
Какие таблицы бывают oracle
Обновлено: 05.07.2024
Чалышев Максим Михайлович
SQL. 5 дней, которые изменят вашу жизнь.
Внешние таблицы – специальный механизм Oracle СУБД с помощью которого можно обращаться в данным , хранящимся в файлах вне базы данных как к обычным таблицам.
Для загрузки данных могут использоваться команды драйвера OracleLoader. В ExternalTable не могут применяться операторы изменения данных (DELETE INSERT UPDATE MERGE).
Но, к таким таблицам вполне могут применяться стандартные запросы SELECT, с использованием групповых операций, агрегатных функций, аналитического SQL.
Все это делает механизм внешних таблиц особенно эффективным для проектов DWH(хранилищ данных) , при формировании ETL(процедур загрузки) для данных.
Теория и практика
Предположим, у нас есть несколько файлов заданного формата, файлы расположены в каталоге temp на диске c:
Необходимо подключить эти файлы как внешние таблицы к экземпляру нашей базы данных.
Название файлов city.csv и man.csv, кодировка UTF8 - ниже представлено содержание этих файлов текстовом виде.
Вы можете создать эти файлы сами с помощью любого текстового редактора. Напоминаю, что кодировка файлов UTF8.
Перед использованием внешних таблиц необходимо создать специальный объект directory указывающий на каталог, где расположены файлы для внешних таблиц
Здесь
• ext_tab_data – название объекта directory
• AS 'c:/temp' – каталог, где расположены файлы для формирования внешних таблиц.
Далее формируем временные таблицы
Создаем таблицу для файла city.csv
Здесь
• city_ext – название таблицы
• TYPE – драйвер загрузки
• DEFAULT DIRECTORY – объект директория, который мы создали
• ACCESS PARAMETERS – параметры загрузки файла , см документацию к LOADER
• LOCATION – название файла на основе которого создается внешняя таблица
Создаем таблицу для файла man .csv
Здесь
• city_ext – название таблицы
• TYPE – драйвер загрузки
• DEFAULT DIRECTORY – объект директория, который мы создали
• ACCESS PARAMETERS – параметры загрузки файла, см документацию к LOADER
• LOCATION – название файла на основе которого создается внешняя таблица
Обращаемся к таблицам, которые мы создали с помощью запроса
Используем агрегатную функцию и группировку данных
Соединяем внешнюю таблицу и обычную таблицу в запросе
Используем Аналитический SQL
Важные замечания
• Для внешних таблиц могут создаваться представления и синонимы.
• Кодировка файлов во внешних таблицах должна совпадать с кодировкой базы данных.
• На папки в которых собираются файлы для подготовки внешних таблиц администратор системы должен выдать специальное разрешение на чтение пользователю из, под которого устанавливалась Oracle СУБД.
• Вешние таблицы неэффективны при частом обращении к этим таблицам в высоконагруженных проектах, для таких проектов следует искать другое решение.
Вопросы учеников
Где еще используются на практике внешние таблицы?
Довольно часто внешние таблицы используются при обмене данными между системами
Где можно посмотреть материалы по ACCESS PARAMETERS?
В описании SQLLoader на сайте Oracle.
В разобранном примере используется драйвер SQLLoader можно ли использовать другие драйвера?
Да , например , можно для загрузки данных воспользоваться драйвером DATAPUMP.
Можно ли загрузить данные из внешней таблицы в обычную таблицу?
Да , и на этой возможности основано довольно много ETL.(процедур загрузки) Пример ,
Следующий запрос создаст таблицу cityccode
Запрос добавляет в эту таблицу данные из внешней таблицы, не забудьте завершить запрос операцией Commit
Когда вы меняете данные в БД, то ваши изменения сначала идут в кэш, а потом асинхронно в нескольких потоках (число можно сконфигурировать) пишутся на диск. Синхронно же пишется специальных лог (оперативный журнальный файл), чтобы была возможность восстановить данные после сбоя, если они еще не успели с кэша сброситься на диск. Данный подход позволяет выиграть в скорости, так как в этом случае на диск все пишется последовательно в один файл, причем можно настроить так, чтобы писалось параллельно на два или больше дисков, тем самым увеличивая надежность защиты от потери изменений. Описанных файлов должно быть несколько, и они используются по кругу: как только все данные защищенные одним из лог файлов были записаны фоновым процессом в блоки данных на диск, то данный лог файл может быть переиспользован. Таким образом в какой-то мере это позволяет еще и сэкономить, имея ультрабыстрые диски небольшого размера только для небольших журнальных файлов используемых по кругу.
Обычно я рассказываю об этом, когда мне предлагают что-то сохранять просто в файл на диске, так как это будет «быстрее» за счет того, что мы будет писать все данные последовательно и головке жесткого диска не надо будет бегать и искать рэндомные блоки. Я все же настаиваю, что мы тут ничего не выиграем, так как будем писать на медленный диск, который скоро всего активно используется множеством других процессов для записи огромного количества различных логов, а Oracle синхронно тоже пишет у себя на диск только последовательно, как я описал выше.
Механизм восстановления данных
В СУБД Oracle можно включить архивацию вышеописанных оперативных журнальных файлов, и все изменения будут архивироваться. Таким образом при потере любого диска с блоками данных мы можем восстановить их на любой момент времени, включая момент прямо перед падением, накатив на последние архивные журнальные файлы текущий оперативный журнал.
Stand by копия
Вышеупомянутые архивные файлы можно отправлять по сети и на лету применять к копии БД. Таким образом у вас всегда под рукой будет горячая копия с минимальным запаздыванием данных. В некоторых приложениях, где нет необходимости показывать данные с точностью до последнего момента, можно настроить такую БД только на чтение и разгрузить основной экземпляр БД, причем таких экземпляров на чтение может быть несколько.
Подвисание некоторых запросов на запись
При зависании некоторых ваших запросов в произвольный момент времени стоит заглянуть в alert.log на предмет наличия incomplete checkpoint. Это говорит о том, что ваши оперативные журнальные файлы слишком большие или их слишком мало, таким образом, защищаемые ими данные не успевают сбрасываться из кэша на диск, а СУБД заполнила уже все доступные оперативные журнальные файлы и хочет использовать их по кругу повторно, чего делать ни в коем случае нельзя, вот и появляется пауза. Хотя если ваше приложение работает на java, то в первую очередь я бы загляну на наличия Full GC в логах.
Неблокирующее чтение и сегмент отката
Одной из наиболее замечательных особенностей СУБД Oracle является неблокирующее чтение, которое достигается за счет сегмента отката. Запросы к Oracle на чтение никогда не блокируются, так как данные почти всегда могут быть прочитаны из сегмента отката.
Сегмент отката дает еще одну плюшку: из него можно попытаться считать немного устаревшие данные для какой-нибудь таблицы, которые были в ней на определенный момент. Называется данная фича — flashback.
Однако иногда сегмент отката может подложить свинью: если у вас есть большой job для bulk удаления данных (удаление генерирует всех больше данных в сегменте отката), то вы можете получить ORA-01555: snapshot too old. Главное что в этом случае надо помнить — это то, что не надо переписывать ваш job, чтобы он коммитил через каждые N операций, а нужно использовать отдельный специально созданный сегмент отката для таких операций.
Уровни изоляции транзакций
В Oracle вообще нет уровня изоляции READ_UNCOMMITED. Дело в том, что в других базах данных он используется для достижения максимального параллелизма путем удаления блокировок чтения. Но в Oracle чтение и так всегда выполняется без блокировок, таким образом мы уже имеем все преимущества, которые может дать этот уровень, не вводя никаких дополнительных ограничений.
Вообще, в Oracle явно доступно всего два уровня изоляции: по умолчанию используется READ_COMMITTED, но при желании вы можете установить SERIALIZABLE.
Однако на уровне операторов (SELECT, UPDATE и т.д.) у вас по умолчанию уже есть REPEATABLE_READ, т.е. в рамках одного оператора вы всегда получаете согласованное чтение, что достигается конечно же за счет сегмента отката. Мне всегда очень нравился пример приводимый Томом Кайтом для описания того, что это дает. Допустим у вас есть очень большая таблица со счетами и вы выполняете SELECT на получение суммы. В Oracle, в отличие от многих других БД, даже если в середине вашего запроса другая транзакция переведет некоторую суммы с первого счета на последний, вы в итоге все равно получите данные актуальные на начало вашего запроса, так как дойдя до последний строчки ваш SELECT увидит, что строчка была изменена, пойдет в сегмент отката и прочитает данные, которые были в этой ячейке на момент начала выполнения запроса. Во многих других базах данных, вы получите ответ в виде суммы, никогда не существующей в вашей таблице. Однако в Oracle в данном случае есть опасность получить ORA-01555: snapshot too old.
В дополнение к стандартным уровням изоляции в Oracle еще есть так называемые READ_ONLY транзакции, которые дают REPEATABLE_READ в рамках всей транзакции, а не только в рамках одного оператора. Но как следует из названия, в такой транзакции вы можете выполнять только чтение.
Позвольте Oracle кэшировать ваши данные эффективно
В Oracle все данные читаются-пишутся не прямо на диск, а через кэш. По умолчанию кэш основан на LRU алгоритме, так что если вы читаете какую-нибудь очень большую табличку по идентификатору в больших количествах, запрашивая в каждый раз новую строчку, то такие запросы могут вытеснять из кэша небольшую статическую табличку, которой бы самое милое дело постоянно находиться в кэше. Для таких целей при создании таблицы вы можете указать специальный вид кэша, куда будут ходить запросы к вашим таблицам. Так для первой таблицы в вышеописанном примере подойдет кэш RECYCLE, который по сути не хранит никакие данные, а сразу их выбрасывает из кэша. А для второй таблицы подойдет кэш KEEP, который позволить хранить в кэше небольшие статические таблице и запросы ко всем остальным таблицам не будут вытеснять данные статических таблиц из кэша.
Пустые строки
В оракл есть одна очень интересная особенность, от которой они теперь уже никогда не смогут избавиться. Дело в том, что если вы кладете в БД пустую строку, то она сохраниться как NULL. Таким образом при последующем чтении вы никогда не получите пустой строки, а только NULL. Имейте так же в виду, что по этой же причине пустые строки не попадают в индекс, так что если вы будете делать запросы, план выполнения которых, будет использовать индекс, то ваше пустые (вернее NULL) строки вы никогда не получите, но об этом чуть позже.
Индексы
Кроме всем известных индексов в виде B-деревьев в Oracle еще есть так называемые битовые индексы, которые показывают очень высокую производительность на запросах к таблицам в которых есть колонки с очень разреженными значениями. Особенно эффективно в этом случае будут работать запросы (по сравнению с обычными индексами) в которых присутствуют сложные комбинации OR и AND к разряженным столбцам. Данный индекс храниться не в B-дереве, а в битовых картах, что и дает возможность быстрого выполнения описанных запросов. Вопрос в количестве уникальных значений в таблице при которых данный индекс еще будет более предпочтителен весьма сложен: это может быть как 10 уникальных значений, так и 10 000. Здесь надо создавать индекс на конкретной таблице и смотреть что получается. Главное не пытайтесь использовать данный индекс на таблицах с большим количеством вставок и обновлений индексируемой колонки, так как такие операции будут блокировать довольно большие участки в индексируемой таблице и ваша система может встать колом или даже поймаете deadlock.
Одна из вещей, которая меня всегда очень радовала в Oracle — это возможность создания индекса по функции. Т.е. если вам в запросах приходиться использовать какую-нибудь функцию, то вы можете построить по ней индекс и значительно ускорить операции чтения.
Еще одно интересное свойство индексов, о котором необходимо знать, это то, что в индексе не хранятся значения NULL. Таким образом если вы будете делать запросы с условием <, > или <> по индексируемой колонке, то в ответ строчек со значением NULL в индексируемой колонке вы обратно не получите. С другой стороны данное свойство можно очень эффективно использовать дня некоторых специфичных случаев. Например, у вас есть очень большая табличка в которой хранятся ордера, которая никогда не чистится. И существует фоновый процесс, который обязан все ордера отсылать в какую-нибудь backoffice систему. Первое решение, которое напрашивается — это завести еще одну колонку с флагом is_sent, где изначально стоит 0 и при отсылке мы будем проставлять 1. Т.е. фоновый процесс при каждом запуске будет делать запрос к таблице с условием is_sent=0. Битовый индекс вы здесь использовать не можете, так как табличка очень активно пополняется. Обычный индекс на основе В-дерева будет занимать очень много места, так как нужно хранить ссылки на огромное количество строчек. Но если мы слегка поменяем нашу логику и в качестве пометки отсылки, и в колонку is_sent будем класть NULL вместо 1, то индекс у нас будет крошечный, так как в любой момент в нем будут храниться только не NULL значения, а их будет очень мало.
Таблицы бывают разные
Кроме обычных таблиц в oracle как и во многих других БД есть так называемые индекс-таблицы, когда данные таблицы непосредственно лежат в индекс-дереве первичного ключа. Таким образом достигается сразу две вещи: во первых для чтения данных по первичному ключу вы имеете на одно чтение меньше, во вторых данные в таблице получаются упорядоченными по первичному ключу, так что операция ORDER BY PK будет выполняться без дополнительной сортировки. К недостаткам можно отнести тот факт, что отличить логирование в оперативные журнальные файлы данного индекса вы уже не сможете.
Еще один замечательный тип таблиц — это кластерные таблицы, которые позволяют хранить данные из двух или более таблиц кластеризованные по одному значению ключа в одном блоке данных. Это может быть весьма эффективно если вы всегда используете какие-нибудь таблицы совместно.
На основе кластерных таблиц есть еще кластерные хэш-таблицы, в которых для доступа вместо B-дерева используется таблица на основе хеша кластерного ключа. Звучит, конечно, очень интересно, но, честно говоря, на практике никогда не сталкивался.
Связывание переменных
Наверное об этом уже наслышан каждый программист, но я все же упомяну о такой обязательной техники, как связывание переменных. Дело в том, что для каждого уникального запроса строится план разбора и кладется в кэш. Если различных запросов очень много, как, например, весьма распространенный запрос по ID, то на каждый запрос буден генериться свой план, к тому же они будут вытеснять из кэша все другие планы, что может в разы увеличить время отклика вашей базы данных.
Стоит так же заметить, что не стоит этим злоупотреблять и использовать связывание для столбцов с небольшим количеством различных значений, как-то флаг is_deleted, ведь различных запросов в этом случае будет не так много, а, возможно, для более конкретного запроса СУБД удастся построить более эффективный план.
Еще пара заметок для программиста
Если у вас колонка имеет тип VARCHAR2(100), то попытка туда запихнуть строку longString.substring(0, 100) не факт, что увенчается успехом, так как ограничение 100 в определении колонки по умолчанию относится к количеству байтов, а не символов, поэтому при наличии двухбайтовых символов вы можете попасть впросак. На самом деле данное поведение можно немного сконфигурировать, подробнее можно почитать тут. Хорошо если вы еще не пытаетесь выполнить вставку в бесконечном цикле, по принципу делать пока не получиться, ведь это «получиться» в данном случае никогда не наступит.
Ну и общая рекомендация для всех типов БД: никогда не делайте update всех колонок в таблице при изменении одного поля объекта. Кажется весьма очевидным, но как показывает практика, данный антипаттерн часто имеет место быть, поэтому я настоятельно рекомендую проверить, что ваши фреймворки делают UPDATE только действительно измененных полей.
Данные в реляционных базах данных хранятся в таблицах. Таблицы - это ключевой объект, с которыми придется работать в SQL.
Таблицы в БД совсем не отличаются от тех таблиц, с которыми все уже знакомы со школы - они состоят из колонок и строк.
Каждая колонка в таблице имеет своё имя и свой тип, т.е. тип данных, которые будут в ней содержаться. Помимо типа данных для колонки можно указать максимальный размер данных, которые могут содержаться в этой таблице.
Например, мы можем указать, что для колонки возраст тип данных - это целое число, и это число должно состоять максимум из 3-х цифр. Т.о. максимальное число, которое может содержаться в этой колонке = 999. А с помощью дополнительных конструкций можно задать и правила проверки корректности для значения в колонке,- например, мы можем указать, что для колонки возраст в таблице минимальное значение = 18.
Создание таблицы
После выполнения данной sql-команды в базе данных будет создана таблица под названием hello . Эта таблица будет содержать всего одну колонку под названием text_to_hello . В этой колонке мы можем хранить только строковые значения(т.е. любой текст, который можно ввести с клавиатуры) длинной до 100 байт.
Обратите внимание на размер допустимого текста в колонке text_to_hello . 100 байт - это не одно и то же, что и 100 символов! Для того, чтобы сказать базе данных Oracle, что длина строки может быть 100 символов, нужно было определить столбец следующим образом:
Создание таблицы с несколькими полями
В таблице может много столбцов. Например, можно создать таблицу с тремя, пятью или даже 100 колонками. В версиях oracle с 8i по 11g максимальное количество колонок в одной таблице достигает 1000.
Для того, чтобы создать таблицу с несколькими колонками, нужно перечислить все колонки через запятую.
Например, создадим таблицу cars , в которой будем хранить марку автомобиля и страну-производитель:
Эта таблица может содержать, например, такие данные:
Следует обратить внимание на последние 2 строки в таблице cars - они не полные. Первая из них содержит данные только в колонке model , вторая - не содержит данных ни в одной из колонок. Эта таблица может даже состоять из миллиона строк, подобных последней - и каждая строка не будет содержать в себе абсолютно никаких данных.
Значения по умолчанию
При создании таблицы можно указать, какое значение будет принимать колонка по умолчанию:
В этом примере создается таблица cars, в которой помимо модели и страны-производителя хранится еще и количество колес, которое имеет автомобиль. И поле wheel_count по-умолчанию будет принимать значение, равное 4.
Что значит по-умолчанию? Это значит, что если при вставке данных в эту таблицу не указать значение для колонки wheel_count , то оно будет равно числу 4.
Понятие NULL. Not-null колонки
Ячейки в таблицах могут быть пустыми, т.е. не содержать значения. Для обозначения отсутствия значения в ячейке используется ключевое слово NULL . Null могут содержать ячейки с любым типом данных.
Рассмотрим таблицу cars из предыдущего примера. В каждой из трех ее колонок может храниться Null(даже в колонке wheel_count , если указать значение Null явно при вставке).
Но представляют ли информационную ценность строки в таблице, где абсолютно нет значений? Конечно нет. Если рассматривать таблицу cars как источник информации об автомобилях, то нам хотелось бы получать хоть какую-то полезную информацию. Наиболее важной здесь будет колонка model - без нее информация о стране-производителе и количестве колес будет бесполезной.
Для того, чтобы запретить Null-значения в колонке при создании таблицы, к описанию колонки добавляется not null :
Теперь БД гарантирует, что колонка model не будет пустой, по крайней мере до тех пор, пока флаг not null включен для этой колонки.
Также можно указать, что колонка wheel_count тоже не должна содержать Null :
Комментарии к таблице, колонкам
Для создаваемых таблиц и их колонок можно указывать комментарии. Это значитально облегчит понимание того, для чего и как они используются.
Например, укажем комментарии для таблицы cars и ее колонок:
Для того, чтобы удалить комментарий, нужно просто задать в качестве его значения пустую строку:
Oracle Database — это объектно-реляционная СУБД (система управления базами данных), созданная компанией Oracle. В настоящее время она имеет множество разных версий и типов. Однако в этой статье мы поговорим не о видах баз данных Oracle, а о структуре и основных концепциях, которые относятся к СУБД Oracle Database. Поняв архитектуру СУБД Oracle, вы заложите фундамент, необходимый для понимания прочих средств (а они весьма обширны), предоставляемых базой данных Oracle.
Базы данных Oracle: экземпляры и сущности
СУБД Oracle Database включает в себя физические и логические компоненты. Особого упоминания заслуживает понятие экземпляра. Замечено, что некоторые используют термины «база данных» и «экземпляр» в качестве синонимов. Да, это взаимосвязанные, но всё же разные вещи. База данных в терминологии Oracle — это физическое хранилище информации, а экземпляр — это программное обеспечение, которое работает на сервере и предоставляет доступ к информации, содержащейся в базе данных Oracle. Экземпляр исполняется на конкретном сервере либо компьютере, в то самое время как база данных хранится на дисках, подключённых к этому серверу:
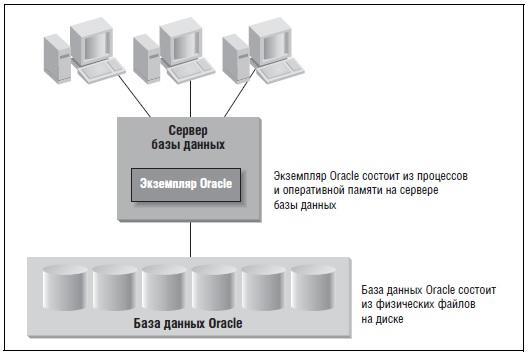
При этом база данных Oracle является физической сущностью, состоящей из файлов, которые хранятся на дисках. В то же самое время, экземпляр – это сущность логическая, состоящая из структур в оперативной памяти и процессов, которые работают на сервере. Экземпляр может являться частью только одной базы данных. При этом с одной базой данных бывает ассоциировано несколько экземпляров. Экземпляр ограничен по времени жизни, тогда как БД, условно говоря, может существовать вечно.
Также стоит заметить, что у пользователей нет прямого доступа к информации, которая хранится в базе данных Oracle — они должны запрашивать эту информацию у экземпляра Oracle.
Если упрощённо, то экземпляр — это мост к базе данных, а сама БД – это остров. Когда экземпляр запущен, мост работает, а данные способны попадать в базу данных Oracle и покидать её. Если мост перекрыт (экземпляр остановлен), пользователи не могут обращаться к базе данных, несмотря на то, что физически она никуда не исчезла.
Структура базы данных Oracle
База данных Oracle включает в себя: — табличные пространства; — управляющие файлы; — журналы; — архивные журналы; — файлы трассировки изменения блоков; — ретроспективные журналы; — файлы резервных копий (RMAN).
Табличные пространства Oracle
Любые данные, которые хранятся в базе данных Oracle, просто обязаны существовать в каком-либо табличном пространстве. Под табличным пространством (tablespace) понимают логическую структуру, то есть вы не сможете попросить ОС показать вам табличное пространство Oracle.
При этом каждое табличное пространство включает в себя физические структуры, называемые файлами данных (data files). Одно табличное пространство Oracle способно содержать один либо несколько файлов данных, в то время как каждый файл данных может принадлежать лишь одному tablespace. Создавая таблицу, мы можем указать, в какое именно табличное пространство мы её поместим — Oracle находит для неё место в каком-нибудь из файлов данных, которые составляют указанное табличное пространство.
На рисунке ниже вы можете посмотреть на соотношение между файлами данных и табличными пространствами в базе данных Oracle.
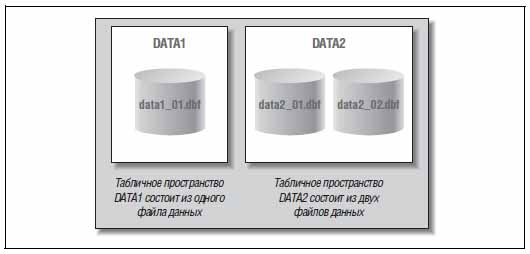
Создавая новую таблицу, мы можем поместить её в табличное пространство DATA1 либо DATA2. Таким образом, физически наша таблица окажется в одном из файлов данных, которые составляют указанное табличное пространство.
Файлы базы данных Oracle
База данных Oracle может включать в себя физические файлы 3-х основных типов: • control files — управляющие файлы; • data files — файлы данных; • redo log files — журнальные файлы либо журналы.
Посмотрим на отношения между ними:
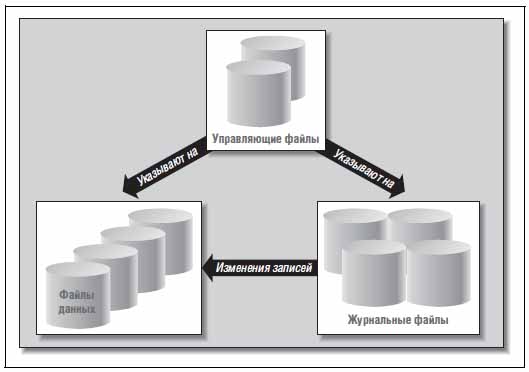
В управляющих файлах содержится информация о местонахождении других физических файлов, которые составляют базу данных Oracle, — речь идёт о файлах данных и журналов. Также там хранится важная информация о содержимом и состоянии БД Oracle. Что это за информация: • имя базы данных Oracle; • время создания БД; • имена и местонахождение журнальных файлов и файлов данных; • информация о табличных пространствах; • информация об архивных журналах; • история журналов, порядковый номер текущего журнала; • информация о файлах данных в автономном режиме; • информация о резервных копиях, контрольных точках, копиях файлов данных.
При этом функция управляющих файлов не ограничивается хранением важной информации, нужной при запуске экземпляра, — полезны они и в процессе удалении БД Oracle. К примеру, уже с версии Oracle Database 10g можно посредством команды DROP DATABASE удалить все файлы, которые перечислены в управляющем файле БД, включая сам управляющий файл.
Инициализация СУБД Oracle
Когда вы запускаете экземпляр Oracle, происходит считывание параметров инициализации. Параметры определяют, каким образом базе данных Oracle следует использовать физическую инфраструктуру и прочую конфигурационную информацию об экземпляре.
Как правило, инициализационные параметры хранятся в файле параметров инициализации экземпляра (обычно это INIT.ORA) либо, начиная с Oracle9i, в репозитории, называемом файлом параметров сервера (SPFILE). С выходом каждой новой версии Oracle число обязательных параметров инициализации уменьшается.
Кстати, в дистрибутиве Oracle можно найти пример файла инициализации, который пригоден для запуска базы данных. Также можно воспользоваться специальной программой Database Configuration Assistant (DCA) — она подскажет обязательные значения.
Более подробную информацию смотрите в официальной документации для СУБД Oracle Database.
Читайте также: