
Что такое ассоциативность кэша
Обновлено: 01.07.2024
Кэш-память (КП), или кэш, представляет собой организованную в виде ассоциативного запоминающего устройства (АЗУ) быстродействующую буферную память ограниченного объема, которая располагается между регистрами процессора и относительно медленной основной памятью и хранит наиболее часто используемую информацию совместно с ее признаками (тегами), в качестве которых выступает часть адресного кода.
В процессе работы отдельные блоки информации копируются из основной памяти в кэш - память . При обращении процессора за командой или данными сначала проверяется их наличие в КП. Если необходимая информация находится в кэше, она быстро извлекается. Это кэш-попадание. Если необходимая информация в КП отсутствует ( кэш-промах ), то она выбирается из основной памяти, передается в микропроцессор и одновременно заносится в кэш - память . Повышение быстродействия вычислительной системы достигается в том случае, когда кэш-попадания реализуются намного чаще, чем кэш-промахи.
Зададимся вопросом: "А как определить наиболее часто используемую информацию? Неужели сначала кто-то анализирует ход выполнения программы, определяет, какие команды и данные чаще используются, а потом, при следующем запуске программы, эти данные переписываются в кэш - память и уже тогда программа выполняется эффективно?" Конечно нет. Хотя в современных микропроцессорах имеется определенный механизм, который позволяет в некоторой степени реализовать этот принцип. Но в основном, конечно, кэш - память сама отбирает информацию, которая чаще всего используется. Рассмотрим, как это происходит.
Механизм сохранения информации в кэш-памяти
При включении микропроцессора в работу вся информация в его кэш-памяти недостоверна.
При обращении к памяти микропроцессор, как уже отмечалось, сначала проверяет, не содержится ли искомая информация в кэш-памяти.
Для этого сформированный им физический адрес сравнивается с адресами ячеек памяти, которые были ранее кэшированы из ОЗУ в КП.
При первом обращении такой информации в кэш -памяти, естественно, нет, и это соответствует кэш-промаху. Тогда микропроцессор проводит обращение к оперативной памяти, извлекает нужную информацию, использует ее в своей работе, но одновременно записывает эту информацию в кэш .
Если бы в кэш - память заносилась только востребованная микропроцессором в данный момент информация , то, скорее всего, при следующем обращении вновь произошел бы кэш-промах: вряд ли следующее обращение произойдет к той же самой команде или к тому же самому операнду. Кэш-попадания происходили бы лишь после того, как в КП накопится достаточно большой фрагмент программы, содержащий некоторые циклические участки кода, или фрагмент данных, подлежащих повторной обработке. Для того чтобы уже следующее обращение к КП приводило как можно чаще к кэш-попаданиям, передача из оперативной памяти в кэш - память происходит не теми порциями (байтами или словами), которые востребованы микропроцессором в данном обращении, а так называемыми строками. То есть кэш - память и оперативная память с точки зрения кэширования организуются в виде строк. Длина строки превышает максимально возможную длину востребованных микропроцессором данных. Обычно она составляет от 16 до 64 байт и выровнена в памяти по границе соответствующего раздела (рис. 4.1).
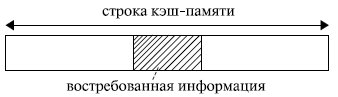
Рис. 4.1. Организация обмена между оперативной и кэш-памятью
Высокий процент кэш-попаданий в этом случае обеспечивается благодаря тому, что в большинстве случаев программы обращаются к ячейкам памяти, расположенным вблизи от ранее использованных. Это свойство, называемое принципом локальности ссылок, обеспечивает эффективность использования КП. Оно подразумевает, что при исполнении программы в течение некоторого относительно малого интервала времени происходит обращение к памяти в пределах ограниченного диапазона адресов (как по коду программы, так и по данным).
Например, микропроцессору для своей работы потребовалось 2 байта информации. Если строка имеет длину 16 байт , то в кэш переписываются не только нужные 2 байта, но и некоторое их окружение. Когда микропроцессор обращается за новой информацией, в силу локальности ссылок, скорее всего, обращение произойдет по соседнему адресу. Затем опять по соседнему, опять по соседнему и т. д. Таким образом, ряд следующих обращений будет происходить непосредственно к кэш -памяти, минуя оперативную память (кэш-попадания). Когда очередной сформированный микропроцессором физический адрес выйдет за пределы строки кэш -памяти (произойдет кэш-промах ), будет выполнена подкачка в кэш новой строки, и вновь ряд последующих обращений вызовет кэш-попадания.
Чем длиннее используемая при обмене между оперативной и кэшпамятью строка, тем больше вероятность того, что следующее обращение произойдет в пределах этой строки. Но в то же время чем длиннее строка, тем дольше она будет перекачиваться из оперативной памяти в кэш . И если очередная команда окажется командой перехода или выборка данных начнется из нового массива, то есть следующее обращение произойдет не по соседнему адресу, то время, затраченное на передачу длинной строки, будет использовано напрасно. Поэтому при выборе длины строки должен быть разумный компромисс между соотношением времени обращения к оперативной и кэш -памяти и вероятностью достаточно удаленного перехода от текущего адреса при выполнении программы. Обычно длина строки определяется в результате моделирования аппаратно-программной структуры системы .
После того как в КП накопится достаточно большой объем информации, увеличивается вероятность того, что формирование очередного адреса приведет к кэш-попаданию. Особенно велика вероятность этого при выполнении циклических участков программы.
Старая информация по возможности сохраняется в кэш -памяти. Ее замена на новую определяется емкостью, организацией и стратегией обновления кэша.
Типы кэш-памяти
Если каждая строка ОЗУ имеет только одно фиксированное место , на котором она может находиться в кэш -памяти, то такая кэш - память называется памятью с прямым отображением.
Предположим, что ОЗУ состоит из 1000 строк с номерами от 0 до 999, а кэш - память имеет емкость только 100 строк. В кэш -памяти с прямым отображением строки ОЗУ с номерами 0, 100, 200, . 900 могут сохраняться только в строке 0 КП и нигде иначе, строки 1, 101, 201, …, 901
ОЗУ - в строке 1 КП, строки ОЗУ с номерами 99, 199, …, 999 сохраняются в строке 99 кэш -памяти (рис. 4.2). Такая организация кэш -памяти обеспечивает быстрый поиск в ней нужной информации: необходимо проверить ее наличие только в одном месте. Однако емкость КП при этом используется не в полной мере: несмотря на то, что часть кэш -памяти может быть не заполнена, будет происходить вытеснение из нее полезной информации при последовательных обращениях, например, к строкам 101, 301, 101 ОЗУ .
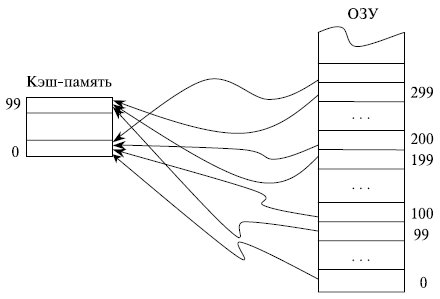
Рис. 4.2. Принцип организации кэш-памяти с прямым отображением
Кэш - память называется полностью ассоциативной, если каждая строка ОЗУ может располагаться в любом месте кэш -памяти.
В полностью ассоциативной кэш -памяти максимально используется весь ее объем: вытеснение сохраненной в КП информации проводится лишь после ее полного заполнения. Однако поиск в кэш -памяти, организованной подобным образом, представляет собой трудную задачу.
Компромиссом между этими двумя способами организации кэш -памяти служит множественно-ассоциативная КП, в которой каждая строка ОЗУ может находиться по ограниченному множеству мест в кэш -памяти.
При необходимости замещения информации в кэш -памяти на новую используется несколько стратегий замещения. Наиболее известными среди них являются:
- LRU - замещается строка, к которой дольше всего не было обращений;
- FIFO - замещается самая давняя по пребыванию в кэш-памяти строка;
- Random - замещение проходит случайным образом.
Последний вариант, существенно экономя аппаратные средства по сравнению с другими подходами, в ряде случаев обеспечивает и более эффективное использование кэш -памяти. Предположим, например, что КП имеет объем 4 строки, а некоторый циклический участок программы имеет длину 5 строк. В этом случае при стратегиях LRU и FIFO кэш - память окажется фактически бесполезной ввиду отсутствия кэш -попаданий. В то же время при использовании стратегии случайного замещения информации часть обращений к КП приведет к кэш -попаданиям.
Некоторые эвристические оценки вероятности кэш -промаха при разных стратегиях замещения (в процентах) представлены в табл. 4.1.
Анализ таблицы показывает, что:
- увеличением емкости кэша, естественно, уменьшается вероятность кэш-промаха, но даже при незначительной на сегодняшний день емкости кэш-памяти в 16 Кбайт около 95 % обращений происходят к КП, минуя оперативную память;
- чем больше степень ассоциативности кэш-памяти, тем больше вероятность кэш-попадания за счет более полного заполнения КП (время поиска информации в КП в данном анализе не учитывается);
- механизм LRU обеспечивает более высокую вероятность кэш-попадания по сравнению с механизмом случайного замещения Random , однако этот выигрыш не очень значителен.
Соответствие между данными в оперативной памяти и в кэш -памяти обеспечивается внесением изменений в те области ОЗУ , для которых данные в кэш -памяти подверглись изменениям. Существует два основных способа реализации этих действий: со сквозной записью ( writethrough ) и с обратной записью ( write-back ).
При считывании оба способа работают идентично. При записи кэширование со сквозной записью обновляет основную память параллельно с обновлением информации в КП. Это несколько снижает быстродействие системы, так как микропроцессор впоследствии может вновь обратиться по этому же адресу для записи информации, и предыдущая пересылка строки кэш -памяти в ОЗУ окажется бесполезной. Однако при таком подходе содержимое соответствующих друг другу строк ОЗУ и КП всегда идентично. Это играет большую роль в мультипроцессорных системах с общей оперативной памятью.
Кэширование с обратной записью модифицирует строку ОЗУ лишь при вытеснении строки кэш -памяти, например, в случае необходимости освобождения места для записи новой строки из ОЗУ в уже заполненную КП. Операции обратной записи также инициируются механизмом поддержания согласованности кэш -памяти при работе мультипроцессорной системы с общей оперативной памятью.
Промежуточное положение между этими подходами занимает способ, при котором все строки, предназначенные для передачи из КП в ОЗУ , предварительно накапливаются в некотором буфере. Передача осуществляется либо при вытеснении строки, как в случае кэширования с обратной записью, либо при необходимости согласования кэш -памяти нескольких микропроцессоров в мультипроцессорной системе, либо при заполнении буфера. Такая передача проводится в пакетном режиме, что более эффективно, чем передача отдельной строки.
Разработчики кэш-памяти столкнулись с проблемой, состоящей в том, что потенциально в кэш-памяти может оказаться любая ячейка огромной основной памяти. Если рабочий набор данных, используемых в программе, достаточно большой, то это означает, что за каждое место в кэш-памяти будут соревноваться многие фрагменты основной памяти. Как ранее уже сообщалось, нередко соотношение между кэш-памятью и основной памятью составляет 1 к 1000.
3.3.1 Ассоциативность
Можно было бы реализовать кэш-память, в которой каждая кэш-строка может хранить копию любой ячейки памяти. Это называется полностью ассоциативной кэш-памятью (fully associative cache). Чтобы получить доступ к кэш-строке, ядро процессора должно было бы сравнить теги всех до единой кэш-строк с тегом запрашиваемого адреса. Тег должен будет хранить весь адрес, который не будет указываться смещение в кэш-строке (это означает, что значение S, показанное на рисунке в разделе 3.2, будет равно нулю).
Есть кэш-память, которая реализована подобным образом, но взглянуть на размеры кэш-памяти L2, используемой в настоящее время, то видно, что это непрактично. Учтите, что 4 Мб кэш-памяти с кэш-строками размером в 64Б должна иметь 65 536 записей. Чтобы получить адекватную производительность, логические схемы кэш-памяти должны быть в состоянии в течение нескольких циклов выбрать из всех этих записей ту, которая соответствует заданному тегу. Затраты на реализацию такой схемы будут огромными.

Рис.3.5: Схематическое изображение полностью ассоциативной кэш-памяти
Для каждой кэш-строки требуется, чтобы компаратор выполнил сравнение тега большого размера (заметьте, S равно нулю). Буква, стоящая рядом с каждым соединением, обозначает ширину соединения в битах. Если ничего не указано, то ширина соединения равна одному биту. Каждый компаратор должен сравнивать два значения, ширина каждого из которых равна Т бит. Затем, исходя из результата, должно выбираться и стать доступным содержимое соответствующей кэш-строки. Для этого потребуется объединить столько наборов линий данных О, сколько есть сегментов кэш-памяти (cache buckets). Число транзисторов, необходимых для реализации одного компаратора будет большим в частности из-за того, что компаратор должен работать очень быстро. Итеративный компаратор использовать нельзя. Единственный способ сэкономить на количестве компараторов, это снизить их число с помощью итеративного сравнения тегов. Это не подходит по той же самой причине, по которой не подходят итеративные компараторы: на это потребуется слишком много времени.
Полностью ассоциативная кэш-память практична для кэш-памяти малого размера (например, кэш-память TLB в некоторых процессорах Intel является полностью ассоциативной), но эта кэш-память должна быть небольшой - действительно небольшой. Речь идет максимум о нескольких десятках записей.
Для кэш-памяти L1i, L1d и кэш-памяти более высокого уровня необходим другой подход. Все, что можно сделать, это ограничить поиск. В самом крайнем случае каждый тег отображается точно в одну кэш-запись. Расчет прост: для кэш-памяти 4MB/64B с 65 536 записями мы можем напрямую обращаться к каждому элементу и использовать для этого с 6-го по 21-й биты адреса (16 битов). Младшие 6 битов являются индексом кэш-строки.

Рис.3.6: Схематическое изображение кэш-памяти с прямым отображением
Как видно из рисунка 3.6 реализация такой кэш-памяти с прямым отображением (direct-mapped cache) может быть быстрой и простой. Для нее требуется только один компаратор, один мультиплексор (на этой схеме приведены два, поскольку тег и данные разделены, но это не является строгим конструктивным требованием) и некоторая логическая схема для выбора контента, содержащего действительно допустимые кэш-строки. Компаратор сложный из-за требований, касающихся скорости, но теперь он только один; в результате можно потратить больше усилий, чтобы сделать его более быстрым. Реальная сложность такого подхода заключена в мультиплексорах. Количество транзисторов в простом мультиплексоре растет по закону O(log N), где N является количеством кэш-строк. Это приемлемо, но может получиться медленный мультиплексор, и в этом случае скорость можно увеличить, если потратиться на транзисторы в мультиплексорах и для увеличения скорости распараллелить часть работы. Общее количество транзисторов будет расти медленное в сравнении с ростом размера кэш-памяти, что делает это решение очень привлекательным. Но у такого подхода есть недостаток: он работает только в случае, если адреса, используемые в программе, равномерно распределены относительно битов, используемых для прямого отображения. Если это не так, и это обычно бывает, некоторые кэш-записи используются активно и, поэтому, неоднократно высвобождаются, в то время как другие практически вообще не используются, либо остаются пустыми.

Рис.3.7: Схематическое изображение кэш-памяти с множественной ассоциативностью
Эту проблему можно решить с помощью кэш-памяти с множественной ассоциативностью (set associative). Кэш-память с множественностью ассоциативностью сочетает в себе черты кэш-памяти с полной ассоциативностью и кэш-памяти с прямым отображением, что позволяет в значительной степени избежать недостатков этих решений. На рис.3.7 показана схема кэш-памяти с множественной ассоциативностью. Память под теги и под данные разделена на наборы, выбор которых осуществляется в соответствие с адресом. Это похоже на кэш-память с прямым отображением. Но вместо того, чтобы для каждого значения из набора использовать отдельный элемент, один и тот же набор используется для кэширования некоторого небольшого количества значений. Теги для всех элементов набора сравниваются параллельно, что похоже на функционирование полностью ассоциативной кэш-памяти.
Результатом является кэш-память, которая достаточно устойчива к промахам из-за неудачного или преднамеренного выбора адресов с одними и теми же номерами наборов в одно и то же время, а размер кэш-памяти не ограничен количеством компараторов, которые могут работать параллельно. Если кэш-память увеличивается (смотрите рисунок), то увеличивается только количество столбцов, а не количество строк. Число строк увеличивается только в том случае, если повышается ассоциативность кэш-памяти. Сегодня процессоры для кэш-памяти L2 используют уровни ассоциативности до 16 и выше. Для кэш-памяти L1 обычно используется уровень, равный 8.
Таблица 3.1: Влияние размера кэш-памяти, ассоциативности и размера кэш-строки
| Размер кэш-памяти L2 | Ассоциативность | |||||||
|---|---|---|---|---|---|---|---|---|
| Прямое отображение | 2 | 4 | 8 | |||||
| CL=32 | CL=64 | CL=32 | CL=64 | CL=32 | CL=64 | CL=32 | CL=64 | |
| 512k | 27 794 595 | 20 422 527 | 25 222 611 | 18 303 581 | 24 096 510 | 17 356 121 | 23 666 929 | 17 029 334 |
| 1M | 19 007 315 | 13 903 854 | 16 566 738 | 12 127 174 | 15 537 500 | 11 436 705 | 15 162 895 | 11 233 896 |
| 2M | 12 230 962 | 8 801 403 | 9 081 881 | 6 491 011 | 7 878 601 | 5 675 181 | 7 391 389 | 5 382 064 |
| 4M | 7 749 986 | 5 427 836 | 4 736 187 | 3 159 507 | 3 788 122 | 2 418 898 | 3 430 713 | 2 125 103 |
| 8M | 4 731 904 | 3 209 693 | 2 690 498 | 1 602 957 | 2 207 655 | 1 228 190 | 2 111 075 | 1 155 847 |
| 16M | 2 620 587 | 1 528 592 | 1 958 293 | 1 089 580 | 1 704 878 | 883 530 | 1 671 541 | 862 324 |
В таблице 3.1 показано количество промахов кэш-памяти L2 для некоторой программы (в данном случае — для компилятора gcc, который, по мнению разработчиков ядра Linux, является наиболее важным бенчмарком) при изменении размера кэш-памяти, размера кэш-строки, а также значения множественной ассоциативности. В разделе 7.2 мы познакомимся с инструментальным средством, предназначенным для моделирования кэш-памяти, которое необходимо для этого теста.
Просто, если это еще не очевидно, взаимосвязь всех этих значений в том, что размер кэш-памяти равен
размер кэш-строки х ассоциативность х количество множеств
Отображение адресов в кэш-память вычисляется как
O = log2 от размера кэш-строки
S = log2 от числа наборов
согласно рисунку в разделе 3.2.

Рис.3.8: Размер кэш-памяти и уровень ассоциативности (CL=32)
Рис. 3.8 делает данные таблицы более понятными. На рисунке приведены данные для кэш-строки фиксированного размера, равного 32 байта. Если посмотреть на цифры для заданного размера кэш-памяти, то видно, что ассоциативность действительно может существенно помочь сократить число промахов кэш-памяти. Для кэш-памяти размером 8 МБ при переходе от прямого отображения на кэш-память с 2-канальной ассоциативностью экономится почти 44% кэш-памяти. В случае, если используется кэш-память со множественной ассоциативностью, то процессор может хранить в кэш-памяти рабочий набор большего размера, чем в случае кэш-памяти с прямым отображением.
В литературе иногда можно прочитать, что введение ассоциативности имеет тот же самый эффект, как удвоение размера кэш-памяти. Это, как это видно для случая перехода от кэш-памяти размером 4 МБ к кэш-памяти размером 8 МБ, верно в некоторых крайних случаях. Но это, конечно, не верно при последующем увеличении ассоциативности. Как видно из данных, последующее увеличение ассоциативности дает существенно меньший выигрыш. Нам, однако, не следует абсолютно не учитывать этот факт. В программе нашего примера пик использования памяти равен 5,6 MB. Так что при размере кэш-памяти в 8 Мб, что те же самые кэш-наборы будут использоваться многократно (более, чем дважды). С увеличением рабочего набора экономия может увеличиться, поскольку, как мы видим, при меньших размерах кэш-памяти преимущество от использования ассоциативности будет больше.
В целом, увеличение ассоциативность кэш-памяти выше 8, как кажется, дает слабый эффект при одном потоке рабочей нагрузки. С появлением многоядерных процессоров, которые используют общую кэш-память L2, ситуация меняется. Теперь у вас в основном есть две программы, которые обращаются к одной и той же кэш-памяти, в результате чего на практике эффект от использования ассоциативности должен увеличиться вдвое (или в четыре раза для четырехядерных процессоров). Таким образом, можно ожидать, что с увеличением числа ядер, ассоциативность общей кэш-памяти должна расти. Как это станет делать невозможным (16-канальную ассоциативность реализовывать уже трудно) разработчики процессоров начнут использовать общую кэш-память уровня L3 и далее, в то время как кэш-память уровня L2 будет, потенциально, совместно использоваться некоторым подмножеством ядер.
Другой эффект, который мы можем увидеть на рис.3.8, это то, как увеличение размера кэш-памяти способствует увеличению производительности. Эти данные нельзя интерпретировать без знания размера рабочего набора. Очевидно, что кэш-память такого размера, как основная память, должен привести к лучшим результатам, нежели кэш-память меньшего размера, так что в целом нет никаких ограничений на увеличение размера кэш-памяти и получения ощутимых преимуществ.
Как уже упоминалось выше, размер рабочего набора в его пиковом значении равен 5,6 Мб. Это значение не позволяет нам рассчитать размер памяти, который бы принес максимальную выгоду, но позволяет оценить этот размер. Проблема в том, что вся память используется не непрерывно и, следовательно, у нас есть конфликты даже при наличии 16M кэш-памяти и рабочего набора, размер которого равен 5,6M (вспомните преимущество 2-канальной ассоциативной кэш-памяти размером в 16 МБ над версией с прямым отображением). Но можно с уверенностью сказать, что при такой нагрузке преимущество кэш-памяти размером в 32 МБ будет несущественным. Однако кто сказал, что рабочий набор должен оставаться неизменным? С течением времени рабочие нагрузки растут и то же самое должно касаться размера кэш-памяти. Когда покупаются машины и принимается решение, за какой размер кэш-памяти требуется заплатить, стоит измерить размер рабочего набора. Почему это важно, можно увидеть на рис. 3.10.

Рис.3.9: Размещение памяти, используемой при тестировании
Запускается два типа тестов. В первом тесте элементы обрабатываются последовательно. В тестовой программе используется указатель n , но элементы массива связаны друг с другом, так что они обходятся в том порядке, в котором они находятся в памяти. Этот вариант показан в нижней части рис.3.9. Есть одна обратная ссылка, идущая от последнего элемента. Во втором тесте (верхняя часть рисунка) элементы массива обходятся в произвольном порядке. В обоих случаях элементы массива образуют циклический односвязный список.

Для многих пользователей основополагающими критериями выбора процессора являются его тактовая частота и количество вычислительных ядер. А вот параметры кэш-памяти многие просматривают поверхностно, а то и вовсе не уделяют им должного внимания. А зря!
В данном материале поговорим об устройстве и назначении сверхбыстрой памяти процессора, а также ее влиянии на общую скорость работы персонального компьютера.
Предпосылки создания кэш-памяти
Любому пользователю, мало-мальски знакомому с компьютером, известно, что в составе ПК работает сразу несколько типов памяти. Это медленная постоянная память (классические жесткие диски или более быстрые SSD-накопители), быстрая оперативная память и сверхбыстрая кэш-память самого процессора. Оперативная память энергозависимая, поэтому каждый раз, когда вы выключаете или перезагружаете компьютер, все хранящиеся в ней данные очищаются, в отличие от постоянной памяти, в которой данные сохраняются до тех пор, пока это нужно пользователю. Именно в постоянную память записаны все программы и файлы, необходимые как для работы компьютера, так и для комфортной работы за ним.
Каждый раз при запуске программы из постоянной памяти, ее наиболее часто используемые данные или вся программа целиком «подгружаются» в оперативную память. Это делается для ускорения обработки данных процессором. Считывать и обрабатывать данные из оперативной памяти процессор будет значительно быстрей, а, следовательно, и система будет работать значительно быстрее в сравнении с тем, если бы массивы данных поступали напрямую из не очень быстрых (по меркам процессорных вычислений) накопителей.
Если бы не было «оперативки», то процесс считывания напрямую с накопителя занимал бы непозволительно огромное, по меркам вычислительной мощности процессора, время.

Но вот незадача, какой бы быстрой ни была оперативная память, процессор всегда работает быстрее. Процессор — это настолько сверхмощный «калькулятор», что произвести самые сложные вычисления для него — это даже не доля секунды, а миллионные доли секунды.
Производительность процессора в любом компьютере всегда ограничена скоростью считывания из оперативной памяти.
Процессоры развиваются так же быстро, как память, поэтому несоответствие в их производительности и скорости сохраняется. Производство полупроводниковых изделий постоянно совершенствуется, поэтому на пластину процессора, которая сохраняет те же размеры, что и 10 лет назад, теперь можно поместить намного больше транзисторов. Как следствие, вычислительная мощность за это время увеличилась. Впрочем, не все производители используют новые технологии для увеличения именно вычислительной мощности. К примеру, производители оперативной памяти ставят во главу угла увеличение ее емкости: ведь потребитель намного больше ценит объем, нежели ее быстродействие. Когда на компьютере запущена программа и процессор обращается к ОЗУ, то с момента запроса до получения данных из оперативной памяти проходит несколько циклов процессора. А это неправильно — вычислительная мощность процессора простаивает, и относительно медленная «оперативка» тормозит его работу.
Такое положение дел, конечно же, мало кого устраивает. Одним из вариантов решения проблемы могло бы стать размещение блока сверхбыстрой памяти непосредственно на теле кристалла процессора и, как следствие, его слаженная работа с вычислительным ядром. Но проблема, мешающая реализации этой идеи, кроется не в уровне технологий, а в экономической плоскости. Такой подход увеличит размеры готового процессора и существенно повысит его итоговую стоимость.

Объяснить простому пользователю, голосующему своими кровными сбережениями, что такой процессор самый быстрый и самый лучший, но за него придется отдать значительно больше денег — довольно проблематично. К тому же существует множество стандартов, направленных на унификацию оборудования, которым следуют производители «железа». В общем, поместить оперативную память прямо на кристалл процессора не представляется возможным по ряду объективных причин.
Как работает кэш-память
Как стало понятно из постановки задачи, данные должны поступать в процессор достаточно быстро. По меркам человека — это миг, но для вычислительного ядра — достаточно большой промежуток времени, и его нужно как можно эффективнее минимизировать. Вот здесь на выручку и приходит технология, которая называется кэш-памятью. Кэш-память — это сверхбыстрая память, которую располагают прямо на кристалле процессора. Извлечение данных из этой памяти не занимает столько времени, сколько бы потребовалось для извлечения того же объема из оперативной памяти, следовательно, процессор молниеносно получает все необходимые данные и может тут же их обрабатывать.
Кэш-память — это, по сути, та же оперативная память, только более быстрая и дорогая. Она имеет небольшой объем и является одним из компонентов современного процессора.
На этом преимущества технологии кэширования не заканчиваются. Помимо своего основного параметра — скорости доступа к ячейкам кэш-памяти, т. е. своей аппаратной составляющей, кэш-память имеет еще и множество других крутых функций. Таких, к примеру, как предугадывание, какие именно данные и команды понадобятся пользователю в дальнейшей работе и заблаговременная загрузка их в свои ячейки. Но не стоит путать это со спекулятивным исполнением, в котором часть команд выполняется рандомно, дабы исключить простаивание вычислительных мощностей процессора.
Спекулятивное исполнение — метод оптимизации работы процессора, когда последний выполняет команды, которые могут и не понадобиться в дальнейшем. Использование метода в современных процессорах довольно существенно повышает их производительность.
Речь идет именно об анализе потока данных и предугадывании команд, которые могут понадобиться в скором будущем (попадании в кэш). Это так называемый идеальный кэш, способный предсказать ближайшие команды и заблаговременно выгрузить их из ОЗУ в ячейки сверхбыстрой памяти. В идеале их надо выбирать таким образом, чтобы конечный результат имел нулевой процент «промахов».
Но как процессор это делает? Процессор что, следит за пользователем? В некоторой степени да. Он выгружает данные из оперативной памяти в кэш-память для того, чтобы иметь к ним мгновенный доступ, и делает это на основе предыдущих данных, которые ранее были помещены в кэш в этом сеансе работы. Существует несколько способов, увеличивающих число «попаданий» (угадываний), а точнее, уменьшающих число «промахов». Это временная и пространственная локальность — два главных принципа кэш-памяти, благодаря которым процессор выбирает, какие данные нужно поместить из оперативной памяти в кэш.
Временная локальность
Процессор смотрит, какие данные недавно содержались в его кэше, и снова помещает их в кэш. Все просто: высока вероятность того, что выполняя какие-либо задачи, пользователь, скорее всего, повторит эти же действия. Процессор подгружает в ячейки сверхбыстрой памяти наиболее часто выполняемые задачи и сопутствующие команды, чтобы иметь к ним прямой доступ и мгновенно обрабатывать запросы.
Пространственная локальность
Принцип пространственной локальности несколько сложней. Когда пользователь выполняет какие-то действия, процессор помещает в кэш не только данные, которые находятся по одному адресу, но еще и данные, которые находятся в соседних адресах. Логика проста — если пользователь работает с какой-то программой, то ему, возможно, понадобятся не только те команды, которые уже использовались, но и сопутствующие «слова», которые располагаются рядом.
Набор таких адресов называется строкой (блоком) кэша, а количество считанных данных — длиной кэша.
При пространственной локации процессор сначала ищет данные, загруженные в кэш, и, если их там не находит, то обращается к оперативной памяти.
Иерархия кэш-памяти
Любой современный процессор имеет в своей структуре несколько уровней кэш-памяти. В спецификации процессора они обозначаются как L1, L2, L3 и т. д.

Если провести аналогию между устройством кэш-памяти процессора и рабочим местом, скажем столяра или представителя любой другой профессии, то можно увидеть интересную закономерность. Наиболее востребованный в работе инструмент находится под рукой, а тот, что используется реже, расположен дальше от рабочей зоны.
Так же организована и работа быстрых ячеек кэша. Ячейки памяти первого уровня (L1) располагаются на кристалле в непосредственной близости от вычислительного ядра. Эта память — самая быстрая, но и самая малая по объему. В нее помещаются наиболее востребованные данные и команды. Для передачи данных оттуда потребуется всего около 5 тактовых циклов. Как правило, кэш-память первого уровня состоит из двух блоков, каждый из которых имеет размер 32 КБ. Один из них — кэш данных первого уровня, второй — кэш инструкций первого уровня. Они отвечают за работу с блоками данных и молниеносное обращение к командам.
Кэш второго и третьего уровня больше по объему, но за счет того, что L2 и L3 удалены от вычислительного ядра, при обращении к ним будут более длительные временные интервалы. Более наглядно устройство кэш-памяти проиллюстрировано в следующем видео.
Кэш L2, который также содержит команды и данные, занимает уже до 512 КБ, чтобы обеспечить необходимый объем данных кэшу нижнего уровня. Но на обработку запросов уходит в два раза больше времени. Кэш третьего уровня имеет размеры уже от 2 до 32 МБ (и постоянно увеличивается вслед за развитием технологий), но и его скорость заметно ниже. Она превышает 30 тактовых циклов.

Процессор запрашивает команды и данные, обрабатывая их, что называется, параллельными курсами. За счет этого и достигается потрясающая скорость работы. В качестве примера рассмотрим процессоры Intel. Принцип работы таков: в кэше хранятся данные и их адрес (тэг кэша). Сначала процессор ищет их в L1. Если информация не найдена (возник промах кэша), то в L1 будет создан новый тэг, а поиск данных продолжится на других уровнях. Для того, чтобы освободить место под новый тэг, информация, не используемая в данный момент, переносится на уровень L2. В результате данные постоянно перемещаются с одного уровня на другой.
Также при хранении одних и тех же данных могут задействоваться различные уровни кэша, например, L1 и L3. Это так называемые инклюзивные кэши. Использование лишнего объема памяти окупается скоростью поиска. Если процессор не нашел данные на нижнем уровне, ему не придется искать их на верхних уровнях кэша. В этом случае задействованы кэши-жертвы. Это полностью ассоциативный кэш, который используется для хранения блоков, вытесненных из кэша при замене. Он предназначен для уменьшения количества промахов. Например, кэши-жертвы L3 будут хранить информацию из L2. В то же время данные, которые хранятся в L2, остаются только там, что помогает сэкономить место в памяти, однако усложняет поиск данных: системе приходится искать необходимый тэг в L3, который заметно больше по размеру.
В некоторых политиках записи информация хранится в кэше и основной системной памяти. Современные процессоры работают следующим образом: когда данные пишутся в кэш, происходит задержка перед тем, как эта информация будет записана в системную память. Во время задержки данные остаются в кэше, после чего их «вытесняет» в ОЗУ.
Итак, кэш-память процессора — очень важный параметр современного процессора. От количества уровней кэша и объема ячеек сверхбыстрой памяти на каждом из уровней, во многом зависит скорость и производительность системы. Особенно хорошо это ощущается в компьютерах, ориентированных на гейминг или сложные вычисления.
Вы здесь: Главная Память. Нижний уровень КЭШ-память Ассоциативная памятьАрхитектура ЭВМ
Компоненты ПК
Интерфейсы
Мини блог
Самое читаемое
- Арифметико логическое устройство (АЛУ)
- Страничный механизм в процессорах 386+. Механизм трансляции страниц
- Организация разделов на диске
- Диск Picture CD
- White Book/Super Video CD
- Прямой доступ к памяти, эмуляция ISA DMA (PC/PCI, DDMA)
- Карты PCMCIA: интерфейсы PC Card, CardBus
- Таблица дескрипторов прерываний
- Разъемы процессоров
- Интерфейс Slot A
Ассоциативная память
Ассоциативная память
В ассоциативной памяти элементы выбираются не по адресу, а по содержимому. Поясним последнее понятие более подробно. Для памяти с адресной организацией было введено понятие минимальной адресуемой единицы (МАЕ) как порции данных, имеющей индивидуальный адрес. Введем аналогичное понятие для ассоциативной памяти, и будем эту минимальную единицу хранения в ассоциативной памяти называть строкой ассоциативной памяти (СтрАП). Каждая СтрАП содержит два поля: поле тега (англ. tag — ярлык, этикетка, признак) и поле данных. Запрос на чтение к ассоциативной памяти словами можно выразить следующим образом: выбрать строку (строки), у которой (у которых) тег равен заданному значению.
Особо отметим, что при таком запросе возможен один из трех результатов:
- имеется в точности одна строка с заданным тегом;
- имеется несколько строк с заданным тегом;
- нет ни одной строки с заданным тегом.
Поиск записи по признаку — это действие, типичное для обращений к базам данных, и поиск в базе зачастую чвляется ассоциативным поиском. Для выполнения такого поиска следует просмотреть все записи и сравнить заданный тег с тегом каждой записи. Это можно сделать и при использовании для хранения записей обычной адресуемой памяти (и понятно, что это потребует достаточно много времени — пропорционально количеству хранимых записей!). Об ассоциативной памяти говорят тогда, когда ассоциативная выборка данных из памяти поддержана аппаратно. При записи в ассоциативную память элемент данных помещается в СтрАП вместе с присущим этому элементу тегом. Для этого можно использовать любую свободную СтрАП. Рассмотрим разновидности структурной организации КЭШ-памяти или способы отображения оперативной памяти на КЭШ.
Полностью ассоциативный КЭШ
Схема полностью ассоциативного КЭШа представлена на рисунке (см. рисунок ниже).
Опишем алгоритм работы системы с КЭШ-памятью. В начале работы КЭШ-память пуста. При выполнении первой же команды во время выборки ее код, а также еще несколько соседних байтов программного кода, — будут перенесены (медленно) в одну из строк КЭШа, и одновременно старшая часть адреса будет записана в соответствующий тег. Так происходит заполнение КЭШ-строки.
Если следующие выборки возможны из этого участка, они будут сделаны уже из КЭШа (быстро) — "КЭШ-попадание". Если же окажется, что нужного элемента в КЭШе нет, — "КЭШ-промахом". В этом случае обращение происходит к ОЗУ (медленно), и при этом одновременно заполняется очередная КЭШ-строка.
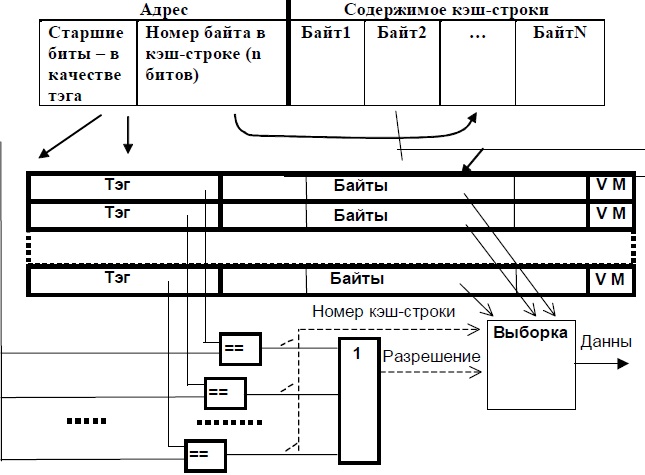
Схема полностью ассоциативной КЭШ-памяти
Обращение к КЭШу происходит следующим образом. После формирования исполнительного адреса его старшие биты, образующие тег, аппаратно (быстро) и одновременно сравниваются с тегами всех КЭШ-строк. При этом возможны только две ситуации из трех, перечисленных ранее: либо все сравнения дадут отрицательный результат (КЭШ-промах), либо положительный результат сравнения будет зафиксирован в точности для одной строки (КЭШ-попадание).
При считывании, если зафиксировано КЭШ-попадание, младшие разряды адреса определяют позицию в КЭШ-строке, начиная с которой следует выбирать байты, а тип операции определяет количество байтов. Очевидно, что если длина элемента данных превышает один байт, то возможны ситуации, когда этот элемент (частями) расположен в двух (или более) разных КЭШ-строках, тогда время на выборку такого элемента увеличится. Противодействовать этому можно, выравнивая операнды и команды по границам КЭШ-строк, что и учитывают при разработке оптимизирующих трансляторов или при ручной оптимизации кода.
Если произошел КЭШ-промах, а в КЭШе нет свободных строк, необходимо заменить одну строку КЭШа на другую строку.
Основная цель стратегии замещения — удерживать в КЭШ-памяти строки, к которым наиболее вероятны обращения в ближайшем будущем, и заменять строки, доступ к которым произойдет в более отдаленном времени или вообще не случится. Очевидно, что оптимальным будет алгоритм, который замещает ту строку, обращение к которой в будущем произойдет позже, чем к любой другой строке-КЭШ.
К сожалению, такое предсказание практически нереализуемо, и приходится привлекать алгоритмы, уступающие оптимальному. Вне зависимости от используемого алгоритма замещения, для достижения высокой скорости он должен быть реализован аппаратными средствами.
Среди множества возможных алгоритмов замещения наиболее распространенными являются четыре, рассматриваемые в порядке уменьшения их относительной эффективности. Любой из них может быть применен в полностью ассоциативном КЭШ.
Наиболее эффективным является алгоритм замещения на основе наиболее давнего использования ( LRU — Least Recently Used ), при котором замещается та строка КЭШ-памяти, к которой дольше всего не было обращения. Проводившиеся исследования показали, что алгоритм LRU, который "смотрит" назад, работает достаточно хорошо в сравнении с оптимальным алгоритмом, "смотрящим" вперед.
Наиболее известны два способа аппаратурной реализации этого алгоритма. В первом из них с каждой строкой КЭШ-памяти ассоциируют счетчик. К содержимому всех счетчиков через определенные интервалы времени добавляется единица. При обращении к строке ее счетчик обнуляется. Таким образом, наибольшее число будет в счетчике той строки, к которой дольше всего не было обращений и эта строка — первый кандидат на замещение.
Второй способ реализуется с помощью очереди, куда в порядке заполнения строк КЭШ-памяти заносятся ссылки на эти строки. При каждом обращении к строке ссылка на нее перемещается в конец очереди. В итоге первой в очереди каждый раз оказывается ссылка на строку, к которой дольше всего не было обращений. Именно эта строка прежде всего и заменяется.
Другой возможный алгоритм замещения — алгоритм, работающий по принципу "первый вошел, первый вышел" ( FIFO — First In First Out ). Здесь заменяется строка, дольше всего находившаяся в КЭШ-памяти. Алгоритм легко реализуется с помощью рассмотренной ранее очереди, с той лишь разницей, что после обращения к строке положение соответствующей ссылки в очереди не меняется.
Еще один алгоритм — замена наименее часто использовавшейся строки (LFU — Least Frequently Used). Заменяется та строка в КЭШ-памяти, к которой было меньше всего обращений. Принцип можно воплотить на практике, связав каждую строку со счетчиком обращений, к содержимому которого после каждого обращения добавляется единица. Главным претендентом на замещение является строка, счетчик которой содержит наименьшее число.
Простейший алгоритм — произвольный выбор строки для замены. Замещаемая строка выбирается случайным образом. Реализовано это может быть, например, с помощью счетчика, содержимое которого увеличивается на единицу с каждым тактовым импульсом, вне зависимости от того, имело место попадание или промах. Значение в счетчике определяет заменяемую строку.
Кроме тега и байтов данных в КЭШ-строке могут содержаться дополнительные служебные поля, среди которых в первую очередь следует отметить бит достоверности V (от valid — действительный имеющий силу) и бит модификации M (от modify — изменять, модифицировать). При заполнении очередной КЭШ-строки V устанавливается в состояние "достоверно", а M — в состояние "не модифицировано". В случае, если в ходе выполнения программы содержимое данной строки было изменено, переключается бит M, сигнализируя о том, что при замене данной строки ее содержимое следует переписать в ОЗУ. Если по каким-либо причинам произошло изменение копии элемента данной строки, хранимого в другом месте (например в ОЗУ), переключается бит V. При обращении к такой строке будет зафиксирован КЭШ-промах (несмотря на то, что тег совпадает), и обращение произойдет к основному ОЗУ. Кроме того, служебное поле может содержать биты, поддерживающие алгоритм LRU.
Оценка объема оборудования
Типовой объем КЭШ-памяти в современной системе — 8…1024 кбайт, а длина КЭШ-строки 4…32 байт. Дальнейшая оценка делается для значений объема КЭШа 256 кбайт и длины строки 32 байт, что характерно для систем с процессорами Pentium и PentiumPro. Длина тега при этом равна 27 бит, а количество строк в КЭШе составит 256К/ 32=8192. Именно столько цифровых компараторов 27 битных кодов потребуется для реализации вышеописанной структуры.
Приблизительная оценка затрат оборудования для построения цифрового компаратора дает значение 10 транз/бит, а общее количество транзисторов только в блоке компараторов будет равно:
10*27*8192 = 2 211 840,
что приблизительно в полтора раза меньше общего количества транзисторов на кристалле Pentium. Таким образом, ясно, что описанная структура полностью ассоциативной КЭШ-памяти ( ассоциативная память ) реализуема только при малом количестве строк в КЭШе, т.е. при малом объеме КЭШа (практически не более 32…64 строк). КЭШ большего объема строят по другой структуре.
Читайте также: