
Power query как уменьшить размер файла
Обновлено: 04.07.2024
Данный вопрос возникает периодически на различных форумах. Решил написать некоторые рекомендации по уменьшению веса файла. Применив их Вы сможете понять - действительно ли Ваши данные настолько раздувают файл или же в файле имеется много лишнего.
Почему я это пишу. Бывают ситуации, когда в файле всего один лист, данных на нем на 1000 строк и 20 столбцов. Никаких формул, только значения. Но размер файла непомерно велик - скажем 10 Мб. Этого недопустимо. Или есть различные формулы, но Вы все равно считаете, что размер файла не соответствует тому, что должно бы быть.
Автоматически убрать все лишнее из файла так же поможет команда надстройки MulTEx Оптимизировать книгу
При этом описанные ниже причины, которые влияют на размер файла, так же могут влиять и на его "быстродействие".
Следующие действия необходимо проделать на каждом листе книги:
- Первое, что необходимо вспомнить - а не в общем ли доступе файл ? Если в Общем, то есть вероятность, что размер файла растет именно из-за этого. Дело в том, что при установке общего доступа к файлу, по умолчанию ведется журнал изменений, в который записываются все действия, произведенные в книге каждым пользователем за период, указанный в параметрах. Чем больше пользователей - тем сильнее раздувается файл. Как избавиться или изменить период:
Excel 2007 и выше : вкладка Рецензирование (Review) - Доступ к книге (Shared workbook) ;
Excel 2003 : Сервис - Доступ к книге.
Переходим на вкладку Подробнее(Advanced) и выбираем Не хранить журнал изменений (don't keep change history) .
Еще лучше - снять общий доступ с книги, сохранить. Если общий доступ все еще нужен, то открываем книгу и опять даем общий доступ, но теперь устанавливаем кол-во дней, в течении которых надо хранить журнал. По умолчанию - 30, но можно сделать меньше, если файл сильно разбухает за озвученный период. Далее неплохо бы отключить оба пункта в разделе Включить в личное представление (Include in personal view) : параметры печати (Print settings) и фильтры (Filter settings) . Личные представления позволяют сохранять для каждого пользователя файла свои параметры печати и настройки фильтров. Чем больше разных пользователей – тем больше настроек сохраняется и тем выше вероятность замедления работы файла и увеличения его размеров. А практическая ценность этих пунктов в ущерб удобству и быстроте работы с файлом сомнительная.
После этого сохранить файл.
Подробнее про общий доступ можно прочитать в статье: Ведение журнала сделанных в книге изменений - Убедитесь, что лист не содержит ячеек без данных , но занимающих пространство. Перейдя на лист, нажмите Ctrl+End. Активируется последняя ячейка листа. Если она расположена ниже или правее последних нужных рабочих данных - то удалите все строки и столбцы после последних данных таблицы. Удалите полностью строки. Сделать это быстро можно так. Нажимаем Ctrl+End и попадаем на последнюю ячейку. Выделяем эту строку и нажимаем Ctrl+Shift+стрелка Вверх. Выделились все строки вместе с последней строкой данных. Удерживая Shift жмем на клавиатуре стрелку Вниз. Тоже самое и со столбцами.
- Посмотрите лист на предмет форматирования . Необходимо избегать форматирования ЦЕЛИКОМ столбцов либо строк. Это приводит к раздуванию файла. Все форматирование, выходящее за границы таблицы необходимо убрать. А еще лучше - вообще избегать излишнего форматирования, особенно если книгой никто, кроме Вас не пользуется. Вместо Заливки ячеек - Белым цветом ставьте "Нет заливки".Чтобы убрать все форматирование из ячеек: выделяете необходимый диапазон и:
для Excel 2003 : Правка - Очистить - Формат.
В Excel 2007-2010 : вкладка Главная (Home) - Очистить (Clear) -Очистить форматы (Clear formats) - Проверить наличие в книге лишних объектов . Удаляем объекты:
В Excel 2003: меню Правка- Перейти – Выделить – Объекты.
в Excel 2007-2010: вкладка Главная (Home) -Найти и выделить (Find & Select) -Выделение группы ячеек (Go To Special. ) -Объекты (Objects) .
Нажмите Delete. Все объекты на листе будут удалены. Правда есть небольшой шанс, что на листе так же есть и скрытые объекты. Тогда надо идти в редактор VBA (Alt+F11) -Ctrl+R. Отображаете окно свойств (F4). Находите объект ЭтаКнига (ThisWorkbook), в окне свойств этого объекта находите свойство DisplayDrawingObjects и ставите там значение - -4104-xlDisplayShapes. После этого переходите опять на лист и повторяете операции по выделению и удалению объектов, описанные выше. Зачем все так сложно? То, что мы не видим все объекты на листе не означает, что их там нет. Плюс могут быть объекты нулевых размеров. Как правило "невидимые" и "нулевые" объекты попадают на лист в результате копирования из других файлов и работы различных макросов. И в некоторых случаях объекты переносятся с нулевой длиной и шириной или вообще невидимые. Как следствие - объект не видно, но файл увеличивается в размерах. И при каждом копировании он начинает увеличиваться в размерах в геометрической прогрессии, т.к. по умолчанию объекты копируются вместе с ячейками. После нескольких таких копирований-вставок файл начинает дико тормозить даже при выделении ячеек. Выделили ячейку, хотите выделить другую - файл задумался на пару секунд. - Если привыкли помечать ячейки примечаниями (вкладка Рецензирование -Создать примечание), то самое время задуматься так ли это необходимо. Т.к. примечание это тоже объект, то их избыточное количество на листах так же может привести к замедлению работы файла. Удалить все примечания из выделенных ячеек очень просто: выделяем ячейки - вкладка Рецензирование -Удалить. Небольшой совет: если нет прямой необходимости в хранении примечаний именно таким образом, то самый правильный способ выделить отдельный столбец в таблице, в который заносить примечания для строки данных. Данный способ оптимально подходит для таблиц в правильной структуре. Тогда можно будет осуществлять поиск, сортировку и фильтрацию по примечаниям. Если примечаний уже много и информацию из них необходимо перенести в ячейки, то можно воспользоваться этим решением: Как получить текст примечания в ячейку?
- Еще очень хорошо помогает удаление всех формул и связей . Удаление не в прямом смысле: заменить все формулы значениями, которые они вернули. Это можно сделать без макросов: выделяем все ячейки с данными на листе-Копируем-правая кнопка мыши-Специальная вставка-Значения. Но это не очень удобно, если листов много, поэтому я заготовил для этого еще и макрос, который проделает эту операцию на всех листах активной книги:
Sub All_Names_Visible() Dim objName As Object, wsSh As Object For Each objName In ActiveWorkbook.Names objName.Visible = True Next objName For Each wsSh In Sheets For Each objName In wsSh.Names objName.Visible = True Next objName Next wsSh End Sub
Данный код используется как и предыдущий. Он отображает все имена на листе и в книге. После выполнения макроса необходимо повторно нажать сочетание клавиш Ctrl+F3 на листе. Теперь Вы можете удалить ненужные Вам имена. Так же все имена можно сразу удалить при помощи следующего кода:
Sub Delete_All_Names() Dim objName As Object, wsSh As Object On Error Resume Next For Each objName In ActiveWorkbook.Names objName.Delete Next objName For Each wsSh In Sheets For Each objName In wsSh.Names objName.Delete Next objName Next wsSh End Sub
После всех этих действий необходимо сохранить файл, чтобы изменения вступили в силу. Только после этого станет видно изменился размер файла или нет. Я бы советовал сохранять файл как копию, если не уверены, что удалили действительно ненужное.
Это продолжение перевода книги Кен Пульс и Мигель Эскобар. Язык М для Power Query. Главы не являются независимыми, поэтому рекомендую читать последовательно.
Одной из самых больших проблем для профессионалов Excel является импорт и очистка неструктурированных текстовых файлов. В них зачастую:
- отсутствуют символы-разделители,
- в разных строках поля разделены различным количеством пробелов,
- присутствуют непечатаемые символы,
- повторяются строки заголовка.
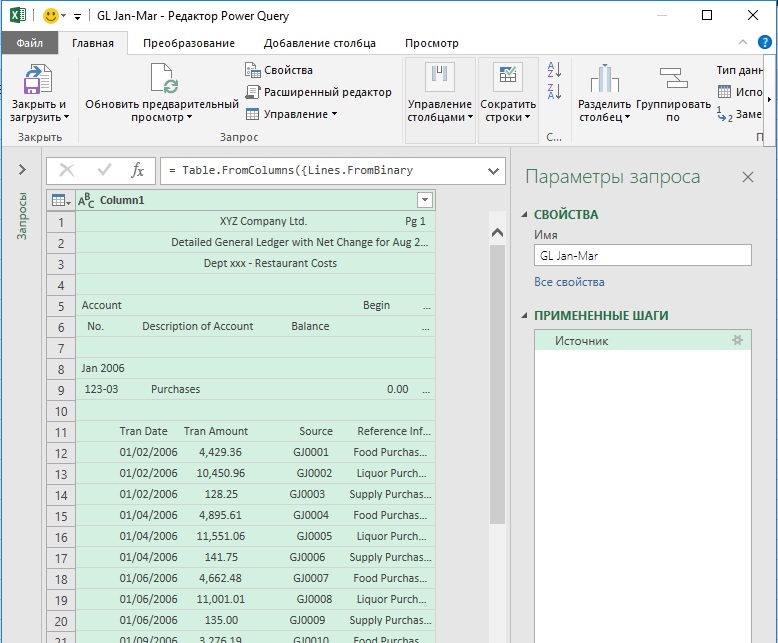
Рис. 7.1. Импорт неструктурированного текстового файла; чтобы увеличить изображение кликните на нем правой кнопкой мыши и выберите Открыть картинку в новой вкладке
Поскольку файл не содержит разделителей, Power Query не сделал никаких предположений о данных. Он предоставил вам возможность обработать данные вручную. На первом этапе основная цель – как можно быстрее представить данные в виде подобия столбцов. Верхние 10 строк, похоже, лишние, а вот 11-я строка напоминает заголовки. Главная –> Удалить строки –> Удаление верхних строк –> 10.
Далее следует избавиться от пробелов. В Excel это стандартная практика при обработке текста. Например, функция СЖПРОБЕЛЫ() удаляет все начальные, конечные и повторяющиеся пробелы, а ПЕЧСИМВ() – непечатные символы. Power Query также умеет это делать. Щелкните правой кнопкой мыши Column1 –> Преобразование –> Очистить. А затем Column1 –> Преобразование –> Усечь. Усечение Power Query работает немного иначе функции СЖПРОБЕЛЫ() в Excel. Усечение удаляет только начальные и конечные пробелы, оставляя внутренние пробелы без изменений.
Разделение столбцов
Следующий шаг – разделение столбцов. Поскольку дата содержит 10 символов, можно попробовать оставить чуть больше, например, 12 для первого столбца. Главная –> Разделить столбец –> По количеству символов –> 12. Обратите внимание на настройку переключателя Разделение:
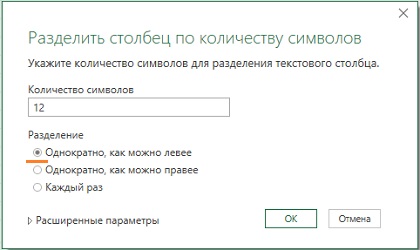
Рис. 7.2. Выделение первого столбца
Повторно усеките два новых столбца:
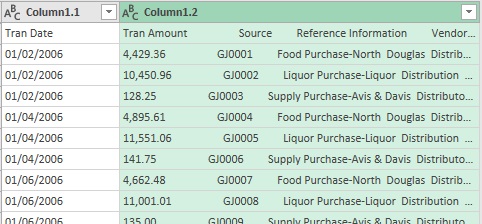
Рис. 7.3. Промежуточный вид запроса
Подберите количество символов для выделения столбца Tran Amount, усеките столбцы после разделения, и т.д. У вас получится приблизительно так:
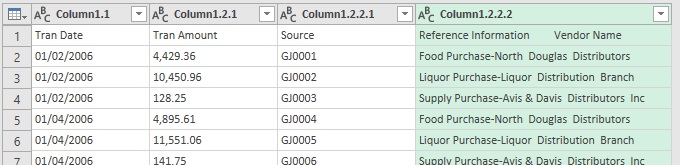
Рис. 7.4. Выделено четыре столбца
Для разделения последнего столбца используйте иной трюк: Главная –> Разделить столбец –> По разделителю –> ˽˽ (два пробела). Усеките два образовавшихся столбца. Обратите внимание, каждый раз, когда вы разделяли столбцы, Power Query автоматически добавлял еще один шаг – изменял тип нового столбца на текст. Это лишнее действие, поэтому удалите все шаги Измененный тип. Далее Главная –> Использовать первую строку в качестве заголовков. С этапом разбиения месива данных на столбцы вы справились:
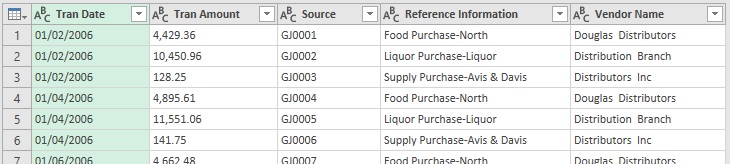
Рис. 7.5. Неструктурированные данные разбиты на столбцы
Удаление мусора
Если вы прокрутите вниз, то обнаружите, что в данных много строк мусора:
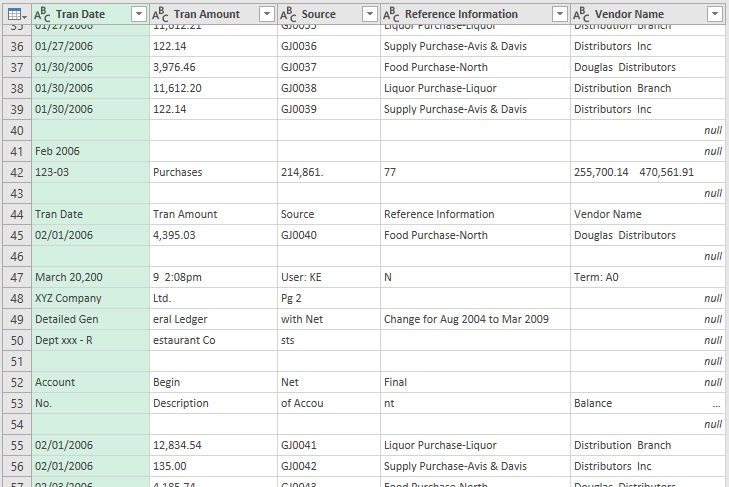
Рис. 7.6. Строки заголовка второй страницы, смешанные с данными
Щелкните правой кнопкой мыши столбец Tran Date –> Тип изменения –> Используя локаль –> Дата –> Английский (США). Подробнее см. Глава 2. Изменение настроек Power Query, действующих по умолчанию. Появится куча ошибок:
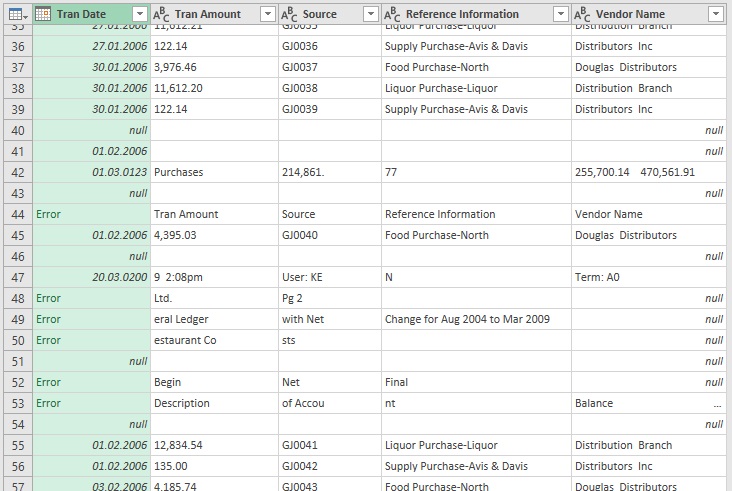
Рис. 7.7. Часть ячеек в столбце Tran Date содержат ошибки или значение null
В отличие от многих других программ, ошибки в Power Query очень функциональны. Их можно контролировать, на них можно реагировать. Изучив ошибки на рис. 7.7, вы увидите, что они появились только в строках, которые являются мусором. Значение null также сигнализируют, что эти строки не нужны. Выделите столбец Tran Date, кликните на нем правой кнопкой мыши, выберите Удалить ошибки. Отфильтруйте столбец Tran Date –> снимите флажок null.
На данный момент всё еще осталось несколько нерелевантных строк, чтобы найти их, сначала отсортируйте Tran Date по возрастанию (рис. 7.8), а затем по убыванию, и снимите флажки с ненужных строк.
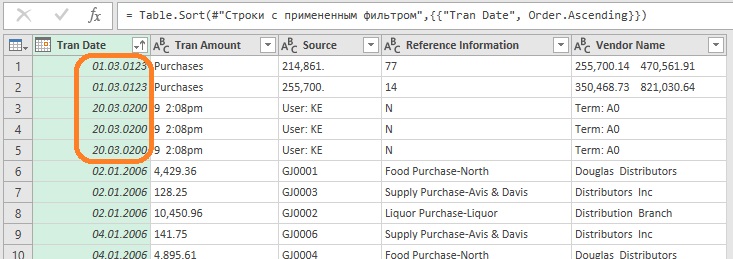
Рис. 7.8. Несколько нерелевантных строк
Щелкните правой кнопкой мыши столбец Tran Date –> Переименовать –> Date. Щелкните правой кнопкой мыши столбец сумма Tran Amount –> Переименовать –> Amount. Щелкните правой кнопкой мыши столбец Amount –> Тип изменения –> Используя локаль –> Десятичное число –> Английский (США). Отфильтруйте столбец Amount –> снимите флажок null. Все строки мусора удалены.
Присмотревшись к данным в двух последних столбцах, вы понимаете, что разбиение на столбцы было выполнено неверно:
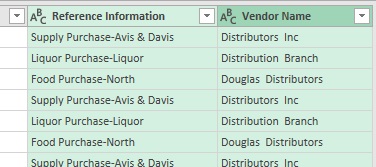
Рис. 7.9. Два последних столбца разделены неверно
Объедините столбцы: выделите столбец Reference Information, удерживая нажатой клавишу Ctrl, выделите столбец Vendor Name. Важно помнить, что порядок выделения столбцов определяет, какой из них будет первым при объединении. Пройдите по меню Преобразование –> Объединить столбцы –> Разделитель –> Пробел. Снова разделите столбцы, используя разделитель дефис. Дайте разделенным столбцам разумные названия: Category и Vendor.
Чистовая обработка
Возможно в названии некоторых поставщиков (Vendor), используется дефис, поэтому в окне Разделить столбец по разделителю установите переключатель в положение Самый левый разделитель:
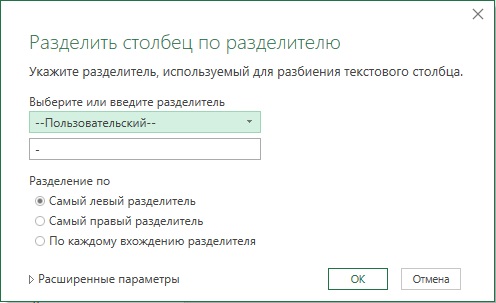
Рис. 7.10. Настройка разделения столбца
Помните, что при настройке этой операции, вы не ограничены разделителями, состоящими из одного символа. Если требуется, вы можете ввести в это поле хоть целое слово.
Возможно, в столбце Vendor остались сдвоенные пробелы. Вы не можете использовать усечение, так как оно не работает между словами в столбце. Щелкните правой кнопкой мыши Vendor –> Замена значений –> Значение для поиска – два пробела подряд –> Заменить на – один пробел –> Ok. Если вы подозреваете, что два пробела подряд могут встречаться несколько раз, повторите шаг с заменой. Дайте запросу говорящее имя, например, Transactions.
Цель достигнута – у вас чистый набор данных (рис. 7.11), который можно загрузить в таблицу: Главная –> Закрыть и загрузить.
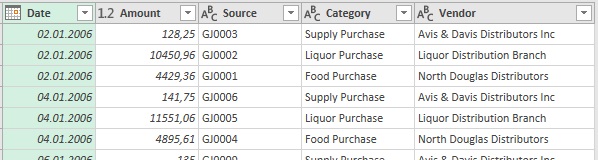
Рис. 7.11. Очищенные данные
Данные загрузятся на лист Excel и будут отформатированы как Таблица:
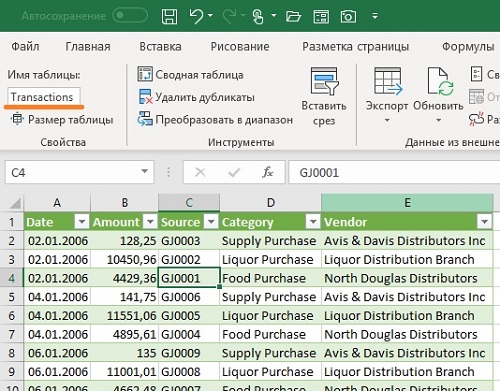
Рис. 7.12. Данные загружены в Таблицу
Проверка импорта
Чтобы проверить качество данных, щелкните в любой ячейке Таблицы, Вставить –> Сводная таблица –> На существующий лист –> Диапазон G2. Настройте сводную таблицу:
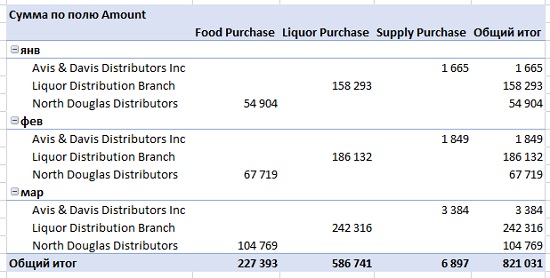
Рис. 7.13. Сводная таблица для проверки качества данных
О качестве данных говорят следующие признаки:
- Даты в строках, сгруппированы по месяцам (если бы хотя бы одно значение в столбце не было датой, группировка не выполнилась)
- Три поставщика в строках (а не их разнобой)
- Три категории по столбцам
- Суммы в ячейках (если бы хотя бы одно значение не было числом, здесь отражалось бы количество ячеек)
Автоматическая обработка подобных файлов
Всё, что было сделано до сих пор, было возможно выполнить и без Power Query. Преимущество описанной методики вы ощутите, когда через квартал к вам поступит новый текстовый файл. В мире Excel это означает еще один утомительный час импорта, очистки и форматирования. В мире Power Query вам нужно выполнить всего лишь несколько простых операций:
- Щелкните правой кнопкой мыши запрос Transactions –> Изменить
- Перейдите к первому шагу и щелкните значок шестеренки
- Измените имя файла GL Apr-Jun.txt
- Главная –> Закрыть и загрузить
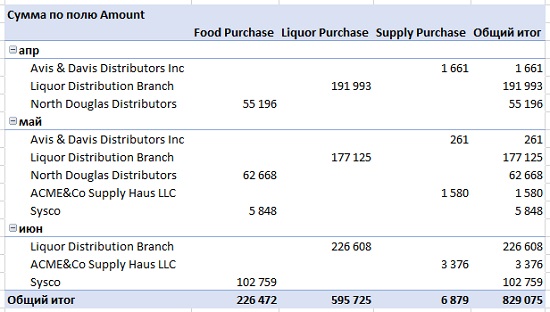
Рис. 7.14. Сводная таблица на данных второго квартала
Появились новые поставщики, новые транзакции и новые даты. Если вам нужны данные, как за первый, так и за второй кварталы, воспользуйтесь импортом всех файлов из папки, как описано в главе 4.
3 комментария для “Глава 7. Импорт больших текстовых файлов в Power Query”
Здравствуйте.
Спасибо большое за ваш блог и за эту книгу!
Я внимательно всё читаю, разбираю примеры и заметил одну странность, которую так и не смог объяснить. В этой главе, если в рассмотренном примере сначала отфильтровать пустые строки, то пропадёт большая часть строк (причём не пустых).
А в последней строке появится ошибка, которую невозможно будет удалить!
Подскажите пожалуйста, почему если в начале мы удаляем ошибки, а потом фильтруем пустые строки, то всё в порядке, а если в начале фильтруем пустые строки, то теряем часть данных и получаем неустранимую ошибку? (прилагаю скриншот к вопросу)
Эта статья предназначена для разработчиков моделей данных Power BI Desktop, создающих модели импорта. В ней описываются различные методы, которые помогут сократить объем данных, загружаемых в модели импорта.
Данные, загружаемые в модели импорта, сжимаются и оптимизируются, а затем сохраняются на диск с помощью подсистемы хранилища VertiPaq. При загрузке исходных данных в память может выполняться 10-кратное сжатие, поэтому есть все основания ожидать, что 10 ГБ исходных данных могут сжаться до размера около 1 ГБ. Кроме того, при сохранении на диск данные могут сжиматься еще на 20 %.
Несмотря на эффективность работы подсистемы хранилища VertiPaq, следует стараться загружать в модели как можно меньший объем данных. Это особенно справедливо в отношении больших моделей или моделей, размер которых предположительно будет расти со временем. Вот четыре наиболее важные причины:
- Модели больших размеров могут не поддерживаться вашей емкостью. Общая емкость вмещает модели размером до 1 ГБ, тогда как емкости Premium — модели размером до 13 ГБ. Дополнительные сведения см. в статье, посвященной поддержке больших наборов данных в Power BI Premium.
- Чем меньше размер моделей, тем меньше состязаний за ресурсы емкости, особенно память. Это позволяет нескольким моделям одновременно дольше оставаться в памяти, что приводит к снижению частоты вытеснения. Дополнительные сведения см. в статье Управление емкостями Premium.
- Модели меньшего размера обеспечивают более быстрое обновление данных, что приводит к сокращению задержек при формировании отчетов, увеличению пропускной способности при обновлении набора данных и снижению нагрузки на исходную систему и ресурсы емкости.
- Уменьшение количества строк в таблице может привести к ускорению вычислений, что повышает общую производительность запросов.
В этой статье рассматриваются восемь различных методов уменьшения объема данных. К этим методам относятся следующие:
Удаление ненужных столбцов
Столбцы таблицы модели служат двум основным целям:
- формирование отчетов для создания макетов отчетов с соответствующими фильтрами, группированием и обобщением данных модели;
- структурирование модели за счет связей, вычислений, ролей безопасности и даже цветового форматирования данных.
Столбцы, которые не служат этим целям, скорее всего, можно удалить. Удаление столбцов называется вертикальной фильтрацией.
Рекомендуется проектировать модели с точным количеством столбцов в соответствии с известными требованиями к отчетам. Эти требования могут со временем меняться, но следует иметь в виду, что проще будет добавить столбцы позже, чем удалить их. Удаление столбцов может привести к нарушению структуры отчетов или модели.
Удаление ненужных строк
Таблицы модели должны содержать как можно меньше строк. Для этого можно загружать в таблицы модели отфильтрованные наборы строк, причем фильтрация может производиться по сущности или по времени. Удаление строк называется горизонтальной фильтрацией.
Фильтрация по сущности предполагает загрузку в модель подмножества исходных данных. Например, вместо загрузки фактов продаж для всех регионов продаж можно загрузить факты только для одного региона. Такой подход к проектированию приводит к созданию большого количества небольших моделей и может также исключить необходимость в определении безопасности на уровне строк (однако потребует предоставления определенных разрешений для набора данных в службе Power BI и создания "дублирующихся" отчетов, подключенных к каждому набору данных). Чтобы упростить управление и публикацию, можно использовать параметры Power Query и файлы шаблонов Power BI. Дополнительные сведения см. в записи блога Deep Dive into Query Parameters and Power BI Templates (Подробный обзор параметров запросов и шаблонов Power BI).
Фильтрация по времени предполагает ограничение объема журнала данных, загружаемого в таблицы типов фактов (и ограничение количества строк дат, загружаемых в таблицы дат модели). Мы рекомендуем не загружать автоматически весь доступный журнал, если только это не требуется явно для создания отчетов. Важно понимать, что временные фильтры Power Query можно параметризировать и даже использовать в них относительные периоды времени (относительно даты обновления, например "данные за последние пять лет"). Также имейте в виду, что ретроспективное изменение фильтров времени не нарушит отчеты. Оно приведет лишь к тому, что в отчетах будут доступны данные за меньший (или больший) период.
Группировка и сведение данных
Пожалуй, самым эффективным способом уменьшения размера модели является загрузка предварительно сведенных данных. Этот метод позволяет получать более обобщенные таблицы типов фактов. Однако из-за этого может снижаться степень детализации.
Например, в исходной таблице фактов продаж для каждой строки заказа имеется отдельная строка. За счет суммирования всех метрик продаж с группированием по датам, клиентам и продуктам можно достичь значительного сокращения объема данных. Учтите, что еще более значительного уменьшения объема данных можно достичь путем группирования по дате на уровне месяца. Это может привести к уменьшению размера модели на 99 %, однако создавать отчеты на уровне отдельных дней или заказов станет невозможно. Решение об обобщении данных фактов всегда сопровождается компромиссами. Последствия этих компромиссов можно уменьшить с помощью смешанной модели, которая рассматривается далее в разделе Переход в смешанный режим.
Оптимизация типов данных столбцов
Подсистема хранилища VertiPaq использует отдельные структуры данных для каждого столбца. Эти структуры данных позволяют добиться максимальной оптимизации для данных числовых столбцов, использующих кодировку значений. Однако текстовые и другие нечисловые данные используют хэш-кодировку. Для этого подсистема хранилища должна присваивать числовой идентификатор каждому уникальному текстовому значению, содержащемуся в столбце. Именно этот идентификатор затем сохраняется в структуре данных, что требует поиска хэша во время хранения и выполнения запросов.
В некоторых случаях исходные текстовые данные можно преобразовывать в числовые значения. Так, номер заказа на продажу может постоянно предваряться текстовым значением (например, SO123456). Префикс можно удалить, а порядковый номер преобразовать в целое число. В случае с большими таблицами это может привести к значительному сокращению объема данных, особенно если столбец содержит уникальные значения или значения высокой кратности.
В этом примере рекомендуется задать для свойства "Способ вычисления итогового значения по умолчанию" значение "Не суммировать". Это позволит свести к минимуму ненужное сведение номеров заказов.
Создание пользовательских столбцов
Подсистема хранилища VertiPaq хранит вычисляемые столбцы модели (определенные в DAX) так же, как и обычные столбцы, источником которых являются Power Query. Однако структуры данных хранятся немного иначе и обычно обеспечивают менее эффективное сжатие. Кроме того, они создаются после загрузки всех таблиц Power Query, что может привести к увеличению времени обновления данных. Поэтому добавлять столбцы таблицы лучше не как обычные вычисляемые столбцы, а как вычисляемые столбцы Power Query (определенные в M).
Предпочтительнее создавать пользовательские столбцы в Power Query. Если источником является база данных, повысить эффективность загрузки можно двумя способами. Вычисление можно определить в инструкции SQL (с использованием собственного языка запросов поставщика) или реализовать как столбец в источнике данных.
Однако в некоторых случаях вычисляемые столбцы модели могут быть предпочтительнее. Это может быть верно в ситуации, когда формула предполагает вычисление мер или требует определенной функции моделирования, которая поддерживается только в функциях DAX. Один такой пример приведен в статье Сведения о функциях для иерархий "родители-потомки" в DAX.
Отключение загрузки запросов Power Query
Запросы Power Query, предназначенные для поддержки интеграции данных с другими запросами, не должны загружаться в модель. Чтобы избежать загрузки запроса в модель, отключите загрузку запросов в таких ситуациях.

Отключение параметра "Автоматические дата и время"
В Power BI Desktop есть параметр Автоматические дата и время. Когда этот параметр включен, он создает скрытую автоматическую таблицу даты и времени для столбцов даты. В этой таблице поддерживаются авторы отчетов при настройке фильтров, группировании и действий детализации для календарных периодов времени. Скрытые таблицы — это по сути вычисляемые таблицы, которые увеличивают размер модели. Дополнительные сведения об использовании параметра "Автоматические дата и время" в Power BI Desktop см. в этом руководстве.
Переход в смешанный режим
В Power BI Desktop в смешанном режиме создается составная модель. Это позволяет определять режим хранения для каждой таблицы. Таким образом, для каждой таблицы свойство "Режим хранения" можно установить в значение "Импорт" или "DirectQuery" (также возможен вариант "Двойной").
Эффективным методом уменьшения размера модели является установка свойства "Режим хранения" для больших таблиц типов фактов в значение "DirectQuery". Учтите, что такой подход к проектированию может хорошо сочетаться с использованием группирования и сведения данных, о которых говорилось ранее. Например, сводные данные по продажам можно использовать для эффективного создания "сводных" отчетов. На странице детализации же могут отображаться подробные данные по продажам для конкретного (узкого) контекста фильтра, то есть приводиться все запросы на продажу, относящиеся к этому контексту. В этом примере страница детализации будет содержать визуальные элементы на основе таблицы DirectQuery, которые используются для получения данных по заказам на продажу.
Однако использование составных моделей связано с множеством последствий для безопасности и производительности. Дополнительные сведения см. в статье Использование составных моделей в Power BI Desktop.
Дальнейшие действия
Дополнительные сведения о проектировании модели импорта в Power BI см. в следующих статьях:
Я собираюсь использовать простой сценарий, чтобы упростить мой вопрос.
У меня есть таблица A (1000 записей). Эта таблица содержит данные за 5 лет
таблица B (1 000 000 записей). Эта таблица содержит данные за 20 лет.
В таблице A также есть столбец, содержащий ключ для присоединения к таблице B. Ключ к самой ранней созданной записи из таблицы B.
Я использую режим импорта для загрузки этих данных. Когда я загружаю обе таблицы, он импортирует все записи из обеих таблиц. Я ищу только те записи из таблицы B, которые присоединяются к таблице A. аналогично INNER JOIN.
Я попытался использовать функцию слияния и выбрать INNER в качестве типа соединения. Теоретически, это должно извлечь только 1000 записей обратно, но когда данные загружаются в PowerBI, все записи из обеих таблиц загружаются в рабочий стол PowerBI.
Я пытаюсь уменьшить размер набора данных, только извлекая соответствующие записи из таблицы B, но безуспешно.
Кто-нибудь есть какие-либо предложения?
2 ответа
Удалите все поля, которые вы не используете, особенно те, которые имеют большое количество различных значений для хранения. Фильтруйте ваш запрос по датам и другим полям. Если вы смотрите в качестве примера только год, не загружайте данные за 3 года. Здесь мы также фильтруем по бизнес-сегменту, продавцу или территории в зависимости от того, что показывает модель данных. У меня есть один большой набор для полного представления, но я считаю, что меньшие, более ловкие отфильтрованные наборы неоценимы для конкретных данных.
Используйте анализатор VertiPaq, чтобы узнать, какие части модель дорогая
Импортируйте таблицу A и таблицу B в редактор запросов, выполните внутреннее объединение, чтобы создать новую таблицу C, в которой есть только совпадающие строки.
Затем щелкните правой кнопкой мыши таблицу A и таблицу B и снимите флажок «Включить загрузку», чтобы эти таблицы использовались только как соединения, а не загружались в модель данных и сохранялись в PBIX.

Как я уже рассказывал, в Power Query существует возможность извлекать данные сразу из всех файлов в указанной папке, воспользовавшись командой Данные -> Создать запрос -> Из файла -> Из папки.
Так как данная команда отображает информацию о всех файлах содержащихся в указанной пользователем директории, то эту особенность можно использовать также и в качестве своеобразного инструмента для инвентаризации файлов.
Объясню на примере - допустим мне необходимо получить список всех видеофайлов из определённой папки а также и узнать какие из них занимают слишком много места.
Для решения этой задачи, открываю MS Excel и выбираю упомянутую выше команду, а именно Данные -> Создать запрос -> Из файла -> Из папки.

Далее, указываю директорию (папку) в которой находятся все мои папки с видеофайлами.

И после этого Power Query формирует таблицу с перечислением всех файлов находящихся в указанной директории.
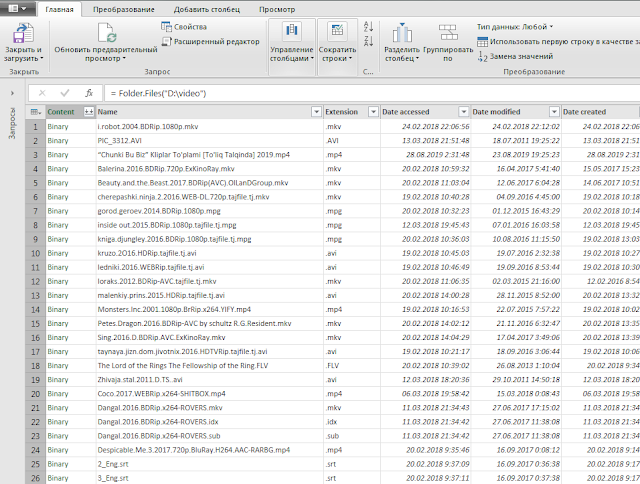
Из этой таблицы мне нужны только столбцы Name, Attributes и Folder Path. Выделяю каждый из этих столбцов удерживая клавишу Ctrl и из контекстного меню правой кнопки мышки выбираю команду Удалить другие столбцы.
Так как я хочу узнать какие видеофайлы занимают больше всего места, мне нужно отсортировать их по размеру, но в текущей таблице этих данных пока нет. Чтобы получить информацию о размере каждого файла, нажимаю на иконку со смотрящими в разные стороны стрелками на заголовке столбца Attributes, и из появившегося списка всевозможных аттрибутов файла, выбираю Size и жму OK.

И получаю готовый, отсортированный а самое главное - легко обновляемый список доступных на компьютере видеофайлов.
Читайте также: