
Как составить proto файл
Обновлено: 06.07.2024
Так случилось, что в процессе реализации одного из проктов мне пришлось познакомиться с технологией protobuf, предолженной Google для решения проблем сериализации в ключе межъязыкового, межплатформенного и кроссплатформенного общения.
Поставленные цели перекликаются с тем, что знаем по технологиям JSON и оригинального XML, однако технология protobuf имеет ряд преимуществ в ключе своей завершенности. Т.е. если средства, обычно предоставляемые для работы с JSON или XML являются некоторыми низкоуровневыми инструментами, то protobuf обеспечивается инструментами самого высокого уровня.
Надо отметить, что, наверное единственный недостаток технологии заключается в необходимости тянуть в проект дополнительные связи с внешней библиотекой. Так, например, работая с JSON или XML, я часто использую свои парсеры и синтезаторы пакетов, чтобы не использовать сторонних библиотек, усложняющих сборку проекта на стороне. Здесь же вся соль технологии заключается в обработке метаописаний и, поэтому, без установки и использования специальных инструментов просто не обойтись.
Суть технологии составляет специальный метакомпилятор, утилита protoc, которая обрабатывает ваше метаописание того набора данных, который нужно сериализовать и составляет по нему систему файлов с исходными кодами неких программных элементов, с помощью которых можно будет легко выполнить сериализацию и десериализацию этих данных. Вам не придется писать ни строчки для синтеза и анализа необходимых пакетов сериализации.
На момент написания этой статьи, Google предоставлял технологию protobuf для языков C++, Java и Python. Кроме того, сторонними заинтересованными компаниями, группами и лицами предоставлена реализация этой технологии для пары десятков других известных языков и, даже, специально для сред разработки.
Подробности сборки читайте в файле README.txt. Тем кто не знаком с такой системой сборки можно дать только один совет - как можно скорее познакомьтесь с ней. Обратите внимание на цель make check. По этой цели вызывается система автоматических тестов собранного пакета.
После установки пакета можно начинать эксперименты по его использованию. Здесь нам, прежде всего, помогут следующие ссылки на оригинальные ресурсы Goggle.
Получив начальное представление о технологии можно познакомиться с конкретной реализацией на простом примере.
Я начал с того, что доверился показательности примера метаописания адресной книги, приведенной в учебнике к C++, и, на его основе, написал простую программку на C++, которая исполняет сериализацию и десериализацию простейшей адресной книги.
В общем, метаописание достаточно понятное. Подробности следует смотреть в руководстве к метаязыку описания данных. Сейчас дадим лишь несколько пояснений.
Объявление пакета (package) вводит в контексте C++ одноименное пространство имен, что предотвращает возможные коллизии данных.
Каждый элемент данных сопровождается модификатором: required, optional и repeated.
Итак, у нас есть метаописание адресной книги. В нашем случае оно лежит в файле addressbook.proto. Создадим по нему систему классов в пространстве имен tutorial к языку C++. Для этого отдадим файл метаописания утилите protoc следующим образом.
При успешном выполнении этой операции мы получим два файла: addressbook.pb.h и addressbook.pb.cc. Это заголовочный файл и файл реализации для классов составленных по метаописанию. Теперь надо включить эти классы в пространство нашего проекта и можно начинать их использовать в коде проекта.
Приведу сразу пример той небольшой программки, которая у меня получилась.
Большую часть представленного примера программы составляет заполнение адресной книги. Из кода видно, что API для технологии protobuf достаточно простой и интуитивно понятный.
Вот что выводится в консоль в результате выполнения этой программы.
Напомню, что во всем этом есть небольшая ложка дегтя - необходимость линковки с библиотекой обеспечивающей фундамент технологии protobuf, с библиотекой libprotobuf. Я делал пример в QtCreator с использованием системы сборки QMake и мой проектный файл выглядит следующим образом.
В заключении следует заметить, что если надо внести изменения в структуру данных подлежащих сериализации, то понадобится перезапустить метакомпилятор protoc по новому описанию и убедиться, что в пространстве проекта лежат измененые файлы - результаты работы метакомпилятора. Соответственно понадобится изменить и проект, но только по части кода заполнения и извлечения данных из предоставленных бизнес-объектов.
Таким образом, основным достоинством технологии является простота использования. Сделал метаописание бизнес-объекта и получил готовый код бизнес-объект и его сериализации. Все что остается - использовать полученный код.
Наверное следует добавить, что предоставленные средства дают возможность не только выполнять сериализацию в строку, но и в поток, что позволяет сразу вывести данные в файл, сеть или куда-то еще, что поддерживает обычные C++ потоки типа std::ostream и std::istream.
Для запуска Томита-парсера необходимо создать файлы, перечисленные в следующей таблице.
| Содержание | Формат | Примечания |
|---|---|---|
| config.proto — конфигурационный файл парсера. Сообщает парсеру, где искать все остальные файлы, как их интерпретировать и что делать. | Protobuf | Нужен всегда. |
| dic.gzt — корневой словарь. Содержит перечень всех используемых в проекте словарей и грамматик. | Protobuf / Gazetteer | Нужен всегда. |
| mygram.cxx — грамматика | Язык описания грамматик | Нужен, если в проекте используются грамматики. Таких файлов может быть несколько. |
| facttypes.proto — описание типов фактов | Protobuf | Нужен, если в проекте порождаются факты. Парсер запустится без него, но фактов не будет. |
| kwtypes.proto — описания типов ключевых слов | Protobuf | Нужен, если в проекте создаются новые типы ключевых слов. |
| Содержание | Формат | Примечания |
|---|---|---|
| config.proto — конфигурационный файл парсера. Сообщает парсеру, где искать все остальные файлы, как их интерпретировать и что делать. | Protobuf | Нужен всегда. |
| dic.gzt — корневой словарь. Содержит перечень всех используемых в проекте словарей и грамматик. | Protobuf / Gazetteer | Нужен всегда. |
| mygram.cxx — грамматика | Язык описания грамматик | Нужен, если в проекте используются грамматики. Таких файлов может быть несколько. |
| facttypes.proto — описание типов фактов | Protobuf | Нужен, если в проекте порождаются факты. Парсер запустится без него, но фактов не будет. |
| kwtypes.proto — описания типов ключевых слов | Protobuf | Нужен, если в проекте создаются новые типы ключевых слов. |
Таким образом, минимальный набор файлов для запуска парсера включает конфигурационный файл и корневой словарь (см. пример minimal). При этом не будут использоваться грамматики и пользовательские типы ключевых слов, а также не будут порождаться факты. Типовой сценарий использования парсера подразумевает наличие всех пяти типов файлов.
Конечный метод оптимизации производительности сети - не передача по сети, но это часто невозможно. Но мы по-прежнему можем добиться лучшей производительности, оптимизируя данные, передаваемые по сети, и производительность следует выжимать из всех возможных мест. Посмотрите здесьProtocol Buffers 。
Protocol Buffers Это гибкий, эффективный и автоматизированный механизм для сериализации структурированных данных, аналогичный XML, номеньше,Быстрее,проще, Определите способ структурированных данных один раз, а затем вы можете просто написать его, используя специально сгенерированный код, или прочитать структурированные данные из большого количества потоков данных на разных языках. Вы даже можете обновить структуру данных, не разрушая развернутыестарый Формат скомпилированной программы. Давайте посмотрим, какProtocol Buffers Используется в нашем проекте Android.
Давайте взглянемProtocol Buffers То, что проект предоставил нам, мы используемProtocol Buffers Общий процесс того, что должно быть сделано. Как показано ниже:

Вручную каждый разProtocol Buffers Компилятор, очевидно, слишком проблематичен для преобразования файлов .proto в файлы Java.Protocol Buffers Разработчики проекта, очевидно, подумали об этом, поэтому они также предоставили нам плагин Gradle для Android Studioprotobuf-gradle-plugin Для автоматического выполнения при компиляции нашего проектаProtocol Buffers Translater.
Мы можемprotobuf-gradle-plugin МестныйProtocol Buffers Путь к компилятору заставляет его использовать локальную компиляцию для выполнения компиляции, или вы можете использоватьProtocol Buffers Другой инструмент, предоставляемый проектом, динамически загружает и выполняет процесс компиляции во время компиляции.
Мы рассмотрим этот процесс подробно позже.
Мы можем быть в следующих местах:
Скачав пакетный protobuf, вы также можете напрямую клонировать код protobuf и скомпилировать компилятор вручную. Здесь мы клонируем код из GitHub и вручную скомпилируем компилятор:
После загрузки кода войдите в каталог protobuf и выполнитеautogen.sh :
Этот скрипт в основном используется для загрузки gmock-1.7.0 для тестирования и генерацииconfigure Жду документов. Вы можете использовать следующие команды, чтобы понять, какую конфигурацию мы можем сделать для компиляции protobuf и информацию о конфигурации по умолчанию:
Выполните configure для настройки компиляции:
Это сгенерирует make-файл, скомпилирует и установит:
Этот процесс компилируется и устанавливаетсяProtocol Buffers В дополнение к компилятору, он также будет скомпилирован для хоста для поддержки использования в C ++Protocol Buffers Библиотека. (Скомпилированный бинарный файл добавляется вprotobuf/src/.libs под. )
После установки выполните следующую команду, чтобы убедиться, что она установлена:
Добавляя к нему при выполнении protoc--help Параметры могут узнать больше использования этого инструмента.
Можно сослаться наИспользуйте буфер протокола в Java Узнайте больше об основах создания .proto файлов в этой статье.
Вы можете скомпилировать файл .proto с помощью следующей команды:
-I, --java_out используются для указания исходного каталога (куда помещается исходный код приложения - если не указан, используется текущий каталог), целевого каталога (где вы хотите разместить сгенерированный код; обычно такой же, как $ SRC_DIR) и, наконец, Параметр является путем к файлу .proto. ProtoC будет генерировать классы Java и структуру каталогов в соответствии со стандартным стилем Java. Для приведенного выше примера, он будет генерироватьcom/example/tutorial/ Структура каталогов иAddressBookProtos.java файл.
Мы скопируем файлы Java, сгенерированные файлом .proto, в наш проект Android:

Добавьте пару в build.gradle нашего приложенияprotobuf-java Зависимости, как полагаться на другие библиотеки Java:
Добавьте класс для доступа к классу Protocol Buffers. Здесь мы добавляем два класса, AddPerson используется для создания объекта Person:
Класс AddressBookProtobuf используется для кодирования / декодирования объектов AddressBook:
Выполнение protoc для компиляции файла .proto всегда слишком проблематично. Protobuf-gradle-plugin может автоматически компилировать файл .proto при компиляции нашего приложения, что значительно сокращает наше использование в проектах Android.Protocol Buffers Сложность.
Сначала нам нужно добавить файл .proto в наш проект, например:

Затем изменитьapp/build.gradle Сконфигурируйте подключаемый модуль protobuf gradle:
- Добавить пару для buildscript protobuf-gradle-plugin Зависимость:
- в apply plugin: 'com.android.application' Позже используйте плагин protobuf:
- Добавьте блок protobuf и настройте выполнение protobuf-gradle-plugin:
protoc Блок используется для настройки компилятора Protocol Buffers, здесь мы указываем компилятор, который мы скомпилировали ранее.
task.builtins Этот блок необходим. Этот блок используется для указания того, для какого языка программирования мы хотим сгенерировать код. Здесь мы генерируем код для C ++ и Java. Если этот блок отсутствует, во время компиляции будет сообщено о следующей ошибке:
В подсказке говорится, что путь к выходному каталогу не указан.
Это связано с тем, что параметры команды компилятора protobuf, выполняемой protobuf-gradle-plugin, находятся в protobuf-gradle-plugin/src/main/groovy/com/google/protobuf/gradle/GenerateProtoTask.groovy Построен в:
Как видите, выходной каталог создается встроенными.
Таким образом, нам не нужно каждый раз запускать protoc вручную.
Сделайте небольшую модификацию предыдущего блока protobuf, нам даже не нужно компилировать компилятор protobuf. Изменить следующим образом:
Для получения дополнительной информации о методе записи .proto файла, API буферов протокола и других, пожалуйста, обратитесь кРуководство разработчика Protobuf、Используйте буфер протокола в JavaИ другие сопутствующие официальные документы.
После долгого разговора, как работает Protobuf? Здесь мы сравниваем производительность нашего наиболее часто используемого формата JSON и Protobuf. Тест основан на fastjson, который пользуется хорошей репутацией среди разработчиков.
Структура данных, используемая для теста, - это адресная книга, которую мы видели ранее. Мы тестируем производительность Protobuf и JSON, создавая данные AddressBook, содержащие разное количество людей, и выполняя множество операций кодирования и декодирования этих данных. Тестовый код для кодирования / декодирования Protobuf - это AddressBookProtobuf, замеченный ранее. Тестовый код JSON выглядит следующим образом:
Выполните тестирование с помощью следующего фрагмента кода:
Здесь мы выполняем 3 набора тестов кодирования и 3 набора тестов декодирования. Для теста кодирования первая группа одиночных данных содержит 10 человек, вторая группа содержит 50 человек, а третья группа содержит 100 человек. Затем каждая информация кодируется 5000 раз.
Для теста декодирования отдельные данные в трех группах также содержат 10 человек, 50 и 100, и затем операция кода декодирования выполняется 5000 раз для каждого из данных.
Выполните вышеуказанный тест на платформе Android 4.4.4 CM от Galaxy Nexus и, наконец, получите следующие результаты:
Сравнение длины данных после кодирования (в байтах)
| Количество персон | Protobuf | Protobuf(GZIP) | JSON | JSON(GZIP) |
|---|---|---|---|---|
| 10 | 860 | 291 | 1703 | 344 |
| 50 | 4300 | 984 | 8463 | 1047 |
| 100 | 8600 | 1840 | 16913 | 1913 |
Для тех же данных длина данных, закодированных в Protobuf, составляет примерно половину длины данных, закодированных в JSON. Но если закодированные данные снова сжимаются, разница между ними относительно невелика.
Сравнение производительности кодирования (S)
| Количество персон | Protobuf | JSON |
|---|---|---|
| 10 | 4.687 | 6.558 |
| 50 | 23.728 | 41.315 |
| 100 | 45.604 | 81.667 |
Производительность кодирования улучшена как минимум на 28,5% и максимум на 44,2%. По сравнению с JSON производительность кодирования Protobuf была значительно улучшена.
Сравнение производительности декодирования (S)
| Количество персон | Protobuf | JSON |
|---|---|---|
| 10 | 0.226 | 8.839 |
| 50 | 0.291 | 43.869 |
| 100 | 0.220 | 85.444 |
С точки зрения производительности декодирования, Protobuf имеет потрясающее улучшение по сравнению с JSON. Время декодирования Protobuf едва ли увеличивается с увеличением длины данных, в то время как с увеличением длины данных время, необходимое для декодирования, становится все длиннее и длиннее.
E-commerce давно перестали быть сайтами с картинками — сегодня это огромные онлайн-платформы с множеством высоконагруженных сервисов. В Ozon порядка 60% сервисов — от инфраструктурных проектов до пользовательских — написано на Go, в IT-лаборатории компании сейчас одна из самых больших golang-команд России. Об инструментах разработки и трендах в развитии языка рассказывает Владимир Сердюков, ведущий разработчик группы «Личный кабинет» Ozon.
ведущий разработчик группы «Личный кабинет» Ozon
Как-то ко мне пришел тестировщик и показал тестовый смартфон, на котором было запущено наше приложение — но вместо текста и элементов интерфейса на нем был белый экран. Мы начали разбираться.
Понять, почему это произошло, можно будет ближе к концу статьи, но забегая вперед (спойлер) — отсутствовало одно из обязательных полей в выдаче от бэкенда.
Почему эту проблему стоит обсуждать?
Подобные проблемы сложно локализовать, и они не заметны на этапе тестирования. Как же тогда их решить? Я бы рекомендовал следующее:
- использовать один контракт для разных платформ (в одном виде для desktop, приложения и т.д.);
- хранить контракты в одном репозитории;
- генерировать код под разные платформы (не писать вручную, забыть про копипасту).
proto 2 vs proto 3
Для работы с контрактами мы в Ozon используем protobuf — механизм, придуманный Google для сериализации структур данных. Чтобы из proto-файлов сгенерировать код, мы используем proto 3 с набором плагинов, один из которых — gogoproto, призванный упростить этот процесс и частично забороть особенности proto v3.
Предыдущая версия протокола (proto 2) позволяла реализовывать обязательные поля при помощи тега optional и задавать стандартное значение. Однако это приводило к проблемам портирования возможности генерации кода на другие языки программирования.
4–5 декабря, Онлайн, Беcплатно
Это стало причиной появления proto 3. В новой версии протокола поменялось отношение к обязательным полям: все поля стали необязательные, а значения по умолчанию просто не отправляются. Кроме того, были исправлены enum, улучшен декодинг в json и внесены другие мелкие изменения.
Как сделать поля обязательными в proto 3
Чтобы сделать поля обязательными, можно использовать Well-known типы данных. Это может быть строка, булево значение, число, timestamp и тому подобное.


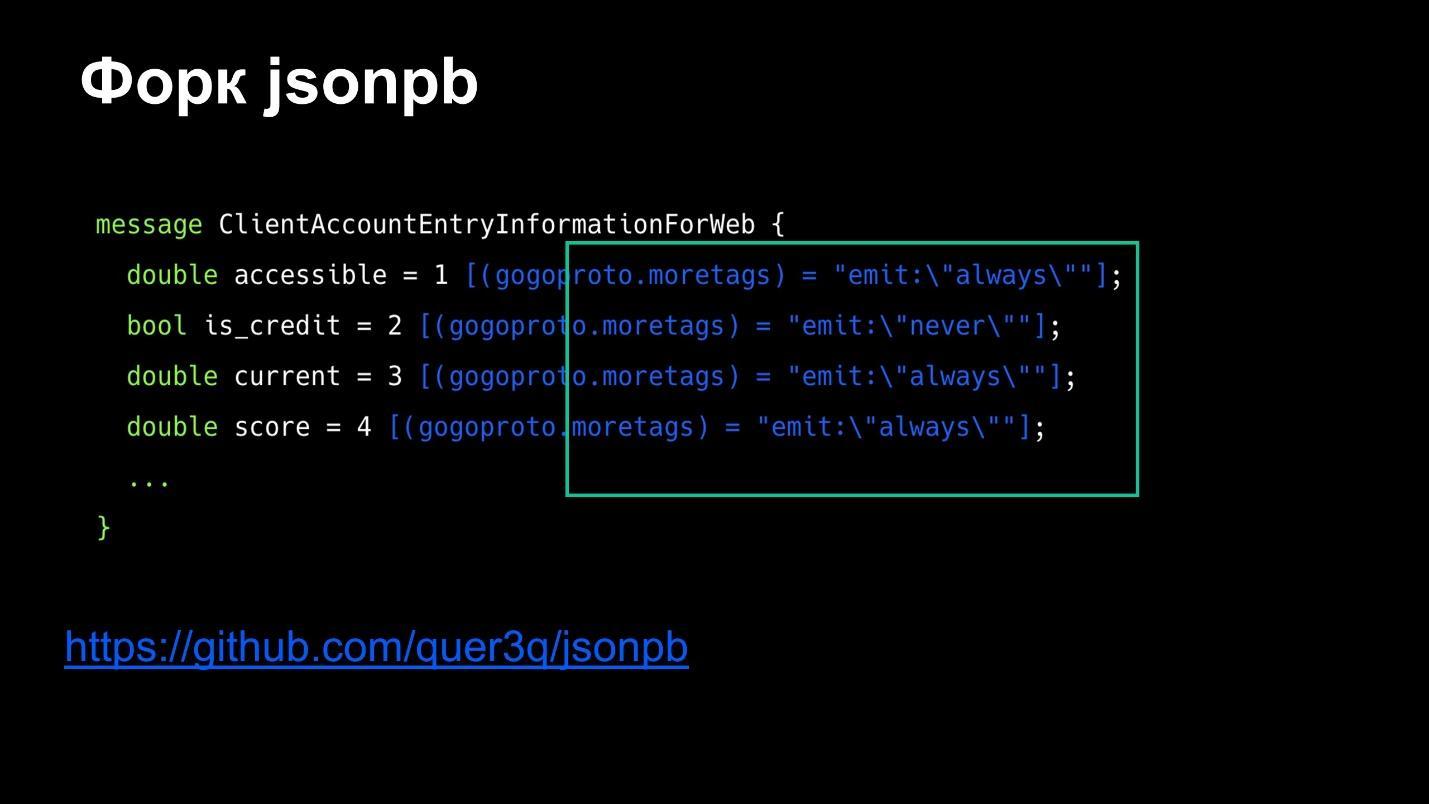
Как проверить, что новые изменения не ломают контракты?
Теперь понятно, как можно сделать поля обязательными, но что делать, если вдруг поле перестало быть обязательным или произошло что-то еще?
Для этого есть несколько инструментов для валидации proto-файлов, например buf.build и uber/prototool.
Оба инструмента работают по схожей схеме: чтобы запустить валидацию, создайте yaml-файл, в нем укажите конфигурацию, какие proto-файлы надо проверить, а какие нет. Также можно указать, какую ветку из репозитория брать. В обоих случаях работа идет только с git.
uber/protool пока не поддерживает apiv2, поэтому стоит приглядеться внимательнее к buf.build.
Что такое apiv2?
Поддержка работы с protobuf в Go впервые была анонсирована в 2010 году, первая версия Go вышла только спустя два года. С тех пор прошло много времени, изменились требования.
В итоге, несколько месяцев назад, 2 марта 2020 года, была анонсирована apiv2. Вот что изменилось по сравнению с прошлой версией:
- появилась рефлексия для proto.Message;
- канонический маппинг для json-полей;
- улучшение производительности;
- не получится использовать старые плагины и инструменты.
Давайте рассмотрим пример того, что теперь можно сделать из коробки. Есть api, возвращающее данные, которые мы не хотим показывать в логах (например, пароли пользователей, номера банковских карт и т.п.).

Для этого подключаем специальный пакет google.protobuf.FieldOptions и сразу добавляем флаг non_sensitive . Он будет отвечать за то, нужно ли маскировать данные внутри ответа. Выставим по умолчанию значение false (привет, proto2).
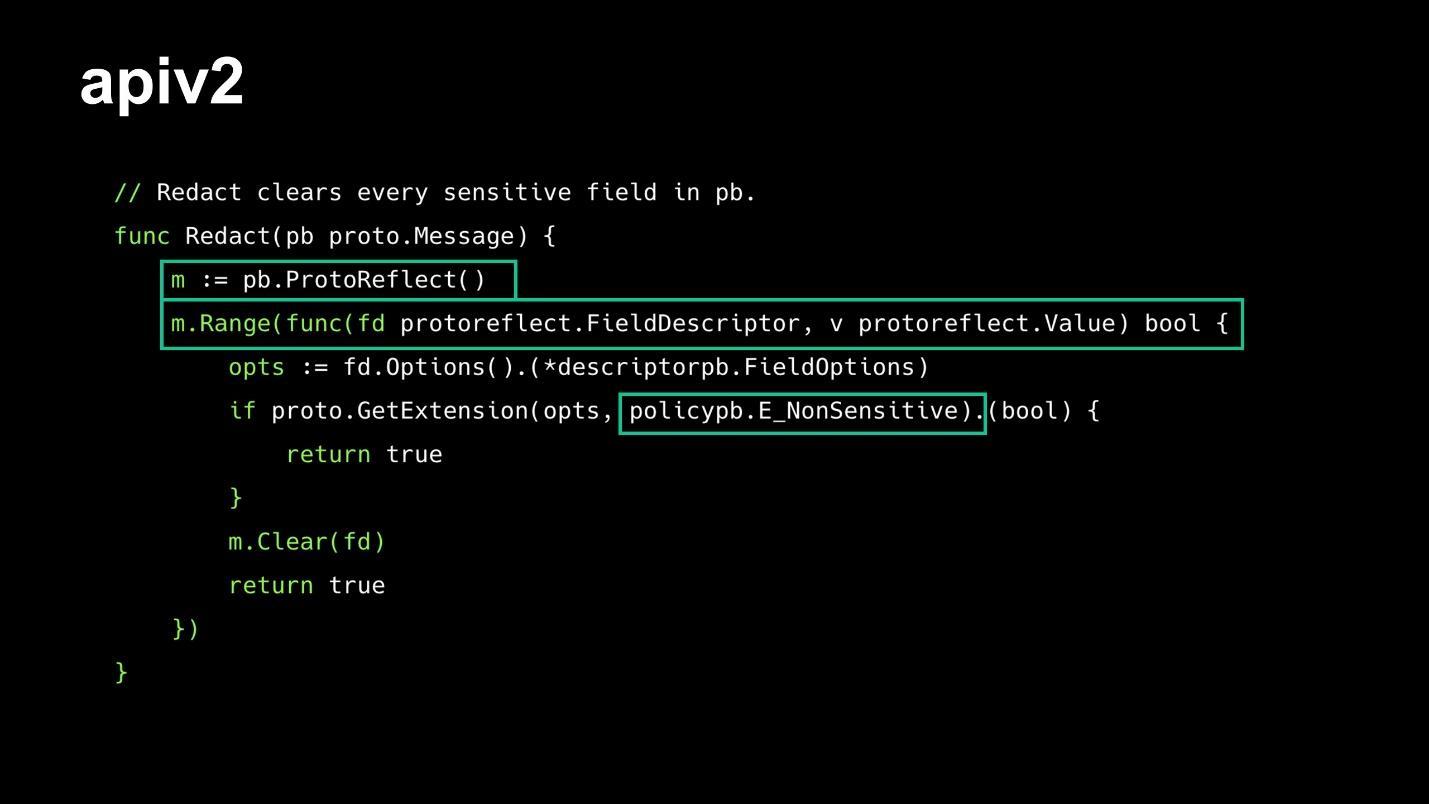
Подключаем новый интерфейс — ProtoReflect() и используем функцию Range() .
Таким образом проходимся по все кастомным полям и проверяем значение non_sensitive поля (конечно же, используя рефлексию). Как только находим поле, в котором нужно убрать данные, вызываем Clear() .
Читайте также: