
Если нет файла роботс
Обновлено: 02.07.2024
Думаю, никто не будет в обиде, если я перенесу эту статью сюда.
Энциклопедия интернет-маркетинга: составляем корректный robots.txt своими руками
SEOnews запустил проект для специалистов и клиентов "Энциклопедия интернет-маркетинга", в рамках которого редакция пуб…
Если попросить SEO-специалиста оценить важность правильно составленного robots.txt для сайта, хороший SEOшник оценит ее на 5 баллов из 5.
Кривой robots.txt, не учитывающий всех тонкостей сайта, может сильно навредить его индексации.
Одна неучтенн а я директива, и поисковики тут же вывалят в свой индекс всю подноготную сайта, например, как это было в 2011 году с утечкой SMS пользователей Мегафона.
Или одна лишняя или неправильно составленная директива, и часть сайта, или даже весь сайт, вылетит из индекса поисковых систем, а значит, потеряет весь поисковый трафик.
Если вы уже знакомы с основами составления robots.txt, можете сразу переходить к пункту 3 «Составление robots.txt».
- Введение
- Что такое robots.txt
- Директивы и спецсимволы robots.txt
- Настройка Google Search Consloe (GSC)
- Как составить правильный robots.txt самостоятельно
- Распространенные ошибки при составлении robots.txt
- Заключение
- Полезные ссылки
Для начала определимся что из себя представляет этот файл и зачем он нужен.
В справке Яндекса дано следующее определение:
То есть, другими словами, robots.txt — набор директив, которым однозначно подчиняются роботы поисковых систем при индексировании сайта.
Сказано «индексировать» страницу или раздел, будет индексировать. Сказано «не индексировать», не будет.
Но, несмотря на всю важность данного файла, подавляющее большинство сайтов в русском сегменте интернета не имеют правильно составленного robots.txt.
Порядок включения директив:
<Директива><двоеточие><пробел><документ, к которому применяется директива>
Для начала стоит сказать о том, какие директивы могут использоваться в файле robots.txt.
User-agent — указание робота, для которого составлен список директив ниже. Обязательная для robots.txt директива, которая указывается в начале файла.
- Основной User-agent поисковой системы Яндекс — Yandex (список роботов Яндекса, которым можно указать отдельные директивы).
- Основной User-agent поисковой системы Google — Googlebot (список роботов Google, которым можно указать отдельные директивы).
- Если список директив указывается для всех возможных User-agent’ов, ставится — «*»
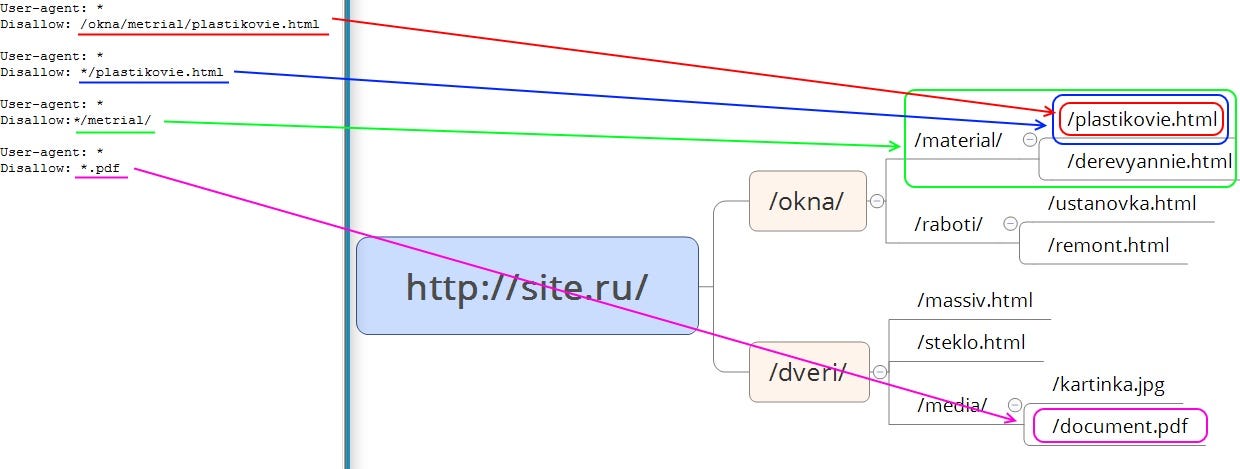
Disallow — директива запрета индексации документов. Можно указывать как каталог, так и часть названия документа, так и полный путь документа.
- При запрете индексации документа путь определяется от корня сайта (красная стрелка на рисунке 1).
- Для запрета индексации документов второго и далее уровней можно указывать полный путь документа, или перед адресом документа указывается знак «*» (синяя стрелка на рисунке 1).
- При запрете индексации каталога также будут запрещены к индексации все страницы, входящие в этот каталог (зеленая стрелка на рисунке 1).
- Можно запрещать для индексации документы, в url которых содержатся определенные символы (розовая стрелка на рисунке 1).
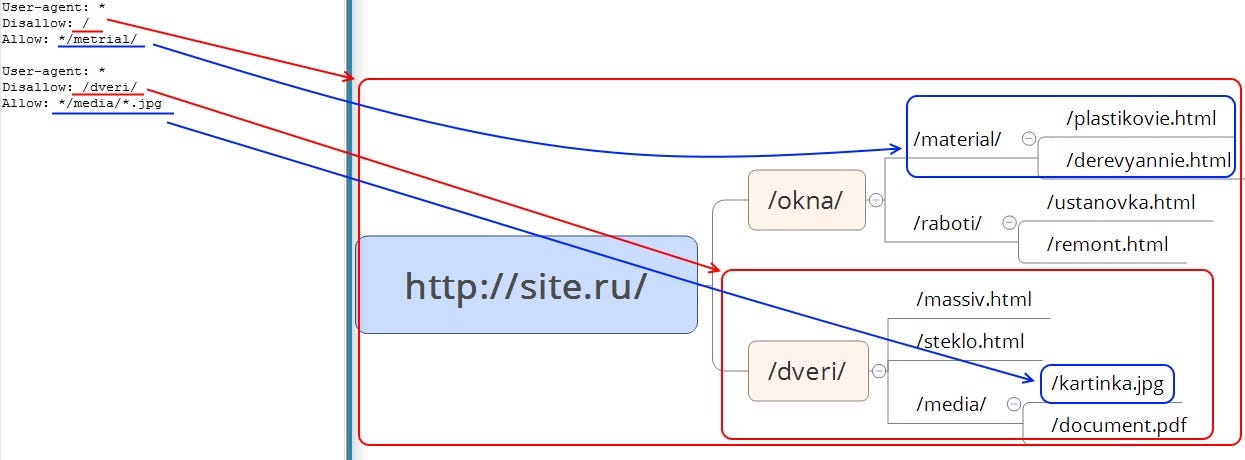
Allow — директива разрешения индексации документов. Является директивой по умолчанию для всех документов на сайте, если не указано другое.
- Используется для открытия к индексации документов (синие стрелки), которые по той или иной причине находятся в каталогах, закрытых от индексации (красные стрелки).
- Можно открывать для индексации документы, в url которых содержатся определенные символы (синие стрелки).
- Стоит обратить внимание на правила применения директив Disallow-Allow: «Директивы Allow и Disallow из соответствующего User-agent блока сортируются по длине префикса URL (от меньшего к большему) и применяются последовательно.»
Sitemap — директива для указания пути к файлу xml-карты сайта.
- Если сайт имеет более 1 карты xml, допустимо указание нескольких путей.
Спецсимволы
Host — директива указания главного зеркала сайта. Учитывается только роботами Яндекса.
Crawl-delay — директива указания минимального времени (в секундах) между окончанием загрузки одной страницы и началом загрузки следующей. Учитывается только роботами Яндекса. Директива используется, чтоб роботы поисковых систем не перегружали сайт.
- Для ограничения времени между окончанием загрузки одной страницы и началом загрузки следующей в поисковой системе Google используется функция «Настройки сайта» в Google Search Console
Clean-param — директива используется для удаления параметров из url-адресов сайта. Учитывается только роботами Яндекса.
- Может использоваться для удаления меток отслеживания, фильтров, идентификаторов сессий и других параметров.
- Для правильной обработки меток роботами Google используется функция «Параметры URL» в Google Search Console.
Как говорилось ранее, часть функций, которые можно указать для роботов Яндекса в robots.txt, для роботов Google надо указывать в Google Search Console.
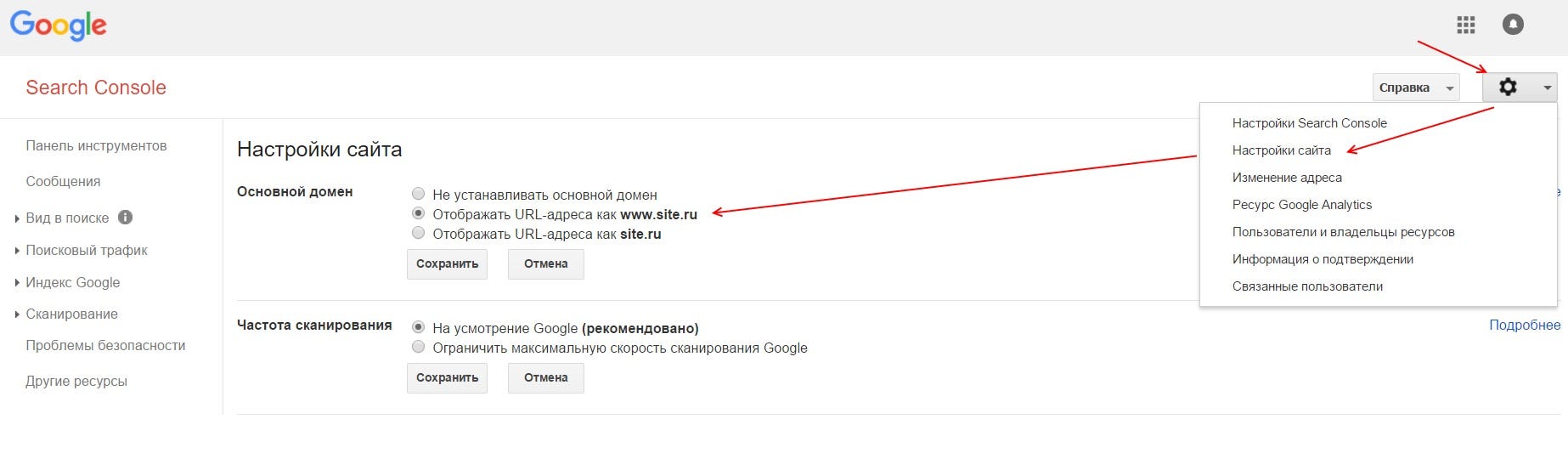
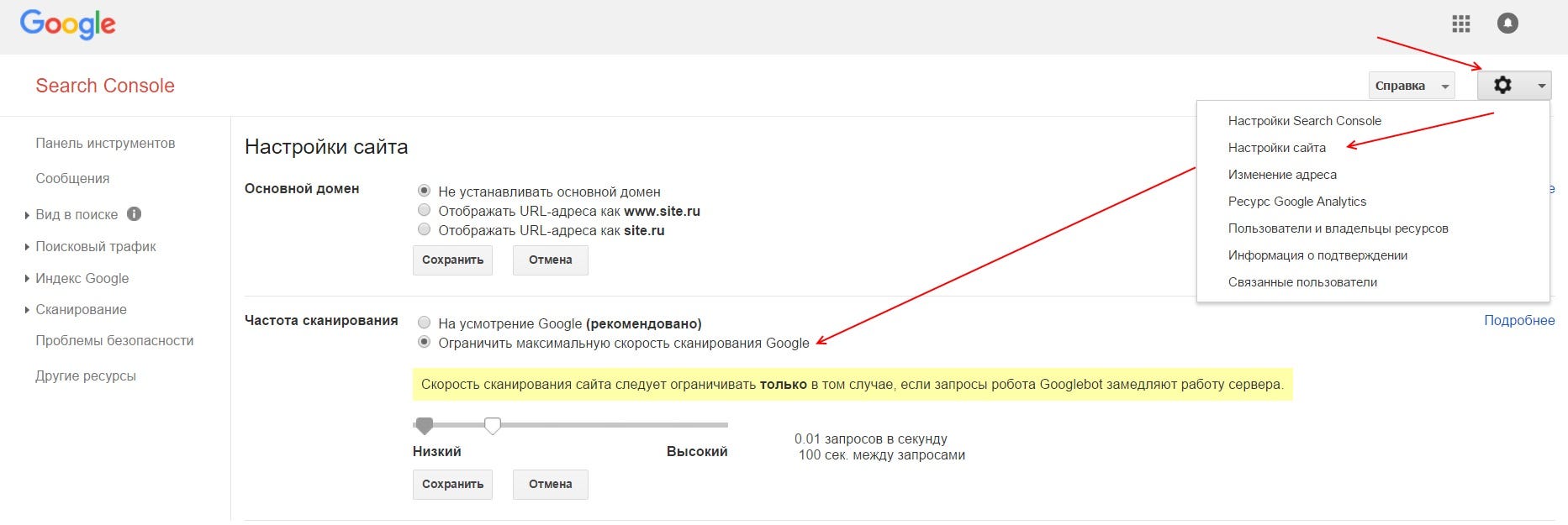
Чтобы ограничить скорость сканирования сайта роботами Google необходимо подтвердить сайт в GSC. Зайти в настройки сайта (знак шестеренки), там выбрать ссылку «Настройка сайта», в блоке «Частота сканирования» выбрать пункт «Ограничить максимальную скорость сканирования Google» и выставить приемлемое значение, после чего сохранить изменения.
Для того чтобы задать, как Google будет обрабатывать параметры в url-адресах сайта необходимо подтвердить сайт в GSC. Зайти в раздел «Сканирование» — «Параметры URL», нажать на кнопку «Добавление параметра», заполнить соответствующие поля и сохранить изменения.
- В поле «Параметр» добавляется сам параметр. Это поле является регистрозависимым.
- В поле «Изменяет ли этот параметр содержание страницы, которое видит пользователь?», вне зависимости от реального значения параметра, рекомендуем выбирать пункт «Да, параметр изменяет, реорганизует или ограничивает содержимое страницы», так как при выборе варианта «Нет, параметр не влияет на содержимое страницы (например, отслеживает использование) есть вероятность того что, одна страница с параметром все же попадет в индекс.
- Выбор в поле «Как этот параметр влияет на содержимое страницы?» влияет только на то как этот параметр будет отображаться в списке других параметров в GSC, поэтому допускается выбор любого значения.
- В блоке «Какие URL содержащие этот параметр, должен сканировать робот Googlebot?» выбор должен делаться исходя из того, что за параметр вводится. Если это метки для отслеживания, рекомендуется выбирать «Никакие URL». Если это какие-то GET параметры для продвигаемых страниц, выбирать стоит «Каждый URL».

Если робот Google уже нашел какие-либо параметры на сайте, то вы увидите список этих параметров в таблице и сможете посмотреть примеры таких страниц.
Рассмотрев основные директивы для работы с файлом robots.txt перейдем к составлению robots.txt для сайта.
Во-первых, мы не рекомендуем брать и в слепую использовать шаблонные robots.txt, которые можно найти в интернете, так как они просто не могут учитывать всех тонкостей работы вашего сайта.
1. Первым делом добавим в robots.txt три User-Agent с одной пустой строкой между каждой директивой
Третий User-Agent добавляется по причине того, что для роботов каждой поисковой системы наборы директив будут различаться.
2. Каждому User-agent’у рекомендуется добавить директивы запрета индексации самых распространенных форматов документов
Документы закрываются от индексации по той причине, что они могут «перетянуть» на себя релевантность и попадать в выдачу вместо продвигаемых целевых страниц.
Даже если сейчас на вашем сайте пока нет документов в вышеперечисленных форматах, рекомендуем не удалять эти строки, а оставить их на перспективу.
3. Каждому User-agent’у добавляем директиву разрешения индексации JS и CSS файлов
JS и CSS файлы открываются для индексации, так как часто они находятся в каталогах системных папок, но они требуются для правильного индексирования сайта роботами поисковых систем.
4. Каждому User-agent’у добавляем директиву разрешения индексации самых распространенных форматов изображений
Allow: /*/<папка содержащая медиа файлы>/*.jpg
Allow: /*/<папка содержащая медиа файлы>/*.jpg
Allow: /*/<папка содержащая медиа файлы>/*.jpg
Allow: /*/<папка содержащая медиа файлы>/*.jpg
Картинки открываем для исключения возможности случайного запрета их для индексации.
Так же как и с документами, если сейчас у вас на сайте нет графических изображений в каком-либо из перечисленных форматах, все равно лучше оставить эти строки.
5. Для User-agent’а Yandex добавляем директиву удаления меток отслеживания, чтобы исключить возможность появления дублей страниц в индексе поисковых систем
6. Эти же параметры закрываем в GSC в разделе «Параметры URL»
Внимание! Если закрыть от индексации роботами Google метки при помощи директивы запрета, есть вероятность того, что вы не сможете запустить на такие страницы рекламу в Google Adwords.
7. Для User-agent’а «*» закрываем метки отслеживания стандартной директивой запрета
8. Далее задача закрыть от индексации все служебные документы, документы бесполезные для поиска и дубли других страниц. Директивы запрета копируются для каждого User-agent’а. Пример таких страниц:
- Администраторская часть сайта
- Персональные разделы пользователей
- Корзины и этапы оформления
- Фильтры и сортировки в каталогах
9. Последней директивой для User-agent’а Yandex указывается главное зеркало
10. Последней директивой, после всех директив, через пустую строку указываются директивы xml-карт сайта, если таковые используются на сайте
После всех манипуляций должен получится готовый файл robots.txt, который можно использовать на сайте.
Шаблон, который можно взять за основу при составлении robots.txt
Важно! Когда копируете шаблон в текстовый файл, не забудьте убрать лишние пустые строки.
Пустые строки в robots.txt должны быть только:
- Между последней директивой одного User-agent’а и следующим User-agent’ом.
- Последней директивой последнего User-agent’а и директивой Sitemap.
Но прежде чем добавлять его на сайт, мы рекомендуем проверить его в сервисах анализа, например, для Яндекса, нет ли в нем ошибок. А заодно проверить несколько документов из каталогов, которые запрещены к индексации, и несколько документов, которые должны быть открыты для индексации, и проверить, нет ли каких-либо ошибок.
Хоть составление правильного robots.txt задача не самая сложная, но есть распространенные ошибки, которые многие допускают, и от которых мы хотим вас предупредить.
4.1. Полное закрытие сайта от индексации
Такая ошибка приводит к исключению всех страниц из индекса поисковых систем и полной потери поискового трафика.
4.2. Не закрытие от индексации меток отслеживания
Эта ошибка может привести к появлению большого количества дублей страниц, что негативно скажется на продвижении сайта
4.3. Неправильное зеркало сайта
Скорее всего в большинстве случаев Яндекс просто проигнорирует эту директиву, но если, например, у вас есть несколько судбоменов для разных регионов, то есть вероятность того, что зеркала просто «склеятся».
Здесь роботс полностью разрешает индексацию всего сайта.
Файл robots.txt необходимо загрузить в корневой каталог вашего сайта, чтобы он был доступен по адресу:
Для размещения файла в корне сайта обычно необходим доступ через FTP. Однако, некоторые системы управления (CMS) дают возможность создать robots.txt непосредственно из панели управления сайтом или через встроенный FTP-менеджер.
Если файл доступен, то вы увидите содержимое в браузере.
Для чего нужен robots.txt
Сформированный файл для сайта является важным аспектом поисковой оптимизации. Зачем нужен robots.txt? Например, в SEO robots.txt нужен для того, чтобы исключать из индексации страницы, не содержащие полезного контента и многое другое. Как, что, зачем и почему исключается уже было описано в статье про запрет индексации страниц сайта, здесь не будем на этом останавливаться. Нужен ли файл robots.txt всем сайтам? И да и нет. Если использование подразумевает исключение страниц из поиска, то для небольших сайтов с простой структурой и статичными страницами подобные исключения могут быть лишними. Однако, и для небольшого сайта могут быть полезны некоторые директивы, например директива Host или Sitemap, но об этом ниже.
Как создать robots.txt
Поскольку это текстовый файл, нужно воспользоваться любым текстовым редактором, например Блокнотом. Как только вы открыли новый текстовый документ, вы уже начали создание robots.txt, осталось только составить его содержимое, в зависимости от ваших требований, и сохранить в виде текстового файла с названием robots в формате txt. Все просто, и создание файла не должно вызвать проблем даже у новичков. О том, как составить и что писать в роботсе на примерах покажу ниже.
Cоздать robots.txt онлайн
Редактирование robots.txt
Правильная настройка robots.txt
Чтобы понять, как сделать правильный robots txt, для начала необходимо разобраться с общими правилами, синтаксисом и директивами файла robots.txt.
Правильный robots.txt начинается с директивы User-agent , которая указывает, к какому роботу обращены конкретные директивы.
Примеры User-agent в robots.txt:
Учитывайте, что подобная настройка файла robots.txt указывает роботу использовать только директивы, соответствующие user-agent с его именем.
Пример robots.txt с несколькими вхождениями User-agent:
Директива User-agent создает лишь указание конкретному роботу, а сразу после директивы User-agent должна идти команда или команды с непосредственным указанием условия для выбранного робота. В примере выше используется запрещающая директива «Disallow», которая имеет значение «/*utm_». Таким образом, закрываем все страницы с UTM-метками. Правильная настройка robots.txt запрещает наличие пустых переводов строки между директивами «User-agent», «Disallow» и директивами следующими за «Disallow» в рамках текущего «User-agent».
Пример неправильного перевода строки в robots.txt:
Пример правильного перевода строки в robots.txt:
Как видно из примера, указания в robots.txt поступают блоками, каждый из которых содержит указания либо для конкретного робота, либо для всех роботов «*».
Пример совместного использования директив в robots.txt:
Данный пример запрещает всем роботам индексацию всех страниц, начинающихся с «/blog», но разрешает индексации страниц, начинающиеся с «/blog/page».
Прошлый пример robots.txt в правильной сортировке:
Сначала запрещаем весь раздел, потом разрешаем некоторые его части.
Еще один правильный пример robots.txt с совместными директивами:
Обратите внимание на правильную последовательность директив в данном robots.txt.
Директивы «Allow» и «Disallow» можно указывать и без параметров, в этом случае значение будет трактоваться обратно параметру «/».
Пример директивы «Disallow/Allow» без параметров:
Для правильного составления robots.txt необходимо точно указывать в параметрах директив приоритеты и то, что будет запрещено для скачивания роботам. Более полно использование директив «Disallow» и «Allow» мы рассмотрим чуть ниже, а сейчас рассмотрим синтаксис robots.txt. Знание синтаксиса robots.txt приблизит вас к тому, чтобы создать идеальный robots txt своими руками.
Синтаксис robots.txt
Вот конкретные список простых правил, следуя которым, вы исключите частые ошибки robots.txt:
Поскольку разные поисковые системы могут трактовать синтаксис robots.txt по-разному, некоторые пункты можно опустить. Так например, если прописать несколько директив «User-agent» без пустого перевода строки, все директивы «User-agent» будут восприняты корректно Яндексом, так как Яндекс выделяет записи по наличию в строке «User-agent».
Как проверить robots.txt
Для того, чтобы проверить robots.txt на корректность синтаксиса и структуры файла, можно воспользоваться одной из онлайн-служб. К примеру, Яндекс и Google предлагают собственные сервисы анализа сайта для вебмастеров, которые включают анализ robots.txt:
Кроме сервисов проверки от Яндекс и Google, существует множество других онлайн валидаторов robots.txt.
Robots.txt vs Яндекс и Google
Есть субъективное мнение, что указание отдельного блока директив «User-agent: Yandex» в robots.txt Яндекс воспринимает более позитивно, чем общий блок директив с «User-agent: *». Аналогичная ситуация robots.txt и Google. Указание отдельных директив для Яндекс и Google позволяет управлять индексацией сайта через robots.txt. Возможно, им льстит персонально обращение, тем более, что для большинства сайтов содержимое блоков robots.txt Яндекса, Гугла и для других поисковиков будет одинаково. За редким исключением, все блоки «User-agent» будут иметь стандартный для robots.txt набор директив. Так же, используя разные «User-agent» можно установить запрет индексации в robots.txt для Яндекса, но, например не для Google.
Отдельно стоит отметить, что Яндекс учитывает такую важную директиву, как «Host», и правильный robots.txt для яндекса должен включать данную директиву для указания главного зеркала сайта. Подробнее директиву «Host» рассмотрим ниже.
Запретить индексацию: robots.txt Disallow
Пример как в robots.txt запретить индексацию сайта:
Данный пример закрывает от индексации весь сайт для всех роботов.
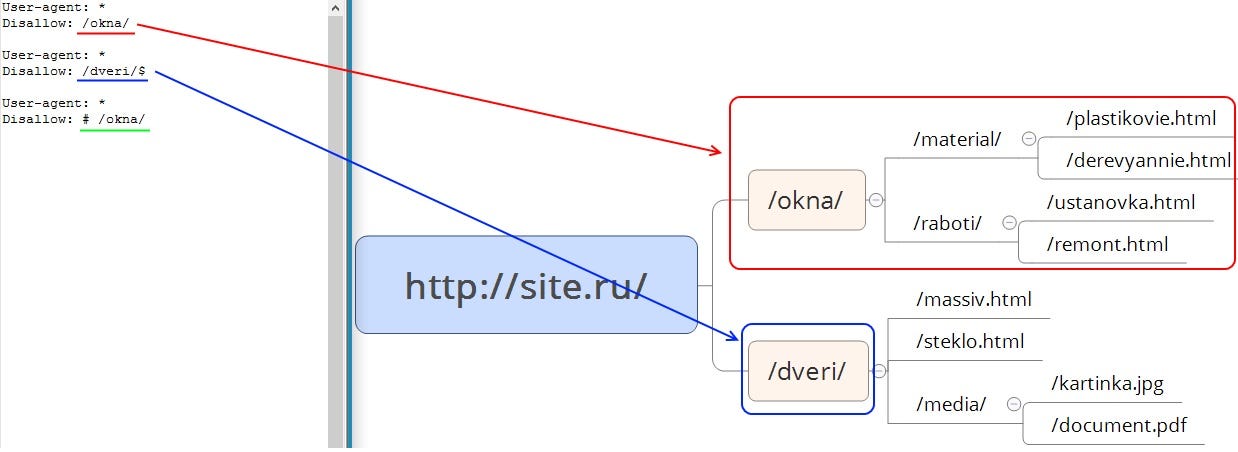
В параметре директивы Disallow допускается использование специальных символов * и $:
В данном случае, директива Disallow будет запрещать /page, но не будет запрещать индексацию страницы /page1, /page-be-cool или /page/kak-skazat.
Если закрыть индексацию сайта robots.txt, в поисковые системы могут отреагировать на так ход ошибкой «Заблокировано в файле robots.txt» или «url restricted by robots.txt» (url запрещенный файлом robots.txt). Если вам нужно запретить индексацию страницы, можно воспользоваться не только robots txt, но и аналогичными html-тегами:
Разрешить индексацию: robots.txt Allow
Пример, как в robots.txt запретить индексацию сайта кроме некоторых страниц:
Запрещается индексировать весь сайт, кроме страниц, начинающихся с /page.
Disallow и Allow с пустым значением параметра
Пустая директива Disallow:
Не запрещать ничего или разрешить индексацию всего сайта и равнозначна:
Пустая директива Allow:
Разрешить ничего или полный запрет индексации сайта, равнозначно:
Главное зеркало сайта: robots.txt Host
Директива Host служит для указания роботу Яндекса главного зеркала Вашего сайта. Из всех популярных поисковых систем, директива Host распознаётся только роботами Яндекса . Директива Host полезна в том случае, если ваш сайт доступен по нескольким доменам, например:
Или для определения приоритета между:
Пример robots.txt с указанием главного зеркала:
Директива Host в файле robots.txt может быть использована только один раз, если же директива Хост будет указана более одного раза, учитываться будет только первая, прочие директивы Host будут игнорироваться.
Если вы хотите указать главное зеркало для робота Google, воспользуйтесь сервисом Google Инструменты для вебмастеров.
Карта сайта: robots.txt sitemap
При помощи директивы Sitemap, в robots.txt можно указать расположение на сайте файла карты сайта sitemap.xml.
Пример robots.txt с указанием адреса карты сайта:
Указание адреса карты сайта через директиву Sitemap в robots.txt позволяет поисковому роботу узнать о наличии карты сайта и начать ее индексацию.
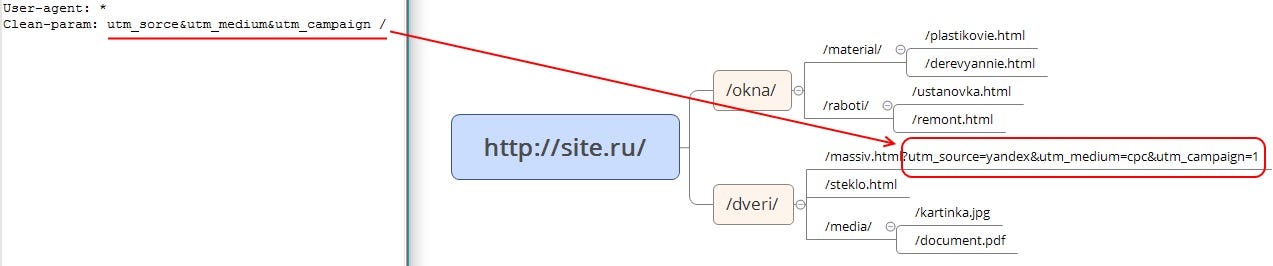
Директива Clean-param
Директива Clean-param позволяет исключить из индексации страницы с динамическими параметрами. Подобные страницы могут отдавать одинаковое содержимое, имея различные URL страницы. Проще говоря, будто страница доступна по разным адресам. Наша задача убрать все лишние динамические адреса, которых может быть миллион. Для этого исключаем все динамические параметры, используя в robots.txt директиву Clean-param.
Синтаксис директивы Clean-param:
Рассмотрим на примере страницы со следующим URL:
Пример robots.txt Clean-param:
Директива Crawl-delay
Данная инструкция позволяет снизить нагрузку на сервер, если роботы слишком часто заходят на ваш сайт. Данная директива актуальна в основном для сайтов с большим объемом страниц.
Пример robots.txt Crawl-delay:
В данном случае мы «просим» роботов яндекса скачивать страницы нашего сайта не чаще, чем один раз в три секунды. Некоторые поисковые системы поддерживают формат дробных чисел в качестве параметра директивы Crawl-delay robots.txt.
Комментарии в robots.txt
Примеры комментариев в robots.txt:
В заключении
— это текстовый файл, который содержит параметры индексирования сайта для роботов поисковых систем.
Яндекс поддерживает стандарт исключений для роботов (Robots Exclusion Protocol) с расширенными возможностями.
При очередном обходе сайта робот Яндекса загружает файл robots.txt . Если при последнем обращении к файлу, страница или раздел сайта запрещены, робот не проиндексирует их.
Требования к файлу robots.txt
Размер файла не превышает 500 КБ.
Если файл не соответствует требованиям, сайт считается открытым для индексирования.
Яндекс поддерживает редирект с файла robots.txt , расположенного на одном сайте, на файл, который расположен на другом сайте. В этом случае учитываются директивы в файле, на который происходит перенаправление. Такой редирект может быть удобен при переезде сайта.
Рекомендации по наполнению файла
Яндекс поддерживает следующие директивы:
Задает роботу минимальный период времени (в секундах) между окончанием загрузки одной страницы и началом загрузки следующей.
Рекомендуем вместо директивы использовать настройку скорости обхода в Яндекс.Вебмастере.
Задает роботу минимальный период времени (в секундах) между окончанием загрузки одной страницы и началом загрузки следующей.
Рекомендуем вместо директивы использовать настройку скорости обхода в Яндекс.Вебмастере.
Наиболее часто вам могут понадобиться директивы Disallow, Sitemap и Clean-param. Например:
Роботы других поисковых систем и сервисов могут иначе интерпретировать директивы.
Примечание. Робот учитывает регистр в написании подстрок (имя или путь до файла, имя робота) и не учитывает регистр в названиях директив.Использование кириллицы
Для указания имен доменов используйте Punycode. Адреса страниц указывайте в кодировке, соответствующей кодировке текущей структуры сайта.
Пример файла robots.txt :
Как создать robots.txt
В текстовом редакторе создайте файл с именем robots.txt и укажите в нем нужные вам директивы.Пример файла. Данный файл разрешает индексирование всего сайта для всех поисковых систем.
Вопросы и ответы
Сайт или отдельные страницы запрещены в файле robots.txt, но продолжают отображаться в поискеКак правило, после установки запрета на индексирование каким-либо способом исключение страниц из поиска происходит в течение двух недель. Вы можете ускорить этот процесс.
Думаю, никто не будет в обиде, если я перенесу эту статью сюда.
Энциклопедия интернет-маркетинга: составляем корректный robots.txt своими руками
SEOnews запустил проект для специалистов и клиентов "Энциклопедия интернет-маркетинга", в рамках которого редакция пуб…
Если попросить SEO-специалиста оценить важность правильно составленного robots.txt для сайта, хороший SEOшник оценит ее на 5 баллов из 5.
Кривой robots.txt, не учитывающий всех тонкостей сайта, может сильно навредить его индексации.
Одна неучтенн а я директива, и поисковики тут же вывалят в свой индекс всю подноготную сайта, например, как это было в 2011 году с утечкой SMS пользователей Мегафона.
Или одна лишняя или неправильно составленная директива, и часть сайта, или даже весь сайт, вылетит из индекса поисковых систем, а значит, потеряет весь поисковый трафик.
Если вы уже знакомы с основами составления robots.txt, можете сразу переходить к пункту 3 «Составление robots.txt».
- Введение
- Что такое robots.txt
- Директивы и спецсимволы robots.txt
- Настройка Google Search Consloe (GSC)
- Как составить правильный robots.txt самостоятельно
- Распространенные ошибки при составлении robots.txt
- Заключение
- Полезные ссылки
Для начала определимся что из себя представляет этот файл и зачем он нужен.
В справке Яндекса дано следующее определение:
То есть, другими словами, robots.txt — набор директив, которым однозначно подчиняются роботы поисковых систем при индексировании сайта.
Сказано «индексировать» страницу или раздел, будет индексировать. Сказано «не индексировать», не будет.
Но, несмотря на всю важность данного файла, подавляющее большинство сайтов в русском сегменте интернета не имеют правильно составленного robots.txt.
Порядок включения директив:
<Директива><двоеточие><пробел><документ, к которому применяется директива>
Для начала стоит сказать о том, какие директивы могут использоваться в файле robots.txt.
User-agent — указание робота, для которого составлен список директив ниже. Обязательная для robots.txt директива, которая указывается в начале файла.
- Основной User-agent поисковой системы Яндекс — Yandex (список роботов Яндекса, которым можно указать отдельные директивы).
- Основной User-agent поисковой системы Google — Googlebot (список роботов Google, которым можно указать отдельные директивы).
- Если список директив указывается для всех возможных User-agent’ов, ставится — «*»
Disallow — директива запрета индексации документов. Можно указывать как каталог, так и часть названия документа, так и полный путь документа.
- При запрете индексации документа путь определяется от корня сайта (красная стрелка на рисунке 1).
- Для запрета индексации документов второго и далее уровней можно указывать полный путь документа, или перед адресом документа указывается знак «*» (синяя стрелка на рисунке 1).
- При запрете индексации каталога также будут запрещены к индексации все страницы, входящие в этот каталог (зеленая стрелка на рисунке 1).
- Можно запрещать для индексации документы, в url которых содержатся определенные символы (розовая стрелка на рисунке 1).
Allow — директива разрешения индексации документов. Является директивой по умолчанию для всех документов на сайте, если не указано другое.
- Используется для открытия к индексации документов (синие стрелки), которые по той или иной причине находятся в каталогах, закрытых от индексации (красные стрелки).
- Можно открывать для индексации документы, в url которых содержатся определенные символы (синие стрелки).
- Стоит обратить внимание на правила применения директив Disallow-Allow: «Директивы Allow и Disallow из соответствующего User-agent блока сортируются по длине префикса URL (от меньшего к большему) и применяются последовательно.»
Sitemap — директива для указания пути к файлу xml-карты сайта.
- Если сайт имеет более 1 карты xml, допустимо указание нескольких путей.
Спецсимволы
Host — директива указания главного зеркала сайта. Учитывается только роботами Яндекса.
Crawl-delay — директива указания минимального времени (в секундах) между окончанием загрузки одной страницы и началом загрузки следующей. Учитывается только роботами Яндекса. Директива используется, чтоб роботы поисковых систем не перегружали сайт.
- Для ограничения времени между окончанием загрузки одной страницы и началом загрузки следующей в поисковой системе Google используется функция «Настройки сайта» в Google Search Console
Clean-param — директива используется для удаления параметров из url-адресов сайта. Учитывается только роботами Яндекса.
- Может использоваться для удаления меток отслеживания, фильтров, идентификаторов сессий и других параметров.
- Для правильной обработки меток роботами Google используется функция «Параметры URL» в Google Search Console.
Как говорилось ранее, часть функций, которые можно указать для роботов Яндекса в robots.txt, для роботов Google надо указывать в Google Search Console.
Чтобы ограничить скорость сканирования сайта роботами Google необходимо подтвердить сайт в GSC. Зайти в настройки сайта (знак шестеренки), там выбрать ссылку «Настройка сайта», в блоке «Частота сканирования» выбрать пункт «Ограничить максимальную скорость сканирования Google» и выставить приемлемое значение, после чего сохранить изменения.
Для того чтобы задать, как Google будет обрабатывать параметры в url-адресах сайта необходимо подтвердить сайт в GSC. Зайти в раздел «Сканирование» — «Параметры URL», нажать на кнопку «Добавление параметра», заполнить соответствующие поля и сохранить изменения.
- В поле «Параметр» добавляется сам параметр. Это поле является регистрозависимым.
- В поле «Изменяет ли этот параметр содержание страницы, которое видит пользователь?», вне зависимости от реального значения параметра, рекомендуем выбирать пункт «Да, параметр изменяет, реорганизует или ограничивает содержимое страницы», так как при выборе варианта «Нет, параметр не влияет на содержимое страницы (например, отслеживает использование) есть вероятность того что, одна страница с параметром все же попадет в индекс.
- Выбор в поле «Как этот параметр влияет на содержимое страницы?» влияет только на то как этот параметр будет отображаться в списке других параметров в GSC, поэтому допускается выбор любого значения.
- В блоке «Какие URL содержащие этот параметр, должен сканировать робот Googlebot?» выбор должен делаться исходя из того, что за параметр вводится. Если это метки для отслеживания, рекомендуется выбирать «Никакие URL». Если это какие-то GET параметры для продвигаемых страниц, выбирать стоит «Каждый URL».
Если робот Google уже нашел какие-либо параметры на сайте, то вы увидите список этих параметров в таблице и сможете посмотреть примеры таких страниц.
Рассмотрев основные директивы для работы с файлом robots.txt перейдем к составлению robots.txt для сайта.
Во-первых, мы не рекомендуем брать и в слепую использовать шаблонные robots.txt, которые можно найти в интернете, так как они просто не могут учитывать всех тонкостей работы вашего сайта.
1. Первым делом добавим в robots.txt три User-Agent с одной пустой строкой между каждой директивой
Третий User-Agent добавляется по причине того, что для роботов каждой поисковой системы наборы директив будут различаться.
2. Каждому User-agent’у рекомендуется добавить директивы запрета индексации самых распространенных форматов документов
Документы закрываются от индексации по той причине, что они могут «перетянуть» на себя релевантность и попадать в выдачу вместо продвигаемых целевых страниц.
Даже если сейчас на вашем сайте пока нет документов в вышеперечисленных форматах, рекомендуем не удалять эти строки, а оставить их на перспективу.
3. Каждому User-agent’у добавляем директиву разрешения индексации JS и CSS файлов
JS и CSS файлы открываются для индексации, так как часто они находятся в каталогах системных папок, но они требуются для правильного индексирования сайта роботами поисковых систем.
4. Каждому User-agent’у добавляем директиву разрешения индексации самых распространенных форматов изображений
Allow: /*/<папка содержащая медиа файлы>/*.jpg
Allow: /*/<папка содержащая медиа файлы>/*.jpg
Allow: /*/<папка содержащая медиа файлы>/*.jpg
Allow: /*/<папка содержащая медиа файлы>/*.jpg
Картинки открываем для исключения возможности случайного запрета их для индексации.
Так же как и с документами, если сейчас у вас на сайте нет графических изображений в каком-либо из перечисленных форматах, все равно лучше оставить эти строки.
5. Для User-agent’а Yandex добавляем директиву удаления меток отслеживания, чтобы исключить возможность появления дублей страниц в индексе поисковых систем
6. Эти же параметры закрываем в GSC в разделе «Параметры URL»
Внимание! Если закрыть от индексации роботами Google метки при помощи директивы запрета, есть вероятность того, что вы не сможете запустить на такие страницы рекламу в Google Adwords.
7. Для User-agent’а «*» закрываем метки отслеживания стандартной директивой запрета
8. Далее задача закрыть от индексации все служебные документы, документы бесполезные для поиска и дубли других страниц. Директивы запрета копируются для каждого User-agent’а. Пример таких страниц:
- Администраторская часть сайта
- Персональные разделы пользователей
- Корзины и этапы оформления
- Фильтры и сортировки в каталогах
9. Последней директивой для User-agent’а Yandex указывается главное зеркало
10. Последней директивой, после всех директив, через пустую строку указываются директивы xml-карт сайта, если таковые используются на сайте
После всех манипуляций должен получится готовый файл robots.txt, который можно использовать на сайте.
Шаблон, который можно взять за основу при составлении robots.txt
Важно! Когда копируете шаблон в текстовый файл, не забудьте убрать лишние пустые строки.
Пустые строки в robots.txt должны быть только:
- Между последней директивой одного User-agent’а и следующим User-agent’ом.
- Последней директивой последнего User-agent’а и директивой Sitemap.
Но прежде чем добавлять его на сайт, мы рекомендуем проверить его в сервисах анализа, например, для Яндекса, нет ли в нем ошибок. А заодно проверить несколько документов из каталогов, которые запрещены к индексации, и несколько документов, которые должны быть открыты для индексации, и проверить, нет ли каких-либо ошибок.
Хоть составление правильного robots.txt задача не самая сложная, но есть распространенные ошибки, которые многие допускают, и от которых мы хотим вас предупредить.
4.1. Полное закрытие сайта от индексации
Такая ошибка приводит к исключению всех страниц из индекса поисковых систем и полной потери поискового трафика.
4.2. Не закрытие от индексации меток отслеживания
Эта ошибка может привести к появлению большого количества дублей страниц, что негативно скажется на продвижении сайта
4.3. Неправильное зеркало сайта
Скорее всего в большинстве случаев Яндекс просто проигнорирует эту директиву, но если, например, у вас есть несколько судбоменов для разных регионов, то есть вероятность того, что зеркала просто «склеятся».
Читайте также: