
Vcls vmware что это
Обновлено: 04.07.2024
Прошел уже почти год с момента как я опубликовал последнюю запись на тему документа по Best Practices в VMware 7.0. Изначально я не планировал разбирать его дальше раздела, посвященного виртуальным машинам, однако результаты посещаемости сайта говорят о том, что данный цикл интересен читателю и было бы неплохо его закончить.
В течение следующих частей мы посмотрим на рекомендации VMware по управлению виртуальной инфраструктурой. Сегодня на очереди vCenter Server, vMotion, DRS, DPM.
Еще раз напоминаю, что это вольное изложение и часть информации из документа будет опущена, а что-то может быть сформулировано не совсем корректно. Не забудьте ознакомиться с оригинальным документом.
Для тех, кто здесь впервые, рекомендую предварительно ознакомиться с другими частями:
General Resource Management
Гипервизор ESXi предоставляет пользователю несколько механизмов для конфигурации и распределения ресурсов между виртуальными машинами. При этом ручное распределение вычислительных ресурсов может оказать значительное влияние на производительность виртуальных машин. Отсюда следует ряд рекомендаций:
- Следует использовать Reservation, Shares и Limits только в случае необходимости;
- Если ожидаются частые изменения в инфраструктуре, которые могут влиять на общее количество доступных ресурсов, стоит использовать Shares, а не Reservation для честного распределения ресурсов между виртуальными машинами;
- При использовании Reservation, рекомендуется указывать минимально необходимое количество CPU или RAM, а не резервировать все ресурсы для виртуальной машины. После того, как резерв будет удовлетворен, оставшиеся ресурсы будут распределены на основании показателя Shares. Не стоит выставлять большие значения Reservations, это может помещать запуску других виртуальных машин, которым не остается свободных ресурсов в пуле;
- При использовании резервов, всегда необходимо оставлять свободные ресурсы для работы гипервизора и прочих служб, например, DRS и миграции;
- Чтобы полностью изолировать пул ресурсов, необходимо использовать тип Fixed, а также включить для него Reservation и Limit;
- Если сервис состоит из нескольких виртуальных машин (multi-tier service), стоит группировать данные виртуальные машины в рамках одного пула ресурсов для управления потребностями на уровне сервиса целиком.
VMware vCenter
- vCenter Server должен получать достаточное количество вычислительных и дисковых ресурсов для функционирования;
- Количество потребляемых ресурсов и производительность напрямую зависит от размера инфраструктуры (количество хостов, виртуальных машин и т.п.), а также от количества подключенных клиентов. Превышение допустимых максимумов однозначно скажется на производительности в худшую сторону, и к тому же не поддерживается;
- Для получения минимальных задержек при работе vCenter с базой данных, следует минимизировать количество сетевых узлов между ними;
- Сетевые задержки между vCenter Server и хостами ESXi могут влиять на производительность операций, в которые вовлечены данные хосты.
VMware vCenter Database Considerations
Работа vCenter напрямую зависит от работоспособности и производительности базы данных, в которой он хранит конфигурационную информацию о всем окружении, статистику, задачи, события и т.д.
VMware vCenter Database Network and Storage Considerations
- Если vCenter Appliance использует thin или lazy-zeroed диски, процесс загрузки может быть дольше, чем в случае использования дисков в формате eager-zeroed;
- В крупных инсталляциях могут генерироваться большие объемы данных и хорошей практикой будет наблюдение за утилизацией дискового пространства. Как настроить оповещения сказано в соответствующей KB.
VMware vCenter Database Configuration and Maintenance
- Следует использовать statistic level в соответствии с текущими требованиями. Данное значение может варьироваться от 1 до 4, но 1 достаточно в большинстве случаев. Более высокие значения могут замедлить работу vCenter, а также увеличится потребление дискового пространства. В случае, если необходим более высокий уровень статистики, например, при отладке, по окончанию данного процесса его следует снизить;
- При запуске vCenter формирует пул из 50 потоков для подключения к БД. Размер данного пула меняется динамически в зависимости от работы vCenter и не требует модификации. Однако, при необходимости, размер данного пула может быть изменен до 128 потоков, при этом следует учитывать, что это увеличит потребление ОЗУ и может снизить скорость загрузки VC;
- При необходимости подключения к БД VCSA следует воспользоваться материалом из данной KB;
- В случае, если наблюдается медленное выполнение запросов, производительность может быть увеличена с помощью выполнения процедуры Vacuum and Analyze на базе данных VCDB.
PostgreSQL (vPostgres) Database Recommendations
В качестве базы данных vCenter использует PostgreSQL (vPosgress). Несмотря на то, что на этапе инсталляции, оптимизация работы базы данных выполняется автоматически, есть некоторые моменты на которые стоит обратить внимание:
- vCenter Server Appliance создает несколько виртуальных дисков в момент инсталляции. Для улучшения производительности в больших окружениях следует убедиться, что виртуальные диски с партициями /storage/db, /storage/dblog и /storage/seat располагаются на разных физических дисках;
- На виртуальном диске /storage/dblog хранятся транзакционные логи базы данных. vCenter особенно чувствителен к производительности данной партиции, в связи с чем виртуальный диск с данным разделом рекомендуется располагать на высокопроизводительном хранилище с наименьшим временем отклика;
- Несмотря на то, что у PostgreSQL имеется свой собственный кэш, данные так же кэшируются на уровне операционной системы. Таким образом, производительность может быть улучшена за счет увеличения кэша ОС. Сделать это можно увеличив объем ОЗУ, выделенный виртуальной машине с vCenter Server, после чего, часть выделенной оперативной памяти будет задействована под кэш;
- При достижении размера партиции /storage/dblog примерно до 90%, происходит сброс транзакционных логов. Чем быстрее заполняется этот раздел – тем чаще происходит операция сброса, увеличивая при этом количество дисковых операций. Увеличение размеров данной партиции снижает частоту сброса логов и уменьшает общий ввод-вывод. Это может помочь в больших инфраструктурах, однако, здесь есть и минусы – в случае необходимости восстановления после сбоя, данная процедура может занять большее время;
- Для мониторинга дискового пространства можно использовать параметры vpxd.vdb.space.errorPercent и vpxd.vdb.space.warningPercent в расширенных настройках vCenter Server;
- Так же для мониторинга можно использовать плагин pgtop для vCenter Server Appliance.
VMware vMotion and Storage vMotion
VMware vMotion Recommendations
- Виртуальные машины, создаваемые в vSphere 7.0, имеют версию vHardware 17 (а в более свежих апдейтах – 18). Поскольку виртуальные машины с vHardware версии 17 могут запускаться только на хостах ESXi 7.0 и выше, vMotion для данных VM будет функционировать только в рамках хостов, поддерживающих данную версию;
- Начиная с версии 6.5 vSphere поддерживает шифрование при выполнении операций миграции vMotion. Шифрование выполняется как на источнике, так и на приемнике, поэтому в случае миграции виртуальной машины на хост, версия которого ниже, чем 6.5, шифрования траффика при операциях vMotion производиться не будет;
- Производительность vMotion со включенным шифрованием будет значительно выше, в случае если хост поддерживает инструкции AES_NI (Intel’s Advanced Encryption Standard New Instruction Set). Без поддержки данных инструкций, производительность vMotion может быть неприемлемой;
- Зашифрованные виртуальные машины всегда используют Encrypted vMotion при миграции. Для нешифрованных виртуальных машин, шифрование может быть отключено (Disabled), обязательно (Required) и «по возможности» (Opportunistic);
- Производительность vMotion напрямую зависит от скорости сети, поэтому рекомендуется иметь сетевое подключение 10GB/s и выше для сети, которая задействована под миграцию;
- Все vmknic для vMotion следует располагать на одном и том же виртуальном свитче, при этом каждая из подгрупп, к которым они подключены, должна использовать разные физические интерфейсы в качестве активного аплинка;
- В случае использования сети 40GB/s, рекомендуется сконфигурировать минимум 3 vMotion vmknics. Использование нескольких vmknic позволяет создавать множество потоков vMotion, утилизируя при этом большее количество процессорных ядер и увеличивая общую производительность;
- При выполнении операций vMotion, ESXi старается зарезервировать процессорные ресурсы на источнике и приемнике, с целью максимальной утилизации пропускной способности сети. Количество резервируемого CPU зависит от количества vMotion NICs и их скорости, и составляет 10% производительности процессорного ядра за каждый 1Gb/s сетевого интерфейса, или же 100% процессорного ядра за каждый 10GB/s сетевой интерфейс, c минимальным резервом в 30%. Из этого вытекает то, что всегда следует держать незарезервированные процессорные ресурсы, чтобы процессы vMotion могли полностью утилизировать доступный сетевой канал и выполнять миграции быстрее;
- Производительность vMotion может быть снижена, если swap уровня хоста размещен на локальных дисках (SSD или HDD).
VMware Storage vMotion Recommendations
- Производительность Storage vMotion напрямую зависит от инфраструктуры хранения данных, от скорости подключения ESXi к хранилищам, от скорости работы хранилища-источника и хранилища-приемника. В момент операции миграции происходит чтение данных виртуальной машины из источника и запись в приемник, при этом виртуальная машина продолжает функционировать;
- Storage vMotion будет иметь максимальную производительность в моменты низкой активности в сети хранения и если перемещаемые виртуальные машины при этом не создают большого дискового ввода-вывода;
- Одна операция миграции позволяет перемещать до 4-х дисков виртуальной машины одновременно, но при этом на один Datastore будет копироваться не более одного диска одновременно. Например, перемещение 4-х дисков VMDK с хранилища A в хранилище B будет выполняться последовательно диск за диском, в то время, как перемещение четырех дисков VMDK с хранилищ A, B, C, D в хранилища E, F, G, H будут идти параллельно;
- Как вариант, можно использовать anti-affinity правила для дисков виртуальных машин, тем самым выполнять операции svMotion на разные Datastore параллельно;
- При выполнении операции Storage vMotion на более быстрое хранилище, эффект будет заметен только по окончанию процедуры миграции. В то же время эффект от перемещения на более медленное хранилище будет проявляться постепенно с операцией копирования;
- Storage vMotion работает значительно лучше на массивах, поддерживающих VAAI.
VMware Cross-Host Storage vMotion Recommendations
Cross-host Storage vMotion позволяет перемещать виртуальные машины одновременно между хостами и хранилищами.
- Cross-host Storage vMotion оптимизирован для работы с блоками размером 1MB, который уже достаточно давно является размером блока, выбираемым по умолчанию для VMFS. Однако, при создании хранилищ VM на VMFS3 размер блока мог быть выбран другой и при апгрейде хранилища до VMFS5 он не изменялся. В таком случае, самым верным вариантом будет пересоздать хранилище;
- При использовании 40GB/s интерфейсов, применяются те же правила, что и для обычного vMotion, и рекомендуется использовать 3 vMotion vmknics;
- Аналогичным образом одновременно копируется 4 диска и применяются те же правила, что и при Storage vMotion;
- В большинстве своем, Cross-host Storage vMotion для миграции виртуальных дисков использует сеть vMotion. Однако, если оба хоста, между которыми выполняется миграция, подключены к одному и тому же массиву, поддерживающему VAAI, и хост-источник имеет доступы к Datastore, на который будет мигрирована виртуальная машина, в таком случае будет задействован VAAI функционал массива. Если же VAAI не поддерживается, будет задействована сеть хранения данных для копирования дисков, а не сеть vMotion;
При миграции выключенных виртуальных машин, Cross-host Storage vMotion будет использовать технологию Network File Copy (NFC). Однако, как и в случае со включенными виртуальными машинами, NFC будет задействовать VAAI, если это возможно, или же сеть хранения данных (нужно помнить, что это будет возможно только в случае, если хост-источник имеет доступ к хранилищу, куда перемещается машина).
Примечание: до vSphere 6.0 NFC использовал только management сеть. Начиная с vSphere 6.0, NFC траффик все так же использует сеть управления по умолчанию, однако, теперь для нужд NFC можно выделить отдельный интерфейс (vmknic Storage Replication).
VMware Distributed Resource Scheduler (DRS)
DRS in General
- Следует следить за рекомендациями DRS, особенно в случае использования ручных ограничений и правил. В некоторых случаях невыполнение текущих рекомендаций может помешать генерации новых;
- В случае использования affinity rules, следует наблюдать за DRS Faults и ошибками в работе DRS, которые могут возникать из-за препятствия существующих правил балансировке. Устранение текущих ошибок может значительно помочь с балансировкой существующей нагрузки;
- Начиная с vSphere 7.0 привычная метрика cluster-level balance была заменена на новую – Cluster DRS Score, которая является индикатором состояния кластера и виртуальных машин в данном кластере.
DRS Cluster Configuration Setting
DRS affinity rules позволяют обеспечивать нахождение группы виртуальных машин в рамках одного хоста (VM/VM affinity), в то время как anti-affinity rules, препятствуют этому (VM/VM anti-affinity). Правила DRS так же позволяют явно указать хосты, на которых будут запускаться виртуальные машины (VM/Host affinity), или наоборот не будут (VM/Host anti-affinity).
В большинстве случаев, отказ от использования affinity rules позволит получить наилучший эффект от работы DRS, однако в некоторых случаях, данные правила могут улучшить производительность и обеспечить высокую доступность для сервисов.
Доступны следующие правила:
- Keep Virtual Machines Together – позволяет достичь повышения производительности за счет уменьшения задержек при взаимодействии между виртуальными машинами в группе;
- Separate Virtual Machines – Использование данного правила для группы VM, предоставляющих один и тот же сервис, позволит повысить доступность сервиса, за счет исключения ситуации, при которой все виртуальные машины, обеспечивающие один и тот же сервис оказались на одном хосте, с которым возникли неполадки;
- Virtual Machines to Hosts – Включает в себя правила Must run on, Should run on, Must not run on и Should not run on, которые могут применяться, например, в случае с лицензированием, поскольку ограничивают круг хостов, на которых могут запускаться VM.
DRS Cluster Sizing and Resource Settings
- Превышение допустимых максимумов по количеству хостов, виртуальных машин, пулов ресурсов не поддерживается. Несмотря на то, что система с превышенными максимумами может оставаться работоспособной, это может повлиять на производительность vCenter Server и DRS;
- С осторожностью следует подходить к установке reservations, shares и limits. Слишком большой резерв может оставить мало незарезервированных ресурсов в кластере, что повлияет на DRS. В то же время слишком низкие лимиты могут препятствовать виртуальной машине в использовании свободных ресурсов, что скажется на ее производительности;
- DRS учитывает NetIOC (NIOC) при расчетах рекомендаций;
- Как уже упоминалось выше, для операций vMotion следует оставлять свободные ресурсы CPU на хостах.
DRS Performance Tuning
Начиная с vSphere 7.0 реакция механизма DRS зависит от типа нагрузок и настраивается соответственно нагрузкам в кластере. Всего таких уровней 5:
Level 1 – Только необходимая миграция, например, при вводе хоста в режим Maintenance. На текущем уровне DRS не предлагает миграцию с целью улучшения производительности;
Level 2 – Используется для стабильных рабочих нагрузок. DRS рекомендует миграцию виртуальных машин, только в моменты нехватки ресурсов;
Level 3 – Уровень по умолчанию. Подходит для большинства стабильных нагрузок;
Level 4 – Для систем, которым свойственны всплески при потреблении ресурсов и требуется реакция DRS;
Level 5 – Данный уровень следует использовать для динамичных нагрузок, потребление ресурсов которых постоянно изменяется.
В vSphere имеется ряд функций, которые могут упростить управление кластером:
- VM Distribution – DRS старается равномерно распределять виртуальные машины в кластере, тем самым косвенно повышая доступность систем;
- Начиная с vSphere 7.0 в дополнении к процессорным ресурсам и оперативной памяти, DRS учитывает так же и пропускную способность сети, когда формирует рекомендации по перемещению VM.
Обще вышеуказанных опции доступны в разделе Additional Options настроек DRS.
Для получения высоких показателей DRS Score, возможно, следует ослабить действующие в кластере правила, изменить уровень реагирования DRS, либо снизить потребление ресурсов в кластере.
Есть несколько причин, по которым DRS Score может быть занижен:
- Миграции препятствуют affinity и anti-affinity правила;
- Миграции препятствуют несовместимые хосты в кластере;
- Затраты ресурсов на миграцию могут быть выше, чем ожидаемые преимущества после ее выполнения;
- На всех хостах в кластере повышенная загрузка сетевых интерфейсов;
- В кластере нет свободных ресурсов, чтобы удовлетворить потребности виртуальных машин.
VMware Distributed Power Management (DPM)
VMware Distributed Power Management позволяет экономить электроэнергию, в моменты, когда хосты в кластере не утилизированы и не находятся под нагрузкой. Данный функционал позволяет консолидировать виртуальные машины на группе хостов, после чего переводит высвободившиеся гипервизоры в Standby режим. DPM поддерживает достаточную вычислительную емкость в кластере, чтобы удовлетворить нужды всех виртуальных машин. В моменты, когда потребность в ресурсах увеличивается, DPM включает дополнительные хосты и переносит на них виртуальные машины, приводя кластер к сбалансированному состоянию.
Начиная с vSphere 7.0, DPM учитывает всю выделенную оперативную память для виртуальных машин и поскольку эти значения достаточно стабильны, в большинстве случаев работа DPM зависит от процессорной утилизации.
DPM использует DRS, а значит большинство практик, применяемых к DRS, применяются и к DPM.

В начале обозначим, что в рамках данной статьи мы будем понимать под кластером группу хостов (физических серверов) под управлением единого сервиса для совместного выполнения определенных функций как целостная система, связывающаяся через сеть.
На платформе виртуализации VMware vSphere можно построить 2 разновидности кластеров: High-availability кластер (HA) и Distributed Resource Scheduler кластер (DRS).
HA-кластер будет означать, что определенное количество физических серверов объединяется в кластер и на них запускаются виртуальные машины. В случае выхода из строя одного из хостов, виртуальные машины запускаются на других серверах из группы, на которых предварительно было выделено для этого место. В итоге время простоя равно времени загрузки операционной системы «виртуалки».
Если необходимо сократить время простоя до минимального времени рекомендуется использовать технологию VMware Fault Tolerance. Основную идею опции можно описать как создание синхронно работающей реплики виртуальной машины на другом сервере и мгновенное переключение на неё при выходе из строя основного хоста.
Fault Tolerance
Технология VMware DRS используется для выравнивания нагрузки в кластере. Для этого на первоначальном этапе ресурсы кластера объединяются в пул и затем происходит балансировка нагрузки между хостами путем перемещения виртуальных машин. DRS может рекомендовать перемещение с необходимым подтверждением от администратора или делать это в автоматическом режиме. Происходит это с использованием утилиты «живой миграции» vMotion, благодаря которой миграция не требует остановки ВМ. Пользователи продолжают работать с одним экземпляром ВМ до тех пор, пока данные не будут перенесены на другой хост. В последний момент копируются последние изменения из оперативной памяти, пользователь видит незначительное кратковременное снижение быстродействие системы и через мгновение уже работает с той же ВМ, которая по факту уже находится на другом физическом сервере.
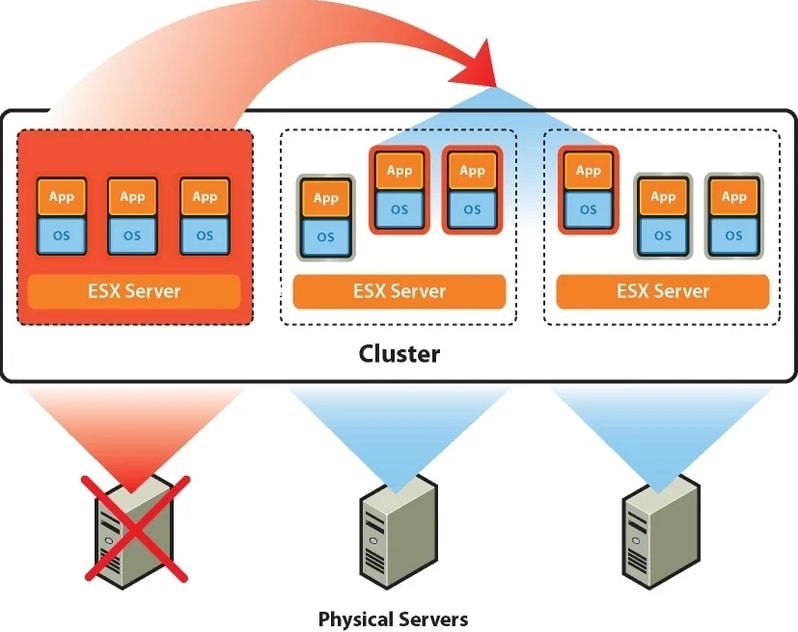
Принцип работы VMware HA + DRS
В случае с кластером VMware группа из 2-х и более серверов ESXi находится под централизованным управлением VMware vCenter Server. Собственно, создавать виртуальные машины можно и на одном хосте с установленным гипервизором VMware ESXi, но возможностей HA, DRS и прочих у вас не будет. Вы просто сможете «нарезать» ваш физический сервер на несколько виртуальных, а его неработоспособность будет означать простой всех ВМ.
Чтобы пользоваться всеми кластерными возможностями необходимо использовать платформу VMware vSphere, которая включает в себя сервер управления ESXi-хостами и СХД, так называемый и упомянутый выше, vCenter Server. Также для построения кластера потребуется подключение системы хранения данных. В ней в особенной кластерной файловой системе VMFS хранятся разделы с файлами виртуальных машин, которые доступны для чтения и записи всем ESXi-хостам кластера. По причине хранения в одном месте и независимости виртуальной машины от физической платформы достигается быстрое перемещение и восстановление при помощи HA, DRS, FT, vMotion.
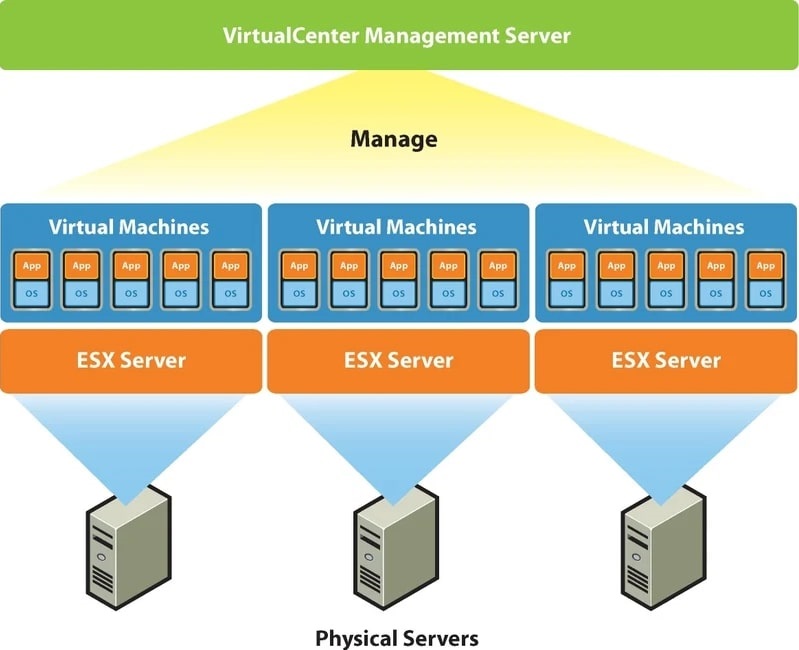
Платформа VMware vSphere
VMware vCenter Server, если говорить упрощенно, является набором служб и базой данных. Каждая из служб занимается своим конкретным списком задач и взаимодействует с другими службами и/или хостами ESXi. vCenter Server – это некий командный пункт, которому подчиняются гипервизоры ESXi на хостах. Общение между ними происходит через хостовых агентов VPXA. Из панели управления vCenter Server можно делать даже больше, чем подключившись напрямую к ESXi. Если в ESXi вы сможете создавать/удалять виртуальные машины, то с помощью vCenter Server вы можете дополнительно создать и настроить для них кластер и все необходимые кластерные опции, часть из которых описана выше.
VMware vCenter Server может работать как на отдельной физическом сервере, так и внутри виртуальной машины на том же хосте, которым сам же и управляет.
Тема безусловно интересная и обширная, однако для развертывания подобных инфраструктур требуются большие материальные затраты. Если мы хотим пользоваться всеми возможностями, которые повышают отказоустойчивость и надежность системы, необходимо приобрести минимум два сервера и СХД, купить лицензию на платформу VMware VSphere у одного из дистрибьюторов. Установка, настройка и администрирование кластера VMware также потребует от вас временных и финансовых вложений.
Что делать в случае, если от вашей IT-инфраструктуры требуется высокая надежность, которую предоставляет платформа VMware vSphere, но нет возможности понести значительные капитальные вложения? Ответом на этот вопрос для многих корпоративных клиентов стало использование облачных технологий, а именно услуга аренды инфраструктуры (IaaS). Облачный провайдер обладает необходимым сетевым и серверным оборудованием, которое расположено в безопасных дата-центрах. IT-специалисты провайдера оказывают техническую поддержку 24*7, а бизнес может воспользоваться всеми преимуществами виртуализации в кластере VMware.
Клиенты не используют VMware vCenter Server. За управление кластерами и физическим оборудованием отвечает провайдер. Клиенты получают значительное количество возможностей управления своим виртуальным ЦОДом с помощью удобного портала самообслуживания VMware vCloud Director. Создание vЦОДа для клиента происходит в кратчайшие сроки, при этом может быть создано необходимое количество виртуальных машин с нужными характеристиками и операционными системами, маршрутизируемые и изолированные сети с любой топологией, настроены гибкие правила Firewall и многое другое.
Если вашему бизнесу требуется надежное IT-решение на основе кластера VMware, для принятия решения рекомендуем воспользоваться тестовым доступом к облаку Cloud4Y.
Практическим применением знаний о работе с массивами EVA и iLO в серверах ProLiant, которые вы получили чуть раньше, может стать развертывание высокодоступного кластера на vSphere.
Кластер может использоваться для предприятий среднего и крупного размера, чтобы уменьшить время внеплановых простоев. Поскольку для бизнеса важны такие параметры как доступность его сервиса или услуги клиенту в режиме 24x7, то такое решение основывается на кластере высокой доступности. В кластер всегда входят как минимум 2 сервера. В нашем решении серверы под управлением VMware отслеживают состояние друг друга, при этом в каждый момент времени ведущим будет только один из них, на нем будет разворачиваться виртальная машина с нашим бизнес-приложением. В случае отказа ведущего сервера его роль автоматически принимает второй, при этом для заказчика доступ к бизнес-приложению практически не прерывается.
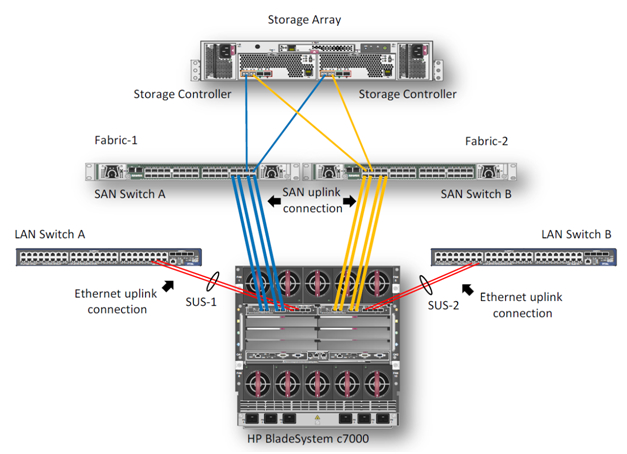
1. Описание задачи
В данном примере мы опишем процесс создания высокодоступного кластера VMware на блейд-серверах BL460c G7. Оборудование состоит из блейд-корзины HP c7000 и двух блейд-серверов BL460c G7, где скофигурирован VMware HA(High Available)-кластер. В демо-центре HP в Москве сейчас доступны только модели блейд-серверов G7, но на основе описанного примера можно собрать кластер и на новых блейд-серверах Gen8. Конфигурирование, в целом, не будет различаться. Система хранения – HP EVA 4400. Для Ethernet и Fibre Channel подключений в корзине c7000 установлены 2 модуля HP Virtual Connect Flex Fabric в отсеках 1 и 2.
2. Описание компонентов

Virtual Connect FlexFabric — конвергентный виртуализированный модуль ввода/вывода для блейд-корзины с7000.
Модуль HP Virtual Connect FlexFabric использует технологии Flex-10, FCoE, Accelerated iSCSI для коммутации блейд-серверов и сетевой инфраструктуры (SAN и LAN) со скоростью 10Gb.
Из возможностей: перенос «профилей» (таблица MAC и WWN серверов) не только между разными лезвиями в шасси, но и на удалённые сайты, где есть такой же блейд-сервер.
Так же при использовании Virtual Connect каждый из двух портов сетевой карты блейд-сервера можно делить на 4 виртуальных порта 1GbE/10GbE/8Gb FC/iSCSI общей пропускной способностью 10GbE на порт. Это позволяет получить от 8 виртуальных портов на сервер (на BL460с G7), которые необходимо задавать при первой инициализации.
Единственное ограничение в том, что HP Virtual Connect FlexFabric не являются полноценными коммутаторами. Это аггрегаторы, для работы которых необходимо иметь отдельные Ethernet- и SAN-свитчи (в последней прошивке, правда, появилась возможность Direct Connect с HP P10000 3PAR).
Общий вид использованного оборудования отражается в Onboard Administrator.

Интегрированная в ProLiant BL460c G7 карта NC553i Dual Port FlexFabric 10Gb может работать с модулями HP Virtual Connect FlexFabric напрямую, без дополнительных мезонин-карт. Два модуля HP Virtual Connect FlexFabric установлены для отказоустойчивости путей связи связи блейд-серверов с системой хранения EVA 4400 и Ethernet-коммутаторами.
В данном примере будем рассматривать сценарий, когда трафик от модуля HP Virtual Connect FlexFabric разделяется на Ethernet-коммутаторы и FC-фабрику. FCoE в этом случае используется для коммутации модулей с блейд-серверами внутри корзины.
Для работы с различными протоколами модулям HP Virtual Connect FlexFabric необходимы трансиверы. В этом примере 4 Gb FC SFP трансиверы были установлены в порты 1 и 2 на каждом из модулей, а 10 Gb SFP+ трансиверы были установлены в порты 4 и 5. 10GbE-каналы использованы в данном тесте чтобы задействовать сетевое оборудование в нашем демо-центре.
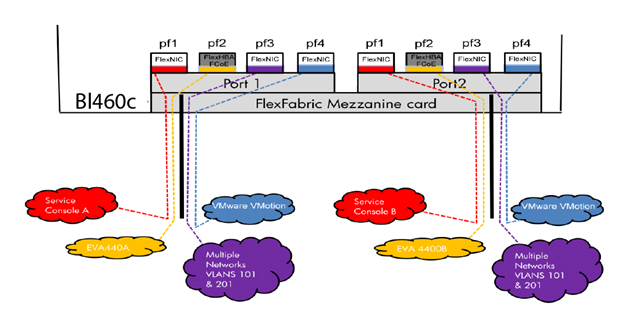
Диаграмма показывает, что 3 порта сетевого адаптера NC553i Dual Port FlexFabric 10Gb сконфигурированы как FlexNIC для взаимодействия виртуальных машин между собой и для подключения к сетевой инфраструктуре. Оставшийся порт был сконфигурирован как FCoE для связи с SAN-инфраструктурой и системой хранения EVA 4400.
Вместе с каждым Virtual Connect модулем поставляется ПО для управления HP Virtual Connect Manager, для Enterprise модулей – HP Virtual Connect Enterprise Manager. С помощью Enterprise Manager можно управлять из одной консоли до 256 доменами (1 домен — 4 Blade системы с Virtual Connect).
После подключения модуля необходимо его сконфигурировать. Делается это либо подключением к Onboard Administrator самой корзины, либо по IP-адресу, который назначается модулю по умолчанию на заводе.
3. Настройка профилей в Virtual Connect Manager
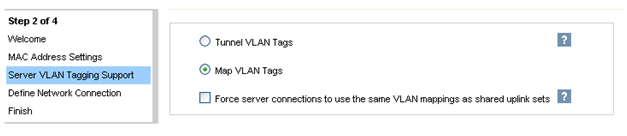
После подключения HP FlexFabric мы должны определить домен, Ethernet-сеть, SAN-фабрику и серверные профили для хостов. Эти настройки производятся в HP Virtual Connect Manager или в командной строке. В нашем примере домен уже был создан, поэтому следующим шагом будет определение VC Sharing Uplink Sets для поддержки Ethernet сетей виртуальных машин с именами HTC-77-A и HTC-77-B. Включаем “Map VLAN tags” функцию в мастере установки.
Функция “Map VLAN tags” дает возможность использовать один физический интерфейс для работы с множеством сетей, используя Shared Uplink Set. Таким образом можно настроить множество VLANs на интерфейсе сетевой карты сервера. Параметры Shared Uplink Sets были заданы в мастере установки VCM. Пример задания SUS:
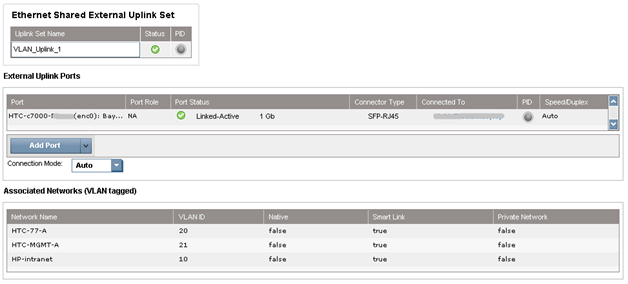
Обе сети «HTC-77-A» и «HTC-MGMT-A» были назначены: VLAN_Uplink_1 на порт 5 модуля 1; второй Shared Uplink Set (VLAN_Uplink_2) был назначен на порт 5 модуля 2, и включает в себя сети HTC-77-B (VLAN 20) и HTC-MGMT-B (VLAN 21). Пример создания сетей Ethernet в VCM:
Модуль HP Virtual Connect может создавать внутренную сеть без аплинков, используя высокопроизводительные 10Gb соединения с бэкплейном корзины с7000. Внутренняя сеть может быть использована для VMware vMotion, а также для организации отказоустойчивости сети. Трафик этой сети не выходит на внешние порты корзины c7000. В нашем случае были настроены 2 сети VMware vMotion. Для консоли управления были настроены две сети с именами HP-MGMT-A и HP-MGMT-B. Порт 6 модулей HP Virtual Connect FlexFabric в отсетках 1 и 2 был использован для подключения к консоли управления.

После этого начинается настройка фабрики SAN. Все довольно просто: в VCM выбрать Define – SAN Fabric. Выбираем SAN-1 модуль в отсеке 1, порт X1. Для второго модуля SAN-2 порт также X1. Пример настройки SAN:

Последним шагом будет «склеивание» всех ранее сделанных настроек в серверный профиль. Это можно сделать несколькими способами: например, через web-интерфейс VCM или через командную строку Virtual Connect – Virtual Connect Scripting Utility (VCSU). Перед установкой ОС необходимо проверить, что все системные, NIC и FC драйверы обновлены, а все параметры сети заданы. Пример создания профиля в CVM:
В VCM выбираем Define – Server Profile, вводим имя профиля и выбираем сетевые подключения профиля из созданных ранее.
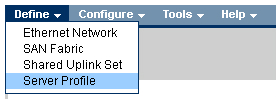
В нашем случае все порты были назначены нами заранее: 6 Ethernet портов и 2 SAN порта на каждый профиль. Профили для отсека 11 и 12 идентичны, т.е. каждый сервер видит один и тот же набор портов. Суммарная скорость не превышает 10Гб/с на каждый порт сетевой карты сервера.
Если в будущем планируется расширение сети, то рекомендуется назначить нераспределенные (unassigned) порты в профиле. Делая так, можно в дальнейшем активировать эти порты без выключения и перезагрузки сервера.
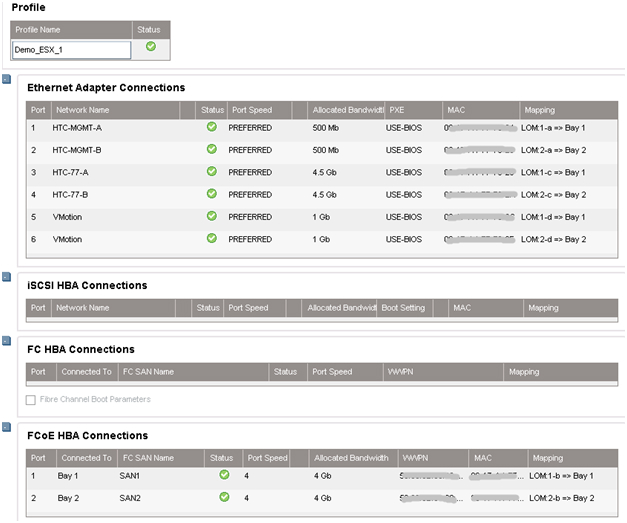
При создании профиля по умолчанию доступны только 2 порта в разделе Ethernet. Чтобы добавить больше, необходимо вызвать контекстное меню правой кнопкой мыши и выбрать “Add connection”.
Назначаем скорость для каждого типа портов: портам управления – 500Mb/s, портам vMotion – 1Gb/s, портам SAN – 4Gb/s и портам виртуальных машин – 4.5Gb/s.
После создания профилей они привязываются к блейд-отсеку корзины в этом же меню.

4. Настройка кластера VMware
На этом настройки корзины завершены. Далее происходит удаленное подключение к самим блейдам и разворачивание VMware ESX 5.0, пример удаленной установки ОС на серверы ProLiant через iLO уже был описан.
В нашем случае вместо Windows в выпадающем меню установщика выбирается VMware и указывается путь к дистрибутиву.
После установки сервер перезагружается и можно приступать к настройке виртуальных машин. Для этого подключаемся к серверу ESX. Заходим в раздел Configuration, создаем 6 vmnics на каждый хост, как и в модуле Virtual Connect: Service Console (vSwitch0), VM Network (vSwitch1), vMotion (vSwitch2). Таким образом мы получаем отказоустойчивую конфигурацию, где каждой сети соответствую 2 vmnics.
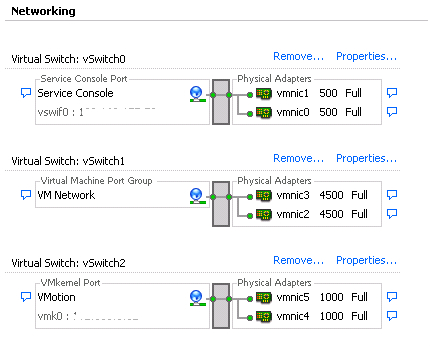
Как только добавляются vmnics можно заметить, что каждому адаптеру автоматически задается скорость, заданная в серверном профиле, при конфигурации в Virtual Connect Manager.
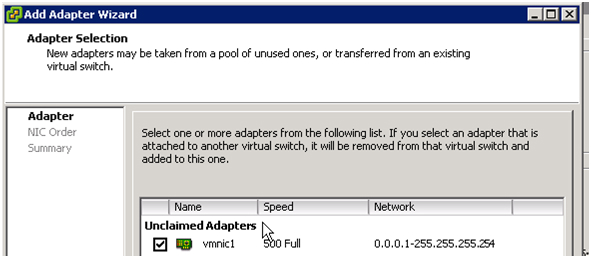
После добавления vmnics объединяем их в группу с помощью vSwitch: вкладка Port – в поле Configuration выбираем vSwitch – Edit, выбираем NIC Teaming, убеждаемся, что оба vmnics видны. Балансировку нагрузки выбираем «Route based on the originating virtual port ID» — эти настройки рекомендуется ставить по умолчанию (подробнее об этом методе можно прочесть на сайте VMware.
5. Настройка дискового массива EVA 4400
В предыдущем обзоре было рассказано как работать с интерфейсом управления дисковыми массивами EVA — Command View.
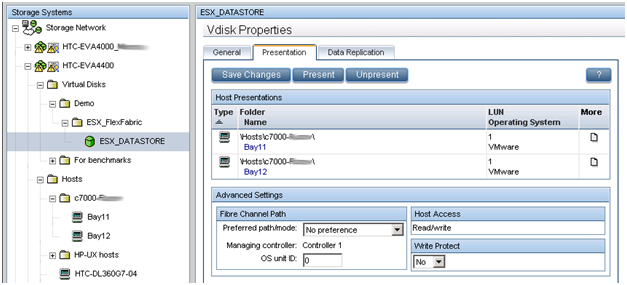
В данном примере мы создаем LUN размером в 500 ГБ, который разделяется между двумя хостами виртуальных машин. По описанному в предыдущей статье методу создается виртуальный диск и презентуется двум хостам ESX. Размер LUN определяется типом ОС и ролями, которые данный кластер будет выполнять. Обязательным условием для кластера (в частности, для VMware vMotion) – LUN должен быть разделяемым. Новый LUN должен быть отформатирован в VMFS, и функция Raw Device mappings (RDMs) для виртуальных машин должна быть задействована.
6. Внедрение VMware HA и VMware vMotion
HP Virtual Connect в сочетании с VMware vMotion дает тот же уровень избыточности, как при использовании двух модулей VC-FC и двух модулей VC-Eth, за исключением того, что только 2 модуля HP FlexFabric необходимы. HP Virtual Connect FlexFabric дает возможность организовать отказоустойчивые пути к общему LUN и отказоустойчивого объединения сетевых интерфейсов (NIC Teaming) для работы в сети. Все настройки VMware vSphere отвечают Best Practices описанным в документе.
Была проведена проверка на доступность кластера. На одном из хостов была развернута виртуальная машина Windows 2008 Server R2.
Виртуальная машина вручную несколько раз была смигрирована с одного сервера на другой, во время мигации кластер оставался доступным.
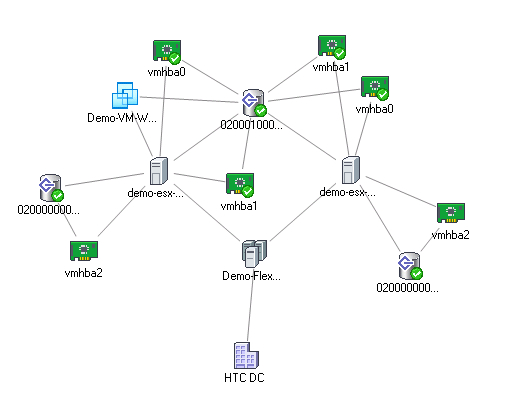
HTC DC – наш DC, Demo-FlexFabric Cluster – наш кластер, Demo-ESX1 и Demo-ESX2 – хосты VMware, vmhba2 – SAS контроллеры блейд-серверов, подключенные к внутренней дисковой подсистеме. Vmhba0 и vmhba1 – два порта встроенных сетевых карт NC553i Dual Port FlexFabric 10Gb Adapter, подключенных к разделяемому LUN EVA 4400. Demo-VM-W2K8R2-01 – виртуальная машина.

В этой статье мы не будем углубляться в какие-либо технические подробности. Вместо этого разберёмся в терминологии VMware. Этот небольшой обзор будет полезен тем, кто хочет понять разницу между базовыми продуктами VMware. Почти все знают об ESXi. А как насчёт vSphere и vCenter? Люди часто путают эти термины, но на самом деле ничего сложного в них нет. Давайте разложим всё по полочкам.
Появившись на рынке в 2001 году, гипервизор VMware ESX (ранее известный как VMware ESX Server) положил начало виртуальной революции. Сегодня VMware — ведущий разработчик программных продуктов для виртуализации (сейчас является частью Dell). Каждые полтора года компания выпускает новое программное обеспечение с расширенными функциями, которое совместимо с большим количеством оборудования, в том числе с накопителями SSD NVMe, жёсткими дисками очень большой ёмкости и новейшими центральными процессорами Intel или AMD.
VMware ESXi
ESXi —— это гипервизор; крошечная частичка программного обеспечения, которая устанавливается на физический сервер и позволяет запускать несколько операционных систем на одном хост-компьютере. Эти ОС работают отдельно друг от друга, но могут взаимодействовать с окружающим миром через сеть. При этом остальные компьютеры подключены к локальной сети (Local Area Network, LAN). Операционные системы запускаются на виртуальных машинах (Virtual Machine, VM), у каждой из которых есть своё виртуальное оборудование.
Существуют платная и бесплатная версии VMware ESXi. У нас можно заказать установку бесплатной версии на выделенные серверы. Функционал бесплатной версии несколько ограничен. Она позволяет консолидировать на одном компьютере ограниченное количество ОС, и ею нельзя управлять через центральный сервер управления — vCenter. Тем не менее, Free ESXi (или VMware ESXi Hypervisor) подключается к удалённым хранилищам, где можно создавать, хранить и использовать виртуальные машины. То есть, это удалённое хранилище может быть разделено между несколькими ESXi-хостами, но не между виртуальными машинами. Виртуальные машины «принадлежат» каждому хосту, что делает невозможным центральное управление.
Работа с бесплатной версией ESXi очень проста и состоит из базовых процессов: обучения, тестирования производственных процессов, проверки систем аварийного восстановления, утверждения архитектурных решений. Используя снапшоты, вы можете проверить корректность работы патчей Windows. Как вариант, это может быть полезно, если вы решили клонировать свой производственный сервер с помощью VMware Converter или технологии P2V, и хотите протестировать пакет обновлений Microsoft перед его установкой.
VMware vCenter
VMware vCenter — это платформа централизованного управления виртуальной инфраструктурой VMware. С её помощью вы можете распоряжаться почти всеми процессами всего с одной консоли. Сервер vCenter можно установить на Windows или развернуть как предварительно настроенную виртуальную машину с помощью Photon OS — мощного дистрибутива на базе Linux. Раньше VMware использовали дистрибутив Suse Linux Enterprise Server (SUSE), но недавно перешли на Photon OS.
vCenter Server — это лицензированное программное обеспечение. Приобрести его можно двумя способами:
- vCenter Server Essentials как часть пакета vSphere Essentials. Эта версия vCenter справляется с управлением тремя хостами с двумя физическими процессорами на каждом. Если у вас небольшая компания, то вы будете оперировать примерно с 60 ВМ, и эта версия vCenter вам подойдёт. С базовым набором вы получаете лицензию не только на vCenter server, но и на ESXi (до трёх хостов с двумя ЦП на каждом).
- Standalone vCenter Server — полноценная самостоятельная версия vCenter server, способная управлять 2 000 хостами с 25 000 рабочих виртуальных машин. Это лицензия исключительно на vCenter. Сам по себе vCenter — только часть лицензионной головоломки. Чтобы управлять всеми хостами с одного устройства, вам нужна лицензия на каждый из них. Лицензии бывают трёх видов: standard, enterprise, enterprise Plus, и каждая распространяется на один процессор. Так что, если вы планируете создать хост с двумя физическими процессорами, то вам понадобится 2 лицензии только для одного этого хоста.
VMware vSphere
VMware vSphere — это коммерческое название всего пакета продуктов VMware. Как говорилось ранее, разные пакеты ПО стоят разных денег. Самые дешёвые — базовые пакеты vSphere essentials или Essentials Plus. Есть ли между ними разница? Да, но она состоит в количестве доступных функций, а не в самом программном наполнении.
В зависимости от типа лицензии, вы получаете доступ к определённому количеству функций, управлять которыми можно через vSphere Web client. Существует также программа vSphere HTML 5 client, но пока что она не пригодна для использования. Компания продолжает её разработку.
В пакете Essentials нет функции High Availability (автоматический перезапуск ВМ), vMotion, ПО для резервного копирования (VDP) и возможности использовать хранилище VSAN.
Пакет Essentials подходит для маленьких компаний, которым не нужно постоянно быть онлайн. С другой стороны, возможность переносить свои виртуальные машины на другой хост и выполнять техническое обслуживание или обновление хоста, оставаясь в сети, даёт вам реальное преимущество. Всё это можно сделать в течение рабочего дня, не перебивая работу пользователей.
Кроме того, в случае непредвиденного аппаратного сбоя, vSphere High Availability (HA) автоматически перезапустит виртуальные машины, которые перестали работать вместе с проблемным хостом. Эти виртуальные машины автоматически перезапускаются на других хостах из кластера VMware. Системе нужно немного времени, чтобы определить, какой компьютер дал сбой и какие хосты могут временно взять на себя его виртуальные машины. У этих хостов должно быть достаточно памяти и мощности ЦП, чтобы выдержать дополнительную нагрузку. Как только система заканчивает анализ, ВМ перезапускаются. Весь процесс автоматизирован и не требует вмешательства администратора.
Подведём итог
Как видите, терминологию VMware понять довольно просто, как и разницу между ESXi, vSphere и vCenter. Система лицензирования также ясна. Сам по себе гипервизор бесплатный, но его функционал ограничен, вследствие чего такое ПО не застраховано от потери данных. Поэтому ESXi предназначен для использования только в тестовых средах.
Читайте также: