
Как вычислить процент сжатия файла относительно исходного
Обновлено: 04.07.2024
Цель: изучение принципов архивации файлов, функций и режимов работы архиватора WinRar, приобретение практических навыков работы по созданию архивных файлов и извлечению файлов из архивов, определение процента сжатия файлов.
При выполнении работы должны соблюдаться правила ТБ при работе за ПК и правила поведения в компьютерном классе.
Выполнение работы:
Создайте на диске Е: папку с номером группы. В этой рабочей папке вы будете хранить все свои практические работы.
В рабочей папке создайте папку Архивы-Фамилии . (укажите в имени папки ваши настоящие фамилии).
В отдельном окне откройте папку ДЛЯ ПРАКТИКИ, которая находится на диске Е:
В папке ДЛЯ ПРАКТИКИ найдите текстовые файлы с расширениями *.doc и . txt и скопируйте их в свою рабочую папку. Запишите исходные размеры файлов в таблицу (смотри ниже).
В папке ДЛЯ ПРАКТИКИ найдите файл-электронную таблицу *. xls и скопируйте его в свою рабочую папку. Запишите исходный размер файла в таблицу.
В отдельном окне откройте в папке ДЛЯ ПРАКТИКИ папку КОМПЛЕКТУЮЩИЕ.
Найдите в этой папке и скопируйте в свою рабочую папку рисунки с расширениями * .jpg и * .bmp
Сравните размеры файлов *.bmp и *.jpg и запишите данные в таблицу.
Оформите данную таблицу в тетради для практических работ.
Вместо знака * запишите настоящее имя копируемого вами файла.
Текстовые файлы:
Графические файлы:
Процент сжатия текстовой информации (для всех файлов)
Процент сжатия графической информации (для всех файлов)
Задание №2. Создание архива с помощью программы WinRar.
Откройте свою рабочую папку Архивы-Фамилии .
Выделите файл, который будете упаковывать, например, с расширением . txt .
В контекстном меню выделенного объекта выберите пункт Добавить в архив…
Не меняя имени архива, установите Формат архива : RAR (вкладка Общие )
Выберите Метод сжатия: максимальный
Запустите процесс архивации щелчком по кнопке ОК . Созданный архив будет помещен в вашу рабочую папку, где находятся неупакованные исходные файлы.
Повторите архивирование этого же файла , но теперь установите Формат архива : ZIP .
Сравнительные характеристики созданных архивов занесите в таблицу.
Аналогичным образом создайте по два архива для остальных файлов *. doc , *. xls , * .jpg , *. bmp . Сравнительные характеристики созданных архивов занесите в таблицу.
Чтобы архивировать несколько файлов в один архив, их нужно предварительно выделить , удерживая нажатой кнопку Ctrl на клавиатуре, а затем выполнить архивирование.
Заархивируйте все текстовые файлы в один архив с именем Текст.rar
Заархивируйте все графические файлы в один архив с именем Графика.rar
Заархивируйте все текстовые файлы в один архив с именем Текст.zip
Заархивируйте все графические файлы в один архив с именем Графика.zip
Сравнительные характеристики созданных архивов занесите в таблицу.
Задание №3. Определите процент сжатия файлов
Процент сжатия определяется по формуле
где S – размер архивных файлов, S o – размер исходных файлов.
Полученные вычисления запишите в таблицу.
Задание №4. Извлечение файлов из архива
Запустите программу WinRar двойным щелчком левой кнопкой мыши по архиву Текст.rar . В появившемся окне отражен список файлов, содержащихся в архиве.
Выделите один файл из списка.
Нажмите на панели инструментов кнопку Извлечь в… и укажите место для записи данных – ваша рабочая папка.
Установите Режим обновления файлов – Извлечь с заменой файлов .
Во вкладке Дополнительно установите переключатель Не удалять. Для того, чтобы полностью распакованный архив не занимал место на винчестере, выбирают переключатель Удалять всегда .
Результат работы продемонстрируйте преподавателю.
Теоретические сведения к практической работе :
Работа с архивами данных
Архивация (упаковка) - помещение (загрузка) исходных файлов в архивный файл в сжатом или несжатом виде.
Архивация предназначена для создания резервных копий используемых файлов, на случай потери или порчи по каким-либо причинам основной копии (невнимательность пользователя, повреждение магнитного диска, заражение вирусом и т.д.).
Для архивации используются специальные программы, архиваторы, осуществляющие упаковку и позволяющие уменьшать размер архива, по сравнению с оригиналом, примерно в два и более раз.
Архиваторы позволяют защищать созданные ими архивы паролем, сохранять и восстанавливать структуру подкаталогов, записывать большой архивный файл на несколько дисков (многотомный архив).
Сжиматься могут как один, так и несколько файлов, которые в сжатом виде помещаются в так называемый архивный файл или архив. Программы большого объема, распространяемые на дискетах, также находятся на них в виде архивов.
Архивный файл - это специальным образом организованный файл, содержащий в себе один или несколько файлов в сжатом или несжатом виде и служебную информацию об именах файлов, дате и времени их создания или модификации.
Выигрыш в размере архива достигается за счет замены часто встречающихся в файле последовательностей кодов на ссылки к первой обнаруженной последовательности и использования алгоритмов сжатия информации.
Степень сжатия зависит от используемой программы, метода сжатия и типа исходного файла. Наиболее хорошо сжимаются файлы графических образов, текстовые файлы и файлы данных, для которых степень сжатия может достигать 5-40%, меньше сжимаются файлы исполняемых программ и загрузочных модулей — 60-90%. Почти не сжимаются архивные файлы. Программы для архивации отличаются используемыми методами сжатия, что соответственно влияет на степень сжатия.
Для того чтобы воспользоваться информацией, запакованной в архив, необходимо архив раскрыть или распаковать. Это делается либо той же программой-архиватором, либо парной к ней программой-разархиватором.
Разархивация (распаковка) - процесс восстановления файлов из архива в первоначальном виде. При распаковке файлы извлекаются из архива и помещаются на диск или в оперативную память.
Самораспаковывающийся архивный файл — это загрузочный, исполняемый модуль, который способен к самостоятельной разархивации находящихся в нем файлов без использования программы-архиватора.
Самораспаковывающийся архив получил название SFX-архив (SelF-eXtracting). Архивы такого типа в обычно создаются в форме .ЕХЕ-файла.
Архиваторы, служащие для сжатия и хранения информации, обеспечивают представление в едином архивном файле одного или нескольких файлов, каждый из которых может быть при необходимости извлечен в первоначальном виде. В оглавлении архивного файла для каждого содержащегося в нем файла хранится следующая информация:
сведения о каталоге, в котором содержится файл;
дата и время последней модификации файла;
размер файла на диске и в архиве;
код циклического контроля для каждого файла, используемый для проверки целостности архива.
При создании нового архива нужно задать параметры архивирования. Прежде всего, необходимо задать имя архивного файла и место его сохранения на диске. Далее, нужно выбрать формат архивации RAR или ZIP (формат ZIP более широко распространен, а метод RAR обеспечивает больше возможностей и более сильное сжатие).
В обоих форматах поддерживаются шесть методов архивации: Без сжатия, Скоростной, Быстрый, Обычный, Хороший и Максимальный. Максимальный метод обеспечивает наиболее высокую степень сжатия, но с наименьшей скоростью. Напротив, Скоростной сжимает плохо, но очень быстро. Метод Без сжатия просто помещает файлы в архив без их упаковки. Если вы создаете архив для передачи по компьютерным сетям или для долговременного хранения, имеет смысл выбрать метод Максимальный для получения наилучшего сжатия. Если же вы создаете ежедневную резервную копию данных, то, как правило, лучше использовать Обычный метод.
WinRAR позволяет создавать многотомные архивы, то есть архивы, состоящие из нескольких частей. Обычно тома используются для сохранения большого архива на нескольких дискетах или других сменных носителях. Первый том архива имеет обычное расширение гаг, а расширения последующих томов нумеруются как r00, r01, r02 и так далее.
Архив может быть непрерывным (позволяет добиться максимальной степени сжатия) и самораспаковывающимся (SFX, от англ. Self-eXtracting). Для разархивации такого архива не нужна специальная программа, достаточно запустить файл архива на выполнение, так как он является исполняемым файлом и имеет расширение .exe.
Для архивации звуковых и графических файлов может использоваться дополнительный специальный метод мультимедиа сжатие , при котором может быть достигнута на 30% более высокая степень сжатия, чем при обычном сжатии.
В данной статье я расскажу вам о широко известном алгоритме Хаффмана, и вы наконец разберетесь, как все там устроено изнутри. После прочтения вы сможете своими руками(а главное, головой) написать архиватор, сжимающий реальные, черт подери, данные! Кто знает, быть может именно вам светит стать следующим Ричардом Хендриксом!
Да-да, об этом уже была статья на Хабре, но без практической реализации. Здесь же мы сфокусируемся как на теоретической части, так и на программерской. Итак, все под кат!
Немного размышлений
В обычном текстовом файле один символ кодируется 8 битами(кодировка ASCII) или 16(кодировка Unicode). Далее будем рассматривать кодировку ASCII. Для примера возьмем строку s1 = «SUSIE SAYS IT IS EASY\n». Всего в строке 22 символа, естественно, включая пробелы и символ перехода на новую строку — '\n'. Файл, содержащий данную строку будет весить 22*8 = 176 бит. Сразу же встает вопрос: рационально ли использовать все 8 бит для кодировки 1 символа? Мы ведь используем не все символы кодировки ASCII. Даже если бы и использовали, рациональней было бы самой частой букве — S — дать самый короткий возможный код, а для самой редкой букве — T (или U, или '\n') — дать код подлиннее. В этом и заключается алгоритм Хаффмана: необходимо найти оптимальный вариант кодировки, при котором файл будет минимального веса. Вполне нормально, что у разных символов длины кода будут отличаться — на этом и основан алгоритм.
Кодирование
Ни один код не должен быть префиксом другого
Это правило является ключевым в алгоритме. Поэтому создание кода начинается с частотной таблицы, в которой указана частота (количество вхождений) каждого символа:

Символы с наибольшим количеством вхождений должны кодироваться наименьшим возможным количеством битов. Приведу пример одной из возможных таблиц кодов:

Код каждого символа я разделил пробелом. По-настоящему в сжатом файле такого не будет!
Вытекает вопрос: как этот салага придумал код как создать таблицу кодов? Об этом пойдет речь ниже.
Построение дерева Хаффмана
Здесь приходят на выручку бинарные деревья поиска. Не волнуйтесь, здесь методы поиска, вставки и удаления не потребуются. Вот структура дерева на java:
Это не полный код, полный код будет ниже.
Вот сам алгоритм построения дерева:
- Извлечь два дерева из приоритетной очереди и сделать их потомками нового узла (только что созданного узла без буквы). Частота нового узла равна сумме частот двух деревьев-потомков.
- Для этого узла создать дерево с корнем в данном узле. Вставить это дерево обратно в приоритетную очередь. (Так как у дерева новая частота, то скорее всего она встанет на новое место в очереди)
- Продолжать выполнение шагов 1 и 2, пока в очереди не останется одно дерево — дерево Хаффмана

Здесь символ «lf»(linefeed) обозначает переход на новую строку, «sp» (space) — это пробел.
А что дальше?
Мы получили дерево Хаффмана. Ну окей. И что с ним делать? Его и за бесплатно не возьмут А далее, нужно отследить все возможные пути от корня до листов дерева. Условимся обозначить ребро 0, если оно ведет к левому потомку и 1 — если к правому. Строго говоря, в данных обозначениях, код символа — это путь от корня дерева до листа, содержащего этот самый символ.

Таким макаром и получилась таблица кодов. Заметим, что если рассмотреть эту таблицу, то можно сделать вывод о «весе» каждого символа — это длина его кода. Тогда в сжатом виде исходный файл будет весить: 2 * 3 + 2*4 + 3 * 3 + 6 * 2 + 1 * 4 + 1 * 5 + 2 * 4 + 4 * 2 + 1 * 5 = 65 бит. Вначале он весил 176 бит. Следовательно, мы уменьшили его аж в 176/65 = 2.7 раза! Но это утопия. Такой коэффициент вряд ли будет получен. Почему? Об этом пойдет речь чуть позже.
Декодирование
Ну, пожалуй, осталось самое простое — декодирование. Я думаю, многие из вас догадались, что просто создать сжатый файл без каких-либо намеков на то, как он был закодирован, нельзя — мы не сможем его декодировать! Да-да, мне было тяжело это осознать, но придется создать текстовый файл table.txt с таблицей сжатия:
Запись таблицы в виде 'символ'«код символа». Почему 01110 без символа? На самом деле он с символом, просто средства java, используемые мной при выводе в файл, символ перехода на новую строку — '\n' -конвертируют в переход на новую строку(как бы это глупо не звучало). Поэтому пустая строка сверху и есть символ для кода 01110. Для кода 00 символом является пробел в начале строки. Сразу скажу, что нашему коэффициенту ханаэтот способ хранения таблицы может претендовать на самый нерациональный. Но он прост для понимания и реализации. С удовольствием выслушаю Ваши рекомендации в комментариях по поводу оптимизации.
Имея эту таблицу, очень просто декодировать. Вспомним, каким правилом мы руководствовались, при создании кодировки:
Ни один код не должен являться префиксом другого
Реализация
Пришло время унижать мой код писать архиватор. Назовем его Compressor.
Начнем с начала. Первым делом пишем класс Node:
Класс, создающий дерево Хаффмана:
Класс, облегчающий чтение из файла:
Ну, и главный класс:
Файл с инструкциями readme.txt предстоит вам написать самим :-)
Заключение
Наверное, это все что я хотел сказать. Если у вас есть что сказать по поводу моей некомпетентности улучшений в коде, алгоритме, вообще любой оптимизации, то смело пишите. Если я что-то недообъяснил, тоже пишите. Буду рад услышать вас в комментариях!
Да-да, я все еще здесь, ведь я не забыл про коэффициент. Для строки s1 кодировочная таблица весит 48 байт — намного больше исходного файла, да и про добавочные нули не забыли(количество добавленных нулей равно 7)=> коэффициент сжатия будет меньше единицы: 176/(65 + 48*8 + 7)=0.38. Если вы тоже это заметили, то только не по лицу вы молодец. Да, эта реализация будет крайне неэффективной для малых файлов. Но что же происходит с большими файлами? Размеры файла намного превышают размер кодировочной таблицы. Вот здесь-то алгоритм работает как-надо! Например, для монолога Фауста архиватор выдает реальный (не идеализированный) коэффициент, равный 1.46 — почти в полтора раза! И да, предполагалось, что файл будет на английском языке.
Выпустил upgrade: добавил GUI + изменил алгоритм обработки исходного текста так, чтобы не читать весь файл в память. Короче, кидаю ссылку на git для любознательных: сами всё увидите.
Благодарности
Как и автор каждой хорошей книги, я созидал эту статью не без помощи других людей. Имхо, очень мало людей сделало что-то крутое в одиночку.
Огромное спасибо Исаеву Виталию Вячеславовичу за небходимую теоретическую поддержку.
Также, часть материала этой статьи взята из книги Роберта Лафоре «Data Structures and Algorithms in Java». Если сомневаетесь как или окуда начать свой путь в теории алгоритмов и структур данных — берите, не прогадаете.
Есть ли способ получить возможную степень сжатия файла, просто прочитав его?
Вы знаете, некоторые файлы более сжимаемы, чем другие. мое программное обеспечение должно сказать мне процент возможного сжатия моих файлов.
напр.
Compression Ratio: 50% - > я могу сохранить 50% пространства моего файла, если я сжимаю его
Compression Ratio: 99% - > я могу сохранить только 1% пространства моего файла, если я сжимаю его
3 ответа
У меня есть файл XML формата .zfo , который сжимается с помощью алгоритма zip. Мне нужно удалить это сжатие из файла, чтобы он был в пригодной для использования форме XML. Вот досье . Как я могу удалить это сжатие или распаковать этот файл XML? Это не так, как вы могли бы себе представить.
Во-первых, это будет во многом зависеть от выбранного вами метода сжатия. И во-вторых, я серьезно сомневаюсь, что это возможно без вычисления сложности времени и пространства, сравнимой с фактическим сжатием. Я бы сказал, что лучше всего сжать файл, отслеживая размер того, что вы уже создали, и отбрасывая/освобождая его (как только вы закончите с ним, очевидно), вместо того, чтобы записывать его.
Чтобы действительно сделать это, если вы действительно не хотите реализовать его самостоятельно, вероятно, будет проще всего использовать класс java.util.zip, в частности класс Deflater и его метод deflate .
Невозможно без изучения файла. Единственное, что вы можете сделать, это получить приблизительное соотношение по расширению файла, основанное на статистике, собранной из относительно большой выборки, путем фактического сжатия и измерения. Например, статистический анализ, скорее всего, покажет, что .zip, .jpg не являются сильно сжимаемыми, но такие файлы, как .txt и .doc, могут быть сильно сжимаемыми.
Результаты этого будут только для приблизительного руководства и, вероятно, в некоторых случаях будут далеки, поскольку нет абсолютно никакой гарантии сжимаемости по расширению файла. Файл может содержать все, что угодно, независимо от того, какое расширение говорит, что это может быть или не быть.
UPDATE: Предполагая, что вы можете изучить файл, вы можете использовать java.util.zip APIs, чтобы прочитать необработанный файл, сжать его и посмотреть, в чем разница между " до " и "после".
Во-первых, вам нужно поработать над теорией информации. Существует две теории о поле теории информации:
- Согласно Шеннону, можно вычислить энтропию (т. е. сжатый размер) источника, используя его вероятности символов. Таким образом, наименьший размер сжатия определяется статистической моделью, которая создает вероятности символов на каждом шаге. Все алгоритмы используют этот подход неявно или явно для сжатия данных. Посмотрите эту статью в Википедии для получения более подробной информации.
- Согласно Колмогорову, наименьший размер сжатия можно найти, найдя наименьшую возможную программу, которая создает исходный код. В этом смысле он не может быть вычисляемым. Некоторые программы частично используют этот подход для сжатия данных (например, вы можете написать небольшое консольное приложение, которое может выдавать 1 миллион цифр PI вместо того, чтобы сжать этот 1 миллион цифр PI).
Таким образом, вы не можете найти сжатый размер без оценки фактического сжатия. Но если вам нужно приближение, вы можете положиться на теорию энтропии Шеннона и построить простую статистическую модель. Вот очень простое решение:
- Вычислите статистику порядка 1 для каждого символа в исходном файле.
- Вычислите энтропию, используя эти статистические данные.
Ваша оценка будет более или менее такой же, как алгоритм сжатия по умолчанию ZIP (deflate). Вот более продвинутая версия той же идеи (имейте в виду, что она использует много памяти!). Он фактически использует энтропию для определения границ блоков, чтобы применить сегментацию для разделения файла на однородные данные.
У меня есть тензор A в numpy, который равен N1 x .. x Nn x M1 x . x Mm , и тензор B , который равен M1 x . x Mm . Как вычислить тензорное сжатие C из A и B , которое должно быть N1 x . x Nn? я пробовал делать различные перестановки np.tensordot(A, B, . ) Но на самом деле я с ним не знаком.
Похожие вопросы:
Я хочу вычислить / оценить, каким будет размер файла изображения (. jpg) после сжатия со значением Encoder.Quality. Здесь я не должен выполнять какое-либо сжатие перед оценкой, есть ли какая-либо.
Мне нужно сжатие динамического диапазона java fft die volume control. У кого был опыт работы с этим на Android.
У меня возникла проблема с де-сжатием файла ZIP с помощью Java. Метод приведен ниже. Файловая структура правильна, как только файл де-сжат, это означает, что каталоги находятся в порядке внутри.
Я пытаюсь сделать программу, чтобы сжать файл, чтобы .tar.gz: Вот код: import java.io.*; import java.util.logging.Level; import java.util.logging.Logger; import java.util.zip.GZIPOutputStream;.
У меня есть файл XML формата .zfo , который сжимается с помощью алгоритма zip. Мне нужно удалить это сжатие из файла, чтобы он был в пригодной для использования форме XML. Вот досье . Как я могу.
У меня есть тензор A в numpy, который равен N1 x .. x Nn x M1 x . x Mm , и тензор B , который равен M1 x . x Mm . Как вычислить тензорное сжатие C из A и B , которое должно быть N1 x . x Nn? я.
Я использую jammit gem. Я хочу отключить сжатие java в производственном режиме на сервере. потому что я делаю сжатие на своем компьютере. Как я могу это сделать? спасибо
Я использую hadoop для хранения файлов. Я хочу знать фактический размер файла. getFileSystem().getContentSummary(new Path(fileName)).getLength(); Он возвращает сжатый размер файла. Я использую.
Я ищу сжатие длины строки, чтобы избежать длинного имени файла, как показано ниже. Строка также содержит UTF-8 символов.
Все алгоритмы сжатия оперируют входным потоком информации с целью получения более компактного выходного потока при помощи некоторого преобразования. Основными техническими характеристиками процессов сжатия и результатов их работы являются:
Алгоритмы, которые устраняют избыточность записи данных, называются алгоритмами сжатия данных, или алгоритмами архивации. В настоящее время существует огромное множество программ для сжатия данных, основанных на нескольких основных способах.
Все алгоритмы сжатия данных делятся на:
) алгоритмы сжатия без потерь, при использовании которых данные на приемной восстанавливаются без малейших изменений;
)алгоритмы сжатия с потерями, которые удаляют из потока данных информацию, незначительно влияющую на суть данных, либо вообще невоспринимаемую человеком.
Существует два основных метода архивации без потерь:
алгоритм Хаффмана (англ. Huffman), ориентированный на сжатие последовательностей байт, не связанных между собой,
Алгоритм Лемпеля-Зива. Классический алгоритм Лемпеля-Зива -LZ77, названный так по году своего опубликования, предельно прост. Он формулируется следующим образом: если в прошедшем ранее выходном потоке уже встречалась подобная последовательность байт, причем запись о ее длине и смещении от текущей позиции короче чем сама эта последовательность, то в выходной файл записывается ссылка (смещение, длина), а не сама последовательность.
4.Показатель степени сжатия файлов
Сжатие информации в архивных файлах производится за счет устранения избыточности различными способами, например за счет упрощения кодов, исключения из них постоянных битов или представления повторяющихся символов или повторяющейся последовательности символов в виде коэффициента повторения и соответствующих символов. Алгоритмы подобного сжатия информации реализованы в специальных программах-архиваторах (наиболее известные из которых arj/arjfolder, pkzip/pkunzip/winzip, rar/winrar) применяются определенные Сжиматься могут как один, так и несколько файлов, которые в сжатом виде помещаются в так называемый архивный файл или архив.
Целью упаковки файлов обычно являются обеспечение более компактного размещения информации на диске, сокращение времени и соответственно стоимости передачи информации по каналам связи в компьютерных сетях. Поэтому основным показателем эффективности той или иной программы-архиватора является степень сжатия файлов.
Степень сжатия файлов характеризуется коэффициентом Кс, определяемым как отношение объема сжатого файла Vc к объему исходного файла Vо, выраженное в процентах (в некоторых источниках используется обратное соотношение):
Степень сжатия зависит от используемой программы, метода сжатия и типа исходного файла.
Кроме того, программы для архивации все же различаются реализациями алгоритмов сжатия, что соответственно влияет на степень сжатия.
Пошаговая инструкция
В этом пошаговом руководстве я покажу Вам, как узнать степень сжатия файлов архива. Для этого щелкнем правой кнопкой мыши по заархивированному файлу и выбираем графу «Свойства».
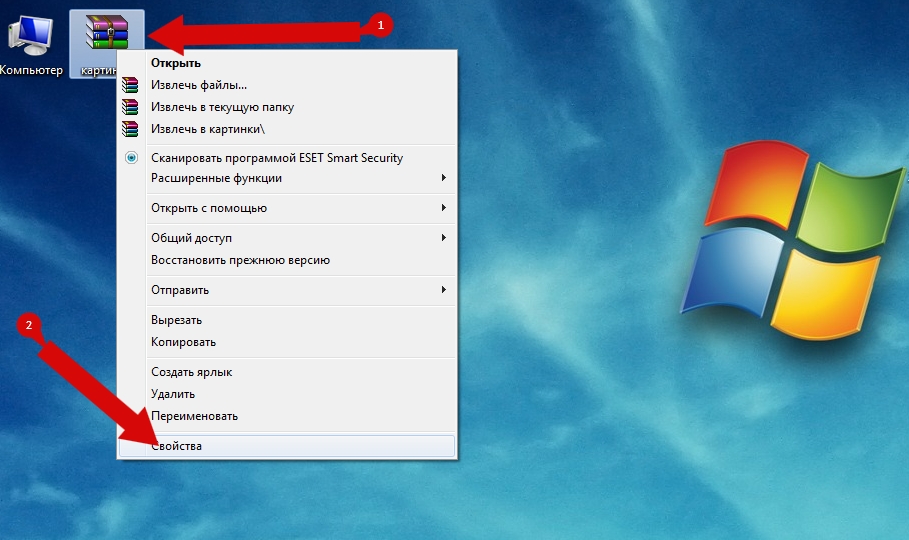
В новом диалоговом окне переходим во вкладку «Архив» и в графе «Степень сжатия» Вы видите процент сжатия документа. Это все! Если информация помогла Вам – жмите Спасибо!
Приветствую!
В этой подробной пошаговой инструкции, с фотографиями, мы покажем вам, как узнать степень сжатия файлов в архиве.
Воспользовавшись этой инструкцией, вы с легкостью справитесь с данной задачей.
Узнаём степень сжатия архива
Для определения степени сжатия на компьютере должен быть установлен архиватор WinRar. Если он у вас не установлен, то вот в этой подобной пошаговой инструкции рассказывается о том, где его бесплатно скачать и как установить.

Вызовите контекстное меню, кликнув правой клавишей мышки на интересующем архиве, для которого требуется определить степень сжатия.
В нём выберите пункт Свойства.

В открывшемся окне перейдите во вкладку Архив. Там в строке Степень сжатия будет указан интересующий нас параметр.
Если у вас остались вопросы, вы можете задать их в комментариях.
В свою очередь, Вы тоже можете нам очень помочь.
Просто поделитесь статьей в социальных сетях с друзьями.
Поделившись результатами труда автора, вы окажете неоценимую помощь как ему самому, так и сайту в целом. Спасибо!
- Помогла понравилась статья? Поделись ею в соцсетях!
- Спасибо!
Привет.
Не секрет, что в экономике ныне дела обстоят не лучшим образом, цены растут, а доходы падают. И данный сайт также переживает нелёгкие времена 🙁
Если у тебя есть возможность и желание помочь развитию ресурса, то ты можешь перевести любую сумму (даже самую минимальную) через форму пожертвований, или на следующие реквизиты:
Читайте также: