
Как запаковать в dll
Обновлено: 06.07.2024
и восстановления исходного кода
Автор: Сергей Чубченко. Дата публикации: 06.09.2004Учимся распаковке DLL библиотек
В данной статье я расскажу основные приемы, используемые для распаковки DLL библиотек. Несмотря на большое сходство EXE и DLL, многих начинающих исследователей кода распаковка DLL просто отпугивает, а многим из них кажется, что это вообще невозможно. Как ни странно все делается почти также просто, как и распаковка EXE файлов, правда есть определенные тонкости. Распаковку DLL библиотек мы рассмотрим на примере плагина GenOEP.dll из поставки PEiD’а, так как он наверняка найдется у многих.
[Нам понадобятся]
1. Olly Debugger
2. Lord PE
3. ImpREC
4. PEiD
5. Мозги
[Немного исследования]
Откроем наш плагин в Olly. Нам сразу будет предложено использовать программу loaddll.exe из поставки olly. Чтож, неплохая идея, поэтому отвечаем "Да". Просмотрев то, что находится начиная с точки входа
нетрудно догадаться, что программа запакована UPX’ом, поэтому ищем следующие команды ниже:
как ни странно все стандартно:
Ставим бряк на 10004A08 адрес, дважды щелкнув по строчке байт и запускаем DLL. Да, да, именно запускаем, так как она будет запущена с помощью специальной утилиты Olly, которая как бы эмулирует вызов этой библиотеки из EXE. Брякнулись? Запускаем Lord PE, выбираем в списке процессов loaddll.exe и видим в списке ниже гору библиотек. Найдем среди этого списка нужный нам плагин (genoep.dll), далее щелкаем правой кнопкой и выбираем пункт "Dump full". Теперь мы имеем нормальный дамп Dll’ки, правда пока не работоспособный.
[Восстановление импорта]
Надеюсь, что вы еще не закрыли Olly, так как брякнутый на OEP процесс нам еще понадобится, для получения из него импорта. запускаем ImpREC и выбираем в списке процессов "loaddll.exe". Теперь посмотрите чуть правее. Как вы думаете, для чего нужна кнопка "Pick dll"? Как ни странно именно для выбора DLL. Щелкнем по ней и выберем в полученном списке наш плагин (скорее всего он будет первым в списке) и щелкнем по кнопке "OK".
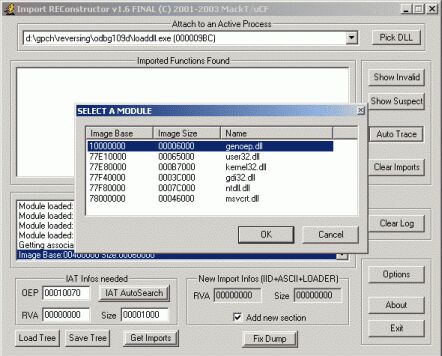
Теперь осталось только вбить найденный нами OEP (а это как вы помните адрес, по которому jmp’ается прога после восстановления регистров (POPAD)) в строку "OEP". Не забудем вычесть из него значение Image Base (для данной DLL библиотеки оно равно 10000000. Щелкаем по кнопке "IAT AutoSearch". Далее как обычно - жмем "Get Imports" и получаем список функций. Они восстановились нормально, так как мы имеем дело с простым упаковщиком.
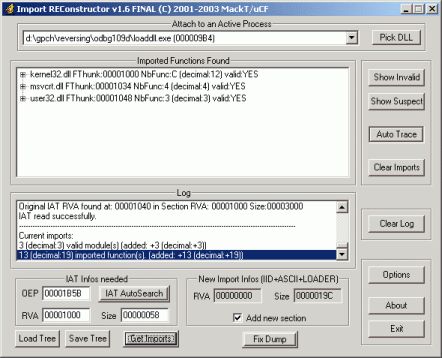
Щелкаем по кнопке "Fix Dump", выбираем сдампенную в предыдущем шаге DLL и получаем полноценный рабочий дамп, который можно проверить запустив PEiD и найдя этот плагин в списке плагинов.
Вот мы с Вами и научились распаковывать DLL. Как видите это не намного сложнее распаковки EXE файлов, но немного поинтереснее. Думаю Вы без труда найдете практическое применение полученным знаниям. Это поможет локализаторам программ на русский язык, которые обычно не русифицируют плагины, так как редакторы ресурсов не могут отобразить запакованные ресурсы программ. Ну и конечно это пригодится для исследования вредоносного кода антивирусным аналитикам, особенно когда код разнесен по нескольким DLL, которые еще к тому же упакованы.
Если вам уже приходилось заменять значки папок, то вы, стало быть, в курсе, что при этом система предлагает поискать альтернативный значок в файле SHELL32.dll, расположенный в папке system32. Спрашивается, почему Windows хранит иконки именно в DLL-файлах, а не в отдельных папках и что вообще представляют собой файлы DLL?
Файлы DLL или Dynamic Link Library они же динамически подключаемые библиотеки представляют собой контейнеры, нечто вроде архивов, в которых могут храниться различные используемые исполняемыми файлами EXE компоненты, например, фрагменты кода или графические элементы, в нашем случае иконки. Использование DLL в Windows основано на принципе модульности, причем каждая отдельная совместимая библиотека может быть подключена к тому или иному приложению, тем самым расширяя его функциональные возможности.
Вам может быть интересно: Как убрать рекомендуем из пуска

При этом будущая динамическая библиотека отобразится в левой колонке рабочего окна утилиты. После этого нажмите на панели инструментов кнопку Import и в открывшемся окошке укажите путь к файлу иконки, нажав кнопку «Browse». Больше ничего в настройках менять не нужно.



Нажмите «OK» и в левой колонке утилиты у вас появятся две папки Icon Image и Icon Directory, в них и будут храниться ваши иконки.

Если хотите, можете попробовать поиграть с настройками встроенного редактора иконок, изменив метод интерполяции или добавив задний фон.

Точно таким же образом одна за другой в библиотеку добавляются прочие иконки. Чтобы сохранить результаты работы, жмем кнопку Save – библиотека будет сохранена в каталог, из которого вы брали иконки.

Готово, теперь можете использовать свою библиотеку по назначению, подставляя к ней путь в окошке смены значка.
Давным-давном, когда Windows XP еще не было, в поисках информации о пакерах мы с Волком забирались в самые дебри исходников тогда еще молодого UPX. Но то ли ацетилхолина у нас в мозгах синтезировалось меньше нужного, то ли UPX уже тогда был очень занудным — в общем, мы почти ничего из тех сорцов не извлекли. Мэтт Питрек, и тот помог больше. Сейчас с инфой значительно проще стало. Почти всё есть. Даже сорцы вполне себе нормального банковского троя можно скачать (Zeus 2.0.8.9, bit.ly/v3EiYP). Да чего уж там, сорцы винды уже давно в паблике (Windows 2000, bit.ly/rBZlCy).
Об упаковщиках информация тоже есть, но в основном исследовательская, непосредственно разработки касающаяся не с той стороны, с которой нам бы хотелось. Отличным примером тому является статья »Об упаковщиках в последний раз» (bit.ly/vRPCxZ, bit.ly/tSUxT7) в двух частях, написанная небезызвестными гуру Volodya и NEOx.
Мы, в свою очередь, постараемся максимально конкретно и последовательно дать информацию именно о разработке простейшего, но легко модифицируемого под любые свои нужды PE-пакера.
Алгоритм
Вот есть у нас, например, notepad.exe. В обычном своем 32-битном виде он весит где-нибудь 60 Кб. Мы хотим его существенно уменьшить, сохранив при этом всю его функциональность. Какими должны быть наши действия? Ну, для начала мы наш файлик от первого до последнего байтика прочтем в массив. Теперь мы можем делать с ним всё что угодно. А нам угодно его сжать. Берем его и отдаем какому-нибудь простому компрессору, в результате чего получаем массив уже не в 60 Кб, а, например, в 20 Кб. Это круто, но в сжатом виде образ нашего «Блокнота» — это просто набор байтов с высокой энтропией, это не экзешник, и его нельзя запустить, записав в файл и кликнув. Для массива со сжатым образом нам нужен носитель (загрузчик), очень маленький исполняемый файл, к которому мы прицепим наш массив и который его разожмет и запустит. Пишем носитель, компилируем, а затем дописываем к нему в конец наш сжатый «Блокнот». Соответственно, если полученный в результате всех действий файл (размер которого немного больше, чем у просто сжатого «Блокнота») запустить, он найдет в себе упакованный образ, распакует, распарсит его структуру и запустит.
Как видишь, нам предстоит автоматизировать не слишком сложный процесс. Нужно будет просто написать две программы, загрузчик и, собственно, упаковщик.
Алгоритм работы упаковщика:
- считать PE-файл в массив;
- сжать массив каким-нибудь алгоритмом сжатия без потерь;
- в соответствии с форматом PE дописать сжатый массив к шаблону-загрузчику.
Алгоритм работы загрузчика:
- найти в конце себя массив со сжатым PE-файлом;
- разжать его;
- распарсить заголовки PE-файла, расставить все права, выделить память и в итоге запустить.
Начнем разработку с загрузчика, так как именно им впоследствии будет манипулировать упаковщик.
Загрузчик
Итак, первое, что должен сделать наш загрузчик, — это найти в своем теле адрес массива со сжатым образом PE-файла. Способы поиска зависят от того, как упаковщик имплантировал этот массив в загрузчик.
Например, если бы он просто добавил новую секцию с данными, то поиск выглядел бы так:
Но, на наш с Волком взгляд, этим кодом в загрузчике можно пожертвовать. Вообще, всё, что может сделать упаковщик, пусть он и только он и делает. Адрес образа в адресном пространстве загрузчика можно вычислить заранее, при упаковке, а потом просто вписать в нужное место. Для этого оставляем в нашей программе две метки:
Когда упаковщик будет имплантировать в загрузчик массив со сжатым образом, он пройдется сигнатурным поиском по телу загрузчика и заменит 0xDEADBEEF на адрес массива, а 0xBEEFCACE — на его размер.
Теперь, когда мы определились, как искать адрес, можно выбрать готовую реализацию алгоритма сжатия для использования в нашем упаковщике.
Неплохой вариант — использовать aplib, маленькую библиотеку с аккуратным и очень компактным кодом, реализующую сжатие на базе алгоритма Лемпеля-Зива (LZ). И мы обязательно его выбрали бы в любой другой день, однако сегодня у нас настроение для еще более простого и компактного решения — встроенных в Windows функций!
Начиная с XP, наша любимая ntdll.dll начала экспортировать две прекрасные функции:
Названия их говорят сами за себя — одна функция для компрессии, другая для декомпрессии. Конечно, если бы мы разрабатывали действительно серьезный продукт, мы бы эти функции не трогали, ведь остались еще компьютеры и с Windows 2000, и даже с NT 4.0, 😉 но для наших скромных целей RtlCompressBuffer\RtlDecompressBuffer вполне подойдут.
В хедерах Platform SDK этих функций нет, статически мы их прилинковать не сможем, поэтому придется воспользоваться GetProcAddress:
Когда есть чем распаковать и есть что распаковать, можно уже, наконец, это сделать. Для этого мы выделим память с запасом (так как не знаем объем распакованного файла) и запустим определенную выше функцию:
Параметр COMPRESSION_FORMAT_LZNT1 означает, что мы хотим использовать классическое LZ-сжатие. Функция умеет сжимать и другими алгоритмами, но нам хватит и этого.
Теперь у нас в памяти (pbImage) есть сырой образ PE-файла. Чтобы его запустить, нужно провести ряд манипуляций, которые обычно делает нативный PE-загрузчик Windows. Мы сократим список до самых-самых необходимых:
- Разместить начало образа (хедеры) по адресу, указанному в поле Image Base опционального заголовка (OPTIONAL_HEADER).
- Разместить секции PE-файла по адресам, указанным в таблице секций.
- Распарсить таблицу импорта, найти все адреса функций и вписать в соответствующие им ячейки.
Естественно, стандартный PE-загрузчик выполняет целую кучу других действий, и тем, что мы их отметаем, мы ограничиваем совместимость нашего упаковщика с некоторыми PE-файлами. Но для абсолютного большинства хватит и этих действий — можно не фиксить релоки, фиксапы и прочую редкую и противную фигню.
Если вдруг тебе захочется серьезной совместимости, ты или сам напишешь крутой PE-лоадер, или найдешь в Сети наиболее полную его реализацию — нам с Волком было лень писать свою, и мы воспользовались трудами gr8 из hellknights выкинув из нее всё, что не поняли. 😉 Даже в урезанном виде функция PE-лоадера — это строчек сто, не меньше, поэтому здесь мы приведем только ее прототип (полный код лежит на диске):
Она принимает указатель на наш распакованный образ и возвращает дескриптор загруженного модуля (эквивалент адреса, по которому загружен PE-файл) и адрес точки входа (по указателю AddressOfEntryPoint). Эта функция делает всё, чтобы правильно разместить образ в памяти, но не всё, чтобы можно было, наконец, передать туда управление.
После выполнения функции LoadExecutable в загрузчике неплохо было бы освободить память, выделенную для распаковки, — она нам больше не пригодится.
Дело в том, что система по-прежнему ничего не знает о загруженном нами модуле. Если мы прямо сейчас вызовем точку входа, с которой сжатая программа начнет выполнение, то может возникнуть ряд проблем. Работать программа будет, но криво.
Например, GetModuleHandle(NULL) будет возвращать Image Base модуля загрузчика, а не распакованной программы. Функции FindResource и LoadResource будут рыться в нашем загрузчике, в котором никаких ресурсов нет и в помине. Могут быть и более специфические глюки. Чтобы всего этого не происходило, нужно в системных структурах процесса по возможности везде обновить информацию, заменив адреса модуля загрузчика на адреса загруженного модуля.
В первую очередь нужно пофиксить PEB (Process Enviroment Block), в котором указан старый Image Base. Адрес PEB очень легко получить, в юзермоде он всегда лежит по смещению 0x30 в сегменте FS.
Также не помешает пофиксить списки модулей в структуре LDR_DATA, на которую ссылается PEB. Всего там три списка:
- InLoadOrderModuleList — cписок модулей в порядке загрузки;
- InMemoryOrderModuleList — cписок модулей в порядке расположения в памяти;
- InInitializationOrderModuleList — cписок модулей в порядке инициализации.
Нам надо найти в каждом списке адрес нашего загрузчика и заменить его на адрес загруженного модуля. Как-нибудь так:
Вот теперь можно смело вызывать точку входа загруженного модуля. Он будет функционировать так, словно был вызван самым обычным образом.
AddressOfEntryPoint — это относительный виртуальный адрес (RVA, Relative Virtual Address) точки входа, взятый из optional header в функции LoadExecutable. Для получения абсолютного адреса мы просто прибавили к RVA адрес базы (то есть свежезагруженного модуля).
Процесс отладки бажного файла в OllyDbg
Уменьшение размера загрузчика
Если наш загрузчик скомпилировать и собрать в VS 2010 с флагами по умолчанию, то мы получим не двухкилобайтную программку-носитель, а монстра размером более 10 Кб. Студия встроит туда целую кучу лишнего, а нам надо всё это оттуда выгрести.
Поэтому в свойствах компиляции проекта загрузчика (вкладка С/C++) мы делаем следующее:
- В разделе «Оптимизация» выбираем «Минимальный размер (/O1)», чтобы компилятор старался сделать все функции более компактными.
- Там же указываем приоритет размера над скоростью (флаг /Os).
- В разделе «Создание кода» выключаем исключения С++, мы их не используем.
- Проверка переполнения буфера нам тоже не нужна (/GS-). Это штука хорошая, но не в нашем случае.
В свойствах линкера (компоновщика):
- Отключаем к чертям «Манифест». Он большой, и из-за него в загрузчике создается секция .rsrc, которая нам совершенно не нужна. Вообще, каждая лишняя секция в PE-файле — это минимум 512 совершенно ненужных байт, спасибо выравниванию.
- Отключаем создание отладочной информации.
- Лезем во вкладку «Дополнительно». Выключаем «Внесение случайности в базовый адрес» (/DYNAMICBASE:NO), иначе линкер создаст секцию релоков (.reloc).
- Указываем базовый адрес. Выберем какой-нибудь нестандартный повыше, например 0x02000000. Именно это значение будет возвращать GetModuleHandle(NULL) в загрузчике. Можно его даже захардкодить.
- Указываем нашу точку входа, а не CRT-шную: /ENTRY:WinMain. Вообще, мы привыкли это делать директивой pragma прямо из кода, но раз уж залезли в свойства, то можно и тут.
Остальные настройки для линкера задаем непосредственно из кода:
Здесь мы объединили секцию .rdata, в которой содержатся данные, доступные только для чтения (строки, таблица импорта и т. п.), с секцией кода .text. Если бы мы использовали глобальные переменные, то нам также надо было бы объединить с кодом секцию .data.
Всего перечисленного хватит, чтобы получить лоадер размером в 1,5 Кб.
Переделываем в криптор
Собственно, от криптора наш пакет отличает совсем немногое: отсутствие функции шифрования и противоэмуляционных приемов. Самое простое, что можно с ходу сделать, — это добавить xor всего образа сразу после распаковки в загрузчике. Но, чтобы эмуляторы антивирусов подавились, этого недостаточно. Нужно как-то усложнить задачу. Например, не прописывать ключ xor’а в теле загрузчика. То есть загрузчик не будет знать, каким ключом ему надо расшифровывать код, он будет его перебирать в определенных нами рамках. Это может занять какое-то время, которое есть у пользователя, в отличие от антивируса.
Также ключ можно сделать зависимым от какой-нибудь неэмулируемой функции или структуры. Только их еще найти надо.
Чтобы код загрузчика не палился сигнатурно, можно прикрутить к упаковщику какие-нибудь продвинутые вирусные движки для генерации мусора и всяческого видоизменения кода, благо их в Сети навалом.
Упаковщик
Нам остается разработать консольную утилиту, которая будет сжимать отданные ей файлы и прицеплять к лоадеру. Первое, что она должна делать по описанному в начале статьи алгоритму, — это считывать файл в массив. Задача, с которой справится и школьник:
Далее наш пакер должен сжать полученный файл. Мы не будем проверять, действительно ли это PE-файл, корректные ли у него заголовки и т. п., — всё оставляем на совести пользователя, сразу сжимаем. Для этого воспользуемся функциями RtlCompressBuffer и RtlGetCompressionWorkSpaceSize. Первую мы уже описали выше — она сжимает буфер, вторая же нужна, чтобы вычислить объем памяти, необходимой для работы сжимающего движка. Будем считать, что обе функции мы уже динамически подключили (как и в загрузчике), остается только их запустить:
В результате у нас есть сжатый буфер и его размер, можно прикрутить их к загрузчику. Чтобы это сделать, нужно для начала скомпилированный код нашего загрузчика встроить в упаковщик. Самый удобный способ засунуть его в программу — это воспользоваться утилитой bin2h. Она конвертнет любой бинарник в удобный сишный хедер, все данные в нем будут выглядеть как-то так:
Скармливаем ей файл с нашим лоадером и получаем всё необходимое для дальнейших извращений. Теперь, если придерживаться алгоритма, описанного в начале статьи, мы должны прицепить к загрузчику сжатый образ. Здесь нам с Волком придется вспомнить 90-е и свое вирмейкерское прошлое. Дело в том, что внедрение данных или кода в сторонний PE-файл — это чисто вирусная тема. Организуется внедрение большим количеством разных способов, но наиболее тривиальные и популярные — это расширение последней секции или добавление своей собственной. Добавление, на наш взгляд, чревато потерями при выравнивании, поэтому, чтобы встроить сжатый образ в наш загрузчик, мы расширим ему (загрузчику) последнюю секцию. Вернее, единственную секцию — мы же избавились от всего лишнего. 😉
Создание хедера с помощью bin2h можно автоматизировать
Алгоритм действий будет такой:
- Находим единственную секцию (.text) в загрузчике.
- Изменяем ее физический размер, то есть размер на диске (SizeOfRawData). Он должен быть равен сумме старого размера и размера сжатого образа и при этом выравнен в соответствии с файловым выравниванием (FileAlignment).
- Изменяем виртуальный размер памяти (Misc.VirtualSize), прибавляя к нему размер сжатого образа.
- Изменяем размер всего образа загрузчика (OptionalHeader.SizeOfImage) по древней формуле [виртуальный размер последней секции] + [виртуальный адрес последней секции], не забывая выравнивать значение по FileAlignment.
- Копируем сжатый образ в конец секции.
Тут есть небольшая хитрость. Дело в том, что наша студия делает виртуальный размер (Misc.VirtualSize) секции с кодом (.text) равным реальному невыравненному размеру кода, то есть указывает размер меньше физического. А значит, есть шанс сэкономить до 511 байт.
То есть так бы мы записали данные после кучи выравнивающих нулей, а зная фишку, можно записаться поверх этих нулей.
Кусок кода парсера таблицы импорта
Вот как все наши мысли будут выглядеть в коде:
О, мы едва не забыли заменить метки 0xDEADBEEF и 0xBEEFCACE, оставленные в загрузчике, на реальные значения! 0xBEEFCACE у нас меняется на размер сжатого образа, а 0xDEADBEEF — на его абсолютный адрес. Адрес образа вычисляется по формуле [адрес образа] + [виртуальный адрес секции] + [смещение образа относительно начала секции]. Следует отметить, что замену надо производить еще до обновления значения Misc.VirtualSize, иначе полученный в результате файл не заработает.
Ищем и заменяем метки с помощью очень простого цикла:
Вот, собственно, и всё. Теперь в памяти у нас есть упакованный и готовый к работе файл, достаточно сохранить его на диске с помощью функций CreateFile/WriteFile.

Наш упаковщик сжал notepad.exe лучше, чем UPX!
Однако существуют программы, использующие сторонние библиотеки, но при этом состоящие из одного единственного файла. Все утилиты от SysInternals, а также любимый мной LINQPad представляют из себя один файл в котором содержится все, что требуется для работы. Пользоваться такими утилитами одно удовольствие — они сразу готовы к использованию, их удобно передавать и хранить.
В статье рассказывается, как создавать такие автономные программы из одного файла. Разобран пример как со сжатием зашить библиотеку AutoMapper в программу и как ее потом достать и использовать.
Исходный код к статье — скачать
Код программы использует стороннюю библиотеку AutoMapper. Чтобы убедиться в работоспособности библиотеки после ее зашития в ресурсы, в программе вызывается код из семплов к библиотеке. Этот код здесь не приведен, ибо это статья не об AutoMapper. Но сама библиотека интересная и полезная — рекомендую посмотреть, что же она делает в коде.
Если CLR не удалось найти сборку, вызывается событие AppDomain.AssemblyResolve. Событие дает возможность загрузить требуемую сборку вручную. Поэтому для реализации автономной программы, состоящей из одного exe файла, достаточно зашить все зависимые сборки в ресурсы и в обработчике AssemblyResolve подгружать их.
Удобно класть в ресурсы сборки в архивированном виде. Архивация уменьшает размер итоговой программы приблизительно в 2 раза. Скорость запуска увеличивается, но эти доли секунды мало кто заметит. А вот уменьшение размера файла позволит его быстрее качать по сети.
Итак, у нас есть работающий проект, использующий сторонние библиотеки. Хочется, чтобы exe файл проекта был автономен и не требовал наличия зависимых dll в своем каталоге.
Полученную ранее архивированную сборку добавляем в ресурсы проекта через Project Properties-Resources-Files. Студия при добавлении ресурса генерирует код, который позволяет использовать добавленный ресурс через Resources класс.
Регистрируем обработчик AssemblyResolve (до использования классов зависимой библиотеки):
| AppDomain .CurrentDomain.AssemblyResolve += AppDomain_AssemblyResolve; |
| private static Assembly AppDomain_AssemblyResolve( object sender, ResolveEventArgs args ) if ( args.Name.Contains( "AutoMapper" ) ) Console .WriteLine( "Resolving assembly: " , args.Name ); // Загрузка запакованной сборки из ресурсов, ее распаковка и подстановка Для нескольких зависимых библиотек стоит ввести соглашение, согласно которому имя ресурса и искомой сборки совпадают. Тогда можно с помощью отражения автоматически искать требуемую библиотеку в ресурсах. По умолчанию зависимые библиотеки, добавляемые через References, копируются в выходную директорию проекта. Чтобы AssemblyResolve сработал, нужно либо скопировать выходной exe файл в другую директорию, либо запретить копировать зависимые библиотеки в конечную директорию через References-AutoMapper-Properties-Copy Local=false. Включение зависимых сборок в ресурсы самой программы позволяет ей работать автономно. Для запуска требуется один лишь exe файл. Это важно для служебных утилит, сразу готовых к использованию. Фактически такие автономные программы не требуют установки и их удобно передавать по сети или хранить на флешке. Архивирование сборок позволяет уменьшить размер программы и больше таких программ разместить на флешке / быстрее выкачивать из сети. Читайте также:
|