
Как проверить файл robots txt в google search console
Обновлено: 04.07.2024
Думаю, никто не будет в обиде, если я перенесу эту статью сюда.
Энциклопедия интернет-маркетинга: составляем корректный robots.txt своими руками
SEOnews запустил проект для специалистов и клиентов "Энциклопедия интернет-маркетинга", в рамках которого редакция пуб…
Если попросить SEO-специалиста оценить важность правильно составленного robots.txt для сайта, хороший SEOшник оценит ее на 5 баллов из 5.
Кривой robots.txt, не учитывающий всех тонкостей сайта, может сильно навредить его индексации.
Одна неучтенн а я директива, и поисковики тут же вывалят в свой индекс всю подноготную сайта, например, как это было в 2011 году с утечкой SMS пользователей Мегафона.
Или одна лишняя или неправильно составленная директива, и часть сайта, или даже весь сайт, вылетит из индекса поисковых систем, а значит, потеряет весь поисковый трафик.
Если вы уже знакомы с основами составления robots.txt, можете сразу переходить к пункту 3 «Составление robots.txt».
- Введение
- Что такое robots.txt
- Директивы и спецсимволы robots.txt
- Настройка Google Search Consloe (GSC)
- Как составить правильный robots.txt самостоятельно
- Распространенные ошибки при составлении robots.txt
- Заключение
- Полезные ссылки
Для начала определимся что из себя представляет этот файл и зачем он нужен.
В справке Яндекса дано следующее определение:
То есть, другими словами, robots.txt — набор директив, которым однозначно подчиняются роботы поисковых систем при индексировании сайта.
Сказано «индексировать» страницу или раздел, будет индексировать. Сказано «не индексировать», не будет.
Но, несмотря на всю важность данного файла, подавляющее большинство сайтов в русском сегменте интернета не имеют правильно составленного robots.txt.
Порядок включения директив:
<Директива><двоеточие><пробел><документ, к которому применяется директива>
Для начала стоит сказать о том, какие директивы могут использоваться в файле robots.txt.
User-agent — указание робота, для которого составлен список директив ниже. Обязательная для robots.txt директива, которая указывается в начале файла.
- Основной User-agent поисковой системы Яндекс — Yandex (список роботов Яндекса, которым можно указать отдельные директивы).
- Основной User-agent поисковой системы Google — Googlebot (список роботов Google, которым можно указать отдельные директивы).
- Если список директив указывается для всех возможных User-agent’ов, ставится — «*»
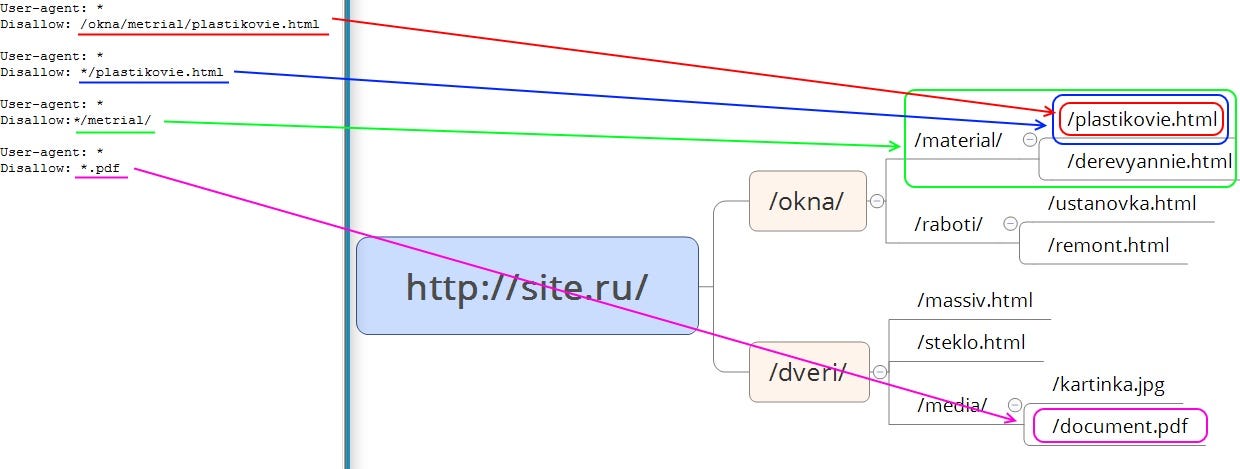
Disallow — директива запрета индексации документов. Можно указывать как каталог, так и часть названия документа, так и полный путь документа.
- При запрете индексации документа путь определяется от корня сайта (красная стрелка на рисунке 1).
- Для запрета индексации документов второго и далее уровней можно указывать полный путь документа, или перед адресом документа указывается знак «*» (синяя стрелка на рисунке 1).
- При запрете индексации каталога также будут запрещены к индексации все страницы, входящие в этот каталог (зеленая стрелка на рисунке 1).
- Можно запрещать для индексации документы, в url которых содержатся определенные символы (розовая стрелка на рисунке 1).
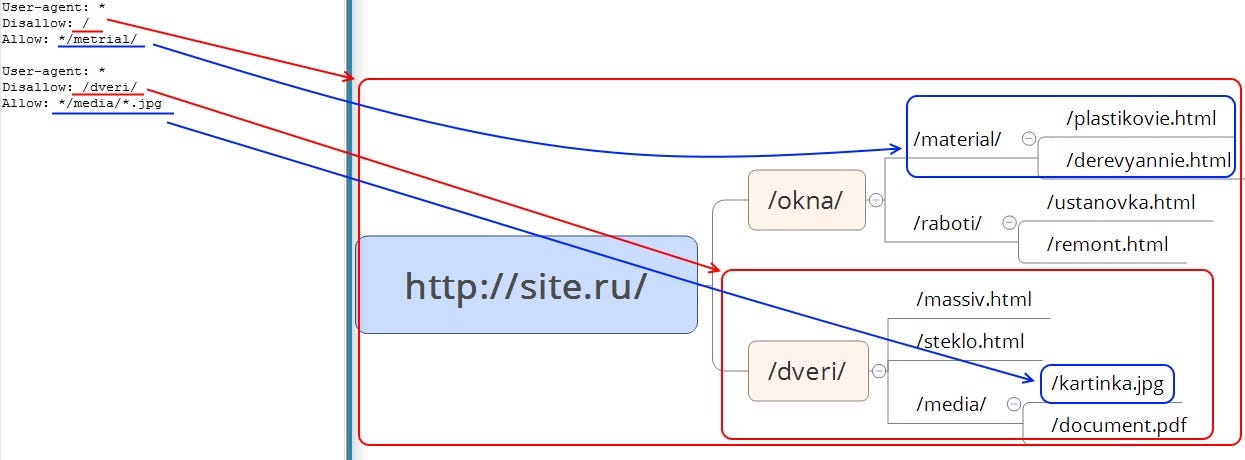
Allow — директива разрешения индексации документов. Является директивой по умолчанию для всех документов на сайте, если не указано другое.
- Используется для открытия к индексации документов (синие стрелки), которые по той или иной причине находятся в каталогах, закрытых от индексации (красные стрелки).
- Можно открывать для индексации документы, в url которых содержатся определенные символы (синие стрелки).
- Стоит обратить внимание на правила применения директив Disallow-Allow: «Директивы Allow и Disallow из соответствующего User-agent блока сортируются по длине префикса URL (от меньшего к большему) и применяются последовательно.»
Sitemap — директива для указания пути к файлу xml-карты сайта.
- Если сайт имеет более 1 карты xml, допустимо указание нескольких путей.
Спецсимволы
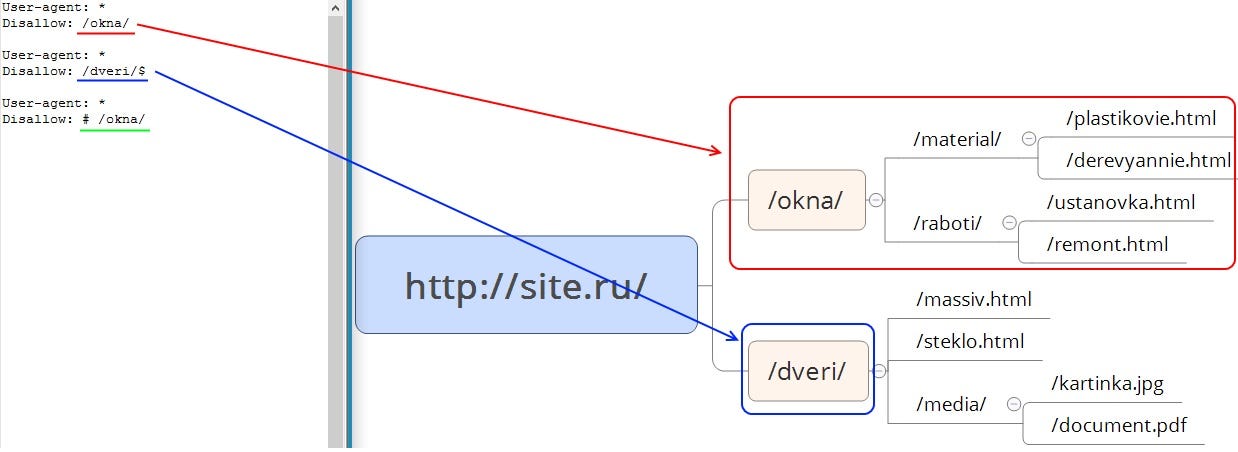
Host — директива указания главного зеркала сайта. Учитывается только роботами Яндекса.
Crawl-delay — директива указания минимального времени (в секундах) между окончанием загрузки одной страницы и началом загрузки следующей. Учитывается только роботами Яндекса. Директива используется, чтоб роботы поисковых систем не перегружали сайт.
- Для ограничения времени между окончанием загрузки одной страницы и началом загрузки следующей в поисковой системе Google используется функция «Настройки сайта» в Google Search Console
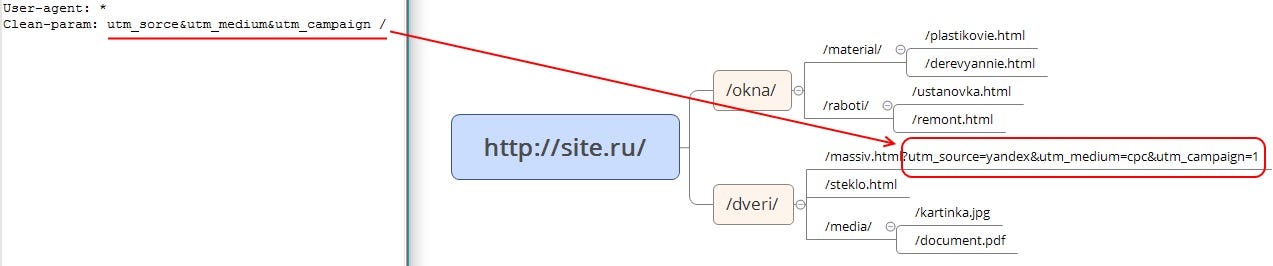
Clean-param — директива используется для удаления параметров из url-адресов сайта. Учитывается только роботами Яндекса.
- Может использоваться для удаления меток отслеживания, фильтров, идентификаторов сессий и других параметров.
- Для правильной обработки меток роботами Google используется функция «Параметры URL» в Google Search Console.
Как говорилось ранее, часть функций, которые можно указать для роботов Яндекса в robots.txt, для роботов Google надо указывать в Google Search Console.
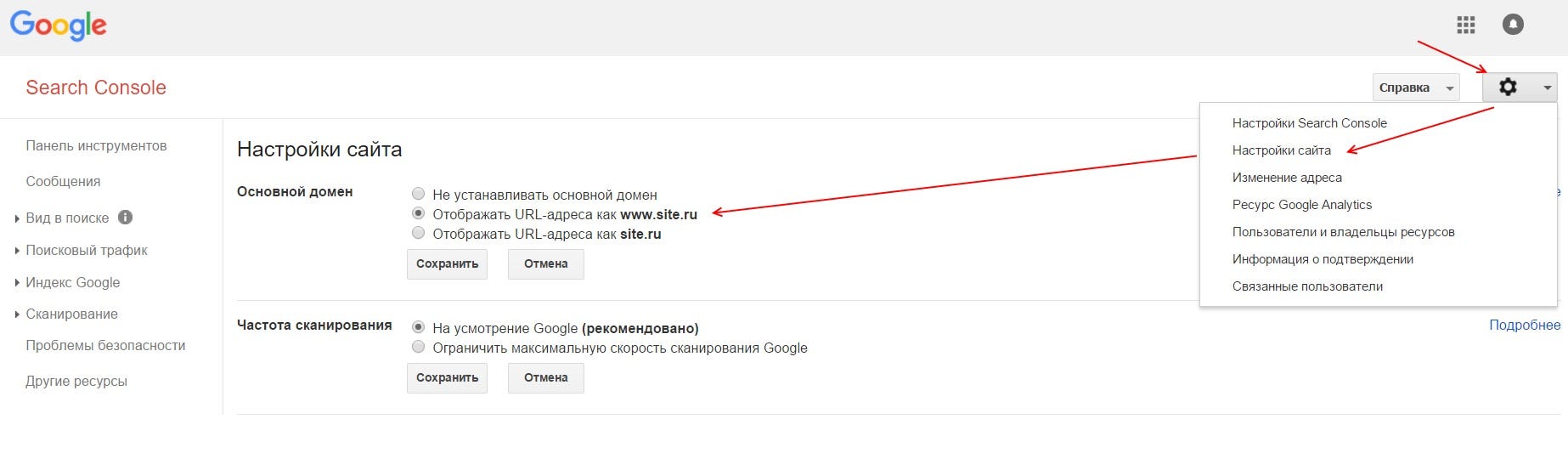
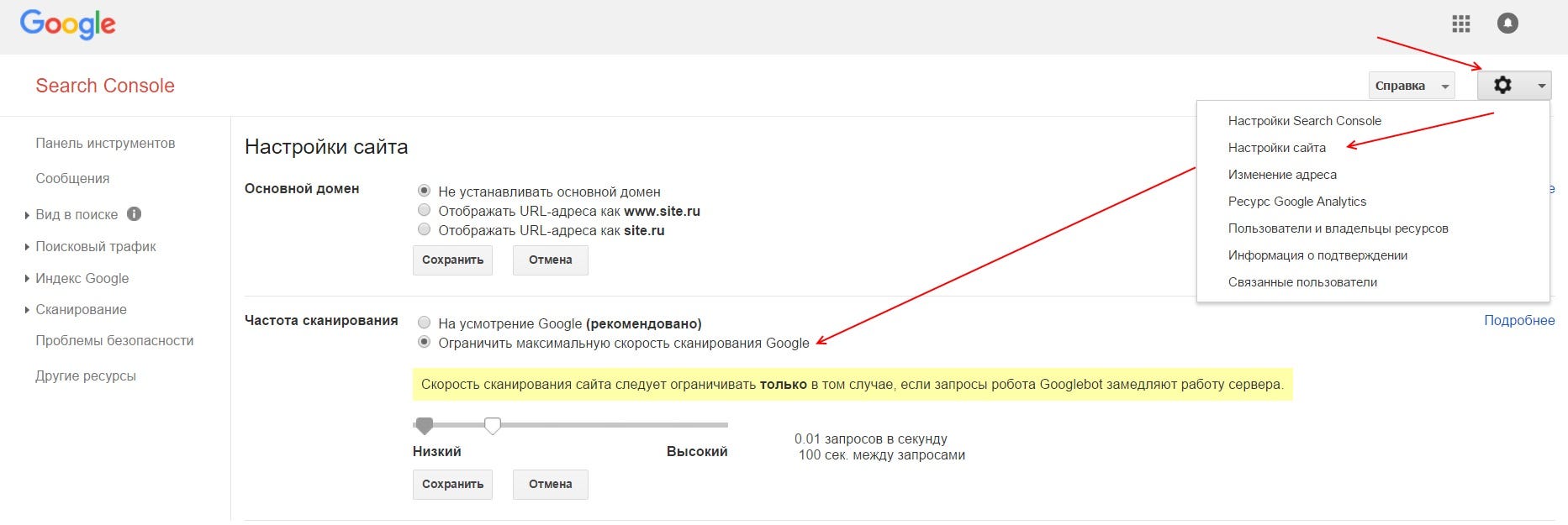
Чтобы ограничить скорость сканирования сайта роботами Google необходимо подтвердить сайт в GSC. Зайти в настройки сайта (знак шестеренки), там выбрать ссылку «Настройка сайта», в блоке «Частота сканирования» выбрать пункт «Ограничить максимальную скорость сканирования Google» и выставить приемлемое значение, после чего сохранить изменения.
Для того чтобы задать, как Google будет обрабатывать параметры в url-адресах сайта необходимо подтвердить сайт в GSC. Зайти в раздел «Сканирование» — «Параметры URL», нажать на кнопку «Добавление параметра», заполнить соответствующие поля и сохранить изменения.
- В поле «Параметр» добавляется сам параметр. Это поле является регистрозависимым.
- В поле «Изменяет ли этот параметр содержание страницы, которое видит пользователь?», вне зависимости от реального значения параметра, рекомендуем выбирать пункт «Да, параметр изменяет, реорганизует или ограничивает содержимое страницы», так как при выборе варианта «Нет, параметр не влияет на содержимое страницы (например, отслеживает использование) есть вероятность того что, одна страница с параметром все же попадет в индекс.
- Выбор в поле «Как этот параметр влияет на содержимое страницы?» влияет только на то как этот параметр будет отображаться в списке других параметров в GSC, поэтому допускается выбор любого значения.
- В блоке «Какие URL содержащие этот параметр, должен сканировать робот Googlebot?» выбор должен делаться исходя из того, что за параметр вводится. Если это метки для отслеживания, рекомендуется выбирать «Никакие URL». Если это какие-то GET параметры для продвигаемых страниц, выбирать стоит «Каждый URL».

Если робот Google уже нашел какие-либо параметры на сайте, то вы увидите список этих параметров в таблице и сможете посмотреть примеры таких страниц.
Рассмотрев основные директивы для работы с файлом robots.txt перейдем к составлению robots.txt для сайта.
Во-первых, мы не рекомендуем брать и в слепую использовать шаблонные robots.txt, которые можно найти в интернете, так как они просто не могут учитывать всех тонкостей работы вашего сайта.
1. Первым делом добавим в robots.txt три User-Agent с одной пустой строкой между каждой директивой
Третий User-Agent добавляется по причине того, что для роботов каждой поисковой системы наборы директив будут различаться.
2. Каждому User-agent’у рекомендуется добавить директивы запрета индексации самых распространенных форматов документов
Документы закрываются от индексации по той причине, что они могут «перетянуть» на себя релевантность и попадать в выдачу вместо продвигаемых целевых страниц.
Даже если сейчас на вашем сайте пока нет документов в вышеперечисленных форматах, рекомендуем не удалять эти строки, а оставить их на перспективу.
3. Каждому User-agent’у добавляем директиву разрешения индексации JS и CSS файлов
JS и CSS файлы открываются для индексации, так как часто они находятся в каталогах системных папок, но они требуются для правильного индексирования сайта роботами поисковых систем.
4. Каждому User-agent’у добавляем директиву разрешения индексации самых распространенных форматов изображений
Allow: /*/<папка содержащая медиа файлы>/*.jpg
Allow: /*/<папка содержащая медиа файлы>/*.jpg
Allow: /*/<папка содержащая медиа файлы>/*.jpg
Allow: /*/<папка содержащая медиа файлы>/*.jpg
Картинки открываем для исключения возможности случайного запрета их для индексации.
Так же как и с документами, если сейчас у вас на сайте нет графических изображений в каком-либо из перечисленных форматах, все равно лучше оставить эти строки.
5. Для User-agent’а Yandex добавляем директиву удаления меток отслеживания, чтобы исключить возможность появления дублей страниц в индексе поисковых систем
6. Эти же параметры закрываем в GSC в разделе «Параметры URL»
Внимание! Если закрыть от индексации роботами Google метки при помощи директивы запрета, есть вероятность того, что вы не сможете запустить на такие страницы рекламу в Google Adwords.
7. Для User-agent’а «*» закрываем метки отслеживания стандартной директивой запрета
8. Далее задача закрыть от индексации все служебные документы, документы бесполезные для поиска и дубли других страниц. Директивы запрета копируются для каждого User-agent’а. Пример таких страниц:
- Администраторская часть сайта
- Персональные разделы пользователей
- Корзины и этапы оформления
- Фильтры и сортировки в каталогах
9. Последней директивой для User-agent’а Yandex указывается главное зеркало
10. Последней директивой, после всех директив, через пустую строку указываются директивы xml-карт сайта, если таковые используются на сайте
После всех манипуляций должен получится готовый файл robots.txt, который можно использовать на сайте.
Шаблон, который можно взять за основу при составлении robots.txt
Важно! Когда копируете шаблон в текстовый файл, не забудьте убрать лишние пустые строки.
Пустые строки в robots.txt должны быть только:
- Между последней директивой одного User-agent’а и следующим User-agent’ом.
- Последней директивой последнего User-agent’а и директивой Sitemap.
Но прежде чем добавлять его на сайт, мы рекомендуем проверить его в сервисах анализа, например, для Яндекса, нет ли в нем ошибок. А заодно проверить несколько документов из каталогов, которые запрещены к индексации, и несколько документов, которые должны быть открыты для индексации, и проверить, нет ли каких-либо ошибок.
Хоть составление правильного robots.txt задача не самая сложная, но есть распространенные ошибки, которые многие допускают, и от которых мы хотим вас предупредить.
4.1. Полное закрытие сайта от индексации
Такая ошибка приводит к исключению всех страниц из индекса поисковых систем и полной потери поискового трафика.
4.2. Не закрытие от индексации меток отслеживания
Эта ошибка может привести к появлению большого количества дублей страниц, что негативно скажется на продвижении сайта
4.3. Неправильное зеркало сайта
Скорее всего в большинстве случаев Яндекс просто проигнорирует эту директиву, но если, например, у вас есть несколько судбоменов для разных регионов, то есть вероятность того, что зеркала просто «склеятся».
Файл robots.txt — это текстовый файл, в котором содержаться инструкции для поисковых роботов, в частности каким роботам и какие страницы допускается сканировать, а какие нет.
Как проверить работу файла robots.txt в Яндекс.Вебмастер
В Яндекс.Вебмастер в разделе «Инструменты→ Анализ robots.txt» можно увидеть используемый поисковиком свод правил и наличие ошибок в нем.

Также можно скачать другие версии файла или просто ознакомиться с ними.

Чуть ниже имеется инструмент, который дает возможно проверить сразу до 100 URL на возможность сканирования.
В нашем случае мы проверяем эти правила.

Как видим из примера все работает нормально.


Также если воспользоваться сервисом «Проверка ответа сервера» от Яндекса также будет указано, запрещен ли для сканирования документ при попытке обратиться к нему.

В Google Search Console
В случае с Google можно воспользоваться инструментом проверки Robots.txt, где потребуется в первую очередь выбрать нужный сайт.

Важно! Ресурсы-домены в этом случае выбирать нельзя.
Теперь мы видим:
- Сам файл;
- Кнопку, открывающую его;
- Симулятор для проверки сканирования.

Если в симуляторе ввести заблокированный URL, то можно увидеть правило, запрещающее сделать это и уведомление «Недоступен».
За последние годы мы несколько раз сталкивались с интересной ситуацией с robots.txt, которая может быть сложной для владельцев сайтов. После выявления проблемы и разговоров с клиентами о том, как её решить, мы обнаружили, что многие люди даже не подозревают, что такое может произойти. А поскольку речь идёт о файлах robots.txt, то это может оказывать большое влияние на SEO.
Поскольку Google обрабатывает каждый из них в отдельности, вы можете передавать совершенно разные инструкции о том, как сайт должен сканироваться.
В статье мы рассмотрим два реальных примера сайтов, которые столкнулись с данной проблемой. Мы также ознакомимся с документацией Google по robots.txt и разберёмся, как обнаружить другие файлы.
Подход Google к обработке файлов robots.txt
Документация Google чётко объясняет, как обрабатываются файлы robots.txt. Вот несколько примеров того, как будут применяться обнаруженные инструкции:

Такой подход определённо может вызвать проблемы, так как Googlebot может получить разные файлы robots.txt для одного и того же сайта и по-разному сканировать каждую его версию. И тогда возможна ситуация, когда владельцы сайтов полагают, что Googlebot выполняет один набор инструкций в то время, как он также получает ещё один набор во время других обходов сайта.
Ниже мы рассмотрим два случая, где мы столкнулись с такой проблемой.
Кейс № 1. Разные файлы robots.txt с конфликтующими директивами в www и non-www версиях
Недавно, выполняя аудит сканирования на одном из сайтов, мы заметили, что некоторые страницы, заблокированные в robots.txt, по факту сканируются и индексируются. Мы знаем, что Google на 100% соблюдает инструкции в файле robots.txt, поэтому это был явный красный флаг.
Отметим, мы имеем в виду те URL, которые сканируются и индексируются в обычном режиме, несмотря на то что инструкции в robots.txt должны запрещать сканирование. Google также может индексировать URL-адреса, заблокированные файлом robots.txt, не сканируя их, но это другая ситуация, которую мы рассмотрим ниже.
Проверяя файл robots.txt вручную, мы увидели набор инструкций для версии без www, и там было прописано ограничение. Затем мы начали вручную проверять другие версии сайта (по поддомену и протоколу), чтобы посмотреть, есть ли какие-либо проблемы там.
И они были: в поддомене с www был ещё один файл robots.txt. И, как вы можете догадаться, он содержал другие инструкции.
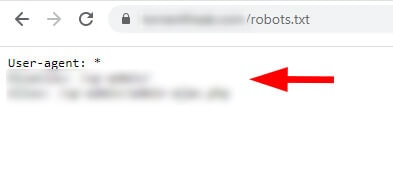
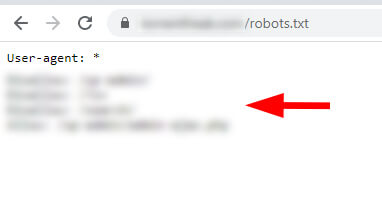
Опять же, как показывает наш опыт, многие владельцы сайтов не знают, что такие ситуации возможны.
- Краткое примечание о заблокированных страницах, которые могут быть проиндексированы
Ранее мы упоминали, что страницы, правильно заблокированные в файле robots.txt, могут быть проиндексированы. Они просто не будут сканироваться.
Google объяснял это много раз, и вы можете узнать больше о том, как он может индексировать такие URL-адреса в справочной документации по robots.txt.
Мы знаем, что это запутанная тема для многих владельцев сайтов, но Google определенно может индексировать страницы, которые заблокированы. Например, это возможно в том случае, когда Google видит входящие ссылки, указывающие на эти страницы.
Когда это происходит, Google индексирует URL-адреса и указывает в результатах поиска, что информации об этих страницах нет. Они будут отображаться без описания.
Но это не та ситуация, которую мы рассматриваем в данной статье. Вот скриншот из FAQ Google по robots.txt, где говорится про возможную индексацию заблокированных URL:

А как насчёт Search Console и файлов robots.txt?
В Search Console есть отличный инструмент, который можно использовать для отладки файлов robots.txt – Robots.txt Tester.
К сожалению, многим владельцам сайтов этот инструмент сложно найти. На него нет ссылок в новом Search Console. Но в него можно попасть из Справочного центра сервиса.
Используя этот инструмент, вы можете просматривать предыдущие файлы robots.txt, которые видел Google. Как вы можете догадаться, мы увидели оба файла robots.txt по анализируемому сайту. Поэтому, да, Google действительно видит второй файл.
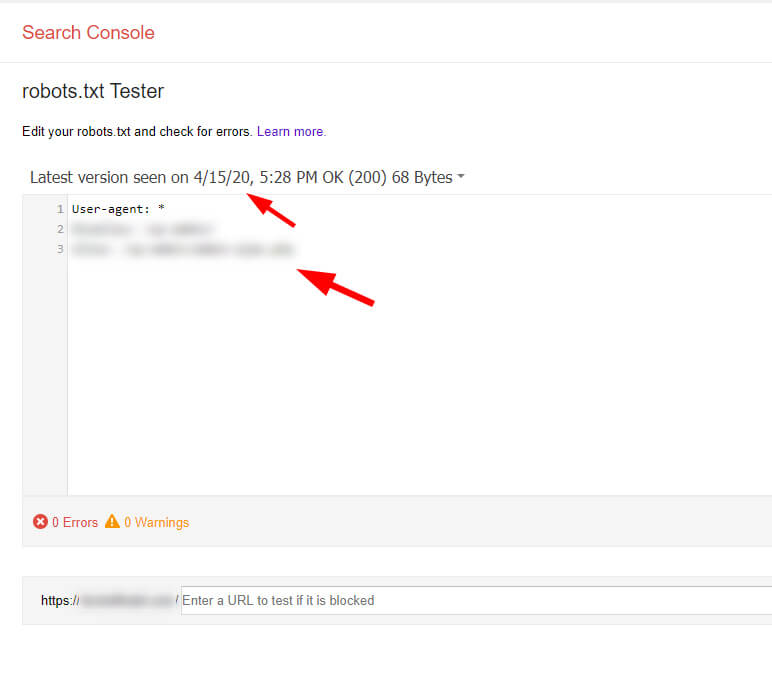

При этом на сайте остались те URL, которые были проиндексированы из-за смешанных директив. Поэтому теперь наш клиент открывает эти URL для сканирования, но следит за тем, чтобы файлы были заблокированы от индексации через метатег robots.
Когда общее количество таких URL в GSC снизится, мы снова добавим правильно реализованную директиву disallow, чтобы заблокировать эту область.
Несколько лет назад к нам обратился один вебмастер в связи с падением органического поискового трафика по сайту без видимых причин.
Покопавшись, мы решили проверить разные версии сайта по протоколу (включая файлы robots.txt для каждой версии).
Помимо этого, на сайте были и другие проблемы, но наличие нескольких файлов robots.txt, один из которых полностью запрещал сканирование, трудно назвать оптимальным.


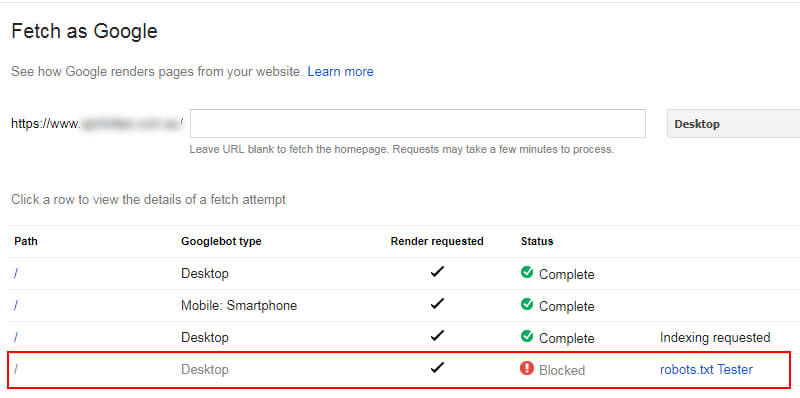
Как и в первом случае, владелец сайта быстро решил проблему (что было нелегко, учитывая их CMS).
Это ещё один хороший пример того, как Google обрабатывает файлы robots.txt, и в чём опасность наличия на сайте нескольких файлов по разным поддоменам или протоколам.
Как найти несколько файлов robots.txt: инструменты
Есть несколько инструментов, которые можно использовать, помимо ручной проверки файлов robots.txt по поддомену или протоколу.
Они также могут помочь увидеть, какие файлы robots.txt ранее отображались по сайту.
Этот инструмент, который мы уже упоминали выше, позволяет видеть текущий файл robots.txt и предыдущие версии, обработанные Google.
Он также функционирует как «песочница», где можно протестировать новые директивы.
В целом это отличный инструмент, который Google по непонятным причинам поместил в дальний угол.
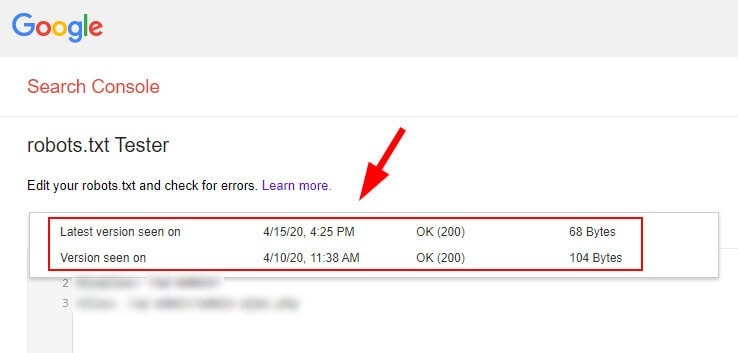
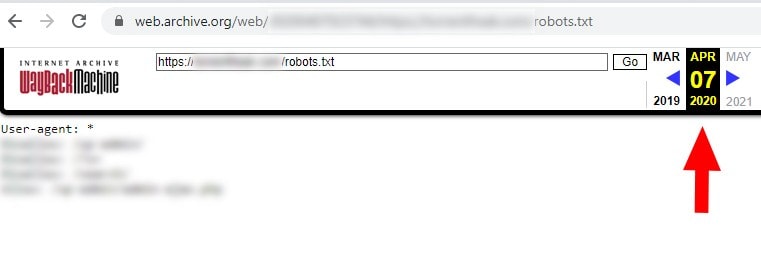
Интернет-архив также может быть полезен в этой ситуации. Мы уже рассматривали его использование в своей колонке на Search Engine Land.
Однако Wayback Machine можно использовать не только для проверки стандартных веб-страниц. Этот инструмент также позволяет просматривать те файлы robots.txt, которые были на сайте ранее.
Таким образом, это отличный способ отследить предыдущие версии файла robots.txt.

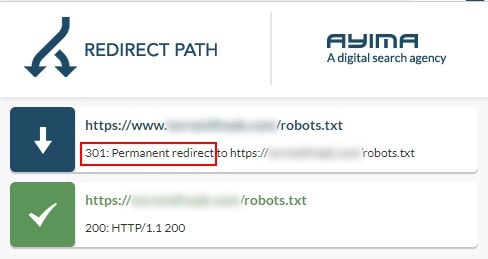
Решение: переадресация 301
Чтобы избежать проблем с robots.txt по поддомену или протоколу, нужно реализовать переадресацию файла robots.txt на нужную версию с помощью 301 редиректа.
В прошлой статье «Как добавить сайт в поисковые системы» мы рассказали, как сообщить поисковым роботам о новом сайте или страницах. Но после добавления сайта в поисковые системы, он все еще может не индексироваться в Google или Яндексе. Что еще хуже, поисковые роботы сканировали сайт раньше, но теперь сайт не индексируется. Единственный выход в этой ситуации ― проверить возможные причины, которые влияют на индексацию сайта. Об этих причинах расскажем в статье.

Из статьи вы узнаете:
Сайт закрыт от индексации в Robots.txt
Одна из самых распространенных причин, из-за которой сайт не индексируется ― запрет на индексацию в файле robots.txt. Часто разработчики сайта хранят тестовую версию на отдельных доменах или поддоменах. Тестовый сайт закрывают от индексации с помощью robots.txt. Когда сайт уже готов, содержимое тестовой версии вместе с файлом robots.txt попадает на рабочий домен. Файл robots.txt забывают изменить и сайт становится недоступным для поисковых роботов.
Если сайт закрыт от индексации, содержимое файла может выглядеть следующим образом:

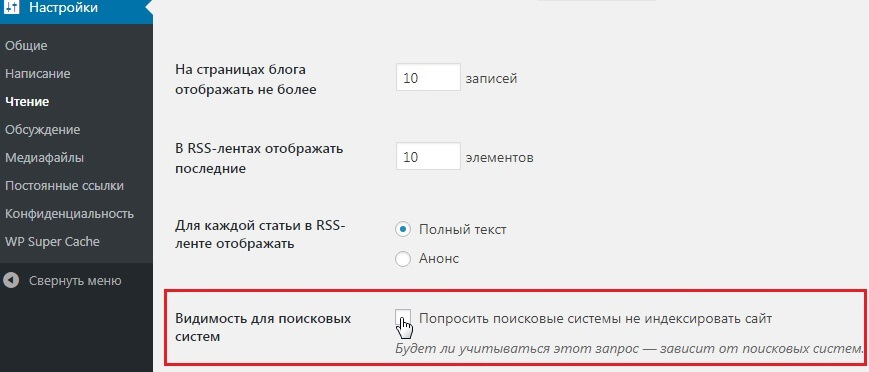
Если у вас сайт на CMS WordPress, проверьте настройки индексации в панели управления сайтом. Зайдите в раздел Настройки → Чтение. Поле Видимость для поисковых систем должно быть пустым:
Как проверить Robots.txt
При помощи следующих инструментов можно проверить не закрыт ли через robots.txt от индексации сайт или определенные страницы:
Предварительно нужно добавить сайт в панель вебмастеров Google или Яндекс, чтобы проверить robots.
Если еще не пользуетесь данными сервисами, читайте статью: Как добавить сайт в инструменты веб-мастеров
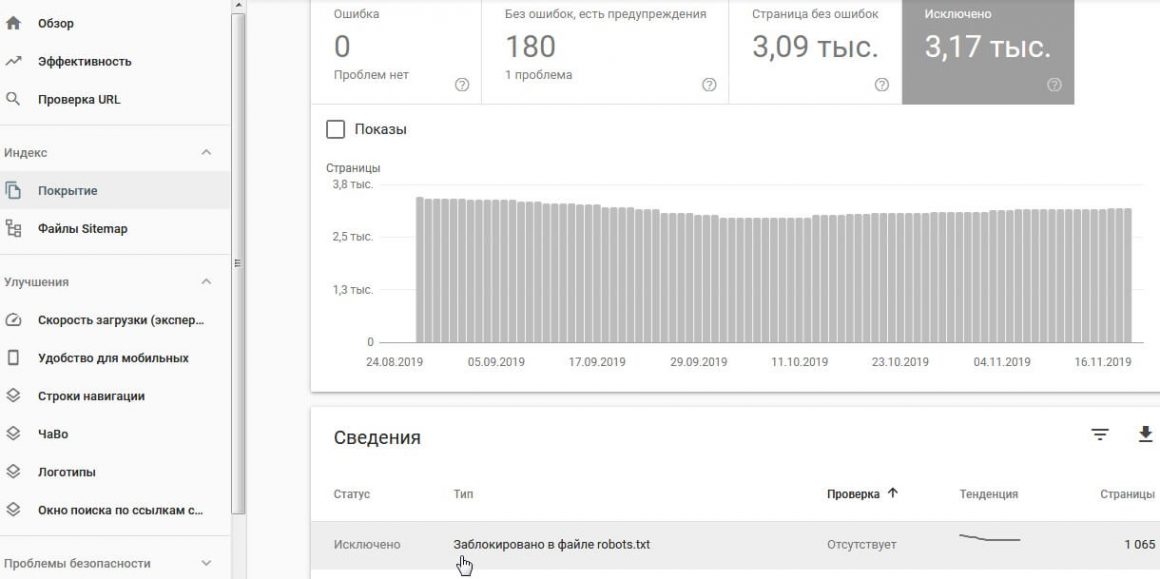
Google Search Console
Отчет Индекс → Покрытие → вкладка Исключено
Яндекс вебмастер
Отчет Диагностика → Диагностика сайта показывает наличие проблем с индексацией сайта.
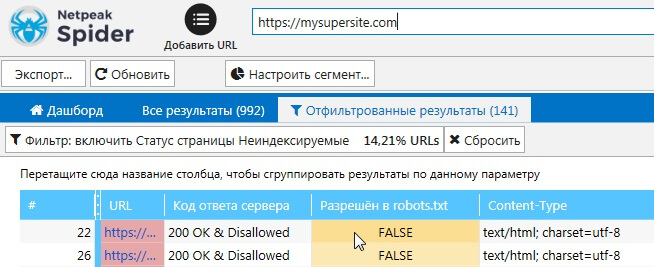
После сканирования сайта или определенных страниц, в результатах отчета будут показаны страницы, которые недоступны для индексации:
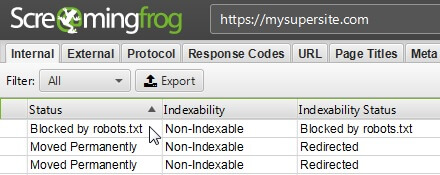
Screaming Frog SEO Spider
Netpeak Spider
Метатеги Robots
Проверьте наличие метатега robots в коде страницы. Его размещают между тегами <head></head>. Выглядеть этот тег может следующим образом:
Метатег robots сообщает поисковым роботам о том, что страницу индексировать не нужно.
Как проверить метатеги Robots
Google Search Console
Отчет Индекс → Покрытие → вкладка Исключено
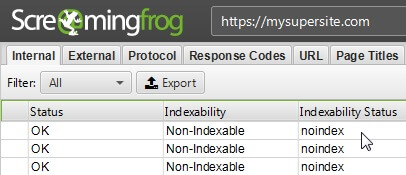
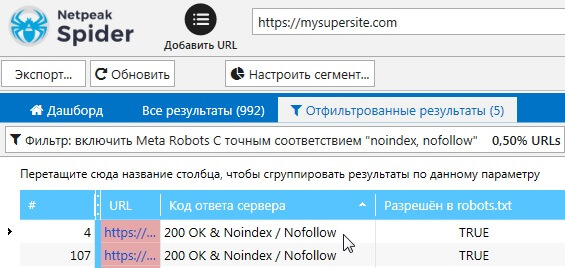
Обнаружить страницы, которые закрыты от индексации с помощью метатегов robots, можно с помощью программ для аудита внутренней оптимизации сайта.
Screaming Frog SEO Spider
Netpeak Spider
Файл .htaccess
С помощью некоторых правил в .htaccess можно закрыть сайт от индексации. Например, можно закрыть доступ для всех посетителей, кроме нужного IP адреса:
Или можно разрешить доступ всем, кроме нужного IP:
Проверьте файл .htaccess на вашем сервере, возможно в нем прописаны запрещающие правила для индексирования.
Более подробно узнать о директивах и правилах можно в нашей статье: Файл htaccess.
Rel Canonical
Рассмотрим на примере две страницы, которые имеют одинаковое содержание:


X‑Robots-Tag
Этот тег можно использовать в конфигурации сервера. На серверах Apache он добавляется в файл .htaccess, на серверах Nginx в файл conf.
Рассмотрим на примере, как выглядит запрет на индексацию файлов .doc через X-Robots-Tag:
Фрагмент кода в файле .htaccess для сервера Apache
Фрагмент кода в файле conf для сервера Nginx
Как проверить наличие X‑Robots-Tag на страницах сайта
Плагин Web Developer для браузеров:



Долгий ответ сервера
Время ответа сервера ― это время, за которое запрос клиента в браузере доходит до сервера и клиент получает ответ сервера. Время отклика измеряется в TTFB (Time To First Byte) ― время до первого байта, или сколько миллисекунд прошло между вашим запросом и ответом сервера. Google рекомендует стремиться к тому, чтобы время отклика было менее 200 миллисекунд. TTFB больше 500 мс уже является проблемой.
Если при обращении поискового робота к серверу, он получает долгий ответ, то робот может не просканировать часть страниц..
Как проверить время ответа сервера
Проверить время ответа сервера можно с помощью сервисов:
Возможные причины долгого ответа сервера
Среди возможных причин можно выделить следующие:
- недостаточный объем ресурсов сервера (слабый процессор, недостаточно памяти);
- не оптимизирована работа сервера;
- отсутствие оптимизации скорости загрузки сайта. Не минимизированы файлы CSS/JS, не сжаты изображения и т.д.
- отсутствие кэширования.
Полезные статьи по теме:
Если вы оптимизировали скорость загрузки сайта, но у вас остались проблемы с долгим ответом сервера, стоит попробовать другие хостинги. Например, мы предлагаем виртуальный хостинг с серверами в Украине, Нидерландах и США . Ваш сайт более требовательный и нужно больше мощностей? Не проблема. У нас есть VIP пакеты с большим объемом ресурсов или можно взять VPS.
Возьмите хостинг на тест и проверьте сами. 30 дней бесплатно!
Пробуйте надежный хостинг с аптаймом 99,5%!
Наша теплая поддержка на связи 24/7

Неверный ответ сервера
Проверьте код ответа сервера. Убедитесь, что нужные вам страницы отдают код 200.
Этот код означает, что страница доступна на сервере.
Как проверить ответ сервера
Проверить ответ сервера можно с помощью инструментов:
Также можно использовать различные плагины для браузеров или можно проверить в самом браузере ― F12+вкладка Network.
Некачественный контент
Если ваши страницы содержат контент, который не имеет ценности для пользователя, то поисковые роботы могут не индексировать их. В англоязычных статьях можно встретить термин thin content, который описывает данные страницы.
Примером такого контента может быть:
- дублированный контент;
- скопированный контент;
- автоматически сгенерированный контент;
- неинформативные страницы с партнерскими ссылками;
- дорвеи.
Проблемы на стороне поисковых систем
Как говорится ― и на старуху бывает проруха. На стороне поисковых систем тоже могут возникать проблемы. Например, в начале июля в Google возникли проблемы с индексацией нового контента. Об этом можно прочитать в новостях:
В Google оперативно реагируют и исправляют проблемы.
The indexing issues from yesterday have been resolved. Thank you for your patience.
— Google Search Central (@googlesearchc) June 3, 2020
Итоги
Подытожим причины, из-за которых страницы сайта могут не индексироваться:
- Сайт закрыт от индексации через
- robots.txt
- метатеги robots
- файл .htaccess
- X-robots-tag
Руслан Иванов
Работает в сфере SEO с 2007 года. Занимается продвижением HOSTiQ с 2016. Пишет статьи по SEO.
Читайте также: