
Создание собственного фреймворка java
Обновлено: 04.07.2024
Введение в фреймворк fork/join, представленный в Java 7, и инструменты, помогающие ускорить параллельную обработку, пытаясь использовать все доступные процессорные ядра.
1. Обзор
Для обеспечения эффективного параллельного выполнения платформа fork/join использует пул потоков, называемый ForkJoinPool , который управляет рабочими потоками типа ForkJoinWorkerThread .
2. ForkJoinPool
ForkJoinPool является сердцем фреймворка. Это реализация ExecutorService , которая управляет рабочими потоками и предоставляет нам инструменты для получения информации о состоянии и производительности пула потоков.
Рабочие потоки могут выполнять только одну задачу за раз, но ForkJoinPool не создает отдельный поток для каждой отдельной подзадачи. Вместо этого каждый поток в пуле имеет свою собственную двустороннюю очередь (или deque , произносится deck ), в которой хранятся задачи.
Эта архитектура жизненно важна для балансировки рабочей нагрузки потока с помощью алгоритма воровства работы.
2.1. Алгоритм Кражи Работ
По умолчанию рабочий поток получает задачи из головы своего собственного deque. Когда он пуст, поток берет задачу из хвоста deque другого занятого потока или из глобальной очереди ввода, так как именно здесь, вероятно, будут расположены самые большие части работы.
Такой подход сводит к минимуму вероятность того, что потоки будут конкурировать за задачи. Это также сокращает количество раз, когда потоку придется искать работу, так как сначала он работает с самыми большими доступными фрагментами работы.
2.2. Создание экземпляра ForkJoinPool
В Java 8 наиболее удобным способом получить доступ к экземпляру ForkJoinPool является использование его статического метода common Pool (). Как следует из названия, это обеспечит ссылку на общий пул, который является пулом потоков по умолчанию для каждой ForkJoinTask .
Согласно документации Oracle , использование предопределенного общего пула снижает потребление ресурсов, поскольку это препятствует созданию отдельного пула потоков для каждой задачи.
Такого же поведения можно добиться в Java 7, создав ForkJoinPool и назначив его общедоступному статическому полю служебного класса:
Теперь к нему можно легко получить доступ:
С помощью конструкторов Forkjoinpool можно создать пользовательский пул потоков с определенным уровнем параллелизма, фабрикой потоков и обработчиком исключений. В приведенном выше примере пул имеет уровень параллелизма 2. Это означает, что пул будет использовать 2 ядра процессора.
3. ForkJoinTask
ForkJoinTask является базовым типом для задач, выполняемых внутри ForkJoinPool. На практике следует расширить один из двух его подклассов: RecursiveAction для void задач и RecursiveTask для задач, возвращающих значение. У них обоих есть абстрактный метод compute () , в котором определена логика задачи.
3.1. Рекурсивное действие – пример
В приведенном ниже примере единица работы, подлежащая обработке, представлена строкой , называемой рабочая нагрузка . Для демонстрационных целей эта задача бессмысленна: она просто вводит данные в верхний регистр и регистрирует их.
Чтобы продемонстрировать поведение разветвления фреймворка, пример разбивает задачу, если рабочая нагрузка .length() превышает заданный порог | с помощью метода createSubtask () .
Строка рекурсивно разделяется на подстроки, создавая Пользовательские экземпляры RecursiveTask , основанные на этих подстроках.
В результате метод возвращает List RecursiveAction>. RecursiveAction>.
Список передается в ForkJoinPool с помощью метода invokeAll() :
Этот шаблон можно использовать для разработки собственных RecursiveAction классов . Для этого создайте объект, представляющий общий объем работы, выберите подходящий порог, определите метод разделения работы и определите метод выполнения работы.
3.2. Рекурсивная задача
Для задач, возвращающих значение, логика здесь аналогична, за исключением того, что результат для каждой подзадачи объединяется в один результат:
В этом примере работа представлена массивом, хранящимся в поле art класса Custom RecursiveTask|/. Метод create Subtasks() рекурсивно делит задачу на более мелкие части работы, пока каждая часть не станет меньше порогового значения . Затем метод invokeAll() отправляет подзадачи в общий пул и возвращает список Future .
Для запуска выполнения для каждой подзадачи вызывается метод join () .
В этом примере это достигается с помощью Java 8 Stream API ; метод sum() используется в качестве представления объединения вложенных результатов в конечный результат.
4. Отправка задач в ForkJoinPool
Для отправки задач в пул потоков можно использовать несколько подходов.
Метод submit() или execute () (их варианты использования одинаковы):
Метод invoke() разветвляет задачу и ожидает результата, и не требует ручного соединения:
Метод invokeAll() является наиболее удобным способом отправки последовательности ForkJoinTasks в ForkJoinPool. Он принимает задачи в качестве параметров (две задачи, varargs или коллекция), а затем возвращает коллекцию объектов Feature в том порядке, в котором они были созданы.
Кроме того, вы можете использовать отдельные методы fork() и join () . Метод fork() отправляет задачу в пул, но не запускает ее выполнение. Для этой цели необходимо использовать метод join () . В случае RecursiveAction функция join() возвращает только null ; для RecursiveTask возвращает результат выполнения задачи:
В нашем примере RecursiveTask мы использовали метод invokeAll() для отправки последовательности подзадач в пул. Ту же работу можно выполнить с помощью fork() и join() , что имеет последствия для упорядочения результатов.
Чтобы избежать путаницы, обычно рекомендуется использовать метод invokeAll() для отправки более одной задачи в ForkJoinPool.
5. Выводы
Использование фреймворка fork/join может ускорить обработку больших задач, но для достижения этого результата необходимо следовать некоторым рекомендациям:
- Используйте как можно меньше пулов потоков – в большинстве случаев лучшим решением является использование одного пула потоков для каждого приложения или системы
- Используйте пул общих потоков по умолчанию, если конкретная настройка не требуется
- Используйте разумный порог для разделения ForkJoinTask на подзадачи
- Избегайте каких-либо блокировок в вашейForkjointask
Примеры, используемые в этой статье, доступны в связанном репозитории GitHub .
Maven является инструментом с открытым исходным кодом, который необходим для построения, управления и автоматизации Java-проектов. Как и большинство фреймворков, Maven создан для решения задач, с которыми разработчики сталкиваются ежедневно. Инструмент особенно полезен для новичков.
Maven может создавать собственную структуру проектов, облегчает процесс подключения необходимых библиотек, управляет отчетностями, зависимостями и документацией. Java-программисту не нужно уделять внимание каждому из этапов сборки проекта — все необходимые параметры фреймворка уже настроены по умолчанию.
Пошаговая установка Maven
1. Для установки фреймворка скачайте его актуальную версию . Минимально необходимое свободное место на диске — 500 Мб.
2. Распакованный архив переместите в удобную для вас директорию. В Windows путь к Maven может выглядеть как C:\Program Files\maven\, в Linux — /opt/maven.
3. Введите mvn -version в командную строку, чтобы проверить корректность установки фреймворка.
4. Далее создайте новый проект в IntelliJIDEA.
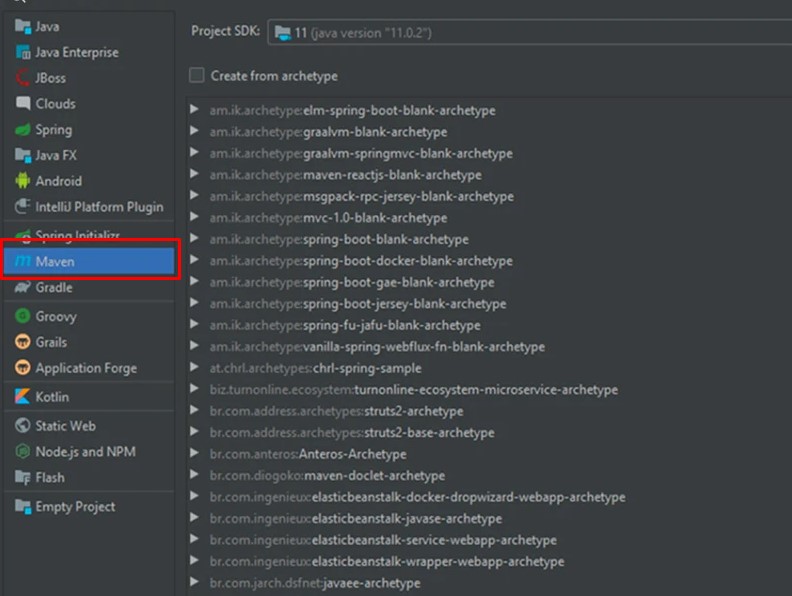
Создание нового проекта
5. Заполните поля в появившемся диалоговом окне.
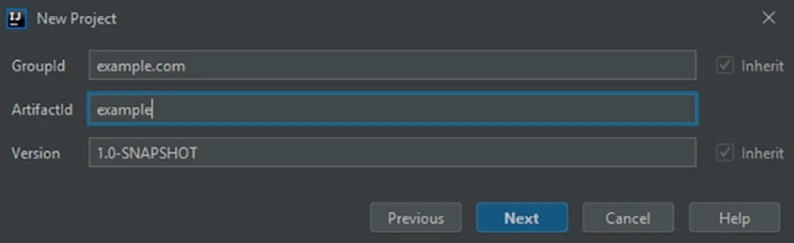
Заполните поля в диалоговом окне
Проект также можно создать в удобном для вас месте. Его структура выглядит так:
- pom.xml — файл, который полностью управляет фреймворком Maven;
- src/main/java — папка, в которой находятся все Java-классы;
- src/main/resources — папка, в которой находятся таблицы стилей, веб-страницы, изображения, используемые приложением.
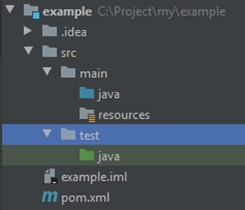
Проект можно создать в удобном для вас месте
Как управлять зависимостями в Maven
Dependency manager в Maven обеспечивает проект необходимыми для работы библиотеками. Просто добавьте их в список зависимостей фреймворка.
Для простой и удобной работы с файлами добавим библиотеку Apache Commons IO. Для этого в pom.xml необходимо добавить несколько строк:
После их добавления файл будет выглядеть так:
Чтобы библиотека была готова к использованию, необходимо разрешить IntelliJ IDEA импортировать зависимость.
Все последующие зависимости также записываются в <dependencies/>. Их можно располагать в любой последовательности.
Информацию о библиотеках можно узнать на сайте самой библиотеки или же в Maven-репозитории .
Какими бывают Maven-репозитории
Maven-репозиторий — это директория, в которой находятся плагины, библиотеки, JAR и другие артефакты, необходимые для работы Maven.
- Централизованный. Вклад сообщества Maven. Здесь находятся все самые популярные и часто используемые библиотеки. Если Maven не находит нужную библиотеку в локальном репозитории, он обращается к центральному.
- Локальный. Директория, которая находится на локальном компьютере пользователя и хранит зависимости проекта. Локальный репозиторий по умолчанию создается в %USER_HOME%.
- Удаленный. Настраивается во избежание ошибок. Репозиторий необходим на случай, если Maven не нашел необходимые зависимости в централизованном репозитории. Для настройки удаленного репозитория нужно внести изменения в pom.xml:
Как собрать Java-проект с помощью Maven
Сборка Java-проекта в Maven состоит из 9 фаз:
1. Clean — удаление файлов из каталога target;
2. Validate — проверка данных, необходимых для сборки;
3. Compile — компиляция файлов;
4. Test — запуск тестов;
5. Package — упаковка скомпилированных файлов в архивы;
6. Verify — верификация упакованных файлов;
7. Install — установка в локальный репозиторий;
8. Site — создание документации к проекту;
9. Deploy — копирование архива в удаленный репозиторий.
Запустить каждую из фаз можно с помощью командной строки или Intellij IDEA.
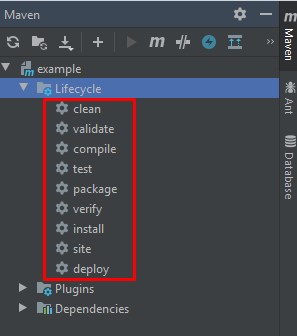
Сборка Java-проекта в Maven состоит из 9 фаз
Плагины Maven
Плагины Maven используются для создания JAR-, WAR-файлов, юнит-тестов кода, создания документации и отчетов, компиляции файлов.
Плагины сборки конфигурируются в файле pom.xml внутри тегов <build></build>, а плагины отчетов — в <reporting></reporting>.
Самые распространенные и часто используемые плагины:
Пример сборки JAR-пакета:
- Clean. Удаляет директорию target после сборки.
Пример с параметром filesets:
Например, для создания автономной документации для проекта плагин Javadoc необходимо добавить в раздел <build> файла pom.xml.
Например, у плагина Antrun должен быть <target>.
Полный список плагинов Maven можно найти здесь .
Highload нужны авторы технических текстов. Вы наш человек, если разбираетесь в разработке, знаете языки программирования и умеете просто писать о сложном!
Откликнуться на вакансию можно здесь .
Всем привет! В предыдущем посте я начал рассказывать про создание test framework-а с нуля. В нем рассказал про выбор технологий, создание проекта в IDE, структуру и написание feature на языке Gherkin. Далее рассмотри создание Step-ов для реализации тестовой логики.
Итак начнем. Тестовая логика у нас прописана в feature-файлах. Для ее реализации необходимы Step-файлы. Они служат для перевода языка Gherkin, на язык программирования, в моем случае это Java. У IntelliJ IDEA есть замечательная настройка, позволяющая автоматически сгенерировать Step-файл для каждого из ключевых слов теста. На практие это выглядит так:
public void userSendLetterTo(String arg0) throws Throwable
Так как Step не является исполняемым классом, то он расположен в package "java"
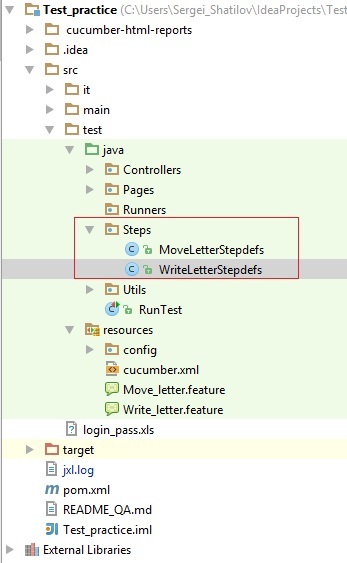
Теперь рассмотрим на примере структуру Step-файла:
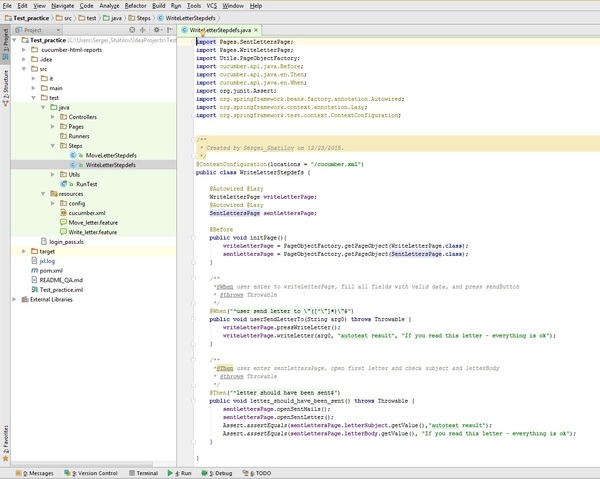
На изображении выше видно, что все ключевые слова реализованы уже на Java языке. Причем нужно не забывать, что при написании реализации ключевых слов необходимо четко указывать в скобках точную фразу, написанную в feature, иначе Step просто не подцепится и компиляция и выполнение теста не произойдет.
Так как я изначально использовал методологию Page Object Pattern, то при написании Step-ов мне всего навсего необходимо было проинициализировать page-и, а дальше уже использовать функции, реализованные в самих page-ах. Самым разумным решением, на мой взгляд, это произвети инициализацию в Before-методе используя PageObjectFactory, а объявление page-ов методом "@Autowired @Lazy" (cucumber). @Lazy говорит о том, что применение и инициализация того или иного page-а будет происходить только в момент его вызова, а не при старте теста. Это отчасти облегчает тест и немного увеличивает его скорость прохождения.
Так же необходимо незабывать писать javadoc-и, так как никогда не известно кто в дальнейшем будет поддерживать ваши тесты. Да и вряд ли вы сами после написания 100-200 тестов будете четко помнить что именно реализует тот или иной метод.
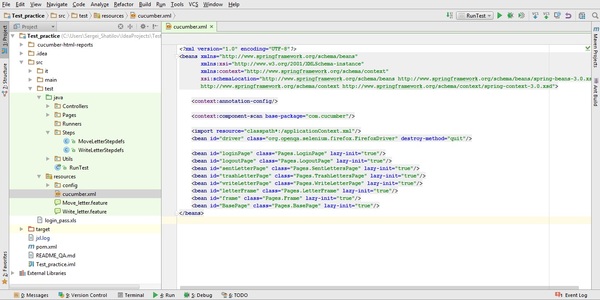
Еще одним из основных параметров, которые необходимо прописать в Step-ах - это @ContextConfiguration(locations = "/cucumber.xml"). Данный параметр указывает на то, где расположена конфигурация cucumber-тестов. В данном xml-файле описана основная конфигурация и описаны bean-ы, используемые в тестах. И так как он является конфигурационным файлом, он расположен в package-е resources.
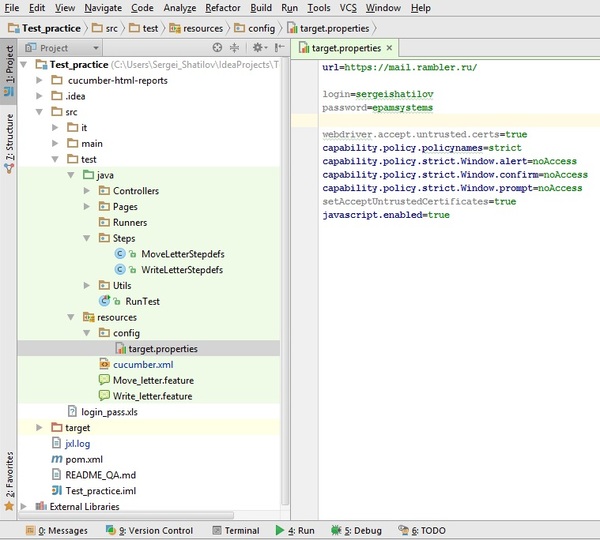
Так же в package-е resources расположен еще один config-файл (target.properties), служащий для конфигурации адреса тестируемого приложения, данных пользователя и других часто используемых параметров.
Ну и для закрепления, ниже изображен еще один Step-файл
Итак, подведем итоги. В данном посте были рассмотрены правила и примеры написания Step-файлов, реализующих тестовую логику, прописанную в feature-файлах. Так же были рассмотрены конфигурационные файлы, используемые в тестах.
З.Ы. Всем огромное спасибо за внимание и интерес к моим постам. В следующем посте мы рассмотрим применение Page Object Pattern при описании элементов страниц.
Пусть автор никого не слушает, а публикует, что собирался. По закону Старджона 90% всего на свете - . , так что, этот ресурс точно не проиграет в качестве контента. И, да, на какой-то публичный репозиторий исходники залить - точно не больше времени, чем уже потрачено.
@madtester, вот тебе совет: не делай посты, заведи блог и пиши туда. тут это нахуй никому не упало, а если кто-то заинтересуется, гугл даст ссылку на твой блог.
Реквестирую ссыль на репозиторий с данным проектом)
Мне кажется, что можно было начать с ИДЕ. В случае, если человек не очень дружит в джавой - хоть немного понятно. А так, действительно получается узкоспециализировано.
Почему ява-кодеры такие тугие? Ну не нужны тут такие посты, это видно по их рейтингу.
На хабр не пускают, а посрать в интернетах "гайдами" нулевого уровня хочется?

Псс, парень. Не хочешь немного системных автотестов?
Хочу рассказать вам о проекте, который разрабатываю я с моим коллегой уже без малого три года, и который совсем недавно мы, неконец, зарелизили. Этот проект посвящен автоматизации тестов, и не абы каких, а системных.
Что такое системные тесты? Если вкратце - это тестирование программы (или набора программ) с учетом окружения, в котором программе предстоит работать.
Представьте, что вы написали приложение-калькулятор. Вы написали для него множество простейших тестов (проверили функции сложения, умножения, деления, и так далее). В сущности, вы написали unit-тесты (или, по-русски, модульные тесты).
Модульные тесты очень хороши, и оченнь многие ответственные программисты пишут достаточно много таких тестов для своих приложений. И это часто даёт им возможность спокойнее спать по ночам, зная, что их программа работает нормально, и хоть прямо сейчас её можно выкатывать довольным заказчикам.
Но так ли это? Ведь ваш калькулятор будет работать не просто так, а в конкретной операционной системе с конкретными настройками. А ещё у него может быть инстяллятор, который должен успешно отрабатывать, несмотря ни на что. А ещё он может зависеть от внешних библиотек, которые не всегда установлены в целевой системе.
И вот получается, что все модули по отдельности вроде бы протестированы, а на самом деле, спокойно спать всё ещё нельзя: ведь если калькулятор устанавливается и работает в Windows XP, то это абсолютно не означает, что он будет так же работать в Windows 7 или Windows 10.
И вот даже в самом простом калькуляторе вы сталкиваетесь с проблемой: как удостовериться, что мой калькулятор успешно устанавливается на Windows XP x32, Windows XP x64, Windows 7 x32, Windows 7 x64. И вот с этого момента вы начинаете, по сути, заниматься системным тестированием.
Системные тесты это замечательная штука, да вот только есть проблема - их очень сложно автоматизировать. Особенно, если вы тестируете приложение с графическим интерфейсом, но даже консольные приложения могут доставлять много боли при системном тестировании. В самом деле, как автоматизировать системные тесты самого элементарного клиент-серверного приложения? Это же надо иметь два компьютера, на один из них надо установить сервер, на другой - клиент, а затем проверить, что они корректно взаимодействуют.
Чаще всего системные тесты проводят вручную. Обычно этим занимаются тестировщики (если они есть). Это проще всего, не требует особого умственного труда, но занимает кучу времени. Для крупных коммерческих проектов один полный прогон системных тестов может занимать несколько месяцев работы целого отдела.
Поэтому часто бывает так: в компании перед релизом проводят один полный прогон системных тестов, в ходе которого вылавливают N багов. Затем разработчики фиксят эти баги, а тесирование проверяет, что баги успешно закрыли. Но на второй полный прогон системных тестов времени уже просто не остаётся, поэтому компания просто надеется, что фиксы найденных багов не затронут другие части системы. Очень надёжно, правда?
Компания и рада бы проводить прогон системных тестов каждый день/неделю, да никаких ресурсов для этого у неё просто нет. Да и представьте сами - если вы написали калькулятор, готовы ли вы каждый раз при новой сборке проверять, что он усатнавливается на все возможные операционные системы?
Именно на решение этой проблемы мы направили свои усилия в своём проекте, который мы решили назвать Testo. В состав этой платформы входит специальный язык тестовый сценариев Testo-lang (да, мы написали целый язык для тестовых сценариев), который позволяет вам писать интуитивно-понятные сценарии для системных тестов.
Вместо тысячи слов - просто посмотрите как с помощью нашего проекта можно автоматизировать установку Dr. Web на Windows 7:
Для создания тестовых сценариев не обязательно иметь навыки программирования - достаточно просто документировать все действия, которые вы делаете руками, тестируя какую-либо программу. Например, тест с Dr. Web выражается вот таким сценарием. Даже если вы не знаете ни одного языка программирования, вы всё равно наверняка сможете понять, что именно тут происходит:

Я не буду в этом посте очень долго распыляться о том, как это работает и устроено. Любители технических подробностей могут найти парочку наших статей на хабре (поиск по слову Testo-lang).
Также у нас есть сайт (тоже легко гуглится по Testo-lang), где вы можете скачать абсолютно бесплатно, без регистрации и СМС нашу платформу и пользоваться её сколько угодно (да, у нас есть платная версия, но она отличается от бесплатной только скоростью работы команды wait).
Больше примеров можно глянуть на Youtube-канале (тоже элементарно гуглится).
Если мы сможем помочь хоть одному пикабушнику, который как раз думает о том "как бы мне автоматизировать вот эту штуку. " - то значит уже три года разработки не прошли даром :)
Мы продолжаем рассказывать о QA. Руководитель отдела тестирования Дмитрий Рак расскажет об архитектуре фреймворка для автоматизации тестирования.
Последние осенние солнечные деньки подходят к концу, мы лениво подбираемся к нашим лаптопам, перебирая в голове тысячи фотографий с желтой листвой под ногами. Чтобы перестать хандрить от мысли о наступающих промозглых утрах и грязевых ландшафтах вокруг, мы решаем создать что-то светлое, вдохновляющее и обещающее невероятные приключения. Например, новый фреймворк для автоматизации тестирования проекта. И, конечно, мы можем взять прекрасную инструкцию из интернета, но не возьмем потому что:
- Создать-то фреймворк − они создали, но не объяснили, зачем;
- Может быть даже какие-то из компонентов забыли;
- Мы получаем невероятно удовольствие от изобретения очередного колеса через муки и страдания.
Зачем автоматизировать тестирование?

Цели создания фреймворка для автоматизации:
- Не хотим писать один и тот же код дважды;
- После создания фреймворка – написание тестов должно свестись к простому составлению последовательности шагов, вытекающих в тестовые сценарии.
Разработчики каждый раз пугаются фразе «создать фреймворк», считая, что это похоже на разработку собственного приложения/библиотеки/модуля. Реальность отличается: фреймворк для автоматизации тестирования − это адаптация нескольких решений, имеющихся на рынке, под нужды конкретного проекта.
Ниже расскажем, из чего может состоять фреймворк и какие цели та или иная его часть может преследовать. Добавим суматохи в ряды автоматизаторов и поговорим в формате User Stories, где каждая будет начинаться с привычных и столь нелюбимых нами: «Как автоматизатор я хочу. ».
Как автоматизатор я хочу иметь возможность расширять решение, добавлять новые возможности и не зависеть от создателей сторонних продуктов.
Вечный выбор между record-replay или языками программирования. Я адепт решений, связанных с языками программирования потому что:
- Готовые решения плохо работают с динамическими данными;
- Готовые решения, в большинстве своем, платные;
- Готовые решения могут менять набор функциональности, доступной для пользователей либо содержать баги, мешающие работе;
- Готовые решения не дают возможности встроить все, что душе заблагорассудится, в их продукт. Необходимо ждать внедрения интеграции от создателей.
Если говорить о выборе языка программирования, то холивары на этот счет никогда не прекращаются в связи с тем, что:
- Бытует миф, что разработчики могут помогать писать автотесты автоматизаторам (на самом деле, нет);
- Говорят, что хранить код продукта вместе с кодом автотестов − это правильно.
Как автоматизатор я хочу иметь возможность легко подключать новые библиотеки и запускать тесты c помощью командной строки.
Далее мы рассмотрим примеры, приближенные к языку программирования Java. Тем не менее, информация ниже применима в любом из языков программирования.
Начнем. Подключаем любой build tool, например, Maven/Ant+Ivy/Gradle и наслаждаемся простотой добавления и широким выбором библиотек, которые можно использовать в проекте. Приятный бонус: запуск тестов из командной строки, что пригодится нам на этапе внедрения в CI, но об этом позже.
Как автоматизатор я хочу иметь возможность запускать тесты в параллели, использовать Asserts и группировку по тест-пакетам.
Для запуска тестов в параллели проще всего использовать xUnit-библиотеки. То есть хватаем JUnit или TestNG, и вуаля. Я фанат TestNG. Возможно, в паре с Hamcrest из-за большего количества функциональности и поддержки от создателей. Говорят, JUnit 5 просто космос. Пишите ваше мнение в комментариях.
Как автоматизатор я хочу описать взаимодействие со всеми элементами в приложении один раз и больше не задумываться о том, как это работает.
Ниже разговор пойдет о фреймворках, так или иначе касающихся взаимодействия с UI-частью приложения через Selenium. И здесь не о библиотеке, а о стандартном подходе в Page Object Model, где в каждом из проектов описаны такие пакеты/модули:
- Elements − взаимодействие с кнопками/инпутами и другими элементами, доступными в приложении. Здесь и ожидания, и логирование, и обработка исключения;
- Pages − описание локаторов и действий с каждым из элементов, используя классы из elements;
- Steps − объединение отдельных действий из разных страниц в так называемые business-scenarios. Ценные для конечного пользователя/описываемые в репортинге. Создатели Serenity прекрасно «переиспользовали» модель у себя во фреймворке, но, к сожалению, пожертвовали гибкостью;
- Tests − из отдельных шагов собирается тестовый сценарий. Из тестов только пробрасывается ввод от конечного пользователя.
Окей, элементы расписаны. Что дальше?

Из них составляем страницы, из страниц готовим наборы бизнес-шагов, из них − тестовые сценарии.
Как автоматизатор я хочу максимальное время уделять тестированию приложения, а не подготовке тестовых данных.
Если тестовые сценарии написаны с помощью UI-библиотеки, например, Selenium, то со временем вы удивитесь почему один небольшой тест занимает 5-10 минут времени. Проблема в создании тестовых данных. Поэтому чем раньше в вашем фреймворке появится возможность использовать REST API или базу данных приложения, тем лучше. REST Assured и JDBC вам в помощь. Приятным бонусом будет то, что теперь внутри фреймворка можно делать тестовую пирамиду и автоматизировать часть проверок, используя только REST API.
Как автоматизатор я хочу забыть, где объявлен WebDriver, забыть о проблемах с параллелизацией и частыми StaleElementReferenceException.
Ребята из Selenide за последние несколько лет сделали многое для того, чтобы мы писали меньше кода.
- Встроенные ожидания;
- WebDriver не хранится как поле класса, а вызывается методом getWebDriver из любой точки кода. Не конфликтует друг с другом из коробки при параллельном запуске;
- StaleElementReferenceException побежден раз и навсегда за счет «умного» обращения к DOM вашей страницы под капотом Selenide.
Как автоматизатор я хочу запускать тесты не у себя на компьютере.
Словосочетание Continuous Integration и так всем известно. Зачем? Чтобы не пить чай, пока запускаются тесты, а продолжать разрабатывать новые. В это время старые генерируют нам проблемы. Здесь подробный список доступных сейчас CI tools. Из приятных нововведений, появившихся не так давно: CircleCI для Selenium-like фреймворка заводится за несколько минут и предоставляет 240 бесплатных минут в неделю.
Как автоматизатор я хочу понимать, почему мои тесты упали.
Читайте также: