
Как работает система компьютерного перевода
Обновлено: 03.07.2024
В Яндекс.Переводчике используется гибридная модель машинного перевода, включающая в себя нейросетевой и статистический подходы.
Статистический подход
Статистический подход основан на моделях языка и перевода:
Для создания модели перевода система сравнивает сотни тысяч параллельных текстов, одинаковых по смыслу, но написанных на разных языках. Сравнивая их, система учится находить соответствия — например, запоминает, что слова «dog» и «собака» являются вероятными переводами друг друга. Результат сравнения записывает в матрицу выравнивания слов. Матрица помогает определить, какие пары фраз в паре предложений могут служить переводами друг для друга. Для создания модели языка система изучает тексты на одном языке и составляет списки всех употребляемых слов и фраз. Каждому слову и фразе соответствует свой числовой идентификатор, определяющий их статистическую популярность в языке (частоту использования).Во время перевода каждое исходное предложение разбивается на слова и фразы, которые переводятся независимо друг от друга. Для каждой части разбитого предложения подбирается потенциальный перевод из матрицы. Затем система заново «собирает» несколько вариантов предложения и выбирает статистически лучший вариант с точки зрения оптимальной сочетаемости слов в натуральном языке.
Достоинством статистического подхода является способность запоминать и переводить короткие фразы и редкие слова. Однако есть и недостаток — в результате может отсутствовать взаимосвязь между фразами, так как при переводе не учитывается контекст.
Нейросетевой подход
Как и в статистическом подходе, нейронная сеть также анализирует массив параллельных текстов, учится находить в них закономерности и составляет списки всех употребляемых слов и фраз.
Однако вместо простых идентификаторов из статистического подхода в нейросетевом подходе используется векторное представление слов (word embedding). Вектор состоит из чисел, характеризующих слово по лексическим и семантическим признакам.
Во время перевода каждое исходное предложение не разбивается на слова и фразы, а переводится полностью. Каждому слову в предложении сопоставляется вектор длиной в несколько сотен чисел. В итоге предложение представляет из себя некое векторное пространство. В этом векторном пространстве нейронная сеть определяет семантику слов и взаимосвязь между ними, даже если слова находятся в разных частях исходного предложения.
Система может распознать, что слова «чай» и «кофе» часто появляются в сходных контекстах. Оба этих слова могут находиться в контексте нового слова «разлив» . В обучающих данных со словом «разлив» встречается лишь одно из них (например, «чай» ). В итоге система выберет слово «чай» .Достоинством нейросетевого подхода является способность учитывать взаимосвязь между словами, что позволяет добиться более связного перевода. Недостатком подхода может быть отсутствие достаточной информации по словам, которые редко встречались и для которых система еще не смогла построить приемлемое векторное представление. К редким словам относятся, например, мало распространенные имена или топонимы.
Выбор варианта перевода и оценка качества
Как только пользователь вводит текст для перевода, Яндекс.Переводчик передает этот текст сразу двум системам: и нейронной сети, и статистическому переводчику.
Результат, полученный от обеих систем, оценивается алгоритмом, основанном на методе обучения CatBoost (english version). При оценке учитываются десятки факторов — от длины предложения (короткие фразы и редкие слова лучше переводит статистическая модель) до синтаксиса. Алгоритм оценивает оба перевода по всем факторам, выбирает лучший и показывает этот перевод пользователю.

В основе современных систем лежит алгоритм перевода, использующий формальную грамматику языков и статистические данные. Чтобы выучить язык, система сравнивает тысячи параллельных текстов — содержащих одну и ту же информацию, но на разных языках. Для каждого изученного текста система строит список уникальных признаков. Например, редко используемые слова и специальные знаки, которые встречаются в тексте с определенной частотой.

В системах машинного перевода, как правило, три основные части: модель перевода, модель языка и декодер. Модель перевода — это таблица, в которой для всех слов и фраз на одном языке перечислены возможные переводы на другой язык с указанием вероятности этих переводов. Система сравнивает не только отдельные слова, но и словосочетания из нескольких слов, идущих подряд. Модели перевода для каждой пары языков содержат миллионы пар слов и словосочетаний. Что касается модели языка, то она создается системой на этапе изучения текстов.
Переводом занимается декодер. Он проводит морфологический и синтаксический анализ текста и для каждого предложения подбирает все варианты перевода с сортировкой по убыванию вероятности. Затем все полученные варианты декодер оценивает с помощью модели языка на частоту употребления и выбирает предложение с наилучшим сочетанием вероятности и частоты.
![]()
Системы машинного перевода можно использовать не только для работы с текстами, но и для перевода отдельных слов. Они содержат полноценные словари с подробными карточками слов и устойчивых выражений. Эти карточки система составляет на основе статистических данных, опираясь на правила языка. Для машинного словаря она отбирает только словарные формы слов и устойчивые выражения. Система проводит морфологический и синтаксический анализ, определяет часть речи, словарную форму слова и устанавливает границы словосочетаний. Эта информация помогает отсеивать неполные словосочетания. Чтобы избежать ошибок и опечаток, алгоритм, основанный на технологии машинного обучения, проверяет все потенциальные пары переводов и отсеивает ненадёжные.
Близкие по значению переводы группируются системой с помощью словарей синонимов. В них попадают слова, которые часто переводятся на другой язык одинаково или образуют словосочетания с одинаковыми словами. В результате машинный словарь получает всё, что ему необходимо знать о каждом слове и выражении: его словарную форму, часть речи, значения и синонимы. Некоторые системы для наглядности добавляют к переводам примеры, которые берут из параллельных текстов.

В этой публикации нашего цикла step-by-step статей мы объясним, как работает нейронный машинный перевод и сравним его с другими методами: технологией перевода на базе правил и технологией фреймового перевода (PBMT, наиболее популярным подмножеством которого является статистический машинный перевод — SMT).
Результаты исследования, полученные Neural Machine Translation, удивительны в части того, что касается расшифровки нейросети. Создается впечатление, что сеть на самом деле «понимает» предложение, когда переводит его. В этой статье мы разберем вопрос семантического подхода, который используют нейронные сети для перевода.
Давайте начнем с того, что рассмотрим методы работы всех трех технологий на различных этапах процесса перевода, а также методы, которые используются в каждом из случаев. Далее мы познакомимся с некоторыми примерами и сравним, что каждая из технологий делает для того, чтобы выдать максимально правильный перевод.
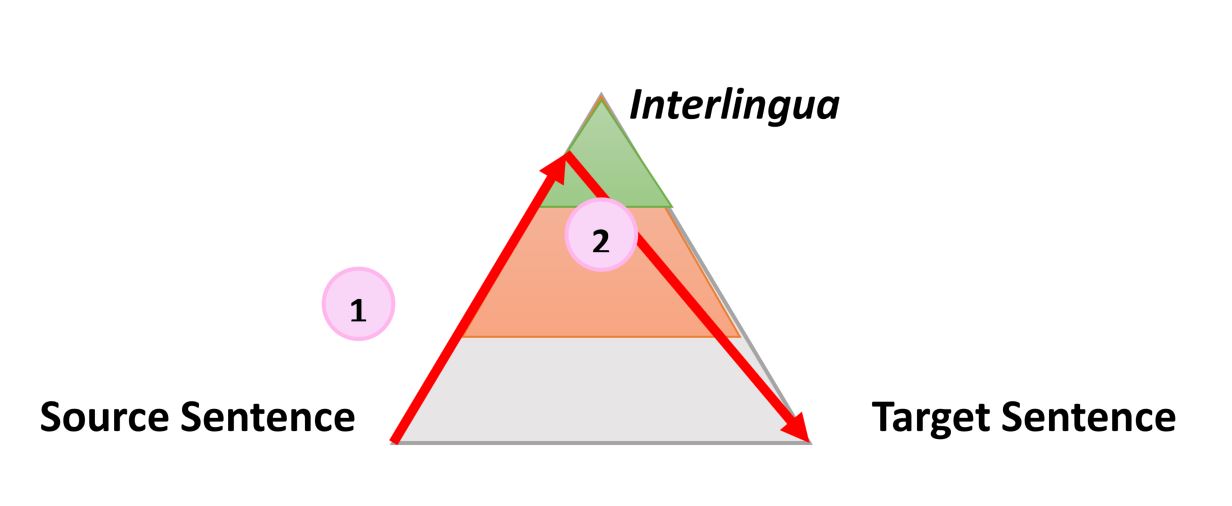
Очень простой, но все же полезной информацией о процессе любого типа автоматического перевода является следующий треугольник, который был сформулирован французским исследователем Бернардом Вокуа (Bernard Vauquois) в 1968 году:
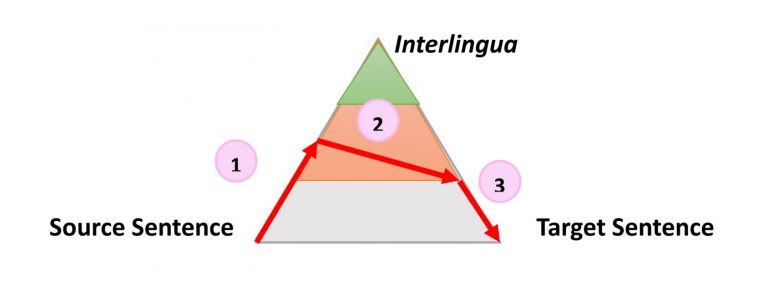
В этом треугольнике отображен процесс преобразования исходного предложения в целевое тремя разными путями.
Левая часть треугольника характеризует исходный язык, когда как правая — целевой. Разница в уровнях внутри треугольника представляет глубину процесса анализа исходного предложения, например синтаксического или семантического. Теперь мы знаем, что не можем отдельно проводить синтаксический или семантический анализ, но теория заключается в том, что мы можем углубиться на каждом из направлений. Первая красная стрелка обозначает анализ предложения на языке оригинала. Из данного нам предложения, которое является просто последовательностью слов, мы сможем получить представление о внутренней структуре и степени возможной глубины анализа.
Например, на одном уровне мы можем определить части речи каждого слова (существительное, глагол и т.д.), а на другом — взаимодействие между ними. Например, какое именно слово или фраза является подлежащим.
Когда анализ завершен, предложение «переносится» вторым процессом с равной или меньшей глубиной анализа на целевой язык. Затем третий процесс, называемый «генерацией», формирует фактическое целевое предложение из этой интерпретации, то есть создает последовательность слов на целевом языке. Идея использования треугольника заключается в том, что чем выше (глубже) вы анализируете исходное предложение, тем проще проходит фаза переноса. В конечном итоге, если бы мы могли преобразовать исходный язык в какой-то универсальный «интерлингвизм» во время этого анализа, нам вообще не нужно было бы выполнять процедуру переноса. Понадобился бы только анализатор и генератор для каждого переводимого языка на любой другой язык (прямой перевод прим. пер.)
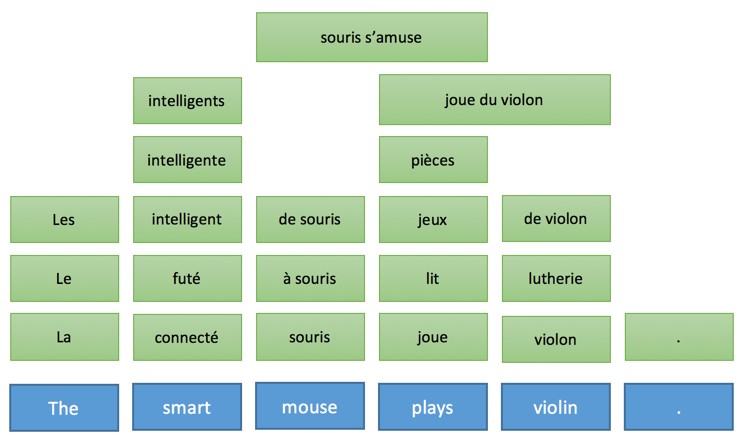
Эта общая идея и объясняет промежуточные этапы, когда машина переводит предложения пошагово. Что еще более важно, эта модель описывает характер действий во время перевода. Давайте проиллюстрируем, как эта идея работает для трех разных технологий, используя в качестве примера предложение «The smart mouse plays violin» (Выбранное авторами публикации предложение содержит небольшой подвох, так как слово «Smart» в английском языке, кроме самого распространенного смысла «умный», имеет по словарю в качестве прилагательного еще 17 значений, например «проворный» или «ловкий» прим. пер.)
Машинный перевод на базе правил
Машинный перевод на базе правил является самым старым подходом и охватывает самые разные технологии. Однако, в основе всех их обычно лежат следующие постулаты:
- Процесс строго следует треугольнику Вокуа, анализ очень часто завышен, а процесс генерации сводится к минимальному;
- Все три этапа перевода используют базу данных правил и лексических элементов, на которые распространяются эти правила;
- Правила и лексические элементы заданы однозначно, но могут быть изменены лингвистом.
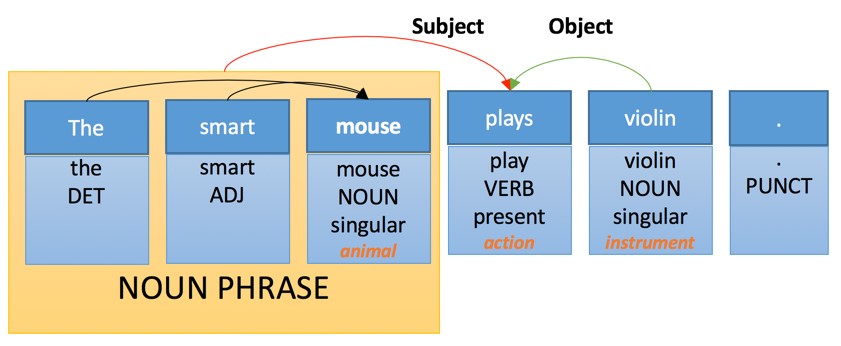
Тут мы видим несколько простых уровней анализа:
- Таргеритование частей речи. Каждому слову присваивается своя «часть речи», которая является грамматической категорией.
- Морфологический анализ: слово «plays» распознается как искажение от третьего лица и представляет форму глагола «Play».
- Семантический анализ: некоторым словам присваивается семантическая категория. Например, «Violin» — инструмент.
- Составной анализ: некоторые слова сгруппированы. «Smart mouse» — это существительное.
- Анализ зависимостей: слова и фразы связаны с «ссылками», при помощи которых происходит идентификация объекта и субъекта действия основного глагола «Plays».

Применение этих правил приведет к следующей интерпретации на целевом языке перевода:
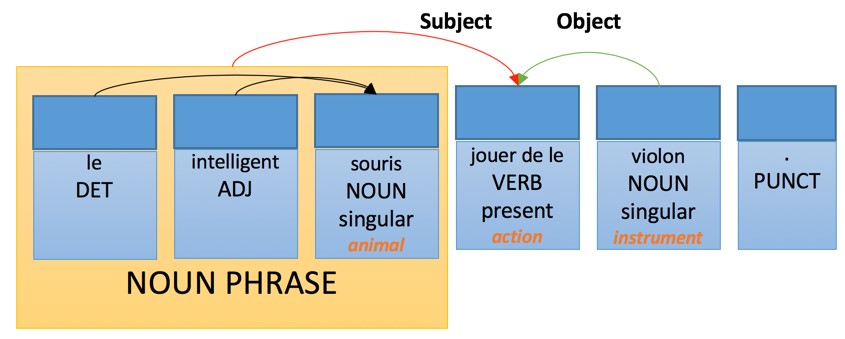
Тогда как правила генерации на французском будут иметь следующий вид:
- Прилагательное, выраженное словосочетанием, следует за существительным — с несколькими перечисленными исключениями.
- Определяющее слово согласованно по числу и роду с существительным, которое оно модифицирует.
- Прилагательное согласовано по числу и полу с существительным, которое оно модифицирует.
- Глагол согласован с подлежащим.
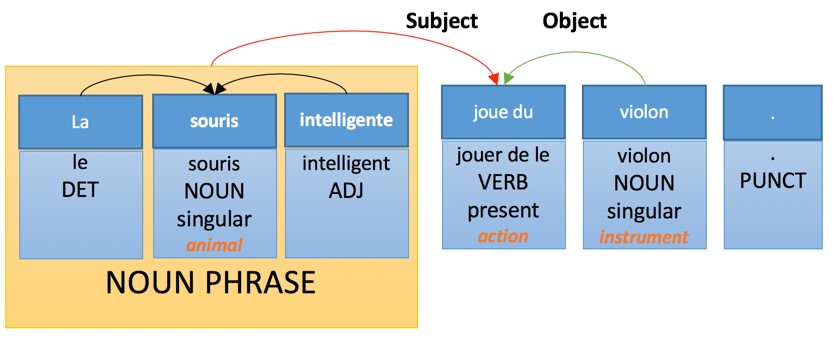
Машинный перевод на базе фраз
Машинный перевод на базе фраз — это самая простая и популярная версия статистического машинного перевода. Сегодня он по-прежнему является основной «рабочей лошадкой» и используется в крупных онлайн-сервисах по переводу.
Выражаясь технически, машинный перевод на базе фраз не следует процессу, сформулированному Вокуа. Мало того, в процессе этого типа машинного перевода не проводится никакого анализа или генерации, но, что более важно, придаточная часть не является детерминированной. Это означает, что технология может генерировать несколько разных переводов одного и того же предложения из одного и того же источника, а суть подхода заключается в выборе наилучшего варианта.
Эта модель перевода основана на трех базовых методах:
- Использование фразы-таблицы, которая дает варианты перевода и вероятность их употребления в этой последовательности на исходном языке.
- Таблица изменения порядка, которая указывает, как могут быть переставлены слова при переносе с исходного на целевой язык.
- Языковая модель, которая показывает вероятность для каждой возможной последовательности слов на целевом языке.
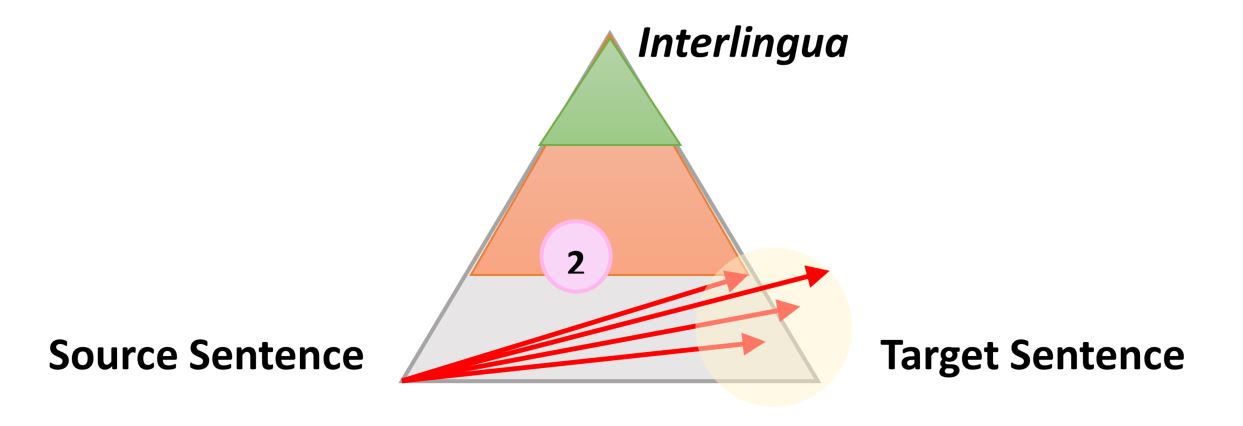
Далее из этой таблицы генерируются тысячи возможных вариантов перевода предложения, например:
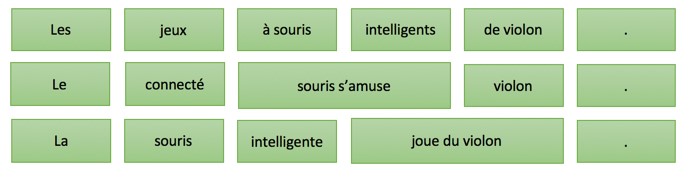
Однако благодаря интеллектуальным вычислениям вероятности и использованию более совершенных алгоритмов поиска, будет рассмотрен только наиболее вероятные варианты перевода, а лучший сохранится в качестве итогового.
В этом подходе целевая языковая модель крайне важна и мы можем получить представление о качестве результата, просто поискав в Интернете:

Поисковые алгоритмы интуитивно предпочитают использовать последовательности слов, которые являются наиболее вероятными переводами исходных с учетом таблицы изменения порядка. Это позволяет с высокой точностью генерировать правильную последовательность слов на целевом языке.
В этом подходе нет явного или неявного лингвистического или семантического анализа. Нам было предложено множество вариантов. Некоторые из них лучше, другие — хуже, но, на сколько нам известно, основные онлайн-сервисы перевода используют именно эту технологию.
Нейронный машинный перевод
Подход к организации нейронного машинного перевода кардинально отличается от предыдущего и, опираясь на треугольник Вокуа, его можно описать следующим образом:
Нейронный машинный перевод имеет следующие особенности:
- «Анализ» называется кодированием, а его результатом является загадочная последовательность векторов.
- «Перенос» называется декодированием и непосредственно генерирует целевую форму без какой-либо фазы генерации. Это не строгое ограничение и, возможно, имеются вариации, но базовая технология работает именно так.
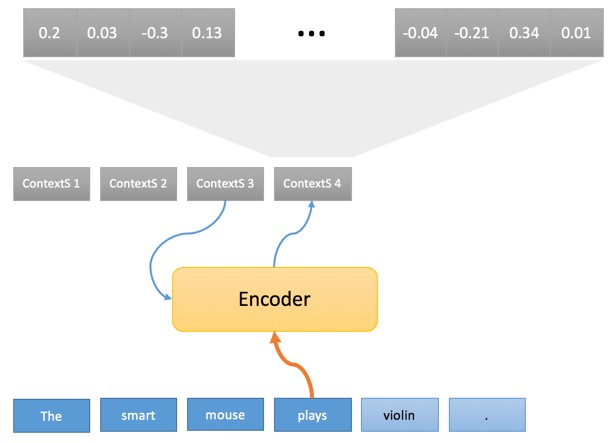
Последовательность исходных контекстов (ContextS 1,… ContextS 5) являет внутренней интерпретацией исходного предложения по треугольнику Вокуа и, как упоминалось выше, представляет из себя последовательность чисел с плавающей запятой (обычно 1000 чисел с плавающей запятой, связанных с каждым исходным словом). Пока мы не будем обсуждать, как кодировщик выполняет это преобразование, но хотелось бы отметить, что особенно любопытным является первоначальное преобразование слов в векторе «float».
На самом деле это технический блок, как и в случае с основанной на правилах системой перевода, где каждое слово сначала сравнивается со словарем, первым шагом кодера является поиск каждого исходного слова внутри таблицы.
Предположим, что вам нужно вообразить разные объекты с вариациями по форме и цвету в двумерном пространстве. При этом объекты, находящиеся ближе всего друг к другу должны быть похожи. Ниже приведен пример:
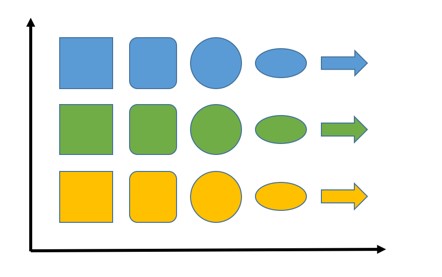
На оси абсцисс представлены фигуры и там мы стараемся поместить наиболее близкие по этому параметру объекты другой формы (нам нужно будет указать, что делает фигуры похожими, но в случае этого примера это кажется интуитивным). По оси ординат располагается цвет — зеленый между желтым и синим (расположено так, потому что зеленый является результатом смешения желтого и синего цветов, прим. пер.) Если бы у наших фигур были разные размеры, мы бы могли добавить этот третий параметр следующим образом:
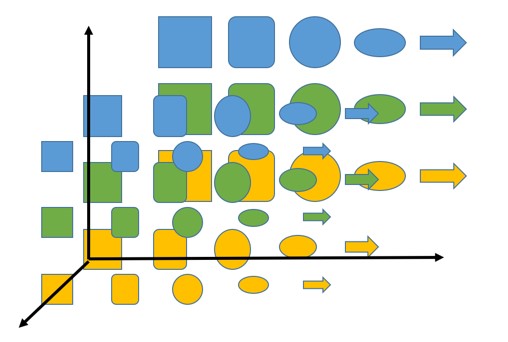
Если мы добавим больше цветов или фигур, мы также сможем увеличить и число измерений, чтобы любая точка могла представлять разные объекты и расстояние между ними, которое отражает степень их сходства.
Основная идея в том, что это работает и в случае размещения слов. Вместо фигур есть слова, пространство намного больше — например, мы используем 800 измерений, но идея заключается в том, что слова могут быть представлены в этих пространствах с теми же свойствами, что и фигуры.
Следовательно, слова, обладающие общими свойствами и признаками будут расположены близко друг к другу. Например, можно представить, что слова определенной части речи — это одно измерение, слова по признаку пола (если таковой имеется) — другое, может быть признак положительности или отрицательности значения и так далее.
Мы точно не знаем, как формируются эти вложения. В другой статье мы будем более подробно анализировать вложения, но сама идея также проста, как и организация фигур в пространстве.
Вернемся к процессу перевода. Второй шаг имеет следующий вид:
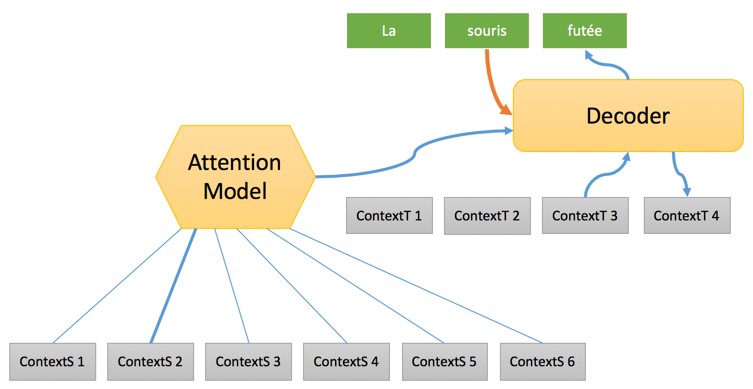
На этом этапе формируется полная последовательность с упором на «исходный контекст», после чего один за другим целевые слова генерируются с использованием:
- «Целевого контекста», сформированного в связке с предыдущим словом и предоставляющего некоторую информацию о состоянии процесса перевода.
- Значимости «контекстного источника», который представляет собой смесь различных «исходных контекстов» опираясь на конкретную модель под названием «Модель внимания» (Attention Model). Что это такое мы разберем в другой статье. Если кратко, то «Модели внимания» выбирают исходное слово для использование в переводе на любом этапе процесса.
- Ранее приведенного слова с использованием вложения слов для преобразования его в вектор, который будет обрабатываться декодером.
Весь процесс, несомненно, весьма загадочен и нам потребуется несколько публикаций, чтобы рассмотреть работу его отдельных частей. Главное, о чем следует помнить — это то, что операции процесса нейронного машинного перевода выстроены в той же последовательности, что и в случае машинного перевода на базе правил, однако характер операций и обработка объектов полностью отличается. И начинаются эти отличия с преобразования слов в векторы через их вложение в таблицы. Понимания этого момента достаточно для того, чтобы осознать, что происходит в следующих примерах.
Примеры перевода для сравнения
Давайте разберем некоторые примеры перевода и обсудим, как и почему некоторые из предложенных вариантов не работают в случае разных технологий. Мы выбрали несколько полисемических (т.е. многозначных, прим. пер.) глаголов английского языка и изучим их перевод на французский.

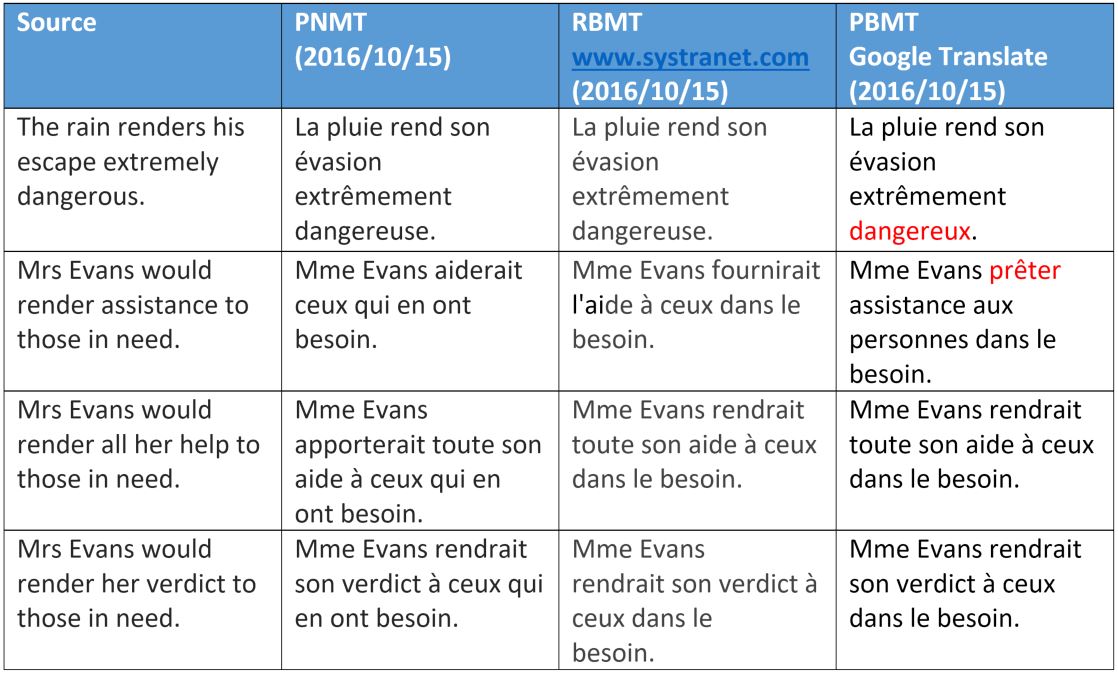
Мы видим, что машинный перевод на базе фраз, интерпретирует «render» как смысл — за исключением очень идиоматического варианта «оказание помощи». Это можно легко объяснить. Выбор значения зависит либо от проверки синтаксического значения структуре предложения, либо от семантической категории объекта.
Для нейронного машинного перевода видно, что слова «help» и «assistance» обрабатываются правильно, что показывает некоторое превосходство, а также очевидную способность этого метода получать синтаксические данные на большом расстоянии между словами, что мы более детально рассмотрим в другой публикации.

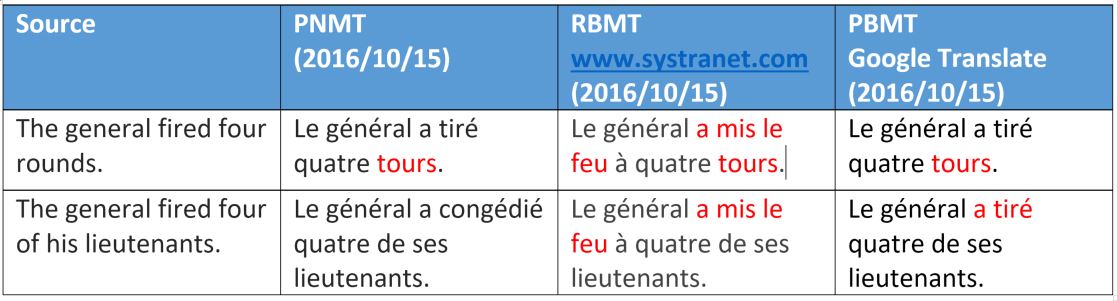
На этом примере опять видно, что нейронный машинный перевод имеет семантические различия с двумя другими способами (в основном они касаются одушевленности, обозначает слово человека или нет).
Однако отметим, что было неправильно переведено слово «rounds», которое в данном контексте имеет значение слова «bullet». Мы объясним этот типа интерпретации в другой статье, посвященной тренировке нейронных сетей. Что касается перевода на базе правил, то он распознал только третий смысл слова «rounds», который применяется в отношении ракет, а не пуль.

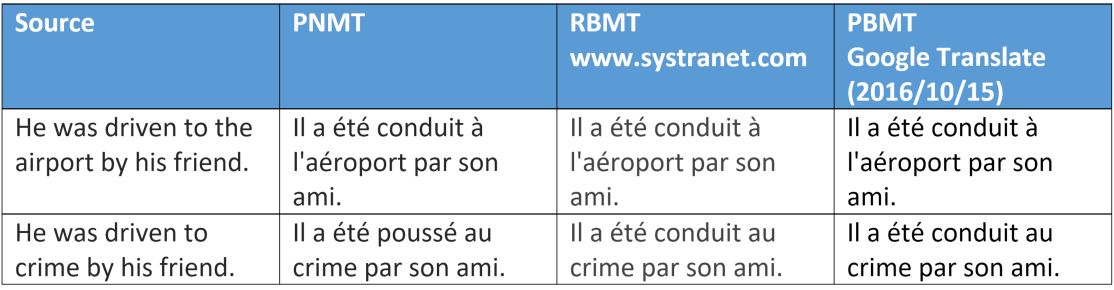
Выше еще один интересный пример того, как смысловые вариации глагола в ходе нейронного перевода взаимодействуют с объектом в случае однозначного употребления предлагаемого к переводу слова (crime или destination).
Другие варианты со словом «crime» показали тот же результат…
Переводчики работающие на базе слов и фраз так же не ошиблись, так как использовали те же глаголы, приемлемые в обоих контекстах.
![]()
Машинное обучение упрощает работу специалистов в самых разных областях, например, переводчикам. Хотя без живых людей по-прежнему не обойтись, их роль в процессе меняется. Технический специалист MedConsult Татьяна Апраксина рассказывала, как в бюро внедрили машинный перевод, как выглядит работа с ним на практике и каких результатов удалось достичь.
У переводчиков есть популярный анекдот: «Голый кондуктор бежит под вагоном» — так выглядит автоматический перевод фразы «A naked conductor runs under the tram» без учета контекста. А должно быть: «Оголенный провод проходит под вагоном». Примерно так выглядел и машинный перевод еще в 2008 году. Но сейчас все сильно изменилось: перевод, выполненный благодаря алгоритмам, сложно отличить от «человеческого». Да, полностью заменить переводчиков нельзя, но новые технологии сильно повышают качество и скорость. Разберемся, как это работает, на примере компании MedConsult.

MedConsult — бюро переводов медицинских документов. Его сотрудники помогают фармацевтическим, медицинским, страховым компаниям и частным заказчикам с переводом документов для регистрации препаратов, выписок из карт и т. д.

Татьяна Апраксина занимается внедрением и поддержкой инструментов автоматизации перевода в компании MedConsult. «Мы решили не разрабатывать программы сами, — рассказывает Татьяна, — создавать свое решение долго и дорого. На рынке есть поставщики услуг машинного перевода: мы пользуемся программой MemoQ и сервисами компании Intento. Наша задача — сделать использование этих инструментов максимально простым для наших переводчиков».
MemoQ — это программа для перевода текстов, в которой сотрудники используют разные плагины, помогающие в работе. В MedConsult начали использовать ее девять лет назад, отказавшись от обычных Word и Excel, и соответственно перестраивать работу переводчиков.
«Это было непросто: обычно переводчики — очень консервативные люди. Но они попробовали инструмент и поняли, что он значительно облегчает работу. Два года назад мы внутри компании начали внедрять плагин с машинным переводом, и теперь большинство переводчиков сами просят подготовить текст с использованием этой технологии».
Как работает программа для перевода

Даже без машинного перевода в MemoQ есть много полезных функций. Например, функция «память переводов» — файл, в котором записаны пары «оригинал-перевод». Если программа находит в тексте сегмент, который уже переводили ранее, — его перевод появится автоматически. В работе с медицинской документацией это экономит кучу времени: многие типовые куски документов уже когда-то переводили. А если программа находит похожий переведенный сегмент, то переводчик просто исправляет различающиеся детали.
Другая функция — глоссарий, словарь терминов. MemoQ позволяет создавать множество глоссариев, по которым программа будет подсвечивать медицинские термины, предлагая правильный перевод. В MedConsult создают глоссарии для каждой компании-заказчика, поэтому все переводчики, работающие над большим пакетом документов одного клиента, используют везде одинаковые термины.
Качество машинного перевода растет. У того же Google с 2009 по 2019 год работал сервис Translator Toolkit — в нем переводчики получали машинный перевод в веб-интерфейсе. Благодаря этому у Translator Toolkit появился большой массив данных о переводах и ручных исправлениях переводчиков за 10 лет. Эти данные использовали для обучения алгоритмов и повысили качество перевода.

По словам Татьяны, пока не все работает идеально. Иногда у поставщиков машинного перевода случаются сбои — может прийти текст очень плохого качества. Тогда приходится снова отправлять запросы на серверы и ждать, когда алгоритмы начнут работать правильно.
Как машинный перевод упрощает работу переводчиков
Пример: индийская фармацевтическая компания хочет продавать в России новое лекарство. Сначала компания оформит российское представительство и запросит в Минздраве список нужных документов. После этого она обратится в бюро медицинских переводов, чтобы перевести всю документацию с английского и подготовить ее по стандартам Минздрава.
Компания присылает в бюро большое количество документов: сертификаты, инструкции, результаты исследований и т. д. Чаще всего их присылают в формате сканов в PDF. Поэтому сканы нужно сначала распознать и перевести в удобный для перевода формат — в текстовые документы, например в Microsoft Word.
В бюро разбирают эти документы по темам и отдают переводчикам, которые, специализируются на конкретных направлениях. Специалист, как правило, имеет медицинское или химическое образование и узкое направление. Если с фармацевтикой могут работать многие, то документы, например, по эндокринологии будет переводить только специалист в этой теме.
Менеджеры бюро загружают текстовые файлы в программу MemoQ, подключают глоссарии и память переводов, после чего начинает работу переводчик. Если работают с типовым документом — может быть достаточно ручных исправлений из памяти переводов. Если текст нужно перевести с нуля, то работают с плагином для машинного перевода.
Переводчик использует машинный перевод как инструмент, но за конечный результат все равно отвечает человек. Чтобы документ был переведен правильно, проверяют падежи, стиль, формулировки, терминологию. Документ также утверждает редактор, а затем верстальщики оформляют его в нужной для Минздрава форме.
Кто занимается машинным переводом?
Обработкой текста занимаются специалисты по NLP (Natural Language Processing) — направлению Data Science. NLP-дата-сайентисты создают нейросети, которые анализируют исходный текст и выдают перевод. Для этого используют машинное обучение — нейросети обучают на больших наборах данных о правильном переводе слов.
В этой профессии есть две специальности, но иногда ими занимается один специалист:
NLP Researcher — исследователь со знаниями в лингвистике. Он подбирает данные для обучения разрабатываемых нейросетей и проводит в них эксперименты по переводу.
NLP Research Engineer — разработчик со знаниями математики и алгоритмов машинного обучения. Он пишет код на Python, который реализует задачи исследователя.
Дата-сайентисты могут работать и в других областях машинного обучения, например бизнес-аналитике и компьютерном зрении.
Data Science с нуля
Освойте самую востребованную профессию 2021 года! Только реальные знание и навыки, поддержка менторов и помощь в трудоустройстве. Дополнительная скидка 5% по промокоду BLOG.
Что дало внедрение машинного перевода?
Компания MedConsult работает с программой MemoQ уже девять лет, а плагин для машинного перевода внедрили два года назад. Главное преимущество над простой работой в Word — упрощение редактуры большого проекта, над которым работает несколько переводчиков. Машинный перевод делает работу качественнее и быстрее. Вот каких результатов с его помощью удалось достичь:
- Улучшилось качество совместного перевода. Все переводчики используют одни и те же глоссарии и память. Поэтому над большим пакетом могут одновременно работать несколько переводчиков: они видят работу друг друга и используют одинаковые термины. Теперь над большим проектом могут работать тридцать переводчиков.
- Время на перевод сократилось в два раза. Время перевода зависит от разных факторов: сроков заказчика, количества документов, сложности темы. Но если вручную человек раньше переводил 2500–3000 слов в день, то с машинным переводом он делает это в два раза быстрее.
Как обучить компьютер переводу?
Мы спросили у Вячеслава Лялина, ведущего автора NLP-трека (интенсивного курса по Natural Language Processing — обработке естественного языка) в Акселераторе SkillFactory, как можно обучить компьютер машинному переводу. По его словам, современные системы перевода можно описать одним предложением: подаем в нейросеть текст на одном языке, а на выходе получаем текст на другом языке.
До нейронных сетей пользовались статистическими системами. Они были сложными и состояли из большого числа компонентов, таких как модель перевода отдельных фраз, языковая модель, которая старается получить из перевода фраз связный текст, и большого числа других подсистем. А с 2016 года мир начал двигаться в сторону нейронных моделей по нескольким причинам.
«Во-первых, нейронные модели стали работать лучше статистических, во-вторых, они были проще, но самое главное — их качество лучше “склеилось” с данными», — считает Вячеслав.
Для обучения нейронной системы перевода достаточно большого датасета так называемых параллельных предложений, то есть пар «предложение-перевод». При обучении системе подают на вход предложение, которое хотят перевести, и внутри она преобразует его в набор чисел (векторы). Эта часть нейросети называется энкодером. Дальше эти векторы изначального предложения передаются в следующую часть нейросети — декодер, — которая предсказывает вероятность следующего слова перевода на основе предыдущих слов перевода и слов оригинального предложения.
Когда система обучена, перевод генерируется пословно. Декодер предсказывает одно слово, после чего оно добавляется в перевод. Дальше декодер на основе векторов из энкодера (информации об оригинальном предложении) и уже сгенерированной части перевода предсказывает следующее слово. Операция повторяется, пока декодер не выдает специальное слово, обозначающее конец перевода.
Machine Learning и Deep Learning
На курсе вы освоите все классические алгоритмы машинного обучения — от деревьев до рекомендательных систем — а также научитесь создавать нейросети.

Впервые идея использовать компьютер для автоматизации перевода текстов с одного естественного языка на другой была предложена Уорреном Уивером в 1949 году. В 1954 году возможности машинного перевода продемонстрировал Джорджтаунский эксперимент, в ходе которого с помощью компьютера быстро перевели с русского на английский язык более 60 предложений. Вот несколько примеров из того эксперимента:
Русский
Мы передаем мысли посредством речи
Величина угла определяется отношением длины дуги к радиусу
Международное понимание является важным фактором в решении политических вопросов
English translation
We transmit thoughts by means of speech.
Magnitude of angle is determined by the relation of length of arc to radius.
International understanding constitutes an important factor in decision of political questions.
Удачным этот опыт можно считать лишь с некоторыми оговорками. Система была построена на простом наборе правил, могла переводить только очень небольшой набор фраз и работала очень долго. Однако Джорджтаунский эксперимент привлек внимание к вопросу машинного перевода. Многие поверили, что еще пара лет — и наступит эра искусственного интеллекта. Правительство, военные и частные корпорации начали щедро вливать деньги в разработки.

В течение последующих тридцати лет исследователи развивали машинный перевод на основе правил: предъявленный текст на исходном языке компьютер переводил с помощью правил и предварительно загруженных словарей. Системы дословного перевода, трансферные системы и системы перевода на примерах считаются разновидностями этого подхода.
Отдельного упоминания заслуживают интерлингвистические системы, идея которых заключалась в преобразовании исходного текста в совокупность концептов, общих для всех языков, с последующей конвертацией их в текст на языке перевода. Этот подход к машинному переводу выделялся среди существовавших на тот момент, но развития так и не получил в силу своей сложности.
В 1980-х годах появился машинный перевод на основе статистических моделей (СМП) — компьютер генерировал текст перевода с помощью параллельных корпусов на языках рабочей пары, выискивая наиболее частотные соответствия слов. Параллельный корпус — это множество пар «текст + перевод». Такие тексты можно выравнивать между собой по абзацам или предложениям. Когда это сделано, на текстах можно обучать статистические модели. Скажем, если у вас есть предложения со словом кошка в русских текстах, то будет огромное количество параллельных английских предложений, где это переводится как cat. Постепенно статистическая система сама обучится тому, что кошка — это cat. Более сложные системы учитывали с помощью статистики и контекст — чтобы научиться не переводить слово «кошки» как cats, если предыдущее слово — альпинистские. Статистический машинный перевод играл ключевую роль вплоть до начала XXI века. И на разных этапах развития этого подхода машина переводила по-разному: по словам, по фразам и на основе синтаксиса.
В 1997 году Р. Ньеко и М. Форкада предложили идею применения в машинном переводе модели «кодер-декодер» — исходный текст шифруется в универсальное «представление», а потом расшифровывается на нужном языке. Напоминает интерлингвистические системы, не так ли? В 2003 году группа исследователей из Монреальского университета под руководством Й. Бенджио разработала языковую модель на основе нейросетей, которая помогла преодолеть проблему парсинга данных, характерную для популярных на тот момент статистических систем. Это и послужило отправной точкой для развития нейронного машинного перевода (НМП), который теперь занимает умы разработчиков и переводчиков.
Системы НМП обучаются на крупных корпусах текстов, что придает им сходство с СМП, однако подход к обработке текста у них совершенно иной. В 2013 году Н. Калкбреннер и Ф. Блансом разработали модель, способную с применением сверточной нейросети-кодера преобразовать исходный текст в непрерывный вектор, а затем с помощью рекуррентной нейросети-декодера перевести этот вектор в текст на языке перевода. Год спустя К. Чо с коллегами предложили в качестве кодера использовать рекуррентные нейросети — по их мнению, РНС лучше подходят для обработки текста. Давайте посмотрим, как это работает.
Только после этого система создает текст на целевом языке. Простейший декодер работает следующим образом:
До тех пор, пока на выходе не получится ‘My flight was delayed’. Следующим наиболее правдоподобным этапом декодер сочтет завершение перевода.
На каждом этапе перевода нейросеть обращается к результатам предыдущего и частично опирается на них, используя релевантные и отбрасывая нерелевантные.
Возможности нейросетей заставляют крупных игроков переключаться на НМП. Еще в сентябре 2016 года Google начал использовать НМП вместо статистического перевода по фразам для пары китайский-английский, а спустя какое-то время добавил еще несколько языков. Любопытно, что Google Translate до сих пор переключается с НМП на СМП для некоторых языковых пар и, поскольку НМП «обращает внимание на контекст», можно узнать, какая именно модель используется в данный момент. В языковых парах, для которых все еще применяется СМП, система подсвечивает отдельные элементы целевого предложения, если навести на него курсор; в случае с языками, для которых подключена нейросеть, предложения подсвечиваются полностью. Из-за этого, кстати, сложнее отследить происхождение ошибок.
Сейчас архитектура «кодер-декодер» на основе РНС, встроенный механизм внимания и длительная кратковременная память (LSTM) — обязательный минимум для среднестатистического онлайн-переводчика (хотя в июне 2017 года появилась новая модель, в которой используются только механизмы внимания). Кроме того, в некоторых системах стали внедрять механизм краудсорсинга. Тот же Google Translate предлагает пользователю отметить наиболее удачный вариант перевода и запоминает самые часто выбираемые из них.
Чтобы сравнить СМП и НМП, в 2016 году провели эксперимент на параллельном корпусе ООН — это 15 языковых пар и 30 направлений перевода. Результаты оценивали с помощью шкалы BLEU (оценивает близость машинного перевода к эталонному человеческому, выполненному профессиональным переводчиком), и по качеству перевода нейросеть не уступала или превосходила СМП во всех 30 направлениях. Исследователи пришли к выводу, что нейросеть делает меньше морфологических и синтаксических ошибок.
Несмотря на все преимущества НМП, ошибки все еще неизбежны, да и процесс обучения нейросетей занимает много времени. К тому же у статистических моделей тоже есть свои сильные стороны. Поэтому в последнее время исследователи комбинируют различные подходы к автоматизации перевода: в попытке добиться более естественного текста рождаются гибридные системы машинного перевода. За примером такой машины далеко ходить не нужно: это всем знакомый Яндекс.Переводчик.
В Яндекс.Переводчике свои варианты перевода генерируют обе модели, а потом специальный алгоритм оценивает/отбирает/комбинирует их и выдает результат. Эксперименты показывают, что переключение модели часто зависит от длины текста и того, есть ли в нем полные предложения — на совсем коротких примерах нейросети иногда еще проигрывают классической статистике. Легкий способ переключиться с обычной статистической модели на нейросеть — добавить точку:
Текст с точкой Яндекс.Переводчик считается достаточно длинным для применения нейросети. А у нейросети с английской грамматикой получается лучше, чем у статистической модели.
Читайте также:
- Не удается продолжить выполнение кода поскольку система не обнаружила steamclient dll
- Определите без компьютера что будет напечатано при выполнении следующих фрагментов а 100
- Устройство которое позволяет передавать и принимать компьютерную информацию по телефонной линии
- Как оптимизировать directx 12
- Где находится файл конфигурации doom