
Наиболее надежный способ обеспечения сохранности компьютерных баз данных это
Обновлено: 05.07.2024
Первая линия безопасности баз данных должна исходить от IT-отдела компании и от администраторов СУБД в частности. Базовая защита БД - это настройка межсетевых экранов перед СУБД, чтобы заблокировать любые попытки доступа от сомнительных источников, настройка и поддержание в актуальном состоянии парольной политики и ролевой модели доступа. Это действенные механизмы, которым должно уделяться внимание. Следующий этап защиты информации в базах данных - аудит действий пользователей, прямая задача отдела информационной безопасности. Значимость аудита объясняется тем, что в промышленной системе сложно тонко настроить права доступа к данным, к тому же бывают и исключительные ситуации.
Например, сотруднику отдела “А” временно понадобился доступ к клиенту отдела “Б”. С большой вероятностью внесение изменений в матрицу доступа к данным не будет иметь обратного характера, что в конечном итоге приводит к наличию учетных записей с сильно расширенными привилегиями, за использованием которых стоит следить.
Штатный аудит баз данных
Для проведения такого мониторинга многие организации пользуются «штатным аудитом» – средствами защиты баз данных, входящими в состав коммерческих СУБД. Штатный режим защиты включает ведение журнала подключения к СУБД и выполнения запросов теми или иными пользователями. Если коротко, принцип работы штатного аудита – это включение и настройка триггеров и создание специфичных функций – процедур, которые будут срабатывать при доступе к чувствительной информации и вносить данные о подобном доступе (кто, когда, какой запрос делал) в специальную таблицу аудита. Этого бывает достаточно для выполнения ряда отраслевых требований регуляторов, но не принесет практически никакой пользы для решения внутренних задач информационной безопасности, таких как расследование инцидентов.
Ключевые недостатки штатного аудита как защиты баз данных:
- Дополнительная нагрузка на серверы баз данных (10-40% в зависимости от полноты аудита).
- Вовлечение администраторов баз данных в настройку аудита (невозможность контроля администраторов – основных привилегированных пользователей).
- Отсутствие удобного интерфейса продукта и возможности централизованной настройки правил аудита (особенно актуально для крупных распределенных компаний, в задачи защиты которых входит целый перечень СУБД).
- Невозможность контроля действий пользователей в приложениях с трехзвенной архитектурой (наличие WEB и SQL-сегмента, что сейчас используется повсеместно из соображений безопасности).
Автоматизированные системы защиты баз данных
Более эффективный подход – использование специализированных систем информационной безопасности в области защиты бд – решений классов DAM и DBF.
DAM (Database Activity Monitoring) – это решение независимого мониторинга действий пользователей в СУБД. Под независимостью здесь понимается отсутствие необходимости переконфигурации и донастройки самих СУБД. Системы такого класса могут ставиться пассивно, работая с копией трафика и не оказывая никакого влияния на бизнес-процессы, частью которых являются базы данных.
- Классификации – определение местонахождения критичной для компании информации. Опция позволяет, просканировав СУБД, увидеть названия таблиц и полей, в которых могут содержаться персональные данные клиентов. Это крайне важно для упрощения последующей настройки политик безопасности.
- Проверки на уязвимости – соответствие конфигурации и настройки СУБД лучшим практикам.
- Получение матрицы доступа к данным – задача решается для выявления расширенных привилегий доступа, неиспользуемым правам, и наличие так называемых «мертвых» учетных записей, которые могли остаться после увольнения сотрудника из компании.
Преимущество систем такого класса – гибкая система отчетности и интеграции с SIEM-системами большинства вендоров, для более глубокого корреляционного анализа выполняемых запросов.
Учитывая достаточно большие риски при таком способе внедрения, крайне редко компании выбирают активную защиту промышленных СУБД и ограничиваются функциями мониторинга. Происходит это по причине возможности неоптимальной настройки правил блокировки. В этом случае ответственность за ложно заблокированные запросы будет лежать на плечах офицера информационной безопасности. Еще одна причина в том, что в сетевой схеме появляется дополнительный узел отказа, - главный блокирующий фактор при выборе такого способа внедрения решения.DBF (Database Firewall) – это смежное по классу решение, которое также обладает возможностью «проактивной» защиты информации. Достигается это блокировкой нежелательных запросов. Для решения этой задачи уже недостаточно работы с копией трафика, а требуется установка компонентов системы защиты «в разрыв».
На российском рынке представлено решение класса DAM «Гарда БД» от компании "Гарда Технологии". Это программно-аппаратный комплекс, который проводит непрерывный мониторинг всех запросов к базам данных и веб-приложениям в реальном времени и хранит их в течение длительного срока. Система проводит сканирование и выявление уязвимостей СУБД, такие как незаблокированные учётные записи, простые пароли, неустановленные патчи. Реагирование на инциденты происходит мгновенно в виде оповещений на e-mail и в SIEM-систему.
Система хранения данных - это программно-аппаратное решение для надежного и безопасного хранения данных, а также предоставления гарантированного доступа к ним.
Так, под надежностью подразумевается обеспечение сохранности данных, хранящихся в системе. Такой комплекс мер, как резервное копирование, объединение накопителей в RAID массивы с последующим дублированием информации способны обеспечить хотя бы минимальный уровень надежности при относительно низких затратах. При этом также должна обеспечиваться доступность, т. е. возможность беспрепятственной и непрерывной работы с информацией для санкционированных пользователей. В зависимости от уровня привилегий самих пользователей, система предоставляет разрешение для выполнения операций чтения, записи, перезаписи, удаления и так далее.
Безопасность является, пожалуй, наиболее масштабным, важным и труднореализуемым аспектом системы хранения данных. Объясняется это тем, что требуется обеспечить комплекс мер, направленный на сведение риска доступа злоумышленников к данным к минимуму. Реализовать это можно использованием защиты данных как на этапе передачи, так и на этапе хранения. Также важно учитывать возможность самих пользователей неумышленно нанести вред не только своим, но и данным других пользователей.
ТОПОЛОГИИ ПОСТРОЕНИЯ СИСТЕМ ХРАНЕНИЯ ДАННЫХ
Большинство функции, которые выполняют системы хранения данных, на сегодняшний день, не привязаны к конкретной технологии подключения. Описанные ниже методы используется при построении различных систем хранения данных. При построении системы хранения данных, необходимо четко продумывать архитектуру решения, и исходя из поставленных задач учитывать достоинства и недостатки, присущие конкретной технологии в конкретной ситуации. В большинстве случаев применяется один из трех видов систем хранения данных:
DAS (Direct-attached storage) - система хранения данных с прямым подключением (рисунок ниже). Устройство хранения (обычно жесткий диск) подключается непосредственно к компьютеру через соответствующий контроллер. Отличительным признаком DAS является отсутствие какого-либо сетевого интерфейса между устройством хранения информации и вычислительной машиной. Система DAS предоставляет коллективный доступ к устройствам хранения, однако для это в системе должно быть несколько интерфейсов параллельного доступа.
Главным и существенным недостатком DAS систем является невозможность организовать доступ к хранящимся данным другим серверам. Он был частично устранен в технологиях, описанных ниже, но каждая из них привносит свой новый список проблем в организацию хранения данных.
NAS (Network-attached storage) - это система, которая предоставляет доступ к дисковому пространству по локальной сети (рисунок выше). Архитектурно, в системе NAS промежуточным звеном между дисковым хранилищем и серверами является NAS-узел. С технической точки зрения, это обычный компьютер, часто поставляемый с довольно специфической операционной системой для экономии вычислительных ресурсов и концентрации на своих приоритетных задачах: работы с дисковым пространством и сетью.
Дисковое пространство системы NAS обычно состоит из нескольких устройств хранения, объединенных в RAID - технологии объединения физических дисковых устройств в логический модуль, для повышения отказоустойчивости и производительности. Вариантов объединения довольно много, но чаще всего на практике используются RAID 5 и RAID 6 [3], в которых данные и контрольные суммы записываются на все диски одновременно, что позволяет вести параллельные операции записи и чтения.
Главными преимуществами системы NAS можно назвать:
- Масштабируемость - увеличение дискового пространства достигается за счет добавления новых устройств хранения в уже существующий кластер и не требует переконфигурации сервера;
- Легкость доступа к дисковому пространству - для получения доступа не нужно иметь каких-либо специальных устройств, так как все взаимодействие между системой NAS и пользователями происходит через сеть.
SAN (Storage area network) - система, образующая собственную дисковую сеть (рисунок ниже). Важным отличием является то, что с точки зрения пользователя, подключенные таким образом SAN-устройства являются обычными локальными дисками. Отсюда и вытекают основные преимущества системы SAN:
- Возможность использовать блочные методы хранения - базы данных, почтовые данные,
- Быстрый доступ к данным - достигается за счет использования соответствующих протоколов.
СИСТЕМЫ РЕЗЕРВНОГО КОПИРОВАНИЯ ДАННЫХ
Резервное копирование - процесс создания копии информации на носителе, предназначенном для восстановления данных в случае их повреждения или утраты. Существует несколько основных видов резервного копирования:
- Полное резервное копирование;
- Дифференциальное резервное копирование;
- Инкрементное резервное копирование.
Рассмотрим их подробнее.
Полное резервное копирование. При его применении осуществляется копирование всей информации, включая системные и пользовательские данные, конфигурационные файлы и так далее (рисунок ниже).
Дифференциальное резервное копирование. При его применении сначала делается полное резервное копирование, а впоследствии каждый файл, который был изменен с момента первого полного резервного копирования, копируется каждый раз заново. На рисунке ниже представлена схема, поясняющая работу дифференциального резервного копирования.
Инкрементное резервное копирование. При его использовании сначала делается полное резервное копирование, затем каждый файл, который был изменен с момента последнего резервного копирования, копируется каждый раз заново (рисунок ниже).
К системам резервного копирования данных выдвигаются следующие требования:
- Надежность - обеспечивается использованием отказоустойчивого оборудования для хранения данных, дублированием информации на нескольких независимых устройствах, а также своевременным восстановлением утерянной информации в случае повреждения или утери;
- Кроссплатформенность - серверная часть системы резервного копирования данных должна работать одинаково с клиентскими приложениями на различных аппаратно-программных платформах;
- Автоматизация - сведение участие человека в процессе резервного копирования к минимуму.
ОБЗОР МЕТОДОВ ЗАЩИТЫ ДАННЫХ
Криптография - совокупность методов и средств, позволяющих преобразовывать данные для защиты посредством соответствующих алгоритмов.
Шифрование - обратимое преобразование информации в целях ее сокрытия от неавторизованных лиц. Признаком авторизации является наличие соответствующего ключа или набора ключей, которыми информация шифруется и дешифруется. Криптографические алгоритмы можно разделить на две группы:
- Симметричное шифрование;
- Асимметричное шифрование.
Под симметричным шифрованием понимаются такие алгоритмы, при использовании которых информация шифруется и дешифруется одним и тем же ключом. Схема работы таких систем представлена на рисунке ниже.
Главным проблемным местом данной схемы является способ распределения ключа. Чтобы собеседник смог расшифровать полученные данные, он должен знать ключ, которым данные шифровались . Так, при реализации подобной системы становится необходимым учитывать безопасность распределения ключевой информации для того, чтобы на допустить перехвата ключа шифрования.
К преимуществам симметричных криптосистем можно отнести:
- Высокая скорость работы за счет, как правило, меньшего числа математических операций и более простых вычислений;
- Меньшее потребление вычислительной мощности, в сравнении с асимметричными криптосистемами;
- Достижение сопоставимой криптостойкости при меньшей длине ключа, относительно асимметричных алгоритмов.
Под асимметричным шифрованием понимаются алгоритмы, при использовании которых информация шифруется и дешифруется разными, но математически связанными ключами - открытым и секретным соответственно. Открытый ключ может находится в публичном доступе и при шифровании им информации всегда можно получить исходные данные путем применения секретного ключа. Секретный ключ, необходимый для дешифрования информации, известен только его владельцу и вся ответственность за его сохранность кладется именно на него. Структурная схема работы асимметричных криптосистем представлена на рисунке ниже.
Ассиметричные криптосистемы архитектурно решают проблему распределения ключей по незащищенным каналам связи. Так, если злоумышленник перехватит ключ, применяемый при симметричном шифровании, он получит доступ ко всей информации. Такая ситуация исключена при использовании асимметричных алгоритмов, так как по каналу связи передается лишь открытый ключ, который в свою очередь не используется при дешифровании данных.
Другим местом применения асимметричных криптосистем является создание электронной подписи, позволяющая подтвердить авторство на какой-либо электронный ресурс.
Достоинства асимметричных алгоритмов:
- Отсутствует необходимость передачи закрытого ключа по незащищенного каналу связи, что исключает возможность дешифровки передаваемых данных третьими лицами,
- В отличии от симметричных криптосистем, в которых ключи шифрования рекомендуется генерировать каждый раз при новой передаче, в асимметричной их можно не менять продолжительное время.
ПОДВЕДЁМ ИТОГИ
При проектировании таких систем крайне важно изначально понимать какой должен получиться результат, и исходя из потребностей тщательно продумывать физическую топологию сети хранения, систему защиты данных и программную архитектуру решения. Также необходимо обеспечить резервное копирование данных для своевременного восстановления в случае частичной или полной утери информации. Выбор технологий на каждом последующем этапе проектирования, зачастую, зависит от принятых ранее решений, поэтому корректировка разработанной системы в таких случаях, нередко, затруднительна, а часто даже может быть невозможно.

В статье будет три части:
- Как защищать подключения.
- Что такое аудит действий и как фиксировать, что происходит со стороны базы данных и подключения к ней.
- Как защищать данные в самой базе данных и какие для этого есть технологии.
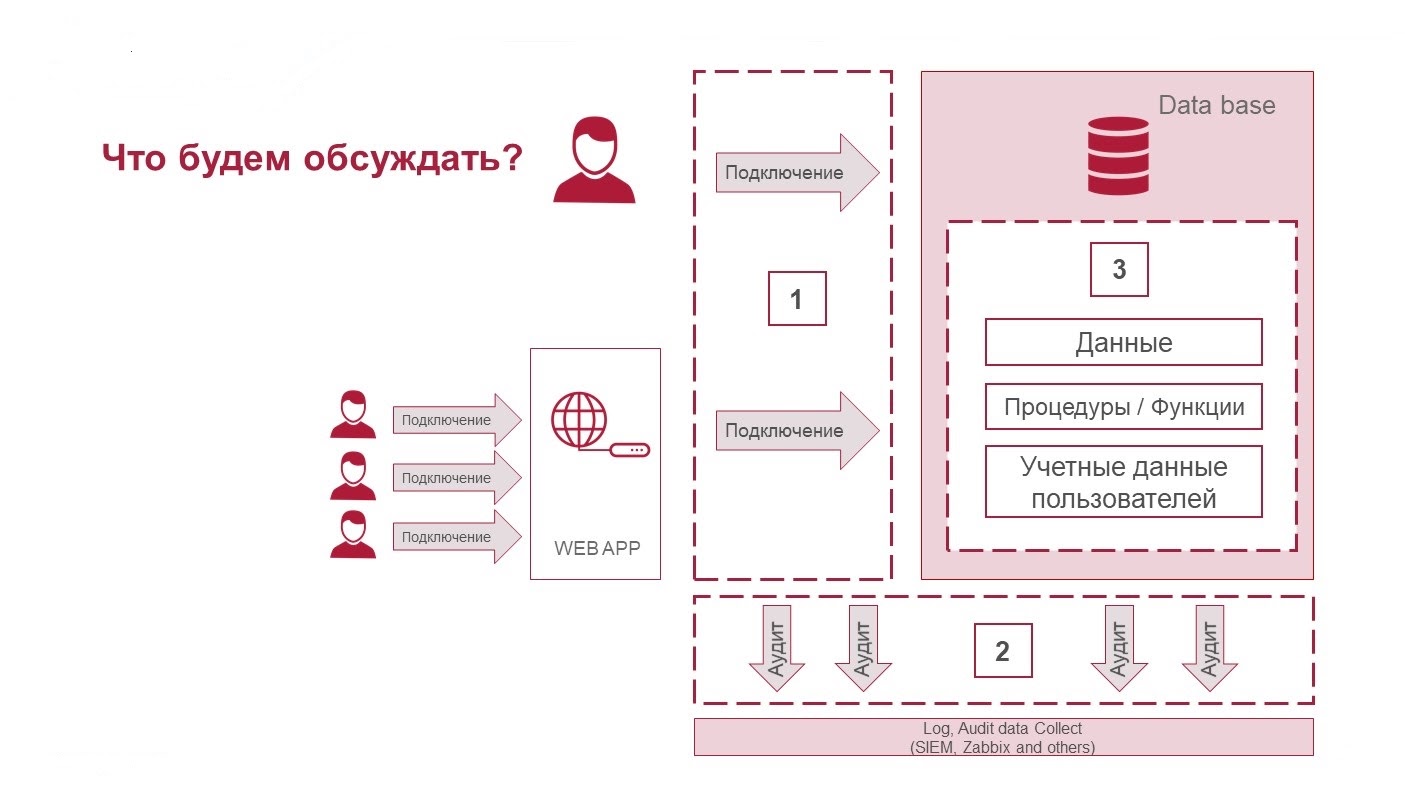
Три составляющих безопасности СУБД: защита подключений, аудит действий и защита данных
Защита подключений
Подключаться к базе данных можно как напрямую, так и опосредованно через веб-приложения. Как правило, пользователь со стороны бизнеса, то есть человек, который работает с СУБД, взаимодействует с ней не напрямую.
Перед тем как говорить о защите соединений, нужно ответить на важные вопросы, от которых зависит, как будут выстраиваться мероприятия безопасности:
- эквивалентен ли один бизнес-пользователь одному пользователю СУБД;
- обеспечивается ли доступ к данным СУБД только через API, который вы контролируете, либо есть доступ к таблицам напрямую;
- выделена ли СУБД в отдельный защищенный сегмент, кто и как с ним взаимодействует;
- используется ли pooling/proxy и промежуточные слои, которые могут изменять информацию о том, как выстроено подключение и кто использует базу данных.
- Используйте решения класса database firewall. Дополнительный слой защиты, как минимум, повысит прозрачность того, что происходит в СУБД, как максимум — вы сможете обеспечить дополнительную защиту данных.
- Используйте парольные политики. Их применение зависит от того, как выстроена ваша архитектура. В любом случае — одного пароля в конфигурационном файле веб-приложения, которое подключается к СУБД, мало для защиты. Есть ряд инструментов СУБД, позволяющих контролировать, что пользователь и пароль требуют актуализации.
Как это повлияет на производительность СУБД?
Посмотрим на примере PostgreSQL, как SSL влияет на нагрузку CPU, увеличение таймингов и уменьшение TPS, не уйдет ли слишком много ресурсов, если его включить.
Нагружаем PostgreSQL, используя pgbench — это простая программа для запуска тестов производительности. Она многократно выполняет одну последовательность команд, возможно в параллельных сеансах базы данных, а затем вычисляет среднюю скорость транзакций.
Тест 1 без SSL и с использованием SSL — соединение устанавливается при каждой транзакции:
vs
Тест 2 без SSL и с использованием SSL — все транзакции выполняются в одно соединение:
vs
Остальные настройки:
Результаты тестирования:
| NO SSL | SSL | |
| Устанавливается соединение при каждой транзакции | ||
| latency average | 171.915 ms | 187.695 ms |
| tps including connections establishing | 58.168112 | 53.278062 |
| tps excluding connections establishing | 64.084546 | 58.725846 |
| CPU | 24% | 28% |
| Все транзакции выполняются в одно соединение | ||
| latency average | 6.722 ms | 6.342 ms |
| tps including connections establishing | 1587.657278 | 1576.792883 |
| tps excluding connections establishing | 1588.380574 | 1577.694766 |
| CPU | 17% | 21% |
При небольших нагрузках влияние SSL сопоставимо с погрешностью измерения. Если объем передаваемых данных очень большой, ситуация может быть другая. Если мы устанавливаем одно соединение на каждую транзакцию (это бывает редко, обычно соединение делят между пользователями), у вас большое количество подключений/отключений, влияние может быть чуть больше. То есть риски снижения производительности могут быть, однако, разница не настолько большая, чтобы не использовать защиту.
Обратите внимание — сильное различие есть, если сравнивать режимы работы: в рамках одной сессии вы работаете или разных. Это понятно: на создание каждого соединения тратятся ресурсы.
У нас был кейс, когда мы подключали Zabbix в режиме trust, то есть md5 не проверяли, в аутентификации не было необходимости. Потом заказчик попросил включить режим md5-аутентификации. Это дало большую нагрузку на CPU, производительность просела. Стали искать пути оптимизации. Одно из возможных решений проблемы — реализовать сетевое ограничение, сделать для СУБД отдельные VLAN, добавить настройки, чтобы было понятно, кто и откуда подключается и убрать аутентификацию.Также можно оптимизировать настройки аутентификации, чтобы снизить издержки при включении аутентификации, но в целом применение различных методов аутентификации влияет на производительность и требует учитывать эти факторы при проектировании вычислительных мощностей серверов (железа) для СУБД.
Вывод: в ряде решений даже небольшие нюансы на аутентификации могут сильно сказаться на проекте и плохо, когда это становится понятно только при внедрении в продуктив.
Аудит действий
Аудит может быть не только СУБД. Аудит — это получение информации о том, что происходит на разных сегментах. Это может быть и database firewall, и операционная система, на которой строится СУБД.
В коммерческих СУБД уровня Enterprise с аудитом все хорошо, в open source — не всегда. Вот, что есть в PostgreSQL:
- default log — встроенное логирование;
- extensions: pgaudit — если вам не хватает дефолтного логирования, можно воспользоваться отдельными настройками, которые решают часть задач.
«Базовая регистрация операторов может быть обеспечена стандартным средством ведения журнала с log_statement = all.
Это приемлемо для мониторинга и других видов использования, но не обеспечивает уровень детализации, обычно необходимый для аудита.
Недостаточно иметь список всех операций, выполняемых с базой данных.
Также должна быть возможность найти конкретные утверждения, которые представляют интерес для аудитора.
Стандартное средство ведения журнала показывает то, что запросил пользователь, в то время как pgAudit фокусируется на деталях того, что произошло, когда база данных выполняла запрос.
Например, аудитор может захотеть убедиться, что конкретная таблица была создана в задокументированном окне обслуживания.
Это может показаться простой задачей для базового аудита и grep, но что, если вам представится что-то вроде этого (намеренно запутанного) примера:
DO $$
BEGIN
EXECUTE 'CREATE TABLE import' || 'ant_table (id INT)';
END $$;
Стандартное ведение журнала даст вам это:
LOG: statement: DO $$
BEGIN
EXECUTE 'CREATE TABLE import' || 'ant_table (id INT)';
END $$;
Похоже, что для поиска интересующей таблицы может потребоваться некоторое знание кода в тех случаях, когда таблицы создаются динамически.
Это не идеально, так как было бы предпочтительнее просто искать по имени таблицы.
Вот где будет полезен pgAudit.
Для того же самого ввода он выдаст этот вывод в журнале:
AUDIT: SESSION,33,1,FUNCTION,DO. «DO $$
BEGIN
EXECUTE 'CREATE TABLE import' || 'ant_table (id INT)';
END $$;"
AUDIT: SESSION,33,2,DDL,CREATE TABLE,TABLE,public.important_table,CREATE TABLE important_table (id INT)
Регистрируется не только блок DO, но и полный текст CREATE TABLE с типом оператора, типом объекта и полным именем, что облегчает поиск.
При ведении журнала операторов SELECT и DML pgAudit можно настроить для регистрации отдельной записи для каждого отношения, на которое есть ссылка в операторе.
Не требуется синтаксический анализ, чтобы найти все операторы, которые касаются конкретной таблицы(*)».
Как это повлияет на производительность СУБД?
Давайте проведем тесты с включением полного аудита и посмотрим, что будет с производительностью PostgreSQL. Включим максимальное логирование БД по всем параметрам.
В конфигурационном файле почти ничего не меняем, из важного — включаем режим debug5, чтобы получить максимум информации.
| log_destination = 'stderr' logging_collector = on log_truncate_on_rotation = on log_rotation_age = 1d log_rotation_size = 10MB log_min_messages = debug5 log_min_error_statement = debug5 log_min_duration_statement = 0 debug_print_parse = on | debug_print_rewritten = on debug_print_plan = on debug_pretty_print = on log_checkpoints = on log_connections = on log_disconnections = on log_duration = on log_hostname = on log_lock_waits = on log_replication_commands = on log_temp_files = 0 log_timezone = 'Europe/Moscow' |
На СУБД PostgreSQL с параметрами 1 CPU, 2,8 ГГц, 2 Гб ОЗУ, 40 Гб HDD проводим три нагрузочных теста, используя команды:
Результаты тестирования:
| Без логирования | С логированием | |
| Итоговое время наполнения БД | 43,74 сек | 53,23 сек |
| ОЗУ | 24% | 40% |
| CPU | 72% | 91% |
| Тест 1 (50 коннектов) | ||
| Кол-во транзакций за 10 мин | 74169 | 32445 |
| Транзакций/сек | 123 | 54 |
| Средняя задержка | 405 мс | 925 мс |
| Тест 2 (150 коннектов при 100 возможных) | ||
| Кол-во транзакций за 10 мин | 81727 | 31429 |
| Транзакций/сек | 136 | 52 |
| Средняя задержка | 550 мс | 1432 мс |
| Про размеры | ||
| Размер БД | 2251 МБ | 2262 МБ |
| Размер логов БД | 0 Мб | 4587 Мб |
В итоге: полный аудит — это не очень хорошо. Данных от аудита получится по объему, как данных в самой базе данных, а то и больше. Такой объем журналирования, который генерится при работе с СУБД, — обычная проблема на продуктиве.
Смотрим другие параметры:
- Скорость сильно не меняется: без логирования — 43,74 сек, с логированием — 53,23 сек.
- Производительность по ОЗУ и CPU будет проседать, так как нужно сформировать файл с аудитом. Это также заметно на продуктиве.
В корпорациях с аудитом еще сложнее:
- данных много;
- аудит нужен не только через syslog в SIEM, но и в файлы: вдруг с syslog что-то произойдет, должен быть близко к базе файл, в котором сохранятся данные;
- для аудита нужна отдельная полка, чтобы не просесть по I/O дисков, так как он занимает много места;
- бывает, что сотрудникам ИБ нужны везде ГОСТы, они требуют гостовую идентификацию.
Ограничение доступа к данным
Посмотрим на технологии, которые используют для защиты данных и доступа к ним в коммерческих СУБД и open source.
Что в целом можно использовать:
- Шифрование и обфускация процедур и функций (Wrapping) — то есть отдельные инструменты и утилиты, которые из читаемого кода делают нечитаемый. Правда, потом его нельзя ни поменять, ни зарефакторить обратно. Такой подход иногда требуется как минимум на стороне СУБД — логика лицензионных ограничений или логика авторизации шифруется именно на уровне процедуры и функции.
- Ограничение видимости данных по строкам (RLS) — это когда разные пользователи видят одну таблицу, но разный состав строк в ней, то есть кому-то что-то нельзя показывать на уровне строк.
- Редактирование отображаемых данных (Masking) — это когда пользователи в одной колонке таблицы видят или данные, или только звездочки, то есть для каких-то пользователей информация будет закрыта. Технология определяет, какому пользователю что показывать с учетом уровня доступа.
- Разграничение доступа Security DBA/Application DBA/DBA — это, скорее, про ограничение доступа к самой СУБД, то есть сотрудников ИБ можно отделить от database-администраторов и application-администраторов. В open source таких технологий немного, в коммерческих СУБД их хватает. Они нужны, когда много пользователей с доступом к самим серверам.
- Ограничение доступа к файлам на уровне файловой системы. Можно выдавать права, привилегии доступа к каталогам, чтобы каждый администратор получал доступ только к нужным данным.
- Мандатный доступ и очистка памяти — эти технологии применяют редко.
- End-to-end encryption непосредственно СУБД — это client-side шифрование с управлением ключами на серверной стороне.
- Шифрование данных. Например, колоночное шифрование — когда вы используете механизм, который шифрует отдельную колонку базы.
Как это влияет на производительность СУБД?
Посмотрим на примере колоночного шифрования в PostgreSQL. Там есть модуль pgcrypto, он позволяет в зашифрованном виде хранить избранные поля. Это полезно, когда ценность представляют только некоторые данные. Чтобы прочитать зашифрованные поля, клиент передает дешифрующий ключ, сервер расшифровывает данные и выдает их клиенту. Без ключа с вашими данными никто ничего не сможет сделать.
Проведем тест c pgcrypto. Создадим таблицу с зашифрованными данными и с обычными данными. Ниже команды для создания таблиц, в самой первой строке полезная команда — создание самого extension с регистрацией СУБД:
Дальше попробуем сделать из каждой таблицы выборку данных и посмотрим на тайминги выполнения.
Выборка из таблицы без функции шифрования:
id | text1 | text2
------+-------+-------
1 | 1 | 1
2 | 2 | 2
3 | 3 | 3
…
997 | 997 | 997
998 | 998 | 998
999 | 999 | 999
1000 | 1000 | 1000
(1000 строк)
Выборка из таблицы с функцией шифрования:
id | decrypt | decrypt
-----+--------------+------------
1 | \x31 | \x31
2 | \x32 | \x32
3 | \x33 | \x33
…
999 | \x393939 | \x393939
1000 | \x31303030 | \x31303030
(1000 строк)
Результаты тестирования:
| Без шифрования | Pgcrypto (decrypt) | |
| Выборка 1000 строк | 1,386 мс | 50,203 мс |
| CPU | 15% | 35% |
| ОЗУ | +5% |
Шифрование сильно влияет на производительность. Видно, что вырос тайминг, так как операции дешифрации зашифрованных данных (а дешифрация обычно еще обернута в вашу логику) требуют значительных ресурсов. То есть идея зашифровать все колонки, содержащие какие-то данные, чревата снижением производительности.
При этом шифрование не серебряная пуля, решающая все вопросы. Расшифрованные данные и ключ дешифрования в процессе расшифровывания и передачи данных находятся на сервере. Поэтому ключи могут быть перехвачены тем, кто имеет полный доступ к серверу баз данных, например системным администратором.
Когда на всю колонку для всех пользователей один ключ (даже если не для всех, а для клиентов ограниченного набора), — это не всегда хорошо и правильно. Именно поэтому начали делать end-to-end шифрование, в СУБД стали рассматривать варианты шифрования данных со стороны клиента и сервера, появились те самые key-vault хранилища — отдельные продукты, которые обеспечивают управление ключами на стороне СУБД.

Средства безопасности в коммерческих и open source СУБД
| Функции | Тип | Password Policy | Audit | Защита исходного кода процедур и функций | RLS | Encryption |
| Oracle | Коммерческая | + | + | + | + | + |
| MsSql | Коммерческая | + | + | + | + | + |
| Jatoba | Коммерческая | + | + | + | + | extensions |
| PostgreSQL | Free | extensions | extensions | - | + | extensions |
| MongoDb | Free | - | + | - | - | Available in MongoDB Enterprise only |
Таблица далеко не полная, но ситуация такая: в коммерческих продуктах задачи безопасности решаются давно, в open source, как правило, для безопасности используют какие-то надстройки, многих функций не хватает, иногда приходится что-то дописывать. Например, парольные политики — в PostgreSQL много разных расширений (1, 2, 3, 4, 5), которые реализуют парольные политики, но все потребности отечественного корпоративного сегмента, на мой взгляд, ни одно не покрывает.
Что делать, если нигде нет того, что нужно? Например, хочется использовать определенную СУБД, в которой нет функций, которые требует заказчик.
Тогда можно использовать сторонние решения, которые работают с разными СУБД, например, «Крипто БД» или «Гарда БД». Если речь о решениях из отечественного сегмента, то там про ГОСТы знают лучше, чем в open source.
Второй вариант — самостоятельно написать, что нужно, реализовать на уровне процедур доступ к данным и шифрование в приложении. Правда, с ГОСТом будет сложнее. Но в целом — вы можете скрыть данные, как нужно, сложить в СУБД, потом достать и расшифровать как надо, прямо на уровне application. При этом сразу думайте, как вы будете эти алгоритмы на application защищать. На наш взгляд, это нужно делать на уровне СУБД, потому что так будет работать быстрее.
д) центили, лимиты, амплитуда, коэффициент вариации, среднее квадратичное отклонение
144. В больнице № 1 показатель больничной летальности составил 2,1±0,4%, а в больнице № 2 - 1,2±0,3%. В какой больнице качество лечения лучше, на основании чего сделан вывод?
а) сравнению данные показатели не подлежат
б) в данном случае для сравнения качества лечения нужно применить метод стандартизации, но данных для этого недостаточно
в) утверждать, что в больнице № 2 качество лечения лучше нельзя, т.к. по критерию Стьюдента t 2
145. К какому виду статистических величин относится показатель календарных дней заболеваемости с временной утратой трудоспособности?
в) соотношения
д) нормированного отношения
146. Медиана ряда (Me) - это
а) наибольшая по значению варианта
б) варианта, встречающаяся чаще других
в) центральная варианта, делящая ряд пополам
147. Назовите крайние варианты вариационного ряда, если известно, что М = 40,0 кг, а = 3,0 кг
в) 39-42 кг
148. Мода-это
а) центральная варианта
б) варианта, встречающаяся чаще других
в) варианта с наименьшим значением признака
149. Укажите формулу, по которой рассчитывается отклонение (d)
а) d = V-M
б) d = M-V
150. Типичность средней арифметической величины характеризуют %
а) среднее квадратичное отклонение и коэффициент вариации
б) мода и медиана.
151. Какая варианта вариационного ряда чаще всего принимается за условную среднюю?
г) Vmin
152. При сравнении интенсивных показателей, полученных на однородных по своему составу совокупностях, необходимо применять
а) оценку показателей соотношения
б) определение относительной величины
г) оценку достоверности разности показателей
д) все вышеперечисленное
153. При увеличении числа наблюдений величина средней ошибки
б) не изменяется
в) уменьшается
154. Величина средней ошибки прямо пропорциональна
а) числу наблюдений (n)
б) колебаниям признака (pq)
155. Разность между двумя относительными показателями считается достоверной, если превышает свою ошибку
а) в 2 и более раз
б) менее чем в 2 раза
156. В каких границах возможны случайные колебания средней величин с вероятностью 95,5%?
в) М±3т.
157. Какой степени вероятности соответствует доверительный интервал Р±2т?
а) вероятности 68,3%
б) вероятности 95,5%
в) вероятности 99,7%
158. Какой степени вероятности соответствует доверительный интервал М±3т?
а) вероятности 68,3%
б) вероятности 95,5%
в) вероятности 99,7%
159. Чем меньше колебания признака, тем величина средней ошибки
б) больше
160. Чтобы уменьшить ошибку выборки, число наблюдений нужно
а) увеличить
б) уменьшить
161. Чем меньше число наблюдений, тем величина средней ошибки
б) больше
162. Разница между средними величинами считается достоверной, если
б) t = 2 и больше
163. Не считается достоверной для научных исследований
а) вероятность 68,3%
б) вероятность 95,5%
в) вероятность 99,7
164. Достоверно ли снижение показателей летальности от ревматизма
Число больных Число умерших
I период 800 24
II период 2100 21
а) снижение показателя летальности недостоверно, случайно
б) снижение показателя летальности достоверно
165. Укажите правильную последовательность схемы маркетингового исследования
1) отбор источников информации
2) сбор информации
3) выявление проблем и формулирование целей исследования
4) представление полученных результатов
5) анализ собранной информации
166. Укажите последовательность методики вычисления стандартизованных показателей прямым методом
1) выбор стандарта
2) расчет "ожидаемых чисел"
3) расчет погрупповых интенсивных показателей
4) распределение в стандарте
5) получение общего интенсивного стандартизованного показателя
6) 1), 2), 3), 4), 5)
167. Коэффициент парной корреляции между показателем заболеваемости населения и показателем госпитализации при сердечно-сосудистой патологии на 1000 городского населения равняется +0,88. Можно ли сделать следующий вывод на основании величины данного коэффициента
а) зависимость между рассматриваемыми явлениями отсутствует, так как коэффициент корреляции имеет положительный знак
б) зависимость между рассматриваемыми явлениями сильная и обратная
в) зависимость между рассматриваемыми явлениями прямая и сильная
г) зависимость - прямая и средняя
д) зависимость - обратная и средняя
168. Теория вероятностей рассматривает
а) вероятные закономерности массовых, однородных случайных явлений
б) события, исход которых точно показывает величину неслучайных явлений
в) события, исход которых характеризует качественные величины неоднородных случайных явлений
г) события, исход которых характеризует количественные величины однородных неслучайных явлений
д) все названное выше
169. Случайным событием называют
а) событие, которое может произойти при любых заданных условиях
б) событие, которое при заданных условиях может произойти или не произойти
в) событие, которое при заданных условиях может произойти
д) событие, которое может не произойти при заданных условиях
170. Вероятность - это
а) явление, исход которого можно точно предсказать
б) величина, определяющая перспективу
того или иного исхода в предстоящем испытании
в) величина среднего квадратичного отклонения параметров вариационного ряда
г) величина средней ошибки интенсивного показателя
д) величины, характеризующие параметры вариационного ряда
171. Относительная частота события представляет собой
а) отношение числа завершившихся данным событием испытаний к числу не завершившихся данным событием испытаний
б) отношение числа завершившихся данным событием испытаний к общему числу испытаний
в) отношение общего числа испытаний к числу завершившихся данным событием испытаний
172. Признак называется качественным, если он
а) может быть непосредственно измерен
б) учитывается по результатам группировки в противопоставляемые друг другу группы
в) учитывается по наличию его свойств у членов изучаемой группы
173. Дисперсией называется
а) средний квадрат отклонения величин признака
у членов совокупности от средней арифметической величины данного признака в совокупности
б) средняя величина абсолютных отклонений величин признака у членов совокупности от средней арифметической величины данного признака в совокупности
174. Наиболее надежный способ обеспечения сохранности компьютерных баз данных - это
а) регулярная проверка жесткого диска персонального компьютера на наличие логических и физических ошибок
б) регулярное резервное копирование данных на внешние носители
в) регулярная оптимизация размещения данных на жестком диске
г) регулярное создание резервных копий данных на жестком диске
175. Средним квадратическим отклонением называется
а) средняя величина абсолютных отклонений величин признака у членов совокупности от средней арифметической величины данного признака в совокупности
б) квадратный корень из среднего квадрата отклонения величин признака у членов совокупности от средней арифметической величины данного признака в совокупности
176. Корреляционной решеткой называется
а) таблица, содержащая данные о величинах двух признаков
б) таблица, содержащая данные о частотах различных сочетаний величин двух признаков
в) таблица, содержащая данные о частотах различных сочетаний величин двух признаков, при построении которой произведен; группировка членов совокупности по величине этих признаков
177. Задачей регрессионного анализа является
а) установление причинно-следственных связей между признаками
б) установление факта связи между признаками
в) установление факта связи между признаками и отыскание численных характеристик для выражения этой связи
178. Задачей факторного анализа является
а) выработка правила, позволяющего приписать данное наблюдет и к одной из групп
б) выявление по большому числу измеренных в эксперименте признаков нескольких гипотетических величин, характеризующих структуру изучаемого явления
в) группировка объекта
179. Для оценки связи качественных признаков следует использовать
а) параметрические показатели связи
б) непараметрические показатели связи
180. Непараметрические показатели связи
а) зависят от закона распределения
б) не зависят от закона распределения
181. Применение непараметрических методов по сравнению с параметрическими имеет
а) меньше ограничений в отношении исходных данных
б) больше ограничений в отношении исходных данных
182. Частный коэффициент корреляции отражает
а) связь между двумя варьирующими признаками
б) линейную связь между двумя варьирующими признаками
в) связь между двумя варьирующими признаками при постоянной величине третьего признака
г) линейную связь между двумя варьирующими признаками при постоянной величине третьего признака
д) связь между двумя варьирующими признаками при переменной величине третьего признака
е) линейную связь между двумя варьирующими признаками при переменной величине третьего признака
183. Коэффициент детерминации позволяет оценить
а) направленность связи между признаками
б) силу связи между признаками
184. Основная цель выравнивания динамического ряда зависимости переменной Y от времени X состоит в
а) усреднении величин Y для данного значения X
б) выявлении основной тенденции изменений Y в зависимости от X
185. При выравнивании динамических рядов методом скользящего среднего рекомендуется использовать усреднение по
а) четному числу точек
б) нечетному числу точек
186. При выравнивании динамических рядов методом скользящего среднего по мере увеличения числа точек, по которым производится усреднение, влияние случайных вариаций на результат сглаживания
б) уменьшается
187. Для использования непараметрических критериев нужно ли знать характер распределения?
188. Для обеспечения сохранности информации, записанной на гибком диске 5,25 дюйма, в процессе ее чтения прорезь на боковой стороне диска должна быть
б) открыта
189. Для обеспечения сохранности информации, записанной на гибком диске 3,5 дюйма, в процессе ее чтения окно на диске должно быть
б) открыто
190. При записи информации на гибкий диск 5,25 дюйма прорезь на боковой стороне диска должна быть
б) открыта
191. При записи информации на гибкий диск 3,5 дюйма окно на диске должно быть
б) открыто
192. При подозрении на наличие компьютерного вируса следует
а) проверить жесткий диск на наличие логических и физических ошибок
б) проверить жесткий диск на наличие компьютерных вирусов посредством запуска диагностической антивирусной программы с жесткого диска
в) перезагрузить персональный компьютер посредством нажатия клавиш , после чего осуществлять дальнейшие мероприятия по диагностике и лечению компьютерного вируса
г) выключить, затем вновь включить питание персонального компьютера, загрузить операционную систему с заведомо неинфицированной вирусами дискеты, затем осуществлять дальнейшие мероприятия по диагностике и лечению компьютерного вируса
д) выключить, затем вновь включить питание персонального компьютера, затем осуществлять дальнейшие мероприятия по диагностике и лечению компьютерного вируса
193. Для уничтожения компьютерного вируса в оперативной памяти персонального компьютера следует
а) перезагрузить персональный компьютер посредством нажатия клавиш
б) выключить, затем вновь через некоторое время включить питание персонального компьютера
194. Может ли быть заражен вирусом гибкий диск 5,25 дюйма с открытой прорезью, находящийся в дисководе персонального компьютера, в оперативной памяти которого имеется компьютерный вирус?
б) нет
195. Может ли быть заражен вирусом гибкий диск 5,25 дюйма с закрытой прорезью, находящийся в дисководе персонального компьютера, в оперативной памяти которого имеется компьютерный вирус?
б) нет
196. Может ли быть заражен вирусом гибкий диск 3,5 дюйма с открытым окном, находящийся в дисководе персонального компьютера, в оперативной памяти которого имеется компьютерный вирус?
б) нет
197. Может ли быть заражен вирусом гибкий диск 3,5 дюйма с закрытым окном, находящийся в дисководе персонального компьютера, в оперативной памяти которого имеется компьютерный вирус?
б) нет
198. УСТАНОВИТЕ СООТВЕТСТВИЕ
1) случайное-в
2) достоверное-а
Исход события
а) обязательно наступает при данных условиях
б) никогда не наступает при данных условиях
в) наступает или не наступает при данных условиях
199. УСТАНОВИТЕ СООТВЕТСТВИЕ
Читайте также: