
Delphi выделить память под массив
Обновлено: 04.07.2024
Буду описывать здесь процесс выполнения различных работ.
четверг, 1 марта 2012 г.
Динамический массив в Delphi
1. Динамические массивы в Delphi не имеют фиксированного размера . Чтобы объявить такой массив необходимо записать:Как видим , мы просто говорим Delphi, что нам нужен одномерный массив типа Integer, а об его размере мы скажем когда нибудь потом.
При таком объявлении память не выделяется, поэтому мы можем объявить много таких динамических массивов, не особо беспокоясь об объеме занимаемой памяти, и использовать любой динамический массив по мере надобности.
2. Для выделения памяти для динамического массива в Delphi используется процедура SetLength:
После вызова этой процедуры будет выделена память для 20 элементов массива, которые будут проиндексированы от 0 до 19 (обратите внимание: индексирование начинается с нуля, а не с единицы!).
После этого можно работать с динамическим массивом- присваивать ему значения, производить с элементами различные вычисления, вывод на печать и т.д.
Например
da_MyArray[0] := 5 ;
da_MyArray[9] := 9 ;
da_MyArray[1] := da_MyArray[0]+ da_MyArray[9] ;
3. Как только динамический массив был распределен, вы можете передавать массив стандартным функциям Length, High, Low и SizeOf Функция Length возвращает число элементов в динамическом массиве, High возвращает самый высокий индекс массива (то есть Length - 1), Low возвращает 0. В случае с массивом нулевой длины наблюдается интересная ситуация: High возвращает -1, а Low - 0, получается, что High меньше Low. :) Функция SizeOf всегда возвращает 4 - длина в байтах памяти указателя на динамический массив
iHigh := High (da_MyArray3);
iLow := Low (da_MyArray3);
4. Доступ к данным динамических массивов с помощью низкоуровневых процедур типа ReadFile или WriteFile , или любых других подпрограмм, получающих доступ сразу ко всему массиву, часто выполняется неправильно. Для обычного массива (его часто называют также статическим массивом - в противоположность динамическому массиву) переменная массива тождественна его данным. Для динамического массива это не так - переменная это указатель. Так что если вы хотите получить доступ к данным динамического массива - вы не должны использовать саму переменную массива, а использовать вместо неё первый элемент массива.
правильно
WriteFile(FHandle, da_MyArray02[0], Length(da_MyArray02), dwTemp, nil )
неправильно
WriteFile(FHandle, da_MyArray02, Length(da_MyArray02), dwTemp, nil )
5. Рассмотрим пример присваивания динамических массивов одного другому
После этих манипуляций da_A[0] равно 4. Дело в том , что при присвоении da_A:=da_B не происходит копирование т.к. da_A, da_B, это всего лишь указатели на область памяти. Для копирования необходимо использовать функцию Copy.
6. Рассмотрим пример копирования динамических массивов с использованием функции Copy
После этих манипуляций da_A[0] равно 3. После функции Copy da_A и da_B указывают на разные области памяти, поэтому при изменении da_B в da_A ничего не происходит и его значения остаются неизменными.
7. Динамические массивы (например, array of Integer ) в Delphi в памяти расположены следующим образом. Библиотека runtime добавляет специальный код, который управляет доступом и присваиваниями. В участке памяти ниже адреса, на который указывает ссылка динамического массива, располагаются служебные данные массива: два поля - число выделенных элементов и счётчик ссылок (reference count).
 |
| Расположение динамического массива в памяти |
Если, как на диаграмме выше, N - это адрес в переменной динамического массива, то счётчик ссылок массива лежит по адресу N - 8 , а число выделенных элементов (указатель длины) лежит по адресу N - 4 . Первый элемент массива (сами данные) лежит по адресу N .
Для каждой добавляемой ссылки (т.е. при присваивании, передаче как параметр в подпрограмму и т.п.) увеличивается счётчик ссылок, а для каждой удаляемой ссылки (т.е. когда переменная выходит из области видимости или при переприсваивании или присваивании nil) счётчик уменьшается.
Использовались функции SetLength, High, Low, Length, SizeOf, OpenFile, WriteFile, SetFilePointer, ReadFile, CloseHandle, ShellExecute, IntToStr, IntToHex, Integer, Copy, Ptr
var rec: array of PTRec;
Вообще, реальная запись выглядит так:
Я могу предположить, что изменение длины массива arr требует динамического "растягивания" памяти под запись,
а я могу предположить что в массиве rec нету элемента с индексом i.
и буду прав.
> Юрий Зотов © (19.09.12 22:21) [5]
Я попробую.
ну и вопросики ты задаёшь )
1) чтобы обращаться к памяти по указателю, нужно чтобы указатель указывал на конкретные данные. Либо на глобальную переменную, либо на локальную переменную, либо на переменную вообще где-то, либо выделяя память в Куче (динамическая память)
2) выделить память в куче можно двумя способами.
GetMem (удаление FreeMem)
New (удаление Dispose)
GetMem просто выделяет память, New выделяет память и инициализирует сложные данные
3) сложные данные - это особые типы данных, которые особым образом инициализируются и удаляются внутри Delphi, без явного участия программиста. К сложным типа относят строки (кроме ShortString), Variant, Interface, динамические массивы. Или структуры/массивы, которые внутри себя содержат сложные типы.
4) если выделяешь память по New(), то автоматическая инициализация произойдёт без твоего участия. Если по GetMem, то тебе надо занулить сложные переменные. Либо FillChar/ZeroMemory, либо в твоём случае:
GetMem(pointer(r), sizeof(TRec));
pointer(r.s) := nil;
pointer(r.arr) := nil;
Советы помогли. Можно предварительно обнулять память или использовать new/dispose. Я дальше почитаю об этом что-нибудь, чтобы лучше понимать.
Следует хотя бы из того, что с ними а) нет проблем с выделением, освобождением памяти, финализацией, меньше проблем с утечками б) нет проблем с чтением, записью в) класс лучше чем record г) Strings.LoadFromFile/SaveToFile лучше чем BlockRead/BlockWrite, которые суть рудименты для обратной совместимости с кодом 20-30 летней давности.
Для наследников TComponent в Delphi придуман механизм сериализации. Готовый.
С чего ты взял, что классы это только TList и прочие готовые? Тебе говорят - сделай свой. Ты в ответ - Нет, мне не надо, мне не подходит, я хочу посложнее сделать с косяками, чтобы потом выгребать. Помогайте мне. И это даже не вникнув в смысл совета.
Каждой программе выделяется своё адресное пространство. В нём хранятся коды команд, ячейки для хранения значений переменных, область стека. Область для хранения значений переменных выделяется при компиляции программы и не меняется в процессе работы программы. Такая память называется статической.
В 32-х разрядных приложениях адресное пространство ограничено значением 2 32 -1
4 Гб (4 294 967 255 байт).
Предположим, что половина памяти отведена под переменные. Длина машинных команд может иметь максимум 15 байт. Тогда в оставшейся половине может разместиться примерно 143 000 000 машинных команд.
Будем считать (очень грубо), что на выполнение одного операнда (сложение, умножение и так далее) требуется 10 команд. Тогда оказывается доступно 14 300 00 операндов.
Если в одной строке (операторе) присутствует в среднем 10 операндов, то в программе может быть примерно 1 340 000 строк (операторов).
Конечно, это сверх приблизительные подсчёты. Относительно короткая программа может потребовать такого объёма памяти, который выходит за рамки отведённого под программу пространства.
Тогда в запасе у программиста есть ещё 4 Гб памяти, называемой динамической. В отличие от статической, она распределяется в процессе работы программы.
Тип char.
Мы уже неоднократно использовали различные типы данных. Например, тип char. В переменной такого типа может храниться один символ. Всего под хранение символа отведен 1 байт, то есть можно закодировать 2 8 -1=255 символа. В первой половине таблицы (127 символов) хранятся специальные символы языка, буквы латинского алфавита и цифры. Во второй половине — буквы национального алфавита.
Такой набор символов называется кодовой таблицей символов, можно найти в справочных материалах.
Для примера, латинской букве A соответствует код $41 в шестнадцатеричном исчислении, 65 в десятичном или 01 00 00 01 в двоичном.
Тип Integer.
Для хранения целых чисел мы использовали тип Integer. По него отводится 4 байта, то есть 32 бита. Так как старший бит кодирует знак (0 — число положительное, 1 — отрицательное), то под само число остаётся 31 бит, в которых может храниться число, меньшее 2 31 -1 =2 147 483 647.
Тип double и extended.
Для работы с вещественными (десятичными) числами чаще всего применяют тип double, под который отводится 8 байт.
Но в хранении вещественных чисел есть одна особенность. Пусть у нас есть число (999 999 999 999. 999). В памяти компьютера оно будет представлено в виде (0.999 999 999 999 999 * 10 12 ). то есть вещественное число хранится в двух частях. Первая часть 6 байт хранит мантису (наши девятки), а вторая — порядок (степень числа 10).
Для типа double мантиса размещается в 52 битах, то максимальное число, которое можно хранить 2 51 -1 =4 503 599 627 370 495. Если вывести это число в Edit (преобразовав его в строку функцией floatToStr(х) ), то мы увидим
4, 503 599 627 370 5*10 15 , то есть вывелась десятичная дробь, имеющая 14 знаков. Это произошло потому, что был отброшен 16-ый знак. Но так как это 5, то следующий знак увеличен на 1 и получилась единица переноса, поэтому вместо 4 мы увидели 5.
Если вывести число 888 888 888 888 888, занимающее 15 позиций, то оно выведется именно как 888 888 888 888 888. Если его умножить на 2, то позиций в числе станет 16, и число выведется в экспоненциальном виде
1,77 777 777 777 778E15, хотя на самом деле это число
1,77 777 777 777 7776E15 .Таким образом все разряды, большие пятнадцати, отбрасываются, а последний разряд округляется.
Это надо учитывать при вычислениях. Например, надо сравнить два десятичных 16-ти разрядных числа и в зависимости от того, какое число больше, сделать какое-то действие.
Пусть у этих чисел отличается только последний знак (например у одного числа он 6, а у другого 7). Но в итоге оба числа окажутся равными, так как последний знак будет отброшен и произведено округление.
Подобные ситуации трудно диагностировать. Поэтому при работе с большими числами надо быть очень внимательным!
Есть ещё один тип для работы с десятичными числами, для хранения которых отводится 10 байт — это тип Extended. У него 19 значащих цифр, в отличие от 15 у double.
Тип Currency.
Под этот тип тоже отводится 10 байт. Но если тип double может быть примерно до 1,7*10 308 , тип Extended 1,1*10 4932 , то тип Currency имеет только 19 значащих цифр без экспоненты (без степени числа 10).
Приведённых типов данных вполне хватает для проведения подавляющего большинства вычислений. Если всё же возникает потребность в иных видах представления чисел, можно обратиться к справочной литературе.
Тип String.
По сути, это одномерный открытый массив символов, длина которого ограничена только доступной памятью.
Идентификаторы переменных.
Имена переменных называют идентификаторами. Они составляются из латинских букв и цифр, а также знака подчёркивания. Первый знак — буква. Количество символов в идентификаторе не ограничено, но компилятор распознаёт только первые 255 символов.
Поэтому, если 255 первых символов будут одинаковыми, а 256-ой символ у этих переменных отличается, они всё равно будут восприняты как одинаковые и произойдет ошибка компиляции, так как в пределах видимости не может не может быть двух одинаковых идентификаторов переменных.
При первом проходе компилятора создаётся таблица, сопоставляющая набор символов (имя переменной) и адрес, отведённый для хранения значения этой переменной.
При втором проходе при компиляции программы компилятор просматривает, где в тексте программы встречается имя переменной, и вместо него подставляет адрес переменной, взятый из таблицы.
Таким образом происходит преобразование мнемонических (символьных) имен в адреса переменных.
Описанный процесс показывает, как происходит распределение памяти для глобальных переменных.
Параметры процедур.
Для работы процедур и функций в них передаются значения переменных. Но, за некоторым исключением, процедура не будет иметь доступа к самим переменным.
При вызове процедуры переменная, передаваемая процедуре как параметр, оставляет свою копию в особой области памяти программы, называемой стеком. В стек копируются значения параметров в той очерёдности, в которой они указаны в шапке процедуры.
Стек — это область памяти фиксированного объёма (65 535 байт) типа «очередь», организованная таким образом, что она растёт как лёд в воде, который сверху периодически поливают водой и он замерзает слой за слоем, а нижняя кромка льда опускается всё ниже и ниже, пока не достигнет дна.
Таким образом, последнее записанное значение оказывается на вершине стека, адрес которой зафиксирован.
При вызове процедуры фактические параметры один за другим копируются в стек в том порядке, в котором они записаны в скобках. При этом в стек размещаются копии значений переменных и констант.
Процедура считывает из стека такое количество значений, которое указано в её шапке. Значения последовательно считываются из стека, начиная с вершины, и присваиваются формальным параметрам процедуры.
Вот почему необходимо, чтобы количество, порядок и типы переменных в вызывающем операторе и в шапке процедуры строго соответствовали друг другу.
Передавая значения параметров в процедуру, надо помнить, что объём стека ограничен и не слишком велик, а также что процесс копирования требует времени, что при частых обращениях к процедуре может стать критичным.
Такая организация передачи значений переменных разрывает связь процедуры с передаваемой переменной, что гарантирует неприкосновенность значения этой переменной. Процедура работает только с копией значения.
Если же процедура должна работать с большим количеством данных, например с массивом, то в процедуру передаётся ссылка на первый элемент массива. В процедуре такие формальные переменные помечены ключевым словом «var».
В этом случае надо быть очень осторожным, так как работа будет проводиться с самим массивом, а не с его копией!
delphi указатели.
Динамическая память. Типы указателей.
При работе программы часто возникает необходимость хранить в памяти полученные результаты (например, результаты расчётов), количество которых заранее не известно.
Имеется возможность при наличии свободного пространства памяти распределять её для хранения таких данных. Как указывалось ранее, в 32-х разрядной версии Delphi возможно адресовать
4Гб памяти. Это пространство называется «куча».
Для размещения данных в куче используют особые переменные, называемые «указатель».
Такая переменная хранит не само значение данных, а указатель на ячейку памяти в куче, в которую записаны данные (точнее, на первый байт данных, так как большинство из них имеют длину, большую одного байта).
Указатели бывают двух типов.
В первом случае известен тип данных, на который ссылается указатель. За счет этого при чтении данных, на которые указывает адрес, содержащейся в переменной «указатель», будет прочитано столько байт, сколько соответствует данному типу данных.
Поэтому такие указатели называются «типизированными».
Например, если указатель объявлен как указывающий на целый тип данных, то при чтении из памяти будет извлечено 8 последовательных байт и полученная информация интерпретирована как целое число.
Во втором случае при объявлении указателя указывается не тип данных, а явно количество байт, отводимых под переменную.
Объявление типизированных указателей.
Типизированный указатель объявляется следующим образом:
type имя_типа=^базовый_тип (или пользовательский тип)
var имя_переменной_указателя: имя_типа;
Или непосредственно var имя_переменной_указателя:^базовый_тип (или пользовательский тип).
Например, объявить указатель на данные целого типа:
type tPInt=^Integer;
var vPInt: tPInt;
var vPInt:^Integer;
Delphi работа с памятью.
Но объявленная переменная-указатель пока не содержит в себе ссылки (адреса). Там находится случайная информация. Чтобы привязать к указателю конкретный адрес в куче, переменную надо инициализировать процедурой: new():
new(vPInt);
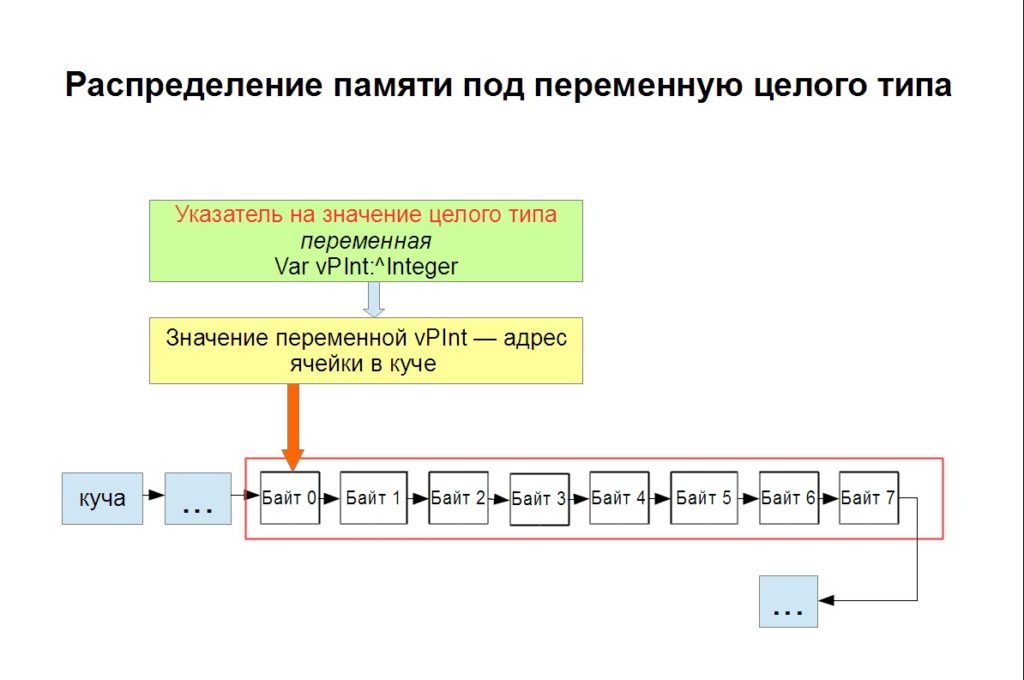
Теперь в указатель vPInt записан конкретный адрес и по этому адресу можно разместить целое значение (разименовать указатель).
Делается это с помощью нотации:
vPInt^:=12345;
Применяя динамическое распределение памяти, надо следить, чтобы она «быстро» не закончилась. Для этого, если надобность в данных отпала, нужно применить процедуру освобождения динамической памяти:
dispose(vPInt);
Теперь связь с кучей потеряна и область памяти, занимаемая ранен данными, оказывается свободной. Далее этот указатель использовать в программе нельзя.
Только что объявленный, но ещё не инициализированный указатель можно приравнять предопределённому «пустому» значению nil:
vPInt:=nil;
Это не позволит прочитать «мусор», если вдруг в указателе случайно оказался реальный адрес. Ещё хуже, если этот указатель указывает на область кучи, содержащей данные. Таким образом можно разрушить хранимые значения.
Однако и после «уничтожения» указателя его также можно приравнять nil.
Проверка значения указателя на nil не позволит дважды инициализировать указатель, что приведёт к ошибке времени выполнения и программа остановится.
Кроме того, если объявленный, но не инициализированный указатель сразу пометить как nil, топроверка указателя на nil позволит записывать данные только в инициализированный указатель.
if vPInt=nil then new(vPInt);
или if vPInt <> nil then vPInt^:=12345;
Процедуру dispose(vPInt); надо всегда применять, как только надобность в данных отпадает (во избежании утечки памяти).
Определение адреса и размера переменной.
Иногда необходимо знать адрес начала расположения переменной. Это делается с помощью функции
addr(X)
Применению указанной функции эквивалентна нотация: @X.
Замечание. Если приравнять vPInt:=addr(X); (или vPInt:=@X), то vPInt^ становится эквивалентом X.
Если мы создаём указатель на сложную структуру, например «запись», то бывает полезно знать, сколько байт она занимает в памяти. Для этого применяют функцию:
sizeOf(vPInt);
Нетипизированные указатели.
Значение, хранящиеся в нетипизированном указателе, содержит адрес первой ячейки памяти, распределённой в куче для хранения данных. Дальнейшие манипуляции с выделенным объёмом памяти ложатся на плечи программиста.
Нетипизированный указатель объявляется следующим образом:
var p:pointer;
Далее выделяется блок памяти процедурой
getMem(p,N)
где N – количество требуемых байт памяти.
Освобождается память процедурой:
freeMem(p,N)
Особенности объявления типизированных указателей.
Типизированные указатели, как и простые переменные, можно приравнивать друг к другу. Например:
var p1,p2:^Integer; x:Integer;
p1:=@x;
p2:=p1;
Но здесь есть существенный нюанс. Дело в том, что приравнивать можно только переменные одного типа.
При объявлении переменных тип переменной назначается неявно и он является уникальным для группы переменных, перечисленных в одном объявлении (как показано в приведённом примере);
Но если сделать объявление переменных:
то типы, присвоенные для p1 и p2 при компиляции, будут иметь разные имена. Поэтому
вызовет ошибку времени выполнения.
В то же время нотация:
type tPInt=^Integer;
var p1: tPInt; p2:tPInt;
p1:=@x;
p2:=p1;
ошибки не вызовет, так как переменным присвоен один и тот же тип.
Другой способ избежать коллизии — использовать нетипизированный указатель. Нотация:
var p1:^Integer; p2:^Integer; p:pointer;
p1:=@x;
p:=p1;
p2:=p;
Заключение.
Рассмотрены понятия динамической и статической памяти, а также как в delphi динамическая память распределяется. Более подробно рассмотрены типы данных Char, Integer, Double. Добавлены новые типы extended и сurrency. Рассмотрен механизм связи идентификатора и его адреса. Также рассмотрен механизм использования параметров процедур и функций. Даны примеры, как в delphi указатели различного типа используются для организации памяти в куче, а также инструменты работы с ними посредством процедур и функций.
Массив √ это упорядоченный набор данных. Как правило, количество элементов массива ограничено. Среда Delphi использует синтаксис языка Object Pascal, а согласно последнему, массивы объявляются так:
Где index1 и indexN принадлежат упорядоченному типу, диапазон которого, как написано в документации по Delphi 6, не превышает 2Gb. BaseType √ тип элементов массива.
Мы объявили массив My_Array, состоящий из 100 элементов типа Real. Массивы могут быть одномерными, двухмерными и n-мерными. Теоретически, ограничения на размерность массива нет, на практике размерность ограничена доступной памятью.
Все сказанное верно для статических массивов. Однако статические массивы обладают существенным недостатком. В большинстве случаев мы не знаем, из скольких элементов будет состоять наш массив. Поэтому приходится резервировать память "про запас": лучше я зарезервирую память еще для десяти элементов массива, чем один элемент массива окажется лишним. Например, при чтении информации из файла мы не знаем, сколько элементов мы можем прочитать: один, два, десять или сто. Обычно для решения таких задач применялись динамические списки LIFO (Last In First Out, стек) или FIFO (First In First Out, очередь).
Разработчики Delphi в последних версиях (5,6) своего продукта реализовали достаточно гибкий механизм для работы с динамическими массивами. Нам уже не нужно создавать динамические списки, мы уже никогда не забудем поставить знак "^" при обращении к элементу списка и на определенное время забудем о процедурах new, mark и dispose.
Примечание. В более ранних версиях (например, 3) такого механизма не существовало.
Динамические массивы не имеют фиксированного размера или длины. Для объявления такого массива достаточно записать:
Как вы видите, мы просто говорим Delphi, что нам нужен одномерный массив типа Real, а об его размере мы сказать просто-напросто забыли.
При таком объявлении память не выделяется, поэтому мы можем объявить хоть сотню таких массивов, не особо беспокоясь о системных ресурсах, и использовать любой массив по мере необходимости. Для выделения памяти для динамического массива используется процедура SetLength:
После вызова этой процедуры будет выделена память для 100 элементов массива, которые будут проиндексированы от 0 до 99 (обратите внимание: индексирование начинается с нуля, а не с единицы!).
Динамические массивы √ это неявные указатели и обслуживаются тем же самым механизмом, который используется для обработки длинных строк (long strings). Чтобы освободить память, занимаемую динамическим массивом, присвойте переменной, которая ссылается на массив, значение nil: A:=nil.
Сухая теория без практики √ это ничто, поэтому для лучшего переваривания материала рассмотрим следующую программу:
Это консольное приложение, при его запуске вы увидите окно, напоминающее сеанс DOS. Скорее всего, это окно закроется, прежде чем вы успеете его увидеть. Поэтому узнать, как же все-таки Delphi работает с этим чудом природы, вам поможет режим пошаговой трассировки программы (активизируется нажатием клавиши F7). Перед запуском приложения с помощью команды меню Run, Add Watch (Ctrl + F5) добавьте в список просмотра переменных две переменные √ A и B .
Затем откройте окно Watch List, нажав комбинацию клавиш Ctrl + Alt + W и установите режим окна Stay On Top (команда Stay On Top появится в всплывающем меню, если вы щелкните правой кнопкой где-нибудь в области окна), чтобы окно не скрылось из виду, когда вы запустите программу .В листинге 1 возле каждой строки я указал значения переменных A и B после прохода строки. Как вы заметили, я пронумеровал только строки, которые содержат операторы, изменяющие переменные A и B.
Строка 1: для переменных A и B память не выделена. Отсюда вывод: до вызова процедуры SetLength работать с массивом нельзя. Во второй строке память выделена только для массива A. Поскольку переменная A √ глобальная, значения элементов массива обнуляются. Если бы переменная A была локальной, потребовалась инициализация элементов массива. Локальные переменные не обнуляются и, как правило, содержат случайные значения (мусор), взятые из памяти, в которой размещена переменная.
В третьей строке мы присваиваем массиву B массив A. Перед этой операцией не нужно выделять память для массива B с помощью SetLength. При присваивании элементу B[0] присваивается элемент A[0], B[1] √ A[1] и т.д. Обратите внимание на строку 4: мы присвоили новые значения переменным массива A и автоматически (массивы √ это же указатели) элементам массива B присвоились точно такие же значения и наоборот: стоит нам изменить какой-либо элемент массива B, изменится элемент массива A с соответствующим индексом.
Теперь начинается самое интересное. При изменении длины массива А (строка 5) произошел разрыв связи между массивами. Это явление демонстрирует строка 6, содержащая ряд операторов присваивания. Сначала мы присваиваем значения элементам массива A: 2, 4, 5. Затем пытаемся изменить значение элемента A[0], присвоив элементу B[0] значение 1. Но, как мы убедились, связи между массивами уже нет и после изменения значения элемента B[0], значение элемента A[0] не было изменено. Еще один важный момент: при изменении длины массива просто добавляется новый элемент, без потери уже существующих значений элементов (строка 5). Длина связанного массива B не изменяется.
В строке 7 мы освобождаем память, выделенную для массива A. Массив B остается существовать до конца работы программы. Массивы нулевой длины содержат значение nil.
Нужно сказать пару слов о сравнении массивов:
При попытке сравнения A=B или B=A мы получим true: массивы равны. А вот в такой ситуации при сравнении мы получим false:
Для того, чтобы обрезать массив можно использовать ту же процедуру SetLength или процедуру Copy. Первая работает намного быстрее, поэтому я рекомендую использовать именно ее. Рассмотрим следующий фрагмент кода:
При обрезании (уменьшении длины) происходит освобождение памяти с конца массива: удаляются последние элементы. Процедуру Copy для этой же цели можно использовать так:
При попытке присвоить значение элементу статического массива, индекс которого выходит за границы массива, мы получим соответствующую ошибку: Constant expression violates subrange bounds (нарушение границ диапазона). При работе с динамическими массивами вы не увидите подобной ошибки. С одной стороны это хорошо, а с другой √ плохо. Вы можете потратить уйму времени, чтобы понять, почему вы не можете присвоить значение элементу массива с индексом 4, пока не обнаружите, что в самом начале программе выделили память только для трех элементов. Сейчас эта ситуация кажется смешной, но она происходит намного чаще, чем вам кажется. Функция SetLength порождает ошибку EOutOfMemory, если недостаточно памяти для распределения массива.
Не применяйте оператор "^" к переменной динамического массива. Также не следует передавать переменную массива процедурам New или Dispose для выделения или освобождения памяти.
Как только динамический массив был распределен, вы можете передавать массив стандартным функциям Length, High и Low. Функция Length возвращает число элементов в массиве, High возвращает массив самый высокий индекс (то есть Length √ 1), Low возвращает 0. В случае с массивом нулевой длины наблюдается парадоксальная ситуация: High возвращает -1, а Low √ 0, получается, что High < Low.
Как мы можем использовать функции High и Low с наибольшей пользой? Для этого рассмотрим процедуру init и функцию sum. Первая из них инициализирует массив (обнуляет значения элементов), а вторая √ подсчитывает сумму элементов массива:
Остается неясным один момент: можно ли использовать многомерные динамические массивы? Да, можем. Объявить двухмерный массив можно так:
Для выделения памяти нужно вызвать процедуру SetLength с двумя параметрами, например,
Работать с двухмерным динамическим массивом можно так же, как и со статическим:
Вы можете создавать не прямоугольные массивы. Для этого сначала объявите массив:
Затем создайте n рядков, но без колонок, например,
Теперь вы можете создавать колонки разной длины:
Примечание. Если вы работали с более ранними версиями Delphi, то, наверное, знаете, что функция SetLength использовалась для динамического изменения длины строки. Скорее всего, вы ее не использовали, потому что длина строки изменялась автоматически при операции присваивания.
Одним из мощнейших средств языка Delphi являются динамические массивы. Их основное отличие от обычных массивов заключается в том, что они хранятся в динамической памяти. Этим и обусловлено их название. Чтобы понять, зачем они нужны, рассмотрим пример:
var
N: Integer;
A: array[1..100] of Integer; // обычный массив
begin
Write('Введите количество элементов: ');
ReadLn(N);
.
end.
Задать размер массива A в зависимости от введенного пользователем значения невозможно, поскольку в качестве границ массива необходимо указать константные значения. А введенное пользователем значение никак не может претендовать на роль константы. Иными словами, следующее объявление будет ошибочным:
var
N: Integer;
A: array[1..N] of Integer; // Ошибка!
begin
Write('Введите количество элементов: ');
ReadLn(N);
.
end.
На этапе написания программы невозможно предугадать, какие именно объемы данных захочет обрабатывать пользователь. Тем не менее, Вам придется ответить на два важных вопроса:
На какое количество элементов объявить массив?
Что делать, если пользователю все-таки понадобится большее количество элементов?
Вы можете поступить следующим образом. В качестве верхней границы массива установить максимально возможное (с вашей точки зрения) количество элементов, а реально использовать только часть массива. Если пользователю потребуется большее количество элементов, чем зарезервировано Вами, то ему можно попросту вежливо отказать. Например:
const
MaxNumberOfElements = 100;
var
N: Integer;
A: array[1.. MaxNumberOfElements] of Integer;
begin
Write('Введите количество элементов (не более ', MaxNumberOfElements, '): ');
ReadLn(N);
if N > MaxNumberOfElements then
begin
Write('Извините, программа не может работать ');
Writeln('с количеством элементов больше , ' MaxNumberOfElements, '.');
end
else
begin
. // Инициализируем массив необходимыми значениями и обрабатываем его
end;
end.
Такое решение проблемы является неоптимальным. Если пользователю необходимо всего 10 элементов, программа работает без проблем, но всегда использует объем памяти, необходимый для хранения 100 элементов. Память, отведенная под остальные 90 элементов, не будет использоваться ни Вашей программой, ни другими программами (по принципу "сам не гам и другому не дам"). А теперь представьте, что все программы поступают таким же образом. Эффективность использования оперативной памяти резко снижается.
Динамические массивы позволяют решить рассмотренную проблему наилучшим образом. Размер динамического массива можно изменять во время работы программы.
Динамический массив объявляется без указания границ:
var
DynArray: array of Integer;
Переменная DynArray представляет собой ссылку на размещаемые в динамической памяти элементы массива. Изначально память под массив не резервируется, количество элементов в массиве равно нулю, а значение переменной DynArray равно nil.
Работа с динамическими массивами напоминает работу с длинными строками. В частности, создание динамического массива (выделение памяти для его элементов) осуществляется той же процедурой, которой устанавливается длина строк - SetLength.
SetLength(DynArray, 50); // Выделить память для 50 элементов
Изменение размера динамического массива производится этой же процедурой:
SetLength(DynArray, 100); // Теперь размер массива 100 элементов
При изменении размера массива значения всех его элементов сохраняются. При этом последовательность действий такова: выделяется новый блок памяти, значения элементов из старого блока копируются в новый, старый блок памяти освобождается.
При уменьшении размера динамического массива лишние элементы теряютяся.
При увеличении размера динамического массива добавленные элементы не инициализируются никаким значением и в общем случае их значения случайны. Однако если динамический массив состоит из элементов, тип которых предполагает автоматическую инициализацию пустым значением (string, Variant, динамический массив, др.), то добавленная память инициализируется нулями.
Определение количества элементов производится с помощью функции Length:
N := Length(DynArray); // N получит значение 100
Элементы динамического массива всегда индексируются от нуля. Доступ к ним ничем не отличается от доступа к элементам обычных статических массивов:
DynArray[0] := 5; // Присвоить начальному элементу значение 5
DynArray[High(DynArray)] := 10; // присвоить конечному элементу значение 10
К динамическим массивам, как и к обычным массивам, применимы функции Low и High, возвращающие минимальный и максимальный индексы массива соответственно. Для динамических массивов функция Low всегда возвращает 0.
Освобождение памяти, выделенной для элементов динамического массива, осуществляется установкой длины в значение 0 или присваиванием переменной-массиву значения nil (оба варианта эквивалентны):
SetLength(DynArray, 0); // Эквивалентно: DynArray := nil;
Однако Вам вовсе необязательно по окончании использования динамического массива освобождать выделенную память, поскольку она освобождается автоматически при выходе из области действия переменной-массива (удобно, не правда ли!). Данная возможность обеспечивается уже известным Вам механизмом подсчета количества ссылок.
Также, как и при работе со строками, при присваивании одного динамического массива другому, копия уже существующего массива не создается.
var
A, B: array of Integer;
begin
SetLength(A, 100); // Выделить память для 100 элементов
A[0] := 5;
B := A; // A и B указывают на одну и ту же область памяти!
B[1] := 7; // Теперь A[1] тоже равно 7!
B[0] := 3; // Теперь A[0] равно 3, а не 5!
end.
В приведенном примере, в переменную B заносится адрес динамической области памяти, в которой хранятся элементы массива A (другими словами, ссылочной переменной B присваивается значение ссылочной переменной A).
Как и в случае со строками, память освобождается, когда количество ссылок становится равным нулю.
var
A, B: array of Integer;
begin
SetLength(A, 100); // Выделить память для 100 элементов
A[0] := 10;
B := A; // B указывает на те же элементы, что и A
A := nil; // Память еще не освобождается, поскольку на нее указывает B
B[1] := 5; // Продолжаем работать с B, B[0] = 10, а B[1] = 5
B := nil; // Теперь ссылок на блок памяти нет. Память освобождается
end;
Для работы с динамическими массивами вы можете использовать знакомую по строкам функцию Copy. Она возвращает часть массива в виде нового динамического массива.
Не смотря на сильное сходство динамических массивов со строками, у них имеется одно существенное отличие: отсутствие механизма копирования при записи (copy-on-write).
Читайте также: