
Текст состоит из символов букв цифр знаков препинания и т д как компьютер их различает
Обновлено: 02.07.2024
Сайт учителя информатики. Технологические карты уроков, Подготовка к ОГЭ и ЕГЭ, полезный материал и многое другое.
§ 4.6. Оценка количественных параметров текстовых документов
Информатика. 7 класса. Босова Л.Л. Оглавление
4.6.1. Представление текстовой информации в памяти компьютера
Текст состоит из символов — букв, цифр, знаков препинания и т. д., которые человек различает по начертанию. Компьютер различает вводимые символы по их двоичному коду. Вы нажимаете на клавиатуре символьную клавишу, и в компьютер поступает определённая последовательность электрических импульсов разной силы, которую можно представить в виде цепочки из восьми нулей и единиц (двоичного кода).
Мы уже говорили о том, что разрядность двоичного кода i и количество возможных кодовых комбинаций N связаны соотношением: 2 i = N. Восьмиразрядный двоичный код позволяет получить 256 различных кодовых комбинаций: 2 8 = 256.
С помощью такого количества кодовых комбинаций можно закодировать все символы, расположенные на клавиатуре компьютера, — строчные и прописные русские и латинские буквы, цифры, знаки препинания, знаки арифметических операций, скобки и т. д., а также ряд управляющих символов, без которых невозможно создание текстового документа (удаление предыдущего символа, перевод строки, пробел и др.).
Соответствие между изображениями символов и кодами символов устанавливается с помощью кодовых таблиц.
Все кодовые таблицы, используемые в любых компьютерах и любых операционных системах, подчиняются международным стандартам кодирования символов.
Кодовая таблица содержит коды для 256 различных символов, пронумерованных от О до 255. Первые 128 кодов во всех кодовых таблицах соответствуют одним и тем же символам:
• коды с номерами от О до 32 соответствуют управляющим символам;
• коды с номерами от 33 до 127 соответствуют изображаемым символам — латинским буквам, знакам препинания, цифрам, знакам арифметических операций и т. д.
Эти коды были разработаны в США и получили название ASCII (American Standart Code for Information Interchange — Американский стандартный код для обмена информацией).
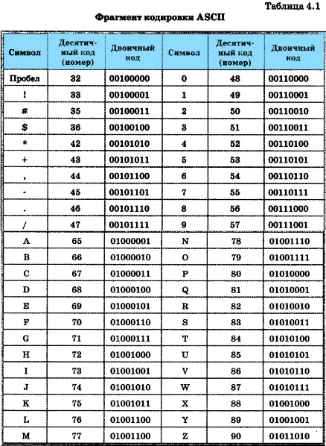
В таблице 4.1 представлен фрагмент кодировки ASCII.

Коды с номерами от 128 до 255 используются для кодирования букв национального алфавита, символов национальной валюты и т. п. Поэтому в кодовых таблицах для разных языков одному и тому же коду соответствуют разные символы. Более того, для многих языков существует несколько вариантов кодовых таблиц (например, для русского языка их около десятка!).
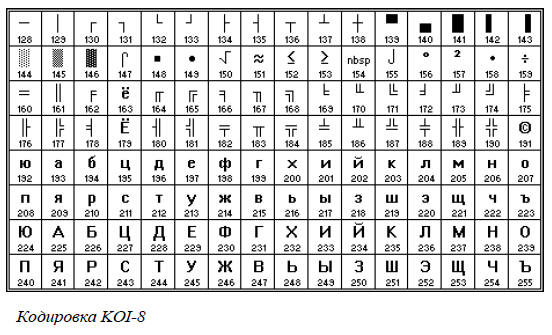
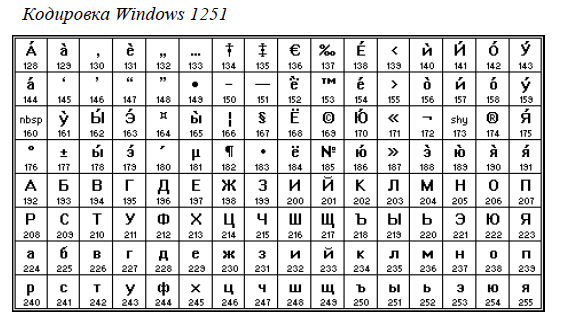
В таблице 4.2 представлены десятичные и двоичные коды нескольких букв русского алфавита в двух различных кодировках.

Например, последовательности двоичных кодов
11010010 11000101 11001010 11010001 11010010
в кодировке Windows будет соответствовать слово «ТЕКСТ», а в кодировке КОИ-8 — бессмысленный набор символов «рейяр».
Как правило, пользователь не должен заботиться о перекодировании текстовых документов, так как это делают специальные про- граммы-конверторы, встроенные в операционную систему и приложения.
Восьмиразрядные кодировки обладают одним серьёзным ограничением: количество различных кодов символов в этих кодировках недостаточно велико, чтобы можно было одновременно пользоваться более чем двумя языками. Для устранения этого ограничения был разработан новый стандарт кодирования символов, получивший название Unicode. В Unicode каждый символ кодируется шестнадцатиразрядным двоичным кодом. Такое количество разрядов позволяет закодировать 65 536 различных символов:
Первые 128 символов в Unicode совпадают с таблицей ASCII; далее размещены алфавиты всех современных языков, а также все математические и иные научные символьные обозначения. С каждым годом Unicode получает всё более широкое распространение.
• «Клавиатура ПЭВМ: принципы работы; устройство клавиши» (134923),
• «Клавиатура ПЭВМ: принципы работы; сканирование клавиш» (135019),
• «Клавиатура ПЭВМ: формирование кода введенного символа» (134868),
которые помогут вам наглядно увидеть, как формируется код символа, введённого с клавиатуры.
4.6.2. Информационный объём фрагмента текста
В зависимости от разрядности используемой кодировки информационный вес символа текста, создаваемого на компьютере, может быть равен:
• 8 битов (1 байт) — восьмиразрядная кодировка;
• 16 битов (2 байта) — шестнадцатиразрядная кодировка.
Информационным объёмом фрагмента текста будем называть количество битов, байтов или производных единиц (килобайтов, мегабайтов и т. д.), необходимых для записи этого фрагмента заранее оговорённым способом двоичного кодирования.
Задача 1. Считая, что каждый символ кодируется одним байтом, определите, чему равен информационный объём следующего высказывания Жан-Жака Руссо:
Тысячи путей ведут к заблуждению, к истине — только один.
Решение. В данном тексте 57 символов (с учётом знаков препинания и пробелов). Каждый символ кодируется одним байтом. Следовательно, информационный объём всего текста — 57 байтов.
Ответ: 57 байтов.
Задача 2. В кодировке Unicode на каждый символ отводится два байта. Определите информационный объём текста из 24 символов в этой кодировке.
Решение. I = 24 • 2 = 48 байтов.
Ответ: 48 байтов.
Ответ: 2 Кб.
Задача 4. Выразите в мегабайтах объём текстовой информации в «Современном словаре иностранных слов» из 740 страниц, если на одной странице размещается в среднем 60 строк по 80 символов (включая пробелы). Считайте, что при записи использовался алфавит мощностью 256 символов.
Решение. Информационный вес символа алфавита мощностью 256 равен восьми битам (одному байту). Количество символов во всём словаре равно 740 • 80 • 60 = 3 552 ООО. Следовательно, объём этого текста в байтах равен 3 552 ООО байтов = 3 468,75 Кбайт ≈ 3,39 Мбайт.
Ответ: 3,39 Мбайт.
САМОЕ ГЛАВНОЕ
Текст состоит из символов — букв, цифр, знаков препинания и т. д., которые человек различает по начертанию. Компьютер различает вводимые символы по их двоичному коду. Соответствие между изображениями и кодами символов устанавливается с помощью кодовых таблиц.
В зависимости от разрядности используемой кодировки информационный вес символа текста, создаваемого на компьютере, может быть равен:
• 8 битов (1 байт) — восьмиразрядная кодировка;
• 16 битов (2 байта) — шестнадцатиразрядная кодировка.
Информационный объём фрагмента текста — это количество битов, байтов (килобайтов, мегабайтов), необходимых для записи фрагмента оговорённым способом кодирования.
Вопросы и задания
2. Почему кодировки, в которых каждый символ кодируется цепочкой из восьми нулей и единиц, называются иначе однобайтовыми?
3. С какой целью была введена кодировка Unicode? Найдите дополнительную информацию об этой кодировке.
4. При работе в Интернете информация на одном из сайтов отобразилась так. как показано ниже.

Это произошло из-за:
1) установленной на компьютере системы контентной фильтрации
2) неправильных настроек монитора
3) неверного определения кодировки страницы
77 105 107 107 121 32 77 111 117 115 101
6. Считая, что каждый символ кодируется одним байтом, определите, чему равен информационный объём следующего высказывания Алексея Толстого:
Не ошибается тот, кто ничего не делает, хотя это и есть его основная ошибка.
7. Считая, что каждый символ кодируется 16 битами, оцените информационный объем следующей фразы А. С. Пушкина в кодировке Unicode:
Привычка свыше нам дана: Замена счастию она.
8. В текстовом режиме экран монитора компьютера обычно разбивается на 25 строк по 80 символов в строке. Определите объём текста, занимающего весь экран монитора, в кодировке Unicode.
§ 4.6. Оценка количественных параметров текстовых документов

§ 2. Представление текстовой информации в компьютере
Всякий текст состоит из символов - букв, цифр, знаков препинания и т. д., - которые человек различает по начертанию. Однако для компьютерного представления текстовой информации такой метод неудобен, а для компьютерной обработки текстов - и вовсе неприемлем. Используется другой способ: все символы кодируются числами, и текст представляется в виде набора чисел - кодов символов, его составляющих. При выводе текста на экран монитора или принтер необходимо восстановить изображения всех символов, составляющих данный текст. Для этого используются кодовые таблицы символов, в которых для каждого символа устанавливается соответствие между его кодом и изображением. Все кодовые таблицы, используемые в любых компьютерах и любых операционных системах, подчиняются международным стандартам кодирования символов.
Основой для компьютерных стандартов кодирования символов послужил ASCII ( American Standard Code for Information Interchange ) - американский стандартный код для обмена информацией, разработанный в 1960-х годах и применяемый в США для любых видов передачи информации. В нём используется `7`-битное кодирование: общее количество символов составляет `2^7=128`, из них первые `32` символа - «управляющие», а остальные - «изображаемые», т. е. имеющие графическое изображение. Управляющие символы должны восприниматься устройством вывода текста как команды, например:
Cимвол
Действие
Английское название
Подача стандартного звукового сигнала
Затереть предыдущий символ
Конец текстового файла
End Of File (EOF)
Отмена предыдущего ввода
К изображаемым символам в ASCII относятся буквы английского (латинского) алфавита (заглавные и прописные), цифры, знаки препинания и арифметических операций, скобки и некоторые специальные символы. Фрагмент кодировки ASCII приведён в таблице.
Символ
Десятичный код
Двоичный код
Символ
Десятичный код
Двоичный код
Хотя в ASCII символы кодируются `7`-ю битами, в памяти компьютера под каждый символ отводится ровно `1` байт (`8` бит). И получается, что один бит из каждого байта не используется.
Главный недостаток стандарта ASCII заключается в том, что он рассчитан на передачу только текста, состоящего из английских букв . Со временем возникла необходимость кодирования и неанглийских букв. Во многих странах для этого стали разрабатывать расширения ASCII-кодировки, в которых применялись однобайтные коды символов; при этом первые `128` символов кодовой таблицы совпадали с кодировкой ASCII, а остальные (со `128`-го по `255`-й) использовались для кодирования букв национального алфавита, символов национальной валюты и т. п. Из-за несогласованности этих разработок для многих языков было создано по нескольку вариантов кодовых таблиц (например, для русского языка их около десятка).
Впоследствии использование кодовых таблиц было несколько упорядочено: каждой кодовой таблице было присвоено особое название и номер. Указав кодовую таблицу, автоматически выбирают и язык, которым можно пользоваться в дополнение к английскому; точнее, выбирается то, как будут интерпретироваться символы с кодами более `127`.
Несовпадение кодовых таблиц приводит к ряду неприятных эффектов: один и тот же текст (неанглийский) имеет различное компьютерное представление в разных кодировках, соответственно, текст, набранный в одной кодировке, будет нечитабельным в другой!
Однобайтовые кодировки обладают одним серьёзным ограничением: количество различных кодов символов в отдельно взятой кодировке недостаточно велико, чтобы можно было пользоваться одновременно несколькими языками. Для устранения этого ограничения в 1993-м году был разработан новый стандарт кодирования символов, получивший название Unicode, который, по замыслу его разработчиков, позволил бы использовать в текстах любые символы всех языков мира.
В Unicode на кодирование символов отводится `32` бита. Первые `128` символов (коды `0-127`) совпадают с таблицей ASCII, все основные алфавиты современных языков полностью умещаются в первые `65536` кодов (`65536=2^16`), а в целом стандарт Unicode описывает все алфавиты современных и мёртвых языков; для языков, имеющих несколько алфавитов или вариантов написания (например, японский и индийский), закодированы все варианты; внесены все математические и иные научные символьные обозначения, и даже - некоторые придуманные языки (например, письменности эльфов и Мордора из эпических произведений Дж.Р.Р. Толкиена). Потенциальная информационная ёмкость Unicode столь велика, что сейчас используется менее одной тысячной части возможных кодов символов!
В современных компьютерах и операционных системах используется укороченная, `16`-битная версия Unicode, в которую входят все современные алфавиты; эта часть Unicode называется базовой многоязыковой страницей (Base Multilingual Plane, BMP).

В данный момент вы не можете посмотреть или раздать видеоурок ученикам
Чтобы получить доступ к этому и другим видеоурокам комплекта, вам нужно добавить его в личный кабинет, приобрев в каталоге.
Получите невероятные возможности



Конспект урока "Оценка количественных параметров текстовых документов"
· информационный объем текста.
Ежедневно каждый человек сталкивается с разными видами информации. Увидев важную информацию, можно записать её в компьютер, чтобы затем воспользоваться ей. В компьютер можно поместить фотографию своего друга или видеосъёмку о том, как вы провели каникулы. Но ввести в компьютер вкус мороженого или мягкость пледа никак нельзя.
Компьютер - это электронная машина, которая работает с сигналами. То есть он работать только информацией, которую можно превратить в сигналы. Если бы люди умели превращать в сигналы вкус или запах, то компьютер мог бы работать и с такой информацией.
Как вы уже знаете, вся информация, независимо от того, какая она графическая, видео или звуковая, представляется в компьютере с помощью чисел, это всего два символа двоичного кода, 0 и 1, которые легко перевести в сигналы.
Более 60% информации, представленной в компьютере, является текстовой информацией. В компьютерном алфавите 256 символов. Сюда входят заглавные и прописные буквы латинского и русского алфавитов, знаки препинания, печатные и непечатные символы, а также комбинации клавиш. человек различает текст по начертанию символов.

А вот компьютер различает символы, которые вводят в компьютер, по их двоичному коду. Вы нажимаете на клавиатуре символьную клавишу, в компьютер мгновенно поступает определённая последовательность электрических импульсов разной силы, которую можно представить в виде цепочки из восьми нулей и единиц (двоичного кода).

Мы уже говорили о том, что разрядность двоичного кода i и количество возможных кодовых комбинаций N связаны соотношением:

Восьмиразрядный двоичный код позволяет получить 256 различных кодовых комбинаций, то есть:

С помощью 256 кодовых комбинаций можно закодировать все символы, расположенные на клавиатуре компьютера, — строчные и прописные русские и латинские буквы, цифры, знаки препинания, знаки арифметических операций, скобки и т. д., а также ряд управляющих символов, без которых невозможно создание текстового документа (удаление предыдущего символа, переход на новую строку строки, пробел и др.).
Для создания 256 комбинаций необходимо 8 ячеек, содержащих 1 или 0. Поэтому каждому символу компьютерного алфавита в памяти компьютера отводится регистр – 8 ячеек.
Чтобы информация на всех компьютерах читалась одинаково, были созданы различные таблицы кодов. В СССР – это КОИ7 и КОИ8, в Америке –ASCII. Для кодирования информации в Windows используют таблицу ANSI.
С помощью кодовых таблиц устанавливается соответствие между изображениями и кодами символов.
Кодовая таблица содержит коды для 256 различных символов, пронумерованных от 0 до 255. Первые 128 кодов во всех кодовых таблицах соответствуют одним и тем же символам:
· коды с номерами от 0 до 32 соответствуют управляющим символам;
· коды с номерами от 33 до 127 соответствуют изображаемым символам — латинским буквам, знакам препинания, цифрам, знакам арифметических операций и т. д.
· Коды с номерами от 128 до 255 используются для кодирования букв национального алфавита, символов национальной валюты и т. п.
Поэтому в кодовых таблицах для разных языков одному и тому же коду соответствуют разные символы. Более того, для многих языков существует несколько вариантов кодовых таблиц. Так для русского языка их более десятка.
Например, последовательности двоичных кодов:

в кодировке Windows будет соответствовать слово «Урок», а в кодировке КОИ-8 — бессмысленный набор символов.
Естественно, пользователь не будет каждый раз перекодировать текстовые документы, это делают специальные программы-конверторы, встроенные в операционную систему и приложения.
Однако, восьмиразрядные кодировки обладают одним серьёзным ограничением: их количество различных кодов символов не хватает, для того чтобы можно было одновременно пользоваться более чем двумя языками. Для того чтобы на компьютере можно было устанавливать больше языков был разработан новый стандарт кодирования символов, получивший название Юникод.

Этот стандарт был предложен в 1991 году некоммерческой организацией «Консорциум Юникода».

С помощью этого стандарта можно закодировать очень большое число символов из разных письменностей: в документах Unicode могут соседствовать китайские иероглифы, математические символы, буквы греческого алфавита, латиницы и кириллицы, при этом становится ненужным переключение кодовых страниц.
Универсальная система кодирования (Юникод) представляет собой набор графических символов и способ их кодирования для компьютерной обработки текстовых данных.
В Юникод каждый символ кодируется шестнадцатиразрядным двоичным кодом. Такое количество разрядов позволяет закодировать

С каждым годом Юникод получает всё более широкое распространение.

В зависимости от разрядности используемой кодировки информационный вес символа текста, создаваемого на компьютере, может быть равен:
• 8 битов или 1 байт — если используется восьмиразрядная кодировка;
• 16 битов или 2 байта — если используется шестнадцатиразрядная кодировка.
Информационным объёмом фрагмента текста будем называть количество битов, байтов или производных единиц (килобайтов, мегабайтов и т. д.), необходимых для записи этого фрагмента заранее оговорённым способом двоичного кодирования.
Перейдём к практической части урока.
Давайте практически найдём информационный объем текста.
Итак, Книга содержит 150 страниц. На каждой странице - 40 строк. В каждой строке 60 символов (включая пробелы). Нужно найти информационный объем текста, если используется восьмиразрядная кодировка.

Рассмотрим следующую задачу
Информационный объем текста, подготовленного с помощью компьютера, равен 3,5 Мегабайт. Нужно найти сколько символов содержит этот текст, если используется восьмиразрядная кодировка.

Рассмотрим следующую задачу

Средняя скорость передачи данных по некоторому каналу связи равна 29 Килобит в секунду. Сколько секунд потребуется для передачи по этому каналу 50 страниц текста, если считать, что один символ кодируется одним байтом и на каждой странице в среднем 96 символов?

И последняя задача.
Пользователь компьютера, хорошо владеющий навыками ввода информации с клавиатуры, может вводить в минуту 100 знаков. Мощность алфавита, используемого в компьютере равна 256. Какое количество информации в байтах может ввести пользователь в компьютер за 1 минуту.

Пришло время подвести итоги урока.
Текст состоит из символов — букв, цифр, знаков препинания и т. д., которые человек различает по начертанию. Компьютер различает вводимые символы по их двоичному коду.
Соответствие между изображениями и кодами символов устанавливается с помощью кодовых таблиц.
В зависимости от разрядности используемой кодировки информационный вес символа текста, создаваемого на компьютере, может
• 8 бит (1 байт) — если используется восьмиразрядная кодировка;
• или 16 бит (2 байта) — если используется шестнадцатиразрядная кодировка.
Информационный объём фрагмента текста — это количество битов, байтов (килобайтов, мегабайтов), необходимых для записи фрагмента оговорённым способом кодирования.

Текст состоит из символов — букв, цифр, знаков препинания и т. д., которые человек различает по начертанию. Компьютер различает вводимые символы по их двоичному коду. Вы нажимаете на клавиатуре символьную клавишу, и в компьютер поступает определённая последовательность электрических импульсов разной силы, которую можно представить в виде цепочки из восьми нулей и единиц (двоичного кода).
Мы уже говорили о том, что разрядность двоичного кода i и количество возможных кодовых комбинаций N связаны соотношением: 2 i = N. Восьмиразрядный двоичный код позволяет получить 256 различных кодовых комбинаций: 2 8 = 256.
С помощью такого количества кодовых комбинаций можно закодировать все символы, расположенные на клавиатуре компьютера, — строчные и прописные русские и латинские буквы, цифры, знаки препинания, знаки арифметических операций, скобки и т. д., а также ряд управляющих символов, без которых невозможно создание текстового документа (удаление предыдущего символа, перевод строки, пробел и др.).
Соответствие между изображениями символов и кодами символов устанавливается с помощью кодовых таблиц.
Все кодовые таблицы, используемые в любых компьютерах и любых операционных системах, подчиняются международным стандартам кодирования символов.
Кодовая таблица содержит коды для 256 различных символов, пронумерованных от О до 255. Первые 128 кодов во всех кодовых таблицах соответствуют одним и тем же символам:
• коды с номерами от О до 32 соответствуют управляющим символам;
• коды с номерами от 33 до 127 соответствуют изображаемым символам — латинским буквам, знакам препинания, цифрам, знакам арифметических операций и т. д.
Эти коды были разработаны в США и получили название ASCII (American Standart Code for Information Interchange — Американский стандартный код для обмена информацией).
В таблице 4.1 представлен фрагмент кодировки ASCII.
Коды с номерами от 128 до 255 используются для кодирования букв национального алфавита, символов национальной валюты и т. п. Поэтому в кодовых таблицах для разных языков одному и тому же коду соответствуют разные символы. Более того, для многих языков существует несколько вариантов кодовых таблиц (например, для русского языка их около десятка!).
В таблице 4.2 представлены десятичные и двоичные коды нескольких букв русского алфавита в двух различных кодировках.
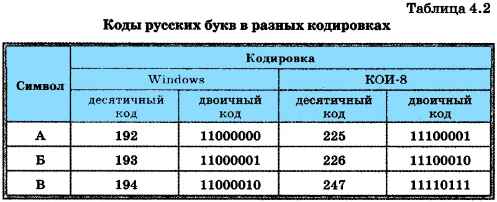
Например, последовательности двоичных кодов
11010010 11000101 11001010 11010001 11010010
в кодировке Windows будет соответствовать слово «ТЕКСТ», а в кодировке КОИ-8 — бессмысленный набор символов «рейяр».
Как правило, пользователь не должен заботиться о перекодировании текстовых документов, так как это делают специальные про- граммы-конверторы, встроенные в операционную систему и приложения.
Восьмиразрядные кодировки обладают одним серьёзным ограничением: количество различных кодов символов в этих кодировках недостаточно велико, чтобы можно было одновременно пользоваться более чем двумя языками. Для устранения этого ограничения был разработан новый стандарт кодирования символов, получивший название Unicode. В Unicode каждый символ кодируется шестнадцатиразрядным двоичным кодом. Такое количество разрядов позволяет закодировать 65 536 различных символов:
Первые 128 символов в Unicode совпадают с таблицей ASCII; далее размещены алфавиты всех современных языков, а также все математические и иные научные символьные обозначения. С каждым годом Unicode получает всё более широкое распространение.
которые помогут вам наглядно увидеть, как формируется код символа, введённого с клавиатуры.
4.6.2. Информационный объём фрагмента текста

В зависимости от разрядности используемой кодировки информационный вес символа текста, создаваемого на компьютере, может быть равен:
• 8 битов (1 байт) — восьмиразрядная кодировка;
• 16 битов (2 байта) — шестнадцатиразрядная кодировка.

Информационным объёмом фрагмента текста будем называть количество битов, байтов или производных единиц (килобайтов, мегабайтов и т. д.), необходимых для записи этого фрагмента заранее оговорённым способом двоичного кодирования.
Задача 1. Считая, что каждый символ кодируется одним байтом, определите, чему равен информационный объём следующего высказывания Жан-Жака Руссо:
Тысячи путей ведут к заблуждению, к истине — только один.
Решение. В данном тексте 57 символов (с учётом знаков препинания и пробелов). Каждый символ кодируется одним байтом. Следовательно, информационный объём всего текста — 57 байтов.
Ответ: 57 байтов.
Задача 2. В кодировке Unicode на каждый символ отводится два байта. Определите информационный объём текста из 24 символов в этой кодировке.
Решение. I = 24 • 2 = 48 байтов.
Ответ: 48 байтов.
Ответ: 2 Кб.
Задача 4. Выразите в мегабайтах объём текстовой информации в «Современном словаре иностранных слов» из 740 страниц, если на одной странице размещается в среднем 60 строк по 80 символов (включая пробелы). Считайте, что при записи использовался алфавит мощностью 256 символов.
Решение. Информационный вес символа алфавита мощностью 256 равен восьми битам (одному байту). Количество символов во всём словаре равно 740 • 80 • 60 = 3 552 ООО. Следовательно, объём этого текста в байтах равен 3 552 ООО байтов = 3 468,75 Кбайт ≈ 3,39 Мбайт.
Ответ: 3,39 Мбайт.
САМОЕ ГЛАВНОЕ
Текст состоит из символов — букв, цифр, знаков препинания и т. д., которые человек различает по начертанию. Компьютер различает вводимые символы по их двоичному коду. Соответствие между изображениями и кодами символов устанавливается с помощью кодовых таблиц.
В зависимости от разрядности используемой кодировки информационный вес символа текста, создаваемого на компьютере, может быть равен:
• 8 битов (1 байт) — восьмиразрядная кодировка;
• 16 битов (2 байта) — шестнадцатиразрядная кодировка.
Информационный объём фрагмента текста — это количество битов, байтов (килобайтов, мегабайтов), необходимых для записи фрагмента оговорённым способом кодирования.
Вопросы и задания
2. Почему кодировки, в которых каждый символ кодируется цепочкой из восьми нулей и единиц, называются иначе однобайтовыми?
3. С какой целью была введена кодировка Unicode? Найдите дополнительную информацию об этой кодировке.
4. При работе в Интернете информация на одном из сайтов отобразилась так. как показано ниже.

Это произошло из-за:
1) установленной на компьютере системы контентной фильтрации
2) неправильных настроек монитора
3) неверного определения кодировки страницы
77 105 107 107 121 32 77 111 117 115 101
6. Считая, что каждый символ кодируется одним байтом, определите, чему равен информационный объём следующего высказывания Алексея Толстого:
Не ошибается тот, кто ничего не делает, хотя это и есть его основная ошибка.
7. Считая, что каждый символ кодируется 16 битами, оцените информационный объем следующей фразы А. С. Пушкина в кодировке Unicode:
Привычка свыше нам дана: Замена счастию она.
8. В текстовом режиме экран монитора компьютера обычно разбивается на 25 строк по 80 символов в строке. Определите объём текста, занимающего весь экран монитора, в кодировке Unicode.
Электронное приложение к учебнику
Презентация «Оценка количественных параметров текстовых документов» (Open Document Format)
Ссылки на ресурсы ЕК ЦОР
Ссылки на ресурсы ФЦИОР
Презентация «Оценка количественных параметров текстовых документов»
Единая коллекция цифровых образовательных ресурсов

1) тренажер «Интерактивный задачник. Раздел "Представление символьной информации"» (N 119265).
Ресурсы ФЦИОР
1) информационный модуль по теме «Представление текста в различных кодировках»;
2) практический модуль теме «Представление текста в различных кодировках»;
3) контрольный модуль по теме «Представление текста в различных кодировках».
Практическая часть урока
1) Выполнить задания № 218, № 219, № 221, № 223, № 225, № 230 в РТ.
2) Работа учащихся с тренажером «Интерактивный задачник. Раздел "Представление символьной информации"» (N 119265) в режиме практики.
Практическая работа №12
"Сканирование и распознавание текстовых документов"
Задание 1. Сканирование
1. Откройте крышку подключенного к компьютеру планшетного сканера. Положите документ на стекло сканера сканируемой стороной (текстом) вниз. Аккуратно закройте крышку сканера.
2. Запустите программу сканирования, идущую в комплекте с вашим сканером. Исследуйте панель инструментов программы сканирования, найдите кнопкуСканировать и щелкните на ней.
3. Дождитесь окончания сканирования.
4. Сохраните отсканированный документ в личной папке виде графического файла с именем Скан и одним из расширений tif, bmb, jpg, png и др.
5. Завершите работу с программой сканирования.
Задание 2. Распознавание
1. Подключитесь к Интернету, запустив браузер Chrome.
Для работы с сайтом можете воспользоваться автоматическим переводом. Если переводчик не включен, то можно перевести страницу, нажав на ней правой кнопкой мыши и выбрав в контекстном меню Перевести на русский.
3. Нажмите на кнопку Выберите файл, найдите и откройте созданный в предыдущем задании файл.
4. Щелкните мышью на кнопке . Дождитесь загрузки изображения ( ); при необходимости поверните его ( ).
5. Щелкните мышью на кнопке . Дождитесь окончания распознавания ( ) и появления области с распознанным текстом.
6. Загрузите распознанный текст в текстовый процессор Word:


7. Включите режим отображения скрытых символов форматирования ( ). Проведите редактирование текстового документа: удалите лишние символы конца абзаца, обратите внимание на неуверенно распознанные слова и символы.
8. Сохраните результат работы в личной папке в файле Распознавание.
Теперь вы умеете:
• сканировать текстовые документы;
• выполнять распознавание отсканированных текстовых документов с помощью онлайн-сервиса.
Читайте также: