
Типы отказоустойчивых кластеров реализованных в windows server 2008
Обновлено: 08.07.2024
Основные изменения
В операционных системах Windows Server® 2008 R2 Enterprise и Windows Server® 2008 R2 Datacenter реализованы следующие изменения, касающиеся отказоустойчивых кластеров.
• Усовершенствование процесса проверки для новых и существующих кластеров.
• Расширение функциональности кластеризованных виртуальных машин (работающих на платформе Hyper-V). Данные улучшения помогают увеличить время работы и упростить процессы управления кластеризованными виртуальными машинами.
• Добавление интерфейса Windows PowerShell.
• Дополнительные параметры переноса параметров между кластерами.
Примечание
Компонент отказоустойчивого кластера недоступен для операционных систем Windows® Web Server 2008 R2 и Windows Server® 2008 R2 Standard.
Что представляет собой отказоустойчивый кластер
Отказоустойчивый кластер – это группа независимых компьютеров, которые работают совместно с целью повышения доступности служб и приложений. Кластерные серверы (называемые узлами) соединены с помощью кабелей и подключены друг к другу посредством программного обеспечения. При сбое на одном из узлов кластера его функции немедленно передаются другому узлу (процесс, называемый отработкой отказа). Пользователи при этом не испытывают каких-либо серьезных нарушений в работе.
Для кого предназначены отказоустойчивые кластеры
Отказоустойчивые кластеры используются ИТ-специалистами для обеспечения высокой доступности служб и приложений.
Что следует принять во внимание
Корпорация Microsoft поддерживает отказоустойчивые кластерные решения, только если все компоненты оборудования имеют эмблему «Certified for Windows Server 2008 R2». Кроме того, должна быть выполнена проверка всей конфигурации (серверы, сеть и хранилище) с использованием мастера проверки конфигурации, который включен в оснастку «Диспетчер отказоустойчивости кластеров».
Обратите внимание, что данная политика отличается от политики поддержки кластеров серверов в Windows Server 2003, по условиям которой требовалось, чтобы кластерное решение было полностью включено в список в узле кластерных решений каталога Windows Server.
Новые возможности, которые предоставляет функция отказоустойчивости кластеров
• Командлеты Windows PowerShell для отказоустойчивых кластеров. Windows PowerShell — это новая оболочка командной строки и технология сценариев, в которой используется единообразный синтаксис и схемы именования ролей и компонентов в операционной системе Windows Server 2008 R2. Новые командлеты для отказоустойчивых кластеров являются мощным средством создания сценариев для задач настройки кластеров и управления ими. В конечном итоге командлеты Windows PowerShell заменят интерфейс командной строки Cluster.exe.
Изменения, внесенные в существующие функции
Ниже представлен краткий список улучшений в отказоустойчивых кластерах.
• Дополнительные проверки кластеров. Дополнительные проверки, реализованные в мастере проверки кластеров в оснастке для отказоустойчивых кластеров, позволят выполнить точную настройку кластеров, осуществлять контроль конфигураций и выявлять потенциальные неполадки в кластерах, прежде чем они вызовут отказ системы.
• Поддержка дополнительных кластеризованных служб. Помимо служб и приложений, которые ранее можно было настраивать в кластере, теперь кластеризация доступна для серверов службы репликации распределенной файловой системы (DFS) и посредника подключений к удаленному рабочему столу (ранее известного как посредник сеансов служб терминалов).
• Дополнительные параметры переноса параметров между кластерами. Мастер миграции в оснастке отказоустойчивых кластеров позволяет переносить параметры с кластеров, работающих под управлением Windows Server 2003, Windows Server 2008 и Windows Server 2008 R2. Ранее перенос был возможен только для кластеров с Windows Server 2003. Мастер также может выполнять перенос параметров для дополнительных типов ресурсов и групп ресурсов.
• Возможность перемещения виртуальной машины на другой узел с незначительным или нулевым прерыванием в обслуживании клиентов. Windows Server 2008 R2 поддерживает динамическую миграцию — способ переноса виртуальной машины на другой узел, во время которого сохраняется подключение клиентов к виртуальной машине. Также доступны методы быстрого переноса и перемещения виртуальных машин, аналогичные методам, которые предоставлялись для кластеров под управлением Windows Server 2008.
Дополнительные проверки кластеров
Мастер проверки кластеров ранее включал проверки, которые помогали тестировать набор серверов, сети и подключенные хранилища перед добавлением их в кластер. Проверки также были полезны при повторном тестировании кластеров после внесения изменений, например после изменения конфигурации хранилища. Эти проверки продолжают оставаться доступными, и в дополнении к ним были реализованы новые наборы тестов. Новые тесты называются проверками конфигурации кластера и помогают выполнять проверку установленных в кластере параметров, например параметров взаимодействия кластеров в доступных сетях. Эти проверки позволяют анализировать текущую конфигурацию вплоть до частных свойств кластеризованных ресурсов с целью проверки их соответствия рекомендациям. Проверки конфигурации кластера можно также применять для просмотра и архивации конфигураций кластеризованных служб и приложений (включая параметры для ресурсов отдельных кластеризованных служб и приложений).
Дополнительные проверки позволят выполнять точную настройку кластеров, осуществлять контроль конфигураций и выявлять потенциальные неполадки в кластерах, прежде чем они вызовут отказ системы. Это помогает оптимизировать конфигурацию и сравнить ее с рекомендациями, определенными для организации.
Поддержка дополнительных кластеризованных служб
Помимо служб и приложений, которые ранее можно было настраивать в отказоустойчивом кластере, теперь доступна кластеризация для следующих служб.
• Посредник подключений к удаленному рабочему столу (ранее — посредник сеансов служб терминалов). Посредник подключений к удаленному рабочему столу поддерживает балансировку нагрузки и переподключение сеанса в ферме серверов удаленного рабочего стола с балансировкой нагрузки. Посредник подключения к удаленному рабочему столу используется для предоставления доступа к программам RemoteApp и виртуальным рабочим столам через подключение удаленных приложений RemoteApp и рабочего стола.
• Репликация DFS. Репликация DFS — это эффективный механизм репликации нескольких основных узлов, который можно использовать для синхронизации папок между серверами в сетях с ограниченной полосой пропускания. Кластеризовать можно любой сервер группы репликации.
Дополнительные параметры переноса параметров между кластерами
Мастер миграции в оснастке отказоустойчивых кластеров позволяет переносить параметры с кластеров, работающих под управлением Windows Server 2003, Windows Server 2008 и Windows Server 2008 R2. Ранее перенос был возможен только для кластеров с Windows Server 2003. Как и раньше, мастер поддерживает перенос параметров со следующих групп ресурсов:
• Файловый сервер
• Протокол DHCP
• Универсальное приложение
• Универсальный сценарий
• Универсальная служба
• WINS-сервер
В операционной системе Windows Server 2008 R2 мастер миграции позволяет также выполнять перенос параметров со следующих групп ресурсов:
Следует заметить, что для других кластеризованных серверов, таких как кластеризованные сервера печати, доступны дополнительные процессы переноса.
Возможность переноса виртуальной машины на другой узел с незначительным или нулевым прерыванием в обслуживании клиентов
Отказоустойчивые кластеры в Windows Server 2008 R2 предоставляют множество способов перемещения виртуальной машины с одного узла кластера на другой.
• Динамическая миграция. При запуске динамической миграции кластер копирует память, используемую виртуальной машиной, с текущего узла на другой узел, так что в момент фактического перехода на другой узел виртуальная машина уже может использовать данные о памяти и состоянии. Обычно процесс перехода выполняется достаточно быстро, поэтому использующий виртуальную машину клиент не теряет подключения к сети. При использовании общих томов кластера динамическая миграция происходит почти мгновенно, поскольку не требуется переносить владение диском.
Динамическая миграция применима при плановом обслуживании, но не в случае незапланированной отработки отказа. На сервере с поддержкой Hyper-V в конкретный момент времени может выполняться только один процесс динамической миграции (на сервер или с него). Например, при наличии кластера, состоящего из четырех узлов, одновременно может быть запущено не более двух процессов динамической миграции при условии, что в операции задействованы разные узлы.
• Быстрая миграция. При запуске быстрой миграции кластер копирует память, используемую виртуальной машиной, на диск хранилища, так что в момент фактического перехода на другой узел данные о памяти и состоянии могут быть быстро прочитаны с диска узлом, принимающим владение.
Быстрая миграция применима при плановом обслуживании, но не в случае незапланированной отработки отказа. Быстрая миграция используется для одновременного перемещения нескольких виртуальных машин.
• Перемещение. При запуске перемещения кластер готовится перевести виртуальную машину в автономный режим путем выполнения операции, указанной в конфигурации кластера для ресурса виртуальной машины.
- Сохранение (задано по умолчанию) — сохранение состояния виртуальной машины с возможностью его восстановления при повторном подключении виртуальной машины к сети.
- Завершение работы — завершение работы операционной системы (с ожиданием закрытия всех процессов) виртуальной машины перед ее отключением от сети.
- Завершение работы (принудительно) — завершение работы операционной системы в виртуальной машине без ожидания окончания медленных процессов с последующим отключением виртуальной машины от сети.
- Выключение — похоже на отключение питания виртуальной машины. Может привести к потере данных
Параметры, указанные для операции перевода в автономный режим, не действуют при динамической миграции, быстрой миграции или незапланированной отработке отказа. Они влияют только на перемещение (или отключение ресурса от сети с помощью действия Windows PowerShell или приложения).
Необходимость изменения существующего кода или сценариев при работе с Windows Server 2008 R2Если приложение или служба запущены в кластере под управлением Windows Server 2008, изменение кода для запуска приложения или службы в кластере под управлением Windows Server 2008 R2 не требуется. Если имеются сценарии на базе Cluster.exe, их можно продолжать использовать в операционной системе Windows Server 2008 R2, однако рекомендуется переписать их с применением командлетов Windows PowerShell. В следующих выпусках в оболочке Windows PowerShell для отказоустойчивых кластеров будет доступен только интерфейс командной строки.
Подготовка к развертыванию данной функции
Внимательно проверьте оборудование, на котором планируется развертывание отказоустойчивого кластера, на совместимость с Windows Server 2008 R2. Это особенно важно, если планируется использовать оборудование, на котором работает кластер серверов с Windows Server 2003. Оборудование, поддерживающее кластер серверов с Windows Server 2003, может не поддерживать отказоустойчивый кластер с Windows Server 2008 R2
Примечание
Нельзя произвести последовательное обновление кластера под управлением Windows Server 2003 или Windows Server 2008 до кластера под управлением Windows Server 2008 R2. Однако после создания отказоустойчивого кластера под управлением Windows Server 2008 R2 можно использовать мастер для переноса на него определенных параметров ресурсов с существующего кластера.
Если планируется использовать общие тома кластера, операционную систему каждого сервера в кластере необходимо настроить таким образом, чтобы ее загрузка выполнялась с той же буквы диска, что и для всех остальных серверов кластера. Другими словами, если загрузка одного сервера выполняется с диска C, все серверы кластера также должны загружаться с дисков с такой же буквой.
Выпуски, которые предоставляют поддержку отказоустойчивых кластеров
Отказоустойчивые кластеры доступны в операционных системах Windows Server 2008 R2 Enterprise и Windows Server 2008 R2 Datacenter. Эта возможность отсутствует в Windows Web Server 2008 R2 и Windows Server 2008 R2 Standard.
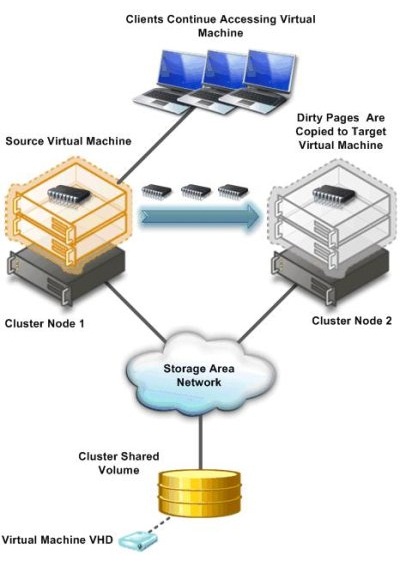
В данной заметке я расскажу как реализовать полноценный кластер Hyper-V 2008 R2 на подручном железе — трех рабочих станциях, две из которых поддерживают аппаратную виртуализацию. Под катом инструкция по сборке отказоустойчивого кластера Hyper-V с учетом нюансов и особенностей, а так же видео-демонстрация технологии Live Migration.
Введение

Краткий экскурс по самой технологии Live Migration. Ее основное отличие от Quick Migration — перенос виртуальной машины «на лету», без выгрузки памяти на диск (это иллюстрирует предыдущая картинка). Помимо этого, по заверениям Microsoft, перенос машины происходит быстрее, чем успевает разорваться TCP-сессия, так что пользователи если и будут испытывать дискомфорт, то небольшой.
Выбор железа и софта
У меня, разумеется, нет лишнего SAN-а для тестирования.
Все что у меня есть — две рабочих станции Aquarius (C2D 6420, 4Gb DDR2, 80Gb HDD) и одна станция на Celeron-D.
Разумеется все процессоры должны иметь поддержку 64бит, так как 2008 R2 существует только в 64-битной редакции.

Для реализации кластера, я возьму бесплатный вариант Hyper-V Server 2008 R2, который представляет собой модифицированный Windows Server 2008 R2 в режиме ядра, со включенным по-умолчанию гипервизором и относительно удобной консольной менюшкой для централизованного управления. Выбор обусловлен тем, что я не хочу, тратить ресурсы хостовой машины на поддержание каких-либо других ролей кроме гипервизора.
В случае использования данного гипервизора, лицензироваться будут только виртуальные машины, которые мы будем на нем крутить. Я это говорю на случай, если кому-то взбредет в голову внедрять данную кустарную систему в продакшн.
В качестве хранилища я буду использовать самую слабую из своих рабочих станций, закинув в нее пару жестких дисков на 250гб каждый и объединив их в софтверный RAID0 силами операционной системы. Для превращения импровизированного сервера в хранилище, я буду использовать самый дешевый из возможных вариантов — iSCSI. Эта же машина будет выступать в качестве управляющей для кластера Hyper-V, ну и заодно будет контроллером нашего маленького домена.
- Microsoft iSCSI Software Target — поставляется только в паре с Windows Storage Server 2008, при покупке серверов у OEM-партнеров Microsoft. Найти ее в открытом доступе не так легко, но если кто найдет — может попробовать. Правда ставится она опять же, исключительно на Storage Server, который не сильно подходит для наших нужд.
- StarWind iSCSI Software Target — продукт компании StarWind(имеющей совершенно непопулярный блог на Хабре) с поддержкой русского языка. У StarWind есть бесплатная версия, ограниченная в объеме хранилища до 2Тб, и двух конкурентных соединений к одному таргету. А нам для проверки больше и не надо.
Наше импровизированное хранилище будет работать под управлением полноценного Windows Server 2008 R2, версия в данном случае существенного значения не имеет, однако опытным путем выяснилось, что управление кластером с 32-битных систем может вызывать некоторые проблемы. Тем более, что в 2008 R2 стоит свежая консоль Failover Clustering, а в других версиях придется обновлять Remote Administration Tools. Ну и не стоит забывать, что машина будет выполнять также функции контроллера домена.
Настройка
Этап первый. Предварительный
Итак, у нас есть два чистых и ненастроенных Hyper-V Server 2008 R2, и один чистый Windows Server 2008 R2.
Перед настройкой кластера, необходимо настроить сетевую инфраструктуру для корректной работы. Задаем всем серверам локальные IP-адреса, предварительно подцепив их в маленький свитч(типа того, что у меня на фотке). Разрешаем удаленный доступ к нодам, как через RDP, так и через консоль MMC.
Лучше сделать это до того, как ноды окажутся в домене. Были ситуации, когда сервер ругался на невозможность изменения политик фаервола. Поднимаем домен и вводим в него наши будущие кластерные ноды.
Разумеется, включаем Failover Clustering Feature.
Этап второй. Хранилище.
Теперь можно перейти непосредственно к настройке хранилища. Начнем с того, что разобьем наш получившийся страйп (RAID0) на два логических диска — один для кворума (который ныне зовется File Share Witness), а второй для хранения наших виртуальных машин. Я выделил под кворум около 15Гб, а все остальное оставил под данные. По-хорошему — под кворум с лихвой хватит и гигабайта, однако мало ли что.

Переходим к установке StarWind iSCSI Target. Для загрузки с сайта производителя потребуется регистрация, которая ни к чему, в принципе, не обязывает. После регистрации, на электронную почту падает ссылка на прямую загрузку инсталлятора и файл-ключ с лицензией. Установка состоит из нескольких нажатий на кнопку Next, так что ничего существенно сложного там нет. После установки необходимо пропустить через Windows Firewall как минимум порты 3260 и 3261. Для ленивых — его можно просто отключить, так как в нашей импровизированной сети находятся только три наших сервера.

Запускаем консоль StarWind и пробуем подключиться к iSCSI-серверу, коим в нашем случае выступает компьютер с таинственным адресом 127.0.0.1. Для авторизации потребуется секретное сочетание дефолтного логина и пароля, которые в базовом варианте выглядят как root и starwind соответственно. Почему не просили задать пароль в процессе установки, или не повесили подсказку в интерфейсе — загадка.

После подключения к серверу, необходимо подсунуть ему файл с лицензией, упавший на электронную почту. Делается это во вкладке Configuration, серверной консоли StarWind. Все интуитивно понятно и просто, за исключением ссылки на загрузку самого файла в верхнем правом углу. Только после регистрации, программа позволит нам создавать таргеты.

В процессе создания таргета, мы создаем предразмеченные img-файлы, которые будут играть роль наших LUN-ов. Размещаем их на наших разделах в соответствии с целями, и не забываем выставлять галочку, отвечающую за конкурентные соединения iSCSI(т.е. кластеризацию). Можно также задать кэширование данных, это будет полезно в случае использования нашего медленного железа.

В результате, должна получиться примерно следующая картина. Два таргета — один под кворум, второй под данные. Пора подцеплять их к серверам.
Этап третий. Цепляемся к хранилищу.
В серверах версии 2008 R2 уже есть предустановленный iSCSI Initiator, отвечающий за подключение LUN-ов с нашего импровизированного хранилища, в качестве локальных дисков. Правда в связи с отсутствием адекватного GUI на консольном Hyper-V Server, его придется вызывать через командную строку или Powershell командой iscsicpl.

В поле, подсвеченное желтым нужно ввести IP-адрес нашего хранилища, после чего должно появиться всплывающее окошко с размещенными на сервере таргетами. Разумеется, если фаервол был правильно настроен или отключен. После того как таргеты будут подключены к нашему серверу, можно будет заняться монтированием их в качестве дисков.

После нажатия на Autoconfigure, в пустом окошке появятся два длинных пути к дискам, начинающимся на \?\. После этого, можно смело идти в Disk Management и задавать буквы дискам. К слову, после задания букв на первом гипервизоре, второй гипервизор подхватит имена дисков автоматически.
В результате мы получили два гипервизора, имеющих по два общих диска, подключенных через iSCSI к нашему хранилищу. Пора переходить непосредственно к кластеризации.
Этап четвертый. Кластеризация.
При настройке отказоустойчивого кластера на двух имеющихся гипервизорах, визард сам выбрал файловые разделы под кворум и под данные. Если я правильно понял алгоритм, в качестве общих ресурсов были выбраны диски, подключенные по iSCSI, и в качестве кворума был выбран наименьший. А может он выбрал их потому, что меньшему разделу я дал лейбл Quorum… =)

После объединения двух гипервизоров в кластер, с помощью визарда и такой-то матери, консоль отказоустойчивого кластера будет выглядеть примерно так, как на картинке сверху. Стоит заметить, что в данный момент мы имеем именно отказоустойчивый кластер, в котором всю работу выполняет только одна нода, а вторая в это время простаивает и ждет пока первая сдохнет. Но нам же нужно не это.

Тут нам поможет Cluster Shared Volumes — новая вкладка в консоли кластера, появившаяся только в 2008 R2. Именно на этом хранилище могут размещаться виртуальные машины, для обеспечения отказоустойчивости. Наша задача — превратить обычный кластерный ресурс в расшареный, используя волшебную кнопку «Add Storage». После предупреждения о том, что данный тип ресурсов работает только в версиях 2008 R2 и выше, во вкладке совместно используемых ресурсов появится наш диск. Диск, в свою очередь будет смонтирован на C:\ClusterStorage\Volume1, так что все совместно используемые данные будут находиться там. В том числе и виртуальные машины. Во избежание лишних глюков, в настройках гипервизоров на каждой ноде, советую выставить дефолтные пути для дисков и виртуальных машин, с размещением на нашем общем диске.

Этап пятый. Виртуальные машины.
Теперь можно создавать виртуальные машины непосредственно из оснастки управления кластером. Во вкладке сервисов выбираем Virtual Machines, выбираем ноду и создаем машину. Монтируем откуда-нибудь дистрибутив с ОС, устанавливаем и отмонтируем. Для корректной работы Live Migration, необходимо отсутствие зависимостей от внешних ресурсов на каждой ноде.
На видео показан процесс перегонки памяти с одной ноды на другую. На переносимой виртуальной машине стоял тот же Windows Server 2008 R2, а памяти у машины было 1024мб. Сразу стоит отметить весьма посредственную скорость миграции, которая связана с кустарной реализацией нашего хранилища и сетью в 100мбит. Позднее пересоберу кластер с использованием гигабитной сети и посмотрю на прирост производительности.
Одно из достоинств Windows Server 2008 - высокая отказоустойчивость системы. Если говорить более конкретно, реализованные в системе Microsoft Windows Server 2008 средства создания отказоустойчивых кластеров обеспечивают поддержку более широкого набора аппаратных компонентов, модель единого кворума, способного функционировать в четырех режимах, а также упрощенный процесс создания кластеров.
Одно из достоинств Windows Server 2008 — высокая отказоустойчивость системы. Если говорить более конкретно, реализованные в системе Microsoft Windows Server 2008 средства создания отказоустойчивых кластеров обеспечивают поддержку более широкого набора аппаратных компонентов, модель единого кворума, способного функционировать в четырех режимах, а также упрощенный процесс создания кластеров.
К числу других модификаций Server 2008, повышающих эффективность средств отказоустойчивости кластеров, относятся гибкость настройки, допускающая более длительные задержки между расположенными в разных местах серверами, чем задержки, считающиеся приемлемыми при передаче сигналов подтверждения соединения heartbeats, а также средства мультисайтовой кластеризации, которые позволяют кластеру иметь IP-адреса в нескольких подсетях и, следовательно, на различных сайтах. Кроме того, средства отказоустойчивой кластеризации обеспечивают более высокий уровень масштабируемости, поскольку дают возможность использовать 16-узловые кластеры в 64-разрядной архитектуре. Для сравнения: в системах Server 2003 (и в 32-разрядной Server 2008) допускаются кластеры не более чем из 8 узлов. Я коснусь некоторых из этих нововведений, описывая основные усовершенствования средств отказоустойчивой кластеризации Server 2008.
Поддержка аппаратных компонентов
В свое время разработчики Windows Server 2003 подготовили специальный список аппаратных компонентов, сертифицированных для работы в кластерных конфигурациях. Пользователям системы Server 2008 приходится покупать компоненты с сертификатом, имеющим соответствующий логотип, а потом осуществлять процесс проверки кластера, дабы удостовериться, что данная конфигурация поддерживается. Если ваша конфигурация проходит тест проверки, это означает, что Microsoft поддерживает такой кластер. Процесс проверки можно выполнять и на настроенном кластере; таким образом выявляются проблемы, которые могут привести к отказу кластера.
Процесс проверки кластера не относится к числу новинок. Когда-то он именовался ClusPrep, и данное решение можно было загрузить с Web-узла Microsoft. В версии 2.0 ClusPrep подвергся модификации, и эта версия включена в комплект поставки Windows Server 2008. В процесс проверки кластера входят четыре типа тестов. Это тесты Inventory, Network, Storage и System Configuration.
Inventory. В ходе теста Inventory собираются следующие данные: сведения о системе BIOS, переменных окружения, о системе хранения данных Fibre Channel, об интерфейсе Serial Attached SCSI (SAS), о хост-адаптерах шины Host Bus Adapters (HBA), хост-адаптерах шины iSCSI, о памяти, операционной системе, об устройствах Plug-and-Play (PnP), о выполняемых процессах, службах, обновлениях программных средств, системных и неподписанных драйверах, а также общая информация о системе (такая, как модель компьютера или домен).
Network. В ходе теста Network проверяется сетевая конфигурация кластера. Затем проверяются сведения по адаптерам, касающиеся IP-адресации и подсетей, а также IP-конфигурация; это позволяет удостовериться в том, что адреса являются уникальными, что к одной подсети подключено не более одного адаптера, что шлюз по умолчанию настроен для работы с одним адаптером и что не существует дублирующих MAC-адресов (последнее обстоятельство важно в ситуациях, когда используются виртуальные машины). Проверяются сетевые каналы связи между узлами, а также правила брандмауэра, с тем чтобы обеспечить бесперебойное взаимодействие между компонентами кластера.
Storage. В ходе этого испытания составляется перечень всех дисков, в первую очередь — совместно используемых, которые видимы из всех узлов. После этого совместно используемые диски проверяются на пригодность к применению в отказоустойчивых конфигурациях; помимо прочего, проверяется способность этих дисков сохранять целостность данных.
System Configuration. В ходе этого теста проверяется корректность настройки службы Active Directory (AD), а также принадлежность всех узлов к одному домену (а в идеале и к одной организационной единице, OU), что важно для организации корректного применения групповых политик. Отметим, что принадлежность к одной OU не является обязательной; при несоблюдении этого условия всего лишь генерируется предупреждение. Также необязательна и принадлежность узлов к одной и той же подсети либо к одному сайту AD. Наряду с этим в ходе теста System Configuration проверяется, все ли драйверы подписаны и установлены ли на серверах операционные системы одной версии, пакеты обновлений и обновления программных средств. Система удостоверяется, что выполняются все необходимые службы кластеров (такие, как RpcSs, Remote Registry, LanmanServer, WinMgmt). Наконец, все узлы проверяются на использование одной и той же архитектуры, что является обязательным для компонентов кластера.
Процесс проверки кластера запускается из оснастки Failover Cluster Management консоли Microsoft Management Console (MMC). Выберите действие Validate a Configuration, введите имена узлов, которые войдут в состав кластера, и укажите тесты, которые необходимо выполнить. На экране 1 показано, как выполняются тесты проверки кластера. По завершении испытаний на экране отображается сводка с указанием состояния каждого теста. Области, требующие внимания, а также компоненты, неспособные функционировать в кластерной конфигурации, выделяются цветом. Для получения более подробного отчета нужно нажать кнопку View Report или перейти в папку \%windir%ClusterReports.
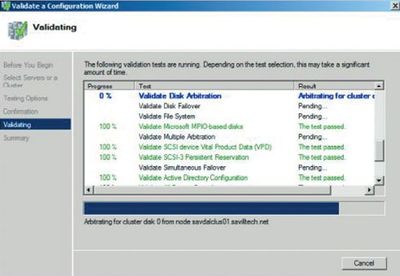
Чтобы клиенты Microsoft не тратили средств на приобретение и установку неподходящих компонентов, корпорация разработала программу Failover Cluster Configuration Program (FCCP). Эта программа позволяет определять, какие компоненты пригодны для работы в кластерной конфигурации. Со списком кластерных конфигураций, уже проверенных специалистами компании Microsoft и ее партнеров, можно познакомиться на Web-узле Microsoft Windows Server Cluster Solutions.
В числе других фундаментальных изменений, которые касаются поддерживаемых системой Server 2008 компонентов, следует отметить SCSI и iSCSI. Проблема сбросов шины SCSI, которая была настоящим бичом версии Server 2003, решена; однако пользователи пакета Server 2008 по-прежнему должны быть настороже, ведь новая версия поддерживает другие средства хранения данных. Параллельный интерфейс SCSI с его ограничениями на длину кабеля и проблемами переходников теперь не поддерживается; ему на смену пришли технологии Fibre Channel, SAS и iSCSI. Если вы работаете с интерфейсом iSCSI, следует использовать отдельную сеть для обмена данными с сетью хранения данных iSCSI; таким образом вы устраните конфликты за полосу пропускания между обращениями к хранимым данным и другими компонентами взаимодействия клиент-кластер. Кроме того, следует позаботиться о том, чтобы средства хранения данных поддерживали стандарт SCSI-3, и прежде всего — итерацию SPC-3, которая документирует фиксированное распределение.
Модель кворума
Концепция кворума имеет большое значение для отказоустойчивости кластеров. Она обеспечивает единообразное представление о кластере в тех случаях, когда сохраняется его неделимость, а также когда узлы кластера дробятся на разделы (т. е. кластер делится на несколько групп узлов, неспособных взаимодействовать друг с другом). Благодаря кворуму ту или иную службу может предоставлять только один раздел кластера. Если одна и та же служба предоставляется несколькими разделами кластера, вероятно возникновение ошибки.
В версии Server 2008 допускается функционирование лишь одной модели кворума, тогда как в Server 2003 таких моделей было несколько. Реализованная в Server 2008 модель Majority Quorum Model может функционировать в одном из четырех режимов в зависимости от того, как размещаются имеющиеся голоса. Перечислим упомянутые выше четыре режима. Это Node Majority, Node and Disk Majority, Node and File Share Majority и No Majority: Disk Only.
Голос могут иметь следующие компоненты кластеров Server 2008:
общие папки-свидетели, т. е. обычные общие папки на серверах Server 2008 или Server 2003, не являющихся частью кластера.Кластер не может одновременно иметь и диск-свидетель, и общую папку-свидетель; эти элементы исключают друг друга. Как я уже говорил, режим, используемый кворумом, зависит от способа распределения пользователем имеющихся голосов. Каждый режим кворума поддерживает отличное от других составляющее кворум сочетание узлов и дисков или комбинаций общих папок-свидетелей. Как показано на рисунке, раздел кластера может иметь кворум лишь тогда, когда на этот раздел приходится более половины числа голосов.

Node Majority. Данный режим назначает голоса только узлам кластера. Это значит, что, если кластер дробится на разделы, раздел может предоставлять службы лишь в том случае, если получает более половины общего числа голосов. Так, если разделяется кластер из пяти узлов, составлять кворум, а значит, и предоставлять службы может лишь раздел с тремя узлами. Режим Node Majority дает наилучшие результаты и рекомендуется для применения в кластерах с нечетным числом узлов. Если количество узлов четное, например при наличии четырех узлов, для кворума необходимо три узла. Если в ситуациях такого типа два узла расположены в одном месте и два узла — в другом и если по какой-то причине взаимодействие между местами расположения узлов невозможно, ни одно из этих мест не будет иметь достаточного числа узлов для формирования кворума, и кластер не сможет предоставлять службы. При наличии нечетного числа узлов — скажем, пяти — одно место будет иметь три узла, а второе — два узла. То место, где размещаются три узла, сможет сформировать кворум и продолжать предоставлять службы. В ситуациях с четным числом узлов разумнее использовать режимы с дисками-свидетелями и общими папками-свидетелями.
Node and Disk Majority. В этом режиме голос имеет каждый узел, а также общий диск, именуемый диском-свидетелем. Режим предпочтителен в ситуациях с четным числом узлов при наличии общих ресурсов хранения данных. Предположим, у нас имеется четыре узла, которые разделены на две равные группы. Только один из разделов может владеть диском-свидетелем и получить вследствие этого дополнительный голос. Следовательно, раздел, владеющий диском-свидетелем, может сформировать кворум и предоставлять службы.
Диск-свидетель должен быть базовым диском с одним томом, иметь объем не менее 512 Мбайт и быть отформатированным по NTFS. Этому диску должен быть присвоен отдельный номер логического устройства, и он не требует буквенного обозначения. Диск-свидетель и хранящиеся на нем данные не следует подвергать проверкам на наличие вирусов.
Node and File Share Majority. Этот режим функционирует точно так же, как и режим Node and Disk Majority, с одним исключением: диск-свидетель в нем заменяется общей папкой. Режим Node and File Share Majority рекомендуется использовать в ситуациях, когда имеется четное число узлов и отсутствуют общие средства хранения данных.
Общая папка должна размещаться на файловом сервере Server 2008 или Server 2003, который не является частью кластера, и данная папка в нем играет роль общей папки-свидетеля (она может располагаться в другом кластере). Кроме того, эта общая папка должна размещаться на сервере, входящем в тот же лес Active Directory (AD), что и обслуживаемый папкой кластер. Возлагаемые на общую папку задачи должны ограничиваться исключительно задачами общей папки-свидетеля. Если кластер является многосайтовым, общая папка в идеале должна размещаться на отдельном сайте, где не представлены узлы кластера; тогда она будет обладать дополнительной устойчивостью в случае отказа сайта. Наконец, общая папка не должна быть частью пространства имен DFS.
No Majority: Disk Only. В этом режиме голос имеет только общий диск (т. е. диск-свидетель). Узлы подобны европейцам с «зеленой картой»: голосов они не имеют. Кластер имеет кворум до тех пор, пока в нем присутствует диск-свидетель. Если кластер разделяется на части, кворум может формировать раздел, владеющий диском-свидетелем. Очевидная слабость этого режима в том, что диск-свидетель является единственной точкой отказа. При отсутствии диска-свидетеля кластер не может формировать кворум и предоставлять службы. В таблице представлены рекомендации, касающиеся того, какой из четырех режимов следует применять в тех или иных случаях. Отметим, что использование режима Disk Only не рекомендуется.
Формирование кластера
Чтобы создать кластер в системе Server 2008, откройте оснастку Failover Cluster Management консоли MMC, выделите пункт Create a Cluster, введите имя кластера и укажите в мастере, какие узлы будут входить в состав кластера. Мастер проверит среду и выберет оптимальный режим кворума, а также ресурсы, которые вам потребуются. Процесс формирования кластера отличается от процесса, реализованного в версии Server 2003, тем, что в более новой версии он выполняется однократно, а настройка всех узлов кластера осуществляется средствами мастера.
Средства кластеризации Server 2008 полностью совместимы с протоколами IPv6 и DHCP; единственное неудобство состоит в том, что, если сетевые адаптеры настроены для использования статического IP, система предложит ввести IP-адрес для кластера. Если статические IP-адреса используются для узлов кластера, необходимо указать IP-адрес, как показано на экране 2.
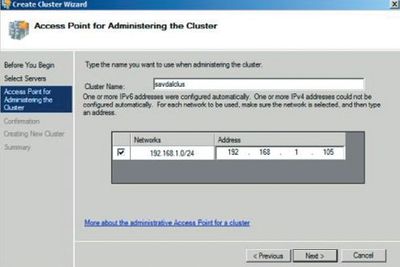
В процессе формирования кластера настраиваются все узлы кластера и автоматически выбираются оптимальные параметры для кворума и конфигурации кластера (в зависимости от наличия общих средств хранения данных и от конфигурации узлов). Если для работы требуется диск-свидетель, для выполнения этой роли выбирается наименьший диск (но он должен вмещать не менее 512 Мбайт данных). Все остальные общие хранилища данных помещаются в область доступных для хранения данных и могут быть использованы ресурсами кластера (в этом состоит отличие от процесса кластеризации, реализованного в версии Server 2003).
По завершении формирования кластера на консоли MMC отображается сводка, где показаны узлы кластера, режим кворума, а также диск, выполняющий функцию диска-свидетеля (если таковой используется). Кроме того, мастер формирует отчет CreateCluster.mhtml и помещает его в папку \%windir%ClusterReports. Как и при проверке кластера, вы можете познакомиться с дополнительными деталями процесса создания кластера, нажав кнопку View Report. Кстати, в процессе создания кластера нет необходимости добавлять все нужные узлы; операцию добавления узлов можно выполнить и позже.
Имейте в виду, что мастер формирования кластеров может осуществлять описанные выше действия, но не более того. Если, к примеру, вы имеете конфигурацию с четным числом узлов, но не имеете общих хранилищ данных, мастер не сможет автоматически назначить общую папку и выбрать режим Node and File Share Majority. Вместо этого оснастка Failover Cluster Management консоли Microsoft Management Console (MMC) сгенерирует предупреждение в области кворума, извещающее о том, что конфигурация не является оптимальной и что вам следует изменить ее. Процесс изменения кворума довольно прост. Чтобы настроить общую папку-свидетель, пользователю достаточно указать, какую общую папку следует использовать (администратор должен иметь полный контроль над этой папкой); обо всем остальном позаботится мастер кворумов.
Windows Server 2008 и кластеры Server 2008
В версии Server 2008 средства отказоустойчивых кластеров были, в сущности, написаны заново — они должны были вписаться в усовершенствования новой серверной операционной системы, касающиеся высокого уровня готовности. К сожалению, эти изменения в архитектуре означают, что кластеры Server 2008 и Server 2003 несовместимы с точки зрения управления или сосуществования. Инструментальные средства управления кластерами Server 2008 не могут применяться к кластерам Server 2003 и наоборот.
Проблемы возникают даже при переходе от среды Server 2003 к среде Server 2008. Возможность «покомпонентного» обновления исключается, поскольку внутри кластера не допускается сосуществование узлов Server 2008 и 2003. Вместо этого приходится создавать новый кластер с узлами Server 2008, а затем с помощью мастера Migration wizard оснастки Failover Cluster Management консоли MMC, которая входит в состав системы Server 2008, переводить ресурсы из среды Server 2003.
При отсутствии избыточных аппаратных компонентов для создания нового кластера Server 2008 необходимо удалить серверы из существующего кластера Server 2003, установить на этих серверах систему Server 2008, создать новый кластер и перевести на него требуемые ресурсы. Затем можно установить систему Server 2008 на остальных узлах Server 2003 и добавить их к кластеру Server 2008. Недостаток этого подхода состоит в том, что в то время, когда вы переводите в новый кластер необходимые ресурсы, оба кластера будут функционировать с сокращенным числом узлов, а это может привести к снижению производительности и повысить опасность отказа.
Усовершенствованные средства кластеризации
В среде Server 2008 легче планировать создание отказоустойчивых кластеров, эти кластеры легче формировать и ими легче управлять, нежели в среде Server 2003.
Версия Server 2008 предусматривает возможность использования большего числа аппаратных компонентов при создании кластеров, и в ней реализовано несколько режимов кворума, что обеспечивает более гибкую настройку. Внесенные в версию Server 2008 усовершенствования в области высокого уровня отказоустойчивости могут поставить себе на службу даже те организации, в штате которых нет групп сотрудников, специализирующихся на работе с кластерами. Кроме того, благодаря многосайтовым возможностям Server 2008 кластеризация представляется привлекательным решением проблемы восстановления после сбоя. Более подробные сведения о создании и проверке отказоустойчивых кластеров Server 2008, включая несколько видеоматериалов с практическими советами, можно получить на Web-сайте SavillTech video.
Сейчас я подробно разберу все моменты по разворачиванию тестового кластера в системе Virtualbox с использование операционной системы WindowsServer 2008 R2 Enterprise, системы FreeNAS, которая будет выступать хранилищем с поднятым сервисом по предоставлению iSCSI сервиса столь необходимого по развёртыванию кластера.
- Два сервера Windows Server 2008 R2 Enterprise введённые в домен
- Домен polygon.local
- Доменная учётная запись с правами Администратора
- Пять выделенных IP адрес
- Система FreeNAS установленная в VirtualBox
- Отключён энергосберегающий режим
- Часовой пояс GMT + 4
- Установлены все обновления через WSUS
Четыре сетевые карточки по две на каждую систему.
Eth0: 10.0.2.19 – внешняя сеть для домена polygon.local
Subnet Mask: 255.255.255.0
Eth1: 192.168.117.2 – внутренняя сеть, т.е. cluster 1 смотрит на cluster 2 и никуда более.
Subnet Mask: 255.255.255.0 (255.255.255.252 на два адреса)
Шлюза и DNS нет.
Subnet Mask: 255.255.255.0
Subnet Mask: 255.255.255.0
Шлюза и DNS нет.
Подготовим хосты Cluster1 и Cluster2 установив, в них компонент «FailoverClustering».
Настройки на хосте Cluster 1
Запускаем оснастку для добавления компонента «Средство отказоустойчивости кластеров»
«Start» – «Control Panel» – «Administrative Tools» – «Server Manager» – «Features» и добавляем
Компонент «Failover Clustering»
Проходим через Next и Install и ожидаем, пока компонент установится.
Настройки на хосте Cluster 2
Проделываем такие же манипуляции, как и с хостом Cluster2 по установке компонента.
Теперь подключим общий диск для обоих хостов .
Чтобы заработал кластер нам нужен общий диск подключённый к нашим системам Cluster1 и Cluster2 для этого задействуем встроенную оснастку «iSCSIInitiator». Как настроить подключение я уже расписывал, делаем согласно инструкции.
После переходим на систему Cluster1, далее открываем оснастку «Start» – «ControlPanel» – «AdministrativeTools» – «Server Manager» – «Storage» – «Disk Management» (Управление дисковой системой)
И обращаем внимание, что у нас появился подключённый через оснастку «iSCSIInitiator» диск:
Сейчас нужно его перевести в «Online» режим:
Создаём том (New Simple Volume…):
Нажимаем Next,
указываем размер тома в мегабайтах (я оставлю по умолчанию 2045), и присвоим букву для логического диска, к примеру «Q», укажем файловую систему (NTFS) и метку тома (к примеру «Quorum»).
Далее нужно зайти на второй узел Cluster2, также открыть оснастку «Start» – «Control Panel» – «Administrative Tools» – «Server Manager» – «Storage» – «Disk Management» (Управление дисковой системой) и по такому же принципу, как выше активируем диск, размечаем, но после переводим в состояние «Offline».
Подготовительная часть закончена.
Теперь можно перейти к объединению узлов Cluster 1 и Cluster 2 в кластер .
Данную процедуру выполняем только единожды
Для этого зайдём на первый хост Cluster1 и открываем оснастку «Failover Cluster Manager» для конфигурирования.
«Start» – «Control Panels» – «Administrative Tools» – «Failover Cluster Manager».
В появившейся оснастки следует запустить мастер проверки конфигурации – «Validatea Configuration…»
Сейчас, когда на обоих хостах установлен компонент, можно перейти к созданию кластера.
Нажимаем Next.
Сейчас необходимо выбрать узлы, из которых будем делать кластер , на предмет соответствия требованиям.
Вводим имя сервера, в моём случае Сluster1 и нажимаем Add (Добавить).
Нажимаем снова Next и на следующем шаге отмечаем пункт – «Run All Tests (recommended)» (Провести все тесты).
На представленном скриншоте ниже видно, что тесты завершаются успешно и Вы можете замечать, то появление, то исчезновение нашего подключённого общего iSCSI диска.
По окончании тестов можно ознакомиться с отчётом в котором присутствуют проблемные места, мешающие при поднятии кластера:
В моём случае все хорошо, проблем нет.
Обзываем кластер именем: service.polygon.local и IP адресом 10.0.2.39
, указываем узлы из которых строим кластер, это Cluster1 & Cluster2, Указываем имя для него service.polygon.local, и адресом 10.0.2.39, см. скриншот ниже, что у Вас должно получиться:
Нажимаем Next
На этом все подготовительные шаги завершены, нажимаем Next, собственно и происходит установка. По окончании развернув оснастку «Failover Cluster Manager» видим имя кластера, ноды из которых он состоит и общий диск.
Вот собственно и весь процесс поднятия кластера в тестовых условиях. Данная заметка своеобразный пошаговый процесс конфигурирования и тестирования функционала для применения уже в боевой системе. На этом всё, удачи.
Читайте также: