
Программа для копирования голоса другого человека на айфон
Обновлено: 06.07.2024

Проблема синтеза речи из текста (Text-to-Speech, TTS) представляет собой одну из классических задач для искусственного интеллекта. Цель ИИ – автоматизировать процесс чтения текста, основываясь на наборах данных, содержащих пары «текст – аудиофайл».
Одной из важных проблем синтеза речи является задача создания образа голоса со всеми его характерными особенностями. Соответствующие наборы методик называют технологией клонирования голоса (англ. voice changing, voice cloning).
Решение указанной проблемы имеет множество практических приложений:
- адаптация голосов актёров при локализации фильмов
- озвучивание персонажей игр
- голосовые поздравления
- начитка аудиокниг, в том числе клонирование голосов родителей для сказок, прочитанных профессиональными дикторами
- создание аудио- и видеокурсов
- рекламные видеоролики и аудиореклама
- голоса ботов и умных устройств, персонализированных голосовых помощников
- синтез устной речи естественного звучания для немых людей, в том числе для людей, утративших возможность говорить из примеров их собственной речи
- адаптация устной речи под модель местного акцента
Очевидно, что подобные технологии могут применяться с преступными целями: мошенничество, телефонное хулиганство, компрометирование в результате совмещения с технологией DeepFake. Поэтому кроме методов клонирования голоса важно разрабатывать средства для предотвращения незаконного использования технологии.
Для обучения системы необходимо иметь большое количество сопоставленных аудиозаписей и текстов. В случае голосов знаменитостей можно прибегать к помощи записей публичных выступлений, интервью, результатам творческой деятельности и т. п. В качестве текстовых пар могут применяться стенограммы или тексты, полученные в результате коррекции автоматически распознанной речи.
Отличительной особенностью последних разработок является то, что для создания правдоподобного образа «голосовой мишени» достаточно всё меньших интервалов звучащей устной речи.
Современное состояние
В сфере создания инструментов для клонирования голоса работают множество команд, стремящихся к коммерциализации программных продуктов. По приведённым ниже ссылкам вы можете оценить текущее состояние технологии:
-
(предоставляется демоверсия программы).
- Vera Voice, созданный компанией Screenlife Technologies Тимура Бекмамбетова и командой проекта «Робот Вера». Недавно команда показала пример адаптации голосов русских знаменитостей:
(есть демо для 27 языков, включая русский). (можно загрузить демоверсию на 3 часа речи).
Другие компании стараются обойти стороной этический вопрос за счёт использования вместо клонирования голоса нейросетевых систем синтеза-смешения множества голосов. Таким коммерческим продуктом является, например, Yandex SpeechKit.
В связи с тем, что данная технология представляет конкурентный интерес для множества IT-компаний, проекты с открытым исходным кодом крайне редки. В этой статье мы остановимся на редком свободном проекте Real-Time Voice Cloning. Этот открытый репозиторий является результатом применения технологии переноса обучения SV2TTS, описанной в научной публикации (сэмплы, полученные в результате применения подхода).
Автор библиотеки с июня 2019 участвует в упомянутом выше коммерческом проекте Resemble.AI и уделяет репозиторию меньше времени, но ничто не мешает вам сделать собственный форк проекта.
Алгоритм клонирования голоса
Чтобы компьютер мог читать вслух текст, ему нужно понимать две вещи: что он читает и как это произнести. Поэтому в проекте Real-Time Voice Cloning система клонирования принимает два входных источника: текст, который необходимо озвучить, и образец голоса, которым этот текст должен быть прочитан.

С технической точки зрения система разбита на три компонента:
- Переданный аудиофайл с образцом речи, записанным в виде звуковой дорожки, преобразуется кодером речи (speaker encoder) в векторное представление фиксированной размерности.
- Переданный текст также кодируется в векторное представлении кодером текста (text encoder). Объединение речевого вектора и вектора текста декодируется в спектрограмму. Кодер текста, конкатенатор векторов и декодер (на схеме объединены синим цветом) представляют собой структуру синтезатора речи.
- Вокодер (vocoder, виртуальное устройство синтеза речи) преобразует спектрограмму в звуковую форму.
Модели трёх выделенных компонентов обучаются независимо друг от друга.
Где взять данные?
Объёмы информации, необходимой для качественного обучения системы клонирования, составляют десятки и сотни Гб. В рассматриваемой библиотеке для хранения датасетов служит одна общая директория. Все сценарии предварительной обработки данных выводят результаты в новый каталог SV2TTS , создаваемый в корневом каталоге датасетов. Внутри этой директории появится каталог для каждой модели: кодера, синтезатора и вокодера.
Для обучения кодера речи можно обратиться к следующим библиотекам:
-
(зеркало): набор данных train-other-500 (извлеките как LibriSpeech/train-other-500 ). : наборы данных Dev A–D, в том числе набор метаданных (извлеките как VoxCeleb1/wav и VoxCeleb1/vox1_meta.csv ).
: наборы данных Dev A–H (извлеките как VoxCeleb2/dev ).
Для обучения синтезатор и вокодера:
-
: наборы данных train-clean-100 (зеркало) и train-clean-360 (зеркало) – извлеките как LibriSpeech/train-clean-100 and LibriSpeech/train-clean-360 (только если у вас уже есть LibriSpeech): объедините структуру каталогов с загруженными вами наборами данных LibriSpeech
Если вы решили с головой погрузиться в данную тему, обратите внимание на библиотеку Python для работы с аудиодатасетами audiodatasets:
Будьте осторожны: при установке библиотека загружает более 100 Гб данных трех наборов:
Перечислим также другие датасеты, которые не проверялись в рассматриваемой библиотеке, но применимы для обучения, в том числе корпуса русскоязычной устной речи:
Использование предобученных моделей
Имеется инструкция по переносу проекта с помощью Docker, здесь мы рассмотрим установку на локальной машине. Учтите, что наличие GPU является обязательным. Клонируем репозиторий:
В качестве языка программирования используется Python 3, автор рекомендует версию 3.7. В связи с тем, что репозиторий предполагает привлечение вполне конкретных версий библиотек, рекомендуем питонистам пускать в ход виртуальное окружение.
Переходим в папку и устанавливаем необходимые зависимости:
Также потребуется фреймворк глубокого обучения PyTorch (версия не ниже 1.0.1).
Далее необходимо загрузить предобученные модели (архив на Google drive, зеркало). Согласно с вышеописанной схеме загруженный архив содержит три директории для трех моделей. Их нужно слить вместе с соответствующими директориями корневого каталога библиотеки.
Проверить правильность конфигурации можно ещё до загрузки датасетов:
Если все тесты пройдены (вы увидите строку All tests passed ), можно двигаться дальше. Скрипт предложит указать пути к файлам примеров, но для работы удобнее обратиться кграфическому интерфейсу:
Если у вас уже загружены датасеты, то можно сразу указать путь к директории:
Чтобы просто поиграть с программой, достаточно наименьшего по объёму датасета LibriSpeech/train-clean-100 (см. выше).
Пример результата вызова интерфейса:

Для первой пробы вы можете нажать под каждым разделом кнопки Random , чтобы выбрать случайный аудиопример, затем Load , чтобы загрузить голосовой ввод в систему. Выпадающий список Dataset служит для выбора набора данных, Speaker – для выбора персоны, Utterance – для произносимой фразы. Чтобы услышать как звучит отрывок, просто нажмите Play . Для запуска алгоритма нажмите Synthesize and vocode . С помощью кнопки Record one можно записать свой собственный сэмпл.
Пример работы с интерфейсом без обучения нейросетей представлен в следующем видеоролике:
Процесс обучения
Вместо предобученных моделей можно также задействовать модели, обученные на других примерах. Процесс обучения происходит посредством последовательного запуска скриптов той же библиотеки. Для того, чтобы узнать дополнительную информацию о каждом из скриптов, при используйте запуске из командной строки добавляйте аргумент -h .
Начинаем с подготовки данных для обучения кодера:
Для обучения кодер использует окружение visdom . Инструменты окружения выглядят следующим образом:

При необходимости вы можете отключить окружение с помощью аргумента --no_visdom .
Далее запускаем два скрипта, генерирующих данные для синтезатора. Начинаем с аудиофайлов:
Теперь вы можете обучить синтезатор:
Синтезатор будет выводить сгенерированные аудио и спектрограммы в каталог моделей. Используем синтезатор для генерации обучающих данных вокодера:
Наконец, обучаем вокодер:
Вокодер выводит сгенерированные аудиофайлы в директорию модели.
При возникновении вопросов относительно работы библиотеки мы также рекомендуем ознакомиться с диссертацией автора. Там же приведены ссылки на научные работы, посвящённые теме клонирования и изменения голоса.

Интернет гигант, и по совместительству «китайский Google», отчитался о работе, проведённой в сфере развития искусственного интеллекта. Компания представила интересный программный продукт, работающий с нейронными сетями, который способен за секунды клонировать голос любого человека. Программе достаточно проанализировать короткий фрагмент исходника, и на выходе получается неотличимый от оригинала клон голоса. Более того, помимо точных характеристик тембра и прочего, программа умеет придавать голосу особенности, к примеру, акцент.
Этот вариант является более продвинутой версией программы, которая имитировала голос, анализируя довольно длинные фрагменты образцов, но специалисты подразделения Deep Voice представили год назад продукт, которому хватает всего получасового фрагмента. Однако конкуренты тоже не спят, программа VoCo от знаменитой компании Adobe может имитировать речь, обработав двадцатиминутный материал, а молодая компания Lyrebird из Канады вообще продемонстрировала удивительные результаты – их программа могла создать клон на основе всего минутного фрагмента исходника.
Сферы применения

И вот новая подвижка в этом направлении от Baidu, теперь программе достаточно изучить всего несколько секунд исходника. Впечатляет, но для чего это всё, какая практическая польза от подобной технологии? О сути, это просто игрушка, баловство. Но не стоит спешить с выводами, поскольку точек приложения может быть очень много. Даже банальная болезнь, когда человек лишается на время или постоянно способности говорить. А технология ему эту способность вернёт, пусть и таким не очень естественным образом. А если у вас неспокойный ребёнок, не желающий засыпать, пока не услышит сказку от мамы, её голоса. И если вам некогда, либо вы далеко, то голос ваш сам прибудет к вашему ребёнку. Со всеми интонациями и характеристиками, даже если нет возможности связаться по телефону. Кроме того, голосовые ассистенты теперь будут говорить с вами тем голосом, который вам приятен и знаком.
Обратная сторона

Да, обратная сторона имеется у любой технологии, даже самой мирной на первый взгляд. В нашем случае, это злоупотребления технологией, голос известных людей могут использовать несанкционированно и в не очень законных целях. Сейчас лучшие системы распознавания голоса в подавляющем большинстве случаев идентифицируют клонированный голос как оригинал, это более 95 процентов. В этом кроются опасности, технология станет доступна широким массам, и случаи мошенничества не заставят себя ждать.

Говорят, ещё в советское время на телефонных станциях установили оборудование для прослушки разговоров. Естественно, записать и физически прослушать все разговоры тогда не было возможности, зато эффективно работала технология голосовой идентификации. По образцу голоса конкретного человека система мгновенно срабатывала — на прослушку или запись, с какого бы телефона он ни звонил. Эти технологии доступны и сегодня, вероятно, используются в оперативно-разыскной деятельности. Голос человека уникален, как его отпечатки пальцев.
Благодаря передовым разработкам в области ИИ теперь злоумышленники смогут пустить оперативников по ложному следу. 24 апреля 2017 года канадский стартап Lyrebird анонсировал первый в мире сервис, с помощью которого можно подделать голос любого человека. Для обучения системы достаточно минутного образца.
Сайт Lyrebird объясняет, что на основе минутного образца система «генерирует уникальный ключ», с помощью которого может обработать любую другую речь, придав ей характеристики нужного голоса.
Эту систему можно использовать, чтобы выдать себя за другого человека, то есть для розыгрышей (только не шутите с голосами личностей, которые находятся в федеральном розыске). С этого дня не стоит удивляться, если вам с незнакомого номера звонит мама/бабушка/жена/ваш ребёнок — и говорит странные вещи, просит помочь или перечислить деньги на какой-то счёт. Голосом вашего родственника может говорить кто угодно.
Возможности системы не ограничиваются розыгрышами и социальной инженерией. Например, вы можете разработать собственный уникальный голос — и использовать его в общении, если ваш собственный голос не устраивает по каким-то причинам. Такая услуга будет полезна телефонным операторам, маркетологам, продажникам и другим профессионалам в сферах, где важную роль играют разговоры, общение по телефону. Хотите очаровать девушку, расположить к себе собеседника, добавить себе авторитетности — просто добавьте немного низких частот и бархатистости.
Известно, что голос человека напрямую связан с психологическими чертами личности, эта информация передаётся собеседнику на подсознательном уровне. Так, писклявые, тонкие и визжащие звуки голоса вызывают дискомфортные тревожные ощущения, и такие голоса подсознательно ассоциируются с юностью, энергичностью, неопытностью и незрелостью. С другой стороны, людей с низкими голосами воспринимают как людей самодостаточных, высокоинтеллектуальных и уверенных в себе. Человек с низким голосом интуитивно считается знающим и авторитетным. Этими приёмами пользуются даже имиджмейкеры, когда техническими методами понижают голос политических кандидатов во время телетрансляций, чтобы вызвать большее доверие избирателей женского пола.
В сервисе Lyrebird для использования в своих целях можно выбрать один из тысяч заранее подготовленных наиболее оптимальных голосов — или спроектировать собственное оригинальное звучание. Разработчики гарантируют, что обработка уникальным «ключом» тысячи предложений на их кластерах GPU занимает менее 0,5 секунды.
Технология генерации речи Lyrebird разработана в Монреальском институте алгоритмов обучения (Montreal Institute for Learning Algorithms, MILA) при Монреальском университете (Канада).
В качестве демонстрации технологии разработчики сгенерировали ключи для голосов Дональда Трампа, Барака Обамы и Хиллари Клинтон. В демонстрационном аудиоклипе эти политики обсуждают возможности системы подделки голосов Lyrebird (аудио).
Вот отдельные сгенерированные фразы разными голосами. Одни и те же фразы одинаковый голос произносит с разными интонациями:
В демонстрационном плейлисте представлены два десятка голосов с разными характеристиками, как пример того, какие голоса можно сгенерировать на свой вкус.
Сейчас Lyrebird заканчивает разработку API, чтобы сервис реально можно было использовать в своих приложениях. Разработчики говорят, что Lyrebird — первая в мире компания, которая предлагает технологию для точной подделки чужих голосов. В связи с этим на них налагаются определённые этические обязательства. Главным этическим обязательством является повсеместное информирование о возможностях технологии по точной подделке чужого голоса, так что с этого дня — с 24 апреля 2017 года — ни один суд в мире, ни одно оперативно-разыскное мероприятие не должно полагаться на аутентичность голоса конкретного человека. С этого дня голоса перестали быть уникальными, каждый из них можно подделать.
Гражданам, которые заботятся о своей приватности, можно посоветовать быть осторожным с использованием своего голоса — не передавать его по незащищённым каналам и говорить краткими фразами, чтобы злоумышленник не смог собрать достаточно материала для подделки личности.

Программы для изменения голоса на Айфон позволят вам менять голос как после записи, так и в реальном времени.
Встроенных в операционную систему iOS инструментов, способных в режиме реального времени изменять голос, или же корректировать заранее записанные диктофонные записи, не предусмотрено.
Разработчики из Apple предлагают только ускорять воспроизведение аудиозаписей или же замедлять (к примеру, в iMovie), а вот за остальными функциями придется обращаться к цифровому магазину App Store, который, как ни странно, предлагает достаточно мало «жанровых» вариантов.
Инструменты, корректно изменяющие голос, можно по пальцам пересчитать:
Voice Changer Plus

Если еще год назад в меню предлагали активировать эхо и добавлять «аплодисменты», то в дальнейшем появились и голоса Бэтмен с Джокером, и роботов из «Звездных Воин» и даже водолазов, находящихся на дне океана.
Разнообразия в Voice Changer Plus даже больше, чем нужно, а потому появится возможность экспериментировать с вариантами с утра и до позднего вечера. Кстати, работать с редактором необычайно легко – нужно всего-то открыть раздел с «Новой записью», затем – поработать с настройками (можно выбрать битрейт, формат, название и даже каталог для сохранения – внутреннюю память или облачное хранилище), а после – выбрать понравившийся шаблон. Дальше останется нажать на зеленую кнопку «Play» и приступить к записи.
Подхватывается голос точно и без шумов. А еще тут не отыскать рекламы и постоянных раздражающих уведомлений, отнимающих кучу времени.
Call Voice Changer

Простая программа на Айфон для изменения голоса. Если работать с звуковыми редакторами уже надоело, а результат изменения голоса нужно «слышать» в режиме реального времени, то инструмент от TeleStar LTD придется по душе всем и каждому. Главное назначение Call Voice Changer – изменение голоса при звонках через мессенджеры, социальные сети или SIM-карту.
Из плюсов – свободное распространение, вложенные инструкции по настройке и управлению голосом в режиме реального времени (опять же, доступны и шаблоны, и изменяемые параметры, с помощью которых легко собирается совсем уж «нестандартное произношение»).
Из минусов – реклама и ограничения, навязываемые разработчиками с целью финансового обогащения. А потому доступных звуковых эффектов тут меньше, чем хотелось бы. А за все «дополнительные» придется платить. Причем суммы серьезные.
Voice Changer App

Инструмент для изменения голоса с интуитивным интерфейсом, прекрасной технической реализацией (сразу после запуска можно забыть о проблемах с оптимизацией, вылетах или сбросе прогресса при сохранении получаемого после редактирования трека или аудиозаписи), и несложным взаимодействием с шаблонами и эффектами.
Главное преимущество Voice Changer App – интерфейс. Разработчики позаботились и о внешнем виде каждой отдельной кнопки, фона, информационных блоков (художники выложились на 100% и ни процентом меньше!), и о порядке действий. Тут некогда плутать по меню. Каждое новое действие угадывается с первых же секунд и сразу приводит к нужному результату.
Русского языка в данном приложении на Айфон в наличии не предусмотрено, как и рекламы. А потому можно спокойно экспериментировать и добиваться нужных результатов без перерывов.


Бывают ситуации, когда необходимо изменить свой голос, чтобы собеседник вас не узнал. Проще всего это сделать имея Android-смартфон, однако даже если у вас iPhone или Mac, то такая возможность тоже есть.
Но для начала разочарую всех, кто хочет изменить голос во время обычного вызова на iPhone. Без джейлбрейка это сделать невозможно.
Поэтому нам ничего не остается, кроме как воспользоваться VoIP. Данная технология позволяет осуществлять телефонные звонки с помощью интернета вместо обычных телефонных сетей.
Как изменить голос во время звонка на iPhone
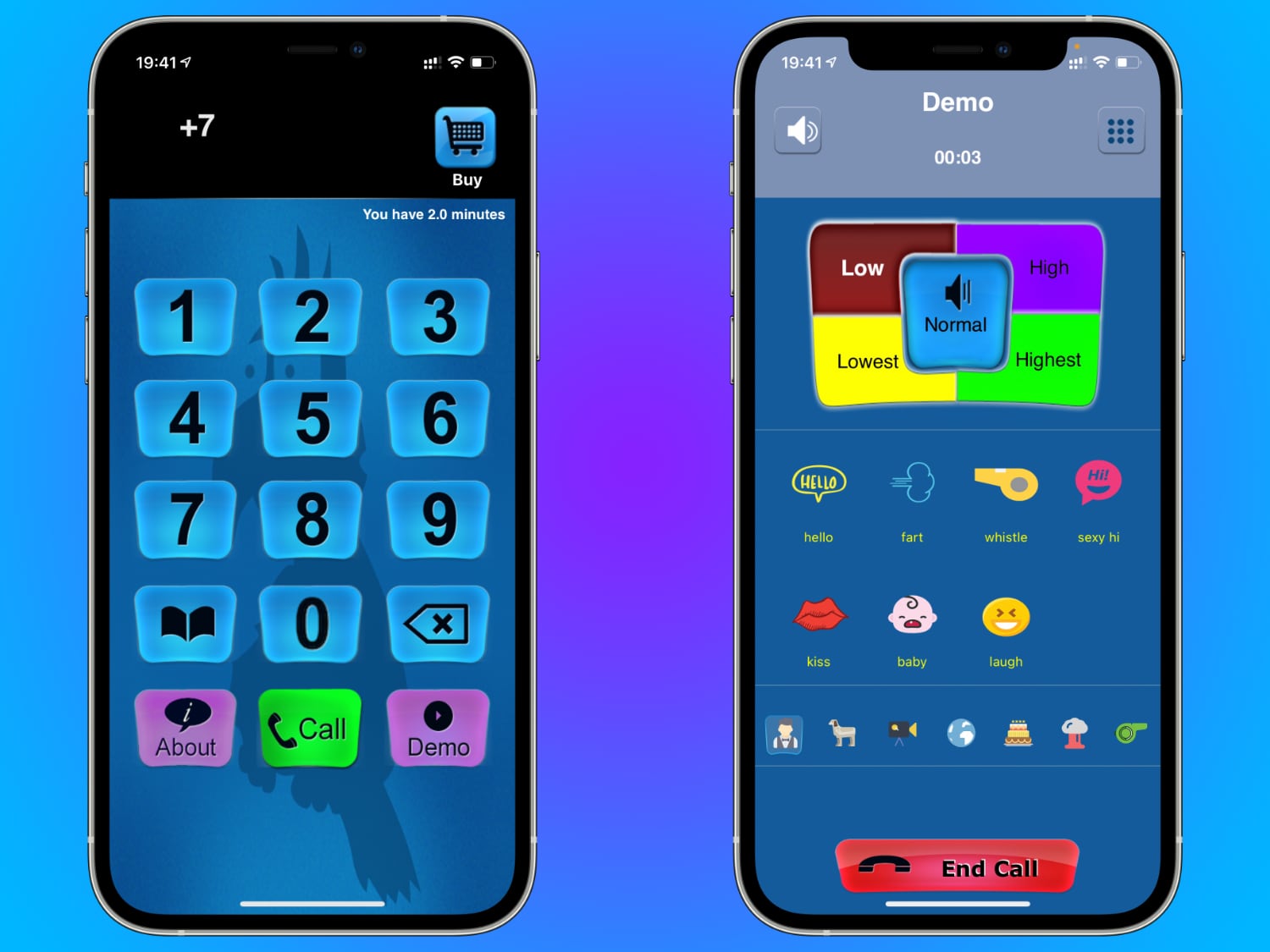
Для этого нам поможет приложение Call Voice Changer. На выбор предоставляется четыре эффекта для голоса, которые меняют его тональность. Также есть много звуков для тех, кто желает разнообразить общение.
Интерфейс Call Voice Changer максимально простой. На главном экране показывается окно набора номера и кнопка вызова. Рядом с ней находится меню с контактами, для быстрого поиска абонента.
▪️ 15 минут: 449 руб.
▪️ 35 минут: 899 руб.
▪️ 80 минут: 1790 руб.
Если вы хотите протестировать преобразователь голоса и не желаете тратить бесплатные минуты, то такая возможность есть. Внизу находится кнопка демо-режима, в котором можно выбрать нужный эффект и послушать, как с ним звучит ваш голос.
Как изменить голос во время звонка на Mac
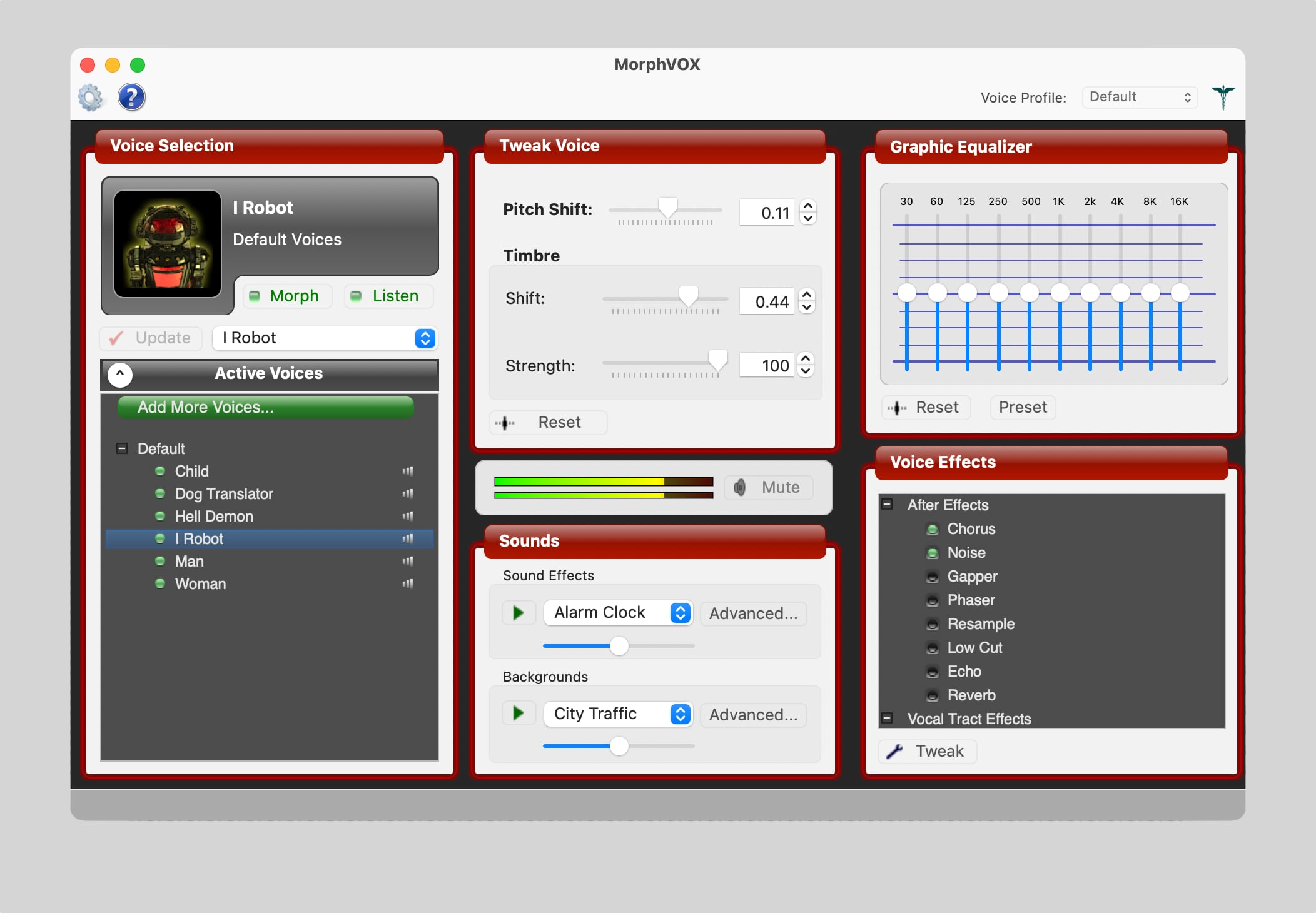
В этом поможет утилита MorphVOX. Она стоит $39,95 или 2929 рублей, но есть бесплатная триальная версия, которая работает неделю без ограничений.
MorphVOX получает звук с обычного микрофона и интегрируется в систему в качестве виртуального.
Данная особенность MorphVOX играет только на руку нам, поскольку теперь мы можем менять голос во время звонка практически в любом приложении. Главное, установите MorphVOX в качестве микрофона по умолчанию в настройках нужной программы. Она работает с FaceTime, Telegram и Skype.
В MorphVOX есть несколько эффектов для голоса. Например, можно притвориться роботом, незнакомой женщиной или мужчиной. Кроме того, пользователи могут покупать и загружать дополнительные голоса. А еще в программе есть эквалайзер и плагины.
(21 голосов, общий рейтинг: 4.29 из 5)
Читайте также: