
Какой разделитель используется по умолчанию в файле загрузки параметров посетителей
Обновлено: 30.06.2024
Быстрый и практический пример использования файлов data.sql и schema.sql в Spring Boot.
1. Обзор
Spring Boot позволяет очень легко управлять изменениями в нашей базе данных. Если мы оставим конфигурацию по умолчанию, она будет искать сущности в наших пакетах и автоматически создавать соответствующие таблицы.
Но иногда нам понадобится более тонкий контроль над изменениями в базе данных. Именно тогда мы сможем использовать файлы data.sql и schema.sql весной.
2. Файл data.sql
Давайте также предположим, что мы работаем с JPA – и определим простую Страну сущность в нашем проекте:
Если мы запустим наше приложение, Spring Boot создаст для нас пустую таблицу, но не заполнит ее ничем.
Простой способ сделать это-создать файл с именем data.sql:
Когда мы запустим проект с этим файлом в пути к классу, Spring подберет его и использует для заполнения базы данных.
3. Файл schema.sql
Иногда мы не хотим полагаться на механизм создания схемы по умолчанию. В
Иногда мы не хотим полагаться на механизм создания схемы по умолчанию. В
Также важно не забыть отключить автоматическое создание схемы, чтобы избежать конфликтов:
4. Управление Созданием Базы Данных С Помощью Hibernate
4. Управление Созданием Базы Данных С Помощью Hibernate
Стандартные значения свойств Hibernate: create , update
- Стандартные значения свойств Hibernate: create
- , update
- update – объектная модель, созданная на основе сопоставлений (аннотаций или XML), сравнивается с существующей схемой, а затем Hibernate обновляет схему в соответствии с различием. Он никогда не удаляет существующие таблицы или столбцы, даже если они больше не требуются приложению update
- – объектная модель, созданная на основе сопоставлений (аннотаций или XML), сравнивается с существующей схемой, а затем Hibernate обновляет схему в соответствии с различием. Он никогда не удаляет существующие таблицы или столбцы, даже если они больше не требуются приложению update
- – объектная модель, созданная на основе сопоставлений (аннотаций или XML), сравнивается с существующей схемой, а затем Hibernate обновляет схему в соответствии с различием. Он никогда не удаляет существующие таблицы или столбцы, даже если они больше не требуются приложению update
Spring Boot внутренне устанавливает значение этого параметра по умолчанию в create-drop , если диспетчер схем не был обнаружен, в противном случае none для всех остальных случаев.
Мы должны тщательно установить значение или использовать один из других механизмов для инициализации базы данных.
5. @Sql
Spring также предоставляет аннотацию @Sql — декларативный способ инициализации и заполнения нашей тестовой схемы.
Давайте посмотрим, как использовать аннотацию @Sql для создания
Атрибутами аннотации @Sql являются:
- config – локальная конфигурация для сценариев SQL. Мы описываем это в
- config – локальная конфигурация для сценариев SQL. Мы описываем это в config – локальная конфигурация для сценариев SQL. Мы описываем это в скрипты –
- мы можем объявить пути к файлам сценариев SQL, чтобы
Аннотацию @Sql | можно использовать на уровне класса или на уровне метода . Мы можем загрузить дополнительные данные, необходимые для конкретного тестового случая, аннотируя этот метод:
6. @SqlConfig
Мы можем настроить способ анализа и запуска сценариев SQL с помощью аннотации @SqlConfig .
@SqlConfig может быть объявлен на уровне класса, где он служит глобальной конфигурацией. Или его можно использовать для настройки конкретной аннотации @Sql .
Давайте рассмотрим пример, в котором мы указываем кодировку наших SQL-скриптов, а также режим транзакций для выполнения скриптов:
И давайте рассмотрим различные атрибуты @SqlConfig :
7. @SqlGroup
Java 8 и выше позволяют использовать повторяющиеся аннотации. Эта функция также может быть использована для @Sql аннотаций. Для Java 7 и ниже существует аннотация контейнера — @SqlGroup . Используя аннотацию @SqlGroup , мы можем объявить несколько @Sql аннотаций:
8. Заключение
В этой краткой статье мы рассмотрели, как мы можем использовать файлы schema.sql и data.sql для настройки начальной схемы и заполнения ее данными. Мы также видели, как мы можем использовать @Sql, @SqlConfig и @SqlGroup аннотации для загрузки тестовых данных для тестов.
Имейте в виду, что этот подход больше подходит для базовых и простых сценариев, любая расширенная обработка базы данных потребует более продвинутых и усовершенствованных инструментов, таких как Liquibase или Flyway .

Чтобы маркетологу использовать инструментарий, потребуется подготовить файл со списком контактов и загрузить таблицу в Аудитории. Однако, загрузка часто сопровождается ошибками, решение которых не очевидно. Попробуем разобрать популярные ошибки и подготовить файл к загрузке.
Какие ошибки загрузки файлов встречаются
Встречаются две ошибки при загрузке списка с электронными адресами и телефонами:
- Ошибка валидации заголовка в файле CRM сегмента;
- Количество корректных уникальных элементов меньше, чем 1000.
В первом случае предупреждение возникает когда некорректно указан разделитель столбцов или используется неверный формат заголовков столбцов. В записи должно быть хотя бы одно из полей phone или email, а поля записи отделяются друг от друга запятой.
Какие требования Яндекс предъявляет к файлам
Требования к файлам Яндекс описал в официальной справке. Коротко перечислим их и мы:
- Формат файла — CSV;
- Максимальный размер — 1 Гб;
- Требования к формату записей: в первой строке указываются названия полей, отделенные запятой;
- Обязательные поля в записях: phone или email;
- Количество записей — от 1000;
- Кодировка файла — UTF-8 или Windows-1251.
Как должен выглядеть правильный список контактов
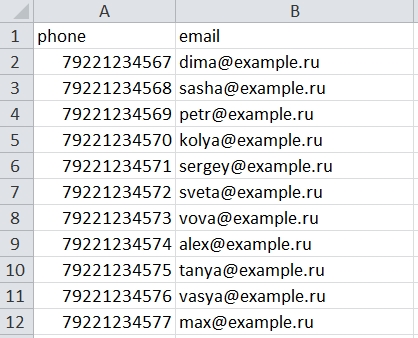
Первый вариант устранения проблемы на Windows 10 записан на скринкасте. Ниже найдете подробный путь до нужных настроек.
- В Windows 10: Настройка языка → Дата и время → Формат даты, времени и региона → Дополнительные параметры даты и времени → Изменение форматов даты, времени и чисел → Дополнительные параметры.
- В Windows 7: Панель управления → Часы, язык и регионы → Изменение форматов даты, времени и чисел → Дополнительные параметры.
В поле Разделитель элементов списка вместо точки с запятой укажите запятую и примените настройки.
После сохранения вернитесь к исходному файлу с контактами и пересохраните файл в CSV формате еще раз. Если все хорошо, то загрузка списка на сервер Яндекса пройдет без ошибок.
Если же метод не помог и ошибка никуда не делась, то рекомендую открыть документ программой Notepad++ (или стандартным блокнотом Windows) и проверить корректность написания заголовков и разделителей столбцов.
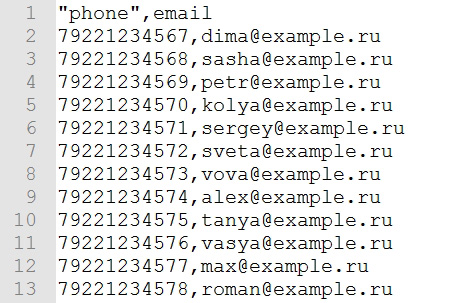
Не забудьте перепроверить корректность разделения столбцов. Во всех строках значения должны разделяться только запятой, но никак не точкой с запятой.
Если все верно, то сохраняйте файл с данными и загрузите ещё раз в Аудитории. Уверен, что теперь все получится.
Загрузить список в формате XLSX получится?
К сожалению, нет. Формат файлов табличного типа XLSX не подойдет для загрузки контактов в Яндекс.Аудитории. Причины очевидны:
Заключение
Статья получилась объемной, поэтому в заключение выделю главные правила работы со списками в Яндекс.Аудиториях.
Надеюсь, что материал оказался полезным. Если остались вопросы, то пишите в комментариях ниже. И не забывайте делиться ссылкой с коллегами.

В марте 2018 года Яндекс объединил сегменты «Адреса электронной почты» и «Номера мобильных телефонов» для Яндекс.Аудиторий в один — «Данные из CRM». Это позволяет сократить время на создание файла, так как теперь не нужно формировать два отдельных списка, всю информацию можно загрузить в один файл. Также благодаря тому, что в файле теперь больше данных, рекламодателю проще набрать минимальный охват — 1000 записей.
Читайте и смотрите по теме:
Готовим файл для загрузки
Для создания сегмента понадобится файл с контактами клиентов. Он должен соответствовать требованиям:
в первой строке пишутся названия столбцов: phone и email;
в каждой строке можно разместить запись об одном клиенте;
формат номера телефона — 79657777777 для российских номеров, для других стран семерка в начале номера меняется на соответствующую цифру, начинать номер с восьмерки или со знака «+» нельзя;
Теперь согласно этим требованиям создаем таблицу в Excel.

Сохраняем таблицу в формате «CSV (разделители — запятые)».
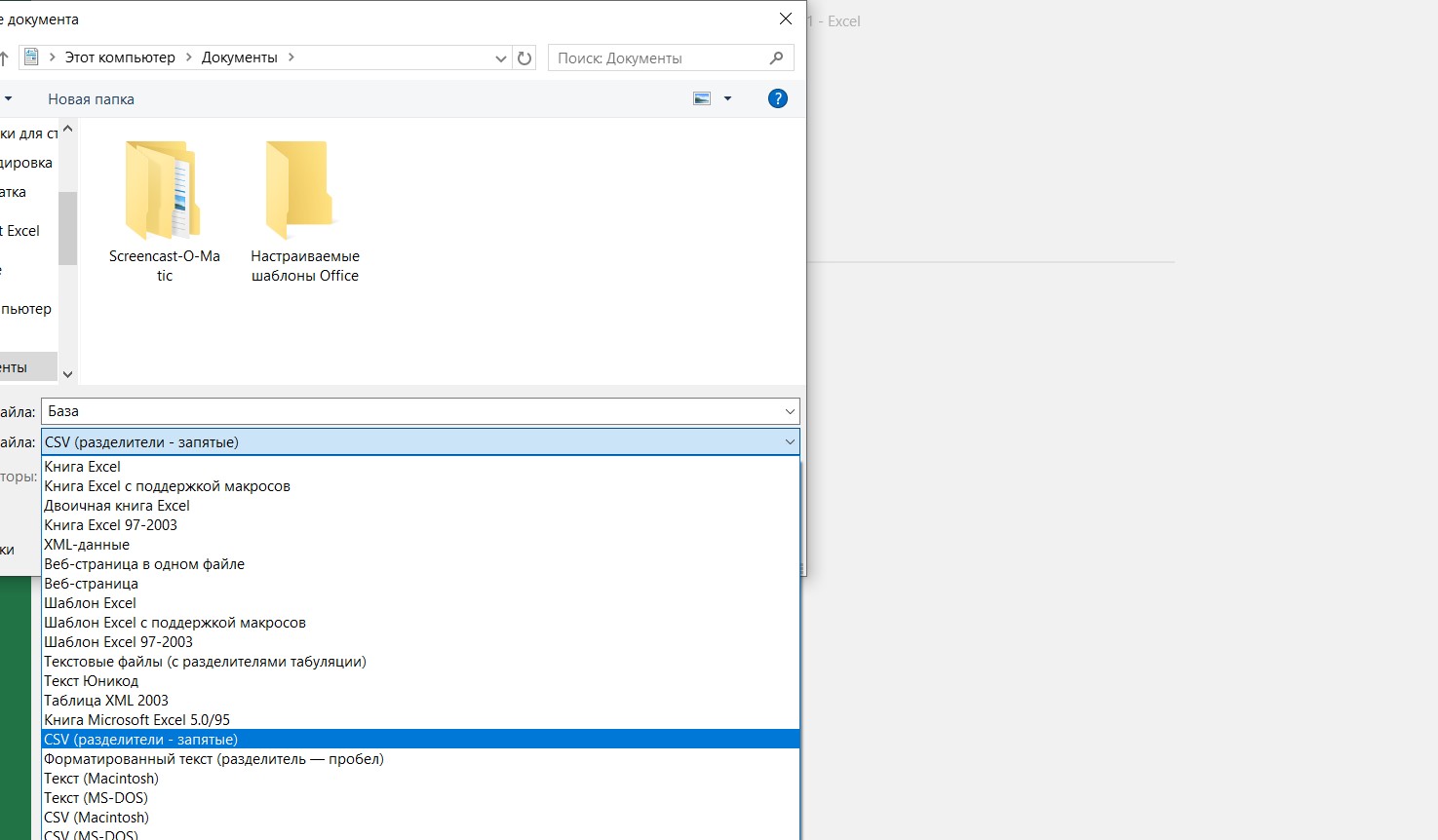
Загружаем файл в систему
Переходим в Яндекс.Аудитории, нажимаем «Создать сегмент» — «Данные CRM».

Даем название сегменту, загружаем нужный файл и ставим чекбоксы.

Нажимаем «Создать сегмент», и, казалось бы, все должно работать. Но система выдает такую ошибку.

Почему возникает эта ошибка? Дело в том, что в большинстве систем Windows в Российской Федерации при сохранении файла в формате «CSV (разделители — запятые)» сохраняется не запятая, а точка с запятой.
Проверьте это, открыв файл в программе «Блокнот». Скорее всего вы увидите эту ошибку — точку с запятой вместо обычной запятой.

Исправляем ошибку
Зайдите в «Настройки языка» в своем компьютере.

Затем перейдите в раздел «Сопутствующие параметры» — «Форматы даты, времени и региона».

После этого переходим в «Региональные параметры» — «Региональные стандарты».


В разделе «Региональные стандарты» находим пункт «Дополнительные параметры».

Здесь нас интересуют два выделенных пункта.

Меняем разделитель — вместо точки с запятой ставим запятую. Также нужно поменять разделитель целой и дробной части, иначе запятая будет использоваться в обоих выделенных пунктах и система не сможет работать корректно. Вместо запятой ставим точку. Сохраняем изменения нажав «Применить» — OK.
Снова заходим в Excel, сохраняем тот же файл в формате «CSV (разделители — запятые)». Проверяем файл в «Блокноте».

Теперь все отображается корректно. Переходим в Яндекс.Аудитории, загружаем файл и создаем сегмент. Если в файле не менее 1000 записей, система не выдает ошибку и загружает сегмент. Он отправится на обработку, обычно она занимает не более двух часов.
Если в файле менее 1000 записи, система вам об этом сообщит.

После обработки сегмента вы увидите охват сегмента, тип данных («Данные CRM») и статус «Готов». Охват может быть больше, чем количество записей в файле. Это связано с тем, что показатель отражает количество анонимных идентификаторов пользователей. У одного пользователя может быть несколько устройств и несколько браузеров, а подсчет охвата производится по файлам cookie.
Несколько рекомендаций по использованию данных CRM
Вот несколько простых правил, которые помогут сделать работу с данными CRM более эффективной.
Пополняйте базу: собирайте контакты пользователей на сайте, в соцсетях и офлайн. Как? Читайте в нашем материале.
По возможности сегментируйте базу. Так вы сможете создать более персонализированное предложение.
Выбирайте сегменты в качестве аудиторий ретаргетинга для показа в РСЯ.
Задавайте корректировки ставок по сегментам на поиске или в РСЯ. Для этого нужно создать в Директе аудиторию ретаргетинга на основе этого сегмента, а затем при настройке кампаний задать корректировку. Например, можно задать корректировку −100% для пользователей, которые уже совершили покупку, чтобы не показывать им рекламу.
Создавайте похожие сегменты. Это можно сделать в Яндекс.Аудиториях, выбрав «Похожий сегмент» и указав сегмент на основе данных CRM в качестве исходного.
Яндекс.Метрика опубликовала руководство по офлайн-загрузке параметров посетителей. Этот способ позволяет добавить в отчеты те данные, которые уже есть в вашей базе: например, доход на клиента или уровень лояльности.
Чтобы Метрика могла определить, какому посетителю записать новые атрибуты, необходимо связать данные из вашей базы и данные в Метрике — присвоить им общий идентификатор.
Существует два способа:
- передать в Метрику ваши идентификаторы клиентов (UserID);
- или внести в вашу CRM уникальные номера посетителей из Метрики (ClientID).
Связка по UserID: если у вас есть собственные идентификаторы клиентов
Этап 1. Учим Метрику узнавать клиентов
Чтобы начать передавать в Метрику идентификаторы авторизованных посетителей (UserID), нужно добавить на сайт код, который будет подставлять эти идентификаторы в метод setUserID:
Идентификаторы UserID не будут показываться в отчетах: они сохранятся в базе данных Метрики в качестве ключей, которые позволят сопоставить посетителей в Метрике и клиентов в вашей CRM.
UserID можно передавать не только для авторизованных посетителей. Уникальный идентификатор также можно забирать из «меченой» ссылки, которую вы отправляли вашим клиентам по почте, или из реферера соцсетей. Также в качестве UserID подойдёт номер дисконтной карты или промо-код, который посетители вводят на сайте.
Этап 2. Загружаем данные
После того, как UserID переданы в Метрику, нужно подготовить файл с атрибутами клиентов, которые нужно добавить в отчеты. Это таблица в формате csv с тремя столбцами:
- в первом — UserID, который послужит ключом для связки данных в файле и в Метрике,
- во втором — название параметра,
- в третьем — его значение.
Вот как может выглядеть этот файл:


Когда файл будет обработан, в интерфейсе вы увидите уведомление:

Статус «Выполнено (80% привязки)» означает, что переданные UserID нашлись в Метрике для 80% клиентов из файла. Чаще всего данные привязываются не полностью из-за того, что не все клиенты успели побывать на сайте — а значит, их UserID еще не переданы, и Метрика не знает, каким посетителям записывать атрибуты из таблицы. Поэтому параметры будут добавлены только для 80% «привязанных» посетителей — об этом полезно помнить, интерпретируя данные в отчётах.
Связка по ClientID: если своих идентификаторов посетителей нет
ClientID — это номер, который Метрика присваивает каждому посетителю. Его можно использовать в качестве ключа для объединения данных, если на сайте нет собственной системы идентификаторов — или же если клиенты регистрируются редко, а заказы обычно делают по телефону.
Чтобы забирать ClientID из Метрики, добавьте на сайт код, который будет вызывать метод getClientID и записывать полученное значение в вашу CRM:
Когда достаточное количество посетителей побывает на сайте и вы получите их ClientID, можно будет сформировать csv-таблицу с атрибутами клиентов. Она будет выглядеть так же, как в примере с UserID, только на этот раз в первом столбце в качестве ключа для склейки посетителей будет использоваться ClientID. И при загрузке таблицы в Метрику также нужно будет выбрать тип файла «Сlient_ID».
Как обновить или удалить загруженные данные
Чтобы в отчетах начали показываться новые значения параметров, нужно загрузить актуальный файл. А если нужно удалить данные, в том же меню для загрузки данных выберите вариант «Удалить» — и передать файл с пустыми значениями параметров:
Загрузка такого файла не обнуляет значения параметров, а именно удаляет их. То есть если вы когда-то передали количество покупок на клиента, а затем загрузили пустой файл, параметр offline-purchase просто пропадет из отчетов, а не станет равным нулю.
Что лучше выбрать — онлайн или офлайн передачу параметров посетителей?
С помощью метода userParams имеет смысл отправлять те данные, которые возникают только в онлайне — и при этом вам не нужно хранить их в своей базе. Этот способ также подойдёт интернет-изданиям или блогам, у которых нет CRM.
Другое важное отличие — скорость обновления данных в отчетах. Когда вы наладите работу с методами setUserID или getClientID и большинство ваших клиентов хотя бы раз зайдут на сайт, новые данные в отчетах будут появляться сразу после загрузки актуального файла — а не после того, как клиент вернется на сайт.
Читайте также: