
Скорость доступа к какой памяти наименьшая
Обновлено: 07.07.2024
Расширение пропасти между производительностью процессоров и скоростью доступа к памяти, появление приложений, интенсивно взаимодействующих с памятью через единое адресное пространство, стимулировали создание вычислительных систем с новой архитектурой. Однако для оценки таких систем традиционные тесты уже не подходят. Пришло время тестов «анти-Linpack».
« Известно, что скорость выполнения многих приложений, работающих на высокопроизводительных системах, заметно отстает от их заявленной пиковой производительности, что объясняется, в частности, неоптимальной организацией работы с памятью и коммуникационной сетью. Аналогия здесь исключительно проста: неважно, с какой скоростью может работать конвейер по сборке автомобилей, если ему вовремя не будут поставлены необходимые узлы— значит, он будет простаивать. Высокая производительность, демонстрируемая процессорами компьютерной системы и фиксируемая на тестах Linpack или SPEC, оказывается по этой причине малоинформативной— реальная производительность определяется задержками при работе с памятью и сетью. Данная проблема неадекватности оценки только ухудшается. Производительность процессоров ежегодно растет на 60%, но задержки при обращении к памяти снижаются лишь на 7%, а для коммуникационных сетей ситуация сложнее, но, в целом, еще хуже. Сегодня задержки обращения к памяти оцениваются в сотни тактов процессора, а к сети— от нескольких тысяч до десятков тысяч тактов.
Пока речь идет об обычных приложениях с хорошей пространственно-временной локализацией обращений к участкам памяти небольшого объема, проблему больших задержек можно решить путем увеличения объемов кэш-памяти и использования статического (Itanium) или динамического (Pentium) суперскалярного параллелизма выполнения соседних машинных команд. Однако для приложений с интенсивным и нерегулярным доступом (Data Intensive Systems, DIS) к большим участкам памяти эти приемы не помогут. Требуются новые архитектуры и решения.
Обычно проблема становится нагляднее и быстрее решается при наличии соответствующих оценочных тестов. Например, рейтинг Top500, составленный на базе результатов теста Linpack, способствовал прогрессу в достижении высокой производительности процессоров. Применяемые реализации этого теста имеют лучшую из известных пространственно-временную локализацию обращений к памяти. Для решения проблемы повышения эффективности подсистемы памяти применим тест RandomAccess, оценивающий работу памяти в наихудшем режиме ее использования с самой плохой пространственно-временной локализацией обращений к памяти большого объема по случайным адресам. Этот тест оценивает эффективность такого доступа в единицах измерения, называемых GUPS (Giga-Updates per Second— миллиард операций модификации памяти, выполненных за секунду), поэтому его иногда упрощенно называют тестом GUPS. Другое название этого теста, «анти-Linpack», отражает тот факт, что он с иной стороны, нежели Linpack, оценивает вычислительную систему.
DIS-приложения
К категории DIS относят приложения со следующими общими свойствами:
низкая повторяемость обращений к одним и тем же участкам памяти (низкая временная локализация); малая вероятность обращений к памяти по последовательным адресам (низкая пространственная локализация); большой объем памяти, необходимой для работы приложений (высокая интенсивность работы с данными); слабая предсказуемость смены адресов участков памяти, к которым происходят обращения.Эти свойства делают бесполезными усилия по увеличению объемов кэш-памяти и применению схем «предварительной накачки» данных. Одна задача может и не обладать всеми этими свойствами, однако тест RandomAccess имеет все эти свойства сразу, причем каждое свойство в наихудшем варианте. К перечисленным свойствам DIS-приложений недавно добавились еще требования выполнять на фоне вычислений такого типа обработку колоссальных потоков данных. Это направление получило название Data-Intensive Computing (DIC).
В качестве примеров DIS-приложений можно назвать: задачи, оперирующие с разреженными матрицами; задачи на графах; расчетные задачи на динамически изменяемых сетках нерегулярной структуры; задачи дискретного имитационного моделирования; коммерческие приложения, интенсивно работающие с корпоративными базами данных. Впервые данная аббревиатура была упомянута в проекте DARPA DIS, в рамках которого был составлен пакет тестовых задач и проведены исследования для оценки эффективности решения таких приложений, как радиолокация, обработка и распознавание сложных изображений и сигналов [1]. К настоящему времени к числу тестовых задач добавились обработка разведывательной информации, создание биологического оружия нового поколения, системы управления боевых роботов. Среди «мирных» примеров подобных приложений можно назвать: криптоанализ; средства наблюдения и слежения; моделирование сложных физических систем, включая разработку новых источников энергии и безопасных энергетических установок; задачи из области нанотехнологий; прогнозирование погоды и климатических изменений; разработка новых лекарственных препаратов; информационно-управляющие социально-экономические системы.
Компьютерные системы для выполнения подобных приложений активно ведутся сейчас в рамках проектов DARPA HPCS и DARPA PCA (разработка наземных и бортовых компьютеров), отечественного проекта «Ангара», целью которого является создание суперкомпьютера стратегического назначения, а также специального комплексного проекта Тихоокеанской северо-западной национальной лаборатории Министерства энергетики США по практическому внедрению вычислительных систем нового поколения [2].
Проиллюстрируем на примере, как традиционные системы справляются с задачами DIS. На рис. 1 для микропроцессора Itanium 2/1,3 ГГц с пиковой производительностью 5,2 GFLOPS приведены полученные в НИЦЭВТ данные для теста из набора EUROBEN (поэлементное умножение двух векторов). Четыре варианта этого теста отличаются способом выборки элементов векторов из памяти. В случае последовательной выборки векторов с единичным шагом результаты самые высокие, но и они составляют лишь 23% от пиковой производительности, а при усложнении выборки результат ухудшается, вплоть до 6% при выборке элементов векторов по индекс-вектору. При этом на рис. 1 приведены данные для коротких векторов, которые могут поместиться в кэш-памяти, но если длины векторов увеличить, то реальная производительность на этом тесте может упасть до 0,3% от пиковой.
Данный тест показывает, насколько чувствителен микропроцессор Itanium 2 к пространственно-временной локализации данных и интенсивности работы с памятью. Аналогичные результаты демонстрируют микропроцессоры Pentium, Opteron и Power.
Комплект HPC Challenge
Сегодня при оценочном тестировании вычислительных систем уже невозможно пользоваться одним-двумя тестами для анализа производительности— требуется система из нескольких специально подобранных тестов. Разработанный в рамках программы DARPA HPCS пакет оценочных тестов HPC Challenge— яркий пример такого комплекта.
HPC Challenge содержит семь тестов:
HPL является одной из реализаций теста Linpack, измеряющего производительность вычислительной системы при решении систем линейных уравнений; DGEMM показывает производительность при умножении плотнозаполненных матриц; STREAM используется для измерения пропускной способности памяти при регулярном доступе; RandomAccess измеряет скорость выполнения обращений к памяти по нерегулярным адресам; FFT показывает производительность системы при выполнении быстрого преобразования Фурье; PTRANS измеряет пропускную способность сети, наблюдаемую при параллельном транспонировании матриц;Тесты в HPC Challenge подобраны таким образом, чтобы исследовать производительность системы на всем диапазоне пространственно-временной локализации обращений к памяти. Так, например, тесты HPL и DGEMM имеют высокую пространственно-временную локализацию, FFT— высокую временную и низкую пространственную локализацию, а STREAM— низкую временную и высокую пространственную локализацию при единичном шаге по памяти. На рис. 2 показан пример диаграммы сравнения на этом наборе тестов трех систем из 64 узлов на базе микропроцессоров AMD Opteron, использующих разные коммуникационные сети (RapidArray, Quadrics и Gigabit Ethernet).
Для перспективных вычислительных систем нового поколения, предназначенных для выполнения DIS-приложений, наибольшее значение имеет составляющая G-RandomAccess теста HPC Challenge.
Тест RandomAccess
Тест RandomAccess состоит в выполнении операций модификации ячеек памяти, расположенных по случайным адресам в пределах приблизительно половины физически доступной памяти в исследуемой системе. Под модификацией памяти подразумеваются три операции над 64-разрядным словом: чтение его из памяти, выполнение над ним какой-либо арифметико-логической операции (сложение, логическое И, логическое ИЛИ, исключающее ИЛИ) и запись слова обратно в память. По аналогии с оценкой производительности вычислительных устройств, оцениваемых в MFLOPS, принята единица измерения производительности по тесту RandomAccess— 1 GUPS.
Эта программа тестирования случайным образом читает и обновляет отдельные блоки памяти, имитируя процесс доступа приложений к данным, например, для заполнения большой таблицы или построения гистограммы путем «просеивания» большого объема исходных данных. Элементы памяти индексируются в виде большого массива (при этом способ разбиения адресов между процессорами в системе с распределенной памятью не специфицируется), а номер элемента подбираются с помощью генератора случайных чисел LSFR, чьи параметры вычисляются так, чтобы обеспечить максимальный период повторяемости. Ясно, что для систем с кэш-памятью индексированное чтение по произвольным адресам— достаточно тяжелая операция, сводящая на нет все усилия разработчиков по увеличению кэш-памяти и обычно применяемая для улучшения показателей при выполнении традиционных тестов. Для получения приемлемых результатов по тесту RandomAccess кэш-память процессора должна быть равна всей доступной оперативной памяти системы.
Для разработчиков и пользователей представляет интерес GUPS-рейтинг исследуемой системы и рейтинг ее отдельных компонентов, например, GUPS-рейтинг многопроцессорной системы с распределенной памятью, GUPS-рейтинг SMP-узла или отдельного процессора. Результаты выполнения тестов RandomAccess публикуются на сайте HPC Challenge и имеют официальный статус. Кроме того, этот тест в обязательном порядке используется во множестве исследовательских работ по архитектуре, при испытаниях нового оборудования. Максимальный результат на тестах RandomAccess в начале 2008 года составлял 35,5 GUPS для суперкомпьютера BlueGene/L и 33,6 GUPS для Cray XT3. Однако у создаваемых по проекту DARPA HPCS перспективных систем этот показатель должен быть 64000 GUPS.
Каждому суперкомпьютеру— по GUPS
В таблице 1 приведены результаты тестирования некоторых систем.
Лучший результат по G-RandomAccess на системе IBM BG/L был получен за счет использования большого количества процессоров (65536)— несмотря на то, что отдельный процессор PowerPC440 оказывается в два с половиной раза хуже, чем AMD Opteron в системе Сray XT3 (последняя заняла второе место при использовании меньшего количества процессоров— 25600).
Показатель S-Random для современных коммерческих динамически суперскалярных микропроцессоров до недавнего времени не превышал 0,015 GUPS для одного ядра, при этом наблюдалась деградация при увеличении используемого количества ядер и вычислительных узлов. Показатель S-Random для современных статически суперскалярных микропроцессоров (VLIW или EPIC архитектура) находится на уровне 0,002 GUPS (например, SGI Altix 4700 и другие системы с микропроцессором Itanium 2), что почти в восемь раз хуже, чем для динамически суперскалярных микропроцессоров. Рекордный результат для одного процессора составляет 0,59 GUPS и получен на векторном заказном микропроцессоре системы NEC SX-8.
Программа создания перспективных суперкомпьютеров
Министерство обороны США реализует сегодня программу создания суперкомпьютеров с перспективной архитектурой. Эта программа окажет влияние на отрасль и определит дальнейшее развитие индустрии суперкомпьютеров.
Как видно из таблицы, показатель G-Random на современных вычислительных кластерах на базе суперскалярных микропроцессоров и коммерческих коммуникационных сетей масштабируется плохо. Типичная ситуация— HP XC 3000, для которого на 64 ярах (32 процессора Woodcrest) удается увеличить производительность в три раза до 0,045 GUPS, однако далее идет деградация. Показатель G-random плохо масштабируется и для векторных процессоров, исключение составляет лишь Cray X1E.
Cитуация c результатами на тесте RandomAccess меняется весьма динамично. Данные по кластерам на январь 2008 года уже гораздо лучше; во всяком случае, для кластеров Intel Atlantis, Discovery и Endeavour на 1000 процессорах был получен показатель 2,5 GUPS. Векторные процессоры также демонстрируют рост показателей и улучшение масштабируемости. Например, на экспериментальной установке с опытными кристаллами системы Сray BlackWidow уже на 64 процессорах получено значение 5,4 GUPS; ожидается, что на серийных кристаллах этот показатель будет вдвое выше. Однако, современные кластеры на базе коммерчески доступных микропроцессоров имеют все-таки низкую производительность в GUPS, поэтому в некоторых системах выполняют своеобразный «тюнинг» путем добавления внекристальных специализированных СБИС, которые реализуют функции работы с глобально адресуемой памятью и при этом обеспечение толерантности к задержкам. Такой тьюнинг был сделан в Cray T3E и Сray XT3/XT4/XT5, планируется в Сray Cascade за счет добавления сетевого микропроцессора GEMINI. Умельцы придумали еще один путь повышения показателя производительности за счет программной реализации функций «тьюнинговых» внекристальных СБИС, выполняемых на дополнительных ядрах микропроцессора. Такое решение выглядит достаточно разумным, учитывая, что вычислительная мощность этих ядер на задачах с интенсивным и нерегулярным доступом к данным бесполезна. В этом направлении уже получены обнадеживающие результаты [3].
Тест RandomAccess, как и тест Linpack, уже начал играть свою положительную роль, определяя направление усовершенствования вычислительных систем— повышаются характеристики классических систем, появились новые системы, которые можно объединить в рейтинг по этому тесту. Явный фаворит в этой гонке— Cray XMT (Eldorado) на базе 8 тыс. процессоров, для которого предполагается получить показатель в 120 GUPS. Один из первых образцов Cray XMT планируется установить в Тихоокеанской северо-западной национальной лаборатории для выполнения исследований и разработок по проекту DARPA DIC, а образцы других фаворитов— Cray BlackWidow и CrayBaker будут развернуты в Окриджской национальной лаборатории.
Литература
Data Intensive Systems (DIS) Benchmark Performance Summary. AFRL-IF-TR-2003-198. Final Technical Report, August 2003. Titan Corporation. Data Intensive Computing. Pacific Northwest National Laboratory. U.S.Department of Energy. 2007. K. Underwood, M. Levenharden, R. Brightwell, Evaluating NIC Hardware Requirements to Achive High Message Rate PGAS Support on Multi-Core Processors. SC07, November 10-16, 2007.Технология RandomAccess
Тестирование осуществляется на массиве T размером 2 n 64-разрядных слов, над которыми выполняется модификация на основе логической операции исключающего ИЛИ: T[k] = T[k] XOR ai, где ai— это 64-разрядное слово из потока Ai псевдослучайных чисел, генерируемых полиномом (x 63 + x 2 + x + 1). Изначально задается, что количество обращений к элементам массива T в четыре раза больше количества его элементов, что дает шанс элементам T попасть в кэш-память.
При выполнении теста имеется ряд дополнительных условий, например, возможно отложенное исполнение модификаций, но каждому процессору разрешается сохранять не более 1024 неисполненных модификаций. В случае параллельного исполнения модификаций возможна ситуация, при которой одновременно модифицируется одна и та же ячейка памяти; в этом случае одна модификация будет потеряна, что допускается, однако количество потерянных модификаций не должно превышать 1%.
Тест Random-Access предлагается запускать в трех вариантах.
S-RandomAccess— обработка осуществляется локально только на одном узле или процессоре. EP-RandomAccess. Имеется несколько узлов, каждый из которых выполняет последовательный тест S-RandomAccess без взаимодействия между узлами (вариант получил название Embarassingly Parallel— «неограниченно параллельный»). G-RandomAccess. Глобальное выполнение, при котором несколько узлов вместе обрабатывают один тест над общим массивом данных T, распределенным между узлами. Поток Ai делится между процессорами на интервалы, так что каждый процессор работает только со своим собственным интервалом.Имеются две версии реализации— локальная (последовательная) и глобальная (параллельная, на MPI). Последовательная при использовании соответствующих компиляторов может быть векторизована или распараллелена с использованием тредов. Имеется вариант теста на языке UPC, в котором массив T находится в адресуемой тредами памяти, а элементы его циклически распределены между тредами. Параллельная версия написана с использованием MPI-1 для двух случаев— число процессоров является степенью двойки или не является. В последнем случае не удается распределить память поровну между процессорами, поэтому для MPI-программ, построенных по SIMD-модели вычислений, происходит рассинхронизация, приводящая к снижению показателей теста.
Процедура сборки теста достаточно стандартна— требуется запустить скрипт для Unix-утилиты make(1), причем имеются варианты для большинства системных платформ.
Привет Пикабу! Последние несколько лет в сети разгораются жаркие споры о том, нужна ли быстрая память игровому ПК и так ли важны ее тайминги. В этой статье мы расскажем, стоит ли так внимательно смотреть на тайминги и какая частота оптимальна, а так же сколько ОЗУ нужно именно вам. Как всегда - текстовая версия под видео.
В случае с процессорами AMD Ryzen все понятно — там внутренняя шина напрямую зависит от частоты ОЗУ, так что чем последняя больше, тем быстрее передаются данные между кластерами ядер и тем быстрее работает CPU.

Но в случае с Intel такого нет, кольцевая шина этих процессоров не зависит от частоты ОЗУ. К тому же большая часть игровых ноутбуков работает на медленной памяти с частотой 2400-2666 МГц без каких-либо проблем в играх, как и многие относительно старые топовые Core i7, которые вообще пашут вместе с DDR3 на частоте 1600 МГц и в ус не дуют. Чтобы этот обзор был полезен обоим лагерям, мы расскажем, так ли нужна быстрая память для современного игрового ПК на процессоре Intel, нужно ли так внимательно обращать внимание на тайминги и сколько оперативной памяти нужно современному ПК для игр и работы. Посмотрим, так ли нужны низкие тайминги, и как FPS в тяжелых играх зависит от частоты ОЗУ.
Минутка теории
В этой статье мы будем рассматривать реальную игровую систему с реальными настройками графики. Иными словами, не будет никаких тестов в HD с минимальным пресетом, чтобы максимально нагрузить процессор — все игровые бенчмарки прогонялись в народном разрешении 1920х1080 на максимальных настройках, чтобы упор был именно в видеокарту. В противном случае, если упор идет в процессор, низкий FPS будет еще терпимой проблемой — вы скорее всего будете получать фризы и непрогруженные текстуры. Конечно, если вы суровый челябинский геймер, едва ли это вас остановит, но мы все же рассматриваем реальные игровые условия.
Также мы рассматриваем ситуацию, когда видеокарте хватает собственной памяти — в противном случае вы опять же можете столкнуться с проблемами производительности в играх, и быстрая ОЗУ едва ли вас спасет, потому что она все еще будет чуть ли не на порядок медленнее видеопамяти. Перейдем к тестовой системе.

Что будет, если задрать тайминги в облака?
Первое, что мы проверим — что будет, если мы очень сильно увеличим тайминги ОЗУ. Что же это такое? По сути оперативная память — это набор ячеек, которые могут хранить 0 или 1. Однако процессору, чтобы добраться до определенной ячейки, нужен ее точный адрес — банк памяти, строка и столбец. Тут все очень похоже на реальные адреса — на письме вы должны указать город, улицу, дом и лишь потом только квартиру.
При это процессор — очень ответственный почтальон, он должен точно знать, сколько у него займет по времени обращение к определенной ячейке. И как раз это время и есть тайминг, и всего выделяют 4 основных или первичных, а также с десяток вторичных и нередко под полсотню третичных. Максимальный вклад в быстродействие памяти дают именно первичные тайминги, поэтому именно их мы и будем рассматривать.

И, очевидно, чем тайминги меньше, тем быстрее процессор сможет добираться до нужных ячеек и тем быстрее он будет работать с ОЗУ, поэтому выглядит разумным покупать тот комплект памяти, у которого минимальные задержки на своей частоте.
Итак, тест памяти и кэша в AIDA64 показал, что при таком завышении таймингов слегка снизилась скорость копирования и на 10% увеличилась задержка доступа к ОЗУ. Последнее как раз и было ожидаемо с учетом того, что мы сильно увеличили тайминги, но в общем и целом падение сложно назвать катастрофическим.


Ладно, а как себя поведет игра World War Z на API Vulkan? Он низкоуровневый и в теории может лучше работать с железом. Но и здесь разницы нет — что с оптимизированными, что с задранными таймингами FPS непоколебим и составляет 180.

Может в Far Cry New Dawn картина изменится, как-никак эта игра не очень хорошо оптимизирована под многопоток? И да, разница действительно есть, но ее сложно назвать значительной — средний FPS при увеличении таймингов снизился с 125 до 122, то есть лишь на 2%.

Какой отсюда можно сделать вывод? Даже если поставить откровенно гипертрофированные тайминги, разница в FPS минимальна или ее нет совсем. С учетом того, что продающиеся наборы ОЗУ нередко уже из коробки имеют неплохие тайминги для своей частоты, нет никакого смысла переплачивать за дорогие комплекты с небольшими задержками — вы едва ли уловите разницу в FPS. И это же, в теории, касается процессоров AMD.

Почему так происходит? Все просто — подавляющее большинство современных и не очень процессоров и имеют по три или даже четыре уровня кэша. И информация из ОЗУ заранее пишется в кэш, и лишь потом с ней работает CPU. А с учетом того, что кэша третьего уровня много, нередко пара десятков мегабайт, влияние задержек доступа к памяти становится минимальным.
Играемся с частотой памяти
Окей, а есть ли вообще смысл в большой частоте ОЗУ? Мы решили проверить три варианта. Первый — это DDR4-2133, минимальная пользовательская частота для последнего поколения памяти. Да, вы можете сказать, что большая часть процессоров даже на неразгонных платах поддерживает частоту хотя бы 2400 МГц, но мы решили пойти по самому минимуму и рассмотреть вариант, когда в компьютере стоит самая дешевая память с AliExpress.
Второй вариант — это DDR4-2933. Именно такую память способны поддерживать современные процессоры Intel Core 10-ого поколения, они же Comet Lake, на всех платах даже без разгона. С учетом того, что возможности по оверклокингу у таких процессоров чисто номинальные и вы от силы получите несколько лишних процентов производительности, возникает вопрос — а есть ли вообще смысл переплачивать за платы на чипсете Z490, раз CPU почти не гонится, и остается только разгон памяти?
Ну и третий вариант — это текущая конфигурация на DDR4-3400. Такая частота доступна подавляющему большинству современных процессоров Intel, даже если это урезанные Core i3, при этом планки на ней стоят вменяемых денег.
Для начала — все тот же тест ОЗУ из AIDA64. Тут уже падение скоростей чтения и записи сложно назвать слабым — шутка ли, DDR4-3400 быстрее стоковой DDR4-2133 в полтора раза. А вот задержки увеличились не очень сильно, приблизительно на 20% — сказывается то, что тайминги в обоих случаях были неплохо оптимизированы.

Перейдем к тестам в играх, и начнем с все той же Assassin's Creed Odyssey. Падение частоты больше чем на 20%, с 3400 до 2933 МГц, игра просто не заметила — средний FPS не изменился совершенно. А вот на DDR4-2133 игра уже выдала только 93 кадра в секунду, то есть падение производительности составило порядка 5%.

В World War Z API Vulkan показывает, что он дейсвительно ближе к железу, чем DirectX — уже на 2933 МГц мы видим падение частоты кадров с 180 до 178, а на 2133 МГц мы получаем только 169 FPS. Иными словами, максимальная потеря кадров составила 7% — не так уж и мало.

Ну и переходим к Far Cry New Dawn, и вот тут даже переход на DDR4-2933 снижает FPS на пару процентов, а на DDR4-2133 вы не досчитаетесь уже 13 кадров в секунду, что составляет 11% — достаточно внушительная потеря.

Какой можно сделать вывод? DDR4-2133 для игр брать точно не стоит, во всех протестированных играх такая память ощутимо снижает итоговый FPS. А вот DDR4-2933 показывает себя на удивление неплохо — я ожидал, что в тяжелом Assassin-е будут просадки частоты кадров, но их там не было от слова совсем. Так что Intel не зря выбрала такую частоту дефолтной для своих псевдо новых процессоров — память на ней едва ли будет узким местом в системе.
Что касается обьема ОЗУ, совсем недавно популярный зарубежный Youtube-канал Linus Tech Tips, подтвердил, то, о чем мы уже не раз говорили, объём DDR4 в 4GB почти непригоден для использования, так как после простой загрузки Windows 10 половина памяти уже была занята.

С 8 гигабайтами ОЗУ работать становиться куда приятней. Можно смело запускать 3 ролика в 4K или 27 простых вкладок. В играх потребление памяти зависит от конкретного тайтла, но 16 Гб можно смело назвать золотой серединой. C 8 Gb ОЗУ тоже жить можно, но при этом файл подкачки используется на 20% от своего объёма, так что для дополнительных фоновых процессов неплохо бы обзавестись китом памяти на 16 Gb.


Дальнейшее наращивание объёма оперативной памяти не даёт почти никакого эффекта. Этих же 16 Гб будет сполна хватать для рендера, 32 Gb ОЗУ может понадобиться либо профессионалам, либо если вы любите открывать все и сразу.

Более 32 Gb может потребоваться художникам и создателям контента, которые держат открытыми сразу несколько рабочих программ.
Ну и глобальный итог — нет особого смысла гнаться за очень быстрой памятью. Если между DDR4-2933 и DDR4-3400 разницу уже нужно искать под лупой, то уж при переходе на DDR4-4000 вам потребуется микроскоп. А ведь стоит последняя достаточно дорого, и, сэкономив на ней, вы вполне можете взять более быструю видеокарту и гарантированно получить прирост производительности в играх.
Так что на данный момент имеет смысл остановиться на 8 или лучше 16 Гб памяти с частотой около 3 ГГц, причем не нужно дополнительно ужимать тайминги, стандартного XMP-профиля вполне хватит.
Сегодня мы продолжим повествование о компьютерной памяти, начатое рассказом о ее иерархии. В наши дни процессоры способны работать с невероятной скоростью. Но вся их мощь упирается в те ограничения, которые накладывает медлительная память. Если бы не разработанные инженерами методики преодоления этих досадных ограничений, могучий процессор не столько работал бы, сколько ждал запрошенной из хранилища информации. И в разработке быстрых и мощных чипов не было бы никакого смысла. Разумеется, компьютерные профессионалы всё это уже знают, но для миллионов искренних ценителей высоких технологий этот материал может оказаться познавательным.

Рассмотреть все существующие в мире разновидности запоминающих устройств в рамках краткого обзора не представляется возможным. Поэтому мы остановимся только на тех типах памяти, которыми оснащено большинство персональных компьютеров в современном мире. Речь идет о кеш-памяти первого (L1) и второго (L2) уровней; системной оперативной памяти; виртуальной памяти и, разумеется, жестком диске. Зачем обычному компьютеру так много самой разнообразной памяти? Чтобы ответить на этот вопрос, потребуется немного рассказать о том, для чего служит каждый тип компьютерной памяти.
Медленная и дешевая виртуальная память на жестком диске

Современный компьютер обладает мощным процессором. Но он лишится всякого смысла, если хранилище данных, к которому он обращается будет работать медленно. Если бы процессору пришлось иметь дело с медленной памятью, большую часть своего времени он проводил бы в ожидании отклика запоминающего устройства. Нынешнему процессору нужны миллиарды байт информации в секунду.
Когда промышленность только преодолела 1-гигагерцовый рубеж тактовой частоты процессора, она столкнулась с проблемой: память, которая способна справится с запросами могучего процессора стоит очень дорого. Но ни одна преграда на пути технического прогресса не способна надолго задержать его ход. Решение было найдено: небольшой объем быстрой и дорогой памяти сочетается в современных машинах с более емкими и менее затратными хранилищами информации.
Самым дешевым (и очень медленным) видом перезаписываемой компьютерной памяти является жесткий диск. Скорость доступа к нему невелика, зато он позволяет за умеренные деньги создавать большие постоянные хранилища информации. Стоимость хранения одного мегабайта данных на диске незначительна. Зато и времени на то, чтобы считать этот мегабайт потребуется существенно больше, чем если бы он располагался на более дорогом (и быстром) носителе. Поскольку жесткий диск дешев и ёмок, он образует нижнюю ступень иерархии памяти, к которой обращается процессор, именуемую виртуальной памятью.
На ступеньку выше в этой иерархии располагается оперативная память (ОЗУ, RAM). Ранее мы уже рассмотрели, как работает этот тип памяти. Но в предыдущем нашем повествовании некоторые подробности остались за кадром, которые имеют отношение не столько к оперативной памяти, сколько к процессору и его возможностям взаимодействия с ОЗУ. Сегодня мы прольем свет на эти детали.
Битность процессора указывает нам на то, к скольким битам информации, размещенной в оперативной памяти, он способен получить доступ одновременно. В качестве примера возьмем устаревшие 16-битные процессоры. Они были способны одновременно оперировать с двумя байтами данных (1 байт = 8 битам, таким образом 16 бит = 2 байта). Следовательно, современные 64-битные процессоры обращаются к 8 байтам информации в один момент времени.
В мегагерцах (МГц, миллионах герц) и гигагерцах (ГГц, миллиардах герц) измеряется скорость обработки данных процессором. То есть сколько циклов (тактов) обработки он способен выполнить за одну секунду. Чтобы не погружаться в невообразимо огромные цифры, в качестве примера возьмем старенький (а когда-то представлявшийся верхом совершенства и мощи) процессор Pentium III с тактовой частотой 800 мегагерц в секунду. Его 32-битная архитектура говорит о том, что он способен работать одновременно с четырьмя байтами информации. Не впечатляет? Но он мог проделать эту операцию 800 миллионов раз в секунду. Перед оперативной памятью стоит непростая задача: успевать за процессором, не отставать от него и вовремя предоставлять ему информацию. Иначе все поразительные возможности чипа будут простаивать в ожидании очередной порции байтов.
Системная оперативная память компьютера в одиночку с этой задачей не справляется. Поэтому нужен еще один тип сверхбыстрого хранилища данных: кеш-память (о которой мы поговорим ниже). Но, конечно, чем быстрее работает оперативная память, тем лучше для системы в целом. Скорость чтения и записи оперативной памяти зависит от того типа ОЗУ, который используется в данном компьютере. Поэтому вновь вернемся к оперативной памяти, но на сей раз рассмотрим ее технические характеристики.
Системная оперативная память

Скорость системной оперативной памяти определяется пропускной способностью ее шины. Пропускная способность шины, в свою очередь, определяется числом битов, которые одновременно могут быть направлены центральному процессору. Сколько раз в секунду такой набор битов может быть направлен процессору? Отвечающая на этот вопрос цифра называется скоростью шины. Циклом считается каждая передача данных процессору оперативной памятью.
Например: 32-битная 100-мегагерцовая шина теоретически способна одновременно передавать 4 байта информации (32 бита делить на 8 = 4 байта) 100 миллионов раз в секунду. 66-мегагерцовая 16-битная шина может одновременно передать всего 2 байта 66 миллионов раз в секунду. Простые математические вычисления показывают нам, что первая шина превосходит вторую по объему ежесекундно передаваемой процессору информации примерно втрое (400 миллионов байт против 132 миллионов байт).
Но в реальности оперативная память, разумеется, обычно не работает на пределе возможностей. И сейчас настала пора ввести еще один термин, который тоже накладывает свои ограничения на фактическую скорость передачи данных. Латентность оперативной памяти указывает на количество циклов, необходимых для чтения бита информации. К примеру, оперативная память с тактовой частотой 100 МГц, казалось бы, способна передавать бит за одну стомиллионную долю секунды. На самом же деле, пять стомиллионных долей секунды уйдет на запуск процесса чтения первого бита. Чтобы сократить влияние фактора латентности памяти, процессор использует специальную технологию, именуемую пакетно-монопольным (групповым или просто монопольным) режимом (burst mode).
Память ожидает, что данные, расположенные в ее определенных ячейках, будут запрошены процессором. Поэтому контроллер памяти считывает одновременно несколько битов данных, расположенных в памяти по определенным адресам. Это означает, что вызванная латентностью задержка чтения в полной мере коснется только первого бита информации. Чтение следующих битов займет существенно меньше времени. Характеристики группового режима памяти обыкновенно обозначается в виде четырех чисел, разделенных тире. Первое число говорит нам о количестве циклов, которые потребуются для осуществления операции чтения. Второе, третье и четвертое числа показывают, сколько циклов потребуется для чтения каждого следующего бита в группе.
К примеру, строка «5-1-1-1» способна поведать нам, что для чтения первого бита необходимы пять циклов и один цикл для чтения каждого последующего бита информации. Чем меньше это число, тем выше производительность памяти.
Групповой режим нередко сочетается с другим средством снижения эффекта латентности, так называемой конвейеризацией. Эта методика организует наборы данных в своего рода конвейерные процессы. Контроллер памяти параллельно считывает из памяти одно или несколько слов; отправляет процессору текущее слово или слова; записывает одно слово или несколько в ячейки памяти. Групповой режим и конвейеризация, применяемые в связке, значительно снижают замедляющее влияние латентности.
У читателей может возникнуть вопрос: а почему бы сразу не приобрести самую быструю память с самой высокой из возможных в современном мире пропускной способностью? Но тут вступает в силу ограничение, накладываемое системной шиной материнской платы компьютера. Вы, конечно, можете поставить 100-мегагерцовую память в материнскую плату с 66-мегагерцовой системной шиной. Но ее предельная скорость все равно будет составлять 66 МГц в секунду. И вы не получите никакого преимущества. Так и 32-битная память не соответствует 16-битной шине.
И даже очень скоростная память с широкой полосой пропускания всё равно не достигает той скорости, с которой процессор способен обрабатывать данные. Именно для этого и нужна сверхбыстрая кеш-память.
Кеш-память и регистр процессора

Современный компьютер устроен таким образом, чтобы в 95 % случаев процессор получает данные из кеш-памяти, не нуждаясь в обращении к более медленным хранилищам информации. Некоторые дешевые системы обходятся вовсе без L2-кеша. Зато во многих высокопроизводительных процессорах кеш-память второго уровня встроена непосредственно в чип. Размер кеша второго уровня и его интегрированность непосредственно в центральный процессор являются важнейшими факторами, оказывающими влияние на производительность процессора.
Технически кеш является статической оперативной памятью (SRAM). В памяти этого типа каждая ее ячейка сформирована несколькими транзисторами: обычно их бывает от четырех до шести. Она обладает внешней логической матрицей, именуемой мультивибратором с двумя устойчивыми состояниями (бистабильным мультивибратором, bistable multivibrator). С его помощью реализуется переключение между двумя состояниями. Это означает, что память этого типа не нуждается (в отличие от динамической памяти DRAM) в постоянном обновлении.
Каждая ячейка способна удерживать размещенные в ней данные в течение любого длительного времени. До тех пор, пока не будет отключена энергия. Благодаря отсутствию потребности в постоянном обновлении, SRAM работает необычайно быстро. Но сложная конструкция каждой ячейки памяти этого типа делает ее слишком дорогой для использования в качестве стандартной оперативной памяти компьютера.
Статическая кеш-память бывает асинхронной и синхронной. Синхронная SRAM сконструирована таким образом, чтобы ее скорость в точности соответствовала скорости процессора. Чего нельзя сказать об асинхронном кеше. Эта, казалось бы, незначительная разница сказывается на производительности. Не станем вдаваться в технические подробности, скажем только, что синхронная память предпочтительнее.
Причиной рассмотрения взаимодействия компьютерной памяти и центрального процессора на примерах устаревших систем, является сравнительная простота вычислений. Дело в том, что современные компьютеры базируются на многоядерных процессорах. При этом принцип обращения процессора к памяти остался прежним и каждый может, при желании, самостоятельно произвести вычисления для сложнейшей из современных систем. В рамках краткого обзора эти вычисления выглядели бы нагромождением информации, усложняющей материал, но не вносящей в него ничего нового.
Оперативная память бывает двух форматов и более пяти типов, каждый из которых работает в определенном диапазоне частот. Расскажем, как выбрать максимально допустимую частоту, оценить эффективность работы, и поможем определиться с объемом оперативной памяти для новой сборки или на замену старой.
Форм-фактор
Функционально они одинаковые, но у них разные размеры. Установить вместо DIMM модуль SO-DIMM и наоборот не получится. Форм-фактор указан в первом пункте в технических характеристиках памяти.
Тип памяти

Тип часто указывается в самом названии модуля памяти. Модули разного типа отличаются формой, так что установить один тип памяти в слот для другого не получится.
Объем памяти
Кажется, что чем больше объем оперативной памяти, тем быстрее работает компьютер. При работе с Word вы не заметите разницы между 16 ГБ и 32 ГБ, так как программа не использует весь доступный объем. Но когда вы открываете несколько десятков вкладок в Chrome и работаете с Photoshop, компьютер задействует минимум 8 ГБ оперативной памяти. Если памяти не хватает, включаются алгоритмы сжатия и переноса части данных на жесткий диск, из-за этого компьютер долго думает над некоторыми командами и работает медленно.
Вот на какой объем памяти можно ориентироваться в 2021 году:
- 4–8 ГБ — хватит для работы в Word, небольших таблиц, пары десяток вкладок в браузере.
- 16 ГБ — хороший вариант для домашнего и бюджетного игрового компьютера. Позволит пользоваться всеми популярными программами (в том числе обрабатывать фото и монтировать видео), использовать браузеры, играть в 90% современных игр.
- 32 ГБ и больше — нужны программистам, видеоредакторам, визуализаторам. Всем, кто работает с большими проектами: несколько часов видео со сложным монтажом, 3D-планы зданий и десятки тысяч строк кода в одном проекте.
Объем указан в технических характеристиках. Учтите, что в одной коробке может быть несколько модулей, обратите внимание на пункт Количество модулей.
Если собираете новый компьютер
Посмотрите в характеристики материнской платы. Найдите графу Слоты памяти — в ней будут указаны тип (DDR4, DDR5) и количество модулей.
Обратите внимание на соседние пункты:
- Частотная спецификация памяти — максимальная частота оперативной памяти, которую поддерживает материнская плата.
- Максимальный объем оперативной памяти — максимальный суммарный объем всех модулей памяти, который поддерживает материнская плата. Например, если у вас два слота и максимальный объем 32 ГБ, то вы сможете установить два модуля объемом не более 16 ГБ каждый.
Лучше выбирать четное количество модулей — два или четыре: в двухканальном режиме память будет работать быстрее. Но при этом стоит оставить возможность для увеличения объема. Например, лучше сначала купить один модуль памяти на 16 ГБ, а через месяц-другой установить еще один такой же, чем занять оба слота модулями по 8 ГБ.
Если хотите увеличить объем памяти готового ПК
Посмотрите, какая память установлена в компьютере. Откройте боковую крышку корпуса и достаньте модуль памяти. На одном из бортов будут указаны производитель и маркировка.
Если у вас ноутбук или вы боитесь извлекать память, воспользуйтесь программой CPU-Z
. После запуска зайдите во вкладку SPD, сверху слева найдите список всех доступных слотов памяти и посмотрите, какая память установлена в каждый слот. Если поля пустые, значит, слот не задействован (вы можете установить в него дополнительный модуль памяти с такими же характеристиками, как у остальных).
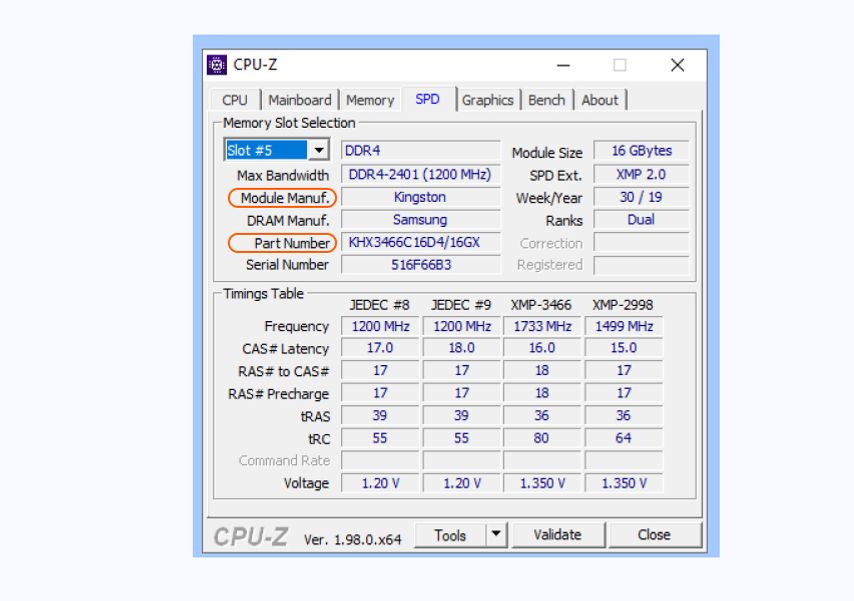
Обратите внимание на пункт Part Number, в нем указана маркировка модуля памяти. По ней можно узнать точные характеристики, включая тактовую частоту.
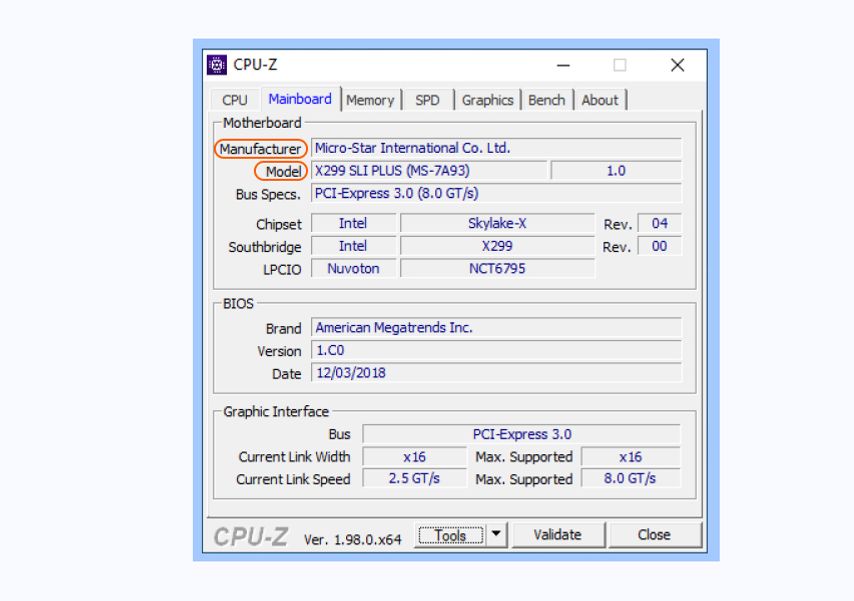
Если хотите установить комплект модулей с большим объемом памяти, посмотрите максимально допустимую частоту и объем для вашей материнской платы. Ее производителя и модель можно посмотреть во вкладке Mainboard.
После того как определились с форматом, типом, объемом и количеством планок, пора подумать про тактовую частоту и скорость работы памяти.
Тактовая частота и скорость работы памяти
Вы уже знаете, какую максимальную тактовую частоту памяти поддерживает ваш компьютер, но просто выбрать память с такой частотой недостаточно. Обратите внимание на поле Латентность (указана в формате CL 16-17-17) в характеристиках. Если коротко, из двух модулей с одинаковой тактовой частотой быстрее тот, у которого цифры в поле Латентность меньше.
: Правда, что повышение частоты оперативной памяти дает прирост мощности?
Нужны ли радиаторы?
Обычно оперативная память нагревается несильно. При базовом напряжении (для DDR4 это 1,2 В) тепла выделяется немного. Но если производитель разогнал модуль и повысил напряжение до 1,3–1,4 В, нагрев увеличится.
Модули памяти Patriot Viper 4 Blackout с металлическими бортами и зубцами для отвода теплаКак правило, у таких модулей есть металлические боковые накладки и дополнительные зубчатые гребни сверху. Они позволяют отводить лишнее тепло и защищают от перегрева.
Если планируете разгонять оперативную память или в ее характеристиках указано напряжение более 1,35 В (у DDR4) или 1,25 В (у DDR5), убедитесь, что у модуля есть такие металлические детали и гребни.
А подсветка?
Никакой практической пользы от нее нет. Но если у вас системный блок с прозрачной боковой стенкой, а внутри находятся видеокарта, система охлаждения и вентиляторы с подсветкой, оперативная память дополнит картинку. Подсветка встречается только в модулях формата DDR4 (в DDR5, скорее всего, тоже будет).
Перед покупкой проверьте, с какими программами для синхронизации подсветки она совместима. Для этого найдите свою материнскую плату на сайте производителя и посмотрите, какие приложения там указаны. Например, у MSI это Mystic Light.

Затем посмотрите, какие программы поддерживают выбранные модули оперативной памяти. Это может быть тот же Mystic Light, Aura Sync, RGB Fusion 2.0 и др. Управлять цветом и эффектами подсветки получится только в том случае, если материнская плата и оперативная память работают с одной и той же программой.
Читайте также: