
Как создать хеш таблицу python
Обновлено: 07.07.2024
В этой статье будет продемонстрировано, как использовать хеш MD5 с помощью модуля Python hashlib .
Что такое хеш?
Хеш - это функция, которая принимает данные переменной длины и преобразует их в фиксированную длину. Значение, возвращаемое хеш-функцией, называется хеш-значением, хеш-кодом или дайджестом. Хеш-значения обычно используются для индексации таблицы фиксированного размера, называемой хеш-таблицей.
Что такое MD5?
Модуль Python hashlib
Чтобы использовать алгоритмы хеширования, импортируйте модуль hashlib .
Теперь мы можем использовать алгоритмы хеширования, поддерживаемые этим модулем. Чтобы проверить доступные хеш-алгоритмы в работающем интерпретаторе Python, используйте постоянный атрибут algorithmms_available .
В списке выше представлены доступные алгоритмы в hashlib , включая доступные алгоритмы OpenSSL.
Чтобы проверить, какие алгоритмы хеширования гарантированно поддерживаются этим модулем на всех платформах, используйте постоянный атрибут algorithmms_guaranteed .
Примечание: md5 находится в списке алгоритмов_гарантия , но некоторые совместимые с FIPS поставщики апстрима предлагают сборку Python, исключающую его.
Используйте алгоритм MD5 в Python
Чтобы использовать алгоритм md5, мы воспользуемся конструктором md5() и загрузим хэш-объект байтовыми объектами с помощью метода update() или передадим данные в качестве параметра конструктора.
Для получения хеш-значения используйте метод digest() , который возвращает байтовый дайджест данных, переданных в хеш-объект.
Вы также можете передать данные в качестве параметра конструктору и получить хеш-значение.
Подобно методу digest() , вы также можете использовать hexdigest() , который возвращает строковый объект дайджеста, содержащий только шестнадцатеричные цифры.
Обратите внимание, что перед строковым литералом, переданным в метод update() , стоит буква b . Используется для создания экземпляра типа bytes вместо типа str . Поскольку функция хеширования принимает в качестве параметра только последовательность байтов. Передача строковых объектов в метод update() не поддерживается.
Вы также можете выполнить несколько вызовов метода update() , что эквивалентно одному вызову со всеми объединенными аргументами.
Таким образом, мы можем использовать алгоритм хеширования md5 через модуль hashlib , в который можно загружать данные, передавая их в качестве параметра конструктора md5() или используя метод update() . Мы можем получить хеш-значение с помощью метода digest() , который возвращает объект bytes метода digest() или hexdigest() , который возвращает строковый объект дайджеста, содержащий только шестнадцатеричные цифры.
В хэш-таблице обработка новых индексов производится при помощи ключей. А элементы, связанные с этим ключом, сохраняются в индексе. Этот процесс называется хэшированием.
Пусть k — ключ, а h(x) — хэш-функция.
Тогда h(k) в результате даст индекс, в котором мы будем хранить элемент, связанный с k .
Коллизии
Когда хэш-функция генерирует один индекс для нескольких ключей, возникает конфликт (неизвестно, какое значение нужно сохранить в этом индексе). Это называется коллизией хэш-таблицы.
Есть несколько методов борьбы с коллизиями:
- Метод цепочек.
- Метод открытой адресации: линейное и квадратичное зондирование.
1. Метод цепочек
Суть этого метода проста: если хэш-функция выделяет один индекс сразу двум элементам, то храниться они будут в одном и том же индексе, но уже с помощью двусвязного списка.
Если j — ячейка для нескольких элементов, то она содержит указатель на первый элемент списка. Если же j пуста, то она содержит NIL .
Псевдокод операций
2. Открытая адресация
В отличие от метода цепочек, в открытой адресации несколько элементов в одной ячейке храниться не могут. Суть этого метода заключается в том, что каждая ячейка либо содержит единственный ключ, либо NIL .
Существует несколько видов открытой адресации:
a) Линейное зондирование
Линейное зондирование решает проблему коллизий с помощью проверки следующей ячейки.
h(k, i) = (h′(k) + i) mod m ,
Если коллизия происходит в h(k, 0) , тогда проверяется h(k, 1) . То есть, значение i увеличивается линейно.
Проблема линейного зондирования заключается в том, что заполняется кластер соседних ячеек. Это приводит к тому, что при вставке нового элемента в хэш-таблицу необходимо проводить полный обход кластера. В результате время выполнения операций с хэш-таблицами увеличивается.
b) Квадратичное зондирование
Работает оно так же, как и линейное — но есть отличие. Оно заключается в том, что расстояние между соседними ячейками больше (больше одного). Это возможно благодаря следующему отношению:
- c1 и c2 — положительные вспомогательные константы,
- i =
c) Двойное хэширование
Если коллизия возникает после применения хэш-функции h(k) , то для поиска следующей ячейки вычисляется другая хэш-функция.
h(k, i) = (h1(k) + ih2(k)) mod m
«Хорошие» хэш-функции
«Хорошие» хэш-функции не уберегут вас от коллизий, но, по крайней мере, сократят их количество.
Ниже мы рассмотрим различные методы определения «качества» хэш-функций.
1. Метод деления
Если k — ключ, а m — размер хэш-таблицы, то хэш-функция h() вычисляется следующим образом:
Например, если m = 10 и k = 112 , то h(k) = 112 mod 10 = 2 . То есть, значение m не должно быть степенью 2. Это связано с тем, что степени двойки в двоичном формате — 10, 100, 1000… При вычислении k mod m мы всегда будем получать p-биты низшего порядка.
2. Метод умножения
- kA mod 1 отделяет дробную часть kA ,
- ⌊ ⌋ округляет значение
- A — произвольная константа, значение которой должно находиться между 0 и 1. Оптимальный вариант ≈ (√5-1) / 2, его предложил Дональд Кнут.
3. Универсальное хеширование
В универсальном хешировании хеш-функция выбирается случайным образом и не зависит от ключей.
Хеш-таблица Python, метод адресации цепочки, разрешение конфликтов, добавление метода остатка, вставка хэша, удаление, операция поиска (подробные примечания)
Хеширование - более важный контент в структуре данных. Хотя метод адресации цепочки, один из двух основных методов, немного громоздок, идея проще, а процесс понятен.
Хеш-таблица (хеш-таблица, также называемая хеш-таблицей) - это структура данных, к которой осуществляется прямой доступ на основе значения ключа. Другими словами, он обращается к записи, сопоставляя значение кода клавиши с положением в таблице, чтобы ускорить поиск. Эта функция отображения называется хеш-функцией, а записанный массив - хеш-таблицей.
Хеш-функция: метод остатка (возьмите остаток после деления ключа на число p, не превышающее длину хеш-таблицы m в качестве хеш-адреса), чтобы установить хеш-таблицу и определить, находится ли данное значение в хеш-таблице .
Этот код использует метод конфликта цепочки для разрешения конфликтов, то есть после хеширования по одному и тому же адресу конфликт элементов разрешается путем создания субцепи, поэтому он не учитывает переполнение всего элемента, превышающего размер хеш-таблицы. Сохраняется только один повторяющийся элемент.
войти
Первая строка чисел указывает размер создаваемой хэш-таблицы, а вторая строка указывает последовательность целых чисел, которые будут использоваться в качестве элементов для создания хэш-таблицы (примечание: элементы разделены пробелами, а первая строка разбросана Размер списка не указывает количество элементов в этой строке), третья строка указывает количество элементов, которые должны быть вставлены n, следующие n строк указывают значение элементов, которые должны быть вставлены; следующая строка указывает количество элементов, которые необходимо удалить, m, а следующая строка m указывает количество элементов, которые должны быть удалены Значение элемента; следующая строка указывает количество элементов, которые необходимо найти r, а следующая строка r указывает значение элемента, которое необходимо найти.
Вывод
Вставка не имеет вывода. Для каждого удаляемого элемента, если элемент находится в хеш-таблице, удалите его, если нет, выведите «Удалить ошибку», обратите внимание на пробел между словами; вставьте и удалите после выполнения После этого узнать, есть ли элемент в хеш-таблице, если есть, вывести True в соответствующей строке, иначе вывести False.
Решая реальные проблемы кодирования, работодатели и рекрутеры стремятся как к эффективности времени выполнения, так и к ресурсоэффективности.
Знание того, какая структура данных лучше всего подходит для текущего решения, повысит производительность программы и сократит время, необходимое для её создания. По этой причине большинству ведущих компаний требуется чёткое понимание структур данных и их тщательное тестирование на собеседовании по кодированию.
Что такое структуры данных?
Структуры данных — это структуры кода для хранения и организации данных, которые упрощают изменение, навигацию и доступ к информации. Структуры данных определяют способ сбора данных, функциональные возможности, которые мы можем реализовать, и отношения между данными.
Структуры данных используются практически во всех областях информатики и программирования, от операционных систем до интерфейсной разработки и машинного обучения.
Структуры данных помогают:
- Управляйте большими наборами данных и используйте их.
- Быстрый поиск определённых данных в базе данных.
- Создавайте чёткие иерархические или реляционные связи между точками данных.
- Упростите и ускорьте обработку данных.
Структуры данных являются жизненно важными строительными блоками для эффективного решения реальных проблем. Структуры данных — это проверенные и оптимизированные инструменты, которые дают вам удобную основу для организации ваших программ. В конце концов, вам не нужно переделывать колесо (или конструкцию) каждый раз, когда это нужно.
У каждой структуры данных есть задача или ситуация, для решения которой она наиболее подходит. Python имеет 4 встроенных структуры данных, списки, словари, кортежи и наборы. Эти встроенные структуры данных поставляются с методами по умолчанию и негласной оптимизацией, которая упрощает их использование.
Большинство структур данных в Python являются их модифицированными формами или используют встроенные структуры в качестве основы.
- Список: структуры, похожие на массивы, которые позволяют сохранять набор изменяемых объектов одного и того же типа в переменную.
- Кортеж: кортежи — это неизменяемые списки, то есть элементы не могут быть изменены. Он объявлен в круглых скобках вместо квадратных.
- Набор: наборы — это неупорядоченные коллекции, что означает, что элементы неиндексированы и не имеют установленной последовательности. Они объявляются фигурными скобками.
- Словарь (dict): Подобно хэш-карте или хеш-таблицам на других языках, словарь представляет собой набор пар ключ / значение. Вы инициализируете пустой словарь пустыми фигурными скобками и заполняете его ключами и значениями, разделёнными двоеточиями. Все ключи — уникальные неизменяемые объекты.
Теперь давайте посмотрим, как мы можем использовать эти структуры для создания всех сложных структур, которые ищут интервьюеры.
Массивы (списки) в Python
Python не имеет встроенного типа массива, но вы можете использовать списки для всех тех же задач. Массив — это набор значений одного типа, сохранённых под тем же именем.
Каждое значение в массиве называется «элементом», и индексирование соответствует его положению. Вы можете получить доступ к определённым элементам, вызвав имя массива с индексом желаемого элемента. Вы также можете получить длину массива с помощью len()метода.
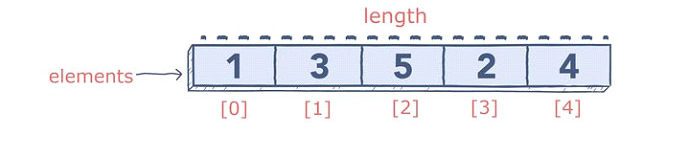
В отличие от языков программирования, таких как Java, которые имеют статические массивы после объявления, массивы Python автоматически увеличиваются или уменьшаются при добавлении / вычитании элементов.
Например, мы могли бы использовать этот append()метод для добавления дополнительного элемента в конец существующего массива вместо объявления нового массива.
Это делает массивы Python особенно простыми в использовании и адаптируемыми на лету.
hash() в Python – одна из встроенных функций. Сегодня мы рассмотрим использование функции hash() и то, как мы можем переопределить ее для нашего настраиваемого объекта.
Что такое hash() в Python?
hash() в Python – это целое число фиксированного размера, которое идентифицирует конкретное значение.
Отметим, что может означать:
- Одинаковые данные будут иметь одинаковое хеш-значение.
- Даже небольшое изменение исходных данных может привести к совершенно иному хеш-значению.
- Хеш получается из хеш-функции, в обязанности которой входит преобразование данной информации в закодированный хеш.
- Очевидно, что количество объектов может быть намного больше, чем количество хеш-значений, и поэтому два объекта могут хешировать одно и то же. Это называется конфликтом хэша. Это означает, что если два объекта имеют одинаковый хэш-код, они не обязательно имеют одно и то же значение.
Что такое хеш-функция?
Мы можем более подробно рассказать о хешировании, но здесь стоит упомянуть важный момент, касающийся создания функции хорошего хеширования:
- Помимо приведенного выше определения, хеш-значение объекта должно быть простым для вычисления с точки зрения пространства и сложности памяти.
- Хеш-коды чаще всего используются при сравнении ключей словаря. Хэш-код ключей словаря сравнивается при поиске определенного ключа. Сравнение хеш-значений происходит намного быстрее, чем сравнение полных значений ключей, потому что набор целых чисел, которым хеш-функция сопоставляет каждый ключ словаря, намного меньше, чем сам набор объектов.
Также обратите внимание, что если два числовых значения могут сравниваться как равные, они также будут иметь одинаковый хэш, даже если они принадлежат к разным типам данных, например 1 и 1.0.
String hash
Давайте начнем создавать простые примеры и скрипты, в которых функция hash() может быть очень полезной. В этом примере мы просто получим хеш-значение String.
При запуске этого скрипта мы получим следующий результат:

Если вы снова запустите тот же скрипт, хеш изменится, как показано ниже:

Таким образом, срок жизни хэша зависит только от области действия программы, и он может измениться, как только программа завершится.
Хеш с небольшим изменением данных
Здесь мы увидим, как небольшое изменение данных может изменить хеш-значение. Он изменится полностью или немного? Лучше всего узнать через скрипт:
Теперь запустим этот скрипт:

Посмотрите, как полностью изменился хеш, когда в исходных данных изменился только один символ. Это делает значение хеш-функции совершенно непредсказуемым.
Как определить функцию hash() для пользовательских объектов?
Внутренне функция hash() работает, переопределяя функцию __hash __(). Стоит отметить, что не каждый объект может быть хеширован (изменяемые коллекции не хешируются). Мы также можем определить эту функцию для нашего пользовательского класса. Собственно, этим и займемся сейчас. Перед этим отметим несколько важных моментов:
- Реализация Hashable не должна выполняться для изменяемых коллекций, поскольку ключи должны быть неизменными для хеширования.
- Нам не нужно определять пользовательскую реализацию функции __eq __(), поскольку она определена для всех объектов.
Теперь давайте определим объект и переопределим функцию __hash __():
Теперь запустим этот скрипт:

Эта программа фактически описывала, как мы можем переопределить функции __eq __() и __hash __(). Таким образом, мы можем определить нашу собственную логику для сравнения любых объектов.
Почему изменяемые объекты нельзя хэшировать?
Как мы уже знаем, хешировать можно только неизменяемые объекты. Это ограничение, запрещающее хеширование изменяемого объекта, значительно упрощает хеш-таблицу. Давайте разберемся как.
Если разрешено хеширование изменяемого объекта, нам нужно обновлять хеш-таблицу каждый раз, когда обновляется значение объектов. Это означает, что нам придется переместить объект в совершенно другое место.
В Python у нас есть два объекта, которые используют хеш-таблицы, словари и наборы:
Читайте также: