
Файловая бд как выглядит
Обновлено: 04.07.2024
Предметом курса являются системы управления базами данных (СУБД). Начнем с того, что с самого начала развития вычислительной техники образовались два основных направления ее использования. Первое направление - применение вычислительной техники для выполнения численных расчетов, которые слишком долго или вообще невозможно производить вручную. Становление этого направления способствовало разработке методов численного решения сложных математических задач, развитию класса языков программирования, ориентированных на удобную запись численных алгоритмов.
Второе направление, которое непосредственно касается темы нашего курса, это использование средств вычислительной техники в автоматических или автоматизированных информационных системах. В самом широком смысле информационная система представляет собой программный комплекс, функции которого состоят в поддержке надежного хранения информации в памяти компьютера, выполнении различных преобразований информации и/или вычислений, предоставлении пользователям удобного и легко осваиваемого интерфейса. Обычно объемы информации, с которыми приходится иметь дело таким системам, достаточно велики, а сама информация имеет достаточно сложную структуру. Классическими примерами информационных систем являются банковские системы, системы резервирования авиационных или железнодорожных билетов, мест в гостиницах и т.д.
Предшественницей баз данных являются файловые системы.
Файловые системы – это набор программ, которые выполняют для пользователей некоторые операции, например, создание отчетов. Каждая программа определяет свои собственные данные и управляет ими.
Прежде всего, конечно, файлы применяются для хранения текстовых данных: документов, текстов программ и т.д. Такие файлы обычно образуются и модифицируются с помощью различных текстовых редакторов. Структура текстовых файлов обычно очень проста: это либо последовательность записей, содержащих строки текста, либо последовательность байтов, среди которых встречаются специальные символы (например, символы конца строки). Файлы с текстами программ, объектные модули. С точки зрения файловой системы, такие файлы также обладают очень простой структурой - последовательность записей или байтов. Аналогично обстоит дело с файлами, содержащими графическую и звуковую информацию.
Одним словом, файловые системы обычно обеспечивают хранение слабо структурированной информации, оставляя дальнейшую структуризацию прикладным программам.
Существует ряд недостатков, присущих файловым системам. Отметим их:
Разделение и изоляция данных . Поскольку данные хранятся в разных файлах, то собрать информацию из разных файлов достаточно сложно, приходится создавать некоторый временный файл, в который собирается вся необходимая информация, т.к. приходится организовывать синхронную обработку данных сразу в нескольких файлах.
Дублирование данных . Опять-таки, из-за того, что данные хранятся в разных файлах, то очень часто приходится повторять некоторую информацию, чтобы не потерять смысл. Например, один файл содержит информацию о людях (ФИО, дату рождения, номер паспорта и т.д.), во втором файле содержится вся информация о заработной плате и прочих начислениях. Приходится дублировать информацию по ФИО. А дублирование информации сопровождается неэкономичным расходованием ресурсов (как с точки зрения памяти компьютера, так и с точки зрения человека, который тратит больше времени на внесение информации).
Зависимость от данных. В файловых системах все данные, а также их структура жестко прописаны, поэтому любое изменение в данных или в структуре требует значительных усилий для внесения такого изменения.
Несовместимость форматов файлов. Поскольку структура файла определяется кодом приложения, она также зависит от языка программирования этого приложения. Поэтому зачастую нельзя говорить о совместной обработке файлов, написанных на разных языках.
Фиксированные запросы/быстрое увеличение количества приложений. С увеличением информации появлялось все большее количество файлов в файловой системе и с течением времени становилось тяжело уже обрабатывать такой объем. Кроме этого, чтобы получить необходимый отчет составлялись фиксированные программы, т.е. писался код программы, а потому для каждого другого отчета также приходилось разрабатывать программу, выполняющую запрос.
Все перечисленные недостатки являются следствием двух факторов:
Определение данных содержится внутри приложений, а не хранится отдельно и независимо от них.
Помимо приложений не предусмотрено никаких других инструментов доступа к данным и их обработки.
Для повышения эффективности работы используют базы данных и систему управления базами данных, или СУБД .
База данных – это совместно используемый набор логически связанных данных (и описание этих данных), предназначенный для удовлетворения информационных потребностей организации.
Другими словами, база данных – это единое, большое хранилище данных, которое однократно определяется, а затем используется одновременно многими пользователями.
СУБД – это программное обеспечение, с помощью которого пользователи могут определять, создавать и поддерживать базу данных, а также осуществлять к ней контролируемый доступ.
По-другому, СУБД – это программное обеспечение, которое взаимодействует с прикладными программами пользователя и базой данных и обладает следующими возможностями:
Позволяет определять базу данных; обычно это осуществляется с помощью языка определения данных (DDL – Data Definition Language). Язык DDL предоставляет пользователям средства указания типа данных и их структуры, а также средства задания ограничений для информации, хранимой в базе данных.
Позволяет вставлять, обновлять, удалять и извлекать информацию из базы данных, что обычно осуществляется с помощью языка управления данными (DML – Data Manipulation Language). Наличие централизованного хранилища данных и их описаний позволяет использовать язык DML как общий инструмент организации запросов, который иногда еще называют языком запросов . Этот инструмент позволяет снять такую проблему, как фиксированный набор запросов.
Отметим также, что следует различать описание базы данных и саму базу данных. Описанием базы данных является схема базы данных . Схема создается в процессе проектирования базы данных и изменяется, как правило, очень редко.
Как выше уже было сказано БД – это хранилище данных. При этом, как правило, данными могут пользоваться одновременно несколько пользователей. И к тому же, каждому пользователю могут понадобиться разные данные из одной БД. Для удовлетворения этих потребностей архитектура большинства современных баз данных представляет собой трехуровневую структуру.
Трехуровневая архитектура БД
Внешний уровень – это представление базы данных с точки зрения пользователей. Этот уровень описывает ту часть базы данных, которая относится к каждому пользователю.
Концептуальный уровень – это обобщающее представление базы данных. Этот уровень описывает то, какие данные хранятся в БД, а также связи, существующие между ними.
Иными словами, этот уровень содержит всю логическую структуру базы. На данном уровне представлены следующие компоненты:
Все сущности, их атрибуты и связи;
Накладываемые на данные ограничения;
Семантическая информация о данных;
Информация о мерах обеспечения безопасности и поддержки целостности данных.
Дадим определения некоторых терминов баз данных.
Сущность – это отдельный тип объекта (например, человек, место, вещь, событие и т.д. и т.п.), который необходимо представить в БД.
Атрибут – это свойство, которое описывает некоторую характеристику описываемого объекта.
Связь – это то, что объединяет несколько сущностей.
В данном примере отображено 3 сущности: «Сотрудник», «Отдел», «Должность» и две связи: «Работает в» и «Занимает».
Внутренний уровень – это физическое представление базы данных в компьютере. Этот уровень описывает, как информация хранится в базе данных.
На этом уровне хранится следующая информация:
Распределение дискового пространства для хранения данных и индексов;
Описание подробностей сохранения записей;
Сведения о размещении записей;
Сведения о сжатии данных и выбранных методах их шифрования.
Основным назначением трехуровневой архитектуры является обеспечение независимости от данных , которая означает, что изменения на нижних уровнях никак не влияют на верхние уровни (например, добавление или удаление новых записей никак не влияет на схему БД).
Как уже упоминалось, БД имеет еще схему БД, а потому все эти уровни характерны и для схем БД. Т.е., различают внешнюю схему, концептуальную схему и внутреннюю схему БД.
Иерархические, сетевые и реляционные базы данных.
По моделям представления данных базы данных делят на:
Иерархические БД – это самая первая модель представления данных, в которой все записи базы данных представлены в виде дерева, с отношениями предок-потомок. Такая модель представления данных связана с тем, что на ранних этапах базы данных часто использовались для планирования производственных процессов: каждое выпускаемое изделие состоит из узлов, каждый узел из деталей и т.д. Для того чтобы узнать, сколько и каких деталей необходимо заказать и строили дерево.
Однако, стоит отметить, что иерархическая БД не является оптимальной. Допустим, что один и тот же тип болтов в автомобиле используется 300 раз в различных узлах. При использовании иерархической модели этот тип болтов будет использоваться не один раз, а 300 (на примере рисунка можно провести аналогию для дверей, где для каждой двери нарисовать свои «окно», «замок», «ручка»). Налицо дублирование информации. Чтобы устранить этот недостаток была введена сетевая модель представления данных.
Сетевая база данных – это база данных, в которых одна запись может участвовать в нескольких отношениях предок-потомок. Т.е. фактически база данных представляет собой не дерево, а граф.
Торговая точка 1
иерархическая, и сетевая модель достаточно просты, однако они имеют общий недостаток: для того, чтобы получить ответ даже на самый простой вопрос, программисту необходимо было писать программу, которая бы просматривала базу данных, двигаясь по указателям от записи к записи. И очень часто, пока такая программа писалась, необходимость в получении информации уже отпадала. Поэтому была разработана новая модель данных, а именно: реляционные базы данных.
В реляционной базе данных вся информация представляется в виде таблиц и любые операции над данными – это операции над таблицами. Таблицы состоят из строк и столбцов. Строки – это записи, а столбцы представляют структуру записи (каждый столбец имеет тип данных, длину данных). Строки в столбце не упорядочены, т.е. не существует первой или десятой строки. Однако, поскольку на строки надо как-то ссылаться, то вводится понятие «первичный ключ». Первичный ключ – это столбец, значения которого во всех строках разные. Используя первичный ключ можно однозначно сослаться на какую либо строку таблицы. Отношения предок-потомок в реляционной БД организуется за счет внешних ключей. Внешний ключ – это столбец таблицы, значения которого совпадают со значениями первичного ключа некоторой другой таблицы.
Каждая база данных SQL Server имеет как минимум два рабочих системных файла: файл данных и файл журнала. Файлы данных содержат данные и объекты, такие как таблицы, индексы, хранимые процедуры и представления. Файлы журнала содержат сведения, необходимые для восстановления всех транзакций в базе данных. Файлы данных могут быть объединены в файловые группы для удобства распределения и администрирования.
Файлы базы данных
SQL Server имеют три типа файлов.
| Файл | Описание |
|---|---|
| Первичная | Содержит сведения, необходимые для запуска базы данных, и ссылки на другие файлы в базе данных. В каждой базе данных имеется один первичный файл данных. Для имени первичного файла данных рекомендуется расширение MDF. |
| Вторичная | Необязательные определяемые пользователем файлы данных. Данные могут быть распределены на несколько дисков, в этом случае каждый файл записывается на отдельный диск. Для имени вторичного файла данных рекомендуется расширение NDF. |
| Журнал транзакций | Журнал содержит информацию для восстановления базы данных. Для каждой базы данных должен существовать хотя бы один файл журнала. Для файлов журнала транзакций рекомендуется расширение LDF. |
Например, простая база данных с именем Sales включает один первичный файл, содержащий все данные и объекты, и один файл журнала, содержащий сведения журнала транзакций. Более сложная база данных с именем Orders может содержать один первичный файл и пять вторичных файлов. Данные и объекты внутри базы данных распределяются по всем шести файлам, а четыре файла журнала содержат сведения журнала транзакций.
По умолчанию и данные, и журналы транзакций помещаются на один и тот же диск и имеют один и тот же путь для обработки однодисковых систем. Для производственных сред это может быть неоптимальным решением. Рекомендуется помещать данные и файлы журнала на разные диски.
Логические и физические имена файлов
Файлы SQL Server имеют два типа имен файлов.
logical_file_name: имя, используемое для ссылки на физический файл во всех инструкциях Transact-SQL. Логическое имя файла должно соответствовать правилам для идентификаторов SQL Server и быть уникальным среди логических имен файлов в соответствующей базе данных.
os_file_name: имя физического файла, включающее путь к каталогу. Оно должно соответствовать правилам для имен файлов операционной системы.
Дополнительные сведения об аргументах NAME и FILENAME см. в статье Параметры ALTER DATABASE ((Transact-SQL)) для файлов и файловых групп.
Файлы данных и файлы журналов SQL Server могут использоваться как в файловой системе FAT, так и в системе NTFS. В системах Windows рекомендуется использовать файловую систему NTFS по причинам ее большей безопасности.
Файловые группы, доступные как для чтения, так и для записи, а также файлы журналов не поддерживаются со сжатой файловой системой NTFS. В сжатую файловую систему NTFS разрешено помещать лишь доступные только для чтения базы данных и доступные только для чтения вторичные файловые группы. Для экономии места настоятельно рекомендуется использовать сжатие данных вместо сжатия файловой системы.
Если на одном компьютере запущено несколько экземпляров SQL Server, каждый экземпляр получает отдельный каталог по умолчанию для хранения файлов баз данных, созданных в этом экземпляре. Дополнительные сведения см. в разделе Расположение файлов для экземпляра по умолчанию и именованных экземпляров SQL Server.
Размер файла
Файлы SQL Server могут автоматически увеличиваться в размерах, превосходя первоначально заданные показатели. При определении файла пользователь может указывать требуемый шаг роста. Каждый раз при заполнении файла его размер увеличивается на указанный шаг роста. Если в файловой группе имеется несколько файлов, их автоматический рост начинается лишь по заполнении всех файлов.
Дополнительные сведения о страницах и их типах см. в разделе Руководство по архитектуре страниц и экстентов.
Кроме того, можно указать максимальный размер каждого файла. Если максимальный размер файла не указан, файл может продолжать увеличиваться в размерах, пока не займет все доступное место на диске. Эта функция особенно полезна в случаях, когда SQL Server используется в качестве базы данных, внедренной в приложение, где пользователь не имеет удобного доступа к системному администратору. По мере необходимости пользователь может предоставить файлам возможность увеличиваться в размерах автоматически, тем самым снимая с администратора часть забот по наблюдению за свободным пространством базы данных и по распределению дополнительного пространства вручную.
Дополнительные сведения об управлении файлами журнала транзакций см. в разделе Управление размером файла журнала транзакций.
Файлы моментального снимка базы данных
Вид файла, используемый для хранения копируемых во время записи данных моментального снимка базы данных, зависит от того, создается ли моментальный снимок пользователем или используется внутренними механизмами.
- Данные моментального снимка базы данных, созданного пользователем, хранятся в одном или нескольких разреженных файлах. Технология разреженных файлов является свойством файловой системы NTFS. Изначально разреженный файл не содержит данных пользователя, и место на диске под него не выделяется. Общие сведения об использовании разреженных файлов в моментальных снимках базы данных и о том, как растут моментальные снимки базы данных, см. в разделе Просмотр размера разреженного файла моментального снимка базы данных.
- Моментальные снимки базы данных могут использоваться внутренними механизмами при выполнении определенных команд DBCC. Эти команды включают DBCC CHECKDB, DBCC CHECKTABLE, DBCC CHECKALLOC и DBCC CHECKFILEGROUP. Внутренним моментальным снимком базы данных используются разреженные дополнительные потоки данных исходных файлов базы данных. Подобно разреженным файлам, дополнительные потоки данных являются свойством файловой системы NTFS. Использование разреженных дополнительных потоков данных позволяет связать несколько расположений данных с одним файлом или папкой, не затрагивая при этом размер файла или статистику тома.
Файловые группы
- Эта файловая группа содержит первичный файл данных и все вторичные файлы, не входящие в другие файловые группы.
- Пользовательские файловые группы могут создаваться для удобства администрирования, распределения и размещения данных.
Например, Data1.ndf , Data2.ndf и Data3.ndf могут быть созданы на трех дисках соответственно и отнесены к файловой группе fgroup1 . В этом случае можно создать таблицу на основе файловой группы fgroup1 . Запросы данных из таблицы будут распределены по трем дискам, и это улучшит производительность. Подобного улучшения производительности можно достичь и с помощью одного файла, созданного на чередующемся наборе дискового массива RAID. Тем не менее файлы и файловые группы позволяют без труда добавлять новые файлы на новые диски.
Все файлы данных хранятся в файловых группах, перечисленных в следующей таблице.
| Файловая группа | Описание |
|---|---|
| Первичная | Файловая группа, содержащая первичный файл. Все системные таблицы являются частью первичной файловой группы. |
| Данные, оптимизированные для памяти | В основе оптимизированной для памяти файловой группы лежит файловая группа файлового потока. |
| Файловый поток | |
| Определяемые пользователем маршруты | Любая файловая группа, созданная пользователем при создании или изменении базы данных. |
Файловая группа по умолчанию (первичная)
Если в базе данных создаются объекты без указания файловой группы, к которой они относятся, они назначаются файловой группе по умолчанию. В любом случае только одна файловая группа создается как файловая группа по умолчанию. Файлы в файловой группе по умолчанию должны быть достаточно большими, чтобы вмещать новые объекты, не назначенные другим файловым группам.
Файловая группа PRIMARY является группой по умолчанию, если только она не была изменена инструкцией ALTER DATABASE. Системные объекты и таблицы распределяются внутри первичной файловой группы, а не новой файловой группой по умолчанию.
Файловая группа данных, оптимизированных для памяти
Дополнительные сведения об оптимизированных для памяти файловых группах см. в разделе Оптимизированные для памяти файловые группы.
Файловая группа файлового потока
Дополнительные сведения о файловых группах файлового потока см. в статьях FILESTREAM и Создание базы данных с поддержкой FILESTREAM.
Пример файлов и файловых групп
В следующем примере создается база данных на основе экземпляра SQL Server. База данных содержит первичный файл данных, пользовательскую файловую группу и файл журнала. Первичный файл данных входит в состав первичной файловой группы, а пользовательская файловая группа состоит из двух вторичных файлов данных. Инструкция ALTER DATABASE придает пользовательской файловой группе статус файловой группы по умолчанию. Затем создается таблица, определяющая пользовательскую файловую группу. (В этом примере используется универсальный путь к c:\Program Files\Microsoft SQL Server\MSSQL.1 , чтобы не указывать версию SQL Server.)
Данная иллюстрация обобщает все вышесказанное (кроме данных файлового потока).
Стратегия заполнения файлов и файловых групп
В файловых группах для каждого файла используется стратегия пропорционального заполнения. При записи данных в файловую группу компонент Компонент SQL Server Database Engine записывает в каждый файл количество данных, пропорциональное свободному пространству этого файла, вместо записи всех данных в первый файл до его заполнения. Затем запись производится в следующий файл. Например, если в файле f1 свободно 100 МБ, а в файле f2 — 200 МБ, то в файл f1 записывается одна часть данных, а в файл f2 — две части, и так далее. Таким образом, оба файла будут заполнены примерно в одно и то же время, и достигается простейшее распределение данных между хранилищами.
Например, файловая группа состоит из трех файлов, для всех разрешено автоматическое увеличение. Когда свободное пространство во всех файлах группы закончится, будет расширен только первый файл. Когда заполнится первый файл и в файловую группу снова нельзя будет записывать новые данные, будет расширен второй файл. Когда заполнится второй файл и в файловую группу опять нельзя будет записывать новые данные, будет расширен третий файл. Когда заполнится третий файл и в файловую группу нельзя будет записывать новые данные, будет снова расширен первый файл и т. д.
Правила проектирования файлов и файловых групп
Для файлов и файловых групп действуют следующие правила:
- файл или файловая группа не могут использоваться несколькими базами данных. Например, файлы sales.mdf и sales.ndf, содержащие данные и объекты базы данных sales, не могут использоваться никакой другой базой данных.
- файл может быть элементом только одной файловой группы;
- файлы журнала транзакций не могут входить ни в какие файловые группы.
Рекомендации
Рекомендации при работе с файлами и файловыми группами:
- Для большинства баз данных достаточно использовать один файл данных и один файл журнала транзакций.
- При использовании множества файлов данных создайте вторую файловую группу с дополнительным файлом и сделайте ее файловой группой по умолчанию. Тогда в первичном файле будут храниться только системные таблицы и объекты.
- Чтобы увеличить производительность, по возможности разнесите файлы и файловые группы по нескольким доступным дискам. Объекты, активно конкурирующие за свободное пространство, поместите в разные файловые группы.
- Используйте файловые группы для целенаправленного размещения объектов на конкретных физических дисках.
- Помещайте разные таблицы, использующиеся в одних и тех же запросах с соединениями, в разные файловые группы. Этот этап увеличит производительность, так как для поиска соединяемых данных можно будет использовать параллельный ввод-вывод.
- Часто используемые таблицы и некластеризованные индексы, относящиеся к ним, помещайте в разные файловые группы. Использование разных групп файлов увеличит производительность, так как можно будет использовать параллельный ввод и вывод, если файлы находятся на разных жестких дисках.
- Не помещайте файлы журнала транзакций на тот же физический диск, где находятся другие файлы и файловые группы.
- Если необходимо расширить том или раздел, в котором находятся файлы базы данных, с помощью таких средств, как Diskpart, следует сначала выполнить резервное копирование всех системных и пользовательских баз данных и остановить службы SQL Server. Кроме того, после успешного расширения томов дисков рекомендуется выполнить команду DBCC CHECKDB , чтобы обеспечить физическую целостность всех баз данных в томе.
Дополнительные рекомендации по управлению файлами журнала транзакций см. в разделе Управление размером файла журнала транзакций.
Доброго всем времени суток Я долго думал как Вам представить класс по работе с базой данных на файлах. Проблема в том, что он сам по себе не маленький, да и логика там не особо простая. Поэтому поразмышляв я решил сделать некую документацию по уже готовому коду, а не имитировать написание этого самого кода.
Начну пожалуй с того какова вообще идея этого класса. Я не стал изобретать велосипед, и решил, что база данных будет работать с некими файлами, которые в скуль базах называют таблицами. Т.е. мы будем работать с термином «таблица» он будет обозначать некий файл, в нашей файловой системе, с расширением .tbl
Данные которые записаны в эти файлы лежат в формате json. Кто не знает что это за формат, просто погуглите, в нем нет ничего экстраординарного, именно поэтому останавливаться на этом я не буду.
В общем идея класса проста, он
- создает таблицы
- создает структуру (поля) этих таблиц
- редактирует структуру
- наполняет эти таблицы данными
- удаляет эти данные
- редактирует эти данные
По сути в таблице хранится массив с данными в формате json и класс помогает с этими данными как — то взаимодействовать.
Теперь попробую описать свойства и методы которые есть в классе
Класс базы данных на файлах
Свойства
Методы
- field — поле по которому производить фильтрацию
- condition — знак фильтра. (= <> != > < >= <= IN LIKE)
- value — значение фильтра
- field — наименование поля
- value — значение поля. (необходимо для метода update())
- field — поле по которому необходимо сортировать
- direction — направление ASC или DESC
Как видите в классе очень много всего, поэтому такой формат подачи информации куда полезнее чем имитировать написание этого самого класса. Давайте я Вам дам пару примеров (в конце статьи можете скачать архив с примером).
Примеры
createTable()
Начнем с того что создадим таблицу тест (в архиве с примером это файл create.php)
оно говорит нам что все прошло успешно. В папке database должен появиться файл test.tbl с дефолтным содержанием
insert()
Теперь давайте вставим одну строчку в нашу базу данных (в архиве с примером это файл insert.php)
как видите метод insert() вернул нам id новой строчки в наше базе
select()
Теперь давайте напишем простую выборку из таблицы test (в архиве с примером это файл select.php)
после запуска мы должны увидеть вот такой массив
как видите в нашей таблице сейчас есть одна строчка которую мы вставили чуть выше.
update()
Теперь давайте обновим нашу строчку (в архиве с примером это файл update.php)
после запуска данного кода мы должны увидеть вот такую картину
Этот вывод говорит на о том что обновление прошло успешно. Теперь если запустить вот этот код (в архиве с примером это файл select.php)
мы увидим вот такой массив
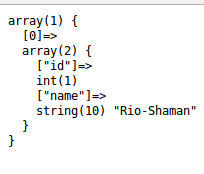
delete()
Теперь давайте удалим вставленную строчку (в архиве с примером это файл delete.php)
после запуска видим вот такую картину
Теперь давайте запустим вот этот код (в архиве с примером это файл select.php)
оно говорит нам о том, что в выборке сейчас ничего нет. Там и нет ничего, мы ведь только что удалили из таблице единственную строчку
addField()
Теперь давайте изменим структуру таблицы, но для начала вставим что — нибудь в базу данных (в архиве с примером это файл addfield.php) исполняем вот этот код
теперь давайте воспользуемся методом addField()
вот что он нам выдаст
Как вы поняли все прошло удачно. Давайте произведем выборку (в архиве с примером это файл select.php)
видим вот такую картину
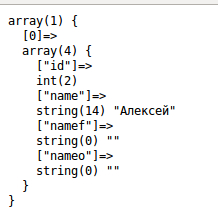
как видите в структуре появились два новых поля nameo и namef
deleteField()
Теперь давайте удалим эти два поля (в архиве с примером это файл deletefield.php)
если сейчас сделать выборку (в архиве с примером это файл select.php)
то увидим вот такую картинку
renameField()
Теперь пришло время попробовать переименовать поле. Исполняем вот этот код (в архиве с примером это файл renamefield.php)
теперь сделаем выборку (в архиве с примером это файл select.php)
увидим вот такой массив
как видно, поле теперь именуется не name а fullname
более сложный select()
Теперь давайте немного усложним нашу выборку. Но для начала добавим в табличку еще несколько имен а именно Сашу, Катю и Юлю (в архиве с примером это файл select2.php)
Теперь сама выборка. Предположим что нам нужно вытащить строчки id которых равны 2 — ум 3 — ем и 4 — ем. Так же необходимо отсортировать имена по алфавиту. Вот как выглядит код выборки (в архиве с примером это файл select2.php)
Вот что мы получаем в итоге на экране
Заключение
Ну собственно на этом все. Этот класс мы будем использовать в нашем мини движке, на котором в последствие мы соберем небольшой интернет — магазин
Есть еще один момент. Данный класс тестировался на php версии 5.3 с разрешенными short_open_tag. Так что перед тестом проверьте удовлетворяет ли Ваш сервер этим требованиям
Так же могут возникнуть некторые проблемы под виндой (хотя не факт). Дело в том, что сейчас под рукой нет винды (я перешел на линукс) и потестить на ней я немогу.
Если у Вас возникнут какие — то ошибки, то пишите их в комментарии, попробуем что — нибудь придумать
Опытный ли вы инженер-программист или студент, пишущий университетский проект, в какой-то момент вам нужно будет выбрать базу данных для ваших целей.
Еще одна причина разобраться с базами данных и их свойствами: вопросы о БД очень распространены на собеседованиях. Когда вам будет нужна короткая шпаргалка, прокрутите в конец поста.

Эти базы состоят из связанных между собой таблиц. Каждая строка таблицы представляет собой запись. Почему такие базы называются реляционными? Потому, что они строятся на отношениях между объектами, описанными в БД.
Допустим, у вас есть таблица с информацией о студентах и таблица оценок курса (курс, оценка, идентификатор студента). Каждая строка с оценкой соотносится с записью о студенте. На диаграмме ниже значение в столбце Student ID указывает на строки в таблице Students по их значению в столбце ID .
Все данные из реляционных баз данных запрашиваются с помощью SQL-подобных языков, имеющих встроенную поддержку операции объединения. Реляционные базы позволяют индексировать столбцы для быстрых запросов. Из-за своей структурированной природы, схема реляционных баз данных определяется до ввода данных. Примеры таких баз:
- MySQL.
- PostgreSQL.
- Oracle.
- MS SQL Server.

В реляционных базах данных все структурировано по колонкам и столбцам. В свою очередь, в нереляционных базах нет общей структурированной схемы для записей. Большая часть NoSQL баз содержит JSON записи. Разные записи могут содержать разные поля.
Это семейство БД называется NoSQL (Not only SQL — не только SQL), так как многие NoSQL базы данных поддерживают SQL, но это не самый лучший вариант их использования. Cуществует 4 типа баз данных NoSQL.
Документные
Атомарной (неделимой) единицей таких БД является документ. Каждый документ — JSON, схема может различаться в разных документах и содержать разные поля. Документные БД позволяют индексировать некоторые поля документа для ускорения запросов на основе этих полей. Следовательно, во всех документах есть поля.
Использование
Поскольку различные записи независимы друг от друга (логически и структурно), эти базы данных поддерживают параллельные вычисления, что позволяет легко анализировать большой объём данных. Примеры:

Колоночные
Атомарная единица таких БД — колонка таблицы. Данные сохраняются столбец за столбцом, что делает колоночные запросы очень эффективными, и, поскольку данные в каждой колонке однородны, это позволяет лучше сжимать данные.
Использование
В тех случаях, когда удобно делать запросы к подмножеству столбцов (оно не обязательно должно быть одинаковым каждый раз!). Колоночные БД обрабатывают такие запросы очень быстро, так как читают только конкретные колонки (в то время как строчные БД должны читать строки полностью).
В науке о данных часто бывает, что каждая колонка представляет определенную характеристику. Как специалист по данным я часто тренирую свои модели на подмножествах характеристик и проверяю отношения между ними и оценками (корреляция, дисперсия, значимость). То же подходит и для логов— в них зачастую множество полей, но при каждом запросе используются только некоторые. Например:

Ключ-значение
В этих БД запросы только на основе ключа — вы запрашиваете ключ и получаете его значение.
Такие БД не поддерживают запросы между различными значениями записей, вроде такого: выбрать все записи, где город — Нью-Йорк.
Полезное свойство этих БД — поле времени жизни (Time-to-Live, TTL), в котором можно задать отдельно для каждой записи и состояния, когда их нужно удалить из БД.
Достоинства
Это очень быстрые БД. Во-первых, потому что используют уникальные ключи, во-вторых, потому что большинство БД типа ключ-значение хранят данные в оперативной памяти, что обеспечивает быстрый доступ к данным.
Недостатки
Необходимо определять уникальные ключи, хорошие идентификаторы, основанные на заранее известных вам данных. Зачастую они дороже, чем другие типы баз данных, так как используют оперативную память.
Использование
В основном используются для кэширования, потому что быстрые и не требуют сложных запросов. Поле времени жизни для кэширования также очень полезно. Такие БД могут использоваться для любых данных, которые требуют быстрых запросов и соответствуют формату ключ-значение. Примеры таких баз:

Графовые
Содержат узлы, отображающие объекты, а также ребра, отображающие отношения между ними.
Использование
Созданы для работы с графовыми данными, такими как сети знаний или социальные сети. Примеры баз:

Как вы уже догадались, универсального решения нет. Самые распространенные БД для регулярного использования — реляционные и документные. Давайте сравним их.
Читайте также: