написании ссылок рекомендуется следовать некоторым правилам. Давайте рассмотрим их.
Используйте чёткие формулировки описания ссылок
На вашей странице легко добавить ссылки. Но этого не совсем достаточно. Мы должны сделать наши ссылки доступными для всех читателей, независимо от их возможностей и инструментов просмотра страницы, которые они предпочитают. Например:
- Пользователям программ читающих с экрана нравится переходить по ссылкам на странице, читая адрес ссылки в тексте.
- Поисковые системы используют текст ссылки для индексирования файлов, поэтому рекомендуется включать ключевые слова в текст ссылки, чтобы эффективно описывать, куда ведёт ссылка.
- Пользователи часто бегло просматривают страницу, не читая каждое слово, и их глаза будут привлечены к тексту, который выделяется, например, ссылки. Им будет полезно описание того, куда ведёт ссылка.
Взгляните на этот пример:
Плохой текст ссылки: Нажми сюда, чтобы скачать Firefox
- Не пишите URL-адрес как часть текста ссылки. URL-адреса выглядят сложными, а звучат ещё сложнее, когда программы чтения с экрана читают их по буквам.
- Не пишите «ссылка» или «ссылки на» в тексте ссылки — это лишнее. Программы чтения с экрана сами проговаривают, что есть ссылка. На экране пользователи также видят, что есть ссылка, потому что ссылки, как правило, оформлены в другом цвете и подчёркнуты (подчёркивая ссылки, вы соблюдаете правила хорошего тона, поскольку пользователи привыкли к этому).
- Следите за тем, чтобы текст ссылки был как можно короче. Длинный текст ссылки особенно раздражает пользователей программ чтения с экрана, которым придётся услышать всё, что написано.
- Минимизируйте случаи, когда несколько копий одного и того же текста ссылок указывает на разные страницы. Это может вызвать проблемы для пользователей программ чтения с экрана, которые часто вызывают список ссылок — несколько ссылок, помеченных как «нажмите здесь», «нажмите здесь», «нажмите здесь», будут путать.
Используйте относительные ссылки, где это возможно
Из прочитанного выше, вы можете подумать, что всё время использовать абсолютные ссылки — хорошая идея; в конце концов, они не ломаются, когда страница перемещается. Тем не менее, лучше использовать относительные ссылки везде, где это возможно, в пределах одного сайта (при ссылке на другие сайты необходимо использовать абсолютную ссылку):
- Во-первых, гораздо проще прописать в коде относительные URL-адреса, как правило, они намного короче абсолютных URL-адресов, что значительно упрощает чтение кода
- Во-вторых, использование относительных URL-адресов эффективней по следующей причине. Когда вы используете абсолютный URL-адрес, браузер начинает поиск реального местоположения сервера запрашивая адрес у Domain Name System (DNS; также прочтите Как работает web), затем он переходит на этот сервер и находит файл, который запрашивается. С относительным URL-адресом проще: браузер просто ищет файл, который запрашивается на том же сервере. Используя абсолютные URL-адреса вместо относительных, вы постоянно нагружаете свой браузер дополнительной работой.
Создавая ссылки на не HTML ресурсы — добавляйте описание
Когда вы создаёте ссылку на файл, нажав на который можно загрузить документ PDF или Word или открыть просмотр видео, прослушивание аудио файла или перейти на страницу с другим, неожиданным для пользователя результатом (всплывающее окно или загрузка Flash-фильма), добавляйте чёткую формулировку, чтобы уменьшить путаницу. Отсутствие описания может раздражать пользователя. Приведём пример:
- Если вы используете соединение с низкой пропускной способностью и вдруг нажмёте на ссылку без описания, начнётся загрузка большого файла.
- Если у вас нет установленного Flash-плеера и вы нажмёте ссылку, то внезапно перейдёте на страницу с Flash-контентом.
Посмотрите на примеры, чтобы увидеть, как добавить описание:
Используйте атрибут download, когда создаёте ссылку
Когда создаёте ссылку на файл, который должен быть загружен, а не открыт в браузере, можете использовать атрибут download , чтобы создать имя файла по умолчанию для сохранения . Приведём пример ссылки для загрузки браузера Firefox 39:
Активное изучение: создание меню навигации
Для этого упражнения мы хотим, чтобы вы создали ссылки на страницы в меню навигации в многостраничном сайте. Это один из распространённых способов создания сайта: на каждой странице используется одна и та же структура страниц, включая одно и то же меню навигации, поэтому при нажатии ссылок создаётся впечатление, что вы остаётесь в одном месте: меню остаётся на месте, а контент меняется.
Вам нужно скачать или создать следующие страницы в одном каталоге (Смотрите navigation-menu-start):
- Добавьте неупорядоченный список в указанном месте в любом html-файле. Список должен состоять из имён страниц (index, projects и т.д.). Меню навигации обычно представляет собой список ссылок, поэтому создание неупорядоченного списка семантически верно.
- Создайте ссылки каждому элементу списка, ведущие на эти страницы.
- Скопируйте созданное меню в каждую страницу.
- На каждой странице удалите только ссылку, которая указывает на эту же страницу (на странице index.html удалить ссылку index и так далее). Дело в том, что, находясь на странице index.html, нам незачем видеть ссылку в меню на эту же страницу. С одной стороны, нам незачем ещё раз переходить на эту же страницу, с другой, такой приём помогает визуально определить, смотря на меню, в какой части сайта мы находимся.
Когда закончите задание, посмотрите, как это должно выглядеть:

Если не удаётся сделать, или вы не уверены, что сделали верно, посмотрите наш вариант navigation-menu-marked-up.
Ссылки электронной почты
Самыми простыми и часто используемыми формами mailto: являются subject, cc, bcc и body; дальше прописываем адрес электронной почты. Например:
Особенности и детали
Примечание: Значение каждого поля должно быть написано в URL-кодировке (то есть с непечатаемыми символами и пробелами percent-escaped). Обратите внимание на знак вопроса (?) для разделения основного адреса и дополнительных полей, амперсанд (&) для разделения каждого поля mailto: URL. Для этого используется стандартное описание URL запроса. Прочтите о методе GET, чтобы лучше понимать описание URL запроса.
Вот несколько примеров использования mailto URLs:
Заключение
Этой информации достаточно для создания ссылок! Вы вернётесь к ссылкам позже, когда начнёте изучать стили. Дальше вы рассмотрите семантику текста и более сложные и необычные возможности, которые будут полезны при создании контента сайта. В следующей главе будет рассматриваться продвинутое форматирование текста.

Сегодня быть онлайн — это привычное состояние для многих людей. Все мы покупаем, общаемся, читаем статьи, ищем информацию на разные темы. Сеть соединяет нас со всем миром, но прежде всего, она соединяет людей. Я сам пользуюсь интернетом уже 20 лет, и мои отношения с ним изменились восемь лет назад, когда я стал веб-разработчиком.
Разработчики соединяют людей.
Разработчики помогают людям.
Разработчики дают людям возможности.
Сервер отвечает запрашиваемым ресурсом, но также отправляет заголовки ответа, содержащие информацию о ресурсе или самом сервере.
Сеть должна быть безопасной
Раньше я никогда не чувствовал опасности, когда искал что-то в интернете. Но чем больше я узнавал о всемирной паутине, тем больше я беспокоился. Вы можете почитать, как хакеры меняют глобальные CDN-библиотеки, случайные сайты майнят криптовалюту в браузере своих посетителей, а также о том, как с помощью социальной инженерии люди регулярно получают доступ к успешным проектам с открытым исходным кодом. Это нехорошо. Но почему вас должно это волновать?
Если вы сегодня разрабатываете для веба, то не просто пишете код. Сегодня в веб-разработке над одним сайтом работает много людей. Возможно, вы также используете много открытого исходного кода. Кроме того, для маркетинговых целей вы можете включить несколько сторонних скриптов. Сотни людей предоставляют код, запущенный на вашем сайте. И разработчикам приходится работать в подобных реалиях.
Можно ли доверять всем этим людям и всему исходному коду?
Я не думаю, что следует доверять какому-либо стороннему коду. К счастью, есть способы защитить свой сайт и сделать его более безопасным. Кроме того, такие инструменты, как helmet могут быть полезны, например, для экспресс-приложений.
Если вы хотите проанализировать, сколько стороннего кода запускается на вашем сайте, можно посмотреть в панели разработчика или попробовать Request Map Generator.
CSP — четко укажите, что разрешено на вашем сайте
Однако CSP касается не только используемого протокола. Он предлагает детальные способы определения того, какие ресурсы и действия разрешены на вашем сайте. Вы можете, например, указать, какие скрипты должны выполняться или откуда загружать изображения. Если что-то не разрешено, браузер блокирует это действие и предотвращает потенциальные атаки на ваш сайт.
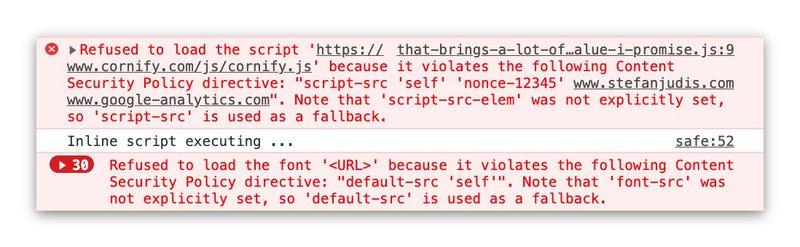
На момент написания статьи для CSP существовало 24 различных варианта конфигурации. Они варьируются от скриптов через таблицы стилей вплоть до сервис-воркеров.

Вы можете найти полный обзор на MDN.
Используя CSP, вы можете указать, что должен включать ваш сайт, а что нет.
Вышеприведенный набор правил предназначен для моего личного сайта, и если вы считаете, что этот пример определения CSP очень сложный, то вы абсолютно правы. Я внедрил у себя этот набор с третьей попытки, развёртывая и снова откатывая, потому что он несколько раз ломал сайт. Но есть способ получше.
Чтобы избежать взлома вашего сайта, CSP также предоставляет режим только для отчетов.
Используя режим Content-Security-Policy-Report-Only , браузеры просто записывают ресурсы, которые были бы заблокированы, вместо их фактической блокировки. Этот механизм отчетности позволяет проверить и настроить ваш набор правил.
Рекомендуемый процесс выглядит так: сначала запустите CSP в режиме отчета, проанализируйте входящие нарушения с реальным трафиком, и только тогда, когда не будет обнаружено нарушений ваших контролируемых ресурсов, включите его.
Общее внедрение CSP

Сеть должна быть доступной
Пока я пишу эту статью, я сижу перед относительно новым MacBook, используя быстрое домашнее Wi-Fi-подключение. Разработчики часто забывают, что такая ситуация не является стандартной для большинства наших пользователей. Люди, посещающие наши сайты, пользуются старыми телефонами и сомнительными соединениями. Тяжелые и перегруженные сайты с сотнями запросов оставляют им плохое впечатление.
И дело не только во впечатлении. Люди платят различные суммы за трафик в зависимости от места проживания. Представьте себе, вы создаете сайт для больницы. Информация на нём может иметь решающее значение и спасти жизни людей. Если страница на сайте больницы имеет размер 5 Мб, то она не только будет медленно работать, но и может оказаться слишком дорогой для тех, кто больше всего в ней нуждается. Цена пяти мегабайтов трафика в Европе или США ничтожна по сравнению с ценой в Африке. Разработчики несут ответственность за доступность веб-страниц для всех. Эта ответственность включает в себя предоставление правильных ресурсов, выбор правильных инструментов (действительно ли вам нужен JS-фреймворк для лендинга?) и недопущение запросов.
Cache-Control — избегайте запросов на неизменные ресурсы
Сегодня сайт может содержать сотни ресурсов, от CSS до скриптов и изображений. Используя заголовок Cache-Control , разработчики могут указать, как долго ресурс должен считаться «свежим» и может отдавать из кэша браузера.
При правильной настройке Cache-Control передача данных сохраняется, и файлы могут использоваться из кэша браузера в течение определенного количества секунд ( max-age ). Браузеры должны повторно проверять кэшированные ресурсы по истечении этого периода времени.
Однако, если посетители обновляют страницу, браузеры всё равно повторно проверяют её, включая ссылки на ресурсы, чтобы убедиться, что кэшированные данные всё ещё действительны. Серверы отвечают заголовком 304, сигнализируя, что кэшированные данные пока действительны, или заголовком 200 при передаче обновленных данных. Это позволяет сохранить переданные данные, но не обязательно сделанные запросы.
Именно здесь вступает в игру функция immutable .
Immutable — никогда не запрашивать ресурс дважды
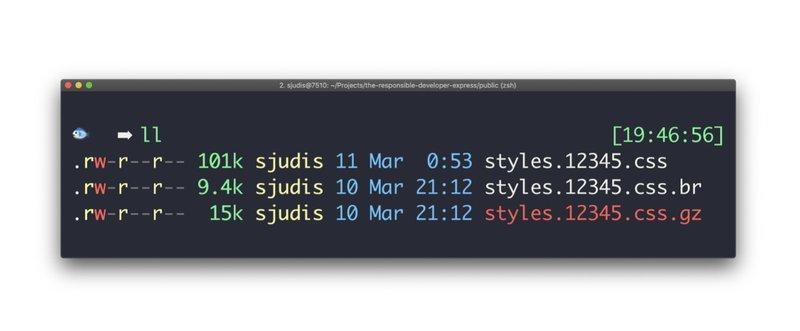
В современных frontend-приложениях файлы CSS и скриптов обычно имеют уникальные имена, например, styles.123abc.css . Имя этого файла зависит от содержимого. И при изменении содержимого файлов меняются и их имена.
Эти уникальные файлы потенциально могут храниться в кэше вечно, включая ситуацию, когда пользователь обновляет страницу. Функция immutable может запретить браузеру повторную проверку ресурса в определенный промежуток времени. Это очень важно для объектов с контрольными суммами, и помогает избежать повторных проверочных запросов.
Реализовать оптимальное кэширование очень сложно, а особенно браузерное кэширование не слишком интуитивно понятно, поскольку имеет различные конфигурации. Я рекомендую ознакомиться со следующими материалами:
- Гарри Робертс написал отличное руководство по управлению кэшем и его настройкам.
- Джек Арчибальд дал советы по лучшим методикам кэширования с иллюстрациями.
- Илья Григорик предложил отличную технологическую схему для кэширования заголовков.
Accept-Encoding — максимальное сжатие (до минимума)
С помощью Cache control мы можем сохранять запросы и уменьшать объем данных, которые многократно передаются по сети. Мы можем не только экономить запросы, но и сокращать то, что передается.
Отдавая ресурсы, разработчики должны позаботиться о том, чтобы отправлять как можно меньше данных. Для текстовых ресурсов, таких как HTML, CSS и JavaScript, сжатие играет важную роль в экономии передаваемых данных.
Самым популярным методом сжатия сегодня является GZIP. Серверам хватает мощности для сжатия текстовых файлов на лету и предоставления сжатых данных при запросе. Но GZIP уже не самый лучший вариант.
Если вы взглянете на создаваемые браузером запросы текстовых файлов, таких как HTML, CSS и JavaScript, и проанализируете заголовки, то найдете среди них accept-encoding .
Этот алгоритм сжатия был создан с учетом небольшого размера файлов. Если вы попробуете сжать файл вручную на вашем локальном устройстве, то обнаружите, что Brotli действительно сжимает лучше, чем GZIP.
Вы, возможно, слышали, что сжатие Brotli выполняется медленнее. Причина в том, что Brotli имеет 11 режимов сжатия, и по умолчанию выбирается тот, при котором получаются файлы наименьшего размера, что удлиняет процедуру. GZIP, с другой стороны, имеет 9 режимов, и по умолчанию выбирается тот, при котором учитывается как скорость сжатия, так и размера файла. В результате режим Brotli по умолчанию непригоден для сжатия «на лету», но если изменить режим, то можно добиться сжатия небольших файлов с той же скоростью, что и у GZIP. Вы можете использовать его для сжатия на лету и рассматривать как потенциальную замену GZIP для поддерживающих браузеров.
Кроме того, если вы хотите максимально экономить файлы, то можете забыть о динамическом сжатии и предварительно сгенерировать оптимизированные GZIP-файлы с помощью файлов zopfli и Brotli для их статического обслуживания.
Если вы хотите прочитать больше о сжатии Brotli и его сравнении с GZIP, сотрудники компании Akamai провели обширное исследование на эту тему.
Accept и Accept-CH — обслуживайте индивидуальные ресурсы для пользователя
Оптимизация текстовых ресурсов очень важна для экономии килобайтов, но как насчёт более тяжелых ресурсов, таких как изображения, чтобы сэкономить ещё больше объёма данных?
Accept — обслуживание изображений правильного формата
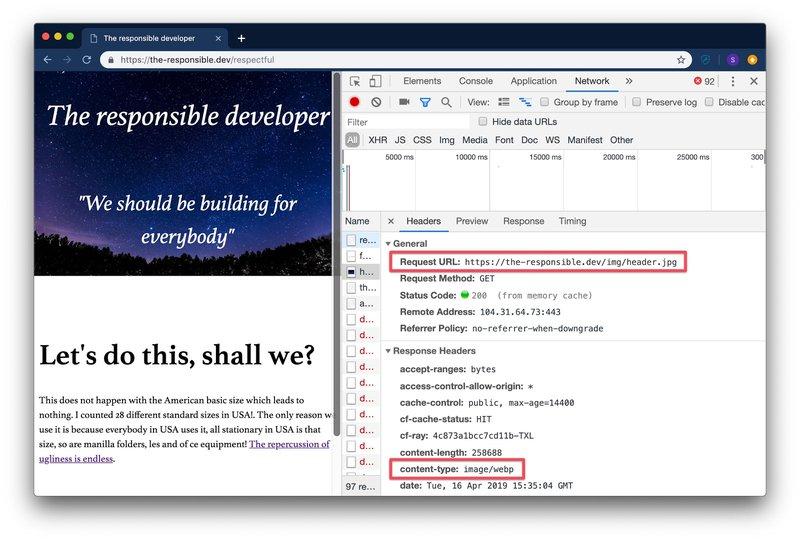
Браузеры не только показывают нам, какие алгоритмы сжатия они понимают. Когда браузер запрашивает изображение, он также предоставляет информацию о том, какие форматы файлов он понимает.
Несколько лет велась борьба вокруг нового формата изображений, но выиграл webp. Webp — это формат изображений, изобретенный Google, и поддержка этого формата сейчас очень актуальна.
Используя этот заголовок запроса, разработчики могут передавать изображение webp , даже если браузер запросил image.jpg , в результате чего размер файла будет меньше. Дин Хьюм написал хорошее руководство о том, как это применять. Очень круто!
Accept-CH — обслуживание изображений правильного размера
Вы также можете включить клиентские подсказки для поддерживающих эту функцию браузеров. Клиентские подсказки — это способ сказать браузерам, чтобы они посылали дополнительную информацию о ширине области просмотра, ширине изображения и даже сетевых условиях, таких как RTT (время на передачу и подтверждение) и типе соединения, например 2g .
Вы можете активировать подсказки, добавив мета-элемент:
Или задав заголовки в исходном запросе HTML:
В последующих запросах браузеры начнут посылать дополнительную информацию за определенный промежуток времени ( Accept-CH-Lifetime в секундах), что может помочь разработчикам адаптировать изображения к условиям пользователя, не меняя HTML.
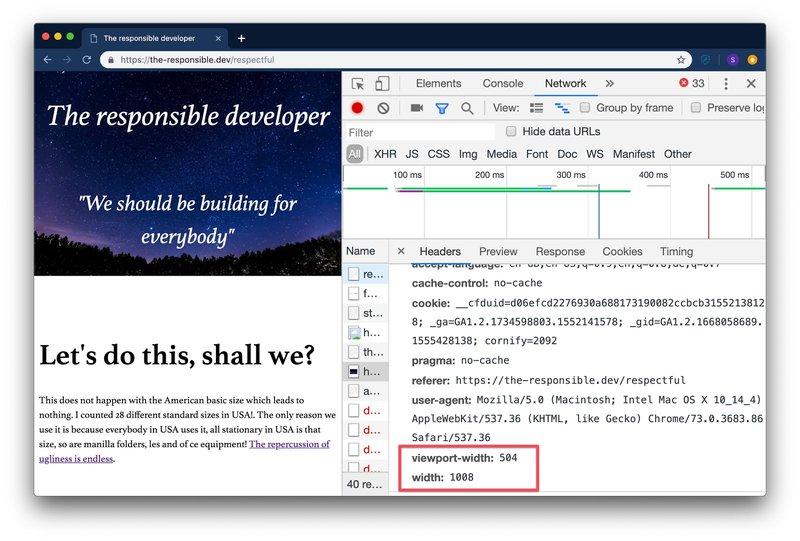
Например, для получения дополнительной информации, такой как ширина изображения на стороне сервера, вы можете снабдить свои изображения атрибутом sizes , чтобы дать браузеру дополнительную информацию о том, как эти изображения будут выглядеть.
С полученным заголовком ответа Accept-CH и изображениями с атрибутом sizes браузеры будут включать заголовки viewport-width и width в запросы изображений, показывая вам, какое изображение подойдёт лучше всего.
Имея поддерживаемый формат и размеры изображения, вы можете отправлять адаптированные данные без необходимости записывать ненадежные элементы изображений и обращать внимание только на формат и размер файлов, как показано ниже.
Если у вас есть доступ к ширине области просмотра (viewport) и размеру изображений, вы можете на своих серверах поставить логику изменения размера ресурсов во главу угла.
Однако нужно учитывать, что не следует создавать изображения для любой ширины просто потому, что у вас есть точная ширина изображения. Отправка изображений для определенного диапазона размеров ( image-200 , image-300 , . ) помогает использовать CDN-кэширование и экономит время вычислений.
Кроме того, с такими современными технологиями, как service worker’ы, вы даже можете перехватывать и изменять запросы прямо в клиенте, чтобы обслуживать лучшие файлы изображений. С включенными клиентскими подсказками service worker’ы получают доступ к информации о макетах, и в сочетании с API изображений, как, например, Cloudinary, вы можете настроить url изображения прямо в браузере для получения картинок надлежащего размера.
Если вы ищете более подробную информацию о клиентских подсказках, можете ознакомиться со статьями Джереми Вагнера или Ильи Григорика на эту тему.
Сеть должна быть бережной
Поскольку каждый из нас проводит в сети много часов в день, есть последний аспект, который я считаю очень важным — сеть должна быть бережной.
Preload — сокращение времени ожидания
Будучи разработчиками, мы ценим время наших пользователей. Никто не хочет терять время. Как уже говорилось в предыдущих главах, предоставление нужных данных играет большую роль в экономии времени и трафика. Речь идёт не только о том, какие запросы делаются, но и о сроках и порядке их выполнения.
Приведу пример: если вы добавите на сайт таблицу стилей, браузеры не будут ничего показывать, пока она не загрузится. Пока на экране ничего не отображается, браузер продолжает анализировать HTML в поисках других ресурсов для запрашивания. После загрузки и парсинга таблицы стилей в ней могут оказаться ссылки на другие важные ресурсы, такие как шрифты, которые тоже могут быть запрошены. Этот процесс может увеличить время загрузки страницы для ваших посетителей.
Используя Rel=preload вы можете дать браузеру информацию о том, какие ресурсы будут запрошены в ближайшее время.
Можете предварительно загрузить ресурсы через HTML-элементы:
Таким образом, браузер получает заголовок или находит элемент ссылки, и немедленно запрашивает ресурсы, чтобы они уже находились в кэше, когда понадобятся. Этот процесс экономит время ваших посетителей.
Для оптимальной предварительной загрузки ресурсов и понимания всех конфигураций я рекомендую обратить внимание на следующие материалы:
-
является экспертом по предварительной загрузке, он опубликовал прекрасный материал по этой теме.
подробно рассказал о preload и других инструментах, таких как prefetch и preconnect.
Feature-Policy — не раздражайте других
Меньше всего я хочу видеть сайты, запрашивающие у меня разрешения без причины. Я могу лишь процитировать своего коллегу Фила Нэша по этому поводу.
Не требуйте разрешение при загрузке страницы. Разработчики должны относиться с уважением и не создавать сайты, раздражающие посетителей. Люди просто кликают на все окна с разрешениями. Если мы не используем их правильно, то сайты и разработчики теряют доверие, а новые блестящие функции — свою привлекательность.
Но что, если ваш сайт обязательно должен включать много стороннего кода, и все эти скрипты запускают множество диалоговых окон с разрешением? Как убедиться, что все включённые скрипты ведут себя правильно?
Именно здесь в игру вступает заголовок Feature-Policy. С его помощью вы можете указать, какие функции разрешены, и ограничить всплывающие диалоговые окна с разрешениями, которые могут быть вызваны сторонним кодом, исполняемым на вашем сайте.
Вы можете настроить это поведение для сайта с помощью заголовка. Также можно задать этот заголовок для встроенного контента, например, плавающих фреймов, которые могут быть обязательными для интеграции со сторонними разработчиками.
На момент написания статьи заголовок Feature-Policy был, скорее, экспериментальным, но интересно посмотреть на его будущие возможности. В недалеком будущем разработчики смогут не только ограничивать себя и не допускать появления раздражающих диалоговых окон, но также блокировать неоптимизированные данные. Эти функции существенно улучшат работу пользователей.

Вы можете найти полный обзор на MDN.
Глядя на список выше, вы можете вспомнить о самом раздражающем моменте — push-уведомлениях. Оказалось, что применение Feature-Policy для push-уведомлений сложнее, чем ожидалось. Если вы хотите узнать больше, можете подписаться на соответствующую тему на GitHub.
Благодаря feature policy можете быть уверены, что вы и сторонние ресурсы не превратите ваш сайт в гонку за разрешениями, которая, к сожалению, уже стала привычной для многих сайтов.
Сеть должна быть для всех
Я знаю, что создание отличного сайта сегодня — очень сложная задача. Разработчики должны учитывать дизайн, устройства, фреймворки, и да… заголовки тоже играют определённую роль. Надеюсь, эта статья даст вам некоторые идеи, и вы будете учитывать безопасность, доступность и уважительность в ваших следующих веб-проектах, потому что это именно те факторы, которые делают сеть по-настоящему отличным местом для всех.

Когда много лет назад придумали HTML, мир был совсем другим. Авторы спецификации вдохновлялись текстовыми документами, где в одном потоке подряд шли абзацы, списки, таблицы, картинки и, конечно, заголовки. Прямо как в ваших рефератах и курсовых: самый большой заголовок — название, заголовки поменьше — части или главы.
В HTML с тех пор шесть уровней заголовков: от <h1> до <h6> . Они озаглавливают всё, что за ними следует и образуют неявные секции. Такие логические части страницы. Неявные они потому, что закрываются только когда появляется следующий заголовок.
Но секции лучше задавать явно с помощью элемента <section> , помните третий выпуск? Эти два фрагмента идентичны, с точки зрения семантики, но этот гораздо понятнее, хоть и многословнее.
Из-за такой системы неявных секций, спецификация настойчиво рекомендует не использовать элементы <h*> для подписей под заголовками. Это обычный параграф, а заголовок должен обозначать отдельную часть содержимого. В спецификации есть глава с примерами разметки сложных элементов: подписи, крошки, диалоги — почитайте.
Ладно! Раз у нас есть явные секции, то по вложенности легко определить отношение частей. Так может браузеры сами догадаются какого уровня заголовки нужны? А то считать: <h1> , <h2> , аш… сбился. Так было бы удобнее менять части кода местами.
Такая же идея пришла в голову авторам HTML5 и они описали в спецификации алгоритм аутлайна. Он разрешает использовать на странице только <h1> , а важность обозначать вложенностью структурных элементов вроде <article> и <section> .
Разработчикам идея очень понравилась, многие даже бросились её внедрять. Но вот беда: алгоритм аутлайна до сих не внедрил ни один браузер, читалка или поисковик. На таких страницах все заголовки кричат, что они №1 и самые важные. Но если важно всё, то уже ничего не важно.
Не надо так делать, об этом теперь пишет сама спецификация. За уровнем заголовков нужно следить самим. На самом деле, это не так сложно: на типичной странице вряд ли наберётся структурных частей больше, чем на 3 уровня. Так что не ленитесь.
Нет, погоди. Я ставлю класс на <div> и все сразу видят — это самый большой заголовок, ставлю другой класс — заголовок становится меньше, видно же. Зачем тогда эта ерунда с расчётом уровней, если есть CSS?
Вы конечно правы, стили создают визуальную модель важности: крупный чёрный текст важнее, меленький серенький вообще не важен. Но только если вы смотрите на такую страницу.
Есть две важные группы пользователей, которые читают вашу страницу по тегам разметки. Они не смотрят насколько крупный и чёрный ваш <div> — чтобы найти на странице самое важное, они ищут <h1> . Это читалки и роботы. С роботами всё понятно: это поисковики, которым нужно помогать понимать ваши страницы.
Читалками или скринридерами пользуются люди, которые плохо или совсем не видят ваши интерфейсы, или не могут управлять браузером привычным образом. VoiceOver, NVDA, JAWS читают содержимое вслух и ориентируются только по значимым тегам. Элементы div и span не значат ни-че-го, какие бы классы и стили вы не накрутили. Такой сайт — как газета без заголовков, просто месиво текста.
Да какая газета! Очнись, 2017 на дворе, я изоморфное одностраничное приложение делаю, а не стенгазету. У меня тут стейты компонентов — нафига семантика там, где нет текста? Очень хороший вопрос.
Все читалки идут по странице тег за тегом, от первого к последнему. И читают подряд всё, что внутри. Крайне неэффективно: каждая страница начинается с шапки и пока её пройдёшь, забудешь за чем шёл. Поэтому у читалок есть специальные режимы, показывающие только важные части страницы. Структурные элементы header, nav, main и другие, все ссылки, все заголовки.
Если вывести все заголовки и прочитать их, можно составить ментальную, а не визуальную модель страницы. А потом взять и сразу перейти к нужной секции, выбрав её заголовок. Меню, поиск, каталог, настройки, логин — все эти части вашего приложения можно озаглавить, чтобы упростить доступ к ним.
Но бывает, что в дизайне нет заголовков для важных частей. Дизайнер рисует, ему всё ясно: меню с котлетой, поиск с полем и так далее. Но это не должно мешает вам делать доступные интерфейсы. Расставьте нужные заголовки, а потом доступно их спрячьте. Как? Только не display: none , его читалки игнорируют. Есть такой паттерн visually hidden, подробнее в описании к видео.
Думайте не только о том, как выглядит ваша вёрстка, но и о том, насколько логично организована разметка. Не забывайте о заголовках: пусть стили показывают, а заголовки рассказывают о ваших страницах или приложениях.
Этичный хакинг и тестирование на проникновение, информационная безопасность
Современные веб-сайты становятся всё сложнее, используют всё больше библиотек и веб технологий. Для целей отладки разработчиками сложных веб-сайтов и веб-приложений потребовались новые инструменты. Ими стали «Инструменты разработчика» интегрированные в сами веб-браузеры:
- Chrome DevTools
- Firefox Developer Tools
Они по умолчанию поставляются с браузерами (Chrome и Firefox) и предоставляют много возможностей по оценке и отладке сайтов для самых разных условий. К примеру, можно открыть сайт или запустить веб-приложение как будто бы оно работает на мобильном устройстве, или симулировать лаги мобильных сетей, или запустить сценарий ухода приложения в офлайн, можно сделать скриншот всего сайта, даже для больших страниц, требующих прокрутки и т.д. На самом деле, Инструменты разработчика требуют глубокого изучения, чтобы по-настоящему понять всю их мощь.
В предыдущих статьях я уже рассматривал несколько практических примеров использования инструментов DevTools в браузере:
Эта небольшая заметка посвящена анализу POST запросов. Мы научимся просматривать отправленные методом POST данные прямо в самом веб-браузере. Научимся получать их в исходном («сыром») виде, а также в виде значений переменных.
По фрагменту исходного кода страницы видно, что данные из формы передаются методом POST, причём используется конструкция onChange="this.form.submit();":

Как увидеть данные, переданные методом POST, в Google Chrome
Итак, открываем (или обновляем, если она уже открыта) страницу, от которой мы хотим узнать передаваемые POST данные. Теперь открываем инструменты разработчика (в предыдущих статьях я писал, как это делать разными способами, например, я просто нажимаю F12):

Теперь отправляем данные с помощью формы.
Переходим во вкладку «Network» (сеть), кликаем на иконку «Filter» (фильтр) и в качестве значения фильтра введите method:POST:

Как видно на предыдущем скриншоте, был сделан один запрос методом POST, кликаем на него:

- Header — заголовки (именно здесь содержаться отправленные данные)
- Preview — просмотр того, что мы получили после рендеренга (это же самое показано на странице сайта)
- Response — ответ (то, что сайт прислал в ответ на наш запрос)
- Cookies — кукиз
- Timing — сколько времени занял запрос и ответ
Поскольку нам нужно увидеть отправленные методом POST данные, то нас интересует столбец Header.
Там есть разные полезные данные, например:
- Request URL — адрес, куда отправлена информация из формы
- Form Data — отправленные значения
Пролистываем до Form Data:

Там мы видим пять отправленных переменных и из значения.
Если нажать «view source», то отправленные данные будут показаны в виде строки:

Вид «view parsed» - это вид по умолчанию, в котором нам в удобном для восприятия человеком виде показаны переданные переменные и их значения.
Как увидеть данные, переданные методом POST, в Firefox
В Firefox всё происходит очень похожим образом.
Открываем или обновляем нужную нам страницу.
Открываем Developer Tools (F12).
Отправляем данные из формы.
Переходим во вкладку «Сеть» и в качестве фильтра вставляем method:POST:

Кликните на интересующий вас запрос и в правой части появится окно с дополнительной информацией о нём:

Переданные в форме значения вы увидите если откроете вкладку «Параметры»:


Другие фильтры инструментов разработчика
Для Chrome кроме уже рассмотренного method:POST доступны следующие фильтры:
Читайте также: