
Oracle изменить кодировку строки
Обновлено: 04.07.2024
по устаревшим причинам у нас есть столбец VARCHAR2 в нашей базе данных Oracle 10-где кодировка символов установлена в AL32UTF8 -которые содержат какие-либо не-UTF-8 значений. Значения всегда находятся в одном из следующих наборов символов:
Я написал функцию Perl для исправления сломанных значений вне базы данных. Для значения из этого столбца базы данных он проходит через этот список кодировки и пытается преобразовать значение в UTF-8. Если преобразование не удается, он пытается следующую кодировку. Первое, что нужно преобразовать без ошибок, - это значение, которое мы сохраняем. Теперь я хотел бы реплицировать эту функциональность внутри базы данных, чтобы любой мог ее использовать.
однако, все, что я могу найти на это CONVERT функции, который никогда не терпит неудачу, но вставляет символ замены для символов, которые он не распознает. Так что, насколько я могу судить, узнать это невозможно. когда преобразование не удалось.
поэтому у меня есть два вопроса:
- есть ли какой-то существующий интерфейс, который пытается преобразовать строку в один из списков кодировок, возвращая первый, который преуспевает?
- а если нет, есть ли другой интерфейс, который указывает на сбой, если он не может преобразовать строку в кодировку? Если да, то я мог бы написать предыдущий функция.
обновление:
Для справки, я написал эту функцию PostgreSQL в PL / pgSQL, которая делает именно то, что мне нужно:
Я бы очень хотел знать, как сделать эквивалент в Oracle.
благодаря ключевой информации о незаконных символах в UTF-8 от @collapsar, а также некоторым раскопкам коллегой, я придумал это:
Любопытно, что он никогда не попадает в WE8ISO8859P1: WE8MSWIN1252 преобразует каждый из списка 800 или так плохих значений, которые у меня есть без жалоб. То же самое не верно для моих реализаций Perl или PostgreSQL, где CP1252 терпит неудачу для некоторых значений, но ISO-8859-1 преуспевает. Тем не менее, значения от Oracle кажутся адекватными, и, похоже, действителен Unicode (протестирован путем загрузки их в PostgreSQL), поэтому я не могу жаловаться. Думаю, этого будет достаточно, чтобы санировать мои данные.
чтобы проверить, содержит ли столбец базы данных недопустимый utf-8, используйте следующий запрос:
учитывая, что ваша кодировка БД-al32utf8.
отметим, что EF BF BD представляет собой незаконное кодирование в utf-8.
поскольку все другие кодировки, которые вы указываете, ориентированы на байт, преобразование в unicode никогда не завершится неудачей, но, возможно, приведет к различным кодовым точкам. без контекстной информации автоматизированное определение фактического источника кодировка невозможна.
С наилучшими пожеланиями, Карстен
ps: имена oracle для кодировок: CP1252 -> WE8MSWIN1252 LATIN-1 -> WE8ISO8859P1
Доброго всем времени. Вопрос, думаю, несложный будет для Вас. Открываю PL/SQL Developer БД запросом и в текстовых полях отображаются кракозябры? Как победить? Лезть в настройки БД через Oracle Configuration Assistant или же в девелопере настройка?
2,332 1 1 золотой знак 14 14 серебряных знаков 35 35 бронзовых знаков 517 2 2 золотых знака 7 7 серебряных знаков 20 20 бронзовых знаковОшибка в вашей настройке языка. Клиент Oracle берет настройку языка из виндовой переменной NLS_LANG, если я правильно помню, ее нужно установить в значение RUSSIAN_AMERICA.CL8MSWIN1251.
Сделать в Винде это можно в "Свойствах системы", закладка "Дополнительно", кнопка "Переменные среды". Добавляете этот параметр, если он не создался клиентом Oracle и задаете значение.
4,021 12 12 серебряных знаков 19 19 бронзовых знаков Спасибо большое, поменял, помогло!) Только небольшая поправочка - это меняется в ключе реестра, а где именно можно узнать из Developer-a: "Help - > Support Info -> Registry" Я точно правил через переменные среды, про реестр тоже слышал. Возможно, разные версии клиента воспринимают разные способы для установки значения. Коллеги, порядок применения настроек следующий. Если значение NLS_LANG изменено в реестре, то сначала используется оно, но если создана переменная окружения, то она сильнее, и имеет приоритет. Так можно запускать разные приложения bat-файлами с разными настройками, делая set nls_lang=. Ну а после того как клиентсое приложение уже запустилось, оно может само выдать ALTER SESSION и менять nls_language и nls_territory сколько угодно раз. То же касается и большинства других NLS-настроек, и не только.Русский текст (кирилица) в клиенте Oracle (PL/SQL Developer и др.)
Установить параметр реестра (выполнить -> regedit.exe):
Код для reg файла:
Путь и содержимое ветки реестра вашего oracle клиента, можно узнать из PL/SQL Developer-a:
Переменная окружения действительно помогает, но ее значение должно быть несколько иным.
Сначала нужно включить проверку соответствия кодировки клиента и сервера. Это делается так: Tools -> Preferences -> Options -> Check for client & server character set mismatch
После этого при подключении вы увидите предупреждение вида "NS_LANG is not defined. ", что означает, что переменная не определена или же там будет указано, что переменная определена, но ее значение не соответствует правильному. Вот это правильное и нужно вписать, чтобы заработало.

До разработки стандарта Юникод существовало множество схем кодировки, которые обладали ограниченными возможностями, а порой и конфликтовали друг с другом. Разработка глобальных приложений по единым правилам была практически невозможна, потому что ни одна кодировка не поддерживала все символы.
Стандарт Юникод решает все эти проблемы. Он разрабатывается и сопровождается Консорциумом Юникода. Содержимое каждой версии определяется Стандартом Юникода и Базой данных символов Юникода, или USD (Unicode Character Database).
Набор символов Юникода позволяет хранить и извлекать данные в более чем 200 различных отдельных наборах. Использование набора символов Юникода обеспечивает поддержку всех этих наборов без внесения архитектурных изменений в приложение.
- Oracle11g Release 2 поддерживает Юникод версии 5.0. Этот стандарт, впервые опубликованный в 2006 году, обеспечивает кодирование более одного миллиона символов. Этого достаточно для поддержки всех современных символов, а также многих древних или малораспространенных алфавитов. Oracle Database 12c включает поддержку Юникода 6.1 (стандарт опубликован в январе 2012 г.) и вводит несколько новых лингвистических порядков сопоставления, соответствующих правилам UCA (Unicode Conation Algorithm).
- Наборы символов Юникода в Oracle11g включают кодировки UTF-8 и UTF-16 . В UTF-8 для представления символа используется 1, 2 или 3 байта в зависимости от символа. В UTF-16 символ всегда представляется двумя байтами. В обеих схемах поддерживаются дополнительные символы, использующие 4-байтовое представление независимо от выбранного набора символов Юникода.
- Наборы символов Юникода в Oracle Database 11g и 12c включают кодировки UTF-8 и UTF-16 . В UTF-8 символы представляются 1, 2 или 3 байтами в зависимости от символа. В UTF-16 все символы представляются 2 байтами. Дополнительные символы поддерживаются обеими кодировками и представляются 4 байтами на символ независимо от выбранной кодировки.
Каждая база данных Oracle имеет два набора символов. Первичный набор символов используется для большинства функций приложений, а отдельный набор символов NLS — для типов данных и функций, специфических для NLS . Для определения используемых наборов символов используется следующий запрос:
В данном случае параметр NLS_CHARACTERSET (первичный набор символов базы данных) имеет значение AL32UTF8 . В этот 32-разрядный набор символов Юникода UTF-8 входит большинство самых распространенных символов в мире. Параметр NLS_NCHAR_ CHARACTERSET , используемый прежде всего для столбцов NCHAR и NVARCHAR2 , представляет собой 16-разрядный набор символов UTF-16 .
Структура имен, присваиваемых наборам символов в Oracle , содержит полезную информацию. Например, US7ASCII поддерживает символы английского языка для США. Набор символов AL32UTF8 поддерживает любые языки. Вторая часть строки определяет количество битов на символ. В US7ASCII символ представляется 7 битами, а AL32UTF8 использует до 32 бит на символ. Оставшаяся часть строки содержит «официальное» название набора символов. Структура имени представлена на рис. 1.


Рис. 1. Структура имени набора символов в Oracle
За дополнительной информацией о Юникоде обращайтесь на сайт Стандарта Юникод по адресу.
Типы данных и национальные наборы символов
Типы данных Globalization Support nclob , nchar и nvarchar2 используют набор символов, определяемый параметром nls_nchar_characterset , — вместо набора символов по умолчанию, устанавливаемого для базы данных в параметре nls_characterset . Эти типы данных поддерживают только многобайтовые символы Юникода, поэтому даже при работе с базой данных, в которой по умолчанию вместо Юникода используется другая кодировка, они будут хранить символы в национальном наборе символов. А так как национальный набор символов поддерживает только кодировки UTF-8 и UTF- 16 , NCLOB , NCHAR и NVARCHAR2 гарантированно будут хранить данные в многобайтовом Юникоде.
Прежде это создавало проблемы при сравнении столбцов nclob/nchar/nvarchar2 со столбцами clob/char/varchar2 . Во всех версиях, поддерживаемых в настоящее время, Oracle выполняет автоматическое преобразование, благодаря которому становится возможным корректное сравнение.
Кодировка символов
Выбор набора символов во время создания базы данных определяет тип кодировки символов. Каждому символу ставится в соответствие код, уникальный для данного символа (кодовая точка). Это значение является частью таблицы отображения символов Юникода, содержимое которой находится под контролем Консорциума Юникода.
Кодовые точки состоят из префикса U+ (или обратной косой черты \ ), за которым следует шестнадцатеричный код символа с диапазоном допустимых значений от U+0000 до U+10FFFF16 . Комбинированные символы (например, А ) могут разбиваться на компоненты (A с умляутом), а затем снова восстанавливаться в своем исходном состоянии. Скажем, декомпозиция А состоит из кодовых точек U+0041 (A) и U+0308 (умляут). В следующем разделе будут рассмотрены некоторые функции Oracle для работы с кодовыми точками.
Кодовой единицей ( code unit ) называется размер в байтах типа данных, используемого для хранения символов. Размер кодовой единицы зависит от используемого набора символов. В некоторых обстоятельствах кодовая точка слишком велика для одной кодовой единицы, и для ее представления требуется несколько кодовых единиц.
Конечно, пользователи воспринимают символы, а не кодовые точки или кодовые единицы. «Слово» \0053\0074\0065\0076\0065\006E вряд ли будет понятно среднему пользователю, который распознает символы на своем родном языке. Не забывайте, что глиф (изображение символа, непосредственно отображаемое на экране) является всего лишь представлением кодового пункта. Даже если на вашем компьютере не установлены необходимые шрифты или он по другим причинам не может вывести символы на экран, это вовсе не означает, что в Oracle соответствующая кодовая точка хранится некорректно.

Параметры Globalization Support (NLS)
Поведение Oracle по умолчанию определяется параметрами Globalization Support (NLS) . Значения параметров, задаваемые при создании базы данных, определяют многие аспекты ее работы — от наборов символов до используемых по умолчанию денежных единиц. В табл. 1 перечислены параметры, которые вы можете изменить в ходе сеанса, с примерами значений и пояснениями. За текущими значениями параметров в вашей системе обращайтесь к представлению NLS_SESSI0N_PARAMETERS .
Таблица 1. Сеансовые параметры NLS
Функции юникода
Поддержка Юникода в PL/SQL начинается с простейших строковых функций. Впрочем, в табл. 2 видны небольшие отличия этих функций от их хорошо известных аналогов.
К именам функций INSTR , LENGTH и SUBSTR добавляется суффикс B, C, 2 или 4; он означает, что функция работает с байтами, символами, кодовыми единицами или кодовыми точками соответственно.
Функции INSTR , LENGTH и SUBSTR используют семантику длины, связанную с типом данных столбца или переменной. Эти базовые функции и версии с суффиксом C часто возвращают одинаковые значения — до тех пор, пока вы не начнете работать со значениями NCHAR или NVARCHAR . Поскольку NLS_NCHAR_ CHARACTERSET и NLS_CHARACTERSET могут различаться, результат вызова INSTR , LENGTH и SUBSTR может отличаться (в зависимости от типа данных) от результата их символьных аналогов.
Таблица 2. Функции Юникода
Рассмотрим эти функции подробнее.
ASCIISTR
ASCIISTR пытается преобразовать полученную строку в ASCII -символы. Если строка содержит символы, отсутствующие в наборе ASCII , они представляются в формате \xxxx . Как будет показано ниже при описании функции DECOMPOSE , такое форматирование иногда оказывается очень удобным.
COMPOSE
Некоторые символы могут иметь несколько вариантов представления кодовых пунктов. Это создает проблемы при сравнении двух значений. Символ А может быть представлен как одним кодовым пунктом U+00C4 , так и двумя кодовыми пунктами U+0041 (буква A) и U+0308. При сравнении PL/SQL считает, что эти два варианта представления не равны.
Однако после использования функции COMPOSE эти две версии равны:
На этот раз сравнение дает другой результат:
DECOMPOSE
Как нетрудно догадаться, функция DECOMPOSE является обратной по отношению к COMPOSE : она разбивает составные символы на отдельные кодовые точки или элементы:
INSTR/INSTRB/INSTRC/INSTR2/INSTR4
Все функции INSTR возвращают позицию подстроки внутри строки и различаются лишь по способу определения позиции. Для демонстрации мы воспользуемся таблицей publication из схемы g11n .
Позиция символа У отличается только для INSTRB . Одна из полезных особенностей INSTR2 и INSTR4 заключается в том, что они могут использоваться для поиска кодовых точек, не представляющих полные символы. Возвращаясь к примеру с символом А, умляут можно включить как подстроку для выполнения поиска.
LENGTH/LENGTHB/LENGTHC/LENGTH2/LENGTH4
Функции LENGTH возвращают длину строки в разных единицах:
LENGTH — возвращает длину строки в символах;
LENGTHB — возвращает длину строки в байтах;
LENGTHC — возвращает длину строки в символах Юникода;
LENGTH2 — возвращает количество кодовых единиц в строке;
LENGTH4 — возвращает количество кодовых точек в строке.
Если строка состоит из композиционных символов, функция LENGTH эквивалентна LENGTHC .
В данном примере только функция LENGTHB дает другой результат. Как и ожидалось, LENGTH и LENGTHC вернули одинаковые результаты. Впрочем, при работе с декомпозиционными символами ситуация меняется. Пример:
Функции возвращают следующие значения длины:
Функция LENGTH возвращает количество символов, но считает A и умляут разными символами. LENGTHC возвращает длину в символах Юникода и видит только один символ.
SUBSTR/SUBSTRB/SUBSTRC/SUBSTR2/SUBSTR4
Разные версии SUBSTR определяются по тому же принципу, что и их аналоги у функций INSTR с LENGTH . SUBSTR возвращает часть строки заданной длины начиная с заданной позиции. Функции этого семейства работают следующим образом:
SUBSTR — определяет позицию и длину по символу;
SUBSTRB — определяет позицию и длину в байтах;
SUBSTRC — определяет позицию и длину в символах Юникода;
SUBSTR2 — использует кодовые единицы;
SUBSTR4 — использует кодовые точки.
Использование этих функций продемонстрировано в следующем примере:
Обратите внимание на отличие SUBSTRB от других функций в результатах выполнения сценария:
UNISTR
Функция UNISTR преобразует строку в Юникод. Эта функция использовалась в ряде предыдущих примеров для вывода символов строки, подвергнутой декомпозиции. В разделе «Кодировка символов» в качестве примера была приведена строка, состоящая из кодовых пунктов. Чтобы привести ее к понятному виду, можно воспользоваться функцией UNISTR :

Что такое кодировка?
При обработке символов в компьютерной системе используются числовые коды символов, а не их графическое представление. Схема кодирования символов (encoded character set) задает соответствие между символами, которые могут приниматься и выводиться компьютером или терминалом, и их кодовым представлением. База данных Oracle в настоящее время поддерживает около 30 схем кодирования символов и при этом значительно большее количество языков и территорий (около 100). Это возможно, потому что Unicode - универсальная кодировка, содержащая большинство основных символов, используемых при письме (scripts) в современном мире.
База данных Oracle поддерживает различные схемы кодирования символов:
однобайтовую;
многобайтную переменной ширины;
всемирную.
Однобайтовые кодировки
Примеры однобайтовых кодировок
American Standard Code for Information Interchange (Американский стандартный код обмена информацией - ASCII) 7-bit American (US7ASCII)
ASCII 7-bit Yugoslavian (YUG7ASCII)
DEC VTTOO 7-bit French (F7DEC)
Примечание: ASCII-кодировки поддерживаются только на платформах, основанных на использовании ASCII. Кодировки EBCDIC используются только на платформах, основанных на использовании EBCDIC.
Многобайтовые кодировки
В многобайтовых кодировках на один символ отводится один или несколько байтов. Обычно многобайтовые кодировки используются для поддержки азиатских языков. В некоторых многобайтовых кодировках значение старшего бита используется для указания, является ли байт одиночным или входит в набор байтов, представляющих символ. Другие же кодировки разделяют однобайтовые и многобайтовые символы. Устройство посылает управляющий код, показывающий, что следующие пары байтов будут интерпретироваться как представление одного символа до тех пор, пока не поступит управляющий код возврата к стандартной кодировке. Кодировки, использующие управляющий код, в основном применяются на платформах IBM.
Примеры многобайтовых кодировок переменной ширины
Shift-JIS 16-bit Japanese (JA16S Л S)
MS Windows Code Page 950 with Hong Kong Supplementary Character Set HKSCS-2001
(ZHT16HKSCS)
Unicode 4.0 UTF-8 Universal character set (AL32UTF8)
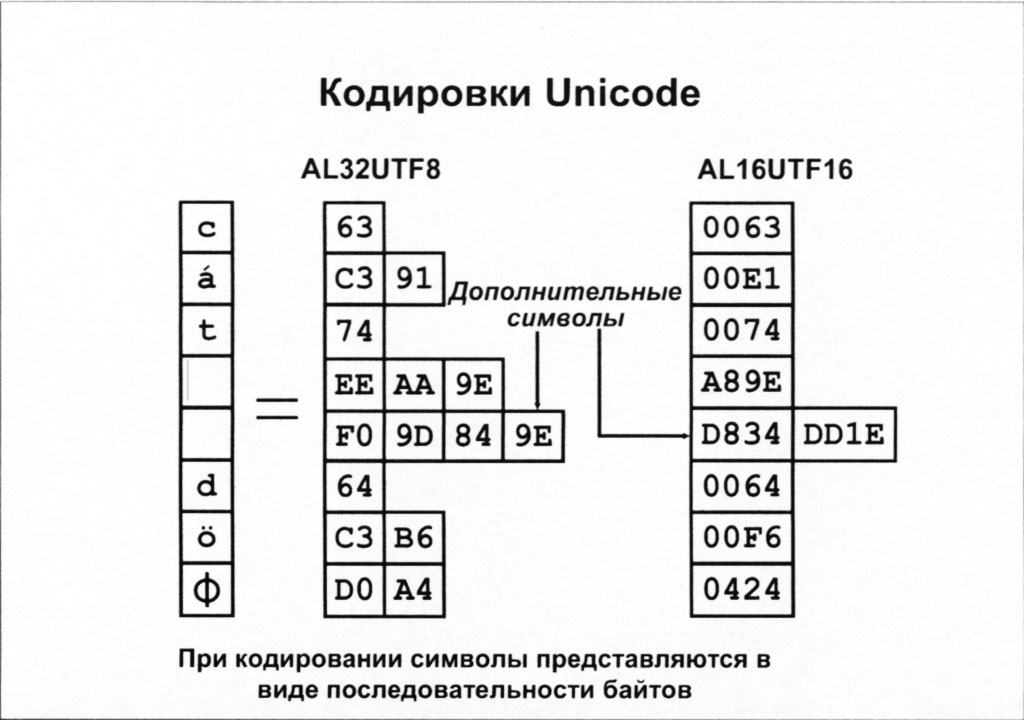
Кодировки Unicode
Unicode - это всемирный стандарт кодирования символов, который позволяет хранить информацию на различных языках в одной схеме кодирования. Unicode предоставляет уникальный код для каждого символа независимо от платформы, программы или языка.
Стандарт Unicode был одобрен многими производителями программного и аппаратного обеспечения. В настоящее время Unicode поддерживается многими операционными системами и браузерами. Стандарты XML, Java, JavaScript, LDAP и WML требуют использования Unicode. Кроме того, стандарт Unicode согласован с стандартом 1SO/1EC 10646.
Кодировка AL32UTF8
Один символ в этой кодировке Unicode может быть предоставлен 1, 2, 3 или 4 байтами. Символы европейских национальных алфавитов поддерживаются с использованием 1 или 2 байтов; Символы азиатских национальных алфавитов - 3 байтами, а дополнительные символы - 4 байтами.
Кодировка AL16UTF16
AL16UTF16 - кодировка Unicode, использующая 16-битовые кодовые последовательности.
В этой системе кодирования один символ может быть представлен 2 или 4 байтами. Символы европейских алфавитов (а также ASCII) и большинства азиатских алфавитов представлены 2 байтами. Дополнительные символы отображаются 4 байтами. AL16UTF16 - основная кодировка Unicode для Microsoft Windows 2000 и Windows ХР.
Дополнительные символы
В первоначальной версии Unicode использовался 2-байтовый формат кодирования. Такое использование 16 бит для каждого кодируемого элемента позволяет представить до 65536 символов. Однако требуется поддерживать значительно большое количество символов. Например, только сообщество говорящих на китайском использует более 55000 символов.
В таких языках, как китайский, японский и корейский еще не закодированы десятки тысяч идеограмм. И несмотря на то, что многие из этих символов используются редко, они все еще представлены в документах, которые должны сохраняться в электронном виде.
Для удовлетворения этого требования в стандарте Unicode определяются дополнительные символы (supplementary characters). Применяя два 16-битовых кодовых указателя (их называют также заменяющими парами (surrogate pairs)) для представления одного символа, можно дополнительно определить до 1 048 576 символов.
Первая группа дополнительных символов (4944 символа) была добавлена в стандарт Unicode 3.1, выпущенный в марте 2001 года. Вместе с уже существовавшими в Unicode 3.0 49194 символами общее число символов, закодированных в Unicode 3.1, составляет сейчас 94140. Это вносит большую сложность в стандарт Unicode. Однако это значительно проще, чем сопровождать большое количество отдельных кодировок. База данных Oracle 10g поддерживает стандарт Unicode 4.0.
Примечание: кодировки UTF-16 и UTF-8 (с дефисом) относятся к кодировкам стандарта Unicode; UTF8, AL32UTF8 и AL16UTF16 (без дефиса) относятся к кодировкам Oracle, основанным на стандарте Unicode.
Примечание: дополнительные сведения о поддержке Oracle стандарта Unicode см. в документе Oracle Database Globalization Support Guide lOg Release 2 (10.2).
Читайте также: