
Instance oracle что это
Обновлено: 05.07.2024
Oracle Database — это объектно-реляционная СУБД (система управления базами данных), созданная компанией Oracle. В настоящее время она имеет множество разных версий и типов. Однако в этой статье мы поговорим не о видах баз данных Oracle, а о структуре и основных концепциях, которые относятся к СУБД Oracle Database. Поняв архитектуру СУБД Oracle, вы заложите фундамент, необходимый для понимания прочих средств (а они весьма обширны), предоставляемых базой данных Oracle.
Базы данных Oracle: экземпляры и сущности
СУБД Oracle Database включает в себя физические и логические компоненты. Особого упоминания заслуживает понятие экземпляра. Замечено, что некоторые используют термины «база данных» и «экземпляр» в качестве синонимов. Да, это взаимосвязанные, но всё же разные вещи. База данных в терминологии Oracle — это физическое хранилище информации, а экземпляр — это программное обеспечение, которое работает на сервере и предоставляет доступ к информации, содержащейся в базе данных Oracle. Экземпляр исполняется на конкретном сервере либо компьютере, в то самое время как база данных хранится на дисках, подключённых к этому серверу:
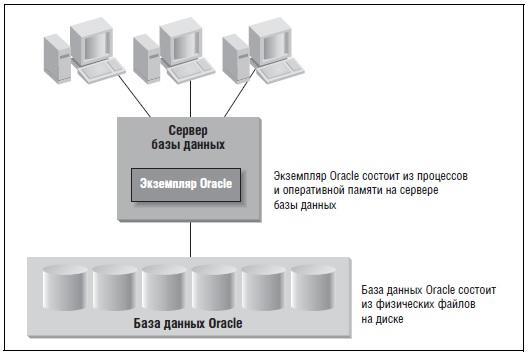
При этом база данных Oracle является физической сущностью, состоящей из файлов, которые хранятся на дисках. В то же самое время, экземпляр – это сущность логическая, состоящая из структур в оперативной памяти и процессов, которые работают на сервере. Экземпляр может являться частью только одной базы данных. При этом с одной базой данных бывает ассоциировано несколько экземпляров. Экземпляр ограничен по времени жизни, тогда как БД, условно говоря, может существовать вечно.
Также стоит заметить, что у пользователей нет прямого доступа к информации, которая хранится в базе данных Oracle — они должны запрашивать эту информацию у экземпляра Oracle.
Если упрощённо, то экземпляр — это мост к базе данных, а сама БД – это остров. Когда экземпляр запущен, мост работает, а данные способны попадать в базу данных Oracle и покидать её. Если мост перекрыт (экземпляр остановлен), пользователи не могут обращаться к базе данных, несмотря на то, что физически она никуда не исчезла.
Структура базы данных Oracle
База данных Oracle включает в себя: — табличные пространства; — управляющие файлы; — журналы; — архивные журналы; — файлы трассировки изменения блоков; — ретроспективные журналы; — файлы резервных копий (RMAN).
Табличные пространства Oracle
Любые данные, которые хранятся в базе данных Oracle, просто обязаны существовать в каком-либо табличном пространстве. Под табличным пространством (tablespace) понимают логическую структуру, то есть вы не сможете попросить ОС показать вам табличное пространство Oracle.
При этом каждое табличное пространство включает в себя физические структуры, называемые файлами данных (data files). Одно табличное пространство Oracle способно содержать один либо несколько файлов данных, в то время как каждый файл данных может принадлежать лишь одному tablespace. Создавая таблицу, мы можем указать, в какое именно табличное пространство мы её поместим — Oracle находит для неё место в каком-нибудь из файлов данных, которые составляют указанное табличное пространство.
На рисунке ниже вы можете посмотреть на соотношение между файлами данных и табличными пространствами в базе данных Oracle.
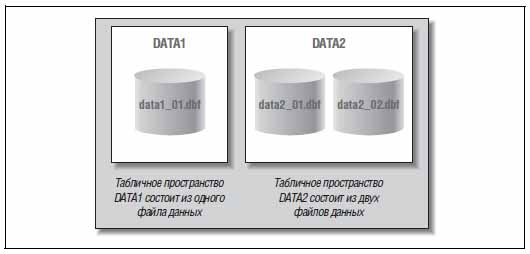
Создавая новую таблицу, мы можем поместить её в табличное пространство DATA1 либо DATA2. Таким образом, физически наша таблица окажется в одном из файлов данных, которые составляют указанное табличное пространство.
Файлы базы данных Oracle
База данных Oracle может включать в себя физические файлы 3-х основных типов: • control files — управляющие файлы; • data files — файлы данных; • redo log files — журнальные файлы либо журналы.
Посмотрим на отношения между ними:
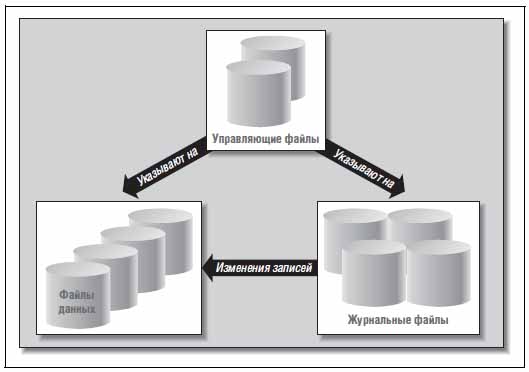
В управляющих файлах содержится информация о местонахождении других физических файлов, которые составляют базу данных Oracle, — речь идёт о файлах данных и журналов. Также там хранится важная информация о содержимом и состоянии БД Oracle. Что это за информация: • имя базы данных Oracle; • время создания БД; • имена и местонахождение журнальных файлов и файлов данных; • информация о табличных пространствах; • информация об архивных журналах; • история журналов, порядковый номер текущего журнала; • информация о файлах данных в автономном режиме; • информация о резервных копиях, контрольных точках, копиях файлов данных.
При этом функция управляющих файлов не ограничивается хранением важной информации, нужной при запуске экземпляра, — полезны они и в процессе удалении БД Oracle. К примеру, уже с версии Oracle Database 10g можно посредством команды DROP DATABASE удалить все файлы, которые перечислены в управляющем файле БД, включая сам управляющий файл.
Инициализация СУБД Oracle
Когда вы запускаете экземпляр Oracle, происходит считывание параметров инициализации. Параметры определяют, каким образом базе данных Oracle следует использовать физическую инфраструктуру и прочую конфигурационную информацию об экземпляре.
Как правило, инициализационные параметры хранятся в файле параметров инициализации экземпляра (обычно это INIT.ORA) либо, начиная с Oracle9i, в репозитории, называемом файлом параметров сервера (SPFILE). С выходом каждой новой версии Oracle число обязательных параметров инициализации уменьшается.
Кстати, в дистрибутиве Oracle можно найти пример файла инициализации, который пригоден для запуска базы данных. Также можно воспользоваться специальной программой Database Configuration Assistant (DCA) — она подскажет обязательные значения.
Более подробную информацию смотрите в официальной документации для СУБД Oracle Database.
Думаю пришло время, поговорить о том, как вообще устроена СУРБД Oracle. Когда речь идет о БД Oracle, то обычно имеется в виду система управления БД. Но, для профессиональных пользователей БД Oracle необходимо понимание разницы между собственно Базой Данных и экземпляром. Иногда эти два понятия вводят в заблуждение администраторов БД других фирм разработчиков. Высокий уровень сервиса гибкость и производительность, которую БД Oracle предоставляет клиентам обеспечивается сложным комплексом структур памяти и процессов операционной системы. Все эти понятия в совокупности называются "экземпляром" (instance). Любая БД Oracle имеет связанный с ней экземпляр. Тот самый, который мы с вами получили при инсталляции. Сама по себе организация экземпляра позволяет СУРБД обслуживать множество типов транзакций, инициируемых одновременно большим количеством пользователей, в то же время обеспечивая высокую производительность, целостность данных и безопасность. При работе БД Oracle одновременно присутствует множество процессов, выполняющих специфические задачи, в рамках СУРБД. Каждый процесс имеет отдельный блок памяти, в котором сохраняются локальные переменные, стек адресов и другая информация. Все эти процессы используют так называемую - "разделяемую область памяти". В ней хранятся данные общего пользования. Доступ к этой памяти, как для записи, так и для чтения, могут получить одновременно различные процессы и программы. Этот блок памяти вообще называется - "Глобальной Системной Областью" или ГСО. По-английски в документации это звучит как System Global Area - SGA. Еще можно уточнить, так как ГСО находится в разделяемом сегменте памяти, ее еще часто называют "Разделяемой Глобальной Областью" Shared Global Area. Вообще просто следует запомнить, что это за область и для чего она нужна. А, как ее назвать это уже на ваше усмотрение. :) Кстати, если провести аналогию между процессами системы и, например, организмом человека, то SGA это мозг, а процессы это скажем руки, ноги, уши и т.д. Но всеми органами (процессами) управляет единый центр мозг (SGA), так как она координирует все процессы обработки информации происходящие в системе. Вот собственно, так и взаимодействует этот сложный "организм".
- Формирование экземпляра Oracle (предустановочная стадия)
- Установка БД экземпляром (установочная стадия)
- Открытие БД (стадия открытия)
Далее по порядку. Экземпляр Oracle формируется на предустановочной стадии запуска системы. На этой стадии считывается файл параметров init.ora, запускаются фоновые процессы, и инициализируется ГСО (SGA). При этом имя экземпляра устанавливается в соответствии со значением указанным в init.ora. Следующая стадия - установочная. Значения параметров контрольного файла init.ora определяют параметры БД, устанавливаемой экземпляром. На данном этапе доступ к контрольному файлу открыт и возможна модификация данных, которые в нем хранятся. И на последней стадии собственно открывается сама База данных. Экземпляр получает исключительный доступ к файлам БД, имена которых, хранятся в контрольном файле и через него они становятся доступны пользователям БД. Фактически, если смотреть на открытие как состояние, то это скорее нормальное рабочее состояние БД. Заметим сразу, что до тех пор, пока БД не будет открыта, к ней может получить доступ только администратор БД и только через утилиту Server Manager. (В версии Oracle 9 этой утилиты нет. Её функции полностью переданы SQL*Plus. Так же, схема INTERNAL в Oracle 9 отсутствует.) Наверное, вы немного подустали уже от сухой теории, да и тот парень на галерке, по-моему, уже посапывает! Давайте разбудим его! :) Посмотрим, как можно управлять БД, используя утилиту Server Manager. Войдите в каталог ..\Oracle\ora81\Bin вашей учебной БД имеющей SID - proba. Затем создайте в этом каталоге bat файл с именем serverora.bat и таким содержимым:
Сразу оговорюсь, делайте это по возможности на самой машине, где установлен сервер Oracle и его экземпляр, а не с клиентской машины, так как может возникнуть ряд нюансов, на которых мы пока не будем акцентироваться. После создания файла запустите его на исполнение, вы должны увидеть примерно следующее:
Введите в ответ на приглашение - internal/oracle@proba или, если вы все делаете на самом сервере - internal/oracle.
Получите в ответ:
Затем введите на приглашение:
Через некоторое время увидим следующее:
Если сначала вы запустите диспетчер задач и перейдете на его закладку Performance, то будете при этом наблюдать следующую картину:
Теперь смотрите внимательно, первая строка сообщает, что экземпляр запущен! Далее пять строк дают служебную информацию и БД монтируется и открывается. Вот так ваш сервер Oracle стартует для того, чтобы начать свою работу.
Теперь хорошо видно, что объем занимаемой памяти увеличился! :) К утилите Server Manager мы еще вернемся, так как она выполняет еще ряд полезных функций, а пока еще раз все внимательно разберите. Да и в конце не забудьте дать команду exit:
И в заключении, экземпляр в котором не установлена БД, называется не занятым (idle). Он занимает память но, не выполняет никакой работы. Это как раз примерно то, о чем я говорил выше. Экземпляр остановлен, а сервис еще нет. Хотя в вашем случае сама БД уже есть, просто она остановлена. Надеюсь, теперь понятно, что такое экземпляр, а что такое сервер БД. :)

Высоконагруженные сайты, доступность «5 nines». На заднем фоне (backend) куча обрабатываемой информации в базе данных. А что, если железо забарахлит, если вылетит какая-то давно не проявлявшаяся ошибка в ОС, упадет сетевой интерфейс? Что будет с доступностью информации? Из чистого любопытства я решил рассмотреть, какие решения вышеперечисленным проблемам предлагает Oracle. Последние версии, в отличие от Oracle 9i, называются Oracle 10g (или 11g), где g – означает «grid», распределенные вычисления. В основе распределенных вычислений «как ни крути» лежат кластера, и дополнительные технологии репликации данных (DataGuard, Streams). В этой статье в общих чертах описано, как устроен кластер на базе Oracle 10g. Называется он Real Application Cluster (RAC).
Статья не претендует на полноту и всеобъемлемость, также в ней исключены настройки (дабы не увеличивать в объеме). Смысл – просто дать представление о технологии RAC.
Статью хотелось написать как можно доступнее, чтобы прочесть ее было интересно даже человеку, мало знакомому с СУБД Oracle. Поэтому рискну начать описание с аспектов наиболее часто встречаемой конфигурации БД – single-instance, когда на одном физическом сервере располагается одна база данных (RDBMS) Oracle. Это не имеет непосредственного отношения к кластеру, но основные требования и принципы работы будут одинаковы.
Введение. Single-instance.
- область хранения данных, т.е. физические файлы на диске (datastorage) (сама БД)
- экземпляр БД (получающая и обрабатывающая эти данные в оперативной памяти) (СУБД)

Во всех современных реляционных БД данные хранятся в таблицах. Таблицы, индексы и другие объекты в Oracle хранятся в логических контейнерах – табличных пространствах (tablespace). Физически же tablespace располагаются в одном или нескольких файлах на диске. Хранятся они следующим образом:
Каждый объект БД (таблицы, индексы, сегменты отката и.т.п.) хранится в отдельном сегменте – области диска, которая может занимать пространство в одном или нескольких файлах. Сегменты в свою очередь, состоят из одного или нескольких экстентов. Экстент – это непрерывный фрагмента пространства в файле. Экстенты состоят из блоков. Блок – наименьшая единица выделения пространства в Oracle, по умолчанию равная 8K. В блоках хранятся строки данных, индексов или промежуточные результаты блокировок. Именно блоками сервер Oracle обычно выполняет чтение и запись на диск. Блоки имеют адрес, так называемый DBA (Database Block Address).

При любом обращении DML (Data Manipulation Language) к базе данных, Oracle подгружает соответствующие блоки с диска в оперативную память, а именно в буферный кэш. Хотя возможно, что они уже там присутствуют, и тогда к диску обращаться не нужно. Если запрос изменял данные (update, insert, delete), то изменения блоков происходят непосредственно в буферном кэше, и они помечаются как dirty (грязные). Но блоки не сразу сбрасываются на диск. Ведь диск – самое узкое место любой базы данных, поэтому Oracle старается как можно меньше к нему обращаться. Грязные блоки будут сброшены на диск автоматически фоновым процессом DBWn при прохождении контрольной точки (checkpoint) или при переключении журнала.

- Что будет, если Oracle упадет где-то на середине длинной транзакции (если бы она вносила изменения)?
- Какие же данные прочтет первая транзакция, когда в кэше у нее «под носом» другая транзакция изменила блок?
- журнал повтора (redo log)
- сегмент отмены (undo)

Когда в базу данных поступает запрос на изменение, то Oracle применяет его в буферном кэше, параллельно внося информацию, достаточную для повторения этого действия, в буфер повторного изменения (redo log buffer), находящийся в оперативной памяти. Как только транзакция завершается, происходит ее подтверждение (commit), и сервер сбрасывает содержимое redo buffer log на диск в redo log в режиме append-write и фиксирует транзакцию. Такой подход гораздо менее затратен, чем запись на диск непосредственно измененного блока. При сбое сервера кэш и все изменения в нем потеряются, но файлы redo log останутся. При включении Oracle начнет с того, что заглянет в них и повторно выполнит изменения таблиц (транзакции), которые не были отражены в datafiles. Это называется «накатить» изменения из redo, roll-forward. Online redo log сбрасывается на диск (LGWR) при подтверждении транзакции, при прохождении checkpoint или каждые 3 секунды (default).
С undo немного посложнее. С каждой таблицей в соседнем сегменте хранится ассоциированный с ней сегмент отмены. При запросе DML вместе с блоками таблицы обязательно подгружаются данные из сегмента отката и хранятся также в буферном кэше. Когда данные в таблице изменяются в кэше, в кэше так же происходит изменение данных undo, туда вносятся «противодействия». То есть, если в таблицу был внесен insert, то в сегмент отката вносится delete, delete – insert, update – вносится предыдущее значение строки. Блоки (и соответствующие данные undo) помечаются как грязные и переходят в redo log buffer. Да-да, в redo журнал записываются не только инструкции, какие изменения стоит внести (redo), но и какие у них противодействия (undo). Так как LGWR сбрасывает redo log buffer каждые 3 секунды, то при неудачном выполнении длительной транзакции (на пару минут), когда после минуты сервер упал, в redo будут записи не завершенные commit. Oracle, как проснется, накатит их (roll-forward), и по восстановленным (из redo log) в памяти сегментам отката данных отменит (roll-back) все незафиксированные транзакции. Справедливость восстановлена.
Кратко стоит упомянуть еще одно неоспоримое преимущество undo сегмента. По второму сценарию (из схемы) когда select дойдет до чтения блока (DBA) 500, он вдруг обнаружит что этот блок в кэше уже был изменен (пометка грязный), и поэтому обратится к сегменту отката, для того чтобы получить соответствующее предыдущее состояние блока. Если такого предыдущего состояния (flashback) в кэше не присутствовало, он прочитает его с диска, и продолжит выполнение select. Таким образом, даже при длительном «select count(money) from bookkeeping» дебет с кредитом сойдется. Согласованно по чтению (CR).
Отвлеклись. Пора искать подступы к кластерной конфигурации. =)
Уровень доступа к данным. ASM.

Хранилищем (datastorage) в больших БД почти всегда выступает SAN (Storage Area Network), который предоставляет прозрачный интерфейс серверам к дисковым массивам.
Сторонние производители (Hitachi, HP, Sun, Veritas) предлагают комплексные решения по организации таких SAN на базе ряда протоколов (самым распространенным является Fibre Channel), с дополнительными функциональными возможностями: зеркалирование, распределение нагрузки, подключение дисков на лету, распределение пространства между разделами и.т.п.
Позиция корпорации Oracle в вопросе построения базы данных любого масштаба сводится к тому, что Вам нужно только соответствующее ПО от Oracle (с соответствующими лицензиями), а выбранное оборудование – по возможности (если средства останутся после покупки Oracle :). Таким образом, для построения высоконагруженной БД можно обойтись без дорогостоящих SPARC серверов и фаршированных SAN, используя сервера на бесплатном Linux и дешевые RAID-массивы.
На уровне доступа к данным и дискам Oracle предлагает свое решение – ASM (Automatic Storage Management). Это отдельно устанавливаемый на каждый узел кластера мини-экземпляр Oracle (INSTANCE_TYPE = ASM), предоставляющий сервисы работы с дисками.
Oracle старается избегать обращений к диску, т.к. это является, пожалуй, основным bottleneck любой БД. Oracle выполняет функции кэширования данных, но ведь и файловые системы так же буферизуют запись на диск. А зачем дважды буферизировать данные? Причем, если Oracle подтвердил транзакцию и получил уведомления том, что изменения в файлы внесены, желательно, чтобы они уже находились там, а не в кэше, на случай «падения» БД. Поэтому рекомендуется использовать RAW devices (диски без файловой системы), что делает ASM.
- отсутствие необходимости в отдельном ПО для управления разделами дисков
- нет необходимости в файловой системе
- Зеркалирование данных:
как правило, 2-х или 3-х ступенчатое, т.е. данные одновременно записываются на 2 или 3 диска. Для зеркалирования диску указываются не более 8 дисков-партнеров, на которые будут распределяться копии данных. - Автоматическая балансировка нагрузки на диски (обеспечение высокой доступности):
если данные tablespace разместить на 10 дисках и, в некоторый момент времени, чтение данных из определенных дисков будет «зашкаливать», ASM сам обратится к таким же экстентам, но находящимся на зеркалированных дисках. - Автоматическая ребалансировка:
При удалении диска, ASM на лету продублирует экстенты, которые он содержал, на другие оставшиеся в группе диски. При добавлении в группу диска, переместит экстенты в группе так, что на каждом диске окажется приблизительно равное число экстентов.
Таким образом, кластер теперь может хранить и читать данные с общего файлового хранилища.
Пора на уровень повыше.
Clusterware. CRS.
На данном уровне необходимо обеспечить координацию и совместную работу узлов кластера, т.е. clusterware слой: где-то между самим экземпляром базы данных и дисковым хранилищем:
CRS (Cluster-Ready Services) – набор сервисов, обеспечивающий совместную работу узлов, отказоустойчивость, высокую доступность системы, восстановление системы после сбоя. CRS выглядит как «мини-экземпляр» БД (ПО) устанавливаемый на каждый узел кластера. Устанавливать CRS – в обязательном порядке для построения Oracle RAC. Кроме того, CRS можно интегрировать с решениями clusterware от сторонних производителей, таких как HP или Sun.
Опять немного «терминологии»…
- CSSD – Cluster Synchronization Service Daemon
- CRSD – Cluster Ready Services Daemon
- EVMD – Event Monitor Daemon
Как уже стало ясно из таблички, самым главным процессом, «самым могущественным демоном», является CRSD (Cluster Ready Services Daemon). В его обязанности входит: запуск, остановка узла, генерация failure logs, реконфигурация кластера в случае падения узла, он также отвечает за восстановление после сбоев и поддержку файла профилей OCR. Если демон падает, то узел целиком перезагружается. CRS управляет ресурсами OCR: Global Service Daemon (GSD), ONS Daemon, Virtual Internet Protocol (VIP), listeners, databases, instances, and services.
- Node Membership (NM).Каждую секунду проверяет heartbeat между узлами. NM также показывает остальным узлам, что он имеет доступ к так называемому voting disk (если их несколько, то хотя бы к большинству), делая регулярно туда записи. Если узел не отвечает на heartbeat или не оставляет запись на voting disk в течение нескольких секунд (10 для Linux, 12 для Solaris), то master узел исключает его из кластера.
- Group Membership (GM). Функция отвечает за своевременное оповещение при добавлении / удалении / выпадении узла из кластера, для последующей реконфигурации кластера.
Информатором в кластере выступает EVMD (Event Manager Daemon), который оповещает узлы о событиях: о том, что узел запущен, потерял связь, восстанавливается. Он выступает связующим звеном между CRSD и CSSD. Оповещения также направляются в ONS (Oracle Notification Services), универсальный шлюз Oracle, через который оповещения можно рассылать, например, в виде SMS или e-mail.
Стартует кластер примерно по следующей схеме: CSSD читает из общего хранилища OCR, откуда считывает кластерную конфигурацию, чтобы опознать, где расположен voting disk, читает voting disk, чтобы узнать сколько узлов (поднялось) в кластере и их имена, устанавливает соединения с соседними узлами по протоколу IPC. Обмениваясь heartbeat, проверяет, все ли соседние узлы поднялись, и выясняет, кто в текущей конфигурации определился как master. Ведущим (master) узлом становится первый запустившийся узел. После старта, все запущенные узлы регистрируются у master, и впоследствии будут предоставлять ему информацию о своих ресурсах.
Уровнем выше CRS на узлах установлены экземпляры базы данных.
Друг с другом узлы общаются по private сети – Cluster Interconnect, по протоколу IPC (Interprocess Communication). К ней предъявляются требования: высокая ширина пропускной способности и малые задержки. Она может строиться на основе высокоскоростных версий Ethernet, решений сторонних поставщиков (HP, Veritas, Sun), или же набирающего популярность InfiniBand. Последний кроме высокой пропускной способности пишет и читает непосредственно из буфера приложения, без необходимости в осуществлении вызовов уровня ядра. Поверх IP Oracle рекомендует использовать UDP для Linux, и TCP для среды Windows. Также при передаче пакетов по interconnect Oracle рекомендует укладываться в рамки 6-15 ms для задержек.
Это данные которые будут обрабатываться как единое целое. Database состоит из файлов операционной системы. Физически существуют database files и redo log files. Логически database files содержат словари, таблицы пользователей и redo log файлы. Дополнительно database требует одну или более копий control file.
Что такое ORACLE Instance?
ORACLE Instance обеспечивает программные механизмы доступа и управления database. Instance может быть запущен независимо от любой database (без монтирования или открытия любой database). Один instance может открыть только одну database. В то время как одна database может быть открыта несколькими Instance.
Instance состоит из:
SGA (System Global Area), которая обеспечивает коммуникацию между процессами;
до пяти (в последних версиях больше) бэкграундовых процессов.
На работе у меня оракл, но непосредственно администрированием я не занимаюсь.
Для чего instance нужен - представление смутное, как говорят, для мало-мальского повышения надежности работы БД.
Есть ли что-то подобное в пг?
или instance как механизм нафиг не нужен?
Экземпляр — это серверные процессы + разделяемая память, которые обслуживают одну директорию с данными (PGDATA в нашем случае). По сути -- это запущенный софт, который предоставляет удалённый SQL-доступ к базе данных.
Аналог SGA — есть, фоновые процессы — есть. PGA нет, содержимое SGA таже отличается, но это естественно.
Вопрос основывался на архитектуре ORACLE, PGA = Process Global Area, одна из частей экземпляра в этой базе.
Они позволяют разорвать 22 проблему: чтобы создать базу, надо подключиться к базе.
ORACLE позволяет поднять инстанцию и сделать `CREATE DATABASE`. Также можно поднять инстанцию, примонтировать базу и двигать файлы данных, потом открыть и работать.
В памяти конкретного процесса обслуживающего текущее соединение.
если это серверный процесс, то по сути это и есть PGA тогда. Значит должен быть аналог в ini файле PGA_AGGREGATE_TARGET/LIMIT
В ORACLE PGA общий (шареный). В Postgres'е — всё храниться в рамках сессий, аналога PGA_LIMIT нет.
В ORACLE PGA общий (шареный). В Postgres'е — всё храниться в рамках сессий, аналога PGA_LIMIT нет.
о оракуле общий SGA, PGA же отдельный для процесса (в режиме выделенного сервера конечно, разделяемый не рассматриваем, там сложнее) и у него свои настройки
По поводу ответа, если у вас планы в аналоге ПГА (в памяти серверного процесса), то получается они не шарятся и каждый раз перепарсиваются (hard parse)?
Пробежал бегло, вот что:
В Постгресе нет глобального кэша разобранных запросов. Более того, если не предпринять специальных усилий, то запрос не будет сохраняться и локально в памяти процесса.
накидайте модель в подтверждение. если сможете.
Пробежал бегло, вот что:
В Постгресе нет глобального кэша разобранных запросов. Более того, если не предпринять специальных усилий, то запрос не будет сохраняться и локально в памяти процесса.
Это почему бы? Планирование конечно не бесплатное но в общем достаточно дешевое для простых запросов.
100.000 readonly простых TPS можно и без использования prepared получить на нормальной железке.
Ну и большая часть API к postgres умеет prepared запросы использовать штатно (не без своих издержек конечно).
Вообще стандартная практика работы с PG такая:
или
1)приложение не использует prepared запросы и работает через внешний connection pooler (pgbouncer)
или
2)приложение работает через API на хранимках, а они свои планы кешируют всегда (если им не мешать основательно руками в этом деле).
PS: shared pool в oracle тоже кучу своих проблем имеет. В общем на вкус и цвет все фломастеры разные.
ну смотрите, допустим приложение, 1000 юзверей, 50 соединений пул.
Приложение содержит 400 разных (до биндов естессно) sql запросов.
Количество юзеров увеличивается до 2000, пул увеличиваем до 100.
В случае когда запросы кешированы в shared pool ничего не меняется, всё наши выделенные сервера (их 100) пользуют те же 400 закешированных и распасенных запросов. База нагружается на soft parsing, что копейки.
Это случай оркла с разделяемым пулом.
В случае же если все запросы локально в серверных процесса база существенно нагружается хард парсингом плюс храним один и те же разобранные запросы в 100 разных серверный процессах.
Мне кажется преимущество 1-й модели очевидны. Да и с точки зрения логики, запрос должен принадлежать базе, а не конкретному подключению(сессии).
ммм конкретнее? ЧТо не устраивает в разделяемом пуле? Защёлки ?
т.е. именно в силу этого запрос принадлежит сессии , а не базе.
посему ему приходится иметь сессионный кеш, или же придумывать версионный кеш с видимостями (xmin xmax пихать в ключи кешевых таблиц, грубо говоря).
с последним у него туго -- судя по всему например таблицы значений иммутабных функий лежат в общем кеше, и при перезагрузке в одном из сеансов мало того, что инвалидизируется кеш, но ранее запущенные запросы, намеревавшиеся взять значение оттуда, а не вычислить -- падают с воплями. и т.п. и т.д. (в общем, тут много не додумано, но уже реализовано. с тем же уровнем изоляции ддл ф--й полная оппа).
давайте по серьёзней.
анализируется возможность перевода с oracle на pg части приложения.
Да, в оракле ДДЛ не транзакционен, но
1. ДДЛ изменений из приложения быть не должно. Только из maintance скриптов.
2.
Читайте также: