
Подключение oracle к idea
Обновлено: 03.07.2024
Эта статья открывает небольшой цикл, посвященный азам взаимодействия с базами данных (БД) в Java и введению в SQL. Многие программы заняты обработкой и модификацией информации, её поддержкой в актуальном состоянии. Поскольку данные — весьма важная часть логики программ, то под них зачастую выделяют отдельное хранилище. Информация в нём структурирована и подчинена специальным правилам, чтобы обеспечить правильность обработки и хранения. Доступ к данным и их изменение осуществляется с помощью специального языка запросов — SQL (Structured Query Language).
Система управления базами данных — это ПО, которое обеспечивает взаимодействие разных внешних программ с данными и дополнительные службы (журналирование, восстановление, резервное копирование и тому подобное), в том числе посредством SQL. То есть программная прослойка между данными и внешними программами с ними работающими. В этой части ответим на вопросы что такое SQL, что такое SQL сервер и создадим первую программу для взаимодействия с СУБД.
Виды СУБД
- Иерархические. Данные организованы в виде древовидной структуры. Пример — файловая система, которая начинается с корня диска и далее прирастает ветвями файлов разных типов и папок разной степени вложенности.
- Сетевые. Видоизменение иерархической, у каждого узла может быть больше одного родителя.
- Объектно-ориентированные. Данные организованы в виде классов/объектов c их атрибутами и принципами взаимодействия согласно ООП.
- Реляционные. Данные этого вида СУБД организованы в таблицах. Таблицы могут быть связаны друг с другом, информация в них структурирована.
- Что такое SQL-Сервер и как он работает? Взаимодействие с СУБД происходит по клиент-серверному принципу. Некая внешняя программа посылает запрос в виде операторов и команд на языке SQL, СУБД его обрабатывает и высылает ответ. Для упрощения примем, что SQL Сервер = СУБД.
- Data Definition Language (DDL) – определения данных. Создание структуры БД и её объектов;
- Data Manipulation Language(DML) – собственно взаимодействие с данными: вставка, удаление, изменение и чтение;
- Transaction Control Language (TCL) – управление транзакциями;
- Data Control Language(DCL) – управление правами доступа к данным и структурам БД.

Первая программа
Разбор кода
Блок констант:
- DB_Driver: Здесь мы определили имя драйвера, которое можно узнать, например, кликнув мышкой на подключенную библиотеку и развернув её структуру в директории lib текущего проекта.
- DB_URL: Адрес нашей базы данных. Состоит из данных, разделённых двоеточием:
- Протокол=jdbc
- Вендор (производитель/наименование) СУБД=h2
- Расположение СУБД, в нашем случае путь до файла (c:/JavaPrj/SQLDemo/db/stockExchange). Для сетевых СУБД тут дополнительно указываются имена или IP адреса удалённых серверов, TCP/UDP номера портов и так далее.
Обработка ошибок:
Вызов методов нашего кода может вернуть ошибки, на которые следует обратить внимание. На данном этапе мы просто информируем о них в консоли. Заметим, что ошибки при работе с СУБД — это чаще всего SQLException.
Используйте JDBC для подключения к базе данных в Eclipse и IntelliJ IDEA
Используйте JDBC для подключения к базе данных в Eclipse и IntelliJ IDEA
Введение
Обратите внимание, что следующий урок по работе с базами данных касается JDBC, поэтому, если вы хотите подключиться к машине, вы должны загрузить драйвер JDBC в соответствующий проект.Установить этот драйвер очень просто, но он все равно должен быть установлен в первый раз. Без понятия. . . Вот простой учебник
Это руководство состоит из двух частей: одна предназначена для использования Eclipse, другая - для использования IntelliJ IDEA. Я использую оба, так что давайте вместе сделаем запись
Здесь я предполагаю, что вы установили среду java, моя версия jdk - 1.8, а затем версия jdbc - 5.1.45, эти две версии полностью совместимы (обратите внимание, что некоторые версии jdk и версии jdbc не могут быть полностью Совместимо)
Кстати, поделитесь jdbc, который я используюПортал
Во-вторых, Eclipse загружает драйвер JDBC.
1. После загрузки пакета jdbc jar найдите место для его размещения, щелкните правой кнопкой мыши проект, в который хотите загрузить драйвер jdbc, и выберите Свойства.

2. Нажмите «Библиотеки», вы увидите файлы библиотеки существующей среды jdk, нажмите «Добавить внешние JAR» .

3. Найдите свой jdbc, выберите его и откройте


5. Окончательный эффект выглядит следующим образом.

6. Просто написать что-нибудь и попробовать этим воспользоваться? Я только что написал класс, вы можете создать его экземпляр для тестирования
В-третьих, IntelliJ IDEA загружает драйвер JDBC.
1. Щелкните Файл, щелкните Структура проекта.

2. Щелкните Модули слева, щелкните Источник модуля, щелкните + в нижнем левом углу, щелкните JAR или каталоги .

3. Также выберите свой jdbc и откройте

4. Отметьте jdbc и нажмите ОК.

5. Окончательный эффект

6. Если вы хотите протестировать, вы можете создать экземпляр приведенного выше примера кода.

Привет, сегодня покажу как подключить Ваше приложение к базе данных (БД) в бесплатной версии Intellij IDEA (community).В статье будет: много картинок, мало букв, будет интересно и полезно.
1: Создаём новый проект в Intellij IDEA

2: Затем идём вFile->Settings->Plugins->MarketPlace и в поисковой строке вводим Database Navigator.Устанавливаем, перезапускаем Intellij IDEA.

3: После установки плагина и перезапуска Intellij IDEA, в Вашем ТулБаре появится новое окно (DB Navigator)
4: Заходим в новое окно(DB Navigator), нажимаем зелёный плюсик и из предложенного списка выбираем MySQL

5: В появившемся окне вписываем в поле Name, имя которое вы хотите дать базе данных. Описание можно оставить пустым.Host и Port трогать не нужно. Проследите за тем что бы в поле Database была строка mysql. Вводим User и Password (Обычно это (root) для Логина и Пароля). После всего нажимайте Test Connection.

6: При тестировании соединения может возникнуть ошибка временной зоны. Для её исправления в поиске операционной системы вводим mysql, и выбираем MySQL Command Line Client (всё как на картинке).

7: В появившемся консоле вводим пароль БД, И вводим команду set global time_zone = '+3:00';(+3 часа это мой часовой пояс так как я нахожусь в Минске, вы вводите часовой пояс своего города).

8: После исправления ошибки жмите Apply, Ok и в вашем DB navigator появляется структура БД с которой вы можете просматривать таблицы и БД.

9: Рекомендую при просматривании таблиц нажимать на кнопку No filters.


11: Когда архив загрузился, открываем его и извлекаем файл (смотрите картинку) в папку (путь к папке нужно запомнить).

12: Переходим в Intellij IDEA, там ищем File->Project Structure ->SDK's -> плюсик который отмечен стрелкой -> ищем файл который только что скачали -> жмём ОК.

13: База Данных подключена к Intellij IDEA! Теперь надо разобраться как подключиться к ней через приложение. Для этого я создал класс который назвал TestConnection и в нём прописал константы (USER_NAME, PASSWORD, URL), создал статические Statement и Connection.

14: Кстати что бы найти значение поля URL, нужно открыть Ваш DB Navigator, нажать на зелёный плюс, выбрать mysql(Тут БД может попросить логин и пароль), и в открывшемся окне выбрать Info. Скопировать значение строки Connection URL.Это и будет URL.
15: Осталось немного. Просим у ДрайверМенеджера что бы он дал нам соединение (смотрите картинку ниже, верхний красный блок).Всё должно быть обёрнуто в ТрайКэтч. А в нижнем блоке создаём Statement.

16: Как я уже писал статья ориентирована на людей уже знакомых с языком MySQL. все запросы легко гугляться, язык очень простой и является MustHave(обязательно) для каждого BackEND Developer, поэтому я не буду объяснять что написано на языке SQL (было бы очень долго). Что касается Java:
1 — В главном методе (main) нужно указать ClassPath (первая строка на картинке).
2 — Во втором красном блоке у Statement я вызвал метод executeUpdater. Его нужно использовать для обновления или добавления данных в таблице. Метод, по умолчанию, в параметры принимает строку в которую Вам следует писать ваши SQL-запросы обёрнутый в двойные кавычки.
3 — Добавление данных в таблицу наглядно.
4 — Для получения данных из таблицы я вызвал метод executeQuery у Statement, он так же принимает строку в параметры.
5 — Что бы вывести в консоль данные полученные с таблицы я использую цикл while с параметром (смотрите картинку) который проходит все строки таблицы по очереди, а в теле вызывается метод getString у resulySet (Всё как на картинке). этот метод принимает в параметры цифру которая означает номер колонки которую вы хотите получить.

Какие могут быть ошибки
Хочу рассказать о некоторых ошибках с которыми Вы можете встретиться, конечно вы можете это не читать, но это очень важно.
1 — Если создание таблицы прошло успешно, её следует закомментировать потому что так как таблица уже создана, при следующем запуске приложение вылетит, потому что код начнёт отрабатывать по новой и попытается создать ещё одну таблицу с таки же Name, а это запрещено.
Будет вот такая ошибка. Что значит «Таблица Name уже существует»

2 — Так же и со всеми данными, если они добавлены успешно, следует удалять или комментировать строки которые их добавляли или обновляли.
3 — Будьте внимательны с SQL, Intellij IDEA не подчёркивает ошибки которые вы допускаете в синтаксисе, закрывайте скобки и кавычки. Пример ошибки синтаксиса SQL
Не секрет, что Oracle претендует на звание крупнейшего в мире корпоративного облака. Oracle Public Cloud, пригоден, по утверждениям компании, для переноса в себя всех приложений и бизнес-процессов предприятия.

Недавно пришлось попробовать Oracle Java Cloud Service в работе. Впечатления, в общем - положительные, но был немного расстроен, т.к не имел возможности работать с этим сервисом в своей любимой среде разработки - Intellij IDEA.
И вот два дня назад появился плагин Oracle Cloud integration. О том, какие возможности он нам предоставляет, я и хотел рассказать в этой статье.
Установка
Первым делом нам необходимо установить плагин:
1)Скачиваем к себе наш плагин: Oracle Cloud integration;
2)Переходим "File">"Settings">"Plugins" и нажимаем "Install plugin from disk", и указываем путь к скачанному jar файлу;
3)Перезагружаем Intellij IDEA.
Настройка Cloud Configuration
После установки плагина нам необходимо создать Application Server configuration.
1)Переходим в "Run/Debug Configurations";
2)Нажимаем "Add new configuration" и выбираем "Oracle Cloud Deployment";
3)Нажимаем кнопку ". ", и появляется окно конфигурации облака;
4)Нажимаем кнопку "+", задаем имя нашей конфигурации и заполняем все поля;
5)Нажимаем "Test connection". После того как мы увидим "Connection successful" мы можем перейти к настройке Run/Debug Configurations;
6)Нажимаем "OK" и сохраняем наши настройки.
Пример:
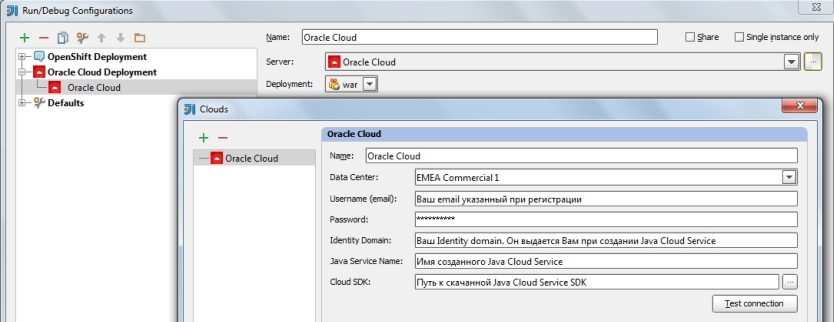
Настройка Run/Debug Configurations
Этот плагин позволяет нам загружать на сервер war и ear артефакты.
1) "Deployment" комбобокс предлагает нам сделать выбор из уже существующих артефактов. Если "Deployment" комбобокс пустой, переходим
"File" > "Project structure" > "Artifacts" и создаем нужный нам артефакт. Теперь у нас все готово к загрузке приложения на сервер.
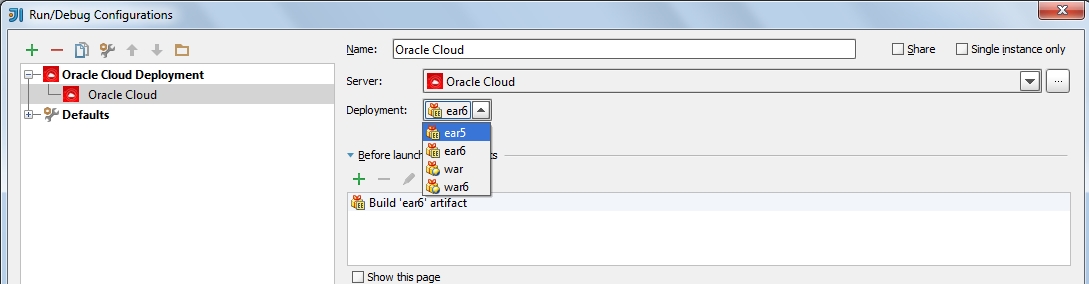
Загрузка приложения на сервер
Теперь у нас все готово к отправке приложения на сервер.
Выбираем созданный нами Run Configuration и нажимаем кнопку "Run" или "Debug". После этого стартует процедура загрузки приложения на сервер.
Oracle Cloud Integration создаст нам приложение с именем, аналогичным имени артефакта.
Access to remote logs
Кроме возможности отправлять на сервер артефакты, плагин также предоставляет нам доступ к логам приложения.
После завершения отправки артефакта на сервер, мы можем просмотреть информацию о процессе загрузки в Event Log-e.
Также там печатается URL, по которому доступно приложение.
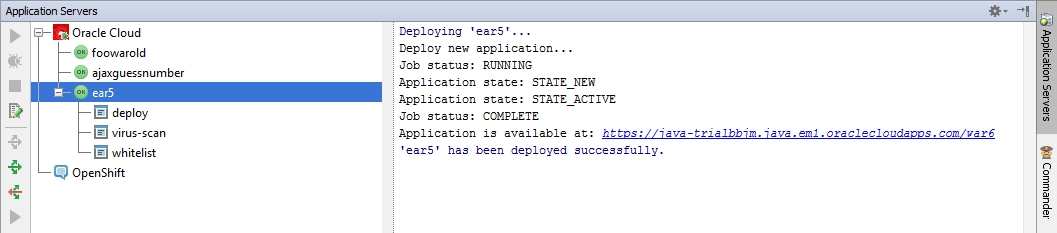
Virus-scan Log

Этот лог предоставляет нам результат проверки приложения на вирусы.
Whitelist Log
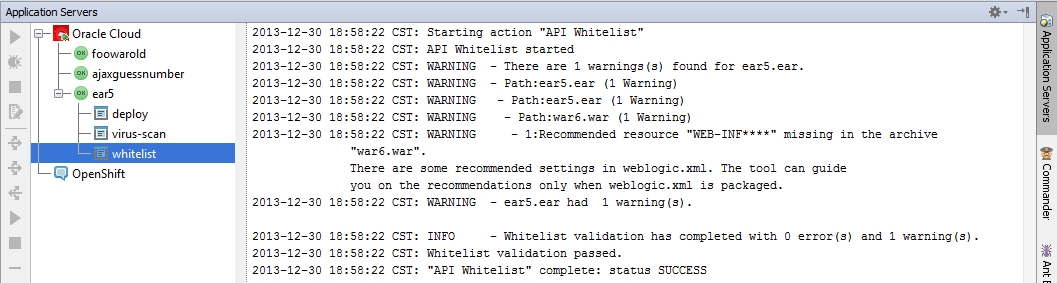
Этот лог отвечает за валидность отправляемого на сервер приложения. В роли сервера нам дается WebLogic server 10.3.6. Если вы будете пытаться загрузить на сервер приложение, несовместимое с данной версией WebLogic, - whitelist сообщит вам об этом. Также, он замечает ошибки в конфигурационных файлах, будь то weblogic.xml или web.xml.
Deploy/Redeploy Log

Данный лог выводит информацию о процессе deploy/redeploy приложения. При возникновении каких-либо ошибок в процессе отправки, вы увидите их именно здесь.
Service instance Log
Заключение
В итоге мы имеем возможность работать с Oracle Java Cloud Service непосредственно из Intellij IDEA.
Надеемся, что в ближайшее время будут добавлены новые возможности.
Из моих экспериментов можно подвести следующие итоги:
1)Не поддерживает отправку JavaEE6 приложений;
2)Не поддерживает отправку Web 3.0 и выше;
3)Поддерживает JavaEE5;
3)Поддерживает Web 2.4, 2.5

IntelliJ IDEA – это интегрированная написанная на Java среда разработки (IDE). Создана она компанией JetBrains и доступна как лицензионное издание сообщества Apache 2, а также в проприетарном коммерческом формате. Поскольку YugabyteDB совместим с PostgreSQL, большинство сторонних инструментов и приложений будут работать “из коробки”.
В этом материале вы узнаете как:
- установить кластер YugabyteDB на движке Google Kubernetes;
- установить БД Northwind;
- настроить IntelliJ для работы с YugabyteDB;
- протестировать некоторые основные функции БД IntelliJ с помощью YugabyteDB.
Распределенные базы данных SQL пользуются популярностью среди организаций, заинтересованных в переносе инфраструктуры данных в облако. Это часто затевается ради уменьшения TCO (Total Cost of Ownership) или избавления от ограничений горизонтального масштабирования СУБД: Oracle, PostgreSQL, MySQL и Microsoft SQL Server. Основные характеристики распределенного SQL:
- Наличие SQL API для запросов и моделирования данных, с поддержкой внешних ключей, частичных индексов, хранимых процедур и триггеров.
- Интеллектуальное распределенное выполнение запросов позволяет отдалить обработку передаваемых по сети данных, уменьшая время отклика на запросы.
- Поддержка автоматического и прозрачного распределенного хранения данных для обеспечения высокой производительности и доступности.
- Обеспечение строго согласованной репликации и распределенных ACID-транзакций.
Для получения углубленных знаний о распределенном SQL, ознакомьтесь с официальной документацией .
YugabyteDB – это высокопроизводительная распределенная СУБД с открытым исходным кодом, построенная на масштабируемом и отказоустойчивом дизайне, вдохновленном Google Spanner. YugabyteDB совместима с PostgreSQL, а также умеет интегрироваться с проектами GraphQL и поддерживает хранимые процедуры, триггеры, а также UDFs.
Остались вопросы – обратитесь к официальному форуму .
Шаг 1: Установка YugabyteDB на кластер GKE с помощью Helm 3
Полный мануал можно найти по этой ссылке. Предположим, что у вас уже есть запущенный и работающий кластер GKE.
Первое, что нужно сделать – добавить репозиторий:
Создадим пространство имен yb-demo:
В ответ получим следующее:
Теперь установим YugabyteDB и укажем значения для некоторых ограничений:

Обратите внимание на внешний IP-адрес и порт для сервиса yb-tserver, который мы собираемся использовать для установления соединения между YugabyteDB и IntelliJ: 35.224.XX.XX:5433.
Шаг 2: Создайте Northwind БД
Следующим шагом является загрузка образца схемы и данных. Вы можете найти множество примеров совместимых с YugabyteDB баз данных в документации для разработчиков. Для этого туториала будем использовать образец БД Northwind, содержащий данные о продажах компании “Northwind Traders”. Это отличная учебная схема для ERP-системы малого бизнеса с клиентами, заказами, закупками, поставщиками, доставкой и прочим.
Подключитесь к yb-tserver-pod:
Чтобы загрузить файлы схемы и данные, выполните следующие команды:
Выйдите из оболочки pod и подключитесь к службе YSQL:
Создайте базу данных и подключитесь к ней:
Теперь можно создать объекты БД и заполнить их данными, используя файлы, которые мы загрузили в yb-tserver-pod:
Убедитесь, что таблицы созданы:
Проверьте, что данные присутствуют, выполнив простой SELECT :
По умолчанию настроенная YugabyteDB поставляется без пароля для пользователя yugabyte. Изменение выполняется так же, как и в PostgreSQL:
Шаг 3: Настройка IntelliJ для работы с YugabyteDB
Откройте окно БД (View > Tool Windows > Database):

Добавьте источник данных PostgreSQL. (New (+) > Data Source > PostgreSQL):

На вкладке General заполните данные для подключения к БД:
- Host: внешний IP-адрес, который GKE назначил YugabyteDB на предыдущем шаге.
- Port: YugabyteDB использует порт 5433.
- Database: образец БД northwind из предыдущего шага.
- User: по умолчанию – это yugabyte.
- Password: пароль из предыдущего шага.
- Driver: установите последнюю версию драйвера PostgreSQL.
Прежде чем нажать кнопку “ОК”, убедитесь, что присутствует соединение.
Шаг 4: Выполнение запроса
Теперь давайте протестируем интеграцию, выполнив следующий запрос в IntelliJ:

В окне вывода должны увидеть следующий результат:

Шаг 5: Генерируем объяснение
IntelliJ умеет создавать визуализацию ваших запросов. Например, можно получить визуализацию последнего запроса, выбрав Explain Plan > Show Visualization.

Примечание: не все функции управления базами данных IntelliJ поддерживаются с помощью YugabyteDB.
Теперь у вас есть кластер YugabyteDB на три узла и GKE с образцом базы данных Northwind, которые и дальше можно использовать в тестах на IntelliJ. Дополнительные сведения о взаимодействии с БД с помощью IntelliJ ищите в документации , а для получения информации о сторонних интеграциях с YugabyteDB ознакомьтесь с документацией для разработчиков.
Читайте также: