
Место где постоянно обновляется информация в интернете о местонахождении web страниц и файлов это
Обновлено: 05.07.2024
Тематические коллекции ссылок - это списки, составленные группой профессионалов или даже коллекционерами-одиночками. Очень часто узкоспециализированная тема может быть раскрыта одним специалистом лучше, чем группой сотрудников крупного каталога. Тематических коллекций в Сети так много, что давать конкретные адреса не имеет смысла.
Подбор доменного имени
Поисковые машины
Скажи мне, что ты ищешь в Интернете, и я скажу, кто ты
Если бы компьютер был высокоинтеллектуальной системой, которой можно было легко объяснить, что вы ищете, то он выдавал бы два-три документа - именно те, которые вам нужны. Но, к сожалению, это не так, и в ответ на запрос пользователь обычно получает длинный список документов, многие из которых не имеют никакого отношения к тому, о чем он спрашивал. Такие документы называются нерелевантными (от англ. relevant - подходящий, относящийся к делу). Таким образом, релевантный документ - это документ, содержащий искомую информацию. Очевидно, что от умения грамотно выдавать запрос зависит процент получаемых релевантных документов. Доля релевантных документов в списке всех найденных поисковой машиной документов называется точностью поиска. Нерелевантные документы называют шумовыми. Если все найденные документы релевантные (шумовых нет), то точность поиска составляет 100%. Если найдены все релевантные документы, то полнота поиска - 100%.
Таким образом, качество поиска определяется двумя взаимозависимыми параметрами: точностью и полнотой поиска. Увеличение полноты поиска снижает точность , и наоборот.
Как работает поисковая машина
Поисковые системы можно сравнить со справочной службой, агенты которой обходят предприятия, собирая информацию в базу данных (рис. 4.21). При обращении в службу информация выдается из этой базы. Данные в базе устаревают, поэтому агенты их периодически обновляют. Некоторые предприятия сами присылают данные о себе, и к ним агентам приезжать не приходится. Иными словами, справочная служба имеет две функции: создание и постоянное обновление данных в базе и поиск информации в базе по запросу клиента.

Рис. 4.21. Поисковые системы можно сравнить со справочной службой, агенты которой обходят предприятия, собирая информацию в базу данных
Аналогично, поисковая машина состоит из двух частей: так называемого робота (или паука), который обходит серверы Сети и формирует базу данных поискового механизма.
База робота в основном формируется им самим (робот сам находит ссылки на новые ресурсы) и в гораздо меньшей степени - владельцами ресурсов, которые регистрируют свои сайты в поисковой машине. Помимо робота (сетевого агента, паука, червяка), формирующего базу данных, существует программа , определяющая рейтинг найденных ссылок.
Принцип работы поисковой машины сводится к тому, что она опрашивает свой внутренний каталог (базу данных) по ключевым словам, которые пользователь указывает в поле запроса, и выдает список ссылок, ранжированный по релевантности .
Следует отметить, что, отрабатывая конкретный запрос пользователя, поисковая система оперирует именно внутренними ресурсами (а не пускается в путешествие по Сети, как часто полагают неискушенные пользователи), а внутренние ресурсы, естественно, ограниченны. Несмотря на то что база данных поисковой машины постоянно обновляется, поисковая машина не может проиндексировать все Web-документы: их число слишком велико. Поэтому всегда существует вероятность , что искомый ресурс просто неизвестен конкретной поисковой системе.
Эту мысль наглядно иллюстрирует рис. 4.22. Эллипс 1 ограничивает множество всех Web-документов, существующих на некоторый момент времени, эллипс 2 - все документы, которые проиндексированы данной поисковой машиной, а эллипс 3 - искомые документы. Таким образом, найти с помощью данной поисковой машины можно лишь ту часть искомых документов, которые ею проиндексированы.
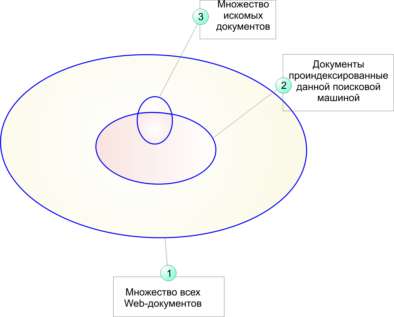
Проблема недостаточности полноты поиска состоит не только в ограниченности внутренних ресурсов поисковика, но и в том, что скорость робота ограниченна, а количество новых Web-документов постоянно растет. Увеличение внутренних ресурсов поисковой машины не может полностью решить проблему, поскольку скорость обхода ресурсов роботом конечна.
При этом считать, что поисковая машина содержит копию исходных ресурсов Интернета, было бы неправильно. Полная информация (исходные документы) хранится отнюдь не всегда, чаще хранится лишь ее часть - так называемый индексированный список , или индекс , который гораздо компактнее текста документов и позволяет быстрее отвечать на поисковые запросы.
Для построения индекса исходные данные преобразуются так, чтобы объем базы был минимальным, а поиск осуществлялся очень быстро и давал максимум полезной информации. Объясняя, что такое индексированный список , можно провести параллель с его бумажным аналогом - так называемым конкордансом, т.е. словарем, в котором в алфавитном порядке перечислены слова, употребляемые конкретным писателем, а также указаны ссылки на них и частота их употребления в его произведениях.
Очевидно, что конкорданс (словарь) гораздо компактнее исходных текстов произведений и найти в нем нужное слово намного проще, нежели перелистывать книгу в надежде наткнуться на нужное слово .
Построение индекса
Схема построения индекса показана на рис. 4.23. Сетевые агенты, или роботы-пауки, "ползают" по Сети, анализируют содержимое Web-страниц и собирают информацию о том, что и на какой странице было обнаружено.
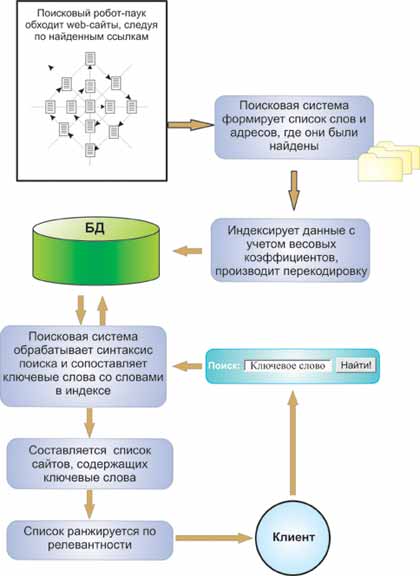
Рис. 4.23. Роботы-пауки просматривают информационное наполнение Web-страниц и создают базу, на основе которой производится поиск
При нахождении очередной HTML-страницы большинство поисковых систем фиксируют слова, картинки, ссылки и другие элементы (в разных поисковых системах по-разному), содержащиеся на ней. Причем при отслеживании слов на странице фиксируется не только их наличие, но и местоположение, т.е. где эти слова находятся: в заголовке (title), подзаголовках ( subtitles ), в метатэгах 1 Метатэги - это служебные тэги, позволяющие разработчикам помещать на Web-страницы служебную информацию, в том числе для того, чтобы сориентировать поисковую машину. ( meta tags ) или в других местах. При этом обычно фиксируются значимые слова, а союзы и междометия типа "а", "но" и "или" игнорируются. Метатэги позволяют владельцам страниц определить ключевые слова и тематику, по которым индексируется страница. Это может быть актуально в случае, когда ключевые слова имеют несколько значений. Метатэги могут сориентировать поисковую систему при выборе из нескольких значений слова на единственно правильное. Однако метатэги работают надежно только в том случае, когда заполняются честными владельцами сайта. Недобросовестные владельцы Web-сайтов помещают в свои метатэги наиболее популярные в Сети слова, не имеющие ничего общего с темой сайта. В результате посетители попадают на незапрашиваемые сайты, повышая тем самым их рейтинг. Именно поэтому многие современные поисковики либо игнорируют метатэги, либо считают их дополнительными по отношению к тексту страницы. Каждый робот поддерживает свой список ресурсов, наказанных за недобросовестную рекламу.
Очевидно, что если вы ищете сайты по ключевому слову "собака", то поисковый механизм должен найти не просто все страницы, где упоминается слово "собака", а те, где это слово имеет отношение к теме сайта. Для того чтобы определить, в какой степени то или иное слово имеет отношение к профилю некоторой Web-страницы, необходимо оценить, насколько часто оно встречается на странице, есть ли по данному слову ссылки на другие страницы или нет. Короче говоря, необходимо ранжировать найденные на странице слова по степени важности. Словам присваиваются весовые коэффициенты в зависимости от того, сколько раз и где они встречаются (в заголовке страницы, в начале или в конце страницы, в ссылке, в метатэге и т.п.). Каждый поисковый механизм имеет свой алгоритм присваивания весовых коэффициентов - это одна из причин, по которой поисковые машины по одному и тому же ключевому слову выдают различные списки ресурсов. Поскольку страницы постоянно обновляются, процесс индексирования должен выполняться постоянно. Роботы-пауки путешествуют по ссылкам и формируют файл, содержащий индекс, который может быть довольно большим. Для уменьшения его размеров прибегают к минимизации объема информации и сжатию файла. Имея несколько роботов, поисковая система может обрабатывать сотни страниц в секунду. Сегодня мощные поисковые машины хранят сотни миллионов страниц и получают десятки миллионов запросов ежедневно.
При построении индекса решается также задача снижения количества дубликатов - задача нетривиальная, учитывая, что для корректного сравнения нужно сначала определить кодировку документа. Еще более сложной задачей является отделение очень похожих документов (их называют "почти дубликаты"), например таких, в которых отличается лишь заголовок, а текст дублируется. Подобных документов в Сети очень много - например, кто-то списал реферат и опубликовал его на сайте за своей подписью. Современные поисковые системы позволяют решать подобные проблемы.

развитие познавательных интересов, навыков работы в сети Интернет и на компьютере.
Воспитательные:
осуществлять нравственное и эстетическое воспитание, воспитывать любовь к своей малой родине.
Методы обучения: объяснительно-иллюстративный, частично-поисковый.
Тип урока: объяснение нового материала; практическая работа.
Ход урока.
1.Оргмомент. Повторить технику безопасности. (Слайд1).
(Слайд 2). Здравствуйте ребята. Сегодняшнее занятие мне хотелось бы начать стихами Щербаковой Лолиты:
В современной нашей формации
Не прожить нам без информации,
А ее — огромный поток!
Информацию я встречу, даже если не хочу,
В школе, дома, на прогулке ее везде я получу.
Даже если ты не хочешь ее в школе добывать,
Пообщаешься с друзьями – знаешь их уже на «пять»,
Информация – подруга, информация – сестра,
Без тебя нам будет туго, а с тобою жизнь светла!
Информация повсюду в общем доступе лежит,
Стать всезнайкой очень просто – только руку протяни.
Сегодня мы с вами будем учиться находить нужную нам информацию среди сотен миллиардов Web – страниц и сотен миллионов файлов. (Слайд 3).
Тема сегодняшнего урока: «Поиск информации в Интернете»
Как называются программы для работы в Интернете?
Назовите самый распространенный браузер?
На каком языке пишется имя сайта?
Сочетание каких клавиш позволяет осуществить переход с английского на русский язык и наоборот?

3. Объяснение нового материала.
Для поиска информации используются специальные поисковые системы, которые содержат постоянно обновляемую информацию о местонахождении и файлов на сотнях миллионов серверов Интернета. Поисковые системы содержат тематически сгруппированную информацию об информационных ресурсах Всемирной паутины в базах данных. Специальные программы – роботы периодически «обходят» Web – серверы Интернета, читают все встречающиеся документы, выделяют в них ключевые слова и заносят в базу данных Интернет – адреса документов. Большинство поисковых систем разрешают автору Web – сайта самому внести информацию в базу данных, заполнив регистрационную анкету. В процессе заполнения анкеты разработчик сайта вносит адрес сайта, его название, краткое описание содержания сайта, а также ключевые слова , пол которым легче всего будет найти сайт. (Слайд 4).
1) Поиск по ключевым словам. Поиск документа в базе данных поисковой системы осущетвляется с помощью введения запроса в поле поиска. Запрос должен содержать одно или несколько ключевых слов, которые являются главными для этого документа. (Слайд 5). Через некоторое время после отправки запроса поисковая система вернет список Интернет – адресов документов, в которых были найдены указанные ключевые слова. Для просмотра такого документа в браузере достаточно активизировать указывающую на него ссылку. Если ключевые слова были выбраны неудачно, то список адресов документов может быть слишком большим. (Слайд 6).Для того чтобы уменьшить список, можно в поле поиска ввести дополнительные ключевые слова или воспользоваться каталогом поисковой системы. (Слайд 7 - 9). Одной из наиболее полных и мощных поисковых систем является Google, в базе данных которой хранятся 8 миллиардов Web- страниц, и каждый месяц программы роботы заносят в нее 5 миллионов новых страниц. В Рунете обширные базы данных, содержащие по 200 миллионов документов, имеют поисковые системы Яндекс и Rambler.
2) Поиск в иерархической системе каталогов. (Слайд 10).
В базе данных поисковой системы Web – сайты группируются в иерархические тематические каталоги, которые являются аналогами тематического каталога в библиотеке. Тематические разделы верхнего уровня, например «Интернет» , «Компьютеры», «Наука и образование»…, содержат вложенные каталоги. Например, каталог «Интернет» может содержать подкаталоги «Поиск», «Почта»… (Слайд 11). Поиск информации в каталоге сводится к выбору определенного каталога, после чего пользователю будет представлен список ссылок на Интернет – адреса наиболее посещаемых и содержательных Web – сайтов. Каждая ссылка обычно аннотирована, т.е. содержит короткий комментарий к содержанию документа. (Слайд 12). Наиболее полный многоуровневый иерархический тематический каталог русскоязычных Интернет – ресурсов имеет поисковая система Апорт. (Слайд 13).
3) Поиск файлов. Для поиска файлов на серверах файловых архивов существуют специализированные поисковые системы, в том числе российская файловая поисковая система FileSearch. Для поиска файла необходимо имя файла ввести в поле поиска, и поисковая система выдаст Интернет – адреса серверов файловых архивов, на которых хранится файл с заданным именем. (Слайд 14).
4. Практическая работа: (Слайд 16).
Я люблю свой край зеленый -
Сказку майскую полей,
У крыльца густые клены, теплый иней тополей.
Я люблю родное небо -
Над равниной синий зонт,
запах дыма, запах хлеба
И в лугах ромашек звон
Рядом с речкой вьётся ловко
Путь дорога без конца.
Прохожу я мимо сада -
Листья словно в серебре.
До чего же сердце радо
Потому то, утром синим
Мне дорога так легка.
Мы в пути с моей Россией
Не на годы - на века.
Ну а сейчас вы на практике закрепите полученную информацию.
Вам предстоит найти в Интернете информацию о городе Красный Холм и краснохолмском районе и найденный материал оформить в виде буклета, используя приложение Microsoft Office Publisher 2007.
В конце урока мы посмотрим, у кого что получилось.
5. Домашнее задание: п. 3.5 страница 107 – 110 читать ответить на вопросы. (Слайд 15).
6. Подведение итогов. Выставление оценок. Сегодня на уроке вы познакомились со способами поиска информации в Интернете. Освежили в памяти страницы истории родного города, родного края, который является частицей большой страны под названием Россия.
Использованная литература:
Учебник Н.Д.Угринович «Информатика и икт 8 класс» 2009, БИНОМ. Лаборатория знаний, 2009.

Я зарегистрировался на форуме под псевдонимом. Сложно ли меня найти?
Не сложно! Интернет не анонимен! Допустим, вы зарегистрировались под «левым» ником на форуме и написали там что-то резкое в адрес одного из неадекватных посетителей этого форума. Или же вы ведете свой блог под псевдонимом и критикуете власти вашей страны. Сложно ли найти вас? Надежно ли защищены ваши настоящие фамилия и имя, телефон и домашний адрес?
Если вы думаете, что Интернет анонимен, и если вы зарегистрировались под «левым» ником и выходите в Интернет только под псевдонимом, то можете делать в Интернете все, что угодно, и вас никто не найдет, то вы глубоко заблуждаетесь. Это совсем не так!
Забегая вперед скажу, что если вы хотите быть невидимым в Интернете, то вам необходимо использовать браузер Tor или VPN-сервис о чем подробно написано в этой статье.
Когда провайдер присваивает вашему компьютеру IP-адрес, то у себя в специальных лог-файлах отмечает (служебных текстовых файлах, которые сокращенно называют логами), что такой-то клиент с таким-то IP-адресом работал в Интернете в такое-то время. Все эти операции выполняются автоматически серверами провайдера (специально настроенными мощными компьютерами). Провайдер ведет записи обо всех посещенных вами веб-сайтах, а также совершенных операциях. Серверы, на которых расположены веб-сайты, которые вы посещаете, тоже записывают в своих логах IP-адреса посетителей и информацию о совершенных ими действиях.
Таким образом, посетитель форума или представитель власти, которых вы «задели», может обратиться лично, через суд или через другие компетентные органы к владельцу форума, и владелец форума сообщит ваш IP-адрес, по которому легко определить вашего провайдера. После чего будет отправлен запрос провайдеру, в ответ на который провайдер сообщит ваши Ф.И.О., адрес и телефон. Конечно, в разных странах совершенно разное законодательство и, возможно, провайдер не даст эту информацию первому встречному, все зависит от того, как составлен запрос, по какому он поводу, но в любом случае ваш интернет-провайдер не сможет отказаться сообщить информацию компетентным органам. Да, все это займет некоторое время, но в конечном счете узнать кто вы, ваши имя и фамилию, адрес и телефон не так уж и сложно. Вот краткая сводка мест, где сохраняется информация о ваших действиях в Интернете:
Где и какая сохраняется информация о вас и посещаемых вами веб-сайтах?
Сервер вашего интернет-провайдера имеет такой же объем информации о вас, что и серверы, на которых расположены посещаемые вами веб-сайты (смотрите список выше), так как вся эта информация проходит через него.
Хакеры, находящиеся с вами в одной сети, могут перехватывать передающиеся в сети данные, увидеть кто и какие веб-сайты посещает, даже прочесть вашу электронную почту. И для этого совсем необязательно быть «хакером», достаточно просто бесплатно скачать в Интернете и установить специальную программу. Таких программ полно в Интернете и для их использования не нужно обладать какими-то специальными знаниями.
Поиско́вая систе́ма (англ. search engine ) — это компьютерная система, предназначенная для поиска информации.
Поисковая система — программно-аппаратный комплекс с веб-интерфейсом, предоставляющий возможность поиска информации в интернете.
Характеристики поисковых систем
Полнота – одна из основных характеристик поисковой системы, представляющая собой отношение количества найденных по запросу документов к общему числу документов в сети Интернет, удовлетворяющих данному запросу. К примеру, если в Интернете имеется 100 страниц, содержащих словосочетание «как выбрать автомобиль», а по соответствующему запросу было найдено всего 60 из них, то полнота поиска будет 0,6. Очевидно, что чем полнее поиск, тем меньше вероятность того, что пользователь не найдет нужный ему документ, при условии, что он вообще существует в Интернете.
Точность – еще одна основная характеристика поисковой машины, которая определяется степенью соответствия найденных документов запросу пользователя. Например, если по запросу «как выбрать автомобиль» находится 100 документов, в 50 из них содержится словосочетание «как выбрать автомобиль», а в остальных просто наличествуют эти слова («как правильно выбрать магнитолу и установить в автомобиль»), то точность поиска считается равной 50/100 (=0,5). Чем точнее поиск, тем быстрее пользователь найдет нужные ему документы, тем меньше различного рода «мусора» среди них будет встречаться, тем реже найденные документы не будут соответствовать запросу.
Скорость поиска тесно связана с его устойчивостью к нагрузкам. Например, по данным ООО «Рамблер Интернет Холдинг», на сегодняшний день в рабочие часы к поисковой машине Рамблер приходит около 60 запросов в секунду. Такая загруженность требует сокращения времени обработки отдельного запроса. Здесь интересы пользователя и поисковой системы совпадают: посетитель желает получить результаты как можно быстрее, а поисковая машина должна отрабатывать запрос максимально оперативно, чтобы не тормозить вычисление следующих запросов.
Наглядность представления результатов является важным компонентом удобного поиска. По большинству запросов поисковая машина находит сотни, а то и тысячи документов. Вследствие нечеткости составления запросов или неточности поиска, даже первые страницы выдачи не всегда содержат только нужную информацию. Это означает, что пользователю зачастую приходится производить свой собственный поиск внутри найденного списка. Различные элементы страницы выдачи поисковой системы помогают ориентироваться в результатах поиска.
На серверах поисковых служб есть специальные программы (их называют роботами или пауками), которые собирают информацию в Интернете и возвращают на свой сервер все обнаруженные страницы. Из накопленной таким образом информации формируются базы, особым образом проиндексированные.
Основные задачи поисковых серверов:
■ находить новые сайты и вносить их в собственную базу данных (хранилище) адресов;
■ ранжировать сайты в базе данных и делать результаты поиска наиболее соответствующими запросам пользователей.
Поисковые системы стремятся предоставлять пользователям наиболее релевантные результаты поиска.
Примечание. Релевантность (от англ. relevancy) - степень соответствия документа запросу. Релевантность документа запросу пользователя определяется в соответствии с заложенным в поисковую систему .алгоритмом. Алгоритмы у поисковых систем разные, однако построены они на общих принципах, поэтому ищут поисковые системы примерно одинаково. Основные отличия поисковых серверов заключаются не в алгоритмах определения релевантности, а в способах их реализации и хранилищах адресов.
При вводе запросов (ключевых слов) в поисковые серверы пользователь надеется быстро получить ссылки на нужные ресурсы. А поисковые серверы, в свою очередь, конкурируют между собой за выдачу наиболее точных результатов.
Поисковая система Google.
Среди множества поисковых систем с огромным отрывом лидирует Гугл. В 1998 году студенты Стэнфордского университета, Сергей Брин и Ларри Пейдж, создали эту систему. Сергей сделал ошибку в слове Googol (число 10 в 100 степени), так и возникло название Гугл. Сегодня Гугл является крупной поисковой системой и работает со 191 языками.
В народе бытует пословица «Гугл поможет всё найти». И это действительно так. Поисковик Google внес не только изменения в виртуальный мир, но и значительно расширил англоязычный и русскоязычный словарный запас. Это лидирующая мировая поисковая система в Интернете, принадлежащая корпорации Google Inc.
История начинается в далёком 1998 году, всё начиналось в тесной комнатушке студенческого общежития. Ныне этот поисковый магнат имеет представительства более, чем в сорока странах мира. Сердцем компании является Маутин-Вью, где находится её штаб-квартира.
В самом начале Ларри Пейдж и Сергей Брин начинали работу над поисковиком под названием BackRub. Отличительной особенностью этой системы был тот факт, что сайт является более важным, если на него ссылаются множество других ресурсов и наоборот. Позднее подобную систему ранжирования страниц стал использовать в своих алгоритмах и поисковик Google.
Трудно поверить в то, что менее, чем за 15 лет компания приобрела мировую известность, но это так.
Информацию пользователям поисковик Google предоставляет вследствие работы поискового робота, бота, который всю информацию о страницах заносит в свою базу данных. Компания разработала серию отдельных роботов, сканирующих определённые страницы сайтов. Так Гугл бот — Мобил используется для индексации мобильных устройств, Гугл бот — Image – работает с изображениями и картинками, Adsbot — Google производит оценку качества содержащейся информации на страницах веб-ресурсов. Все пользователи оценили удобство работы с данной поисковой системой и заметили, что она выдаёт самую актуальную и релевантную информацию. Однако веб-мастерам приходится немного «попотеть» продвигая ресурсы под эту поисковую систему.
Поисковик Google выдаёт перечень сайтов, выстраиваемых в зависимости от значения PR, веса страницы, зависящего от количества ссылаемых на страницу ресурсов и других важных показателей. Появилась «теория песочницы», говорящая о том, что домены с частой сменой владельцев и новыми именами помещаются в зону ожидания. Правдивость этой теории не была доказана, как, впрочем, и не было опровергнута.
Ещё одной легендой поисковика Google является «бонус новичков», основанная на том домысле, что при первоначальной индексации сайт занимает более высокие позиции благодаря завышенному показателю PR.
В Америке неоднократно разгорались скандалы вследствие нарушения поисковой системой авторских прав, однако Гугл всегда отстаивал свои позиции и жалобы Церкви саентологии и известной газеты The New York Times были отклонены.
Система имеет сложный язык запросов, однако именно это позволяет ограничивать поиск отдельными доменами, типами файлов или языками. При этом такой мощный механизм может одновременно применяться и хакерами для сканирования страниц на наличие слабых мест.
В 2009 году корпорация реализовала Википоиск, позволяющий всем желающим настроить результаты выдачи поисковых запросов. Пользователь получил возможность самостоятельно удалять или поднимать вверх результаты выдачи. Технология не прижилась и существовала всего полгода.
3 года назад новым функционалом российских пользователей порадовал поисковик Google: возможность поиска по голосу. Для этого возле строки поиска в телефоне следует нажать кнопку, произнести запрос, который впоследствии отправляется на сервер. Через время браузер выдаёт результаты поиска согласно распознанному запросу.
Поисковик Google обладает ещё одной функцией, с которой знакомы все, кто когда-либо пользовался поисковой системой. Логотип поисковика в праздники меняется со стандартного на тематический, но всегда в стиле Гугл. Патент на подобную опцию компании удалось получить после 10 лет ожидания. Компания в настоящее время поддерживает множество проектов, призванных сделать ещё более совершенным глобальную сеть.
Краткая характеристика Яндекс
Яндекс – самая крупная отечественная поисковая система. Дата основания – 23 сентября 1997г. В последнее время Яндекс активно выходит на международный уровень и уже имеет локализованные версии сервиса в Украине, Казахстане, Беларуси и Турции. Помимо поиска Яндекс предоставляет много дополнительных возможностей, в том числе, бесплатный хостинг Народ.ру, сервис для ведения блога Я.ру, почтовый сервис, рекламная сеть Яндекс Директ, и, кроме того, с недавнего времени Яндекс активно продвигает свой собственный браузер. Помимо основного поиска, Яндекс предоставляет возможность поиска по блогам, картинкам и видео.
В 2011 году был разработан и внедрен новый, метод машинного обучения «Матрикснет», который значительно улучшил качество поиска.
Кроме того, в 2011 году компания Яндекс разместила акции на американской бирже высоких технологий Nasdaq, что является знаковым событием для отечественных интернет-компаний.
В декабре 2012г. Был внедрен новый алгоритм «Калининград», который позволил сделать поиск персонализированным. Это значит, что теперь основным фактором ранжирования является сам пользователь, который формирует запрос для поисковой системы. Другими словами, результаты поиска по одному и тому же вопросу для двух разных пользователей теперь будет различаться в зависимости от нужд и предпочтений самих пользователей. Это новый шаг на пути эволюции поисковых систем.
Кроме того, среди нововведений Яндекса можно отметить:
- введение геозависимости запросов в зависимости от региональной принадлежности пользователя и сайта;
- учет поведенческих факторов;
- разработка механизма подсказок, исправления ошибок и распознавания аббревиатур;
- активная борьба с продажными ссылками и переоптимизированными текстами;
- введение персонализированного поиска;
- учет добавочной смысловой стоимости сайта.
Краткая характеристика Google
Общепризнанный лидер среди поисковых систем. Поисковая система появилась в 1996 году, и изначала предназначалась для поиска в картотеке библиотеки Стэнфорда. Корпорация Google была основана в 1998 году. В настоящий момент имеет более 100 региональных версий в различных странах. Кроме того, Google это не только поиск, но и еще более 50 различных сервисов, в том числе самый популярный браузер Google Chrome.
С этих двух самых популярных поисковых систем на сайт приходит больше всего посетителей, так что не теряй времени даром, и начинай продвигать свои запросы. Для того, чтобы определить на каком месте твой сайт находится сейчас, советую прочитать статью о том, как проверить позиции сайта в поисковых системах.
Несмотря на все возможности популярных поисковых систем, они не могут решить все проблемы. В частности, ими не всегда удобно пользоваться для поиска научной информации. Для этих целей существуют специальные научные поисковые системы.
Читайте также: